262
IMPLEMENTASI ALGORITMA C5.0 DALAM KLASIFIKASI
PENDAPATAN MASYARAKAT (STUDI KASUS: KELURAHAN
MESJID KECAMATAN MEDAN KOTA)
Apriani Candra Wijaya, Nelly Astuti Hasibuan, Putri RamadhaniProgram Studi Teknik Informatika STMIK Budi Darma, Medan, Indonesia Jl. Sisingamangaraja No. 338 Simpang Limun, Medan, Indonesia
ABSTRAK
Kelurahan Mesjid adalah kelurahan yang bergerak dibidang Kemasyarakatan. Dalam menentukan kelayakan mendapatkan bantuan langsung tunai bagi masyarakat Kelurahan Mesjid cenderung bingung untuk menentukan atribut apa saja yang paling menetukan kelayakan tersebut, karena ada beberapa atribut yang menentukan tingkat kelayakan yang mendapatkan bantuan langsung tunai.Dalam penelitian ini, peneliti mencoba untuk menganalisis poin utama dari masalah yang ada dan tekad oleh temuan memperkuat kasus ini bahwa data dan hasil keputusan menggunakan data mining dengan metode algoritma C5.0 Pohon keputusan dapat menemukan hubungan tersembunyi antara sejumlah variabel input dengan sebuah variabel target dari data Masyarakat kelurahan mesjid.Penelitian ini menghasilkan pohon keputusan dari kasus yang diangkat menunjukkan bahwa ada beberapa atribut yang mempengaruhi dalam penentuan masyarakat yang mendapatkan BLT. Akan ditampilkan daftar nilai gain dari tiap atribut. Posisi atribut yang memiliki nilai gain paling tinggi yang ditampilkan menunjukkan penentuan atribut mana menjadi penentuan kelayakan.
Kata Kunci: Data Mining, Algoritma C5.0, Kelayakan Bantuan
I. PENDAHULUAN
Klasifikasi merupakan penyusunan bersistem dalam kelompok atau golongan menurut kaidah yang ditetapkan. Klasifikasi digunakan dalam berbagai sektor kehidupan. Salah satunya ekonomi. Program Bantuan untuk masyarakat miskin merupakan program yang membantu masyarakat miskin untuk tetap memenuhi kebutuhan hariannya. Program bantuan untuk masyarakat miskin yakni BLT (Bantuan Langsung Tunai). Salah satu kelurahan di Kota Medan yang mendapatkan program bantuan untuk masyarakat miskin yaitu Kelurahan Mesjid, namun program
bantuan untuk masyarakat miskin yang di
selenggarakan oleh pemerintah masih belum tergolong sukses, karena masih banyak masyarakat miskin yang belum mendapatkan program bantuan tersebut dan sebaliknya, masyarakat yang tergolong mampu yang
mendapatkan bantuan. Berdasarkan data-data
pendapatan masyarakat yang diperoleh berdasarkan data sensus penduduk, maka data pendapatan masyarakat di klasifikasi menjadi tiga golongan yaitu
pendapatan masyarakat ekonomi kelas tinggi,
pendapatan masyarakat ekonomi kelas menengah, pendapatan masyarakat ekonomi kelas rendah.
Untuk mengelompokkan golongan pendapatan masyarakat tersebut maka digunakan 3 kriteria, yaitu jumlah anggota keluarga, pendapatan perbulan, dan pengeluaran perbulan. oleh karena itu dibutuhkan suatu alat analisis yang mampu menganalisis dengan baik data yang sangat besar tersebut.
Terdapat beberapa langkah dalam pengolahan data sebelum melakukan data mining, yakni membersihkan data dari noise dan data yang tidak konsisten, mengkombinasikan kembali data-data yang telah bersih, maka kita akan memiliki database yang baru, selanjutnya data dilihat kembali apakah membutuhkan suatu transformasi ataukah tidak,
barulah setelah itu data dapat diolah [2]. Klasifikasi merupakan pengelompokkan yang sistematias pada sejumlah objek, gagasan, buku atau benda-benda lain ke dalam kelas atau golongan tertentu berdasarkan ciri-ciri yang sama. Ada beberapa metode yang digunakan untuk mengklasifikasi data, seperti metode C5.0. Metode tersebut dibandingkan akurasinya untuk
kemudian digunakan sebagai model dalam
mengklasifikasi data pendapatan masyarakat tersebut. Metode C5.0 sangat mendukung dalam pembagian pohon keputusan dengan 2 atau lebih subgrup. II. TEORITIS
A. Implementasi
Menurut Purwanto dan Sulistyastuti,
implementasi adalah kegiatan untuk mendistribusikan keluaran kebijakan (to deliver policy output) yang dilakukan oleh para implementer kepada kelompok
sasaran(target group) sebagai upaya untuk
mewujudkan tujuan kebijakan. Tujuan kebijaka
diharapkan akan muncul manakala policy output dapat diterima dan dimanfaatkan dengan baik oleh kelompok sasaran sehingga dalam jangka panjang hasil kebijakan akan mampu diwujudkan. Implementasi merupakan salah satu tahapan dari serangkai proses atau siklus suatu kebijakan.
