PENENTUAN LOKASI TERBAIK DAN JUMLAH OPTIMUM
DATA ARUS LALULINTAS DALAM PROSES ESTIMASI MATRIKS
ASAL-TUJUAN (MAT) DARI INFORMASI DATA ARUS LALULINTAS
1Ofyar Z. TAMIN2, Titi L. SOEDIRDJO3, dan Rudi S. SUYONO4
Jurusan Teknik Sipil ITB, Jalan Ganesha 10, Bandung 40132, Indonesia E-mail: [email protected]
Abstract
To estimate an Origin-Destination (OD) matrix based on traffic counts, traffic count is the major input which obviously affects the accuracy of the estimated matrix. Therefore, any process regarding the traffic count such as the amount and their locations have to be carefully studies to obtain the optimal results. Theoretically, the more data we have, the better will be the estimated OD matrices. However, this is costly and requires long process; therefore, the objective is to obtain the best location and the optimum amount of traffic counts. The model considered 3 (three) major factors i.e. (a) proportion factor of the intrazonal trips for each link, (b) independence and inconsistency conditions, and (c) link condition. Moreover, the optimum amount of traffic count data in obtained based on efficiency consideration. The model has been tested in Bandung consisting of 145 zones and 2485 links (arterial, collector, and local roads). The first stage have been able to select 969 links out of 2485 links (1516 links unselected) and 646 links of them has been reselected in the second stage (another 323 unselected). The best link obtained in the second stage is reevaluated again using link condition criteria and finally obtain the best location of traffic count. The study has also found that the optimum number of traffic count data is about 90 links (around 3,6% of total links).
1. PENDAHULUAN 1.1 Latar Belakang
Dalam perencanaan dan pemodelan transportasi sangat diperlukan tersedianya informasi pola pergerakan manusia dan/atau barang yang biasanya diwakili dengan Origin-Destination Matrix (OD Matrix) atau Matriks Asal-Tujuan (MAT). Metode estimasi MAT yang selama ini digunakan pada umumnya membutuhkan waktu pengumpulan data yang lama serta biaya yang cukup besar sehingga pada akhirnya semakin membuat kompleks permasalahan yang terjadi. Metode estimasi MAT berdasarkan data arus lalulintas yang termasuk kelompok Metode Tidak Konvensional (MTK) merupakan suatu metode estimasi yang cukup efektif dan ekonomis namun memiliki tingkat kehandalan yang tinggi karena data utama yang dibutuhkannya adalah berupa informasi data arus lalulintas yang
1 diterbitkan dalam Jurnal Masyarakat Transportasi Indonesia (MTI), Desember 2000, Hal 1−23.
2 Staf Pengajar, Jurusan Teknik Sipil ITB, Wakil Ketua Program Magister Transportasi ITB, dan Ketua Forum
Studi Transportasi antar Perguruan Tinggi (FSTPT).
3 Staf Pengajar dan Ketua Laboratorium Rekayasa Lalulintas, Jurusan Teknik Sipil ITB. 4
umumnya untuk memperolehnya membutuhkan biaya yang cukup murah, banyak tersedia dan mudah didapat.
Untuk itulah dapat dipahami bahwa metode estimasi MAT dengan menggunakan data arus lalulintas menjadi sangat menguntungkan untuk dipakai. MTK ini terasa sekali sangat diperlukan untuk negara sedang berkembang, terutama bagi kota yang membutuhkan pemecahan masalah transportasi yang bersifat cepat tanggap. Ini diperkuat dengan keterbatasan yang biasanya ada di negara sedang berkembang, yaitu dalam hal sumber daya manusia, waktu dan biaya yang kurang memadai. Hal ini pada akhirnya menghasil kualitas data survei yang rendah terutama bila menggunakan metode estimasi MAT secara konvensional. Oleh sebab itu, sangat diperlukan MTK yang hanya memerlukan data yang dapat diperoleh dengan biaya yang murah dan dalam waktu yang cukup singkat.
1.2 Dasar Analisis
Data arus lalulintas merupakan masukan utama yang digunakan untuk estimasi MAT dengan menggunakan MTK. Untuk itu, setiap proses yang berkaitan dengan data arus lalulintas terutama yang berhubungan dengan pengumpulan data, banyaknya data yang akan dipergunakan serta dimana saja lokasi pengumpulan data tersebut harus dipertimbangkan dengan baik agar hasil yang diperoleh dapat optimal. Proses pengumpulan data merupakan hal utama dan pertama kali dilakukan dari seluruh tahapan analisis estimasi MAT dengan metode ini. Kesalahan dan ketidakefisienan dari proses ini akan berakibat pada keseluruhan proses analisis dan pada akhirnya akan menyebabkan MAT yang dihasilkan memiliki tingkat akurasi yang rendah serta mengakibatkan model ini menjadi kurang handal. Berdasarkan hal tersebut, maka terdapat dasar analisis yang digunakan pada penelitian ini.
1.2.1 Lokasi terbaik
a. Proporsi pergerakan antarzona pada suatu ruas jalan
Besarnya arus lalulintas yang terjadi pada suatu ruas jalan pada dasarnya merupakan total dari seluruh pergerakan yang terjadi dari suatu zona asal i ke zona tujuan d yang menggunakan ruas jalan tersebut sebagai bagian dari rute terbaiknya. Dengan demikian pada arus lalulintas yang terjadi pada suatu ruas jalan terdapat informasi pergerakan antar zona yang diwakili oleh besarnya proporsi pergerakan dari suatu zona asal ke zona tujuan yang menggunakan ruas jalan tersebut. Kondisi ini dinyatakan sebagai:
∑∑
=
i d l id id lT
p
V
.
(1) Berdasarkan hal tersebut, menurut (Tamin, 2000) salah satu tahap terpenting dari proses estimasi MAT dari data arus lalulintas adalah identifikasi rute yang dilalui oleh setiap pergerakan dari setiap zona asal i ke setiap zona tujuan d. Dalam kasus ini, peubah plid
digunakan untuk mendefenisikan proporsi pergerakan dari zona asal i ke zona tujuan d yang bergerak melalui ruas jalan l. Jadi dengan kata lain, arus pada setiap ruas jaringan jalan adalah produk dari:
• pergerakan dari zona asal i ke zona tujuan d atau kombinasi berbagai jenis pergerakan yang bergerak antar zona di dalam suatu daerah kajian (Tid);
• proporsi pergerakan dari zona asal i ke zona tujuan d yang menggunakan ruas jalan l yang didefenisikan sebagai pl
id (0≤plid≤1).
