Fakultas Ilmu Komputer
1
Peringkasan Teks Ekstraktif Kepustakaan Ilmu Komputer Bahasa
Indonesia Menggunakan Metode
Normalized
Distance
dan
K-means
Dhimas Anjar Prabowo1, Mochammad Ali Fauzi2, Yuita Arum Sari3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Semakin cepatnya peningkatan jumlah data digital setiap tahun menyebabkan seseorang menjadi sulit untuk dapat membaca keseluruhan informasi yang ada. Salah satu contoh data digital tersebut adalah data teks dokumen, yang dapat berupa dokumen penelitian. Permasalahan tersebut mendorong urgensi diperlukannya sebuah teknik otomatis yang dapat menyajikan informasi bermanfaat dengan ringkas dan jelas. Di mana salah satu solusi dari permasalahan tersebut adalah dengan teknik peringkasan teks. Penelitian ini menggunakan algoritme Normalized Google Distance (NGD) dan K-means dalam penerapan teknik peringkasan teksnya, dengan objek penelitian yaitu dokumen kepustakaan ilmu komputer berbahasa Indonesia. Di mana NGD digunakan sebagai algoritme untuk medapatkan kalimat-kalimat yang berkaitan dengan judul dari dokumen dan K-means digunakan sebagai algoritme untuk mendapatkan kalimat ringkasan yang berasal dari berbagai topik bahasan yang terkandung dalam dokumen. Hasil pengujian dari penelitian ini menunjukkan bahwa peringkasan teks menggunakan metode NGD dan K-means mendapati nilai rata-rata akurasi precision, recall, dan
relative utility terbaik secara berurutan pada pakar pertama sebesar 0,20, 0,47, 0,48 dan pada pakar kedua sebesar 0,27, 0,43, 0,45. Serta mendapati nilai rata-rata kappa sebesar 0,41 atau moderate.
Kata kunci: peringkasan teks ekstraktif, Normalized Google Distance, K-means
Abstract
The yearly rapid increase of digital data surface a problem for a person to be able to read every information that was served. One example of its data was a textual data document, which could be in a form of research document. This problem urges for a solution that is a technique to present all of the information in a clear and concise form, and one of its solution is a text summarization technique. This research proposed a text summarization technique using Normalized Google Distance (NGD) and K-means as its extractive algorithm, with a textual data that is a research document based on computer science studies in an Indonesian language as its research object. NGD will be used as an algorithm to derive sentences that was related to its document’s title, and K-means will be used as an algorithm to obtain important sentences by its several topics that occurs in the document. The experiment result showed that this research possess an average best of precision, recall, and relative utility measures scores by 0.27, 0.43, and 0.45 respectively. In the other hand, the experiment result also showed that this research possess an average of kappa measure score by 0.41 or moderate.
Keywords: extractive text summarization, Normalized Google Distance, K-means
1. PENDAHULUAN
World Wide Web telah menyediakan informasi online yang sangat banyak sekali jumlahnya. Dengan fakta tersebut, akan muncul banyak halaman web dan informasi yang berbeda-beda setiap kali seseorang mencari sesuatu dalam internet. Di mana hal tersebut membuat seseorang mustahil untuk dapat membaca keseluruhan informasi yang ada
2012).
Salah satu contoh dari banyaknya informasi tersebut adalah data teks dokumen, yang dapat berupa artikel berita, buku elektronik, dokumen penelitian, blog, dan lain sebagainya. Banyaknya data dokumen tersebut membuat penyaringan informasi yang bermanfaat menjadi tidak efisien dan sulit untuk dilakukan. Maka dari itu, diperlukan sebuah teknik otomatis yang dapat mencari tahu, mengindeks, menentukan, dan menyajikan informasi bermanfaat dengan jelas dan ringkas. Di mana membuat penggunanya mampu menghemat waktu dan tenaga. Salah satu solusi dari permasalahan tersebut adalah dengan teknik peringkasan teks (Ferreira et al., 2013).
Secara umum, peringkasan teks dapat didefinisikan sebagai proses untuk mengidentifikasi informasi yang paling berarti dalam sebuah/sekumpulan dokumen yang saling berhubungan. Lalu meringkas dokumen tersebut dalam bentuk yang lebih singkat namun tetap menjaga keseluruhan arti yang terkandung di dalamnya (Babar, 2013). Terdapat faktor penting yang perlu diperhatikan dalam melakukan peringkasan teks, yaitu
compressionrate atau rasio antara panjang dari ringkasan dengan panjang dokumen aslinya. Hal ini perlu diperhatikan karena jika
compression rate diturunkan, maka hasil ringkasan akan semakin ringkas namun beberapa informasi penting akan hilang. Sedangkan jika compression rate dinaikkan, maka hasil ringkasan akan menjadi panjang namun beberapa informasi tidak penting akan ikut termuat. Di mana hal tersebut dapat mempengaruhi kualitas dari ringkasan (Alguliev & Aliguliyev, 2009).
Berbagai penelitian telah dilakukan dalam ruang lingkup peringkasan teks. Sebagai contohnya adalah penelitian yang dilakukan oleh (Prabowo et al., 2016), di mana dilakukan peringkasan teks ekstraktif menggunakan metode Term Frequency-Inverse Document Frequency-Enhanced Genetic Algorithm (TF-IDF-EGA). Peringkasan teks ekstraktif adalah teknik peringkasan teks dengan cara memilih beberapa kalimat tertentu dalam dokumen sebagai hasil dari ringkasan. TF-IDF digunakan sebagai proses untuk menghitung nilai skor setiap kalimat dalam dokumen. EGA sebagai proses untuk memilih kalimat yang akan dijadikan sebagai ringkasan. Metode EGA mampu untuk menghasilkan ringkasan yang terdiri dari kombinasi antara kalimat dengan
skor rendah dan tinggi dengan nilai fitness yang terbaik. Dengan skor rendah terkadang cenderung berupa kalimat deskriptif, dan skor tinggi terkadang cenderung berupa kalimat yang tidak deskriptif. Namun, terdapat kendala yaitu nilai generasi yang sangat besar akan membuat hasil ringkasan terdominasi oleh kalimat dengan nilai skor yang tinggi.
