235
CLUSTERING PENGGUNAAN BANDWIDTH MENGGUNAKAN
METODE K-MEANS ALGORITHM PADA PENERAPAN SINGLE
SIGN ON (SSO) UNIVERSITAS SEBELAS MARET
Vignasari Kokasih1, Wiranto2, Afrizal Doewes31,2,3Program Studi Informatika, FMIPA, Universitas Sebelas Maret
Email: 1[email protected], 2[email protected], 3afrizal [email protected]
ABSTRAK
Akses internet melalui sistem Single Sign On (SSO) di Universitas Sebelas Maret telah banyak di manfaatkan oleh civitas akademik seperti mahasiswa dan karyawan/dosen. Data dari aktifitas penggunaan SSO tersebut tercatat pada log SSO dan telah terkumpul banyak. Pada log tersebut tercatat mengenai: (1) status perangkat jaringan yang di gunakan, (2) riwayat login pengguna dan (3) riwayat logout pengguna SSO. Pada riwayat login dan logout pengguna terdapat detail data seperti jumlah bandwidthdownload dan upload yang digunakan, waktu login, waktu logout dan lain-lain. Teknik data mining dapat di terapkan untuk menggali informasi dari data log SSO yang telah terkumpul banyak. Tujuan penelitian ini untuk menganalisa penggunaanbandwidth Universitas Sebelas Maret (UNS) berdasarkan data trafik internet dari log SSO dengan menggunakan metode data clustering untuk mengelompokkan data yang mempunyai kesamaan dalam satu cluster, yaitu menggunakan algoritma K-means.
Kata Kunci: Data Mining, Clustering, K-Means, Single Sign On
1. PENDAHULUAN
Koneksi internet saat ini telah menjadi bagian yang penting bagi civitas akademika Universitas Sebelas Maret (UNS) mengingat seluruh aktifitas administrasi, keuangan, dan akademik telah di kembangkan dengan sistem berbasis informasi. Kebutuhan akan internet tersebut telah mendorong pihak pimpinan untuk melakukan perbaikan dan pembenahan atas fasilitas internet yang di sediakan. Salah satunya adalah dengan menetapkan kebijakan sistem Single Sign On (SSO) yang mulai diterapkan di hampir seluruh area kampus Universitas Sebelas Maret.
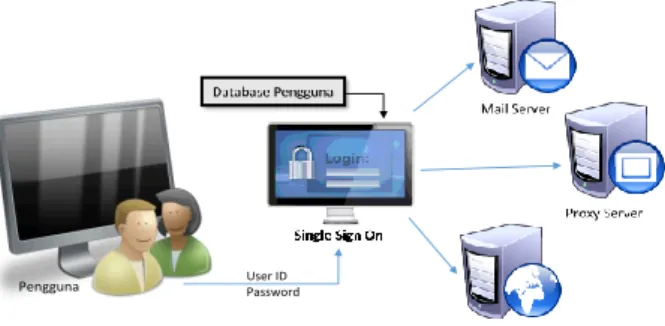
Single Sign On (SSO) adalah sistem yang mengizinkan pengguna agar dapat mengakses seluruh sumber daya dalam jaringan hanya dengan menggunakan satu credential (akun) saja [1]. Sistem Single Sign On menghindari login ganda terhadap aplikasi-aplikasi yang diintegrasikan ke dalam sistem ini, sehingga pengelolaan hak akses aplikasi menjadi terpusat. Sementara pada sistem sign on biasa mengharuskan pengguna untuk selalu login saat melakukan akses pada beberapa aplikasi yang berbeda. Secara umum gambaran sistem single sign on dan sistem sign on biasa dapat dilihat pada Gambar 1 dan Gambar 2.
Gambar 1. Sistem Single Sign On (SSO).
Gambar 2. Sistem sign on biasa. Pengguna User ID Password
Pengguna User ID Password User ID Password User ID Password
Selain sebagai pemusatan data pengguna, sistem single sign on yang sekarang ini di terapkan di UNS juga di manfaatkan untuk sarana pembagian bandwidth. Semua data aktifitas pengguna SSO yang mengakses internet dengan menggunakan jaringan kampus akan tercatat dalam log SSO yang di dalamnya terdapat 3 blok informasi, yakni: (1) status perangkat jaringan, (2) status pengguna yang melakukan login, (3) status pengguna logout. Setiap blok informasi tersebut terdapat detail informasi yang dapat diambil untuk mengetahui pola penggunaan bandwidth.
