PADA ALGORITMA KNN
TESIS
CUT DESY ARISANDI NIM. 177038023
PROGRAM STUDI MAGISTER (S-2) TEKNIK INFORMATIKA FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA MEDAN
2021
i
ANALISIS METODE FUZZY C-MEANS DAN PEARSON CORRELATION UNTUK REDUKSI DATA
PADA ALGORITMA KNN
TESIS
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Megister Teknik Informatika
CUT DESY ARISANDI NIM. 177038023
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
2021
PERNYATAAN
ANALISIS METODE FUZZY C-MEANS DAN PEARSON CORRELATION UNTUK REDUKSI DATA PADA ALGORITMA KNN
Saya mengakui bahwa tesis ini adalah hasil karya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 16 Agustus 2021
Cut Desy Arisandi NIM. 177038023
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai sivitas Akademika Universitas Sumatera Utara, saya yang bertanda tangan dibawah ini :
Nama : Cut Desy Arisandi
NIM : 177038023
Program Studi : Magister Teknik Informatika Jenis Karya Ilmiah : Tesis
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Sumatera Utara Hak Bebas Royalti Non-Ekslusif (Non-Ekclusive Royalti Free Right) atas tesis saya yang berjudul:
ANALISIS METODE FUZZY C-MEANS DAN PEARSON CORRELATION UNTUK REDUKSI DATA PADA ALGORITMA KNN
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non- Eksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media, menformat, mengelola dalam bentuk database, merawat dan mempublikasikan tesis saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis dan sebagai pemegang dan/atau sebagai pemilik hak cipta.
Demikianlah pernyataan ini dibuat dengan sebenarnya.
Medan, 16 Agustus 2021
Cut Desy Arisandi NIM. 177038023
RIWAYAT HIDUP
DATA PRIBADI
Nama Lengkap : Cut Desy Arisandi, S.Kom Tempat dan Tanggal Lahir : Medan, 02 Desember 1991
Alamat Rumah : JL. Air Bersih No. 34 C Medan 20218 Telepon/Faks/HP : 082361941949
Email : [email protected]
Instansi Tempat Bekerja : Pengadilan Negeri Banda Aceh Alamat Kantor : JL. Cut Meutia No. 23 Banda Aceh
DATA PENDIDIKAN
SD : Negeri 068231 Medan TAMAT : 2003 SMP : Negeri 3 Medan TAMAT : 2006 SMA : Swasta Eria Medan TAMAT : 2009 D3 : Teknik Informatika Universitas Sumatera Utara TAMAT : 2012 S1 : Ilmu Komputer Universitas Sumatera Utara TAMAT : 2016 S2 : Teknik Informatika Universitas Sumatera Utara TAMAT : 2021
LEMBAR PANITIA PENGUJI TESIS
Telah di uji pada
Tanggal :16 Agustus 2021
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Muhammad Zarlis Anggota : 1. Dr. Syahril Efendi, S.Si., M.IT
2. Prof. Dr. Tulus, Vor.Dipl.Math.M.Si 3. Dr. Poltak Sihombing, M.Kom
vii
UCAPAN TERIMA KASIH
Puji syukur kehadirat Allah SWT yang telah memberikan kepada kita nikmat dan anugerah yang luar biasa sehingga penulis dapat menyelesaikan tesis yang berjudul “ANALISIS METODE FUZZY C-MEANS DAN PEARSON CORRELATION UNTUK REDUKSI DATA PADA ALGORITMA KNN”, Tesis ini merupakan salah satu syarat untuk memperoleh gelar Magister Teknik Informatika pada program studi S-2 Teknik Informatika Universitas Sumatera Utara.
Pada kesempatan ini penulis mengucapkan terima kasih kepada semua pihak yang telah membantu penulis dalam menyelesaikan tesis ini, antara lain:
1. Bapak Prof. Dr. Runtung Sitepu, S.H., M.Hum., selaku Rektor Universitas Sumatera Utara.
2. Bapak Prof. Dr. Opim Salim Sitompul., selaku Dekan Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
3. Bapak Prof. Dr. Muhammad Zarlis., selaku Ketua Program Studi Pascasarjana (S-2) Teknik Informatika Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara sekaligus juga selaku Dosen Pembanding/Penguji 1 yang selama ini telah memberikan banyak saran, serta pembelajaran yang berharga bagi penulis sebagai arahan untuk menyelesaikan penulisan tesis ini.