Penelitian lain juga dilakukan oleh (Bhole & Agrawal, 2014), di mana dilakukan peringkasan teks ekstraktif menggunakan metode klasterisasi K-means. CosineSimilarity
digunakan sebagai penghitung jarak kemiripan antar kalimat dalam dokumen. K-means sebagai
pengelompok kalimat dalam dokumen
berdasarkan nilai kedekatan jarak hasil dari perhitungan Cosine Similarity. Namun, penentuan jumlah nilai k klaster dan besar
compression rate sulit untuk ditentukan. Selain itu, meskipun Cosine Similarity terbukti baik dalam memilih kalimat paling relevan dalam dokumen, Cosine Similarity tidak cocok untuk digunakan dalam mendapatkan topik yang
berbeda-beda dalam suatu dokumen
(Elfayoumy & Thoppil, 2014).
Metode Normalized Google Distance
(NGD) merupakan metode bebas fitur yang dalam artian NGD tidak menganalisis data yang ada untuk mencari fitur-fitur tertentu, namun NGD menganalisis keseluruhan data secara serempak untuk menentukan nilai kemiripan setiap pasang objek berdasarkan keterkaitan fitur yang paling dominan (term dan kalimat) (Cilibrasi & Vitanyi, 2007). Metode K-means
merupakan metode yang bertujuan untuk dapat mengenali pengelompokan alami dari suatu data yang belum atau tidak memiliki label tertentu. Di mana pengelompokan data ini dilakukan berdasarkan ukuran kemiripan antar data yang ada, dengan ukuran kemiripan yang tinggi antar data dalam satu kelompok dan ukuran kemiripan yang rendah dengan data yang berada pada kelompok lainnya (Jain, 2010). Di mana dalam penelitian ini, penulis
mencoba untuk mengimplementasikan
peringkasan teks ekstraktif menggunakan metode NGD dan K-means. Dengan objek penelitian yaitu dokumen kepustakaan ilmu komputer berbahasa indonesia. Objek penelitian ini dipilih dengan pertimbangan untuk memudahkan proses pencarian pakar yang akan berperan penting dalam tahap pengujian akurasi dari ringkasan yang dihasilkan.
15%, 20%, 25%, dan 30% dari jumlah keseluruhan kalimat yang terdapat dalam dokumen. Karena dengan compression rate
sebesar 5-30% sudah mencukupi untuk menghasilkan ringkasan yang cukup baik (Alguliev & Aliguliyev, 2009). Compression rate ini akan mempengaruhi jumlah nilai k
klaster yang akan digunakan dalam K-means. Penentuan jumlah k klaster dilakukan dengan cara mengalikan tingkat compression rate yang ditentukan dengan total jumlah kalimat yang ada di dalam dokumen. Sehingga setiap pusat klaster akan mewakili satu kalimat ringkasan dengan topik yang berbeda-beda. Penentuan nilai k ini di dasari oleh objek dari penggunaan
K-means yaitu peringkasan teks. Karena pada
umumnya, K-means dijalankan secara
independen untuk nilai k dan partisi yang berbeda-beda tergantung domain permasalahan yang dihadapi (Jain, 2010).
2. METODOLOGI PENELITIAN
Dalam penelitian ini dilakukan 3 tahapan proses algoritme yaitu preprocessing, NGD, dan K-means. Sebagai lebih jelasnya, tahapan proses algoritme secara keseluruhan dapat dilihat pada Gambar 1.
Gambar 1. Keseluruhan alur tahapan algoritme
Data dokumen yang digunakan dalam penelitian ini adalah 10 data dokumen kepustakaan ilmu komputer berbahasa Indonesia dalam tipe ekstensi file Portable Document Format (PDF). Di mana data dokumen ini didapatkan dari penelitian (Fhadli et al., 2017).
2.1. Preprocessing
Tahap yang pertama kali dilakukan dalam penelitian ini adalah preprocessing.
Preprocessing diperlukan untuk mereduksi besar data teks yang akan diolah pada langkah
processing, serta memangkas lama waktu komputasi dengan hanya memperhatikan pada term-term yang signifikan. Pada umumnya langkah preprocessing terdiri dari 4 tahap yaitu sebagai berikut:
1. Parsing
Tahap menentukan bagian teks mana yang akan digunakan dalam dokumen, di mana biasanya dilakukan dengan pemisahan string
setiap kalimat dengan menggunakan simbol tanda titik sebagai pembatasnya.
2. Lexing atau Tokenisasi
Tahap pemotongan setiap string kata dalam seluruh kalimat hasil parsing. Dalam tahap ini juga dilakukan proses pembuangan tanda baca, angka, duplikasi kata, karakter lain selain huruf alfabet, serta pengubahan setiap huruf kapital menjadi huruf kecil.
3. Filtering
Tahap penghapusan seluruh kata umum atau kata tidak penting hasil tokenisasi dan hanya menyisakan kata-kata penting yang berpotensi menjadi sebuah term. Tahap ini dapat dilakukan dengan menggunakan pendekatan bag-of-words. Pendekatan ini merupakan pendekatan yang menggunakan sekumpulan kata-kata penting (wordlist) atau kata-kata tidak penting (stoplist). Di mana dalam penelitian ini akan digunakan pendekatan
stoplist dengan menggunakan kumpulan kata-kata tidak penting hasil penelitian (Tala, 2003).