Dalam penentuan lokasi traffic count, lokasi ruas jalan yang memiliki banyak informasi pergerakan antarzona yang dalam hal ini dapat dilihat dari besar dan jumlah nilai pl
id yang
terdapat pada ruas jalan tersebut akan cukup baik untuk digunakan sebagai kriteria penentuan lokasi traffic count.
b. Kondisi hubungan antarruas jalan
• Saling ketergantungan (independence) antarruas Pergerakan arus lalulintas pada suatu ruas jalan tertentu pada dasarnya merupakan akumulasi atau penjumlahan
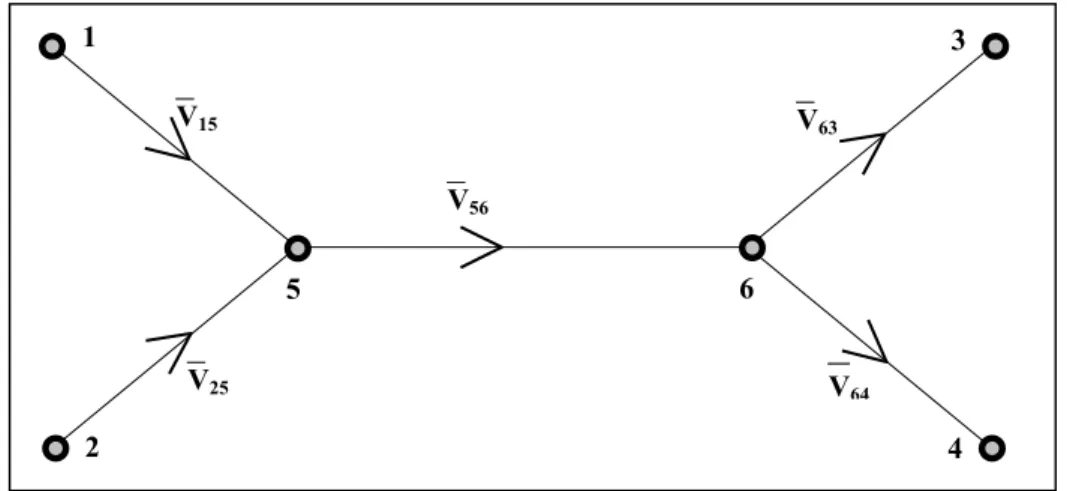
dari arus lalulintas dari ruas-ruas jalan lain yang kemudian memasuki ruas jalan tersebut. Gambar 1 memperlihatkan bahwa arus lalulintas pada ruas 5–6 adalah penjumlahan arus pada ruas 1–5 dan 2–5, sehingga dalam hal ini tidak ada gunanya menghitung arus pada ruas 5–6 karena berdasarkan prinsip kontinuitas,V56=V15
+V25.
Gambar 1: Jaringan Jalan Sederhana (Sumber: Tamin, 1988)
Berdasarkan prinsip kontinuitas tersebut pada dasarnya hanya dibutuhkan data arus lalulintas pada 3 (tiga) ruas jalan saja untuk mendapatkan arus pada semua jalan pada Gambar 1. Karena itu, dari sisi ekonomi dan prinsip pergerakan yang terjadi, perlu diperhatikan cara memilih ruas jalan yang cocok untuk mendapatkan data arus lalulintasnya (Tamin, 2000).
• Kondisi ketidakkonsistenan (inconsistency) arus lalulintas
Kondisi yang berupa permasalahan ketidakkonsistenan dalam perhitungan arus lalulintas timbul jika kondisi kontinuitas arus lalulintas tidak dipenuhi oleh data hasil pengamatan. Dalam hal kasus pada gambar 1 di atas, kondisi ketidakkonsistenan arus lalulintas dari pengamatan tidak memenuhi prinsip kontinuitas dan bisa bisa menghasilkan persamaan berikut:
V56≠V15 +V25 (2) atau V15 +V25≠V63 +V64 (3) 1 2 5 6 3 4 V15 V25 V56 V63
V64Permasalahan ketidakkonsistenan ini biasanya bisa timbul karena galat manusia pada saat pengumpulan data arus lalulintas atau mungkin juga karena perhitungan yang dilakukan pada saat yang tidak bersamaan. Akibatnya, tidak ada solusi MAT yang menghasilkan kembali arus lalulintas yang tidak konsisten. Salah satu cara untuk menghindari masalah ini adalah dengan memilih ruas-ruas jalan yang saling tidak berkaitan untuk dihitung arus lalulintasnya (Tamin, 2000).
1.2.2 Jumlah data arus lalulintas optimum
Persamaan (1) merupakan persamaan dasar yang dikembangkan pada model estimasi MAT berdasarkan informasi data arus lalulintas. Pada model ini peubah pl
id dapat diestimasi
dengan menggunakan model pembebanan rute. Dengan mengetahui nilai pl
id dan satu set
data arus lalulintas (
Vˆ
l ), didapatkan N2 buah Tid yang harus diestimasi dari L persamaan
linier simultan (persamaan 1) dengan jumlah data arus lalulintas. Secara prinsip, N2 data
arus lalulintas dibutuhkan untuk dapat menaksir matriks [Tid]; [N2−N] jika perjalanan
intrazona diabaikan. Secara praktis, jumlah data arus lalulintas yang diperoleh jauh lebih sedikit dari jumlah Tid yang ditaksir sehingga tidak mungkin diperoleh solusi (Tamin, 1988).
Untuk mengatasi hal ini (Tamin, 1988) telah mengembangkan suatu solusi dengan cara memodelkan perilaku pemakai jalan dengan suatu model kebutuhan pergerakan tertentu seperti model Gravity (GR) atau model Gravity-Opportunity (GO). Dalam hal ini, hipotesa yang digunakan adalah bahwa semakin banyak jumlah set data arus lalulintas yang diperoleh dan digunakan dalam proses penaksiran MAT, akan semakin baik dan semakin meningkatkan akurasi MAT yang diperoleh, namun demikian hal ini tentu saja membutuhkan sumberdaya yang cukup besar dan mahal serta memerlukan waktu yang tidak sedikit dan belum tentu efisien. Melalui penelitian ini akan diketahui seberapa besar pengaruh jumlah data arus lalulintas yang digunakan terhadap tingkat akurasi MAT serta berapa jumlah optimum data arus lalulintas tersebut.
2. METODE TIDAK KONVENSIONAL (MTK) 2.1 Metode Estimasi
Tujuan model ini adalah secara efektif menyatukan ke dalam suatu proses semua hal yang biasa dilakukan dalam model perencanaan transportasi empat tahap, lengkap dengan galatnya masing-masing. Ada beberapa alasan utama mengapa data arus lalulintas sangat menarik digunakan sebagai data utama dalam proses penaksiran MAT yaitu (Tamin, 2000): a. Murah, Jenis data seperti ini murah karena hanya membutuhkan tenaga kerja yang
sedikit serta dapat menggunakan penghitung lalulintas otomatis.
b. Ketersediaan, Arus lalulintas biasanya sudah tersedia karena sering digunakan untuk kajian transportasi perkotaan atau antar kota.
c. Tidak mengganggu, Data arus lalulintas bisa didapat tanpa mengganggu arus lalulintas sehingga kemacetan ataupun tundaan serta gangguan lalulintas lain dan bagi pengguna jalan bisa dihindari.