B. Data Mining
Berry dan linoff dalam bukunya data mining technique for marketing, Sales, and Customers Support mendefenisikan data mining sebagai suatu proses eksplorasi dan analisis secara otomatis maupun semiotomatis terhadap data dalam jumlah besar dengan tujuan menemukan pola atau aturan yang berarti.Dalam situasi ini yang melekat dapat berupa korelasi dikontrol untuk, atau dihapus sama sekali, selama kontruksi
263 desain eksperimental, Untuk dapat lebih jelas
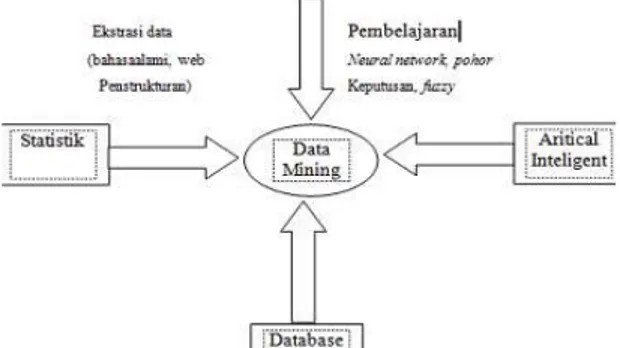
memahami data mining, perhatikan gambar 3.1
Gambar 1. Bidang Ilmu Data Mining C. Proses Data Mining
Salah satu tahapan dalam keseluruhan proses KDD adalah data mining. Proses KDD secara garis besar dapat dijelaskan sebagai berikut.
1. Data Selection
Pemilihan ( seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian inormasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional. 2. enrichmentPre-processing/ Cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain yang membuang duplikasi data, memeriksa data yang konsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Juga dilakukan proses enrichment, yaitu proses “ memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
D. Pengelompokan Data Mining 1. Deskripsi
Terkadang peneliti dan analis secara sederhana ingin mencoba mencari data untuk menggambarkan pola dan kecenderungan yang terdapat dalam data. Sebagai contoh, petugas pengumpulan suara mungkin tidak dapat menentukan keterangan atau fakta bahwa siapa yang tidak cukup professional akan sedikit didukung dalam pemilihan presiden.
2. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih kearah numerik dari pada
kearah kategori. Model dibangun menggunakan record
lengkap yang menyediakan nilai dari variabel target sebagai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variabel target dibuat berdasarkan nilai variabel predikasi. Sebagai contoh akan dilakukan estimasi tekanan darah sistolik pada pasien rumah sakit berdasarkan umur pasien, jenis kelamin, indeks berat badan, dan level sodium darah. Model estimasi yang dihasilkan dapat digunakan untuk kasus baru lainnya.
3. Prediksi.
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam predikasi nilai dari hasik akan ada dimasa mendatang.
Contoh prediksi bisnis dan penelitian adalah:
a. Prediksi harga beras dalam tiga bulan yang akan datang.
b. Prediksi persentasi kenaikan kecelakaan lalu lintas tahun depan jika batas bawah kecepatan dinaikkan. Beberapa metode dan teknik yang digunakan dalam klasifikasi dan estimasi dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi.
4. Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori. Sebagai contoh penggolongan pendapatan dapat dipisahkan dalam tiga kategori,yaitu pendapatan tinggi, pendapatan sedang, dan pendapatan rendah. Contoh lain klasifikasi dalam bisnis dan penelitian adalah:
a. Menentukan apakah suatu transaksi kartu kredit merupakan transaksi yang curang atau tidak.
b. Memperkirakan apakah suatu pengajuan hipotek
oleh nasabah merupakan suatu kredit yang baik atau buruk.
c. Mendiagnosis penyakit seorang pasien untuk
mendapatkan termasuk kategori penyakit apa. 5. Pengklusteran
Pengklusteran merupakan pengelompokan record,
pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan. Kluster adalah kumpulan record yang memiliki kemiripan satu dengan yang lainnya dan memiliki ketidakmiripan dengan record-record dalam kluster lain.
E. Algoritma C5.0
Adalah salah satu algoritma klasifikasi data mining yang khususnya diterapkan pada teknik decision tree.
C5.0 merupakan penyempurnaan algoritma
sebelumnya yang dibentuk oleh Ross Quinlan pada tahun 1987, yaitu ID3 dan C4.5. Dalam memilih atribut untuk pemecah objek dalam beberapa kelas harus dipilih atribut yang menghasilkan information gain paling besar.
Ket :
S = himpunan kasus S1 = jumlah sampel Pi = proporsi kelas
Untuk mendapatkan informasi nilai subset dari atribut A tersebut maka digunakan formula dibawah ini : Untuk mendapatkan nilai gain selanjutnya digunakan formula dibawah ini :
264 𝐺𝑎𝑖𝑛 𝐴 = 𝐼 𝑆1 , 𝑆2 , … , 𝑆𝑚 − E ... 3 Ket : A = atribut S = himpunan kasus S1 = jumlah sampel
III. ANALISA dan PEMBAHASAN
Berhubungan dengan Klasifikasi Pendapatan Masyarakat dilakukan analisis data. Proses mencari data yang diperoleh dari hasil studi lapangan seperti wawancara, dan pengamatan yang dilakukan dan hasilnya nanti akan dapat membentuk pohon keputusan. Program bantuan untuk masyarakat miskin yakni BLT (Bantuan Langsung Tunai). Salah satu kelurahan di Kota Medan yang mendapatkan program bantuan untuk masyarakat miskin yaitu Kelurahan Mesjid, namun program bantuan untuk masyarakat miskin yang di selenggarakan oleh pemerintah masih belum tergolong sukses, karena masih banyak masyarakat miskin yang belum mendapatkan program bantuan tersebut dan sebaliknya.
Setelah melakukan analisa masalah, selanjutnya menentukan variabel input data. Pada algoritma C5.0 akan dilakukan perancangan decision tree, dengan memilih atribut pada field- field data sebagai akar, membuat cabang untuk masing-masing nilai. Membagi kasus dalam cabang, dan mengulangi proses untuk masing-masing cabang sampai semua kasus pada cabang memiliki kelas yang sama. Proses pengambilan keputusan dalam klasifikasi pendapatan masyarakat dikelompokkan menjadi beberapa kriteria. Proses pengambilan keputusan dalam klasifikasi Masyarakat yang mendapatkan BLT dikelompokkan menjadi beberapa kriteria, Berdasarkan variabel-variabel yang sudah dipilih dari 20 data sampel, format data menjadi seperti tabel 1.
Table 1. Sampel data yang digunakan Umur Pendidi kan Peker jaan Pemilik an Rumah Jumlah Anggota Keluarga Pendapata n Keputusan 25 SMA Penja hit Numpa ng
Banyak Rendah Layak
30 SMP Penja
hit
Kontrak Normal Menengah Tidak Layak
32 SMP Supir Milik
Pribadi
Banyak Menengah Layak
34 SMA Penja
hit
Numpa ng
Banyak Menengah Layak
27 SD Supir Numpa
ng
Normal Menengah Tidak Layak
Umur Pendidi kan Peker jaan Pemilik an Rumah Jumlah Anggota Keluarga Pendapata n Keputusan
35 SMP Supir Kontrak Banyak Menengah Layak
34 SMA Penja
hit Milik Pribadi
Banyak Rendah Layak
28 SMP Supir Numpa
ng
Banyak Rendah Layak
27 SD Supir Numpa
ng
Normal Menengah Tidak Layak
25 SD Pedag
ang Numpa ng
Normal Menengah Layak 26 SMP Supir Kontrak Normal Rendah Tidak Layak
27 SMP Penja
hit Milik Pribadi
Banyak Menengah Layak
25 SMA Penja
hit Milik Pribadi
Normal Rendah Layak
50 SMA Pedag
ang Numpa ng
Banyak Rendah Layak
43 SMP Supir Kontrak Normal Menengah Tidak Layak
29 SMP Supir Numpa
ng
Normal Menengah Tidak Layak
26 SMA Penja
hit
Numpa ng
Normal Menengah Layak
28 SMA Penja
hit
Kontrak Normal Menengah Tidak Layak 42 SMA Supir Kontrak Banyak Menengah Layak
24 SD Supir Kontrak Normal Rendah Tidak Layak
Dari tabel diatas, dapat dijelaskan bawah data yang diperoleh adalah Data Pendapatan Masyarakat, Selanjutnya akan diproses secara transformasi data yaitu data diubah dalam bentuk kategori yang sesuai proses data mining agar data siap dihitung menggunakan algoritma C5.0. Berikut ini beberapa criteria yaitu Usia , Pendidikan, Pekerjaan, Pemilikan rumah, Jumlah anggota keluarga, dan pendapatan. Dibentuk menjadi kategori data berdasarkan nilai setiap atribut.
