140
Algoritma Restricted Boltzmann Machines
(RBM) untuk Pengenalan Tulisan Tangan
Angka
Susilawati
Universitas Medan Area [email protected]
Abstrak
Pengenalan tulisan tangan angka telah dimanfaatkan secara luas untuk aplikasi yang memerlukan pemrosesan data tulisan tangan dengan jumlah yang besar seperti pengenalan alamat dan kode pos, interpretasi jumlah uang pada cek, analisis dokumen dan verifikasi tandatangan. Kasus pengenalan angka dalam jumlah besar membutuhkan pengenalan karakter dengan akurasi dan kecepatan tinggi. Banyak algoritma neural network yang dapat diimplementasikan untuk menyelesaikan permasalahan pengelanan pola seperti Restricted boltzmann machines (RBM). RBM merupakan algoritma pembelajaran jaringan syaraf tanpa pengawasan (unsupervised learning) yang hanya terdiri dari dua lapisan yang visible layer dan hidden layer. Penelitian ini membahas tentang pengenalan tulisan tangan angka dengan menggunakan algoritma RBM, dengan menggunakan dataset bencmark MNIST untuk pembelajaran dan pengujian. Terlihat bahwa tingkat keberhasilan untuk pengenalan tulisan tangan angka ditentukan oleh nilai Mean Square Error (MSE) yang kecil.
Keywords— Pengenalan pola, Tulisan Tangan Angka, Algoritma Restricted Boltzmann Machines (RBM).
I. LATARBELAKANG
Artificial Neural Network (ANN) telah banyak
dimanfaatkan sebagai solusi terhadap berbagai macam permasalahan yang sifatnya tidak tetap, yang sulit dipecahkan dengan menggunakan teknik pemrograman konvensional, diantaranya kasus pengenalan pola. Pengenalan pola tulisan tangan angka merupakan topik yang menarik dari pengenalan pola dan kecerdasan buatan (Liu Cheng-Lin,et all, 2004; Supriya Deshmukh, et all, 2009). Hal ini disebabkan oleh pengenalan tulisan tangan angka telah mendapatkan banyak perhatian
di bidang pengenalan pola karena penerapannya di berbagai bidang. Konversi karakter tulisan tangan angka sangat penting untuk membuat beberapa dokumen penting yang berkaitan dengan aktifitas manusia, ke dalam bentuk yang dapat dimanipulasi mesin sehingga dapat dengan mudah digunakan dan disimpan (Sampath Amritha, et all, 2012).
141 alamat dan kode pos, interpretasi jumlah uang
pada cek, analisis dokumen dan verifikasi tandatangan. Kasus pengenalan angka dalam jumlah besar yang membutuhkan pengenalan karakter dengan akurasi dan kecepatan tinggi, terakhir ditemukan pada kasus formulir C1 Komisi Pemilihan Umum (KPU) pada Pemilihan Umum di Indonesia.
Sebagai ujicoba database yang digunakan untuk penelitian ini adalah dataset MNIST. Dataset ini berisi referensi data tulisan tangan angka, yang terdiri dari 60000 data gambar untuk pelatihan dan 10000 data gambar untuk pengujian. Dataset ini dapat diimplementasikan untuk pengenalan angka tulisan tangan dengan menggunakan berbagai metode. B. El Kessab, et al, 2013, melakukan penelitian pengenalan angka tulisan tangan menggunakan jaringan saraf multilayer perceptron (MLP) dan metode ekstraksi ciri berdasarkan bentuk angka, Metode ini diuji pada database angka tulisan tangan MNIST dengan 60.000 gambar untuk pelatihan dan 10000 gambar untuk pengujian, dengan tingkat keberhasilan pengenalan mencapai sekitar 80% untuk identifikasi basis data MNIST.
Penelitian ini menggunakan algoritma
restricted boltzmann machine (RBM) neural
network, yang merupakan metode stochastic
neural network dengan arsitektur bersifat
recurrent network. Penggunaan algoritma ini
diharapkan dapat menghasilkan tingkat akurasi pengenalan angka tulisan tangan yang lebih baik, sekaligus mengetahui kinerja RBM untuk sistem pengenalan angka tulisan tangan.
