SUBWORD EMBEDDING DENGAN PENDEKATAN BYTE PAIR ENCODING DAN MORFOLOGI
BAHASA INDONESIA
DISERTASI
AMALIA 178123001
PROGRAM STUDI DOKTOR (S-3) ILMU KOMPUTER FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA MEDAN
2021
SUBWORD EMBEDDING DENGAN PENDEKATAN BYTE PAIR ENCODING DAN MORFOLOGI
BAHASA INDONESIA
DISERTASI
Diajukan sebagai salah satu syarat untuk memperoleh gelar Doktor dalam Program Doktor Ilmu Komputer pada Fakultas Ilmu Komputer dan Teknologi Informasi, Universitas Sumatera Utara di bawah pimpinan Rektor
Universitas Sumatera Utara Dr. Muryanto Amin, S.Sos., M.Si.
Oleh:
AMALIA NIM: 178123001
PROGRAM STUDI DOKTOR (S-3) ILMU KOMPUTER FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA MEDAN
PENGESAHAN DISERTASI
Judul Disertasi : Subword Embedding Dengan Pendekatan Byte Pair Encoding Dan Morfologi Bahasa Indonesia
Nama Mahasiswa : Amalia Nomor Induk Mahasiswa : 178123001
Program Studi : Doktor (S3) Ilmu Komputer
Menyetujui, Komisi Pembimbing
Prof. Dr. Opim Salim Sitompul, M.Sc Promotor
Prof. Dr. Ir. Teddy Mantoro, M.Sc Dr. Erna Budhiarti Nababan, M.IT Ko-Promotor Ko-Promotor
Mengetahui
Ketua Program Studi Dekan
Dr. Poltak Sihombing, M. Kom Dr. Maya Silvi Lydia, B.Sc., M.Sc
PERNYATAAN ORISINALITAS
SUBWORD EMBEDDING DENGAN PENDEKATAN BYTE PAIR ENCODING DAN MORFOLOGI BAHASA INDONESIA
DISERTASI
Dengan ini saya menyatakan bahwa saya mengakui semua karya Disertasi ini adalah hasil kerja saya sendiri kecuali kutipan dan ringkasan yang tiap bagiannya telah dijelaskan sumbernya dengan benar.
Medan, Oktober 2021
AMALIA NIM : 178123001
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai sivitas akademika Universitas Sumatera Utara, saya yang bertanda tangan di bawah ini:
Nama : AMALIA
NIM :178123001
Program Studi : DOKTOR (S-3) Ilmu Komputer Jenis Karya Ilmiah : DISERTASI
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive Royalty free Right) atas disertasi saya yang berjudul:
SUBWORD EMBEDDING DENGAN PENDEKATAN BYTE PAIR ENCODING DAN MORFOLOGI BAHASA INDONESIA
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non- Eksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media, memformat, mengelola dalam bentuk database, merawat dan mempublikasikan Disertasi saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis dan sebagai pemegang dan atau sebagai pemilik hak cipta.
Demikian pernyataan ini dibuat dengan sebenarnya.
Medan, Oktober 2021
AMALIA
Telah diuji dan dinyatakan lulus pada Tanggal : 19 Oktober 2021
PANITIA PENGUJI DISERTASI
Ketua : Prof. Dr. Opim Salim Sitompul, M.Sc USU Medan Anggota : 1. Prof. Dr. Ir. Teddy Mantoro, M.Sc Univ. Sampoerna
2. Dr. Erna Budhiarti Nababan, M.IT USU Medan 3. Prof. Dr. Muhammad Zarlis USU Medan 4. Dr. Elviawaty Muisa Zamzami, ST., MT., MM USU Medan 5. Prof. Dr. Taufik Fuadi Abidin, S.Si., M.Tech Univ. Syiah Kuala
RIWAYAT HIDUP
DATA PRIBADI
Nama lengkap berikut gelar : Amalia, ST., MT
Tempat dan Tanggal Lahir : Banda Aceh / 21 Desember 1978
Email : [email protected]
Instansi Tempat Bekerja : Program S-1 Ilmu Komputer Fakultas Teknologi dan Informasi Universitas Sumatera Utara
Alamat Kantor : Jalan Universitas No 9-A, Kampus USU
Telepon : (061) 8210077
DATA PENDIDIKAN
SD : SD Negeri 1 Banda Aceh Lulus : 1991
SMP : SMP Negeri 1 Banda Aceh Lulus : 1994
SMA : SMA Negeri 1 Banda Aceh Lulus : 1997
Strata-1 : Universitas Syiah Kuala Lulus : 2003
Strata-2 : Universitas Sumatera Utara Lulus : 2011
KATA PENGANTAR
Puji dan syukur saya ucapkan kepada Allah SWT yang telah memberikan Rahmat- Nya sehingga penulis dapat menyelesaikan disertasi ini. Penulis berterima kasih kepada semua pihak yang telah membantu dan mendukung sehingga disertasi ini bisa diselesaikan. Penulis ingin mengucapkan terima kasih kepada:
1. Bapak Dr. Muryanto Amin, S.Sos, M.Si sebagai Rektor Universitas Sumatera Utara.
2. Ibu Dr. Maya Silvi Lydia, B.Sc, M.Sc sebagai Dekan Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
3. Bapak Dr. Poltak Sihombing, M.Kom sebagai Ketua Program Studi Program Doktor (S-3) Ilmu Komputer.
4. Bapak Prof. Dr. Opim Salim Sitompul, M.Sc sebagai sebagai promotor yang telah membimbing dan memberi banyak masukan kepada penulis selama mengerjakan disertasi ini.
5. Bapak Prof. Ir. Teddy Mantoro, M.Sc sebagai ko-promotor yang telah membimbing dan memberi banyak masukan kepada penulis selama mengerjakan disertasi ini.
6. Ibu Dr. Erna Budhiarti Nababan, M.IT sebagai ko-promotor yang telah membimbing dan memberi banyak masukan kepada penulis selama mengerjakan disertasi ini.
7. Bapak Prof. Dr. Muhammad Zarlis, M.Sc, Ibu Dr. Elviawaty Muisa Zamzami, ST., MT., MM dan Bapak Prof. Dr.Taufik Fuadi Abidin, S.Si.,M.Tech selaku komisi penguji yang telah memberikan masukan, kritik dan saran yang bermanfaat dalam perbaikan disertasi ini.
8. Seluruh dosen serta staf pegawai di Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
9. Suami tercinta Yudhi Andhika Lubis, ST, MM dan anak-anak tercinta Gavin Fadel Al Ghazi Lubis, Jevera Marva Al Ghalibi Lubis dan Alexandra Al Aqsa Lubis yang tak kenal lelah memberikan dukungan, semangat dan motivasi tiada henti sehingga penulis dapat menyelesaikan disertasi ini.
10. Orang tua dan mertua tercinta yang tak kenal lelah memberikan dukungan, semangat dan motivasi tiada henti sehingga penulis dapat menyelesaikan disertasi ini.
11. Keluarga besar dan sahabat penulis yang tak kenal lelah memberikan dukungan semangat dan motivasi sehingga penulis dapat menyelesaikan disertasi ini.
12. Semua pihak yang terlibat langsung ataupun tidak langsung yang tidak dapat penulis ucapkan satu-persatu yang telah membantu penyelesaian disertasi ini.
Medan, Oktober 2021 Penulis
AMALIA
NIM : 178123001
SUBWORD EMBEDDING DENGAN PENDEKATAN BYTE PAIR ENCODING DAN MORFOLOGI BAHASA INDONESIA
ABSTRAK
Word embedding konvensional memperlakukan kata sebagai satuan entitas independen terkecil dan mengabaikan struktur internal pembentuk kata. Hal ini menyebabkan model konvensional ini tidak mampu menghandel Out of Vocabulary (OOV) dan tidak mampu menangkap hubungan eksplisit keterkaitan morfologi sintaksis sebaik semantik. Untuk itu dibutuhkan suatu model word embedding yang dibentuk dari subword pembentuk kata seperti karakter atau morfem. Penelitian ini bertujuan menghasilkan suatu metode pembentukan subword embedding yang sesuai dengan morfologi bahasa Indonesia. Tantangan terbesar dari penelitian ini adalah proses segmentasi kata menjadi bentuk subword dan juga proses penggabungan subword menjadi encoding kata utuh. Pada penelitian ini segmentasi dilakukan dengan metode Byte Pair Encoding (BPE) dengan tambahan informasi morfologi bahasa Indonesia, encoding subword dengan algoritma GloVe, penggabungan encoding subword menjadi encoding kata utuh dengan metode addition dan training level kata dengan algoritma Skip Gram. Training korpus berasal dari Wikipedia berukuran 742 MB dengan jumlah kata 729.260.836 dan kata unik sebanyak 364.184 kata. Setelahproses segmentasi penambahan kosa kata menjadi 385.446 dengan pre-trained subword vector berukuran sebesar 950,3 MB.
