Analisis Sentimen berdasarkan Aspek Pada
Review Restoran Menggunakan Bayesian
Networks Untuk
Dokumen Berbahasa Inggris
Dimas Adhi Prasidya
#1, Mohamad Syahrul Mubarok
*2,
Adiwijaya
#3#Prodi S1 Teknik Informatika, Fakultas Informatika, Universitas Telkom Jl. Telekomunikasi no. 1 Ters. Buah Batu Bandung 40257 Indonesia 1 [email protected],2[email protected],3
Abstract
Sentiment analysis allows its users to find out how other people's opinion about a product or an existing business. Consumers typically give their opinion after using the products or services that were offered. Whether a product is being liked or not, the seller can take strategic steps. The author applies the concept of text mining in the field of sentiment analysis to conduct this study. There are several stages taken. The first stage is the data preprocessing stage, at this stage the process consists of normalization, tokenization, filtering / stop word removal, and lemmatization. The second stage is the stage of learning classifier, which is a construction of a graph structure used for the classification process. There are nine types of graph, each consists of a three nodes which are, word, polarity, and aspect. After a graph is completed, the complexity value of its corresponding graph is calculated using Bayesian Formula Dirichlet Uniform Equivalence the best graph. The third stage is classification, at this stage whether the document is classified sentiments tend to positive, negative, or neutral conflict and its aspects whether food, ambience, miscellaneous, price or service. The fourth stage is the stage of the system evaluation, which calculates precision, recall, and F1-measure are being calculated. Based on the evaluation of the system for the nine graph, best performance the author obtained are graf to 5.8 and 9 with details f1-measure value of 81.25%. However, based on the calculated score graph structure with BDeu graph 5 has the best value. So the graph 5 is the best of 9 graph that has been processed.
Keywords: Sentiment Analysis, Bayesian Networks, Text Preprocessing, BDeu. Abstrak
Analisis Sentimenmemungkinkan penggunanya untuk mengetahui bagaimana pendapat orang lain mengenai produk atau bisnis yang ada. Konsumen biasanya memberikan pendapat mereka setelah menggunakan produk ataupun jasa yang ditawarkan. Dengan mengetahui apakah produknya disukai atau tidak, penjual dapat mengambil langkah strategis. Penulis menerapkan konsep text mining pada bidang analisis sentimendalam penelitian ini. Ada beberapa tahapan yang dilalui. Pertama adalah tahap preprocessing data, pada tahap ini dilakukan proses normalisasi, tokenization,filtering/stop word removal, dan lemmatization. Tahap kedua adalah tahap learning classifier, yaitu membangun struktur graf yang dipakai pada proses klasifikasi. Graf yang dibuat ada Sembilan jenis yang masing – masingnya terdiri dari tiga node, yaitu word, polarity, dan aspect. Setelah graf selesai dibuat, graf tersebut akan dihitung nilai kompleksitasnya dengan menggunakan rumus BDeu (Bayesian Dirchlet EquivalenceUniform) untuk menentukan graf yang terbaik. Tahap ketiga adalah tahap klasifikasi,
pada tahap ini dokumen diklasifikasikan sentimennya apakah cenderung ke positif, negatif, konflik atau netral dan aspeknya apakah food,ambience, miscellaneous, price atau service. Tahap keempat
ISSN 2460-3295
socj.telkomuniversity.ac.id/indosc
Ind. Symposium on Computing Sept 2016. pp. 307-318 doi:10.21108/indosc.2016.162
adalah tahap evaluasi sistem, pada tahap ini dilakukan perhitungan precision, recall, dan f1-measure. Berdasarkan hasil evaluasi sistem, dari sembilan graf hasil performansi terbaik yang didapat adalah graf ke 5, 8 dan 9 dengan rincian nilai f1-measure 81.25 %. Namun berdasarkan skor struktur graf yang dihitung dengan BDeu (Bayesian Dirchlet EquivalenceUniform) graf 5 memiliki nilai terbaik. Sehingga graf 5 merupakan graf terbaik dari 9 graf yang telah diproses.
Kata Kunci: Analisis Sentimen, Bayesian Networks, Text Preprocessing, BDeu.