4. Bapak Prof. Dr. Tulus, Vor.Dipl.Math.M.Si., selaku Pembimbing I yang telah memberikan banyak pelajaran yang berharga dan motivasi kepada penulis dalam penyusunan tesis ini.
5. Bapak Dr. Syahril Efendi, S.Si., M.IT., selaku Sekretaris Program Studi Pascasarjana (S-2) Teknik Informatika Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara sekaligus juga Selaku Pembimbing 2 yang telah memberikan arahan dan motivasi yang berharga bagi penulis dalam menyelesaikan penulisan tesis ini.
6. Bapak/Ibu Dosen Program Studi Pascasarjana (S-2) Teknik Informatika Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara
viii
7. Seluruh Civitas Akademika, Staf, Pegawai, teman-teman, adik-adik, kakak- kakak di Program Studi Pascasarjana (S-2) Teknik Informatika Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara, yang telah membantu penulis dalam menyelesaikan penelitian dan juga telah mewarnai hari-hari indah penulis selama menjalani masa kuliah.
8. Ibunda Elidawati dan ayahanda T. Idris serta Keluarga yang tercinta, karena pengorbanan yang sungguh luar biasa serta cinta kasih dan do’a mereka yang tidak henti-hentinya sehingga penulis dapat mengenyam dan menyelesaikan studi magister serta menyelesaikan tesis ini dengan baik.
9. Sahabat-sahabat di MTI KOM A 2017 yang telah sama-sama berjuang semasa kuliah.
10. Serta Rekan-rekan kerja di Kantor yang tak henti memberikan semangat untuk menyelesaikan studi magister serta tesis ini dengan baik.
Penulis tetap menyadari banyaknya kekurangan dalam penulisan tesis ini.
Oleh sebab itu saran dan kritik sangat dinantikan dan diterima dengan sikap terbuka. Dan pada akhirnya penulis berharap karya tulis ini dapat digunakan sebagai referensi dan dimanfaatkan dengan baik.
Akhirnya kepada Allah jugalah kita menyerahkan segalanya semoga penulisan tesis ini dapat bermanfaat dan terima kasih.
Medan, 16 Agustus 2021 Penulis,
Cut Desi Arisandi NIM. 177038023
ABSTRAK
Algoritma kNN merupakan metode di dalam data mining yang digunakan untuk proses pengklasifikasian data yang cukup populer. Metode kNN tradisional memiliki beberapa kelemahan, seperti: komputasi yang lambat ketika dimensi pada data training tergolong tinggi dan ketergantungan yang kuat pada jumlah data training.
Penelitian ini melakukan pengujian reduksi data pada algoritma kNN menggunakan metode fuzzy c-means clustering dan Pearson correlation pada data pelatihan sebelum proses klasifikasi data dilakukan. Algoritma FCM digunakan dalam proses clustering data untuk memperoleh titik pusat cluster dan kemudian dilakukan pemilihan data training dengan tingkat korelasi terendah menggunakan persamaan Pearson correlation untuk selanjutnya direduksi. Hasil dari kedua metode tersebut berupa data hasil reduksi yang selanjutnya akan dijadikan data training dengan dimensi yang lebih kecil untuk proses klasifikasi pada algoritma kNN. Berdasarkan penelitian yang dilakukan dapat diambil kesimpulan bahwa akurasi klasifikasi data pada algoritma kNN dengan reduksi data menggunakan algoritma fuzzy c-means clustering dan Person correlation memperoleh akurasi rata-rata sebesar 92,22% dan mengalami peningkatan sebesar 2,7% dibandingkan dengan hasil klasifikasi pada algoritma kNN tanpa reduksi data dengan perolehan akurasi rata-rata sebesar 89,52%. Selain itu, penggunaan metode reduksi data yang diusulkan pada algoritma kNN dapat mereduksi data pelatihan menjadi dimensi yang lebih kecil dengan rata-rata persentase reduksi sebesar 19,22%.