Evaluasi dilakukan dengan serangkaian analogi tes untuk menguji kandungan semantik dan sintaksis untuk beberapa contoh vektor yang dihasilkan. Evaluasi mengacu pada benchmark analogi tes set Google dan BATS yang telah diadaptasi untuk bahasa Indonesia. Hasil penelitian menunjukkan subword embedding yang dihasilkan mampu menghandel OOV dan juga mengandung informasi semantik dan juga informasi sintaksis yang lebih baik karena memperhitungkan struktur internal kata yaitu morfem. Selain itu penelitian ini juga memiliki kontribusi tambahan yaitu menghasilkan korpus gabungan dari Wikipedia dan hasil crawling surat kabar sebesar 1.652.081.275 kata, pre-trained word vektor yang dibangun dengan word2vec dan fastText untuk bahasa Indonesia dan juga model evaluasi intrinsik tes set 4935 analogi untuk evaluasi embedding bahasa Indonesia.
Kata Kunci: Byte Pair Encoding, Morfologi Bahasa Indonesia, Subword Embedding, Word Embedding
SUBWORD EMBEDDING USING BYTE PAIR ENCODING AND MORPHOLOGY OF BAHASA INDONESIA
ABSTRACT
The conventional word embedding method treats words as the smallest independent entity unit and ignores word's internal structure. This causes the embedding unable to handle out of Vocabulary (OOV) and unable to capture the explicit relationship between syntactic morphology. One solution is to generate a word embedding from its subwords, such as characters or morphemes. This study aims to generate a subword embedding for bahasa Indonesia by considering additional information on bahasa Indonesia morphology. The biggest challenge of this research is the process of tokenizing each word into its subwords and the process of merging sub words encoding into a full word. This study's framework is word segmentation using Byte Pair Encoding (BPE), sub-word encoding using the GloVe algorithm, merging subword encoding into a whole word encoding using the addition method, and subword embedding using Skip Gram word2vec. The training corpus is from Wikipedia bahasa Indonesia, with total numbers of words is 729,260,836 and 364,184 unique words in the capacity of 746 MB. The implemented model of this study produces a pre-trained Subword embedding with 385,446 tokens in a capacity of 950.3 MB. The evaluation is carried out by utilizing a series of analogy test set to measure the semantic and syntactic relation. The evaluation refers to the benchmark analogy test set of Google and BATS adapted for bahasa Indonesia. The evaluation result showed that the model of this study is able to handle OOV and had a good result in capturing semantic and syntactic relations. In additional contribution, this study also generated another corpus combination from Wikipedia and crawled newspaper with 1,652,081,275 words. This study also yields pre- trained word vectors for bahasa Indonesia, built using word2vec and fastText algorithm. This study also generated an intrinsic evaluation model test set of 4935 analogy questions test for bahasa Indonesia.
Keywords: Byte Pair Encoding, Morphology of Bahasa Indonesia, Subword Embedding, Word Embedding.
DAFTAR ISI
PENGESAHAN DISERTASI ... i
PERNYATAAN ORISINALITAS ... ii
PERNYATAAN PERSETUJUAN PUBLIKASI ... iii
RIWAYAT HIDUP ...v
KATA PENGANTAR... vi
ABSTRAK ... viii
ABSTRACT ... ix
DAFTAR ISI ...x
DAFTAR GAMBAR ... xii
DAFTAR TABEL ... xiv
BAB I PENDAHULUAN ...1
1.1 Latar Belakang ...1
1.2 Rumusan Masalah ...6
1.3 Tujuan Penelitian...7
1.4 Manfaat Penelitian...7
1.5 Batasan Masalah ...8
BAB II TINJAUAN PUSTAKA ...9
2.1 Word Representation Tradisional...10
2.1 Representasi Teks Kontinyu...11
2.2 Word Embedding ...16
2.3 Word Embedding dengan Tambahan Informasi ...21
2.4 Subword Embedding ...24
2.5 Segmentasi Kata ...26
2.6 Linguistik Bahasa Indonesia ...29
2.7 Sumber Daya Linguistik Bahasa Indonesia ...29
2.8 Evaluasi Word Embedding...31
2.8.1 Evaluasi Ekstrinsik ...31
2.8.3 Penerapan Linguistik Bahasa Indonesia ...36
2.9 Mind Map Penelitian ...44
2.9.1 Observasi Ukuran Korpus ...46
2.9.2 Observasi Hyper-Parameter Pembentukan Word Embedding ...55
2.9.3 Pengujian Word Embedding dari Efek Korpus dengan Clustering ...56
2.9.4 Pengujian Word Embedding dengan Klasifikasi ...60
2.9.5 Word Embedding dengan Domain-Spesifik Korpus ...62
2.9.6 Perancangan Model Word Vector Representation Bahasa Indonesia ...62
2.9.7 Hasil Pengujian Word Embedding dengan Clustering ...63
2.9.8 Hasil Pengujian Word Embedding dengan Klasifikasi ...67
2.9.9 Hasil Observasi Word Embedding dari spesifik Domain ...71
BAB III METODOLOGI PENELITIAN ...74
3.1 Persiapan Korpus dan Baseline Model...76
3.2 Tokenization dan Generate Pasangan Kata Target dan Konteks ...77
3.3 Segmentasi Kata dengan BPE ...78
3.4 Identifikasi Morfem Bahasa Indonesia ...81
3.5 Generate Encoding Subword ...82
3.6 Generate Encoding Final Kata ...83
3.7 Generate Word Embedding ...83
3.9 Evaluasi ...85
3.9.1 Analogi Tes Set Bahasa Indonesia – G ...86
3.9.2 Analogi Tes Set Bahasa Indonesia – B ...88
BAB IV HASIL DAN IMPLEMENTASI ...92
4.1 Hasil Observasi Korpus ...92
4.2 Hasil Tokenization dan Generate Pasangan Kata ...93
4.3 Hasil Segmentasi ...94
4.4 Hasil Encoding Subword ...97
4.5 Hasil Word Embedding ...98
4.6 Hasil Perancangan Evaluasi Analogi Tes Bahasa Indonesia ...100
4.6.1 Analogi Test Set Bahasa Indonesia - G ...100
4.6.2 Analogi Tes Set Bahasa Indonesia - B ...101
4.7 Hasil Evaluasi Model ...103
4.7.1 Evaluasi Semantik ...103
4.7.2 Evaluasi Sintaksis ...108
4.1 Analisis Hasil Evaluasi...109
BAB V KESIMPULAN DAN SARAN ...111
5.1 Kesimpulan...111
5.2 Saran ...112
DAFTAR PUSTAKA ...113
DAFTAR GAMBAR
No Judul Gambar Halaman
Gambar 2. 1 Arsitektur NNLM (Bengio et al., 2003) ... 15
Gambar 2. 2 Arsitektur Simple RNN (Mikolov et al., 2011) ... 17
Gambar 2. 3 Arsitektur word2vec CBOW (kiri) dan Skip Gram (kanan) ... 19
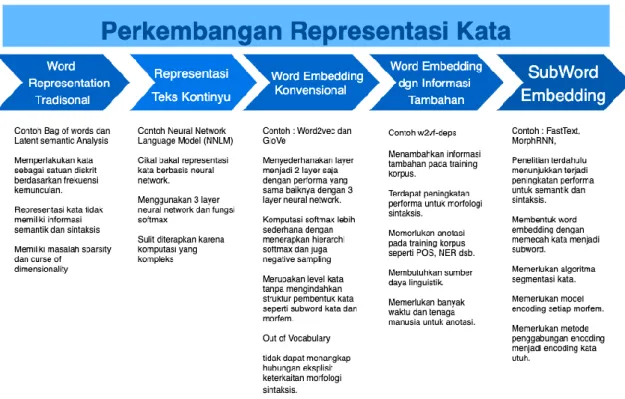
Gambar 2. 4 Perkembangan Representasi Kata NLP ... 26
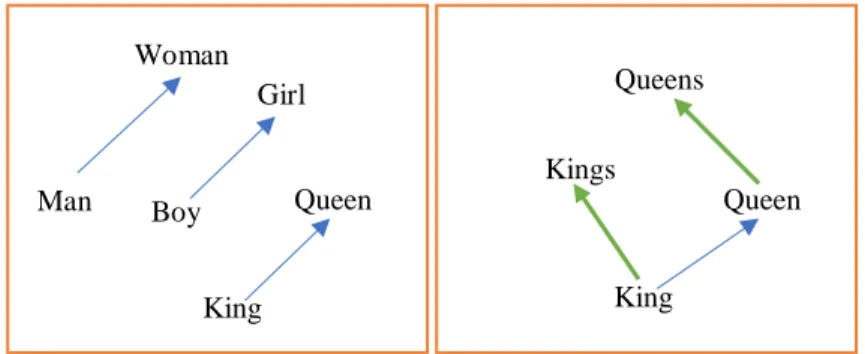
Gambar 2. 5 Analogi Relasi Vektor Word Embedding ... 35
Gambar 2. 6 Mind Map Penelitian . ... 45
Gambar 2. 7 Tahapan Membentuk Pre-Trained Bahasa Indonesia ... 55
Gambar 2. 8 Tahapan Pengujian Word Embedding dengan Clustering ... 57
Gambar 2. 9 Tahapan Klasifikasi Word Embedding dengan fastText ... 61
Gambar 2. 10 Visualisasi Data Hasil Clustering ... 66
Gambar 2. 11 Komparasi Hasil Clustering ... 67
Gambar 2. 12 Sebaran Kata Pre-Trained Word Vektor Untuk Bidang Komputer 73 Gambar 3. 2. Word Encoding sebagai input layer ... 74
Gambar 3.3. Ilustrasi Segementasi Kata Menjadi Subword ... 75
Gambar 3.4 Framework Penelitian Subword Embedding dengan BPE dan Morfologi Bahasa Indonesia ... 76
Gambar 3. 5 Excerpt Code Fungsi Generate Pair Words ... 78
Gambar 3. 6 Ilustrasi Pembentukan Word Embedding dengan Skip Gram ... 84
Gambar 4. 1 Contoh Hasil Tokenisasi Kata ... 93