4. Stemming
Tahap pengubahan setiap kata hasil
filtering menjadi kata dasar dengan cara menghilangkan kata imbuhan yang masih melekat pada setiap kata. Di mana setiap kata hasil stemming ini akan disebut sebagai term yang akan digunakan dalam langkah
processing.
2.2. NGD
Kemudian setelah didapatkan keseluruhan term indeks hasil dari tahap preprocessing, maka dilakukan tahap algoritme NGD. Metode ini adalah bagian dari langkah processing yang
digunakan penulis dalam melakukan
peringkasan teks. Di mana metode ini merupakan metode bebas fitur yang dalam artian NGD tidak menganalisis data yang ada
Mulai
Data Kepustakaan
Preprocessing
Perhitungan NGD
Klasterisasi K-means
Hasil Ringkasan
untuk mencari fitur-fitur tertentu, namun NGD menganalisa keseluruhan data secara serempak untuk menentukan nilai kemiripan setiap pasang objek berdasarkan keterkaitan fitur yang paling dominan (term dan kalimat) (Cilibrasi &
Vitanyi, 2007). Sehingga dalam
penghitungannya, NGD akan menggunakan data teks berupa term-term hasil akhir dari langkah preprocessing, dan tidak menggunakan fitur-fitur tambahan seperti pada beberapa metode peringkasan teks ekstraktif lain.
NGD merupakan metode pengukuran nilai kemiripan kalimat berdasarkan peristiwa kemunculan term yang muncul bersamaan. Di mana dokumen 𝐷 = {𝑆1, 𝑆2, ⋯ , 𝑆𝑛} adalah sebuah dokumen yang tersusun dari sejumlah kumpulan kalimat, dengan n merupakan jumlah kalimat. Lalu 𝑇 = {𝑡1, 𝑡2, ⋯ , 𝑡𝑚} adalah kata atau term yang terdapat dalam dokumen D, dengan m merupakan jumlah term. Dan kalimat
𝑆𝑖 = {𝑡1, 𝑡2, ⋯ , 𝑡𝑚𝑖} adalah sebuah kalimat
yang tersusun dari sekumpulan term yang terdapat dalam kalimat 𝑆𝑖, dengan 𝑚𝑖 merupakan jumlah term yang terdapat dalam kalimat 𝑆𝑖. Selanjutnya, sebelum dapat menghitung nilai kemiripan kalimat, terlebih dahulu dilakukan penghitungan nilai kemiripan term yang telah diperoleh dari langkah
preprocessing. Untuk dapat menghitung kemiripan term 𝑡𝑘 dan 𝑡𝑙, maka digunakan persamaan 1:
𝑠𝑖𝑚𝑁𝐺𝐷(𝑡𝑘, 𝑡𝑙) = 𝑒𝑥𝑝(−𝑁𝐺𝐷(𝑡𝑘, 𝑡𝑙)) (1)
Keterangan persamaan 1:
𝑡𝑘: term ke k,
𝑡𝑙: term ke l.
dengan,
𝑁𝐺𝐷(𝑡𝑘, 𝑡𝑙) =𝑚𝑎𝑥{𝑙𝑜𝑔(𝑓log 𝑛−𝑚𝑖𝑛{𝑙𝑜𝑔(𝑓𝑘),𝑙𝑜𝑔(𝑓𝑘𝑙)}−𝑙𝑜𝑔(𝑓),𝑙𝑜𝑔(𝑓𝑙)}𝑘𝑙) (2)
Keterangan persamaan 2:
𝑓𝑘: jumlah kalimat yang mengandung term
ke k,
𝑓𝑙: jumlah kalimat yang mengandung term
ke l,
𝑓𝑘𝑙: jumlah kalimat yang mengandung
term ke k dan term ke l,
n: jumlah kalimat dalam dokumen. Diikuti dengan aturan:
1. Rentang nilai dari 𝑠𝑖𝑚𝑁𝐺𝐷(𝑡𝑘, 𝑡𝑙) adalah antara 0 dan 1,
Jika 𝑡𝑘 = 𝑡𝑙 atau jika 𝑡𝑘 ≠ 𝑡𝑙 namun 𝑓𝑘 = 𝑓𝑙 = 𝑓𝑘𝑙 > 0, maka
𝑠𝑖𝑚𝑁𝐺𝐷(𝑡𝑘, 𝑡𝑙) = 1.
Jika 𝑓𝑘 > 0, 𝑓𝑙 > 0, dan 𝑓𝑘𝑙 = 0, maka 𝑁𝐺𝐷(𝑡𝑘, 𝑡𝑙) = 1, sehingga
0 < 𝑠𝑖𝑚𝑁𝐺𝐷(𝑡𝑘, 𝑡𝑙) < 1.
Jika 0 < 𝑓𝑘𝑙 < 𝑓𝑙 < 𝑓𝑘 < 𝑛 dan
𝑓𝑘 ∙ 𝑓𝑙 > 𝑛 ∙ 𝑓𝑘𝑙, maka 0 <
𝑠𝑖𝑚𝑁𝐺𝐷(𝑡𝑘, 𝑡𝑙) < 1.
2. 𝑠𝑖𝑚𝑁𝐺𝐷(𝑡𝑘, 𝑡𝑘) = 1 untuk setiap 𝑡𝑘, dan untuk setiap pasang 𝑡𝑘 dan 𝑡𝑙,
𝑠𝑖𝑚𝑁𝐺𝐷(𝑡𝑘, 𝑡𝑙) = 𝑠𝑖𝑚𝑁𝐺𝐷(𝑡𝑙, 𝑡𝑘) atau
bisa dikatakan bahwa hal tersebut simetris.