I. PENDAHULUAN
atural Languange Processing (NLP) adalah bidang penelitian yang mengeksplorasi bagaimana mesin dapat mengolah bahasa alami baik itu berupa text atau suara [1]. Dasar dari NLP terdiri dari beberapa disiplin ilmu, yaitu, komputer, informasi dan teknologi, matematika, electrical and electronic engineering, artificial intelligence dan robotika. Pengaplikasian NLP mencakup sejumlah bidang, yaitu machine translation, text processing and summarization, crong language information retrieval (CLIR), speech recognition, artificial intelligence, expert systems dan sentiment analysis
[1].
Seiring berjalannya waktu di zaman sekarang ini, sudah mulai banyak website yang menawarkan jasa ataupun barang atau yang kita kenal dengan toko online, Tapi kita sebagai konsumen terkadang ingin lebih dahulu mengetahui kualitas pelayanan dari penawar jasa atau barang yang bersangkutan. Kita bisa juga berkontribusi untuk memberikan penilaian kita terhadap pelayanan tersebut dengan cara menulis ulasan (review). Review ini tidak hanya dibutuhkan oleh pembeli, tapi juga penjual. Penjual dapat melihat bagaimana respon dari pembeli mengenai produknya. Tentunya dengan respon yang baik, membuka peluang untuk memproduksi lebih banyak dan meningkatkan keuntungan perusahaan. Begitu juga sebaliknya, jika didapatkan respon negatif maka perlu diadakan perbaikan. Tetapi terkadang, penjual barang tidak memiliki waktu yang cukup untuk menganalisa review – review tersebut dan tentunya jumlahnya tidak sedikit. Untuk itulah diperlukan sebuah sistem yang dapat mengolah data review tersebut dengan menerapkan sentiment analysis. Hal itu dapat mengatasi permasalahan tersebut dengan lebih cepat dan mudah.
Untuk menangani permasalahan tersebut dibutuhkan sebuah proses yang bernama analisis sentiment. Analisis Sentimen adalah sebuah proses analisa pendapat sesorang, sentimennya, perilaku dan emosinya terhadap suatu objek seperti produk, jasa, organisasi, individu, topik dan attributnya [2]. Sentiment analysis dapat digunakan untuk mengkategorikan pendapat berdasarkan sentimennya. Untuk mendapatkan hasil yang lebih akurat, maka objek dari pendapat tersebut perlu diperhatikan. Hal itu dapat dicapai dengan memperhatikan aspek dari objek pendapat tersebut. Aspek yang diperhatikan pada proses klasifikasi pendapat tersebut adalah, food, ambience, miscellaneous, price dan service. Sedangkan sentimen yang diperhatikan adalah positif, negatif, konflik dan netral.
Tahapan yang harus dilalui untuk melakukan analisis sentiment yang pertama adalah preprocessing. Preprocessing terdiri dari empat tahap yaitu case folding, tokenization, stop word removal dan lemmatization. Tahap lemmatization menggunakan
library yang bernama Standford NLP Core untuk bahasa pemrograman Java. Tahap kedua adalah pembangunan classifier, proses pertama yang dilakukan pada tahap pembangunan classifier adalah pembuatan struktur graf Bayesian Networks. Setelah proses pembuatan graf selesai, proses selanjutnya adalah pembuatan Conditional Probability Table(CPT), Conditional Probability Table dibuat sejumlah graf yang dibentuk. Tahap ketiga adalah proses Klasifikasi, classifier yang digunakan pada penelitian ini adalah Bayesian Networks. Bayesian Networks adalah salah satu metode pemodelan data kedalam bentuk DAG (Directed Acrylic Graph), yaitu graf yang menggambarkan hubungan probabilisitik antar variabel yang saling berkaitan [3][25].Metode tersebut dipilih karena pada proses sentiment analysis, objek dan kata sifat pada kalimat saling berkaitan dan dapat mempengaruhi satu sama lain. Bayesian Networks adalah sebuah model graf yang menggambarkan hubungan probabilisitik antar variable yang saling berkaitan. Bayesian Networks tergolong ke dalam
probabilistic grafical model (PGM) dan merupakan jenis graf berarah [4]. Tiap node pada graf merepresentasikan variabel
random, sedangkan edge diantara node merepresentasikan nilai probabilitas antar variabel yang saling terhubung dengan
edge tersebut. Bayesian Networks memiliki beberapa keunggulan [3], yaitu, yang pertama, model menggambarkan keterhubungan antar semua variable, jadi model sudah siap jika ada beberapa data yang hilang., yang kedua Bayesian Networks bisa digunakan untuk mendapatkan pengetahuan tentang masalah yang terjadi dan memprediksi konsekuensi jika
N
dilakukan interferensi, yang ketiga Bayesian Networks dikombinasikan dengan Bayesian statistical akan menghasilkan hasil yang efisien untuk menghindari data overfitting, dan yang terakhir dengan menggunakan pendekatan Bayesian, model bisa dirubah sedemikian rupa sehingga semua data bisa dipakai sebagai data training.