Gambar 4. 2 Contoh Hasil Pasangan Kata Target dan Kata Konteks ... 94
Gambar 4. 3 Model Subword Encoding ... 97
Gambar 4. 4 Visualisasi Model Subword Embedding yang Dihasilkan ... 99
Gambar 4. 5 Hasil Evaluasi Semantik ... 105
Gambar 4. 6 Visualisasi Evaluasi Semantik Percobaan 1 ... 106
Gambar 4. 7 Visualisasi Evaluasi Semantik Percobaan 1 ... 107
DAFTAR TABEL
No Judul Tabel Halaman
Tabel 2. 1 Pembentukan Word Embedding Berdasarkan Kata Konteks ... 20
Tabel 2. 2 Summary Penelitian Terdahulu ... 40
Tabel 2. 3 Pre-Trained Representation Bahasa Inggris yang tersedia... 54
Tabel 2. 4 Informasi Korpus dan Sub-Corpora ... 57
Tabel 2. 5 Hyper-Parameter untuk Model Doc2Vec... 63
Tabel 2. 6 Hasil Evaluasi Cluster TFIDF-LSA ... 64
Tabel 2. 7 Hasil Evaluasi Cluster Doc2Vec ... 64
Tabel 2. 8 Hasil Klasifikasi TFIDF ... 68
Tabel 2. 9 Confusion Matrix Model TFIDF dengan Klasfikasi Linear SVC ... 68
Tabel 2. 10 Parameter Default Model fastText ... 69
Tabel 2. 11 Nilai F-Score Setelah Nilai Parameter di Ubah ... 70
Tabel 2. 12 Confusion Matrix FastText ... 70
Tabel 2. 13 Komparasi Antara TFIDF dan fastText untuk Kasus Klasifikasi ... 71
Tabel 2. 14 Komparasi Kata Terdekat Berdasarkan Kata Target ... 72
Tabel 3. 1 Pola Analogi Tes Set Google ... 86
Tabel 3. 2 Pola Test Analogi BATS ... 88
Tabel 4. 1 Model Baseline Untuk Komparasi ... 92
Tabel 4. 2 Excerpt Daftar Kata dan Frekuensi ... 94
Tabel 4. 3 Hasil Evaluasi Segementasi Kata dengan BPE Modifikasi ... 95
Tabel 4. 4 Morfem Embedding Berdasarkan Subword Terdekat (Nearest
Neigbours) ... 98
Tabel 4. 5 Kategori Morfologi Bahasa Indonesia ... 100
Tabel 4. 6 Analogi Test Bahasa Indonesia – B ... 102
Tabel 4. 7 Evaluasi Semantik ... 104
Tabel 4. 8 Contoh Hasil Yang didapatkan pada Evaluasi Semantik ... 104
BAB I PENDAHULUAN
1.1 Latar Belakang
Salah satu parameter terpenting untuk meningkatkan performansi machine learning termasuk deep learning adalah pemilihan representasi fitur input yang tepat. Perkembangan terkini di bidang Natural Language Processing (NLP) mengungkapkan bahwa saat ini representasi teks yang terbukti efisien untuk input machine learning dan deep learning adalah word embedding (Erhan et al., 2010;
Salakhutdinov and Hinton, 2012; Ling et al., 2015). Word embedding terbukti dapat mengantisipasi kekurangan dari representasi teks diskrit (Bengio, Courville and Vincent, 2014), dimana model diskrit terkendala dengan sparsity dan curse of dimensionality (Popov et al., 2018).
Word embedding dikenal juga dengan istilah continuous representations atau distributed representation (Bansal, Gimpel and Livescu, 2014) merupakan pembentukan representasi teks dengan metode neural network. Proses neural network diimplementasikan untuk memprediksi kata target berdasarkan kata konteks ataupun sebaliknya. Berdasarkan co-occurrence pasangan kata target dan kata konteks pada training korpus maka hasil prediksi dapat di optimalkan dengan men-adjust nilai bobot neural network. Nilai bobot ini selanjutnya menjadi word embedding. Word embedding merupakan transformasi setiap kata pada korpus dengan format dense vector yang mengandung informasi semantik, dimana kata dengan relasi dekat memiliki nilai vektor yang dekat pula.
Namun model word embedding konvensional yang diproses pada level kata memiliki keterbatasan dimana model ini tidak dapat menghasilkan word embedding untuk kata-kata yang tidak terdapat pada training korpus. Dengan kata lain model ini tidak dapat mengatasi out of vocabulary (OOV). Pembentukan word embedding konvensional memperlakukan kata sebagai satuan entitas independen terkecil dan mengabaikan struktur internal subword pembentuk kata seperti karakter dan morfem, sehingga model konvensional ini tidak mampu untuk menangkap hubungan eksplisit keterkaitan morfologi sintaksis (Luong, Socher and Manning, 2013; Xu and Liu, 2017). Sebagai contoh word embedding level kata tidak dapat menghasilkan embedding untuk kata “permainan” jika kata tersebut tidak ada pada training korpus walaupun kata dasar “main” terdapat pada korpus. Hal ini menunjukkan model word embedding konvensional tidak dapat menangkap relasi sintaksis sebaik relasi semantik.
Beberapa peneliti menyelesaikan OOV untuk word embedding dengan memperbesar ukuran training korpus sehingga memperbesar ukuran vocabulary, namun hal ini tidak selalu efektif mengingat tidak efisiennya media penyimpanan dan juga proses komputasi yang semakin kompleks. Selain itu beberapa peneliti terdahulu mengungkapkan ukuran korpus yang besar bukan merupakan parameter terpenting dalam membentuk word embedding yang handal (Altszyler et al., 2017;
Dusserre, 2017; Gu et al., 2018). Salah satu solusi untuk mengantisipasi permasalahan OOV yaitu dengan membentuk word embedding berdasarkan subword pembentuk katanya. Beberapa penelitian terdahulu telah membuktikan metode subword meningkatkan performa downstream NLP (Park et al., 2018)
seperti klasifikasi (Zhang and LeCun, 2017), machine translation (Sennrich, Haddow and Birch, 2016) dan lainnya.
Morfem merupakan satuan gramatikal linguistik terkecil yang memiliki makna. Suatu kata dapat dibentuk dari satu morfem bebas yaitu kata dasar saja ataupun dapat dibentuk dari satu morfem bebas dengan beberapa morfem terikat seperti afiks atau imbuhan. Dengan imbuhan, kata dasar dapat mengalami perubahan morfologi yang berefek secara derivasional dan juga infleksional. Secara linguistik, observasi berbasis morfem lebih baik dalam menghasilkan dan mengenali bentuk kata berbeda dalam jumlah yang jauh lebih besar daripada jika hanya mengandalkan training korpus (Creutz and Lagus, 2007). Selain itu word embedding dengan tambahan informasi morfem atau morfologi embedding selain dapat menjadi solusi untuk permasalahan OOV, model ini juga dapat mengatasi word sense dan ambiguitas kata (Salama, Youssef and Fahmy, 2018).
Terdapat beberapa tantangan dalam membentuk word embedding berbasis morfologi embedding, seperti pemilihan metode segmentasi kata, pemilihan motode encoding morfem dan juga metode penggabungan encoding morfem menjadi encoding kesatuan utuh kata. Namun tantangan terbesar adalah membentuk segmentasi kata menjadi bentuk morfem yang sesuai dengan tata bahasa. Setiap bahasa memiliki aturan bahasa terikat yang unik sehingga tidak ada suatu model segmentasi kata yang dapat mengeneralisasi semua bahasa (Zhu, Vulić and Korhonen, 2019). Beberapa penelitian menunjukkan penambahan informasi subword tanpa tergantung suatu bahasa seperti fastText (Bojanowski et al., 2017) menghasilkan performa lebih baik daripada algoritma embedding berbasis level kata konvensional seperti word2vec (Mikolov, Yih and Zweig, 2013) dan GloVe
(Pennington, Socher and Manning, 2014). Namun evaluasi hanya dilakukan untuk beberapa bahasa tertentu saja sehingga diperlukan observasi lebih mendalam untuk pembuktian keberhasilan pada bahasa Indonesia.