Kemudian dengan hasil dari persamaan 1, dapat dihitung nilai kemiripan antara kalimat 𝑆𝑖 dan 𝑆𝑗 dengan persamaan 3:
𝑠𝑖𝑚𝑁𝐺𝐷(𝑆𝑖, 𝑆𝑗) =
∑𝑡𝑘∈𝑆𝑖∑𝑡𝑙∈𝑆𝑗𝑠𝑖𝑚𝑁𝐺𝐷(𝑡𝑘,𝑡𝑙)
𝑚𝑖𝑚𝑗 (3)
Keterangan persamaan 3:
𝑆𝑖: kalimat ke i,
𝑆𝑗: kalimat ke j,
𝑚𝑖: jumlah term dalam kalimat ke i,
𝑚𝑗: jumlah term dalam kalimat ke j.
Diikuti dengan aturan:
1. Rentang nilai dari 𝑠𝑖𝑚𝑁𝐺𝐷(𝑆𝑖, 𝑆𝑗) adalah antara 0 dan 1,
2. 𝑠𝑖𝑚𝑁𝐺𝐷(𝑆𝑖, 𝑆𝑖) ≥ 0 untuk setiap 𝑆𝑖, 3. Untuk setiap pasang 𝑆𝑖 dan 𝑆𝑗,
𝑠𝑖𝑚𝑁𝐺𝐷(𝑆𝑖, 𝑆𝑗) = 𝑠𝑖𝑚𝑁𝐺𝐷(𝑆𝑗, 𝑆𝑖) atau
bisa dikatakan bahwa hal tersebut simetris.
Di mana dalam perhitungan nilai kemiripannya, penulis menyisipkan term-term yang terkandung dalam judul kepustakaan sebagai kalimat pertama dari keseluruhan kalimat yang ada. Dengan demikian, penulis dapat mengurutkan nilai kemiripan dari keseluruhan kalimat dengan kalimat pertama dan mengambil sebanyak persentase cutting rate kalimat dari keseluruhan hasil pengurutan yang didapat. Hal ini merupakan penerapan dari tugas query-based yang digunakan, dan hal ini dilakukan guna untuk mereduksi banyaknya jumlah kalimat yang akan diseleksi sebagai hasil dari ringkasan. Selain itu, hal ini juga membuat kalimat yang diseleksi berupa kalimat yang benar-benar berkaitan dengan judul dari dokumen kepustakaan yang digunakan.
2.3. Klasterisasi K-means
Selanjutnya ketika nilai kemiripan untuk setiap kalimat terpilih hasil tahap NGD didapatkan, maka dilakukan tahap klasterisasi
digunakan sebagai langkah untuk memilih kalimat ringkasan yang digunakan penulis dalam melakukan peringkasan teks. K-means
merupakan salah satu metode terapan dari problematika klasterisasi data dan bersifat
unsupervised. Metode ini memiliki tujuan untuk dapat mengenali pengelompokan alami dari suatu data yang belum atau tidak memiliki label tertentu. Di mana pengelompokan data ini dilakukan berdasarkan ukuran kemiripan antar data yang ada, dengan ukuran kemiripan yang tinggi antar data dalam satu kelompok dan ukuran kemiripan yang rendah dengan data yang berada pada kelompok lainnya (Jain, 2010).
K-means termasuk dalam tipe klasterisasi
partitional yang bekerja dengan cara mencari keseluruhan kelompok secara serentak sebagai bagian dari data dan tidak menggunakan struktur yang hirarki (Jain, 2010). Langkah-langkah dari proses klasterisasi K-means adalah sebagai berikut:
1. Tentukan jumlah k klaster, dengan 𝐶 =
{𝐶1, 𝐶2, ⋯ , 𝐶𝑘}. Di mana dalam
penelitian ini, penulis menentukan jumlah k klaster dengan cara mengkalikan besar tingkat compression rate yang telah ditentukan dengan total jumlah kalimat yang ada di dalam dokumen. Sehingga nantinya, setiap pusat klaster akan mewakili satu kalimat ringkasan dengan topik yang berbeda-beda.
2. Inisialisasi k centroid/pusat klaster awal, yang pada umumnya dilakukan secara random atau acak.
3. Tempatkan setiap data i ke data pusat klaster terdekat. Penempatan ini pada umumnya dilakukan dengan cara menghitung jarak kedekatan atau kemiripan data terhadap data pusat klaster. Di mana penulis akan menggunakan nilai kemiripan antar kalimat yang telah didapatkan dari perhitungan metode NGD (persamaan 3).
4. Hitung pusat klaster baru berdasarkan isi data klaster yang telah dihasilkan dari langkah ke-3 dengan menggunakan persamaan 4:
Persamaan ini mencari rata-rata nilai kemiripan kalimat ke i terhadap keseluruhan kalimat yang ada dalam klaster ke k, di mana kalimat dengan rata-rata nilai kemiripan yang terbesar akan dipilih sebagai pusat klaster baru yang akan digunakan dalam iterasi berikutnya.
5. Ulangi langkah ke-3 dan 4 hingga kondisi berhenti yang ditentukan terpenuhi. Kondisi berhenti dapat berupa kondisi bahwa tidak ada lagi perubahan pusat klaster atau dapat juga berupa jumlah iterasi maksimum. Selanjutnya setelah klaster terakhir telah didapat, maka proses pemilihan kalimat yang akan dijadikan sebagai ringkasan dilakukan. Proses pemilihan kalimat ini dilakukan dengan cara memilih kalimat yang menjadi centroid
dari setiap klaster yang ada sebagai kalimat ringkasan. Dengan harapan, hal ini dapat mengambil kalimat dengan topik yang berbeda-beda berdasarkan centroid dari setiap klaster yang merepresentasikan topik bahasan yang berbeda-beda. Sehingga akhirnya, hasil ringkasan yang diperoleh adalah kalimat-kalimat yang berkaitan dengan judul dari dokumen kepustakaan (hasil dari NGD) serta tersusun oleh topik bahasan yang berbeda-beda (hasil dari K-means). Proses pemilihan kalimat ini penulis adaptasi dari (García-Hernández et al., 2008) yang memilih kalimat yang paling dekat dengan centroid pada setiap klaster, dengan perubahan yang telah dijelaskan di atas.