Dengan MTK ini, perilaku pemakai jalan dianggap dapat diwakili dengan suatu model kebutuhan transportasi tertentu seperti model Gravity (GR) atau model Gravity-Opportunity
(GO). Arus lalulintas dinyatakan sebagai fungsi MAT yang dinyatakan sebagai fungsi suatu model kebutuhan transportasi dengan parameternya. Tamin (2000) mengungkapkan bahwa Nguyen (1982) telah mengulas secara rinci kemuktahiran (state of the art) penelitian yang berkaitan dengan mengestimasi MAT dengan mengunakan data arus lalulintas. Jika terdapat sejumlah pergerakan antarzona dalam suatu daerah kajian dan diasumsikan bahwa pergerakan antarzona dalam daerah tersebut dapat diwakili oleh suatu model kebutuhan transportasi, maka total pergerakan Tid dengan zona asal i dan zona tujuan
d tadi dapat dinyatakan sebagai:
id d i d i id
O
D
A
B
f
T
=
.
.
.
.
dimana: (4) Aidan Bd = faktor penyeimbang yang dapat dinyatakan dengan:∑
=
d id d d if
D
B
A
)
.
.
(
1
dan∑
=
i i i id df
O
A
B
)
.
.
(
1
(5)fidk = fungsi biaya (fungsi eksponensial negatif exp(−β.Cidk))
Dengan mensubtitusikan persamaan (4) pada persamaan dasar (1), maka persamaan dasar untuk model estimasi kebutuhan transportasi dari data arus lalulintas ini dapat dinyatakan:
∑∑
=
i d l id id d i d i lO
D
A
B
f
p
V
.
.
.
.
.(
)
(6) Persamaan dasar ini sangat penting dan sering digunakan dalam banyak pustaka baik untuk mengestimasi MAT maupun mengkalibrasi model kebutuhan transportasi dari data arus lalulintas; contohnya (Tamin, 1988).2.2 Metode Kalibrasi
Dalam proses estimasi MAT dengan data arus lalulintas proses pengkalibrasian model merupakan unsur kunci pemecahan masalah. Model ini bertujuan untuk mengkalibrasi model dari data arus lalulintas yaitu untuk memperoleh besaran parameter yang akan digunakan untuk mengestimasi MAT. Dalam hal ini jumlah ruas jalan yang dibutuhkan sekurang-kurangnya sama dengan jumlah parameter model yang tidak diketahui.
Secara praktis, sangatlah kecil kemungkinan mendapatkan informasi data arus lalulintas yang bebas dari kesalahan. Hampir selalu terdapat kesalahan pada data arus lalulintas, definisi sistem jaringan atau sistem zona, atau mungkin pada teknik pembebanan rute yang digunakan untuk menjelaskan rute yang dipilih pengendara. Oleh karena itu, dibutuhkan tambahan jumlah ruas jalan untuk menanggulangi jenis kesalahan seperti ini.
Tamin (1988) mengembangkan dua kelompok utama metode estimasi yang dapat digunakan untuk mengkalibrasi parameter model transportasi yang diusulkan dari data arus lalulintas, yaitu metode estimasi Kuadrat-Terkecil (KT) dan metode estimasi Kemungkinan-Maksimum (KM). Ide utama dibalik kedua metode estimasi itu adalah mencoba
mengkalibrasi parameter yang tidak diketahui, yang meminimumkan perbedaan antara arus lalulintas hasil pemodelan dan hasil pengamatan. Hal ini bisa didapat dengan menggunakan ukuran kemiripan antara arus lalulintas hasil pemodelan dan hasil pengamatan, misalnya formula kuadrat-terkecil atau kemungkinan-maksimum (Tamin, 2000).
3. METODOLOGI STUDI
3.1 Analisis Penentuan Lokasi Traffic Count Terbaik
Analisis yang dilakukan untuk penentuan lokasi traffic count terbaik ini dilakukan dalam 2 (dua) tahap seleksi. Setiap tahap analisis tersebut akan menentukan lokasi traffic count
terbaik berdasarkan kriteria yang digunakan. Seluruh proses analisis yang dilakukan dilakukan menggunakan model estimasi MTK yaitu model Gravity-Opportunity (GO). Tiga tahap seleksi lokasi traffic count yaitu:
a. Seleksi tahap I: berdasarkan parameter proporsi pergerakan pada ruas jalan (nilai pidl)
Parameter utama yang digunakan pada seleksi tahap I adalah nilai proporsi pergerakan pada setiap ruas jalan yang ada pada wilayah studi. Nilai proporsi pergerakan (pidl) pada suatu
ruas jalan pada dasarnya adalah besarnya perbandingan jumlah arus lalulintas yang bergerak dari suatu zona asal ke suatu zona tujuan yang menggunakan suatu ruas jalan sebagai ruas terbaiknya terhadap seluruh jumlah arus lalulintas yang bergerak antara kedua zona tersebut. Dengan demikian nilai pidl, yang nilainya berkisar antara 0−1,
menggambarkan besar kecilnya arus lalulintas yang bergerak dari satu zona ke zona lainnya yang menggunakan ruas tertentu. Semakin besar nilai pidl menggambarkan semakin besar
pula jumlah arus lalulintas yang bergerak dari zona asal i ke zona tujuan d yang menggunakan ruas jalan l.
Pergerakan arus lalulintas pada suatu ruas jalan pada dasarnya merupakan penjumlahan seluruh arus yang bergerak dari suatu zona asal i ke zona tujuan d. Sesuai persamaan 1
maka pada setiap ruas jalan mengandung nilai pidl yang mungkin cukup bervariasi serta
sangat tergantung pada aksesibilitas ruas tersebut antara suatu zona asal dan zona tujuan yang ada. Banyaknya nilai jumlah pidl pada suatu ruas ditentukan oleh banyaknya zona asal
dan zona tujuan yang ada pada suatu daerah studi. Jadi bila terdapat N jumlah zona, maka pada tiap ruas akan terdapat sejumlah NxN nilai pidl.
Pada seleksi tahap I ini dilakukan seleksi lokasi traffic count dengan menggunakan parameter pidl ini sebagai parameter yang dapat mengambarkan pergerakan yang terjadi
pada suatu ruas jalan. Selanjutnya untuk memperoleh hubungan antara besarnya proporsi pergerakan (pidl) dan jumlah pergerakan antarzona yang terjadi digunakan parameter Weighted Mean sebagai berikut:
∑
∑
=
id id id l id idT
N
p
T
k
.
.
.
