Rancang Bangun Sistem Pengelolaan Data Kuesioner Kualitas
Pelayanan dan Kepuasan Pengguna Menggunakan Text Mining
(Studi Kasus: BAAK PCR)
Wendyanto
1), Maksum Ro
’
is Adin Saf
2)dan Muhammad Ihsan Zul
3)1) Jurusan Sistem Informasi, Politeknik Caltex Riau, Pekanbaru 28265, email: [email protected]
2) Jurusan Teknik Informatika, Politeknik Caltex Riau, Pekanbaru 28265, email: [email protected] 3) Jurusan Teknik Informatika, Politeknik Caltex Riau, Pekanbaru 28265, email: [email protected]
Abstrak – Salah satu kegiatan yang dilakukan di Biro Administrasi Akademik dan Kemahasiswaan (BAAK)
Politeknik Caltex Riau (PCR) adalah evaluasi pelayanan yang diberikan kepada mahasiswa. Proses ini masih dilakukan dengan cara manual, pengguna mengisi kuesioner dan memasukkan ke kotak saran. Cara seperti ini membuat BAAK dan pimpinan membutuhkan proses yang panjang untuk melihat pelayanan yang telah diberikan dan kepuasan pengguna. Untuk melihat kualitas pelayanan dengan cara ini dapat menghasilkan penilaian yang subjektif. Untuk itu, dibangun sistem untuk membantu mengolah data penilaian untuk melihat kualitas pelayanan dan melihat kepuasan pengguna. Data penilaian akan diolah menggunakan sistem. Sistem yang dibangun menerapkan Text Mining untuk mengolah data penilaian dan Naïve Bayes untuk melakukan pengklasifikasian kualitas pelayanan. Kepuasan pengguna didapatkan dengan cara membandingkan kualitas dan harapan. Dengan Frequent Itemset Mining 3 menunjukkan Naive Bayes menghasilkan akurasi 80%.
Kata Kunci : Kuesioner, Text Mining, Naïve Bayes, Penilaian, Kualitas Pelayanan, Kepuasan Pengguna, BAAK
Abstract - Activities in Biro Administrasi Akademik dan Kemahasiswaan (BAAK) Politeknik Caltex Riau (PCR)
is the evaluation of the services provided to user. This process is still done conventionally, then BAAK and managements requires a long process to see the services given and user satisfaction. To see the quality of service in this way can result in subjective assessments. Therefore, it needs to create a system that helps to process the data in order to see the result of quality of service and user satisfaction. Assessment data will be processed using the system. The system built to apply Text Mining for processing data assessment and Naïve Bayes to classify the quality of service. This user satisfaction can be done by compare the quality and expectation. With Frequent Itemset Mining 3 shows 80% accuracy Naive Bayes.
Keywords: Questioner, Text Mining, Naïve Bayes, Assessment, Quality of Service, User Satisfaction, BAAK
1. PENDAHULUAN
Biro Administrasi Akademik dan Kemahasiswaan (BAAK) Politeknik Caltex Riau mempunyai fungsi memberikan layanan dalam bidang administrasi akademik, kemahasiswaan, perencanaan dan sistem informasi dilingkungan kampus Politeknik Caltex Riau. Pelayanan kepada mahasiswa yang berhubungan dengan administratif baik akademik maupun kemahasiswaan dilaksanakan secara terpusat melalui BAAK.
Terdapat 4 loket yang tersedia untuk melayani kebutuhan pengguna. Pengguna dapat memberikan penilaian dan saran dikertas kemudian dimasukkan kedalam kotak yang tersedia. Kertas akan dikumpulkan oleh pihak BAAK dan diberikan kepada pimpinan untuk evaluasi. Evaluasi terhadap BAAK ini dilakukan oleh Pembantu Direktur 1 Bagian Akademik dan
Kemahasiswaan selaku pimpinan. Pimpinan akan membaca penilaian dan saran untuk melihat kualitas pelayanan yang diberikan oleh
2. REVIEW PENELITIAN TERDAHULU
Penelitian yang dilakukan oleh [2] melakukan analisis terkait kualitas pelayanan dari 3 provider, yaitu telkomsel, xl dan indosat. Data-data yang digunakan untuk penelitian ini berasal dari akun twitter masing-masing perusahaan provider. Data twitter dihitung berdasarkan label positif dan negatif berdasarkan words dictionary yang telah dibuat tanpa membersihkan data. Naïve Bayes digunakan sebagai metode klasifikasi. Hasilnya ditampilkan dengan skor positif dan negatif tiap akun provider.