2.4. Evaluasi Hasil Peringkasan
Untuk peringkasan berbasis ekstraksi kalimat, pada umumnya dievaluasi dengan menggunakan kategori intrinsik bertipe co-selection, yang pada dasarnya mencari tahu seberapa banyak inti informasi yang dikandung dalam hasil ringkasan. Evaluasi co-selection
terdiri dari 2 konten evaluasi yaitu precision,
recall, dan relativeutility (Steinberger & Jezek, 2009).
2.5. Precision dan Recall
dari sistem dan seorang pakar terhadap jumlah kalimat hasil ringkasan dari sistem. Recall
merupakan ukuran nilai kualitas ringkasan yang melihat pada seberapa besar tingkat jumlah irisan kalimat hasil ringkasan dari sistem dan seorang pakar terhadap jumlah kalimat hasil ringkasan dari pakar (Nenkova & McKeown, 2011). Untuk perhitungannya dapat dilihat pada persamaan 5 dan 6:
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 =𝑡𝑜𝑡𝑎𝑙 (𝑘𝑟𝑑𝑠 ∩ 𝑘𝑟𝑑𝑝)𝑡𝑜𝑡𝑎𝑙 𝑘𝑟𝑑𝑠 (5)
𝑅𝑒𝑐𝑎𝑙𝑙 =𝑡𝑜𝑡𝑎𝑙 (𝑘𝑟𝑑𝑠 ∩ 𝑘𝑟𝑑𝑝)𝑡𝑜𝑡𝑎𝑙 𝑘𝑟𝑑𝑝 (6)
Keterangan persamaan 5, 6, dan 7:
krds: kalimat ringkasan dari sistem
krdp: kalimat ringkasan dari pakar
Di mana rentang nilai kualitas dari
precision dan recall adalah dari 0 hingga 1. Dengan kesimpulan bahwa semakin tinggi nilai
precision dan recall maka semakin baik pula ringkasan yang dihasilkan oleh sistem.
Precision dapat dikatakan sebagai tingkat ketepatan sistem dalam memperoleh informasi yang bermanfaat atau sesuai dengan keinginan penggunanya. Sedangkan recall dapat dikatakan sebagai tingkat keberhasilan sistem dalam memperoleh kembali informasi dari dokumen aslinya.
2.6. Relative Utility
Relative utility merupakan ukuran nilai kualitas ringkasan yang melihat pada seberapa besar skor kalimat hasil ringkasan dari sistem dengan keseluruhan skor kalimat hasil identifikasi dari pakar. Untuk perhitungannya dapat dilihat pada persamaan 7:
𝑅𝑒𝑙𝑎𝑡𝑖𝑣𝑒 𝑈𝑡𝑖𝑙𝑖𝑡𝑦 =𝑡𝑜𝑡𝑎𝑙 𝑠𝑘𝑜𝑟 𝑘𝑒𝑠𝑒𝑙𝑢𝑟𝑢ℎ𝑎𝑛 𝑘𝑟𝑑𝑝𝑡𝑜𝑡𝑎𝑙 𝑠𝑘𝑜𝑟 𝑘𝑟𝑑𝑠 (7)
Di mana rentang skor kalimat adalah dari 0 hingga 10 yang dipilih secara selektif oleh pakar. Dengan ketentuan bahwa kalimat yang berpotensi menjadi ringkasan benilai skor tinggi, dan kalimat yang tidak berpotensi menjadi ringkasan bernilai skor rendah (Nenkova & McKeown, 2011). Total skor kalimat hasil ringkasan dari sistem didapat dengan cara mengidentifikasi kalimat ringkasan dari sistem yang muncul dalam kalimat hasil ringkasan dari pakar.
2.6. Kappa Statistic
Kappa Statistic merupakan ukuran nilai persetujuan antara dua atau lebih pakar dalam mengamati sesuatu. Di mana pengukuran ini
ditentukan dengan membandingkan antara jumlah persetujuan yang didapat (po) dengan
jumlah persetujuan yang diharapkan dapat diperoleh berdasarkan peluang (pe) (Viera &
Garrett, 2005). Untuk perhitungannya dapat dilihat pada persamaan 8 hingga 10 dengan memperhatikan Tabel 1.
Tabel 1. Pengukuran kappa
Kappa Pakar 1 – Kalimat Ringkasan?
Pakar 2 – Kalimat Ringkasan?
Ya Tidak Total
Ya a b m1
Tidak c d m0
Total n1 n0 n
𝑝𝑒= [(𝑛𝑛1) ∗ (𝑚𝑛1)] + [(𝑛𝑛0) ∗ (𝑚𝑛0)] (7)
𝑝𝑜=(𝑎+𝑑)𝑛 (8)
𝐾𝑎𝑝𝑝𝑎 =(𝑝𝑜+𝑝𝑒)
(1−𝑝𝑒) (9)
Dengan a merupakan kondisi ketika kedua pakar setuju bahwa kalimat termasuk ringkasan,
b merupakan kondisi ketika pakar kedua setuju bahwa kalimat termasuk ringkasan namun pakar pertama tidak setuju, c merupakan kondisi ketika pakar pertama setuju bahwa kalimat termasuk ringkasan namun pakar kedua tidak setuju, d merupakan kondisi ketika kedua pakar setuju bahwa kalimat bukan termasuk ringkasan. Sedangkan n1 merupakan total nilai
dari a dan c, n0 merupakan total nilai dari b dan
d, m1 merupakan total nilai dari a dan b, m0
merupakan total nilai dari c dan d, lalu n
merupakan total keseluruhan kalimat yang diamati.