II.LITERATURE REVIEW
Bayesian Networks menggambarkan hubungan conditional independence dalam distribusi probabilitas. Hubungan tersebut penting untuk dipahami agar dapat bisa mengerti cara kerja dari Bayesian Networks. Ada 3 jenis dari conditional independence yaitu [3].
1. Causal Chains
Causal Chains adalah dimana saat ada 3 node yang saling terhubung, A menyebabkan B terjadi, dan B menyebabkan C terjadi. Misalnya kita ambil kasus kanker paru – paru. Merokok (A) menyebabkan kanker paru – paru (B), dan kanker paru – paru (B) menyebabkan kematian (C). Contoh graf causal chain dapat dilihat pada Gambar 1.
2. Common Cause
Common cause adalah jika ada 1 node yang mempengaruhi 2 node lain. Misalnya kita ambil kasus pada sakit flu. Flu (A) menyebabkan kita menjadi pusing (B) dan lemas (C). Contoh graf common cause dapat dilihat pada Gambar 2.
3. Common Effect
Common effect adalah jika ada 2 node yang mempengaruhi 1 node lain secara bersamaan. Misalnya kit ambil kasus pada sakit perut. Memakan – makanan kadaluarsa (A) dan tidak mencuci tangan sebelum makan (C), keduanya dapat menyebabkan sakit perut (C). Contoh graf common effect dapat dilihat pada Gambar 3.
4. Direct dependency
Direct dependency adalah jika ada 1 node yang mempengaruhi 1 node lainnya. Contoh, Jundi sakit perut (A) karena memakan permen (B). Contoh graf common effect dapat dilihat pada Gambar 4.
Selanjutnya diperlukan sebuah proses untuk menghitung nilai struktur dari graf yang dibuat. Dari nilai struktur yang didapatkan tersebut, ditentukan graf terbaik. Proses ini disebut structure learning.Skor terbaik yang dimaksud adalah skor yang paling mendekati angka satu. Metode yang dapat digunakan untuk proses ini adalah BDeu (Bayesian Dirichlet equivalent uniform) [5]. Adapun persamaanya dapat dilihat pada persamaan 4 dibawah ini.
Gambar 1 Causal Chains
Gambar 2 Common Cause
Gambar 3 Common Effect
Gambar 4 Common Effect
𝐵𝐷𝑒𝑢(𝑁 ∶ 𝐷, 𝛼) = ∑ { ∑ log Γ (𝛼 𝑞𝑖 ) − log Γ (𝛼 𝑞𝑖 + 𝑛𝑖𝑗) 𝑞𝑖 𝑗 + ∑ log Γ ( 𝛼 𝑟𝑖. 𝑞𝑖 + 𝑛𝑖𝑗𝑘) − log Γ ( 𝛼 𝑟𝑖. 𝑞𝑖 ) 𝑟𝑖 𝑘 } 𝑛 𝑖 Keterangan:
𝛼 : Nilai sampel yang ekivalen
𝑞𝑖 : Jumlah variable parent
𝑟𝑖 : Jumlah variable child
𝑛𝑖𝑗 : Jumlah variabel pada node ke i dan variabel parent ke j
𝑛𝑖𝑗𝑘 : Jumlah variabel pada node ke i variabel parent ke j dan variabel child ke k. N : Network
D : Dokumen
III. RESEARCH METHOD
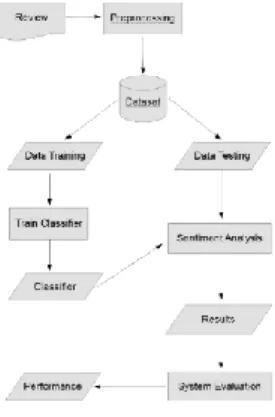
Gambaran sistem secara umum yang dibangun dapat dilihat pada Gambar 1 berikut.