Terdapat beberapa pilihan segmentasi kata dari model supervised penuh seperti CHIPMUNK (Cotterell et al., 2015) sampai model unsupervised seperti Morfessor (Creutz and Lagus, 2007). Salah satu metode kompresi data sederhana yaitu Byte Pair Encoding (BPE) (Gage, 1994) ternyata dapat diimplemantasikan untuk segmentasi kata dan saat ini menjadi de facto standard untuk segmentasi subword terutama untuk proses machine translation (Sennrich, Haddow and Birch, 2016). Keberhasilan ini kemudian diikuti oleh peneliti lain yang membentuk segmentasi kata untuk berbagai bahasa dengan algoritma BPE seperti penelitian (Heinzerling and Strube, 2019) yang menghasilkan subword secara masal untuk 275 bahasa. Namun keberhasilan BPE dalam membentuk segmentasi kata hanya berdasarkan identifikasi urutan karakter yang paling sering muncul dinilai kurang optimal, sehingga beberapa peneliti lain melakukan modifikasi BPE seperti algoritma BPE-dropout (Provilkov, Emelianenko and Voita, 2019) dan juga algoritma BERT untuk word pieces (Devlin et al., 2019).
Segmentasi kata dengan algoritma BPE merupakan metode unsupervised untuk memecah kata menjadi subword berdasarkan urutan karakter yang paling sering muncul pada korpus. Sehingga tidak jaminan bahwa segmentasi yang dihasilkan merupakan suatu morfem bahasa tertentu. Beberapa penelitian tentang morphology embedding fokus untuk suatu bahasa tertentu saja seperti penelitian untuk bahasa Portugis (Hartmann et al., 2017), bahasa Jerman (Cotterell and Schütze, 2015) dan bahasa Swedia (Basirat and Tang, 2018) menunjukkan hasil
yang menjanjikan. Tambahan informasi morfologi juga terbukti berguna untuk bahasa dengan morfologi yang kompleks seperti bahasa Turki (Cotterell, Schütze and Eisner, 2016), bahasa Ibrani (Avraham and Goldberg, 2017) dan bahasa Arab (Salama, Youssef and Fahmy, 2018).
Berdasarkan hal ini maka motivasi penelitian ini yaitu untuk membentuk subword embedding berdasarkan morfologi bahasa Indonesia dengan pendekatan Byte Pair Encoding (BPE). Hipotesis penelitian ini yaitu word embedding yang dibangun dari gabungan subword berupa morfem lebih memiliki makna gramatikal sehingga dapat membentuk word embedding yang lebih baik. Sepanjang pengetahuan kami pembentukan word embedding dengan mempertimbangkan informasi morfem yang sesuai untuk bahasa Indonesia masih belum tersedia.
Kontribusi dari penelitian ini, yaitu suatu metode dalam membangun subword embedding untuk bahasa Indonesia dengan penambahan informasi morfem. Hasil dari penelitian yaitu berupa model pre-trained subword embedding yang berkualitas baik secara semantik dan juga sintaksis sehingga dapat meningkatkan hasil downstream NLP Bahasa Indonesia seperti klasifikasi, clustering, sentiment analysis dan machine translation.
Evaluasi dilakukan dengan menguji model subword embedding yang mengacu pada benchmark anologi tes set dari Google (Mikolov, Yih and Zweig, 2013) dan The Bigger Analogy Test Set (BATS) (Gladkova, Drozd and Matsuoka, 2016). Standar dari model evaluasi ini ditujukan untuk bahasa Inggris, oleh sebab itu agar dapat diterapkan untuk pengujian word embedding bahasa Indonesia maka pada disertasi ini juga dibahas pembentukan analogi tes set untuk bahasa Indonesia.
Selain analogi tes set Google dan BATS, terdapat beberapa penelitian terdahulu lainnya yang fokus mengobservasi pembentukan benchmark analogi tes untuk bahasa Inggris seperti Microsoft Syntactic Relation-MSR (Mikolov et al., 2013), semEval-2012-Task2 (Jurgens et al., 2012), WordSim-353 (Finkelstein et al., 2001) dan SAT (Turney and Littman, 2003). Analogi tes merupakan dependent linguistic yang sangat tergantung suatu bahasa maka beberapa penelitian terdahulu membangun analogi tes untuk evaluasi berbagai bahasa tertentu lainnya seperti evaluasi bahasa Norwegia (Stadsnes, Øvrelid and Velldal, 2018), evaluasi bahasa Korea (Park et al., 2018), evaluasi bahasa China (Chen and Ma, 2019), evaluasi bahasa Perancis, bahasa India, bahasa Polandia (Grave et al., 2018) dan evaluasi bahasa Portugis (Hartmann et al., 2017).
Sehubungan belum banyak tersedianya analogi tes set untuk bahasa Indonesia maka hasil analogi tes set bahasa Indonesia yang dihasilkan dari penelitian ini dapat menjadi tambahan kontribusi pada penelitian ini. Dimana tes analogi ini dapat di manfaatkan untuk evaluasi berbagai model word embedding untuk bahasa Indonesia.
1.2 Rumusan Masalah
Proses word embedding konvensional membentuk embedding berdasarkan level kata tidak dapat menghandel OOV atau kata yang tidak ada pada training corpus. Model word embedding konvensional mengabaikan informasi struktur pembentuk kata sehingga tidak dapat menangkap hubungan eksplisit keterkaitan morfologi sintaksis. Salah satu solusinya yaitu membentuk word embedding berdasarkan bagian yang lebih kecil dari kata yaitu subword seperti morfem.
Tantangan dalam membentuk subword embedding berdasarkan morfologi yaitu segmentasi kata yang harus sesuai dengan morfologi suatu tata bahasa dimana pada penelitian ini menggunakan linguistik bahasa Indonesia. Tantangan lainnya adalah pemilihan model encoding dan juga model penggabungan morfem encoding sehingga membentuk encoding kata utuh sebagai input pada proses embedding sehingga menghasilkan word embedding yang lebih baik dari sisi semantik dan sintaksis.
1.3 Tujuan Penelitian
Tujuan dari penelitian ini adalah membangun suatu metode untuk menghasilkan model subword embedding bahasa Indonesia yang mengikutsertakan informasi morfologi sehingga mampu mengatasi OOV. Model ini juga diharapkan lebih baik dalam menangkap informasi semantik dan juga sintaksis pada setiap representasinya sehingga dapat meningkatkan performa downstream task NLP bahasa Indonesia seperti klasifikasi, clustering, sentimen analisis, machine translation dan lain sebagainya.
1.4 Manfaat Penelitian
Penelitian ini bermanfaat sebagai linguistic resources NLP bahasa Indonesia untuk machine learning dan juga deep learning. Penelitian ini menghasilkan model word embedding yang lebih baik dibandingkan dengan metode word embedding konvensional. Selain itu penelitian ini juga menghasilkan pre-trained word embedding siap pakai untuk bahasa Indonesia. Penelitian ini juga menghasilkan
model evaluasi intrinsik tes analogi bahasa Indonesia yang dapat dimanfaatkan untuk mengevaluasi berbagai model word embedding untuk bahasa Indonesia.
1.5 Batasan Masalah
1. Penelitian ini hanya mengobservasi linguistik bahasa Indonesia yang sesuai EYD.
2. Penelitian ini tidak membahas pembentukan embedding untuk kata majemuk.
3. Penelitian ini menggunakan metode stemming dan bukan lemmatization untuk penentuan kata dasar.
BAB II
TINJAUAN PUSTAKA
State of the art dari penelitian tentang pembentukan word vector representation atau representasi teks telah dimulai dari beberapa dekade. Saat ini para peneliti di bidang komputasi linguistik atau NLP mulai beralih ke metode machine learning terutama deep learning dalam menyelesaikan permasalahan di NLP. Salah satu alasannya karena keberhasilan metode deep learning dalam meningkatkan akurasi yang signifikan contohnya pada bidang machine translation, klasifikasi dan clustering (Loper and Bird, 2004). Pada machine learning, fitur data input harus diubah menjadi bentuk yang dapat diproses lebih lanjut yaitu dalam bentuk data vektor. Untuk kasus pada data tekstual, bentuk dokumen yang terdiri dari kumpulan string atau kalimat juga harus direpresentasikan dalam bentuk vektor. Proses mengubah data teks menjadi bentuk vektor disebut dengan feature engineering dimana proses ini menghasilkan representasi teks. Proses penentuan representasi teks merupakan bagian penting dalam proses NLP karena salah satu dari keberhasilan machine learning sangat tergantung dari pemilihan model word vector representation yang digunakan (Bengio, Courville and Vincent, 2014;
Goldberg, 2017). Secara garis besar perkembangan representasi teks dimulai dari metode representasi teks diskrit seperti Bag of Words (BoW), dilanjutkan dengan metode representasi teks kontinyu seperti ditributional hypothesis dan representasi teks berbasis neural network atau word embedding.