Pada penelitian ini akan dilakukan analisa data trafik internet dengan melakukan pengelompokan data atau sering disebut sebagai clustering. Clustering adalah pembagian data ke dalam beberapa kelompok yang memiliki kemiripan. Setiap kelompok disebut sebagai cluster yang terdiri dari data-data yang mirip diantara mereka dan berbeda dengan data kelompok lain [2]. Ada beberapa algoritma dalam clustering, salah satunya adalah algoritma K-means (KMA), yaitu algoritma yang paling sederhana dan paling umum digunakan dalam kriteria kesalahan kuadrat [3]. Algoritma K-means populer karena mudah untuk diterapkan dan kompleksitas waktunya adalah O(n), di mana n adalah jumlah pola (pattern).
Pemodelan peramalan kebutuhan bandwidth dengan menggunakan metode regresi linier untuk menentukan variable input peramalan, sedangkan jaringan syaraf tiruan backpropagation digunakan untuk tahap peramalan. Data yang digunakan adalah data trafik internet di FMIPA UNS dan mendapatkan simpulan bahwa pemodelan terbaik adalah model download average pada r= 0.91 [4].
Dalam penelitian yang berjudul “The Development of Web Log Mining Based on Improved K-means Clustering Analysis” melakukan analisis terhadap penggalian data pada web log dengan menggunakan K-means. Pada penelitian ini mengusulkan indeks efektif dari algoritma clustering K-means dan diverifikasi dengan melakukan beberapa kali percobaan. Pada penelitian ini juga mengusulkan pemilihan cluster awal secara otomatis menggunakan metode pemilihan centroid dan simpulan yang di dapatkan adalah pemilihan inisialisasi awal cluster tersebut dapat mengurangi outlier dan meningkatkan hasil clustering [5].
Berdasarkan penelitian di atas, penelitian ini mengusulkan untuk melakukan pengolahan data trafik internet tidak hanya pada satu fakultas saja, namun data yang di pakai mencakup seluruh wilayah UNS yang telah menerapkan system SSO dan bertujuan untuk melihat pola persebaran penggunaan bandwidth di UNS pada hari aktif dari tanggal 15 Maret 2015–24 Juni 2015 dengan menggunakan algoritma K-means (KMA).
2. METODE
2.1. Pengumpulan Data
Data yang digunakan adalah data trafik internet yang di dapatkan dari log SSO tanggal 15 Maret 2015–24 Juni 2015. Log SSO adalah kumpulan status keberjalanan SSO yang tercatat pada setiap harinya untuk setiap aktifitas yang dilakukan oleh pengguna maupun perangkat jaringan yang bersangkutan. Pada log ini terdapat 3 blok informasi, yakni: (1) status perangkat jaringan, (2) status pengguna yang melakukan login, (3) status pengguna logout. Setiap blok informasi tersebut terdapat detail informasi yang dapat diambil untuk mengetahui kepadatan trafik akses internet.
2.2. Preprocessing
Pada tahap ini dilakukan seleksi/pemilihan data dengan membuang data log pada hari libur, yaitu: Hari Sabtu dan Minggu.
Hari libur Nyepi 21 Maret 2015.
Hari libur wafatnya Isa Al Masih 3 April 2015. Hari libur buruh Internasional 1 Mei 2015. Hari libur kenaikan Isa Al Masih 14 Mei 2015. Hari libur Isra’ Miraj 16 Mei 2015.
Hari libur Waisak 2 Juni 2015.
Selanjutnya data kembali diseleksi dengan membuang data yang atributnya bernilai NULL. Kumpulan data yang telah di seleksi tersebut akan di ambil atribut total download data (bytes), total upload data (bytes), lokasi akses, tanggal akses dan waktu (s) session yang di gunakan untuk tiap-tiap pengguna. Jika dari ke-5 atribut tersebut pada atribut total download dan total upload data bernilai sama dengan 0, maka atribut tersebut dianggap tidak valid karena dari data tersebut menunjukkan bahwa pengguna tidak melakukan aktifitas akses jaringan/internet sehingga data akan di hapus.
237
Setelah itu, dari data yang di dapat akan di ubah menjadi kecepatan bandwidth rata-rata dengan membagi total data dengan waktu session yang di gunakan pengguna. Sehingga output dari tahap preprocessing ini adalah:
1) Lokasi akses. 2) Tanggal akses.
3) Bandwidth download rata-rata (bytes/s). 4) Bandwidth upload rata-rata (bytes/s).