Kata Kunci: Reduksi Data, Algoritma kNN, Fuzzy C-Means Clustering, Pearson Correlation
ABSTRACT
The kNN algorithm is a method in data mining that is used for the data classification process which is quite popular. The traditional kNN method has several disadvantages, such as: slow computation when the dimensions of the training data are high and a strong dependence on the amount of training data. This study tested data reduction on the kNN algorithm using the fuzzy c-means clustering and Pearson correlation method on the training data before the data classification process was carried out. The FCM algorithm is used in the data clustering process to obtain the center point of the cluster and then select the training data with the lowest correlation level using the Pearson correlation equation for further reduction. Based on the research conducted, it can be concluded that the accuracy of data classification in the kNN algorithm with data reduction using the fuzzy c-means clustering algorithm and Person correlation obtained an average accuracy of 92.22% and an increase of 2.7%
compared to the classification results in kNN algorithm without data reduction with an average accuracy gain of 89.52%. In addition, the use of the data reduction method proposed in the kNN algorithm can reduce the training data into smaller dimensions with an average reduction percentage of 19.22%.
Keywords: Data Reduction, kNN Algorithm, Fuzzy C-Means Clustering, Pearson Correlation
xi DAFTAR ISI
HALAMAN JUDUL ... i
PERSETUJUAN ... ii
PERNYATAAN ... iii
PERSETUJUAN PUBLIKASI ... iv
RIWAYAT HIDUP ... v
LEMBAT PANITIA PENGUJI TESIS ... vi
UCAPAN TERIMA KASIH ... vii
ABSTRAK ... ix
ABSTRACT ... x
DAFTAR ISI ... xi
DAFTAR TABEL ... xiii
DAFTAR GAMBAR ... xiv
BAB 1 : PENDAHULUAN 1.1. Latar Belakang Masalah ... 1
1.2. Rumusan Masalah ... 3
1.3. Batasan Masalah ... 3
1.4. Tujuan Penelitian ... 4
1.5. Manfaat Penelitian ... 4
BAB 2 : LANDASAN TEORI 2.1. Data Mining ... 5
2.2. Knowledge Discovery in Database (KDD) ... 6
2.3. Klasifikasi ... 9
2.4. K-Nearest Neighbor ... 10
2.5. Fuzzy C-Means Clustering (FCM) ... 12
2.6. Pearson Correlation ... 14
2.7. Penelitian-Penelitian Terkait ... 16
BAB 3 : METODOLOGI PENELITIAN 3.1. Tahapan-Tahapan Penelitian ... 18
3.2. Data yang Digunakan ... 19
3.3. Langkah-Langkah Penelitian ... 20
xii
3.6. Perhitungan Metode Pearson Correlation ... 27
3.7. Perhitungan Algoritma kNN ... 29
3.8. Perhitungan Akurasi Klasifikasi Data ... 31
BAB 4 : HASIL DAN PEMBAHASAN 4.1. Pendahuluan ... 33
4.2. Hasil Pengujian Metode yang Digunakan ... 33
4.2.1. Hasil Pengujian Algoritma kNN tanpa Reduksi Data ... 33
4.2.2. Hasil Pengujian Algoritma kNN dengan Reduksi Data ... 34
A. Pengujian Algoritma kNN dengan Reduksi Data pada Dataset I ... 39
B. Pengujian Algoritma kNN dengan Reduksi Data pada Dataset II ... 41
C. Pengujian Algoritma kNN dengan Reduksi Data pada Dataset III ... 42
4.3. Pembahasan ... 43
BAB 5 : KESIMPULAN DAN SARAN 5.1. Kesimpulan ... 47
5.2. Saran ... 47
DAFTAR PUSTAKA ... 48
xiii
DAFTAR TABEL
Tabel 2.1. Penelitian-Penelitian Terkait ... 16
Tabel 3.1. Dataset yang Digunakan ... 19
Tabel 3.2. Data Sebelum Normalisasi ... 22
Tabel 3.3. Nilai Maksimum dan Minimum Data ... 23
Tabel 3.4. Data Hasil Normalisasi ... 25
Tabel 3.5. Data Pelatihan ... 25
Tabel 3.6. Matriks Fuzzy Pseudo-Partition ... 26
Tabel 3.7. Hasil Komputasi Cluster I ... 26
Tabel 3.8. Hasil Komputasi Cluster II ... 26
Tabel 3.9. Titik Pusat Cluster Data ... 27
Tabel 3.10. Nilai Keanggotaan dan Cluster ... 27
Tabel 3.11. Nilai Final Cluster ... 27
Tabel 3.12. Data Pelatihan ... 28
Tabel 3.13. Titik Pusat Cluster Data ... 28