II. TINJAUANPUSTAKA
A. Pengenalan tulisan tangan angka
Pengenalan tulisan tangan merupakan kemampuan komputer untuk menerima dan menafsirkan masukan tulisan tangan yang dimengerti dari suatu sumber seperti dokumen kertas, foto, layar sentuh dan perangkat lainnya.
Tahapan umum yang dilakukan pada sistem pengenalan tulisan tangan terdiri dari (Cheriet et all, 2007) tahap pertama Data acquisition /pemerolehan data yaitu tahap pemerolehan data dari sensor (misal pada kamera) yang digunakan untuk menangkap objek dari dunia nyata dan selanjutnya diubah menjadi sinyal digital (sinyal
yang terdiri dari sekumpulan bilangan) melalui proses digitalisasi. Terdapat dua metode utama yang digunakan untuk pengenalan tulisan (yang biasa disebut recognition system), yaitu pengenalan tulisan secara offline dan online. Pada sistem pengenalan tulisan online, inputan tulisan bersifat temporer diperoleh secara langsung dari alat input digital. Pada sistem pengenalan tulisan secara offline, input tulisan diperoleh dari teks tulisan yang di-scan terlebih dahulu atau dari kamera. Tahap kedua Data preprocessin pemrosesan awal data yaitu informasi dari citra angka, noise dan kompleksitas diminimalisasi, ukuran dan bentuk huruf dinormalisasikan agar memudahkan untuk pemrosesan berikutnya. Tahap ketiga Feature extraction yaitu pada bagian ini dilakukan untuk mendapatkan karakteristik pembeda yang mewakili sifat utama dengan memisahkannya dari fitur yang tidak diperlukan, dan mengurangi kerumitan komputasi serta memungkinkan untuk meningkatkan akurasi. Tahapan terakhir adalah pengenalan data. Tahapan ini dilakukan proses pembelajaran data dan pengujian data untuk mengetahui tingkat keberhasilan algoritma pengenalan pola yang digunakan.
B. Restricted Boltzmann Machine (RBM)
Restricted Boltzmann Machine (RBM)
merupakan aturan pembelajaran dengan menggunakan metode Boltzmann Machine (Hinton et all, 2010). RBM merupakan model generatif probabilistik yang mampu secara otomatis mengekstrak fitur input data dengan menggunakan algoritma pembelajaran tanpa pengawasan (Hinton, 2002; Smolensky, 1986). RBM menggunakan arsitektur jaringan berulang
(recurrent network). Secara teknis, RBM
merupakan jaringan saraf yang bersifat stochastic
(jaringan saraf yang berarti memiliki unit neuron berupa aktivasi biner yang bergantung pada neuron-neuron yang saling terhubung, sedangkan
stochastic berarti aktivasi yang memiliki unsur
probabilistik) yang terdiri dari dua binary unit yaitu visible layer merupakan state yang akan diobservasi dan hidden layer merupakan feature
detectors serta unit bias. Selanjutnya
masing-masing visible unit terhubung ke semua hidden
142 unit dan unit bias terhubung ke semua visible unit
dan semua hidden unit. Untuk memudahkan proses pembelajaran, jaringan dibatasi sehingga tidak ada visible unit terhubung ke visible unit lain
dan hidden unit terhubung dengan hidden unit
lainnya.