Kualitas nilai kappa dapat dibedakan menjadi beberapa kategori atau seperti yang dapat dilihat pada Tabel 2.
Tabel 2. Kualitas nilai kappa
Kappa Tingkat Persetujuan
< 0 Poor
0,01-0,20 Slight
0,21-0,40 Fair
0,41-0,60 Moderate
0,61-0,80 Substantial
0,81-0,99 Almost Perfect
Evaluasi hasil ringkasan ini dilakukan terhadap 3 parameter yang diperlukan dalam melakukan peringkasan, parameter tersebut adalah cutting rate, compression rate, dan iterasi maksimum. Di mana dalam parameter
dokumen yang digunakan. Lalu untuk parameter lainnya, antara lain compression rate
dan iterasi maksimum akan menggunakan persentase dan tingkat nilai yang paling besar yaitu 30% dan 50. Pengujian ini bertujuan untuk mengetahui besar persentase cutting rate
yang diperlukan untuk dapat menghasilkan nilai akurasi terbaik.
Lalu dalam parameter compression rate
akan dilakukan 6 kali uji coba besar persentase
compressionrate, yaitu sebesar 5%, 10%, 15%, 20%, 25%, dan 30% untuk setiap data teks dokumen yang digunakan. Variasi tersebut dipilih karena dengan compressionrate sebesar 5-30% sudah mencukupi untuk menghasilkan ringkasan yang cukup baik (Alguliev & Aliguliyev, 2009). Lalu untuk parameter lainnya, antara lain cutting rate akan menggunakan persentase yang menghasilkan nilai akurasi terbaik. Sedangkan iterasi maksimum akan menggunakan tingkat nilai yang paling besar yaitu 50. Pengujian ini bertujuan untuk mengetahui besar persentase
compression rate yang diperlukan untuk dapat menghasilkan nilai akurasi terbaik.
Dan terakhir dalam parameter iterasi maksimum akan dilakukan 3 kali uji coba besar nilai iterasi maksimum dari algoritme K-means, yaitu sebesar 10, 25, dan 50 untuk setiap data teks dokumen yang digunakan. Lalu untuk parameter lainnya, antara lain cutting rate dan
compression rate menggunakan persentase yang menghasilkan nilai akurasi terbaik. Pengujian ini bertujuan untuk mengetahui besar nilai iterasi maksimum yang diperlukan untuk dapat menghasilkan nilai akurasi terbaik.
3. PENGUJIAN DAN ANALISIS HASIL
Pengujian ini dilakukan dengan mengacu pada perlakukan uji coba yang telah dijelaskan dalam bab 2. Di mana data hasil peringkasan pakar yang digunakan diperoleh dari penelitian (Fhadli et al., 2017) yang menggunakan data teks dokumen yang sama dengan penulis. Lalu dengan satu pakar lain agar analisis pakar tidak bersifat subjektif.
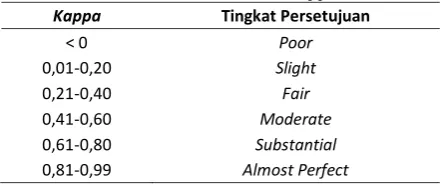
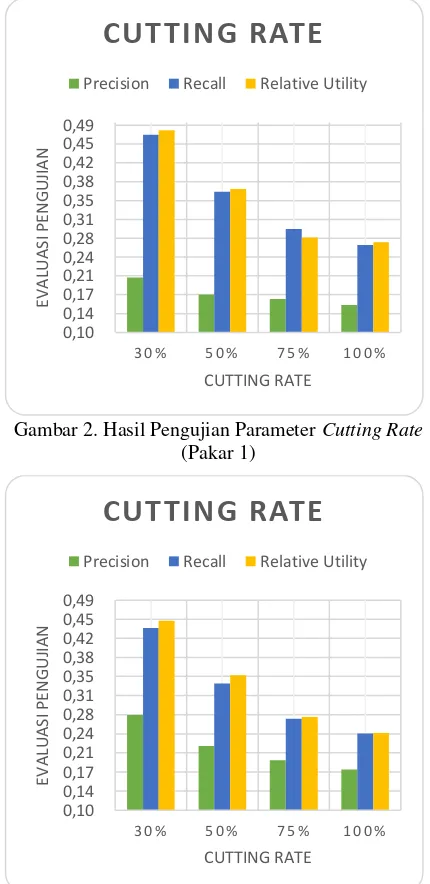
3.1. Hasil Pengujian Parameter Cutting Rate
Berdasarkan Gambar 2 dan 3 dapat dilihat bahwa rata-rata nilai precision, recall, dan
relative utility tertinggi atau yang secara berurutan pada pakar pertama bernilai 0,20, 0,47, 0,48 dan pada pakar kedua bernilai 0,27, 0,43, 0,45 didapatkan pada persentase uji coba
parameter cutting rate sebesar 30%. Dapat dilihat pula bahwa semakin besar persentase
cutting rate yang digunakan maka semakin kecil pula rata-rata ketiga nilai akurasi yang didapat.
Hal ini disebabkan karena besar persentase
cutting rate menentukan banyaknya kalimat berkaitan dengan judul yang akan digunakan dalam klasterisasi untuk mendapatkan hasil ringkasan. Sehingga, semakin besar penggunaan persentase cutting rate akan memperbesar kemungkinan kalimat yang kecil kaitannya dengan judul untuk masuk ke dalam klasterisasi. Di mana hal tersebut dapat membuat kalimat yang kecil kaitannya dengan judul untuk ikut terpilih sebagai hasil ringkasan.