Tabel 3.14. Jarak Korelasi Data Pelatihan dengan Titik Pusat Cluster ... 28
Tabel 3.15. Data Pelatihan Baru ... 29
Tabel 3.16. Data Pelatihan dan Data Pengujian ... 30
Tabel 3.17. Hasil Perhitungan Jarak Data ... 31
Tabel 3.18. Hasil Klasifikasi Data Pengujian dengan kNN ... 31
Tabel 3.19. Kesamaan Hasil Klasifikasi ... 32
Tabel 4.1. Hasil Pengujian Klasifikasi Data dengan kNN ... 34
Tabel 4.2. Data Pelatihan pada Dataset I ... 35
Tabel 4.3. Titik Pusat Cluster pada Dataset I ... 38
Tabel 4.4. Data yang Direduksi pada Dataset I ... 38
Tabel 4.5. Hasil Klasifikasi Dataset I dengan kNN dan Reduksi Data ... 40
Tabel 4.6. Hasil Klasifikasi Dataset II dengan kNN dan Reduksi Data ... 41
Tabel 4.7. Hasil Klasifikasi Dataset III dengan kNN dan Reduksi Data ... 42
Tabel 4.8. Perbandingan Hasil Pengujian Klasifikasi Data ... 43
xiv
DAFTAR GAMBAR
Gambar 2.1. Akar Ilmu Data Mining ... 6
Gambar 2.2. Tahapan-Tahapan KDD ... 7
Gambar 2.3. Tahap Pembangunan Model Klasifikasi ... 9
Gambar 2.4. Tahap Penggunaan Model klasifikasi ... 10
Gambar 2.5. Data Matrik Berukuran i x j ... 13
Gambar 2.6. Data Matrik u Berukuran i x k ... 13
Gambar 3.1. Blok Diagram Langkah-Langkah Penelitian ... 20
Gambar 4.1. Grafik Perbandingan Akurasi Pengujian Klasifikasi Data ... 44
Gambar 4.2. Grafik Perbandingan Persentase Penggunaan Data Pelatihan ... 45
BAB 1 PENDAHULUAN
1.1. Latar Belakang Masalah
Algoritma kNN (k-Nearest Neighbor) merupakan metode klasifikasi yang populer dalam data mining dan statistik karena implementasinya yang sederhana serta memiliki kinerja klasifikasi yang signifikan (Zhang et al, 2018). Algoritma kNN telah banyak digunakan dalam klasifikasi, regresi dan pengenalan pola (Chen, 2017). Proses pembelajaran pada algoritma kNN atau disebut dengan proses learning dilakukan dengan melibatkan sebuah data baru (data pengujian) yang akan dicari kelompoknya berdasarkan sekumpulan data pelatihan. Proses ini akan mencari kemiripan data menggunakan persamaan Euclidean serta mengurutkan data dengan kemiripan tertinggi hingga terendah. Pemilihan klasifikasi data baru dilakukan berdasarkan jumlah klasifikasi terbanyak dari pengurutan data pelatihan dengan melibatkan nilai k (jumlah tetangga terdekat).
Beberapa contoh penerapan metode kNN yang pernah dilakukan oleh peneliti terdahulu seperti penelitian yang dilakukan oleh Jabbar et al., (2013) yang melakukan penelitian tentang klasifikasi penyakit jantung. Hasil klasifikasi yang diperoleh memiliki tingkat akurasi yang baik sebesar 92,14%. Penelitian lainnya dilakukan oleh Handayani (2019) yang melakukan klasifikasi data menggunakan pendekatan kNN untuk klasifikasi tulang belakang yang menunjukkan akurasi sebesar 83%. Dari kedua penelitian yang telah disebutkan dapat diambil kesimpulan bahwa metode kNN mampu mengklasifikasi data dengan baik.
Algoritma kNN dalam penerapannya tidak memerlukan proses pelatihan yang rumit, namum rentan terhadap tingginya dimensionalitas data ketika terdapat banyak data pelatihan yang digunakan untuk proses klasifikasi. Selain itu, kNN memiliki kelemahan, yaitu tidak efisien dan memakan waktu (Yu et al, 2018). Hal ini dikarenakan semakin banyak dimensi data, maka ruang yang bisa ditempati instance juga semakin besar. Oleh karena itu, semakin besar pula kemungkinan bahwa nearest
neighbor dari suatu instance sebetulnya sama sekali tidak dekat dan mengakibatkan instance yang baru bisa ditempatkan ke dalam kelompok yang salah. Metode kNN tradisional memiliki beberapa kekurangan, seperti: komputasi yang lambat ketika jumlah data training yang besar dan ketergantungan yang kuat pada jumlah data training (Chen, 2017).