2.1 Word Representation Tradisional
Pembentukan representasi teks secara tradisional adalah dengan memperlakukan dokumen sebagai kumpulan kata-kata individual atau satuan diskrit. Metode ini juga dikenal dengan nama Bag of Words (BoW). Representasi dilakukan berdasarkan kemunculan n-grams kata dari suatu dokumen sehingga metode ini disebut juga dengan metode count-based frequency. Metode ini tidak menghiraukan informasi order dan posisi kata pada suatu dokumen, tidak ada gagasan relevansi antara kata-kata, semua kata direpresentasikan sebagai indeks dalam suatu vocabulary (Tomas Mikolov et al. 2013). Metode ini sederhana karena hanya melibatkan proses dasar NLP seperti tokenization, stemming, stop word removal dan lain sebagainya. Kekurangan metode ini yaitu sparsity dan juga curse of dimensionality yaitu jumlah dimensi data representasi yang sangat besar.
Setidaknya dengan metode ini, jumlah dimensi vektor sebesar jumlah kosa kata yang terdapat dalam korpus. Beberapa contoh model data representasi dari BoW adalah One Hot Encoding, Count Vectorizer dan Term Frequency-Inverse Document Frequency (TF-IDF) Vectorizer. Representasi teks yang dihasilkan dari model representasi ini tidak dapat menangkap banyak informasi selain jumlah kemunculan kata. Beberapa survey untuk membandingkan model dari representasi teks diskrit ini pernah dilakukan oleh penelitian (Baroni and Lenci, 2010; Turney and Pantel, 2010). Dimana untuk mengantisipasi curse of dimensionality beberapa penelitian, melakukan pengurangan dimensi dengan berbagai teknik seperti Singular Value Decomposition (SVD) (Bullinaria and Levy 2007; Taufik Fuadi Abidin, Yusuf, and Umran 2010) atau dengan metode LDA (Hung, Wang and Lee, 2001).
Permasalahan lainnya, model BoW yang memperlakukan setiap kata sebagai satuan diskrit unik, membuat representasi teks yang dihasilkan tidak dapat diterapkan untuk task atau domain di luar domain korpus. Sehingga representasi teks tidak dapat diimplementasikan secara general untuk task NLP secara umum.
Model pembentukan vektor lainnya yaitu Latent Semantic Indexing (LSI) atau Latent Semantic Analysis (Deerwester et al., 1990; Landauer, Foltz and Laham, 1998; Wiemer-Hastings, 2004; Xiao, 2010; Evangelopoulos, 2013; Setiadi Citawan, Christanti Mawardi and Mulyawan, 2018). Model ini disebut juga dengan model matrix factorization dimana metode ini mencoba mengambil makna kata dengan perhitungan SVD. Namun beberapa permasalahan juga muncul dengan model matrix factorization ini terutama dalam hal curse of dimensionality dan kompleksitas komputasi. Penelitian yang menerapkan metode ini yaitu (P.~Brown et al., 1992) dan (Baker and McCallum, 1998). Beberapa penelitian penerapan LSA untuk Bahasa Indonesia adalah penelitian oleh (Ratna, Purnamasari and Adhi, 2015; Setiadi Citawan, Christanti Mawardi and Mulyawan, 2018).
2.1 Representasi Teks Kontinyu
Salah satu metode pembentukan representasi teks yang merupakan cikal bakal word vectors berbasis neural network adalah penerapan word vector kontinyu.
Awalnya dimulai dengan memperlakukan dokumen teks sebagai kesatuan utuh dan bukan satuan diskrit. Representasi teks kontinyu berpedoman dengan model distributional hypothesis (Sahlgren, 2008) yang membentuk model word vectors dengan matriks co-occurrence. Metode ini menjawab beberapa permasalahan yang disebabkan oleh metode sebelumnya. Pembentukan word vector representation
dengan matriks co-occurence mampu menangkap informasi semantik dan sintaksis tanpa harus tergantung dengan sumber daya linguistik eksplisit. Hanya bermodalkan korpus yang berisi kalimat-kalimat dengan jumlah yang besar.
Metode ini melakukan pembelajaran representasi (learning representation) komposisi dan susunan kata dalam kalimat-kalimat yang terdapat pada suatu korpus yang besar. Ide dasar dari teori distributional hypothesis pertama sekali disampaikan oleh seorang ahli bahasa yang bernama Zellig Harris yang menyatakan
“words are similar if they appear in similar contexts (Harris, 1963). Sehingga dari pembelajaran korpus, model ini mampu menangkap informasi relasi syntagmatic dan paradigmatic. Relasi syntagmatig menyangkut penentuan posisi kata, dan menghubungkan entitas yang terjadi bersama dalam teks. Relasi ini adalah hubungan dalam presentia. Relasi ini bersifat linear, dan berlaku untuk entitas linguistik yang terjadi dalam kombinasi berurutan (Sahlgren, 2008). Syntagm adalah suatu kombinasi yang teratur dari entitas linguistik. Misalnya, suatu kata dibentuk dari sintaksis huruf, kalimat dibentuk dari urutan kata-kata, dan paragraf dibentuk dari urutan kalimat-kalimat. Sedangkan relasi paradigmatic adalah hubungan antara entitas linguistik yang terjadi dalam konteks yang sama tetapi tidak pada waktu yang sama, seperti kata "lapar" dan "haus" dalam kalimat "serigala itu [lapar | haus]". Hubungan paradigmatic adalah hubungan substitusional, yang berarti bahwa entitas linguistik memiliki hubungan paradigmatic ketika pilihan satu tidak termasuk pilihan yang lain (Sahlgren, 2008).
Language model adalah algoritma berbasis probabilitas maximum likelihood untuk prediksi untaian kata dalam suatu kalimat. Probabilitas didapatkan berdasarkan learning dari korpus. Misalkan ada sejumlah n kata dengan untaian
kata (w1, w2, w3… wn) maka probabilitas P (w1, w2,…, wn) dapat dikalkulasi dengan language model, jika diasumsikan setiap kata adalah independen. Probabilitas gabungan (joint probability) untuk keseluruhan kalimat dapat direpresentasikan sebagai hasil perkalian dari probabilitas bersyarat (conditional probabilities) untuk setiap kata berdasarkan formula 1.
𝑃(𝑤1, 𝑤2,…𝑤𝑛) = ∏𝑛𝑖=1𝑃(𝑤𝑖) (1)
Dengan mempedomani suatu arti kata dapat ditentukan berdasarkan kata- kata konteks atau kata-kata yang ada disekelilingnya, maka prediksi urutan kata dapat dicari berdasarkan distribusi probabilitas dari urutan kata-kata pada korpus.
Metode ini dikenal dengan n-gram language model dimana probabilitas kata 𝑤𝑡 muncul setelah urutan kata 𝑤1… 𝑤𝑡−1 dari suatu kalimat W dapat dicari berdasarkan probabilitas kata sebelumnya. Dengan mempertimbangkan finite historical hypothesis maka kemunculan kata ke-n hanya tergantung dari 1 kata sebelumnya yaitu kata ke n-1, maka probabilitas gabungan dapat dicari dengan persamaan 2.
𝑃(𝑤1, 𝑤2,…𝑤𝑛) = ∏𝑛𝑖=1𝑃(𝑤𝑖|𝑤𝑖−𝑛+1, … , 𝑤𝑖−1) (2)
Model statistik bahasa dapat diwakili oleh probabilitas bersyarat dari kata berikutnya yang diberikan berdasarkan kata sebelumnya. Walaupun teori pencarian makna bahasa alami dengan metode distributional hypothesis ini banyak ditentang oleh ahli bahasa, namun setidaknya metode ini mampu memenuhi makna kata berdasarkan aliran structualist. Metode word embedding memprediksi kata konteks berdasarkan kata target (atau sebaliknya) dengan pendekatan neural network language model (NNLM). Proses word embedding dimulai dengan ekstraksi informasi pasangan kata konteks dan kata target dari korpus. Berdasarkan pasangan
kata ini, selanjutnya dilakukan proses feed forward neural network dengan beberapa layer. Proses optimasi dilakukan dengan back forward neural network untuk menghasilkan nilai bobot yang paling optimal. Nilai bobot ini yang selanjutnya menjadi word embedding yang dapat digunakan berulang kali sebagai word representation untuk berbagai task NLP.
Representasi kata yang dihasilkan dengan metode ini terbukti mampu menghasilkan relevansi semantik dan juga sintaksis yang didapatkan dari proses learning representation dengan language model (Bengio et al., 2003)(Wang, Zhou and Jiang, 2019).
Model word embedding dengan NNLM, awalnya di-propose oleh (Bengio et al., 2003). Terdapat persamaan antara NNLM dan n-gram LM yaitu memprediksi kata target berdasarkan n-1 kata sebelumnya. Perbedaan mendasar antara n-gram LM dan NNLM yaitu n-gram LM memprediksi berdasarkan distribusi statistik dan frekuensi kemunculan kata bersama (co-occurrence) sedangkan NNLM memprediksi kata berdasarkan perhitungan neural networks. Penelitian ini menjadi solusi untuk permasalahan dasar n-grams LM terutama dalam mengantisipasi curse of dimensionality. Arsitektur dari model NNLM ini dapat dilihat pada Gambar 2.1 berikut.