Gambar 2. Hasil Pengujian Parameter Cutting Rate (Pakar 1)
3.2. Hasil Pengujian Parameter Compression Rate
Berdasarkan Gambar 4 dan 5 dapat dilihat bahwa rata-rata nilai precision, recall, dan
relative utility tertinggi atau yang secara berurutan pada pakar pertama bernilai 0,20, 0,47, dan 0,48 dan pada pakar kedua bernilai 0,27, 0,43, 0,45 didapatkan pada persentase uji coba parameter compression rate sebesar 30%. Dapat dilihat pula bahwa semakin besar persentase compression rate yang digunakan maka semakin besar pula rata-rata ketiga nilai akurasi yang didapat.
Hal ini disebabkan karena besar persentase
compression rate menentukan banyaknya kalimat yang akan dipilih sebagai hasil ringkasan. Sehingga, semakin besar penggunaan persentase compression rate akan memperbesar banyak kalimat penting yang berkemungkinan untuk terpilih sebagai hasil ringkasan. Namun, perbedaan cara pemilihan kalimat ringkasan dari sistem dan pakar membuat nilai akurasi yang didapat bernilai rendah. Hal ini dikarenakan terkadang pakar memilih kalimat ringkasan secara satu teks paragraf penuh dan kemudian mengambil beberapa kalimat saja pada teks penjelasan lainnya. Berbeda halnya dengan sistem yang memilih kalimat berdasarkan setiap topik dalam data teks dokumen yang digunakan.
Sebagai contoh misalkan dalam topik pertama, sistem hanya mengambil kalimat yang terhitung sebagai kalimat yang menjadi centroid dari keseluruhan kalimat dalam topik tersebut. Di mana hal tersebut menyebabkan sistem untuk menghasilkan kalimat ringkasan yang rata porsinya untuk setiap topik dalam data teks dokumen, yang tidak seperti halnya pakar yang mengambil kalimat ringkasan berdasarkan nalar penting atau tidaknya sebuah kalimat dan bahkan mungkin tidak memilih beberapa kalimat penting yang dirasa telah dijelaskan pada kalimat-kalimat sebelumnya.
Gambar 4. Hasil Pengujian Parameter Compression Rate (Pakar 1)
Gambar 5. Hasil Pengujian Parameter Compression Rate (Pakar 2)
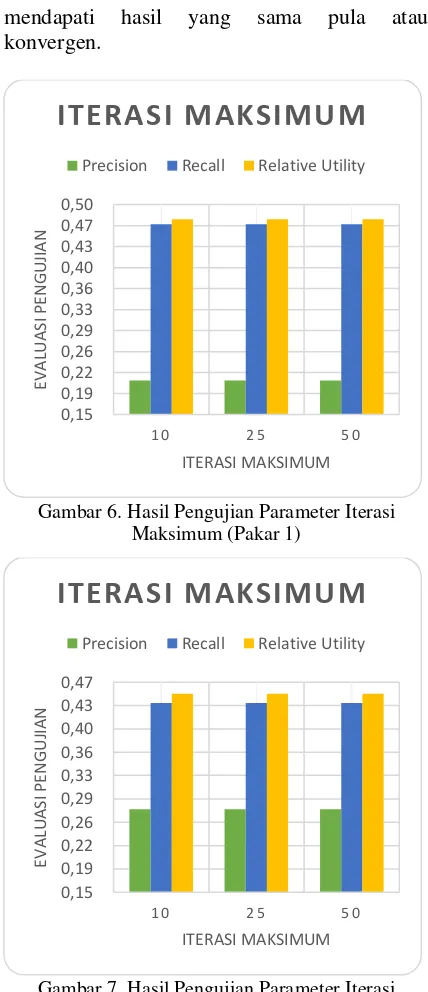
3.3. Hasil Pengujian Parameter Iterasi Maksimum
Berdasarkan Gambar 6 dan 7 dapat dilihat bahwa rata-rata nilai precision, recall, dan
relative utility untuk setiap besar nilai parameter iterasi maksimum adalah sama atau yang secara berurutan pada pakar pertama bernilai 0,20, 0,47, dan 0,48 dan pada pakar kedua bernilai 0,27, 0,43, 0,45. Dapat dilihat pula bahwa besar nilai iterasi maksimum pada setiap varian menghasilkan nilai akurasi yang sama atau tidak mengalami perubahan.
mendapati hasil yang sama pula atau konvergen.
Gambar 6. Hasil Pengujian Parameter Iterasi Maksimum (Pakar 1)
Gambar 7. Hasil Pengujian Parameter Iterasi Maksimum (Pakar 2)
Dari keseluruhan pengujian parameter diatas dapat diketahui bahwa sistem memerlukan persentase cutting rate dan
compression rate sebesar 30%, serta nilai iterasi maksimum sebesar 10 kali iterasi untuk menghasilkan kalimat ringkasan dengan rata-rata nilai akurasi yang paling baik. Di mana rata-rata nilai akurasi precision, recall, dan
relative utility tersebut secara berurutan pada pakar pertama adalah bernilai 0,20, 0,47, 0,48 dan pada pakar kedua adalah bernilai 0,27, 0,43, 0,45.
Berkaitan dengan nilai akurasi yang cukup rendah tersebut, selain dikarenakan perbedaan
cara pemilihan kalimat ringkasan antara sistem dan pakar, hasil akurasi dari sistem memang terkadang didapati lebih cenderung bernilai rendah. Sebagai contoh dalam penelitian (Fhadli et al., 2017) yang menggunakan data teks dokumen yang sama dengan penulis, hanya saja menggunakan metode yang berbeda. Di mana penelitian tersebut menggunakan teknik klasifikasi algoritme Naïve Bayes, dengan 5 data uji atau menggunakan data ke-1 hingga 5 yang digunakan penulis dan didapati hasil rata-rata nilai akurasi f-measure dan relative utility
sebesar 0,21 dan 0,12 secara berurutan. Jika dibandingkan dengan hasil akurasi penelitian penulis pada pakar pertama, untuk f-measure
yang merupakan nilai tengah dari precision dan
recall atau yang dapat dihitung dengan cara 2 kali precision dan recall dibagi jumlah dari
precision dan recall didapati jumlah f-measure
sebesar 0,31, dan relative utility sebesar 0,45. Maka dapat dikatakan bahwa metode NGD dan
K-means menghasilkan ringkasan yang lebih baik dibandingkan dengan metode NaïveBayes. Lalu dengan besar parameter terbaik tersebut, dapat dilakukan pengujian kappa statistic dan didapatkan hasil yang dapat dilihat pada Tabel 3.