Penelitian berikutnya yang dilakukan oleh [3], data yang digunakan adalah judul proyek akhir. Dibutuhkan proses dan waktu untuk mengelola judul Proyek Akhir (PA). Text mining menggunakan algoritma k-Nearest Neighbor (k-NN) dan Cosine Similarity untuk pengecekan kemiripan judul baru yang dimasukan mahasiswa dengan judul-judul yang sudah pernah ada sebelumnya. Penelitian ini menghasilkan kategori kurikulum berbasis kompetensi yang ada di program studi PCR.
Selanjutnya penelitian yang dilakukan oleh [4], data yang digunakan adalah judul proyek akhir. Pemilihan dosen pembimbing dan dosen penguji masih menggunakan cara manual dan tidak sesuainya dosen pembimbing dan dosen penguji dengan judul PA. Text Mining digunakan untuk menganalisa data yang didapat dari judul PA. Teknik klasifikasi menggunakan k-Nearest Neighbor (k-NN) dan Simple Additive Weighting untuk melakukan pembobotan kriteria dosen. Hasil penelitian ini merekomendasikan 5 nama dosen yang memiliki bobot tertinggi untuk menjadi pembimbing dan penguji PA berdasarkan KBK judul mahasiswa.
Pada penelitian ini dibangun sistem pengolahan data kuesioner terkait kualitas pelayanan dan kepuasan secara otomatis. Proses preprocessing dilakukan untuk mengurangi noise pada data. Frequent itemset mining digunakan untuk mendapatkan atribut yang sesuai sebagai data training dan metode klasifikasi text mining adalah Naïve Bayes. Hasil dari penelitian menampilkan kategori kepuasan dan kualitas pelayanan serta visualisasi data berupa grafik. Perbedaan penelitian ini dengan penelitian sebelumnya dapat dilihat dari segi objek, metode, tahap preprocessing dan hasil.
3. METODOLOGI PENELITIAN
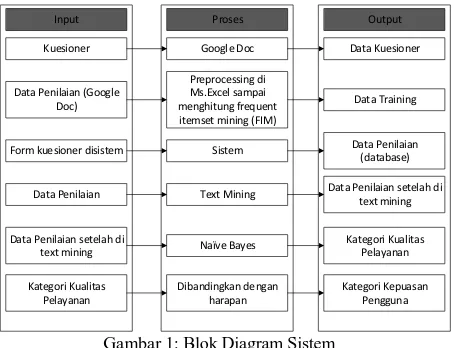
3.1. Blok Diagram Sistem
Gambar 1 menampilkan blok diagram sistem dimulai dari tahap pengumpulan data yang akan digunakan sampai pengolahan data secara otomatis menggunakan sistem.
Form kuesioner disistem Sistem Data Penilaian (database)
Data Penilaian Text Mining Data Penilaian setelah di text mining
Data Penilaian setelah di
text mining Naïve Bayes
Gambar 1: Blok Diagram Sistem
3.2. Gambaran Umum Sistem
Sumber data teks yang akan diolah pada penelitian ini dikumpulkan dengan menyebarkan kuesioner menggunakan Google Docs dan kertas kuesioner yang disebarkan ke mahasiswa Politeknik Caltex Riau. Data yang disebarkan diisi oleh 50 responden. Data yang terkumpul diolah secara manual dengan Microsoft Excel dengan melakukan preprocessing data dan menghitung frequent itemset untuk mendapatkan atribut setiap kategori yang akan digunakan sebagai data training. Frequent itemset adalah frequent patterns yang merupakan pola yang sering muncul dari suatu kumpulan data [5].