Gambar 5 Gambaran Umum Sistem
A. Dataset
Penelitian dilakukan dengan dataset dari SemEval 2014, Task 4 Aspect-based Sentiment Analysis yang berisi data berupa teks review dari restoran. Bentuk dataset berupa Extensible Markup Language (xml) contohnya dapat dilihat pada gambar 2.
Gambar 6 Contoh Dataset Review Produk
Pada SemEval 2014 Task 4 tentang Aspect-based Sentiment Analysis terdapat dua dataset, yaitu, training set yang terdiri dari 3618 data review dan testing set yang terdiri dari 96 data review. Keduanya terbagi kedalam 4 kelas sentimen yaitu positive, negative, neutral, conflict, dan 5 kelas aspek yaitu, food, ambience, miscellaneous, service,
dan price.
B. Preprocessing Data
Preprocessing merupakan tahapan awal dalam mengolah data untuk membuat data lebih mudah atau cocok untuk digunakan dalam proses mining [6]. Adapun tahapannya adalah sebagai berikut:.
<sentence id="2321">
<text>It's a nice place to relax and have conversation.</text> <aspectTerms><aspectTerm term="place"
polarity="positive" from="12" to="17"/> </aspectTerms>
<aspectCategories><aspectCategory category="ambience" polarity="positive"/>
</aspectCategories> </sentence>
1. Normalization
Karena data yang digunakan berekstensi XML, maka tag XML’nya akan dihilangkan terlebih dahulu. Setelah proses tersebut selesai akan dilakukan case folding, yaitu merubah semua huruf menjadi huruf kecil.
2. Tokenization
Pada tahap ini, teks pada dokumen akan dipisahkan menjadi potongan – potongan kata. 3. Stop Word Removal
Pada tahap ini, kata – kata akan diseleksi untuk dipakai atau tidak. Kata yang tidak dipakai akan dihapus dengan menggunakan stoplist. Stoplist berisi stopwords, yaitu kata – kata yang tidak dipakai pada representasi bag-of-words.
4. Stemming atau lemmatization
Pada tahap ini, kata – kata yang telah terpisah, dirubah dengan menghilangkan imbuhan yang ada pada kata tersebut. Metode yang digunakan untuk proses ini adalah dengan menggunakan Algoritma Porter untuk stemming
[7], sedangkan untuk lemmatization menggunakan library yang bernama NLPCore yang dapat diunduh pada situs
Stanford University. C. Building Classifier
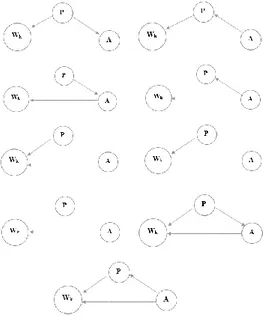
Tahap ini dilakukan dengan cara pembuatan struktur graf terlebih dahulu. Graf dibuat berdasarkan konsultasi dengan pembimbing dan berdasarkan hasil pertimbangan terhadap conditional dependency pada tiap node’nya. Node W adalah kata(word), node P adalah sentiment(polarity), sedangkan node A adalah aspek(aspect).
Daftar Graf yang dibuat:
D. Proses klasifikasi
Proses klasifikasi dilakukan dengan melalui proses inferensi Bayesian networks yang menggunakan formula
bayes rule yang disesuaikan dengan masing – masing struktur graf yang ada.
Gambar 7 Visualisasi Struktur graf yang digunakan
Gambar 8 Proses Klasifikasi Naive Bayes
Dalam penelitian ini, karena proses klasifikasi dilakukan untuk dua domain yaitu aspek dan sentimen, maka probabilitas sebuah dokumen untuk berada pada suatu aspek dan sentimen tertentu.