ˆ
2µ
(7) dimana:µ
ˆ
= weighted mean k = jumlah nilai pidl>0N = jumlah zona pada wilayah studi
Pada tahap ini ruas-ruas jalan yang memiliki nilai weighted mean (
µ
ˆ
) = 0 atau yang memiliki nilai pidl=0 dengan jumlah 100% dari seluruh total pidl akan terseleksi dan tidaklolos dari seleksi tahap ini. Sedangkan untuk ruas-ruas yang berhasil lolos akan ditentukan peringkatnya berdasarkan nilai weighted mean tersebut. Peringkat ini selanjutnya akan digunakan pada seleksi tahap selanjutnya.
b. Seleksi tahap II: berdasarkan parameter hubungan antarruas
Pada seleksi tahap II ini akan dilakukan seleksi ruas jalan berdasarkan hubungan antarruas tersebut sedemikian rupa sehingga ruas yang terpilih sebagai ruas terbaik akan memenuhi persayaratan teknis serta eknomis. Pada seleksi tahap II ini proses seleksi dilakukan dengan mempertimbangkan kondisi ketergantungan (independence) dan faktor ketidakkonsistenan
(inconsistency). Seleksi tahap II ini dilakukan baik terhadap lokasi yang lolos dari seleksi tahap I.
Berdasarkan prinsip ketergantungan (independence) jumlah pergerakan dari suatu ruas tertentu pada dasarnya merupakan penjumlahan dari ruas-ruas yang arah pergerakannya masuk ke ruas tersebut atau dikenal sebagai prinsip kontinuitas dimana V1=V2+V3. Prinsip ini
diambil dengan asumsi bahwa tidak ada arus lalulintas yang hilang ditengah-tengah ruas. Sedangkan berdasarkan prinsip yang digunakan terhadap kemungkinan terjadinya ketidakkonsistenan (inconsistency) pada data arus lalulintas adalah dengan menghindari terjadinya pengambilan data pada lokasi yang saling berdekatan atau saling berhubungan sedemikian rupa sehingga memungkinkan dapat diminimalisasi terjadinya masalah ketidakkonsistenan dalam data arus yang diperoleh.
Seleksi yang dilakukan pada ruas-ruas jalan yang saling berhubungan berusaha untuk mengakomodasi kedua hal tersebut disamping menghindari terjadinya ketidakefisienan sehingga dalam mengeliminasi ruas-ruas yang saling berhubungan pada satu sisi dapat diperoleh informasi arus lalulintas secara optimal, namun disisi lain diusahakan untuk dapat meminimalisasi kemungkinan terjadinya kondisi inconsistency pada arus lalulintas hasil pengamatan.
c. Seleksi tahap III: berdasarkan kondisi ruas lokasi traffic count
Tahap ini merupakan proses penentuan peringkat lokasi traffic count dengan memperhatikan berbagai kriteria yang terkait dengan kondisi ruas jalan yang ada. Beberapa parameter yang berpengaruh akan dipertimbangkan dalam menentukan peringkat lokasi, yaitu:
a. Kriteria peringkat ruas berdasarkan hasil seleksi I dan II (parameter pidl dan hubungan antarruas) Ruas-ruas yang terpilih dari hasil seleksi tahap I dan II sebagai lokasi traffic count terbaik. Kriteria ini dipergunakan karena ruas-ruas yang memiliki nilai proporsi pergerakan (nilai pidl) yang kemudian dibobotkan dengan
pergerakan antarzona yang cukup banyak dan cukup banyak pula dilalui pergerakan, selanjutnya berdasarkan analisis hubungan antarruas maka arus lalulintas yang terjadi pada ruas-ruas tersebut apabila dilakukan survei traffic count akan memenuhi persyaratan kontinuitas (hubungan saling ketergantungan) dan terhindar dari kemungkinan terjadinya inkonsistensi pada arus lalulintas tersebut. Pada analisis ini proses pembobotan pada kriteria ini dilakukan berdasarkan persentase urutan peringkat terbaik dari semua ruas yang lolos seleksi tahap I dan II.
b. Kriteria kondisi kemacetan (degree of saturation/DS) Pada suatu ruas jalan yang sering terjadi kemacetan maka arus lalulintas yang terjadi pada dasarnya merupakan interuppted traffic dimana apabila memungkinkan pelaku perjalanan akan menghindari ruas jalan tersebut sebagai bagian dari rute perjalanan dengan demikian pada ruas-ruas jalan seperti ini walaupun arus lalulintas yang terjadi cukup banyak namun tidak akan efektif bila dilakukan survei pengumpulan data arus lalulintas pada lokasi tersebut. Untuk itu ruas-ruas jalan seperti ini sedapat mungkin untuk dihindari sebagai lokasi traffic count. Pada kriteria ini pembobotan dilakukan berdasarkan besarnya nilai DS yang terjadi pada ruas jalan tersebut.
c. Kriteria kondisi gangguan samping pada ruas jalan Suatu ruas jalan yang banyak mengalami gangguan samping seperti banyaknya jalan akses di sekitar ruas jalan tersebut kurang baik untuk digunakan sebagai lokasi survei karena memungkinkan banyaknya kendaraan yang keluar masuk pada jalan akses tersebut yang akan mempersulit proses pengumpulan data dan pada akhirnya memperkecil tingkat akurasi data-data yang dikumpulkan. Untuk itu sedapat mungkin ruas yang terpilih sebagai lokasi traffic count memiliki hambatan samping yang tidak besar. Proses pembobotan pada kriteria ini dilakukan berdasarkan kelas hambatan samping yang terjadi pada ruas jalan tersebut berdasarkan ketentuan dari (IHCM, 1997).
Analisis penentuan peringkat lokasi traffic count pada tahap ini merupakan upaya untuk mengurangi berbagai pengaruh dari kondisi ruas yang dapat mengakibatkan proses survei traffic count pada lokasi terpilih menjadi tidak effisien terutama terhadap akurasi, konsistensi, dan kehandalan dari data yang dihasilkan. Analisis yang dilakukan adalah berupa analisis multi-kriteria sederhana. Pada proses pertama untuk melakukan analisa ini dilakukan proses pembobotan kriteria (Quantification of Criteria) dari setiap kriteria sebagai berikut:
Tabel 1: Quantification of criteria pada analisis penentuan peringkat lokasi traffic count
Kriteria I Kriteria II Kriteria III
No
Urutan peringkat Qc DS Qc Kelas SF Qc
1 0% - 10% terbaik 1 0.0 – 0.1 1 VL 1 2 10% - 20% terbaik 2 0.1 – 0.2 2 L 2 3 20% - 30% terbaik 3 0.2 – 0.3 3 M 3 4 30% - 40% terbaik 4 0.3 – 0.4 4 H 4 5 40% - 50% terbaik 5 0.4 – 0.5 5 VH 5 6 50% - 60% terbaik 6 0.5 – 0.6 6 - - 7 60% - 70% terbaik 7 0.6 – 0.7 7 - - 8 70% - 80% terbaik 8 0.7 – 0.8 8 - - 9 80% - 90% terbaik 9 0.8 – 0.9 9 - - 10 90% - 100% terbaik 10 0.9 – 0.10 10 - - Keterangan :
1. Kriteria 1 : Berdasarkan hasil seleksi tahap I dan II (proposi pergerakan dan hubungan antar ruas) 2. Kriteria II : Derajat kejenuhan (Degree of Saturation/DS)
3. Kriteria III : Hambatan samping (Side Friction)
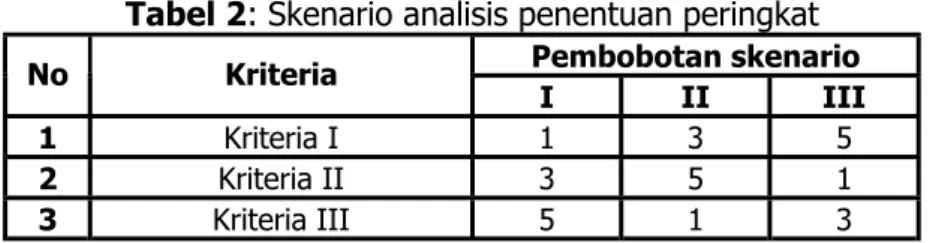
Kemudian pada analisis penentuan peringkat lokasi traffic count terbaik akan dilakukan beberapa skenario. Hal ini dilakukan sedemikian sehingga dapat diperoleh hasil yang optimal berdasarkan tingkat sensitifitas dari setiap kriteria yang ada. Adapun skenario yang dilakukan adalah dengan memberikan bobot yang berbeda pada setiap kriteria.