Output tahapan preprocessing yang akan digunakan pada tahap data clusteringadalah atribut bandwidth download rata-rata dan bandwidth upload rata-rata yang di nyatakan dalam satuan bytes/s. Sedangkan data lokasi akses dan tanggal akses akan digunakan untuk pembagian data yang akan di cluster.
2.3. Data Clustering
Data Clustering (atau hanya disebut clustering), juga disebut analisis cluster, analisis segmentasi, analisis taksonomi atau klasifikasi tanpa pengawasan (unsupervised classification) adalah metode untuk membuat kelompok objek atau cluster, sedemikian sehingga bahwa objek yang sangat mirip dikatakan dalam satu cluster sedangkan objek di-cluster yang berbeda mempunyai perbedaan yang cukup jelas [6]. Clustering merupakan komponen penting dari data mining yaitu proses mengeksplorasi dan menganalisis data dalam jumlah besar untuk menemukan informasi yang berguna [7]. Clustering juga merupakan persoalan mendasar dalam literatur pengenalan pola (pattern recognition).
Langkah-langkah algoritma K-Means adalah sebagai berikut [8]. 1) Menentukan k sebagai jumlah cluster yang ingin dibentuk.
2) Membangkitkan nilai random untuk pusat cluster awal (centroid) sebanyak k.
3) Menghitung jarak setiap data input terhadap masing-masing centroid menggunakan rumus jarak Eucledian (Eucledian Distance) hingga ditemukan jarak yang paling dekat dari setiap data dengan centroid. Berikut adalah persamaan Eucledian Distance:
[∑ ( ) ] [ ] (1)
Dimana xj dan yj berturut-turut adalah nilai atribut x dan y yang ke-j.
4) Mengelompokkan setiap data berdasarkan kedekatannya dengan centroid (jarak terkecil). 5) Memperbaharui nilai centroid.
6) Melakukan perulangan dari langkah 2-5 hingga anggota tiap clustertidak ada yang berubah. 3. HASIL DAN PEMBAHASAN
Penelitian ini menggunakan data log SSO dari tanggal 15 Maret 2015–24 Juni 2015 yang telah di proses dan akan di lakukan proses clustering terhadap data bandwidth download rata-rata dan bandwidth upload rata-rata, yang akan di bedakan berdasarkan tempat akses dan waktu (bulan). Jumlah total data dari log ini ±350.017 data transaksi dan setelah dilakukan tahap pre-processing, didapatkan ±302.783 data transaksi yang akan di olah ke dalam 7 cluster.
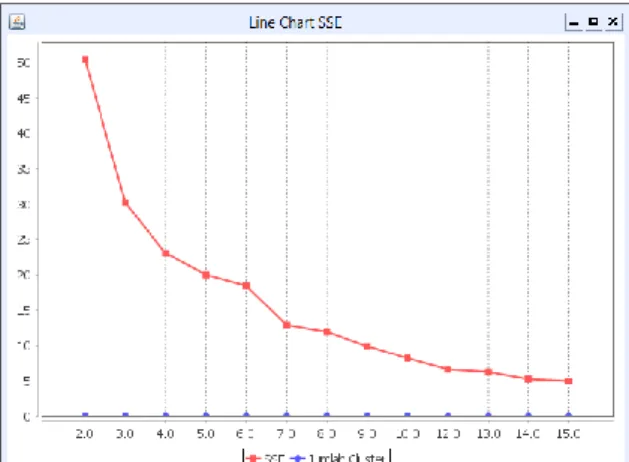
Nilai cluster k= 7 di dapatkan dengan melakukan beberapa kali percobaan clustering dengan menghitung nilai SSE masing-masing cluster untuk di perbandingkan. Hasil percobaan tersebut dapat di lihat pada Gambar 3.
Pada metode elbow nilai cluster yang akan diambil adalah nilai yang mengalami penurunan secara signifikan dan membentuk sudut. Berdasarkan grafik pada Gambar 3 dapat di lihat bahwa nilai cluster k = 7 adalah titik yang memenuhi kriteria metode elbow (siku). Hal inilah yang mendasarkan penelitian ini untuk melakukan clustering data dengan nilai k = 7.