IV. EVALUASISISTEM
A. Dataset
Dataset yang dipakai dalam penelitian ini berasal dari SemEval 2014 Task 4 yang berisi tentang review konsumen terhadap sebuah restoran. Dataset yang tersedia ada dua buah, yaitu:
1.Training set
Data training terdiri dari 3618 review yang terbagi kedalam 5 kelas aspek , yaitu food, service, price, ambience, dan miscellaneous serta 4 jenis sentiment (polarity) yaitu positive, negative, neutral, dan conflict. Detail rincian distribusi lengkap dari dataset dapat dilihat pada tabel 1. Berikut
Tabel 1 Rincian Training Set
2. Testing Set
Testing set terdiri dari 96 review dengan kondisi aspek dan sentiment sama dengan training set. Detail rincian distribusi lengkap dari dataset dapat dilihat pada tabel 2 berikut
Tabel 2 Testing Set
B. Pengujian
Hasil keluaran yang diteliti dari tahap pengujian ini adalah, skor F1-Measure dari setiap graf. Adapun tujuan dari proses pengujian pada penelitian ini adalah sebagai berikut:
1. Menganalisis pengaruh tahap preprocessing, yaitu apakah hasil dari proses stemming atau lemmatization yang memiliki hasil lebih baik.
Review Positive Negative Neutral Conflict Total
Food 846 201 89 66 1202
Price 175 113 10 16 314
Service 319 217 19 34 589
Ambience 216 97 23 46 427
Miscellaneous 515 193 349 29 1086
Revi ew Pos i ti ve Nega ti ve Neutra l Confl i ct Tota l
Food 21 8 1 1 31
Pri ce 2 1 1 1 5
Servi ce 5 1 1 1 8
Ambi ence 2 1 1 1 5
2. Menganalisis pengaruh struktur graf pada Bayesian Network yang digunakan untuk proses klasifikasi dan perhitungan likelihood.
C. Analisis Hasil Pengujian
1. Analisis pengaruh preprocessing, yaitu stemming dan lemmatization terhadap performansi sistem.
Pengujian dilakukan dengan membandingkan jumlah fitur yang diekstraksi dengan menggunakan masing –
masing proses serta hasil evaluasi akhir dari sistem. Berikut
adalah hasil perbandingan dari kedua metode diatas. 1. Ekstraksi Fitur
Pada proses ini, kata – kata yang telah terpisah, dirubah dengan menghilangkan imbuhan yang ada pada kata tersebut. Lalu dibuat sebuah kamus yang berisi daftar kata apa saja yang ada pada seluruh data.
2. Nilai Struktur Graf
Nilai Struktur graf dihitung menggunakan BDeu score, tujuannya untuk menentukan graf mana yang baik dan cocok digunakan untuk kasus seperti ini. Nilai yang paling baik adalah nilai yang mendekati 0. Dari hasil
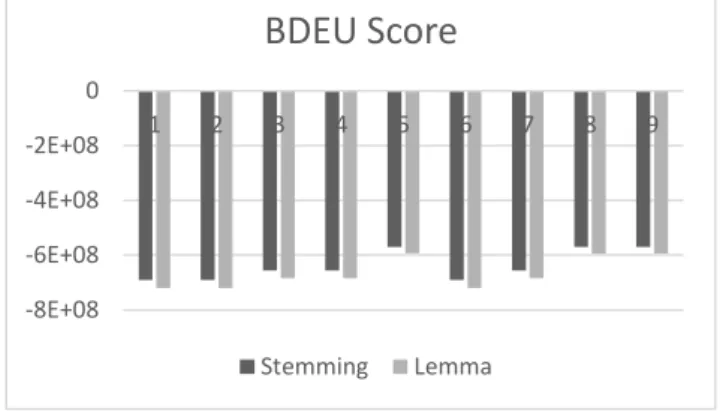
stemming ataupun lemmatization, dapat kita lihat bahwa keduanya memiliki hasil yang sama, yaitu graf ke 5 sebagai graf terbaik. Meskipun skor BDeunya berbeda, tetapi hasil performansi f1-measure-nya sama, dan dari hasil ini dapat disimpulkan bahwa besar nilai pada BDEU ditentukan oleh struktur graf dan banyaknya hasil ekstraksi fitur. Namun yang paling mempengaruhi hasil akhir adalah bentuk dari struktur graf. Perbandingan BDeu score dari hasil stemming dan lemmatization dapat dilihat pada gambar 5.