Tabel 2. Kriteria Usia
Usia Kategori Usia
20-30 Tahun Muda
31- 60 Tahun Tua
Tabel 3. Kriteria Pendidikan
Pendidikan Kategori
Tamat SD Kurang Baik
Tamat SMP Cukup Baik
Tamat SMA Baik
265
Kategori Pekerjaan Kategori
Supir Cukup
Pedagang Baik
Petani Sangat Baik
Penjahit Kurang Baik
Tabel 5. Kriteria Jumlah Anggota Keluarga
Pemilikan Rumah Kategori
Numpang Miskin
Kontrak Sederhana
Milik Pribadi Kaya
Tabel 6. Kriteria Jumlah Anggota Keluarga
Jumlah Anggota Keluarga Kategori
1-4 Orang Normal
>5 Orang Banyak
B. Penyelesaian Pohon Keputusan
Untuk melihat atribut sebagai akar, didasarkan pada nilai Gain tertinggi dari atribut-atribut yang ada.
Untuk menghitung Gain digunakan rumus (3.1),
sedangkan untuk menghitung nilai Entropy dapat
dilihat pada rumus (3.2). Menghitung jumlah kasus, jumlah untuk keputusan “Layak”, jumlah kasus untuk keputusan “Tidak Layak”, dan kasus yang dibagi
berdasarkan atribut Umur, Pendidikan, Pekerjaan,
Pemilikan Rumah, Jumlah Anggota Keluarga dan Pendapatan. Setelah itu, lakukan perhitungan Gain untuk setiap atribut.
1. Nilai Entropy
a. Entropy Total = Entropy (S) = ∑𝑛 −
𝑖=𝑙 pi*log₂
pi
Entropy Total = (8/20 * log 2 (8/20) + (-12/20 * log 2 ((-12/20)) = 0,97088
b. Entropy Usia
Nilai atribut “Tua” = (1/7 * log 2 (1/7) + (-6/7 * log 2 ((-6/7)) =0,59151
Nilai atribut “Muda” = ((-1/13 * log 2 (1/13) + (-6/13 * log 2 (6/13)) =0,79941
c. Entropy Pendidikan
Nilai atribut “ SD” = ((-1/4 * log 2 (1/4) + (-3/4 * log 2 (3/4)) =0,86577
Nilai atribut “ SMP” = ((-4/8 * log 2 (4/8) + (-4/8 * log 2 (4/8)) =0,43556
Nilai atribut “ SMA” = ((-7/8 * log 2 (7/8) + (-1/8 * log 2 (1/8)) =0,33654
d. Entropy Pekerjaan
Nilai atribut “Supir” = ((-2/ 8* log 2 (2/8) + (-6/8 * log 2 (6/8)) =0,81117
Nilai atribut “Penjahit” = ((-6/10 * log 2 (6/10) + (-4/10 * log 2 (4/10)) =0,97086
Nilai atribut “Pedagang” = ((-0/2 * log 2 (0/2) + (-2/2 * log 2 (2/2)) = 0
e. Entropy Pemilikan Rumah
Nilai atribut “Numpang” = ((-3/9 * log 2 (3/9) + (-6/9 * log 2 (6/9)) =0,66073
Nilai atribut “Kontrak” = ((-6/7 * log 2 (6/7) + (-2/7 * log 2 (2/7)) =0,65360
Nilai atribut “ Milik Pribadi” = (0/4 * log 2 (0/4) + (-4/4 * log 2 ((-4/4)) = 0
f. Entropy Jumlah Anggota Keluarga
Nilai atribut “Normal” = ((-8/11 * log 2 (8/11) + (-3/11 * log 2 (3/11)) = 0,66220
Nilai atribut “Banyak” = ((-0/9 * log 2 (0/9) + (-9/9 * log 2 (9/9)) = 0
g. Entropy Pendapatan
Nilai atribut “Rendah” = ((-6/13 * log 2(6/13)+(7/13 * log 2 (7/13)) =0,99569
Nilai atribut “Menengah” = ((-2/7 * log 2 (2/7) + (-5/7 *log 2 (5/7)) = 0,86307
IV. IMPLEMENTASI
Tahap implementasi merupakan tahap penerapan sistem supaya dapat dioperasikan. Pada tahap ini dijelaskan mengenai kebutuhan sistem yang digunakan seperti perangkat keras, dan perangkat lunak yang digunakan untuk proses pengolahan data, dan proses pengujian.