Gambar 2. 1 Arsitektur NNLM (Bengio et al., 2003)
Berdasarkan Gambar 2.2, dapat dilihat NNLM menggunakan 3 layer neural network yaitu input, hidden dan output layer. Pada input layer input x adalah urutan kata konteks dari kata target wt dalam satu kalimat. Kata konteks tersebut misalnya wt-1, wt−2,…, wt−n+1. Pada bagian input terdapat sebuah fungsi probabilitas mapping g yang direpresentasikan dengan |V| x m matriks C. Matriks C, pada baris ke i merupakan feature vektor C(i) untuk kata i. Dimana C merupakan sebuah fungsi non-linear conditional probability distribusi sejumlah kata V untuk kata setelah wt. Sedangkan V adalah jumlah vocabulary. Output dari fungsi g adalah vektor yang merupakan estimasi dari probabilitas P(wt = i | 𝑤1𝑡−1).
Probabilitas P ( wt |wt-1, …wt-n+1) ditentukan dengan mengimplementasikan fungsi non-linear softmax seperti pada persamaan 2.
P ( wt |wt-1, …wt-n+1) = 𝑒𝑦𝑤𝑡
∑ 𝑖𝑒𝑦𝑖 (2) Untuk y untuk dari arsitektur ini dapat dicari dengan persamaan 3.
y = b + Wx + U tanh (d + Hx) (3)
Dimana H adalah hidden layer, dan b adalah nilai bias untuk input layer, sedangkan d adalah bias untuk hidden layer. Untuk input x representasinya dapat dikalkulasikan seperti pada persamaan 4.
x = [C(wt−1), C(wt−2), ··· C(wt−n+1)] (4)
Walaupun metode NNLM yang diajukan oleh Bengio secara teori dapat mengatasi permasalahan dari n-grams LM, namun arsitektur NNLM menjadi rumit terutama pada komputasi antara layer proyeksi dan hidden layer.
2.2 Word Embedding
Pembentukan representasi kata secara kontinyu dengan neural networks, mulai menjadi fokus penelitian NLP dengan sasaran penelitian efisiensi komputasi dari NNLM. Penelitian yang dilakukan oleh (Mikolov et al., 2010) yaitu mengimplematasikan simple Recurrent Neural Network (RNN) atau dikenal juga dengan Elman network (Elman, 1990). Simple RNN lebih sederhana dari arsitektur NNLM oleh Bengio. RNN secara alami lebih cocok diterapkan untuk data tekstual karena RNN merupakan sekuensial input yang dari output terdahulu, dalam hal ini adalah urutan kata target dan kata konteks. Pada pembentukan word embedding, arsitektur dari simple RNN diimplementasikan untuk mempelajari language model, sehingga arsitekturnya lebih dikenal dengan RNNLM. Arsitektur RNNLM dapat dilihat pada Gambar 2.2.
Gambar 2. 2 Arsitektur Simple RNN (Mikolov et al., 2011)
Formula dari RNNLM dapat dilihat pada persamaan 5.
𝑥(𝑡) = 𝑤(𝑡) + 𝑠(𝑡 − 1) (5) 𝑠𝑗(𝑡) = 𝑓(∑ 𝑥𝑖 𝑖(𝑡)𝑢𝑗𝑖 (6) 𝑦𝑘(𝑡) = 𝑔 (∑ 𝑠𝑗 𝑗((𝑡)𝑣𝑘𝑗) (7) Dimana f (z) adalah fungsi aktivasi sigmoid:
𝑓(𝑧) = 1
1+ 𝑒−𝑧 (8) dan g (z) adalah fungsi aktivasi softmax seperti pada persamaan 2.
Selanjutnya, penelitian yang dilakukan oleh (Tomas Mikolov et al. 2013) menghasilkan arsitektur yang diberi nama new log linear. Arsitektur new log linear, lebih sederhana dibandingkan NNLM dimana pada arsitektur ini hidden layer C pada input x dihapus. Arsitektur ini juga menghilangkan fungsi non linear tanh pada hidden layer h. Sehingga proses pada hidden layer h merupakan proses perhitungan linear. Dapat dikatakan bahwa model ini merupakan modifikasi dari NNLM, dengan menghapus layer proyeksi C. Pada new log linear yang ditawarkan ini terdapat dua pilihan arsitektur Continuous Bag of Word (CBOW) dan Skip
Gram. Arsitektur ini lebih efisien secara kompleksitas komputasi pada proses learning dibandingkan NNLM. Hal ini karena penelitian ini mengimplementasikan hirarki softmax dan negatif sampling untuk mengganti fungsi original softmax. Pada hirarki softmax, vocabulary direpresentasikan sebagai Huffman Binary Tree. Huffman Tree menetapkan kode biner yang pendek untuk kata-kata yang sering muncul, dan hal ini mampu meminimalisir jumlah output yang harus dievaluasi. Secara matematis, representasi vocabulary menjadi bentuk Huffman Binary Tree mampu mereduksi jumlah unit output sekitar log2(V), hal ini seperti yang telah dibuktikan oleh penelitian (Mikolov et al., 2011).
Negatif sampling merupakan solusi untuk mengurangi kompleksitas fungsi original softmax. Pada softmax, untuk semua kata yang bukan target akan di anggap salah, sehingga ada 99% kemungkinan kata yang dipilih salah namun tetap harus dilakukan perhitungan. Motivasi negatif sampling yaitu mengurangi perhitungan dengan cara hanya mengambil beberapa contoh saja tanpa harus menghitung keseluruhan vocabulary.
Perbedaan mendasar antara algoritma CBOW dan Skip Gram yaitu pada layer input dan layer output. Pada CBOW input berupa kata konteks dan output adalah memprediksi kata target, sedangkan pada metode Skip Gram output yang diprediksi adalah kata konteks berdasarkan input kata target. Arsitektur kedua arsitektur ini dapat dilihat pada Gambar 2.3.
Gambar 2. 3 Arsitektur word2vec CBOW (kiri) dan Skip Gram (kanan)
Seperti yang ditunjukkan pada Gambar 2.3, kedua model terdiri dari tiga bagian yaitu input layer, hidden layer dan output layer. Terdapat beberapa hyper- parameter seperti window size yang merupakan jumlah kata konteks. Pada contoh Gambar 2.3, nilai window size = 2 berarti kata konteks yang diambil yaitu 2 kata ke kiri dan dua kata ke kanan. Kata tersebut dilambangkan dengan wt − 2, wt − 1, wt + 1
dan wt + 2 dari kata target wt. Jika w1, w2,…, wN, merupakan urutan kata-kata korpus, maka formula arsitektur CBOW untuk memaksimalkan probabilitas dapat dihitung dengan persamaan 9.
1
𝑁∑𝑁𝑡=1∑−𝑐≤𝑗≤𝑐,𝑗≠0𝑙𝑜𝑔𝑝(𝑤𝑡|𝑤𝑡+1) (9)
Dimana c adalah ukuran window size. Dalam menghitung p(wt|wt+j) CBOW menggunakan fungsi softmax seperti persamaan 2, sehubungan exp(x) = ex maka fungsi softmax dapat ditulis juga seperti persamaan 10.
p = (wt+j|wt) =∑ exp (𝑠𝑖𝑚(𝑤𝑡+𝑗,𝑤𝑡)
exp (𝑠𝑖𝑚(𝑤′,𝑤𝑡))
𝑤′∈𝑉 (10) Dimana w’ adalah kata yang terdapat pada vocabulary V.
Selanjutnya nilai bobot dioptimasi dengan perhitungan Stochastic Gradient Descent (SGD) dan juga learning rate.
CBOW
Skip Gram
Penelitian lainnya yaitu dilakukan oleh (Pennington, Socher and Manning, 2014), dengan mengkritik bahwa word2vec hanya berfokus pada informasi yang diperoleh dari kata konteks secara lokal tanpa menghiraukan informasi statistik secara keseluruhan. Sebuah algoritma yaitu GloVe yang membentuk word embedding dengan informasi konteks lokal dan juga keseluruhan (global). Nilai embedding GloVe berdasarkan matriks co-occurence global, setiap elemen Xij
dalam matriks mewakili frekuensi kata wi dan kata wj muncul bersamaan dalam context window tertentu. Untuk membangun hubungan perkiraan antara embedding kata dan matriks co-ocurrence, Pennington et al. usulkan rumus berikut untuk mendekati hubungan antara dua kata:
Dimana 𝑤⃑⃑⃑⃑ dan 𝑤𝑖 ⃑⃑⃑⃑ adalah corresponding embedding dari w𝑗 i dan wj, bi dan bj
adalah nilai parameter offset. Bila dilihat dari sisi perhitungan loss function, nilai word embedding untuk model Glove dapat dicari dengan persamaan 12.
𝐽 = ∑ 𝑓(𝑋𝑖𝑗)(𝑊𝑖𝑇𝑊𝑗
𝑉
𝑖,𝑗=1
+ 𝑏𝑖+ 𝑏𝑗− log (𝑋𝑖𝑗))2
Perbandingan formula untuk pembentukan word embedding berdasarkan kata konteks dengan berbagai model arsitektur dapat dilihat pada Tabel 2.1.