Gambar 9 Perbandingan skor BDeu hasil stemming dengan lemmatization.
3. Hasil Evaluasi Sistem
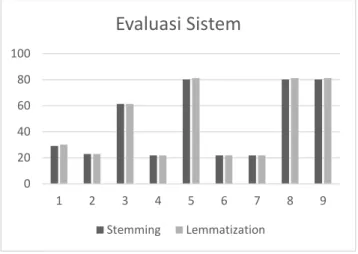
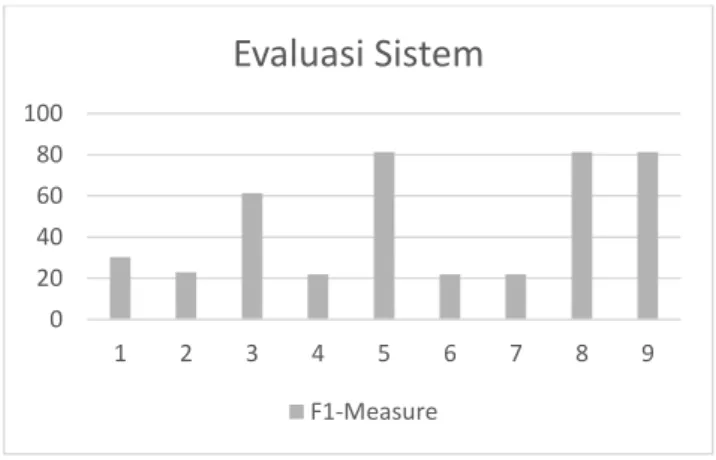
Dari hasil yang didapatkan pada gambar 6 dapat disimpulkan bahwa, meskipun keduanya memiliki nilai yang berbeda untuk setiap grafnya. Tetapi hasil akhirnya masih tetap sama dimana graf ke 5, 8, dan 9 memiliki hasil tertinggi dari semua graf yang ada, untuk penjelasannya akan dijelaskan pada pengujian berikutnya (untuk bagian struktur graf).
-8E+08 -6E+08 -4E+08 -2E+08 0 1 2 3 4 5 6 7 8 9
BDEU Score
Stemming LemmaGambar 10 Perbandingan Hasil evaluasi Sistem
Dari hasil pengujian yang telah dilakukan dapat disimpulkan bahwa baik menggunakan stemming ataupun
lemmatization hasil kesimpulan akhir yang didapat akan tetap sama, yang membedakan hanyalah skor BDeu-nya saja, dan itu disebabkan karena adanya perbedaan jumlah fitur yang diekstraksi. Namun pada evaluasi, nilai
lemmatization lebih tinggi sekitar 1.5% dari stemming. Dari sini dapat disimpulkan bahwa lemmatization lebih baik daripada stemming dengan menggunakan algoritma Porter. Hal yang menyebabkan stemming memiliki fitur yang lebih sedikit daripada lemmatization adalah, karena adanya perbedaan proses pemotongan kata. Terkadang
stemming memiliki masalah yaitu overstemming dan understemming. Overstemming adalah kondisi dimana kata yang seharusnya hanya dipotong sedikit, menjadi dipotong terlalu banyak dan menyebabkan kata tersebut menjadi memiliki konteks yang berbeda sedangkan understemming adalah kondisi dimana kata yang seharusnya dipotong banyak, hanya dipotong sedikit saja [7]. Hal ini menyebabkan kata dapat menghilang akibat overstemming
sedangkan kata yang harusnya memiliki arti dan bentuk yang berbeda, menjadi memiliki bentuk yang sama setelah di overstemming atau understemming.
2. Analisis pengaruh struktur graf Bayesian Network terhadap performansi sistem.
Pengujian dilakukan dengan membandingkan hasil klasifikasi dari sembilan graf yang telah dibuat. Berdasarkan hasll dari pengujian sebelumnya didapatkan bahwa lemmatization menghasilkan hasil yang lebih tinggi daripada stemming, maka pada proses klasifikasi, fitur yang digunakan akan berasal dari lemmatization.