Tabel 2: Skenario analisis penentuan peringkat
Pembobotan skenario No Kriteria I II III 1 Kriteria I 1 3 5 2 Kriteria II 3 5 1 3 Kriteria III 5 1 3
Selanjutnya peringkat ruas ditentukan berdasarkan nilai Wc yang terkecil sebagai ruas dengan peringkat tertinggi sampai pada ruas yang memiliki nilai Wc terbesar sebagai ruas dengan peringkat terendah.
3.2 Studi Penentuan Jumlah Data Arus Lalulintas Optimum
Untuk memperoleh jumlah data arus lalulintas optimum, maka harus diperoleh hubungan kuantitatif antara jumlah data arus lalulintas yang digunakan dalam proses estimasi MAT dengan tingkat akurasi MAT yang dihasilkan. Proses ini dapat dilakukan dengan 2 (dua) buah metode untuk mengetahui sensitivitas jumlah data ruas lalulintas dan peringkat lokasi traffic count terhadap akurasi MAT.
a. Metode I (secara urutan/sorted)
Pada metode ini dipilih kombinasi jumlah data arus lalulintas yang digunakan dalam estimasi MAT (MAT model) yang diperoleh dari proses pembebanan suatu MAT pembanding. Pemilihan kombinasi pada metode I ini dilakukan berdasarkan urutan lokasi traffic count
terbaik hasil seleksi tahap II. Kombinasi jumlah data tersebut dipilih bervariasi dari 2 buah data, 4 buah data dan seterusnya sampai dengan penggunaan seluruh data yang ada. Dengan membandingkan kesesuaian antara MAT model dan MAT pembanding (MAT 100%) menggunakan uji statistik, maka akan diketahui perilaku perubahan tingkat akurasi MAT terhadap jumlah data arus lalulintas serta selanjutnya dapat ditentukan suatu jumlah data optimum.
b. Metode II (secara acak/random)
Metode ini hampir serupa dengan metode I diatas, hanya saja pada metode ini lokasi yang digunakan diambil secara acak. Jadi lokasi mana saja yang termasuk lokasi terbaik berpeluang untuk digunakan sebagai data arus lalulintas baik. Sebagaimana halnya pada metode sebelumnya, pada metode ini akan diperoleh suatu jumlah data arus lalulintas optimum. Hasil dari kedua metode ini kemudian dibandingkan dan kembali diuji tingkat keakurasian MAT-nya sedemikian rupa sehingga jumlah data arus lalulintas optimum dapat diperoleh.
4. DAERAH KAJIAN
Batas wilayah studi yang digunakan adalah seluruh wilayah Kotamadya Bandung dan Kabupaten Bandung yang berada disekitar perbatasan Kotamadya. Hal ini didasarkan pertimbangan bahwa Kabupaten Bandung memiliki interaksi kegiatan ekonomi yang cukup tinggi dengan Kotamadya Bandung. Sistem pembagian zona di Kotamadya Bandung dibagi berdasarkan kelurahan dengan jumlah kelurahan 139 buah, sedangkan kabupaten Bandung pembagian zona berdasarkan kecamatan dengan jumlah kecamatan 41 buah. Berdasarkan data tersebut pembagian zona yang dilakukan pada wilayah studi terdiri dari 100 zona di Kotamadya Bandung, 39 zona di Kabupaten Bandung dan untuk mengantisipasi pergerakan yang berasal dari luar wilayah studi dibuat zona tersendiri yaitu zona eksternal yang terdiri dari kecamatan yang berada diluar wilayah studi sebanyak 6 buah zona. Sistem jaringan yang digunakan pada studi ini terdiri dari semua hirarki jalan yaitu arteri, kolektor dan sebagian jalan lokal sehingga terdapat sebanyak 2485 ruas jalan yang dianalisis pada penelitian ini.
5. HASIL ANALISIS
5.1 Penentuan Lokasi Traffic Count Terbaik
a. Seleksi tahap I: berdasarkan parameter proporsi pergerakan pada ruas jalan
Sebagaimana telah diungkapkan bahwa pada seleksi tahap I parameter yang digunakan adalah nilai pidl yang dapat diketahui dengan menggunakan teknik pembebanan rute. Dalam
penelitian ini akan digunakan teknik equilibrium. Dalam wilayah studi ini terdapat sebanyak 145 zona bangkitan dan tarikan pergerakan dan 2485 ruas; dengan demikian terdapat nilai pidl sebanyak (145x145)=21025 buah untuk setiap ruas jalan sehingga total terdapat
sebanyak 2485x21025 buah nilai pidl. Selanjutnya, untuk setiap ruas jalan tersebut akan
Weighted Mean (
µ
ˆ
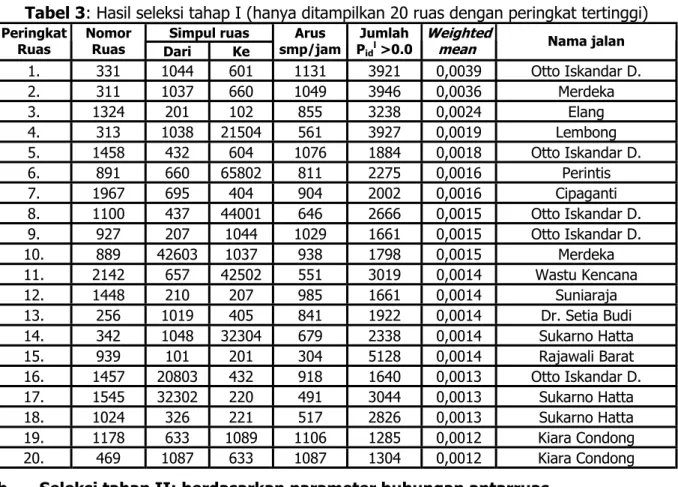
) = 0 atau seluruh nilai pidl-nya adalah nol akan terseleksi secaraotomatis. Dari hasil analisis tahap I ini berhasil lolos sebanyak 969 ruas jalan dari 2485 ruas yang ada (1516 ruas gugur). Ruas-ruas yang lolos tahap I ini selanjutnya akan dianalisis pada tahap berikutnya yaitu seleksi berdasarkan hubungan antarruas. Sebagian hasil seleksi tahap I (hanya 10 ruas jalan dengan peringkat tertinggi) dapat dilihat pada tabel 3.