Sebelum pengujian, data terlebih dahulu diolah menjadi format *.arff agar bisa di implementasikan
menggunakan WEKA (Weikato Environment
Knowledge and Analysis ). arff adalah format yang
digunakan dalam WEKA (Weikato Environment
Knowledge and Analysis ). Data yang sudah dibuat
menggunakan database microsoft excel terlebih
terlebih dahulu diubah ke format *.csv. Berikut langkah-langkah mendapatkan format *.csv.
1. Buka File Microsoft Excel yang akan diolah lalu klik Save As.
Gambar 1. Tampilan pembuatan format csv
2. Simpan ke dalam format *.csv (command
266 Gambar 2. Tampilan pembuatan format csv
3. Selanjutnya buka aplikasi WEKA (Weikato
Environment Knowledge and Analysis ) dan Klik Eksplorer
Gambar 3. Tampilan WEKA untuk ubah format csv ke
arff
4. Klik open file dan buka file *.csv yang sudah disimpan.
Gambar 4. Tampilan WEKA untuk ubah format csv ke
arff
5. Jika file sudah masuk lalu klik save untuk menyimpan file ke format .*arff.
Gambar 5. Tampilan WEKA untuk ubah format csv ke
arff
6. Dibawah ini merupakan tampilan format arff. Buka
dengan notepad ++.
Gambar 6. Tampilan format arff A. Pengujian
Pada tahap pengujian menggunakan software
WEKA (Weikato Environment Knowledge and Analysis ) untuk melihat hasil dari perhitungan menggunakan algoritma C5.0. Berikut adalah langkah-langkah
pengujian menggunakan WEKA(Weikato Environment
Knowledge and Analysis ).
1. Pada menu utama pilih Eksplorer.
Eksplore digunakan untuk menggali lebih jauh data
dengan aplikasi WEKA.
Gambar 7. Tampilan pengujian
2. Selanjutnya klik Open file untuk membuka
dokumen yang telah disimpan.
267 3. Pilih folder data pendapatan masyarakat yang
sudah diolah lalu klik Open.
Gambar 9. Tampilan Pengujian 4. Klik Classify
Classify digunakan untuk proses klasifikasi atau prediksi.
Gambar 10. Tampilan Pengujian 5. Lalu klik Choose
Choose digunakan untuk memilih bentuk pohon keputusan.
Gambar 11. Tampilan Pengujian
6. Pilih folder trees lalu klik J48 J48 atau sama dengan algoritma C5.0
Gambar 12. Tampilan Pengujian
7. Kemudian kik Start untuk memulai klasifikasi, lalu klik kanan pada result list.
Gambar 13. Tampilan pengujian
8. Lalu pilih Visualize tree untuk melihat bentuk pohon keputusan.
Gambar 14. Tampilan pengujian
9. Finish atau tampilan pohon keputusan hasil dari pengujian.
Gambar 15. Tampilan Hasil Pengujian V. KESIMPULAN
Dari hasil penenlitian yang penulis lakukan pada KELURAHAN MESJID KECAMATAN MEDAN
268
penentuan untuk mengklasifikasi pendapatan
masyarakat menggunakan metode C5.0 akan
bermanfaat sekali dalam mengklasifikasi data
pendapatan masyarakat pada KELURAHAN MESJID CECAMATAN MEDAN KOTA. Maka dapat disimpulkan bahwa:
1. Dengan algoritma C5.0 dan pengujian Weka
dapat membantu klasifikasi pendapatan
masyarakat dikelurahan.