Hasil dari clustering data log keseluruhan dapat dilihat pada Tabel 1. Tabel 14. Distribusi frekuensi keseluruhan Cluster Pengguna Centroid (Bps)
Upstream Downstream C1 4464 16663.296371 505682.603495 C2 998 182877.502004 192219.895792 C3 193 604280.694301 418974.119171 C4 11887 9528.202742 244704.490115 C5 1118 31611.640429 956626.836315 C6 244099 1078.290181 10784.756369 C7 40024 5725.634419 87290.163427 Total 302783
Berdasarkan dari tabel 1 dapat di lihat bahwa pengguna SSO kebanyakan termasuk ke dalam cluster 6, dimana berturut-turut centroid upstream dan downstream adalah ≥210 Bps; ≥216 Bps (1 byte = 8 bits) atau sekitar 1 KBps untuk upstream dan 64 KBps untuk downstream. Hasil dari clustering data log keseluruhan berdasarkan bulan dapat dilihat pada Tabel 2.
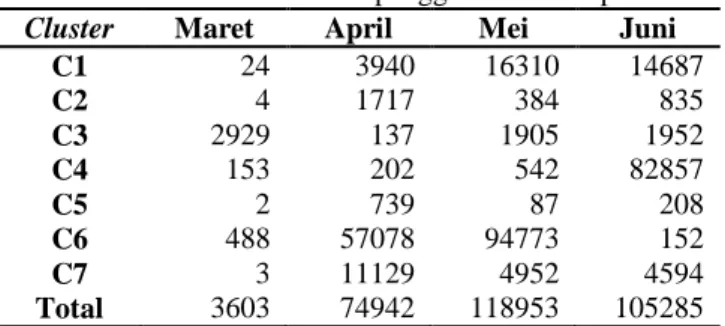
Tabel 15. Distribusi frekuensi pengguna internet per bulan
Berdasarkan dari Tabel 2 dapat di lihat bahwa pengguna SSO kebanyakan melakukan akses di bulan Mei, yaitu bulan aktif akademik menjelang liburan semester ganjil. Sedangkan nilai centroid pada cluster yang memiliki nilai tertinggi untuk tiap bulannya dijelaskan pada Tabel 3.
Tabel 16. Centroidcluster terbesar pada tiap bulan
Bulan Cluster Centroid (Bps) Pengguna
Upstream Downstream
Maret C3 1697.988051 21773.080232 2929
April C6 1086.897544 9423.329234 57078
Mei C6 1030.224051 10590.371889 94773
Juni C4 1024.069505 9027.113726 82857
Berdasarkan dari Tabel 3 dapat di lihat bahwa pengguna SSO kebanyakan mendapatkan fasilitas akses internet melalui jaringan kampus dengan rata-rata kecepatan bandwidth upload dan download berturut-turut, ≥210 Bps; ≥213 Bps (1 byte = 8 bits) atau sekitar 1 KBps untuk upstream dan 8 KBps untuk downstream.
Cluster Maret April Mei Juni
C1 24 3940 16310 14687 C2 4 1717 384 835 C3 2929 137 1905 1952 C4 153 202 542 82857 C5 2 739 87 208 C6 488 57078 94773 152 C7 3 11129 4952 4594 Total 3603 74942 118953 105285
239
Hasil dari clustering data log, jika di petakan berdasarkan tempat lokasi akses jaringan adalah sebagai berikut.
Tabel 17. Distribusi frekuensi pengguna internet per lokasi akses
C1 C2 C3 C4 C5 C6 C7 Total A 33 1 876 152 8569 75 17 9723 B 233 617 23 2608 20863 37 87 24468 C 35 1545 172 6577 74 597 301 9301 D 47 446 42 2959 179 16696 1058 21427 E 8737 84 406 259 1641 17 33 11177 F 127 756 21 63 231 14 12 1224 G 1076 3513 412 110 25820 84 12 31027 H 12075 2690 17 33 957 177 472 16421 I 647 199 3679 379 1520 70 13504 19998 J 540 113 1320 52744 8943 2994 209 66863 K 55 9 1593 425 52 10 141 2285 L 228 848 93 11 3189 8 40 4417 M 606 40 7652 2005 85 22 216 10626 N 22 171 8 1904 28 414 55 2602 O 1782 52 7592 130 382 231 794 10963 P 23 19 80 311 1362 6 30 1831 Q 83 1748 8 22 186 642 366 3055 R 133 1988 260 593 457 7155 975 11561 S 359 1353 29324 4569 4 101 11 35721 T 5143 7 119 46 392 16 1038 6761 U 834 14 7 274 113 24 65 1331
Berdasarkan dari tabel 4 dapat di lihat berturut-turut, tempat yang paling banyak dan paling sedikit di gunakan pengguna SSO untuk mengakses internet adalah lokasi J dan F. Sedangkan nilai centroid pada cluster yang memiliki nilai tertinggi untuk tiap lokasi di jelaskan pada Tabel 5.