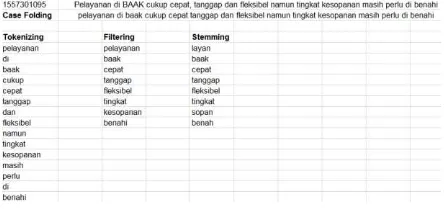
Sistem yang dibangun mempunyai menu untuk pengisian kuesioner. Pengguna akan mengisi kuesioner untuk memberikan penilaian dan tersimpan pada database. Proses preprocessing data penilaian menggunakan text mining. Text mining adalah proses menggali informasi dimana pengguna berinteraksi dengan dokumen–dokumen menggunakan tools analisis [6]. Preprocessing data yang dilakukan dengan case folding, tokenizing, filtering dan stemming dapat dilihat pada Gambar 2
Gambar 2: Pengklasifikasian Kualitas Pelayanan
Naïve bayes akan mengklasifikasikan data penilaian ke dalam kategori kualitas pelayanan. Naïve bayes adalah sebuah metode pengklasifikasian statistik yang bisa digunakan untuk memprediksi probabilitas keanggotaan suatu class [7]. Rumus Naïve Bayes bisa dilihat pada persamaan 1
Keterangan:
X = data dengan class yang belum di ketahui H = hipotesis data X merupakan suatu class
spesifik
|
= probabilitas hipotesis H berdasarkan kondisi X (posteriori probability) = probabilitas hipotesis H (prior probability)|
= probabilitas X berdasarkan kondisi pada hipotesis H= probabilitas dari X
Kualitas pelayanan akan dibandingkan dengan harapan pengguna untuk melihat kepuasan pengguna. Evaluasi pada sistem menggunakan confusion matrix dan k-fold cross validation untuk melihat akurasi. Confusion matrix adalah alat yang berguna untuk menganalisis seberapa baik classifier mengenali tuple dari kelas yang berbeda [5]. K-Fold Cross Validation membagi dataset menjadi sejumlah k partisi secara acak [8].
4. HASIL PENELITIAN
4.1. Data Kuesioner
Gambar 3 menampilkan contoh data yang sudah terkumpul dengan menggunakan Google Docs dan kertas kuesioner. Data ini terkumpul sebanyak 50, kemudian dikelompokkan ke setiap kategori sebanyak 10 data. Data yang sudah dikelompokkan ini kemudian dilakukan preprocessing data.
Gambar 3: Data Kuesioner
4.2. Preprocessing
Ini adalah salah satu contoh proses preprocessing data yang dilakukan dengan cara melakukan case folding, tokenizing, filtering dan stemming. Contoh data yang dipreprocessing dapat dilihat pada Gambar 4
Gambar 4: Preprocessing Data Training
4.3. F requent Itemset Mining
Gambar 5 menampilkan data yang sudah selesai dipreprocessing. Setelah semua data dilakukan preprocessing, maka dilakukan proses frequent itemset mining untuk menghitung frekuensi kemunculan kata pada setiap kategori. Proses frequent itemset dapat dilihat pada Gambar 6
Gambar 5: Data Setelah Preprocessing
Gambar 6: Proses Frequent Itemset Mining
4.4. Implementasi
Gambar 7: Halaman Pengguna
Gambar 8 menampilkan halaman untuk mengolah data kuesioner yang sudah dikumpulkan. Proses pengolahan ini dilakukan secara otomatis dengan menggunakan sistem oleh pegawai BAAK.
Gambar 8: Halaman BAAK
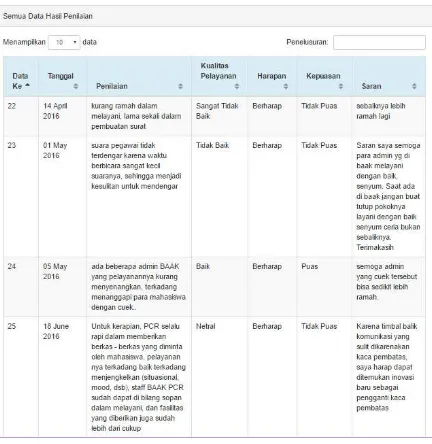
Gambar 9 menampilkan hasil penilaian yang sudah diolah dengan menggunakan sistem dan ditampilkan dihalaman pimpinan.
Gambar 9: Halaman Pimpinan
4.5. Pengujian
4.5.1 Akurasi Naïve Bayes
Data yang sudah dikumpulkan kemudian diujikan untuk setiap kemungkinan frequent item. Pengujian ini menghasilkan akurasi dari klasifikasi data dapat dilihat pada Tabel 1
Tabel 1. Akurasi Na ïve Ba yes
Frequent Itemset Mining Akurasi
2 86%
3 80%
4 66%
4.5.2 K-Fold Cross Validation
Setelah pengujian akurasi naïve bayes, dilakukan proses pengujian kedua dengan k-fold cross validation pada setiap frequent itemset dan nilai k. Pada frequent itemset 2 setelah dilakukan proses k-fold didapatkan nilai k terbaik pada k-5 sebesar 44% dan k-10 sebesar 44%. Tetapi pada frequent itemset 3 yang akurasi naïve bayesnya lebih rendah dari pada frequent itemset 2, didapatkan nilai k yang lebih baik. Pada nilai k-5 sebesar 54%. Tabel 2 menampilkan hasil pengujian k-fold cross validation.