Tabel 3: Hasil seleksi tahap I (hanya ditampilkan 20 ruas dengan peringkat tertinggi) Simpul ruas
Peringkat
Ruas Nomor Ruas Dari Ke
Arus
smp/jam PJumlah idl >0.0
Weighted
mean Nama jalan 1. 331 1044 601 1131 3921 0,0039 Otto Iskandar D. 2. 311 1037 660 1049 3946 0,0036 Merdeka 3. 1324 201 102 855 3238 0,0024 Elang 4. 313 1038 21504 561 3927 0,0019 Lembong 5. 1458 432 604 1076 1884 0,0018 Otto Iskandar D. 6. 891 660 65802 811 2275 0,0016 Perintis 7. 1967 695 404 904 2002 0,0016 Cipaganti 8. 1100 437 44001 646 2666 0,0015 Otto Iskandar D. 9. 927 207 1044 1029 1661 0,0015 Otto Iskandar D. 10. 889 42603 1037 938 1798 0,0015 Merdeka 11. 2142 657 42502 551 3019 0,0014 Wastu Kencana 12. 1448 210 207 985 1661 0,0014 Suniaraja 13. 256 1019 405 841 1922 0,0014 Dr. Setia Budi 14. 342 1048 32304 679 2338 0,0014 Sukarno Hatta 15. 939 101 201 304 5128 0,0014 Rajawali Barat 16. 1457 20803 432 918 1640 0,0013 Otto Iskandar D. 17. 1545 32302 220 491 3044 0,0013 Sukarno Hatta 18. 1024 326 221 517 2826 0,0013 Sukarno Hatta 19. 1178 633 1089 1106 1285 0,0012 Kiara Condong 20. 469 1087 633 1087 1304 0,0012 Kiara Condong b. Seleksi tahap II: berdasarkan parameter hubungan antarruas
Pada seleksi tahap II ini dilakukan seleksi ruas jalan berdasarkan parameter hubungan antarruas sehingga ruas yang terpilih sebagai ruas terbaik akan memenuhi persyaratan teknis serta ekonomis (efisiensi). Pada seleksi ini, seleksi dilakukan dengan mempertimbangkan faktor ketergantungan (independence) dan faktor ketidak-konsistenan (inconsistency). Ruas-ruas yang lolos dari seleksi tahap I akan dilihat hubungan terhadap ruas-ruas lainnya yang sama-sama lolos dari seleksi tahap I. Selanjutnya dilakukan proses seleksi sehingga permasalahan yang berkaitan dengan masalah hubungan antarruas dapat diminimalisasi. Proses ini dapat dilakukan secara manual (dengan bantuan peta jaringan
jalan) ataupun menggunakan algoritma dan program komputer. Untuk analisis tahap II ini, seleksi lokasi traffic count ini dilakukan terhadap 969 ruas jalan telah berhasil lolos dari seleksi tahap I.
Berdasarkan hasil analisis hubungan antarruas, maka untuk seleksi tahap II ini berhasil terpilih sebanyak 646 ruas jalan dari 969 buah ruas jalan (323 ruas gugur). Sebagian ruas jalan yang berhasil lolos seleksi tahap II dapat dilihat pada tabel 4 (hanya 20 ruas dengan peringkat tertinggi yang ditampilkan).
Tabel 4: Hasil Seleksi Tahap II (Hanya Ditampilkan 20 Ruas Dengan Peringkat Tertinggi)
Simpul ruas No. Nomor ruas
Dari Ke Namajalan
Peringkat
hasil seleksi tahap II smp/jam Arus
1 331 1044 601 Otto Iskandar D. 1 1131 2 311 1037 660 Merdeka 2 1049 3 1324 201 102 Elang 3 855 4 313 1038 21504 Lembong 4 561 5 1458 432 604 Otto Iskandar D. 5 1076 6 891 660 65802 Perintis 6 811 7 1967 695 404 Cipaganti 7 904 8 1100 437 44001 Otto Iskandar D. 8 646 9 927 207 1044 Otto Iskandar D. 9 1029 10 889 42603 1037 Merdeka 10 938 11 2142 657 42502 Wastu Kencana 11 551 12 1448 210 207 Suniaraja 12 985 13 256 1019 405 Dr. Setia Budi 13 841 14 342 1048 32304 Sukarno Hatta 14 679 15 939 101 201 Rajawali Barat 15 304 16 1457 20803 432 Otto Iskandar D. 16 918 17 1545 32302 220 Sukarno Hatta 17 491 18 1024 326 221 Sukarno Hatta 18 517 19 1178 633 1089 Kiara Condong 19 1106 20 469 1087 633 Kiara Condong 20 1087
c. Seleksi tahap III
Tahap III ini merupakan proses akhir penentuan peringkat lokasi traffic count dengan memperhatikan beberapa kriteria yang terkait dengan kondisi ruas jalan ada seperti yang terlah dijelaskan sebelumnya. Berdasarkan hasil analisis yang dilakukan untuk peringkat lokasi traffic count terbaik pada tahap III ini, maka 10 ruas dengan peringkat ruas tertinggi dapat dilihat pada tabel 5.
Tabel 5: Hasil Analisis Tahap III (hanya ditampilkan 20 Ruas Dengan Peringkat Tertinggi)
Simpul ruas Seleksi tahap III
No. No.