Untuk melatih RBM, sampel dari training set
yang digunakan sebagai masukan untuk RBM melalui neuron visible, dan kemudian jaringan sampel bolak-balik antara neuron visible dan
hidden. Tujuan dari pelatihan adalah untuk
pembelajaran koneksi bobot pada visible atau
hidden dan bias aktivasi neuron sehingga RBM
belajar untuk merekonstruksi data input selama fase di mana sampel neuron visible dari neuron hidden. Setiap proses sampling pada dasarnya berupa perkalian matriks-matriks antara sekumpulan sampel pelatihan dan matriks bobot, diikuti dengan fungsi aktivasi neuron, yaitu fungsi sigmoid (persamaan 2.12). Sampling antara lapisan hidden dan visible diikuti oleh modifikasi parameter (dikontrol oleh learning rate) Dan diulang untuk setiap kelompok data dalam training set, dan untuk state sebanyak yang diperlukan
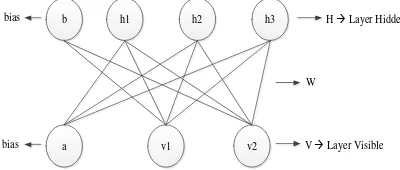
Gambar 1. Arsitektur Rectricted Boltzmann Machine Network
Arsitektur neural network RBM dapat dilihat pada gambar 1 Jaringan ini terdiri atas 2 (dua) unit neuron pada lapisan visible unit (v1, v2,.., vn), 3
(tiga) neuron pada lapisan hidden unit (h1, h2, h3,..,
hn) dan 1 (satu) neuron bias pada lapisan visible
dan 1 (satu) neuron bias pada lapisan hidden. Konfigurasi unit visible (V) dan unit hidden (H) memiliki energi (Hopfiled, 1982) ditunjukkan pada persamaan berikut :
( ) ∑ ∑ ∑
Unit hidden diinisialisasi dan diperbarui menggunakan persamaan berikut, di mana Hj dari
setiap unit hidden j diatur satu dengan probabilitas:
( | ) ( ∑ (2.2)
Di mana ( ) adalah fungsi sigmoid
( ) ( ) (2.3) Unit visible diinisialisasi dan diperbarui menggunakan persamaan berikut, di mana Vi dari
setiap unit hidden i diatur satu dengan probabilitas:
( | ) ( ∑ ( )T (2.4)
C. Algoritma Restricted Boltzmann Machines
Algoritma RBM sebagai berikut: a. Inisialisasi data
1. Inisialisasi bobot awal (weights) dan bias dengan nilai random yang kecil. 2. Tetapkan maksimum Epoch, dan
sampel dari hidden unit)
1. Hitunglah energi aktivasi, probabilitas dan state dari unit hidden (i) dengan menggunakan persamaan 2.2
2. Hitung positif_assosiatif
( ) * P(Hj) (2.5)
Positif assosiatif diperoleh dari perkalian matriks data sampel yang ditranspose dari visible neuron dengan probabilitas yang dihasilkan dari langkah 5
143 1. Hitung energi aktivasi dan
probabilitas dari unit visible (j) dengan menggunakan persamaan 2.4 2. Lakukan langkah 5 untuk update
hidden unit
3. Hitung negatif_assosiatif
( ) * P(Hj) (2.6)
Negatif assosiatif diperoleh dari perkalian matriks data (probabilitas dari unit visible yang diperoleh dari langkah 7) yang ditranspose dengan probabilitas dari unit hidden yang dihasilkan dari langkah 8
d. Update parameter 2. Update bobot
Wij =
Wij +
Δwjk
(2.7)
ΔWij = ε
(Pos_Asso –
Neg_Asso)
(2.8)
Di mana ε adalah learning rate
3. Hitung error
Error = ∑ ( )2
(2.9)
Error dihitung dengan pengurangan Oi merupakan data sampel dan ti
merupakan visibel probabiltas yang dihasilkan dari pase negatif pada langkah 7
III.HASIL DAN PEMBAHASAN
a. Hasil
Proses pembelajaran RBM merupakan pembelajaran tanpa pengawasan (unsupervised
learning), artinya tidak ada target data saat proses
pembelajaran dilakukan. Hasil pembelajaran akan berkelompok sesuai klasifikasi masing-masing data. Output aktual yang dihasilkan pada awal proses akan digunakan sebagai input pada proses berikutnya. Kesalahan (error) pada output jaringan diperoleh dari selisih antara output pada pase
positif dan ouput pada pase negatif. Epoch diperlukan sebagai batasan untuk proses pembelajaran. Untuk tahap pembelajaran, parameter yang akan diuji adalah learning rate
0.01, 0.05, 0.09 dan momentum 0.5, 0.7, 0.9, dengan fungsi aktivasi sigmoid tangen serta pembatasan epoch sebanyak 100 epoch.