Tabel 3. Hasil Pengujian Kappa
Kappa Nilai
Maka dapat dikatakan bahwa tingkat persetujuan antara kedua pakar terhadap hasil ringkasan sistem adalah moderate atau dengan rata-rata kappa sebesar 0,41.
4. KESIMPULAN
Berdasarkan penelitian yang telah dilakukan, penulis dapat mengambil kesimpulan sebagai berikut:
1. Peringkasan teks ekstraktif kepustakaan ilmu komputer bahasa Indonesia menggunakan metode NGD dan K-means dapat diterapkan dengan cara
NGD yang digunakan sebagai
algoritme untuk medapatkan kalimat-kalimat yang berkaitan dengan judul
dari dokumen kepustakaan dan K-means yang digunakan sebagai algoritme untuk mendapatkan kalimat ringkasan yang berasal dari berbagai topik bahasan yang terkandung dalam data teks dokumen.
2. Hasil akurasi dari penelitian dapat diperoleh dengan melakukan pengujian terhadap parameter-parameter yang dibutuhkan, yaitu cutting rate,
compression rate, dan iterasi maksimum, serta dengan melakukan perhitungan akurasi precision, recall,
relative utility, dan kappa statistic
terhadap seluruh data teks dokumen yang digunakan. Di mana didapatkan hasil ringkasan terbaik dengan menggunakan persentase parameter
cutting rate dan compression rate
sebesar 30%, serta nilai iterasi maksimum sebesar 10, yang didapati rata-rata nilai akurasi precision, recall,
relative utility secara berurutan pada pakar pertama sebesar 0,20, 0,47, 0,48 dan pada pakar kedua sebesar 0,27, 0,43, 0,45. Serta mendapati nilai rata-rata kappa sebesar 0,41 atau moderate. Selain kesimpulan tersebut, dari penelitian ini didapati beberapa saran yang dapat digunakan untuk mengembangkan penelitian secara lebih lanjut yaitu penelitian dapat dikembangkan dengan menambahkan fitur statistik lain seperti letak kalimat dalam paragraf, letak tanda quote, karakter dengan
bold, italic atau juga dapat ditambahkan fitur semantik seperti lexicon atau fitur semantik lainnya.
5. DAFTAR PUSTAKA
Alguliev, R. and Aliguliyev, R., 2009. Evolutionary algorithm for extractive text summarization. Intelligent Information Management, 1(02), pp.128-138. Overview [Accessed 24 February 2017].
Bhole, P. & Agrawal, A.J., 2014. Single Document Text Summarization Using Clustering Approach Implementing for
News Article. International Journal of Engineering Trends and Technology, 15(7), pp.364-68.
Cilibrasi, R.L. and Vitanyi, P.M., 2007. The google similarity distance. IEEE Transactions on knowledge and data engineering, 19(3), pp.370-83.
Elfayoumy, S. and Thoppil, J., 2014. A survey of unstructured text summarization techniques. The International Journal of Advanced Computer Science and Applications, 5(7), pp.149-154.
Ferreira, R., de Souza Cabral, L., Lins, R.D., e Silva, G.P., Freitas, F., Cavalcanti, G.D., Lima, R., Simske, S.J. and Favaro, L., 2013. Assessing sentence scoring techniques for extractive text summarization. Expert systems with applications, 40(14), pp.5755-5764.
Fhadli, M., Fauzi, M., & Afirianto, T. Peringkasan Literatur Ilmu Komputer Bahasa Indonesia Berbasis Fitur Statistik dan Linguistik menggunakan Metode Gaussian Naïve Bayes. Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, vol. 1, no. 4, p. 307-319, mei 2017. ISSN 2548-964X. Tersedia pada: < http://j-
ptiik.ub.ac.id/index.php/j-ptiik/article/view/100>. Tanggal Akses: 07 juni 2017.
García-Hernández, R., Montiel, R., Ledeneva, Y., Rendón, E., Gelbukh, A. and Cruz, R., 2008. Text summarization by sentence extraction using unsupervised learning. MICAI 2008: Advances in Artificial Intelligence, pp.133-143. Jain, A.K., 2010. Data clustering: 50 years
beyond K-means. Pattern recognition letters, 31(8), pp.651-666.
Lloret, E., 2008. Text summarization: an overview. Paper supported by the Spanish Government under the project TEXT-MESS (TIN2006-15265-C06-01). Nenkova, A. and McKeown, K., 2011. Automatic summarization. Foundations
and Trends® in Information
Prabowo, D.A., Fhadli, M., Najib, M.A., Fauzi, H.A. and Cholissodin, I., 2016. TF-IDF-Enhanced Genetic Algorithm Untuk Extractive Automatic Text Summarization. Jurnal Teknologi Informasi dan Ilmu Komputer, 3(3), pp.208-215.
Steinberger, J. and Jezek, K., 2009. Evaluation
measures for text
summarization. Computing and Informatics, 28(2), pp.251-275.
Tala, F.Z., 2003. A study of stemming effects on information retrieval in Bahasa Indonesia. Institute for Logic,
Language and Computation,
Universiteit van Amsterdam, The Netherlands.