Tabel 2. 1 Pembentukan Word Embedding Berdasarkan Kata Konteks Model Formula untuk Word Embedding
NNLM tanh (𝑑 + 𝐻[𝑒(𝑤𝑖−𝑛); … 𝑒(𝑤𝑖−2); 𝑒(𝑤𝑖−1)])
CBOW 1
2[𝑒(𝑤𝑖−𝑛) + ⋯ + 𝑒(𝑤𝑖−1) + 𝑒(𝑤𝑖+1) + ⋯ 𝑒(𝑤𝑖−𝑛) ] Skip Gram 𝑒(𝑤𝑗)𝑖 − 𝑛 ≤ 𝑗 ≤ 𝑖 − 1 𝑎𝑡𝑎𝑢 𝑖 + 1 ≤ 𝑗 ≤ 𝑖 + 𝑛 GloVe 𝑒(𝑤𝑗)𝑖 − 𝑛 ≤ 𝑗 ≤ 𝑖 − 1 𝑎𝑡𝑎𝑢 𝑖 + 1 ≤ 𝑗 ≤ 𝑖 + 𝑛
(11)
(12)
2.3 Word Embedding dengan Tambahan Informasi
Secara general, word embedding menggunakan korpus yang berupa kumpulan teks mentah tanpa memerlukan proses anotasi. Studi word embedding seperti yang diimpelementasikan pada model word embedding original word2vec (Mikolov, Yih and Zweig, 2013), dan GloVe (Pennington, Socher and Manning, 2014). Namun model ini tidak dapat mengantisipasi OOV untuk kata yang tidak terdapat pada training korpus. Beberapa penelitian terdahulu berhipotesis bahwa performansi word embedding dapat ditingkatkan jika diberikan tambahan informasi. Beberapa penelitian membentuk word embedding menggunakan korpus yang telah dianotasi dalam membentuk word embedding. Anotasi korpus meliputi informasi linguistik beragam seperti POS tag, dependency parsing, NER dan sebagainya. Penelitian oleh (Levy and Goldberg, 2014a) menggunakan anotasi korpus untuk membentuk word embedding. Penelitian ini merupakan ekstensi dari model arsitektur word embedding word2vec oleh penelitian (Mikolov et al., 2013).
Model ini diperkenalkan dengan nama w2vf-deps. Model arsitektur w2vf-deps mirip dengan arsitektur Skip Gram yang dikombinasikan negatif sampling namun mengganti layer kata konteks dengan korpus yang sudah dianotasi dengan informasi dependency parsing. Penelitian ini menggunakan metode parsing oleh penelitian (Goldberg and Nivre, 2012, 2013) dimana hasil parsing untuk dependency sintaksis terbukti cepat dengan akurasi tinggi. Penelitian ini menggunakan tagset dari Standford Tagger (Toutanova et al., 2003) dan label yang digunakan dari penelitian (de Marneffe and Manning, 2008). Hasil dari penelitian ini, word embedding yang dihasilkan dari korpus dengan tambahan informasi
dependency parsing tidak cocok diterapkan untuk relasi berdasarkan topik, namun baik untuk relasi fungsional similarity.
Penelitian oleh (Bansal, Gimpel and Livescu, 2014), membentuk word embedding dengan tambahan informasi dependency parsing dengan asumsi bahwa kata dengan parents dan children yang sama memiliki kedekatan relasi pada ruang embedding. Penelitian ini menggunakan ukuran window size kecil. Penelitian ini mengungkapkan pengaturan ukuran window size berpengaruh terhadap jenis task NLP yang ingin di implementasikan. Ukuran window size besar lebih cocok untuk implementasi berdasarkan topically-related, sedangkan untuk ukuran window size kecil lebih cenderung embedding yang sama memiliki POS tag yang sama juga.
Penelitian ini membutuhkan proses untuk melabel setiap kalimat pada korpus dengan label child, parent, grandparent.
Penelitian oleh (Abka, 2017) menggunakan word embedding untuk POS tagging Bahasa Indonesia. Word embedding yang dihasilkan dari 4 model arsitektur yaitu CBOW, Skip Gram, GloVe. Input layer berupa proses concatenation antara kata target dan kata konteksnya. Outputnya adalah POS tagger untuk kata target.
Performansi terbaik di peroleh oleh model GloVe dan diikuti oleh Skip Gram.
Penelitian oleh (Manik et al., 2019) membentuk word embedding dengan tambahan layer untuk informasi morfologi dan juga informasi identifikasi huruf kapital seperti yang dipropose oleh penelitian (Collobert, 2011). Penelitian ini menggunakan metode stemming oleh (Adriani et al., 2007) untuk memisahkan kata dasar dan afiks. Selanjutnya untuk kemungkinan morfologi dan fitur kapital di bentuk seperti model one-hot-encoding. Berdasarkan hal ini makan proses derivasi dan
infleksional dapat dilihat berdasarkan morfologi yang terpilih. Karena afiks dapat menunjukkan gramatikal kategori.
Penelitian oleh (Xu and Liu, 2017) merupakan metode pembentukan word embedding dengan menyertakan gabungan informasi morfologi secara implisit.
Informasi morfologi yang dimaksud yaitu arti dari morfem yang diklasifikasikan sebagai set makna dan dibentuk embedding tersendiri. Penelitian ini berbeda dengan penelitian lainnya yang menggabungkan informasi morfem kata secara eksplisit, yaitu kata diurai berdasarkan morfemnya atau disebut dengan subword dan setiap subword menghasilkan suatu embedding tersendiri. Input kata pada algoritma word embedding selanjutnya menggabungkan subword pembentuk kata ini. Pada penelitian (Xu and Liu, 2017), informasi yang dimasukkan pada embedding kata bukan subword tetapi makna dari subword tersebut. Beberapa morfem terutama untuk Bahasa Inggris dapat memiliki arti atau makna yang sama.
Sebagai contoh untuk morfem bahasa Inggris, kata yang dimulai dengan awalan "a"
atau "an" memiliki arti dari "tidak" dan "tanpa" seperti "asexual" dan "annarchy".
Selain itu, kata-kata yang diakhiri dengan sufiks “able” atau “ible” memiliki arti
“capable” seperti “editible” dan "visible". Berdasarkan hal ini maka informasi morfem berupa subword dan arti dari morfem itu sendiri bermanfaat untuk embedding. Model yang menggunakan subword sebagai morfem embedding menghasilkan kata dengan morfem sama memiliki kedekatan di vector space.
Penelitian (Xu and Liu, 2017) mengobservasi morfem pada bahasa Inggris dengan korpus berita sebesar 1,7 GB yang terdiri dari 500 juta token dan 600.000 vocabularies. Hasil dari penelitian menunjukkan metode ini mengungguli metode word embedding standard seperti CBOW, Skip Gram dan Glove. Model ini cocok
diterapkan untuk bahasa dengan sumber linguistik terbatas tetapi memiliki banyak jenis morfologi (infleksional).
2.4 Subword Embedding
Subword Embedding merupakan pembentukan word embedding dengan melakukan segmentasi pada kata menjadi subword atau sub katanya. Metode subword embedding bertujuan untuk menjadi solusi dari OOV. Salah satu subword embedding adalah fastText. FastText merupakan ekstensi dari model skip gram word2vec. Terdapat dua model fastText yaitu sebagai kategorizer (Joulin et al., 2017) dan juga word vector representation (Bojanowski et al. 2017). Pada pembentukan word embedding, tahap awal fastText mengimplementasikan word2vec dengan algoritma Skip Gram untuk menghasilkan word embedding level kata untuk semua kata yang ada di vocabulary. Tahap kedua fastText melakukan segmentasi kata menjadi bentuk subword berdasarkan jumlah karakter n-gram yang telah diinisialisasi. Secara umum fastText menggunakan 3 – 6 karakter. Pada proses segmentasi menjadi n-gram karakter, fastText awalnya menambah bracket ‘<’
untuk awal kata dan ‘>’ untuk akhir kata. Selanjutnya karakter n-gram digenerate berdasarkan panjang n. misalnya n = 3 maka dilakukan sliding windows untuk kata tersebut dengan menghasilkan subword dengan panjang 3 karakter. Misalnya untuk kata ‘makan’ menghasilkan <makan> : <ma, mak, aka, kan, an>. Selanjutnya semua subword yang dihasilkan untuk setiap kata yang ada di vocabulary di encoding dengan metode hashing Fowler-Noll-Vo. Untuk nilai encoding kata utuh dihasilkan dengan cara concatenation dari semua nilai subword ditambah dengan nilai word embedding yang dihasilkan pada tahap pertama. Untuk mengantisipasi OOV, setiap
kata yang tidak ada di vocabulary, maka nilai encoding kata di hasilkan dari summation n-gram karakter saja tanpa menyertakan embedding dari kata lengkap.
Hasil evaluasi fastText menunjukkan fastText lebih efisien dari sisi waktu training dan juga terjadi peningkatan performansi dibandingkan dengan word2vec biasa.
MorphRNN merupakan penelitian oleh (Luong, Socher and Manning, 2013) menambahkan informasi morfologi berupa prefiks dan sufiks. Dengan masing- masing morfem kata sebagai unit dasar yang diimplementasikan dengan model segmentasi morfologi dan komposisinya dengan metode Recursive Neural Network (RNNs) (Socher et al., 2011) dan Neural Language Model. Penelitian ini tidak menggabungkan vektor morfem dengan proses concatenation namun mengkombinasikan morfem-morfem ini dengan RNNs yang menangkap komposisi morfologi. Awalnya morfem di modelkan sebagai vektor dengan angka real, yang digunakan untuk membentuk kata yang lebih kompleks. Sebuah dictionary untuk analisis morfem ini dibangun berdasarkan representasinya.