Tabel 2. K-Fold Cross Validation
Frequent Itemset Mining
2 3
K-Fold Cross Validation
2 30% 46%
3 34% 36%
4 34% 42%
5 44% 54%
6 38% 50%
7 40% 46%
8 40% 46%
9 42% 50%
10 44% 48%
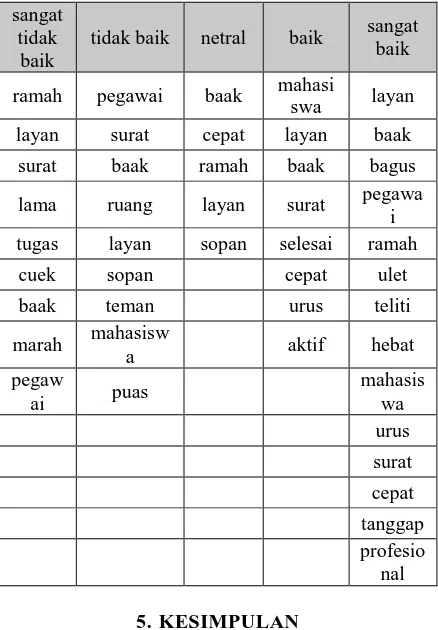
4.5.2 Atribut Data Training
Tabel 3. Atribut Data Training
sangat tidak
baik
tidak baik netral baik sangat baik
ramah pegawai baak mahasi
swa layan
layan surat cepat layan baak
surat baak ramah baak bagus
lama ruang layan surat pegawa
i
tugas layan sopan selesai ramah
cuek sopan cepat ulet
baak teman urus teliti
marah mahasisw
a aktif hebat
pegaw
ai puas
mahasis wa urus
surat
cepat
tanggap profesio
nal
5. KESIMPULAN
Setelah dilakukan implementasi, pengujian berserta analisis pada proyek akhir ini, dapat diambil kesimpulan bahwa sistem ini berhasil melakukan klasifikasi kualitas pelayanan dan kepuasan pengguna. Hasil akurasi yang didapatkan sebesar 80% pada frequent itemset 3. Sehingga pimpinan dapat melihat kualitas pelayanan dan kepuasan pengguna secara lebih cepat karena proses pengolahan data dilakukan secara otomatis dan lebih objektif.
Adapun saran yang dapat diberikan adalah preprocessing sebaiknya dilakukan dengan menambahkan tahap convert negation yang membantu menemukan kata negasi dan membantu perhitungan pada proses klasifikasi dan sistem dapat dikembangkan untuk melihat kualitas pelayanan yang diberikan oleh setiap pegawai. Karena pada sistem ini hanya menghasilkan tingkat kualitas pelayanan secara keseluruhan.
DAFTAR REFERENSI
[1] Kamus Besar Bahasa Indonesia. (n.d.). Retrieved from kbbi.web.id
[2] Calvin (2013). Using Text Mining to Analyze Mobile Phone Provider Service Quality (Case Study: Social Media Twitter).
International Journal of Machine Learning and Computing. 4, 106-109.
[3] Yuliana. (2014). Sistem Pengelolaan Proyek Akhir Menggunakan Text Mining Pada Politeknik Caltex Riau. Tugas Akhir Program D4 Politeknik Caltex Riau. Pekanbaru: Riau.
[4] Gunawan (2015). Sistem Pendukung Keputusan Pemilihan Pembimbing dan Penguji Proyek Akhir di Politeknik Caltex Riau.
3rd Applied Business and Engineering Conference.
[5] Han, Jiawei., Kamber, Micheline., & Pei, Jian. (2012). Data
Mining Concepts and Techniques (3rd ed.). USA : Simon Frase
University.
[6] Feldman, Ronen dan Sanger, James. (2007). The Text Mining
Handbook Advanced Approaches in Analyzing Unstructured Data. New York: Cambridge University Press.
[7] Wu, dkk, (2007). Top 10 Algorithm in Data Mining. Survey Paper-Springer Verlag London Limited.
[8] Hastie, T., Tibshirani, R., Friedman, J. (2011). The elements of statistical learning: Data mining, inference, and prediction (2nded.).