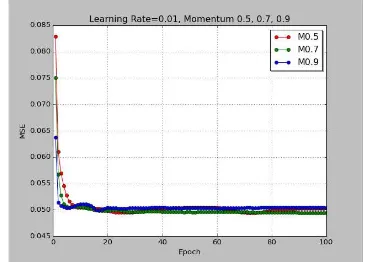
Hasil pembelajaran dapat dilihat pada gambar 2 berikut ini :
Gambar 2. Pembelajaran I dengan (ε) =0.01, (m)=0.5, 0.7, 0.9
Gambar 3. Pembelajaran II dengan (ε) =0.05, (m)=0.5, 0.7,
0.9
Gambar 4. Pembelajaran II dengan (ε) =0.09, (m)=0.5, 0.7,
144 Hasil MSE dapat disimpulkan seperti pada tabel 1
berikut ini :
Tabel 1. Hasil MSE dari tahapan pembelajaran
Nilai MSE menaik seiring menaiknya jumlah epoch. Nilai MSE yang cenderung menurun hingga akhir epoch akan menghasilkan visualisasi klasifikasi tulisan tangan yang jelas. Hasil visualisasi klasifikasi angka tulisan tangan ini dapat dilihat lebih jelas pada bagian pembahasan di bab ini.
Parameter learning rate dan momentum yang menghasilkan nilai MSE yang terkecil adalah learning 0.01 dengan momentum 0.9 dan learning 0.05 dengan momentum 0.5, 0.7. Visualisasi klasifikasi dataset dari pilihan nilai-nilai parameter tersebut menunjukkan hasil yang baik dan jelas. Nilai-nilai dari parameter ini akan digunakan untuk proses pengujian terhadap data pengujian MNIST untuk mengetahui tingkat persentase pengenalan data pengujian MNIST.
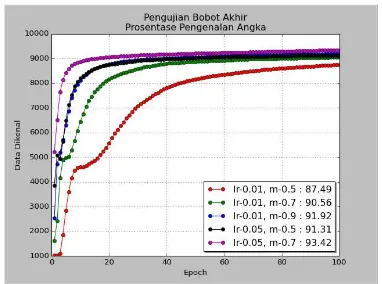
Hasil pengujian bobot akhir dan persentase pengenalan data MNIST dapat dilihat pada gambar 5 dan table 2 berikut ini.
Gambar 5. Grafik persentase pengenalan dataset
Tabel 2. Persentasi pengenalan dataset pengujian
Learning Rate
(ε) Momentum (m)
Persentasi (%)
0.01 0.9 91.92 0.05 0.5 91.31 0.7 93.42
Pada gambar 4 dan tabel 2 terlihat bahwa parameter learning rate 0.01 dengan momentum 0.9 berwarna biru memperoleh tingkat pengenalan sebesar 91.92%, sedangkan learning rate 0.05 dengan momentum 0.5 berwarna hitam memperoleh tingkat penganalan 91.31% serta learning rate 0.05 dengan momentum 0.7 memiliki kinerja yang paling tinggi, mampu mengenali dataset pengujian sebesar 93.42%.
IV.PEMBAHASAN
A. Data Yang Digunakan
Penelitian ini meggunakan dataset MNIST dari UCI Machine learning repository (http://archive.ics.uci.edu/ml). Dataset MNIST dibangun oleh Institute National Standard Technologi (NIST). Dataset ini berisi tulisan tangan berupa angka dari 0 sampai 9 dalam bentuk file gambar. Data pelatihan NIST awalnya disusun dari kumpulan angka yang ditulis oleh pekerja sensus di Amerika Serikat, sedangkan data pengujiannya diperoleh dengan mengumpulkan data tulisan tangan siswa Sekolah Menengah Atas di Amerika Serikat. Perbedaan asal tulisan ini berakibat pada sulitnya mengklasifikasi tulisan yang digunakan untuk pengujian. Disebabkan alasan tersebut, dibentuklah organisasi yang bertugas mengabungkan kedua data tersebut menjadi satu kesatuan yang disebut dengan Modified Institute National Standar and Technology yang disingkat dengan MNIST (Le Cun et al., 1998).