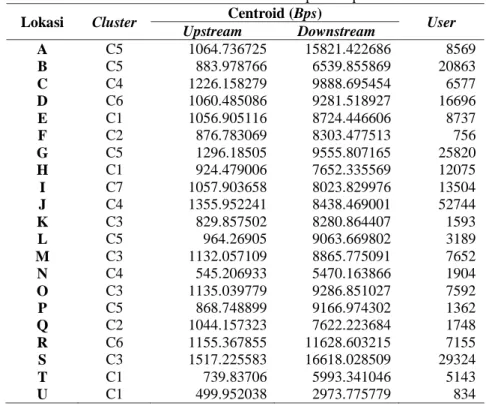
Tabel 18. Centroid cluster terbesar pada tiap lokasi
Lokasi Cluster Centroid (Bps) User
Upstream Downstream A C5 1064.736725 15821.422686 8569 B C5 883.978766 6539.855869 20863 C C4 1226.158279 9888.695454 6577 D C6 1060.485086 9281.518927 16696 E C1 1056.905116 8724.446606 8737 F C2 876.783069 8303.477513 756 G C5 1296.18505 9555.807165 25820 H C1 924.479006 7652.335569 12075 I C7 1057.903658 8023.829976 13504 J C4 1355.952241 8438.469001 52744 K C3 829.857502 8280.864407 1593 L C5 964.26905 9063.669802 3189 M C3 1132.057109 8865.775091 7652 N C4 545.206933 5470.163866 1904 O C3 1135.039779 9286.851027 7592 P C5 868.748899 9166.974302 1362 Q C2 1044.157323 7622.223684 1748 R C6 1155.367855 11628.603215 7155 S C3 1517.225583 16618.028509 29324 T C1 739.83706 5993.341046 5143 U C1 499.952038 2973.775779 834
Berdasarkan dari Tabel 5 dapat di lihat bahwa pengguna SSO kebanyakan mendapatkan fasilitas akses internet melalui jaringan kampus dengan rata-rata kecepatan bandwidth upload dan download di tiap
tempatnya berturut-turut, ≥29Bps sampai dengan ≥210Bps; ≥211Bps sampai dengan ≥214Bps (1 byte = 8 bits) atau sekitar 512 Bps – 2 KBps untuk upstream dan 2 – 16 KBps untuk downstream.
4. SIMPULAN
Himpunan data log bandwidth pada kasus ini dapat di cluster menggunakan algoritma K-means dengan jumlah cluster 7. Pemilihan nilai cluster k=7, sudah melalui beberapa percobaan. Hasil clustering data penggunaan bandwidth dapat di lihat bahwa bulan padat pengguna SSO adalah bulan Mei dengan kecepatan download dan upload yang masih kalah dengan bulan Maret atau bulan dengan pengguna SSO terendah, sedangkan lokasi yang paling banyak dan paling sedikit di gunakan pengguna SSO untuk mengakses internet adalah di lokasi J dan F mempunyai rata-rata kecepatan yang tidak jauh berbeda untuk downstream.
5. REFERENSI
[1] Haryanto, D. 2014. Single Sign On Server System. Bandung: NET-COMLABS ITB.
[2] Berkhin, P. 2002. Survey of Clustering Data Mining Techniques. San Jose, CA: Accrue Software. [3] MacQueen, J. 1967. Some Method for Classification and Analysis of Multivariate Observations.
dalam Proc. of the fifth Berkeley Symposium on Mathematical Statistics and Probability. [4] Putri, A. U. 2014. Peramalan Kebutuhan Bandwidth Menggunakan Jaringan Saraf Tiruan
Backpropagation Dengan Input Berdasarkan Best Subset Regression. Surakarta: Universitas Sebelas Maret.
[5] Wang, T. 2012. The Development of Web Log Mining Based on Improved K-means Clustering Analysis. Springer: Verlag Berlin Heidelberg.
[6] Gan, G., Ma, C., dan Wu, J. 2007. Data Clustering Theory, Algorithms and Applications, Alexandria Virginia: Society for Industrial and Applied Mathematics.
[5] Berry, M. dan Linoff, G. 2000. Mastering Data Mining. New York: John Wiley & Sons.
[6] Sarwono, Y. 2010. Aplikasi Model Jaringan Syaraf Tiruan dengan Radial Basis Function untuk Mendeteksi Kelainan Otak (Stroke Infark). Sekolah Tinggi Manajemen Informatika & Teknik Komputer, Surabaya.