ruas Dari Ke Nama jalan
Arus smp/ja
m
Peringkat
tahap I Peringkat Tahap II Total
Wc Peringkat tahap III
1 2142 657 42502 Wastu Kencana 551 11 11 36 1 2 939 101 201 Rajawali Barat 304 15 15 36 2 3 2146 65801 42403 Wastu Kencana 292 51 50 36 3 4 2138 42401 657 Wastu Kencana 276 62 60 36 4 5 313 1038 21504 Lembong 561 4 4 45 5 6 891 660 65802 Perintis 811 6 6 45 6 7 233 1304 302 Cimindi 260 37 37 45 7 8 309 1036 42601 Merdeka 406 49 48 45 8 9 1959 403 402 Sukajadi 638 50 49 45 9 10 268 1023 409 Ir. H. Juanda 629 52 51 45 10 11 2088 681 7251 Taman Sari 463 60 58 45 11 12 2473 93502 936 Sumatera 314 65 63 45 12 13 1349 21602 104 Veteran 360 94 85 45 13 14 2077 42501 417 Wastu Kencana 351 104 92 45 14 15 2430 69201 69303 Cipaganti 349 111 98 45 15 16 1500 21501 93503 Sumatera 241 139 121 45 16 17 311 1037 660 Merdeka 1049 2 2 54 17 18 1324 201 102 Elang 855 3 3 54 18 19 1967 695 404 Cipaganti 904 7 7 54 19 20 889 42603 1037 Merdeka 938 10 10 54 20
Terlihat pada tabel 5, hasil peringkat pada tahap II kembali dievaluasi kembali berdasarkan kondisi ruas jalan. Misalnya, ruas 2142 berada pada peringkat 11 menjadi ruas peringkat 1 setelah evaluasi tahap III. Sama halnya dengan ruas 2146, peringkat 50 pada tahap II menjadi peringkat 2 pada tahap III. Hal ini membuktikan faktor kondisi ruas jalan sangat menentukan dalam proses pemilihan peringkat meskipun dari kriteria tahap I dan II sudah menjamin mendapat peringkat tinggi.
5.2 Penentuan Jumlah Optimum Data Arus Lalulintas
Sebagaimana yang telah dijelaskan sebelumnya bahwa analisis penentuan jumlah data arus lalulintas optimum ini dilakukan dengan menggunakan 2 (dua) pendekatan yaitu pendekatan terurut berdasarkan hasil peringkat urutan lokasi terbaik (sorted) dan pendekatan acak dari lokasi tersebut (random). Kedua metode ini dilakukan untuk mengetahui pengaruh dan sensitivitas peringkat ruas yang telah ditentukan terhadap keakurasian MAT yang dibentuk.
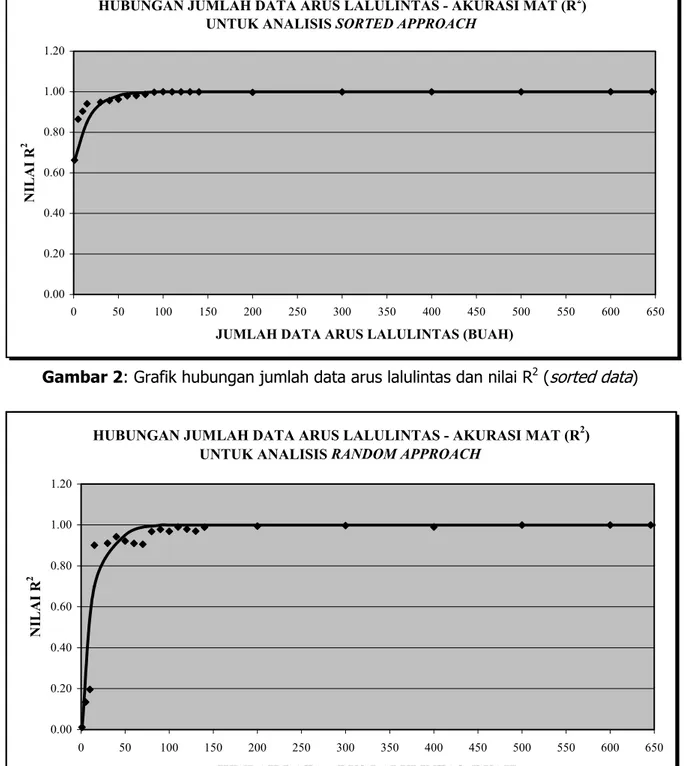
Dalam penelitian ini, pembentukan MAT model berdasarkan data arus lalulintas menggunakan model Gravity-Opportunity (GO). Anindito (2000) menyatakan parameter model GO terbaik untuk Kotamadya Bandung adalah ε=0,4 dan µ=1,0. Nilai parameter ini yang selanjutnya digunakan pada pembentukan MAT. Untuk analisis ini, model harus dikalibrasi untuk mengetahui parameter model GO yang tidak diketahui (α dan β). Proses kalibrasi ini dilakukan dengan menggunakan metode Kuadrat-Terkecil-Tidak-Linier-Berbobot (KTTLB). Jumlah data arus lalulintas optimum yang dihasilkan dengan menggunakan metode terurut (sorted) dan metode acak (random) dapat dilihat pada gambar 2−3.
Berdasarkan hasil analisis yang telah dilakukan terlihat bahwa untuk penggunaan data arus lalulintas sebanyak 90 buah data baik pada analisis terurut (sorted) maupun acak (random) ini memberikan tingkat akurasi yang tinggi yang hampir sama dengan penggunaan 100% data atau sejumlah 646 buah data. Dengan demikian dapat dikatakan bahwa jumlah 90 buah data merupakan jumlah data optimum. Hasil lain yang dapat dilihat adalah bahwa pengambilan data arus lalulintas untuk analisis yang dilakukan secara acak memberikan hasil yang kurang baik dibandingkan secara terurut. Selain itu pengambilan data secara terurut berdasarkan peringkat ruas jalan yang ada memungkinkan dapat diperoleh tingkat akurasi MAT yang cukup baik dibandingkan bila dilakukan secara acak.
5.3 Pengujian Hasil Analisis
Dari studi yang telah dilakukan, telah diperoleh lokasi traffic count terbaik serta dapat diketahui jumlah data arus lalulintas optimum dalam proses estimasi MAT berdasarkan informasi data arus lalulintas untuk wilayah kota Bandung. Untuk memperoleh validasi dari hasil analisis ini, maka perlu dilakukan suatu pengujian untuk melihat apakah hasil analisis yang telah dilakukan ini sesuai dengan tujuan studi ini. Pengujian ini dilakukan dengan cara melakukan estimasi MAT berdasarkan data arus lalulintas dari lokasi-lokasi yang ‘telah gugur’ dalam seleksi yang telah dilakukan.
HUBUNGAN JUMLAH DATA ARUS LALULINTAS - AKURASI MAT (R2) UNTUK ANALISIS SORTED APPROACH
0.00 0.20 0.40 0.60 0.80 1.00 1.20 0 50 100 150 200 250 300 350 400 450 500 550 600 650
JUMLAH DATA ARUS LALULINTAS (BUAH)
NILAI R
2
Gambar 2: Grafik hubungan jumlah data arus lalulintas dan nilai R2 (sorted data)
HUBUNGAN JUMLAH DATA ARUS LALULINTAS - AKURASI MAT (R2)
UNTUK ANALISIS RANDOM APPROACH
0.00 0.20 0.40 0.60 0.80 1.00 1.20 0 50 100 150 200 250 300 350 400 450 500 550 600 650
JUMLAH DATA ARUS LALULINTAS (BUAH)
NILAI R
2
Gambar 3: Grafik hubungan jumlah data arus lalulintas dan nilai R2 (random data)
Jumlah data arus lalulintas yang digunakan adalah 90 buah (jumlah data arus lalulintas optimum). Dari hasil analisis pengujian ini akan dapat diketahui berapa besar pengaruh seleksi dan analisis yang dilakukan karena jika ternyata hasil pada proses pengujian ini sama
dengan hasil analisis yang telah dilakukan maka berarti proses seleksi dan analisis yang dilakukan tersebut mengandung kesalahan atau bahkan tidak perlu dilakukan.