Konklusi untuk perkembangan representasi kata untuk NLP beserta keterbatasan dari masing-masing model dapat dilihat pada Gambar 2.4.
Gambar 2. 4 Perkembangan Representasi Kata NLP
Untuk membentuk subword embedding diperlukan beberapa tahapan awal seperti segmentasi kata, encoding subword dan juga concatenation nilai subword embedding kata menjadi encoding kata yang utuh. Beberapa peneliti terdahulu mengenai hal ini dapat dilihat pada penjelasan berikut ini.
2.5 Segmentasi Kata
Segmentasi adalah metode untuk membagi suatu token atau kata menjadi bagian yang lebih kecil. Segmentasi terdiri berbagai metode seperti memisahkan kata berdasarkan karakter, imbuhan dan lain sebagainya. Penelitian oleh (Cotterell et al., 2015) membentuk model segmentasi dengan Labeled Morphological Segmentation (LMS) dengan algoritma semi Markov Models seperti yang
juga dengan nama CHIPMUNK. CHIPMUNK membagi kata berdasarkan segmentasi morfologinya yaitu morfem dengan cara membentuk label tagset universal secara hierarki untuk melabel morfem hasil dari segmentasi. CHIPMUNK menjadi salah satu opsi karena resources ini sudah menyediakan model segmentasi untuk Bahasa Indonesia. Pada Bahasa Indonesia di model CHIPMUNK jumlah afiks sebanyak 6 buah yaitu -kau, -an, -nya, -ku, -mu dengan jumlah vocabulary sebanyak 35.269. Metode CHIPMUNK memanfaatkan ASPELL dictionary untuk spell checker dan juga identifikasi kata majemuk yang terdapat pada 6 bahasa yang diobservasi.
Penelitian lain untuk segmentasi kata berdasarkan morfologinya dilakukan oleh (Creutz and Lagus, 2007). Model pada penelitian ini diberi nama Morfessor.
Morfessor merupakan unsupervised morfologi segmentasi dari data teks berbasis probabilitas. Morfesor dapat menghandel jenis bahasa infleksional dan memiliki banyak kata majemuk.
Byte Pair Encoding (BPE) pertama sekali diperkenalkan oleh peneliti bernama Gage tahun 1994 (Gage, 1994) untuk data kompresi. Ide dari data kompresi yaitu motivasi untuk optimasi efisien penggunaan memori penyimpanan.
Secara general algoritma BPE mengganti pasangan bytes berurutan yang paling sering muncul dengan single byte yang baru sehingga media penyimpanan lebih kecil. Kompresi ini berulang sampai tidak ada lagi pasangan bytes yang bisa digantikan dengan bytes baru atau tidak ada lagi bytes yang belum digunakan.
Algoritma BPE selanjutnya membangun sebuah tabel yang berisi informasi pair bytes antara pasangan bytes awal dan byte subtitusinya. Penelitian oleh (Sennrich, Haddow and Birch, 2016) mengimplementasikan BPE untuk NLP. Penelitian ini
memanfaatkan BPE untuk segmentasi kata menjadi bagian lebih kecil yaitu subword dengan tujuan untuk translasi. Penelitian ini meyakini bahwa translasi yang dilakukan di level subword dapat lebih meningkatkan performansi translasi.
Penelitian oleh (Heinzerling and Strube, 2019) menghasilkan subword pretrained embedding untuk 275 bahasa termasuk Bahasa Indonesia yang disebut dengan BPEmb. Evaluasi yang digunakan dengan fine-grained entity typing, tetapi evaluasi untuk pre-trained BPEemb ini tidak termasuk untuk Bahasa Indonesia.
Penelitian oleh (Pinter, Guthrie and Eisenstein, 2017) membentuk subword word embedding tanpa harus men-retraining embedding. Penelitian ini memanfaatkan pre-trained word vektor berbasis kata yang telah ada. Penelitian ini melakukan word embedding karakter level untuk semua vocabulary yang ada pada korpus dan selanjutnya dilakukan training dan optimasi berdasarkan hasil dari word embedding yang telah dihasilkan. metode yang di gunakan adalah WordType Character Bi-LSTM.
Penelitian oleh (Zhu, Vulić and Korhonen, 2019) merupakan studi yang fokus dalam mengobservasi variasi dua komponen penting subword-level yaitu segmentasi kata dan juga fungsi komposisi subword. Hasil dari penelitian ini menunjukkan bahwa tidak ada satu konfigurasi yang cukup umum yang dapat mencakup keseluruhan bahasa. Setiap bahasa pasti memiliki keunikan tersendiri.
Hasil dari penelitian ini menunjukkan bahwa segmentasi unsupervised seperti BPE (Heinzerling and Strube, 2019) dan morfessor memiliki memiliki performansi yang sama baiknya dengan supervised segementasi CHIPMUNK. Penelitian ini menunjukkan perbedaan task evaluasi dan bahasa membutuhkan konfigurasi
subword yang berbeda-beda untuk menghasilkan performa terbaik. Hal ini berarti membutuhkan tuning yang tergantung dengan jenis bahasa.
2.6 Linguistik Bahasa Indonesia
Berdasarkan jenis tipologi bahasa Indonesia tergolong sebagai bahasa aglutinatif (agglutinative). Tipologi adalah cara membagi bahasa berdasarkan struktur morfologinya. Pada bahasa dengan jenis aglutinatif, afiksasi mempunyai peranan penting pada proses morfologi dimana prefiks, sufiks ditambahkan pada morfem dasar dan membentuk kata baru (Fromkin, Rodman and Hyams, 2014).
Beberapa contoh afiks contoh derivasi afiks pada bahasa Indonesia yaitu {meng-}
{-i}, {ter-}, {ber-}, {ber-an}, dan {-kan}. Bahasa Indonesia menganut Subjek Verb Objek (SVO). Walaupun tujuan membagi bahasa berdasarkan tipologi untuk mencari persamaan antar bahasa namun setiap bahasa tetap memiliki keunikan tersendiri walaupun berada dalam satu tipologi yang sama. Sebagai contoh bahasa yang juga tergolong bahasa aglutinatif adalah bahasa Turki, bahasa Jepang dan bahasa Finlandia namun dari segi morfologi dan tata bahasa sangat berbeda dengan bahasa Indonesia yang juga merupakan jenis bahasa aglutinatif. Untuk bahasa dengan jenis aglutinatif, pemisahan imbuhan dari kata dasar merupakan proses penting. Segmentasi morfologi terbukti berguna untuk machine translation, sentimen analisis.
2.7 Sumber Daya Linguistik Bahasa Indonesia
Beberapa penelitian terdahulu membentuk word embedding dengan menambahkan informasi tambahan seperti Part of Speech (POS). POS adalah
pembagian kelas kata pada NLP seperti kata benda, kata sifat dan kata kerja.
Metode ini membutuhkan sumber daya lingustik eksplisit seperti POS Tagger, Name Entity Recognation (NER) dan lain sebagainya. Suatu POS tag dibentuk berdasarkan kelas kata atau dikenal dengan istilah treebank atau tagset. Beberapa model tagset dalam bahasa Inggris tergolong lengkap dan menjadi acuan untuk penelitian linguistik bahasa Inggris seperti Penn Tree bank (Marcus et al., 1993;
Taylor, Marcus and Santorini, 2003). Untuk NER beberapa metode ini memungkinkan setiap kata yang memiliki kelas kata dengan arti yang mirip memiliki representasi teks yang mendekati sama. Tujuan dari pengklasifikasian setiap kata berdasarkan kelas kata adalah untuk mengurangi dimensi word vectors sehingga dapat menghasilkan waktu komputasi lebih efisien, namun permasalahan dari metode ini, dibutuhkan sumber linguistik yang lengkap dan juga anotasi manual yang membutuhkan bantuan manusia. Hal ini menyebabkan metode ini menjadi mahal dan menyita waktu. Selain itu metode ini tidak tepat diterapkan untuk pembentukan word vectors untuk bahasa dengan sumber daya linguistik yang minim. Permasalahan untuk bahasa Indonesia, penelitian di bidang NLP tidak saling berkesinambungan (Adriani and Manurung, 2008), setiap peneliti cenderung membangun hal yang sama dengan model dan format yang berbeda. Beberapa penelitian dalam membangun sumber daya linguistik bahasa Indonesia telah dilakukan seperti POS tagger (Rashel, Luthfi and Manurung, 1995; Wicaksono, 2010; Fu et al., 2018; Handrata et al., 2019), chunking (Arman et al., 2013) dan NER (Luthfi, Distiawan and Manurung, 2014; Wibawa and Purwarianti, 2016).
Sumber linguistik penting lainnya adalah algoritma stemming dan stop word list.
Algoritma stemming adalah proses untuk mengambil kata dasar pada kata