1. Nilai Struktur Graf.
Nilai Struktur graf dihitung untuk menentukan graf mana yang baik dan cocok digunakan untuk kasus dataset seperti ini. Nilai yang paling baik adalah nilai yang mendekati 1. Pada gambar 7 dapat kita lihat bahwa graf 5 memiliki nilai yang paling mendekati 1, walaupun hanya berbeda selisih sedikit dari graf 8 dan 9. Hal itu dikarenakan struktur mereka yang hampir mirip.
0 20 40 60 80 100 1 2 3 4 5 6 7 8 9
Evaluasi Sistem
Stemming LemmatizationGambar 11 Grafik skor BDeu
2. Hasil Evaluasi Sistem
Dari grafik evaluasi sistem pada gambar 25 dapat dilihat bahwa semua graf memiliki nilai akurasi yang tinggi, oleh karena itulah, akurasi tidak dapat dijadikan tolak ukur dalam mengevaluasi sistem yang melakukan proses klasifikasi. Perlu adanya variable tambahan yaitu precision dan recall. Precision adalah rasio dari dokumen relevan yang diklasifikasikan oleh classifier, sedangkan recall adalah rasio banyaknya dokumen relevan yang diambil oleh classifier sebanyak total dokumen relevan yang ada pada database. Karena sering adanya perbedaan antara nilai precision dan recall apalagi khususnya untuk kasus multiple-class classification, F1-Measure perlu dihitung sebagai nilai yang merupakan rata – rata dari precision dan recall. Nilai F1-Measure itulah yang kemudian dijadikan tolak ukur untuk evaluasi sistem, dan kembali lagi ke gambar 12-6 terlihat bahwa graf 5, 8 dan 9 memiliki hasil yang sama, begitu juga dengan graf 4, 6 dan 7 hal ini disebabkan karena struktur mereka yang mirip.
Gambar 12 Hasil nilai f1-measure untuk setiap graf
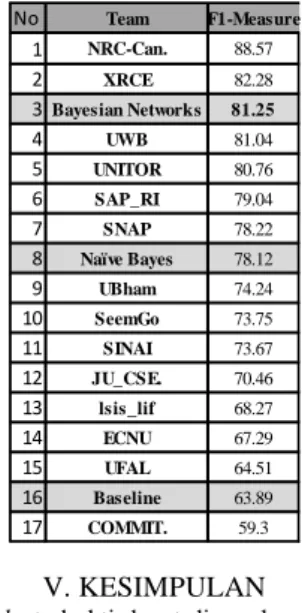
3. Perbandingan hasil penelitian terhadap baseline
Pada SemEval 2014 telah banyak pula peneliti yang memberi data evaluasi sistem hasil penelitian berdasarkan
task yang sama, untuk kemudian dibandingkan dengan peneliti – peneliti yang lain dan dengan nilai baseline
yang ditetapkan sebesar 63.89, dan hasil yang didapat oleh penulis cukup tinggi dan menempati peringkat ke 3.
-8E+08 -6E+08 -4E+08 -2E+08 0 1 2 3 4 5 6 7 8 9
BDEU Score
Total 0 20 40 60 80 100 1 2 3 4 5 6 7 8 9Evaluasi Sistem
F1-MeasureTabel 3 Tabel Baseline
V. KESIMPULAN
1. Metode klasifikasi Bayesian Networks terbukti dapat digunakan untuk mengklasifikasikan aspek dan sentimen dengan performansi klasifikasi terbaik berupa F1-measure sebesar 81.25 %.
2. Struktur graf Bayesian Networks yang memberikan performansi klasifikasi terbaik memiliki skor BDeu sebesar -569705681.6 dengan struktur graf sebagai berikut:
i. Variable Words menjadi child dari variable Polarity dan Aspek.
3. Lemmatization mampu memberikan performansi klasifikasi yang lebih baik dibandingkan dengan stemming. Penggunaan lemmatization menghasilkan performansi klasifikasi F1-measure sebesar 81.25% sedangkan penggunaan stemming memberikan performansi klasifikasi F1-measure sebesar 80.208 %.