5.3.1 Proses pengujian
Proses pengujian dilakukan dengan mengestimasi MAT berdasarkan data arus lalulintas dari lokasi yang telah gugur seleksi. Untuk analisis ini digunakan model Gravity Opportunity dan banyaknya jumlah data yang digunakan adalah sebanyak 90 buah data (jumlah data optimum). Pada tiap model analisis dibentuk 20 kelompok kombinasi data arus lalulintas dengan jumlah data untuk setiap kelompok adalah sejumlah 90 buah data, yang selanjutnya dari tiap kelompok kombinasi dibentuk sebuah MAT. MAT tersebut kemudian dibandingkan dengan MAT pembanding (MAT 100%) yang juga merupakan MAT pembanding dalam analisis sebelumnya.
5.3.2 Hasil analisis pengujian
Dari hasil analisis untuk pengujian yang telah dilakukan terlihat bahwa MAT yang dihasilkan dari data arus lalulintas yang diperoleh dari lokasi yang telah gugur seleksi memiliki tingkat akurasi yang cukup rendah yang tampak dari nilai R2 yang diperoleh yaitu hanya berkisar
antara 0,30–0,60; padahal pada analisis dengan data dari lokasi yang lolos seleksi diperoleh nilai R2≈ 1,00.
Hasil analisis tersebut menunjukkan bahwa penggunaan lokasi traffic count yang ‘tidak lolos seleksi’ memberikan hasil MAT dengan tingkat akurasi yang cukup rendah. Kondisi ini terjadi karena pada dasarnya pada lokasi tersebut tidak banyak terdapat informasi pergerakan antarzona yang diwujudkan dari kecilnya nilai proporsi pergerakan pada ruas (nilai pidl), sehingga pada akhirnya MAT yang dibentuk berdasarkan data arus lalulintas yang
diperoleh dari lokasi-lokasi ini memiliki tingkat akurasi yang sangat rendah.
Berdasarkan hasil pengujian ini maka terlihat bahwa tahapan seleksi dan analisis yang telah dilakukan pada studi ini yaitu untuk menentukan lokasi traffic count terbaik berserta jumlah
data arus lalulintas optimumnya terbukti cukup baik dan signifikan di dalam meningkatkan akurasi MAT. Adapun hasil dari analisis pengujian ini dapat dilihat pada gambar 4.
GRAFIK HASIL PENGUJIAN
UNTUK MODEL GRAVITY OPPORTUNITY
0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 1.00 0 2 4 6 8 10 12 14 16 18 20
Kelompok Kombinasi Data Arus Lalulintas (Tiap Kelompok Berisi 90 Data Arus Lalulintas)
R
2
Gambar 4: Grafik hasil pengujian untuk parameter R2
6. KESIMPULAN
Penelitian ini bertujuan untuk menentukan lokasi terbaik dan jumlah optimum data arus lalulintas yang dapat menghasilkan MAT berakurasi tinggi. Model seleksi lokasi dilakukan dengan mempertimbangkan 3 (tiga) faktor utama: (a) faktor proporsi pergerakan lalulintas antarzona yang menggunakan setiap ruas jalan, (b) faktor hubungan antarruas seperti kondisi saling ketergantungan (independence) dan kondisi ketidakkonsistenan (inconsistency) dari arus lalulintas, dan (c) kondisi ruas jalannya. Selanjutnya, penentuan jumlah data optimum didasarkan pada pertimbangan efisiensi yaitu penggunaan jumlah data seminimal mungkin namun masih menghasilkan MAT berakurasi tinggi. Studi dilakukan dalam wilayah studi Kotamadya Bandung yang meliputi 145 zona pergerakan serta mempertimbangkan 2485 ruas jalan sebagai lokasi data arus lalulintas yang terdiri dari jalan arteri, kolektor, dan lokal.
Hasil tahap I berhasil menyaring 969 ruas dari 2485 ruas jalan yang ada (1516 gugur pada tahap I), dan selanjutnya 646 ruas tersaring pada tahap II (323 ruas kembali gugur). Peringkat ruas terbaik pada tahap II dievalusi kembali dengan kriteria kondisi ruas jalan sehingga menghasilkan peringkat ruas terbaik (646 ruas). Penelitian menghasilkan bahwa jumlah data arus lalulintas optimum yang dibutuhkan adalah sebanyak 90 buah (sekitar 3,6% dari seluruh ruas jalan yang ada).
Penggunaan data arus lalulintas secara terurut dari peringkat loaksi terbaik menghasilkan MAT dengan tingkat akurasi yang jauh lebih baik dibandingkan secara acak. Selain itu proses estimasi MAT dengan menggunakan data arus lalulintas dari lokasi – lokasi yang telah gugur seleksi (tidak memenuhi persyaratan) akan menghasilkan MAT yang memiliki tingkat akurasi yang rendah dibandindingkan dengan analisis MAT dengan menggunakan data dari lokasi terbaik terpilih.
7. UCAPAN TERIMA KASIH
Penulis mengucapkan banyak terima kasih kepada University Research for Graduate Education (URGE) Project, Direktorat Jenderal Pendidikan Tinggi, Departemen Pendidikan Nasional yang telah memberikan bantuan dana untuk penelitian ‘Graduate Team Research Grant, Batch IV, 1998/1999’ dengan judul Dynamic Origin-Destination (O-D) Matrices Estimation From Real Time Traffic Count Information dengan kontrak No. 029/HTTP-IV/URGE/1999.
8. DAFTAR PUSTAKA
1. Anindito, W. Pengaruh Tundaan Di Persimpangan dan Model Pemilihan Rute Terhadap Akurasi Matriks Asal-Tujuan Yang Diperoleh Dari Informasi Data Arus Lalulintas, Thesis S2, Sistem dan Teknik Jalan Raya, ITB, 2000.
2. Patunrangi, J. Pengaruh Resolusi Sistem Zona dan Sistem Jaringan Terhadap Akurasi Matriks Asal-Tujuan (MAT) Yang Diperoleh Dari Informasi Arus Lalulintas, Thesis S2, Rekayasa Transportasi, ITB, 2000.
3. Tamin, O.Z. Estimation of Transport Demand model From Traffic Count, PhD Dissertation, University College London, University of London, 1988.
4. Tamin, O.Z. Perencanaan dan Pemodelan Transportasi, Edisi 2, Penerbit ITB, Bandung, 2000.
5. Willumsen, L.G. Simplified Transport Model Based on Traffic Counts, Transportation 10, Elsevier Scientific Publishing Company, Amsterdam, page 257−278, 1981.