145
Tabel 3. Distribusi Dataset MNIST
Gambar 3 berikut merupakan visualisasi dataset MNIST sebanyak 600 sample data dari 60000 data tulisan tangan untuk pembelajaran. Gambar 3.6 merupakan visualisasi 600 sample data dari 10000 data tulisan tangan untuk pengujian. Dimana, data tersebut terdiri dari angka 0 sampai 9 dengan karakteristik yang berbeda-beda, ada data yang tampak lebih tebal dan ada yang tampak lebih tipis selain itu ada pula data yang tampak dengan jelas dan ada yang tampak tidak jelas.
Gambar 6. Sample Data Pembelajaran 600 dari 60000 Tulisan
Tangan
Gambar 7. Sample Data Pengujian 600 dari 60000 Tulisan
Tangan
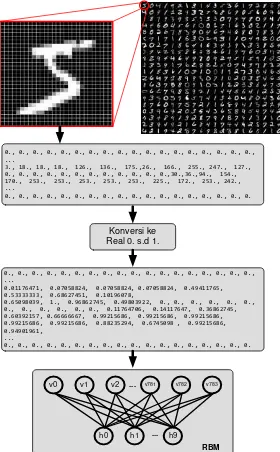
Dan gambar 6 berikut merupakan bentuk format file image dan file label dari dataset MNIST. File image terdapat magic number yang digunakan untuk pengenal dari masing-masing file, gambar yang berisi 60000 gambar tulisan tangan angka dimana, gambar tersebut terpusat pada 28 kolom dan 28 baris pixel gambar serta pixel gambar yang dibaca perbaris. File label terdapat magic number dan label sebanyak 60000 serta label dari masing-masing data.
Magic number Gambar = 60000 Baris = 28 Kolom = 28
28
28
FORMAT FILE IMAGE MNIST - PEMBELAJARAN
FORMAT FILE LABEL MNIST - PEMBELAJARAN
Magic number Label = 60000
Gambar 8. Format file image dan file label Dataset MNIST
Setiap pixel gambar diwakili oleh nilai antara 0 sampai 255, di mana 0 adalah hitam, 255 adalah putih, serta warna keabuan dari piksel. Ukuran gambar terpusat pada 28 x 28 piksel. Dimana pembacaan piksel gambar dilakukan secara perbaris. Data pada masing-masing piksel selanjutnya dibagi dengan angka 255 untuk memperoleh bilangan real antara 0 sampai 1. Data real ini selanjutnya dijadikan data masukan pada pembelajaran RBM yang diwakilkan pada lapisan terlihat (visible layer), kemudian digunakan untuk menginisialisasi nilai pada node yang ada pada lapisan tersembunyi (hidden layer). Adapun tahapan pembacaan data tersebut dapat dilihat pada gambar 3.8 berikut.
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., ...
3., 18., 18., 18., 126., 136., 175.,26., 166., 255., 247., 127., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,30.,36.,94., 154., 170., 253., 253., 253., 253., 253., 225., 172., 253., 242., ...
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., ...
0.01176471, 0.07058824, 0.07058824, 0.07058824, 0.49411765, 0.53333333, 0.68627451, 0.10196078,
0.65098039, 1., 0.96862745, 0.49803922, 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.11764706, 0.14117647, 0.36862745, 0.60392157, 0.66666667, 0.99215686, 0.99215686, 0.99215686, 0.99215686, 0.99215686, 0.88235294, 0.6745098 , 0.99215686, 0.94901961,
...
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.