ACKNOWLEDGMENT
Penulis mengucapkan terimakasih kepada orang-orang yang memberikan semangat, dukungan, dan bantuan kepada penulis. Penulis persembahkan kepada:
1. Bapak Dr. Adiwijaya, S.Si., M.Si. selaku pembimbing I yang telah membimbing dan membantu dalam proses penyelesaian proyek akhir. Segala saran dan kritik yang membangun adalah hal yang paling berharga untuk kami, terimakasih banyak pak.
2. Bapak Mohamad Syahrul Mubarok selaku pembimbing II yang telah menyempatkan waktu nya untuk menerima bimbingan dan membantu dalam proses penyelesaian proyek akhir kami, saran dan masukan sangat membangun dan membuat permainan ini semakin menarik, atas segalanya kami ucapkan terimakasih.
3. Seluruh rekan IF-38-11 Ekstensi yang setia memberi motivasi dan membagi ilmunya selama di tahun perkuliahan.
DAFTAR PUSTAKA
[1] G. G. Chowdury, "Natural Language Processing," University of Strathclyde, Glasgow G1 1XH UK, Scotlandia, 2003.
[2] B. Liu, Sentiment Analysis and Opinion Mining, Morgan and Claypool Publisher, 2012.
[3] K. B. Corb and A. E. Nicholson, "Introducing Bayesian Network," in Bayesian Artificial Intelligence, New Work, CRC Press, 2011, pp. 29-50.
[4] B. Malone, "Parameter Estimation with Complete Data," University of Helsinki, Finland, 2014. [5] B. Malone, "Scoring Functions for Learning Bayesian Networks," University of Helsinki, Finland, 2014. [6] S. Garcia, J. Luengo and F. Herrera, Data Preprocessing in Data Mining, Cham: Springer, 2015.
[7] al and A. G. J. et, "A Comparative Study of Stemming Algorithms," The Maharaja Sayajirao University of Baroda, Gujarat, 1938. No Team F1-Measure 1 NRC-Can. 88.57 2 XRCE 82.28 3Bayesian Networks 81.25 4 UWB 81.04 5 UNITOR 80.76 6 SAP_RI 79.04 7 SNAP 78.22 8 Naïve Bayes 78.12 9 UBham 74.24 10 SeemGo 73.75 11 SINAI 73.67 12 JU_CSE. 70.46 13 lsis_lif 68.27 14 ECNU 67.29 15 UFAL 64.51 16 Baseline 63.89 17 COMMIT. 59.3
[8] R. C and R. R, "International Journal of Advanced Research in Computer and Communication Engineering,"
Effective Pre-Processing Activities in Text Mining using Improved Porter’s Stemming Algorithm, p. 2, 2013. [9] V. Gupta and G. S. Lehal, "Journal Of Emerging Technologies in Web Intelligence," A Survey of Text Mining
Techniques and Application, pp. 60-76, 2009.
[10] D. Heckerman, "A Tutorial on Learning with Bayes Networks," Microsoft Research Advanced Technology Division, Redmond, 1996.
[11] A. K. Ingson, S. Helgadottir and H. Loftsonn, "A Mixed Method Lemmatization Algorithm Using a Hierarchy of Linguistics Identities," Departement of Icelandic, University of Iceland, Iceland.
[12] M. Junker, R. Hochl and A. Dengel, "On the Evaluation of Document Analysis Components by Recall, Precision, and Accuracy," German Research Center for Artificial Intelligence, Kaiserslautern.
[13] A. Kennedy and D. Inkpen, "Sentiment Classification of Movie Reviews using Contextual Valence Shifter," University of Ottawa, Canada, 2006.
[14] J. Plisson, N. Lavrac and D. Mladenic, "A Rule based Approach to Word Lemmatization," Department of Knowledge Technologies, Ljubljana, Slovenia.
[15] M. Potniki, D. Galanis and J. Pavlopoulos, "2014 Task 4: Aspect Based Sentiment Analysis," SemEval-2014, -, 2014.
[16] F. Erwanda, Adiwijaya and G. Septiana, "Implementasi Hubs and authorities centrality dalam Social network analysis," INDOSC, Bandung, 2014.
[17] F. A. Rahman, K. R. Saleh and A. Ghozali, "Kompresi Basisdata Graph Menggunakan Power Graph Analysis," INDOSC, Bandung, 2014.