2. Proses untuk menghasilkan kombinasi item
menggunakan algoritma C5.0 dilakukan dengan
menerapkan nilai Entropy dan nilai Gain
tertinggi. Untuk membentuk pohon keputusan.
3. Pengujian yang telah dilakukan dapat
disimpulkan bahwa data mining menggunakan
metode pohon keputusan algoritma C5.0 untuk
membentuk pohon keputusan dalam
mengklasifikasi pendapatan masyarakat
menggunakan aplikasi Weka dan mendapatkan hasil yang maksimal .
REFERENCES
[1] Purwanto, Erwan A. dan Dyah Ratih Sulistyastuti,2012. Implementasi Kebijakan Public : konsep dan aplikasinya diindonesia. Yogyakarta : Gava Media.
[2] Kusrini, luthfi taufiq Emha, Algoritma Data Mining, 2009, Penerbit Andi, Yogyakarta.
[3] Larose D, T., Data Mining Methods and Models, 2006, Jhon Wiley & Sons, Inc. Hoboken New Jersey
[4] Yogi Yusuf W. Membandingkan performasi algoritma decision tree C5.0 CART dan CHAID untuk kasus prediksi status resiko kredit di suatu bank.2007
[5] Departemen Pendidikan dan Kebudayaan, Kamus Besar Bahasa Indonesia, (Jakarta: Balai Pustaka,1998).
[6] BN. Marbun, Kamus Manajemen,(Jakaarta:Pustaka Sinar Harapan,2003).
[7] Pitma Pertiwi. Analisis Faktor-Faktor Yang Mempengaruhi
Pendapatan Tenaga Kerja Daerah Istimewah
Yogyakarta.2015.
[8] Reksoprayitno, Sistem Ekonomi dan Demokrasi Ekonomi, (Jakarta:Bina Grafika,2004).
[9] Andi Nugroho, Rekayasa Perangkat Lunak Berorientasi Objek, 2010
[10] Aksenova, Svetlana S. Mechine Learning with WEKA – WEKA Tutorial – Explore Tutorial for WEKA Version 3.4.3. 2004. California:California State University.
[11] E. Buulolo, N. Silalahi, Fadlina, and R. Rahim, “C4.5 Algorithm To Predict the Impact of the Earthquake,” Int. J.
Eng. Res. Technol., vol. 6, no. 2, 2017.
[12] H. Widayu, S. D. Nasution, N. Silalahi, and M. Mesran, “DATA MINING UNTUK MEMPREDIKSI JENIS TRANSAKSI NASABAH PADA KOPERASI SIMPAN PINJAM DENGAN ALGORITMA C4.5,” MEDIA Inform.
BUDIDARMA, vol. 1, no. 2, Jun. 2017.
[13] E. Buulolo, “ALGORITMA APRIORI PADA DATA PENJUALAN DI SUPERMARKET,” in Seminar Nasional
Inovasi dan Teknologi Informasi 2015 (SNITI), 2015, no.
September 2015, pp. 4–7.
[14] J. Simarmata, Pengenalan Teknologi Komputer dan Informasi. Yogyakarta: Andi, 2006.
[15] M. Maharani et al., “IMPLEMENTASI DATA MINING
UNTUK PENGATURAN LAYOUT MINIMARKET
DENGAN MENERAPKAN ASSOCIATION RULE,” J. Ris.
Komput., vol. 4, no. 4, pp. 6–11, 2017.
[16] J. Simarmata, Rekayasa Perangkat Lunak. Yogyakarta: Andi, 2010.
[17] F. T. Waruwu, E. Buulolo, and E. Ndruru, “IMPLEMENTASI ALGORITMA APRIORI PADA ANALISA POLA DATA PENYAKIT MANUSIA YANG DISEBABKAN OLEH ROKOK,” KOMIK (Konferensi Nas. Teknol. Inf. dan
Komputer), vol. I, no. 1, pp. 176–182, 2017.
[18] E. Buulolo, “Implementasi Algoritma Apriori Pada Sistem Persediaan Obat ( Studi Kasus : Apotik Rumah Sakit Estomihi Medan ),” Pelita Inform. Budi Dharma, vol. 4, no. Agustus 2013, pp. 71–83, 2013.