Konversi ke Real 0. s.d 1.
v0 v1 v2 ... v781 v782 v783
h0 h1 ... h9
RBM
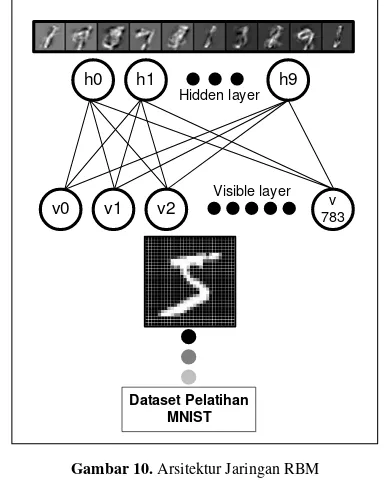
146 B. Pembelajaran
Proses pembelajaran dilakukan dengan menggunakan algoritma jaringan RBM tanpa menyertakan file label sebagai target. Untuk tahap pembelajaran, parameter yang akan diuji adalah
learning rate 0.01, 0.05, 0.09 dan momentum 0.5,
0.7, 0.9, dengan fungsi aktivasi sigmoid dan pembatasan epoch sebanyak 100 epoch. Pembelajaran dilakukan dengan membangun jaringan RBM yang terdiri dari 784 neuron visible
layer dan 10 neuron pada hidden layer. Jumlah
neuron pada visible layer sebesar 784 neuron dihitung berdasarkan resolusi masing-masing angka dataset yakni 28x28, dan 10 neuron pada
hidden layer berdasarkan jumlah klasifikasi angka
0 sampai 9.
v0 v
783
v2 v1
h0 h1 h9
Dataset Pelatihan MNIST
Visible layer Hidden layer
Gambar 10. Arsitektur Jaringan RBM
1. Pembelajaran Tahap I
Pada pembelajaran tahap pertama hasil nilai MSE yang diperoleh untuk nilai Learning Rate 0.01, momentum 0.5, 0.7, 0.9 dapat dilihat pada tabel 3 berikut ini.
Tabel 3. Nilai MSE Learning Rate 0.01,
Momentum 0.5, 0.7, 0.9
Dari tabel 3 terlihat bahwa untuk learning rate
0.01 dengan momentum 0.5 nilai MSE terkecil diperoleh pada epoch ke-72 sebesar 0.0493. Diikuti dengan momentum 0.7 pada epoch ke-95 sebesar 0.0494 dan momentum 0.9 pada epoch ke-26 sebesar 0.0499.
2. Pembelajaran Tahap II
Pada pembelajaran tahap kedua hasil nilai MSE yang diperoleh untuk nilai Learning Rate 0.05, momentum 0.5, 0.7, 0.9 dapat dilihat pada tabel 3.3 berikut ini.
Tabel 4. Nilai MSE Learning Rate 0.05,
Momentum 0.5, 0.7, 0.9
147 3. Pembelajaran Tahap III
Pada pembelajaran tahap ketiga hasil nilai MSE yang diperoleh untuk nilai Learning Rate 0.09, momentum 0.5, 0.7, 0.9 dapat dilihat pada tabel 5 berikut ini.
Tabel 5. Nilai MSE Learning Rate 0.05,
Momentum 0.5, 0.7, 0.9
Dari tabel 5 terlihat bahwa learning rate
0.09 dengan momentum 0.5 nilai MSE terkecil diperoleh pada epoch ke-8 sebesar 0.0485, sedangkan momentum 0.7 pada epoch ke-3 sebesar 0.0492 dan momentum 0.9 pada epoch ke-47 sebesar 0.0512.
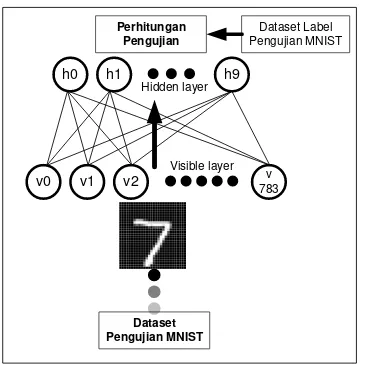
V. PENGUJIAN
Pengujian dilakukan dengan membangun jaringan RBM yang terdiri dari 784 neuron visible
layer dan 10 neuron pada hidden layer, dengan
arsitektur seperti terlihat pada gambar 3.9 Proses pengujian dilakukan dengan cara memasukkan nilai-nilai bobot akhir yang akan diuji ke dalam jaringan RBM, dilanjutkan dengan memberi masukan dataset pengujian sebanyak 10000 data angka tulisan tangan. Pada proses pengujian, jaringan RBM hanya memproses dari visible layer ke hidden layer (phase positif) saja. Hasil perhitungan pada hidden layer selanjutnya dihitung dan diklasifikasikan berdasarkan data label MNIST untuk memperoleh score pengenalan angka tulisan tangan.
v0 v
783
v2 v1
h0 h1 h9
Dataset Pengujian MNIST
Visible layer Hidden layer
Perhitungan Pengujian
Dataset Label Pengujian MNIST
Gambar 11. Arsitektur Pengujian Dataset MNIST
Pengujian dilakukan dengan cara mengisi langsung semua variabel-variabel bobot pada jaringan RBM dengan nilai bobot terakhir dari proses pembelajaran yang telah disimpan sebelumnya. Pengambilan nilai-nilai bobot akhir dari file ini sangat menghemat waktu pembelajaran sehingga tidak diperlukan pembelajaran ulang jaringan.
Pengujian dimulai dengan membaca file-file bobot setiap epoch untuk learning rate 0.01 dengan momentum 0.9. Hasil perhitungan pengenalan angka tulisan tangan setiap epoch
disimpan untuk keperluan analisa selanjutnya. Pengujian yang sama dilanjutkan untuk learning rate 0.05 dengan momentum 0.5 dan 0.7. Hasil lengkap pengujian dapat dilihat pada tabel 6 dan 7. Isi tabel berupa jumlah data angka tulisan tangan yang cocok dibandingkan dengan label dataset pada data pengujian.
Tabel 6. Nilai MSE Learning Rate 0.01,
148
Tabel 7. Nilai MSE Learning Rate 0.05,
Momentum 0.5, 0.7
VI.KESIMPULAN
Penentuan nilai parameter learning rate, momentum dan fungsi aktivasi pada jaringan RBM sangat berpengaruh pada kinerja RBM, khususnya dalam menentukan nilai mean square
error (MSE) dan persentase pengenalan dataset
tulisan tangan angka MNIST. Dari hasil pembahasan terlihat bahwa learning rate 0.05 dengan momentum 0.7 memiliki kinerja yang paling tinggi, mampu mengenali dataset pengujian sebesar 93.42%.
DAFTARPUSTAKA
[1] Amritha, Sampath., Tripti, C. & Govindaru, V. 2012. Freeman code based online handwritten character recognition for Malayalam using Back propagation neural networks. Advance computing: An international journal3 (4): pp. 51-58
[2] C.-L. Liu, K. Nakashima, H. Sako, H. Fujisawa. 2004. Handwritten digit recognition: investigation of normalization and feature extraction techniques, Pattern Recognition, 37(2): 265-279
[3] Deshmukh, Supriya. & Ragha, Leena. 2009. Analysis of Directional Features - Stroke and Contour for Handwritten Character Recognition. IEEE International Advance Computing Conference: pp.1114-1118 [4] Hinton, Geoffrey. 2010. A Practical Guide to Training
Restricted Boltzmann Machines. University of Toronto. [5] Hinton. E. G, Osindero. S, dan Teh. W. Y (2006). A fast
learning algorithm for deep belief nets. Neural Computation, 18(7):1527–1554.
[6] Hinton. E. G (2002). Training products of experts by minimizing contrastive divergence, Neural Computation, vol. 14, pp. 1771–1800.
[7] LeCun, Yann. & Corinna Cortes. 2010. The MNIST Database of Handwritten Digits. Web. <http://yann.lecun.com/exdb/mnist/>.
[8] Salakhutdinov. R, dan Hinton. E. G (2008). Using deep belief nets to learn covariance kernels for Gaussian processes, Advances in Neural Information Processing Systems 20 (NIPS’07): pp. 1249–1256.
[9] Sharma, Om Prakash., Ghose M. K. & Shah, Krishna Bikram. 2012. An Improved Zone Based Hybrid Feature
Extraction Model for Handwritten Alphabets Recognition Using Euler Number. International Journal of Soft Computing and Engineering2 (2) : 504-58 [10] Smolensky. P (1986). Information processing in