Beberapa penyelesaian masalah pada kNN telah dilakukan oleh peneliti terdahulu seperti mereduksi sebagian data (template reduction) agar data training menjadi semakin sedikit, mempercepat proses komputasi dan meningkatkan hasil klasifikasi. Teknik pemilihan instance sebagai metode yang sangat kompetitif untuk meningkatkan kNN dapat dilakukan melalui reduksi data (Barigou, 2018). Penelitian yang dilakukan oleh Yu et al., (2018) yang melakukan efisiensi proses klasifikasi pada algoritma kNN dengan fuzzy. Hasil penelitian tersebut mampu meningkatkan efisiensi klasifikasi menggunakan fuzzy-kNN untuk mengelompokkan data pengujian dan mengurangi jumlah data pelatihan. Algoritma yang ditingkatkan tersebut membuat algoritma kNN memiliki kinerja yang lebih baik. Analisis teoritis dan hasil eksperimen menunjukkan bahwa algoritma tersebut dapat secara efektif meningkatkan efisiensi dan akurasi algoritma saat menangani data dalam jumlah besar dan memenuhi kebutuhan pemrosesan data.
Penelitian tentang reduksi data pada algoritma kNN dilakukan juga oleh Tang et al., (2018) yang melakukan prediksi data menggunakan algoritma PCA-kNN.
Penelitian ini mengintegrasikan PCA dengan KNN yang tidak hanya dapat mengurangi dimensi data untuk mempercepat penghitungan KNN, tetapi juga mengurangi informasi redundansi. Informasi yang tersisa tetap efektif dan meningkatkan kinerja prediksi kNN. Metode PCA-KNN diuji pada kumpulan data historis nilai tukar EUR/USD dan indeks saham China selama periode 10 tahun, mencapai akurasi terbaik sebesar 77,58%. Berdasarkan penelitian tersebut, diketahui bahwa teknik reduksi data diperlukan untuk memperbaiki kinerja algoritma kNN untuk kasus klasifikasi ataupun prediksi data.
Berdasarkan penelitian yang dilakukan sebelumnya, penelitian ini akan melakukan pengujian reduksi data pada algoritma kNN menggunakan metode FCM (fuzzy c-means clustering) dan Pearson correlation. Metode FCM juga telah digunakan sebelumnya untuk memperbaiki kinerja algoritma kNN. Penelitian yang dilakukan oleh Bhuvaneshwari & Poornima (2019) yang melakukan identifikasi dan
3
deteksi kanker serviks menggunakan algoritma FCM dan kNN. Metode yang diusulkan bekerja sangat baik pada multi-sel dan sel yang tumpang tindih dengan presisi sebesar 95% menggunakan pengklasifikasi kNN. Penelitian selanjutnya dilakukan oleh Sjarif et al., (2019) yang melakukan penelitian tentang kinerja metode Pearson correlation dan kNN untuk kasus prediksi pelanggan yang tidak tetap pada industri telekomunikasi. Berdasarkan percobaan didapatkan bahwa hasil algoritma kNN dengan Pearson correlation memiliki kinerja yang lebih baik dibandingkan dengan algoritma lainnya dengan akurasi pelatihan sebesar 80,45% dan pengujian sebesar 97,78%.
Penelitian ini akan menggunakan metode FCM dan Pearson correlation untuk mereduksi data pelatihan sebelum proses klasifikasi data dilakukan menggunakan algoritma kNN. Metode FCM digunakan untuk proses klastering data dengan perolehan titik pusat cluster dan kemudian dilakukan pemilihan data pelatihan yang memiliki korelasi paling rendah menggunakan Pearson correlation untuk selanjutnya direduksi. Hasil dari kedua metode tersebut berupa data hasil reduksi yang selanjutnya akan dijadikan data pelatihan dengan dimensi yang lebih kecil untuk proses klasifikasi pada algoritma kNN. Penggunaan metode ini diharapkan dapat meningkatkan kinerja algoritma kNN baik dari segi waktu ataupun hasil klasifikasi data.
1.2. Rumusan Masalah
Algoritma kNN memiliki beberapa kelemahan, seperti: rentan terhadap tingginya dimensionalitas data, tidak efisien dan memakan waktu ketika data pelatihan memiliki dimensi yang tinggi. Sehingga, dibutuhkan suatu metode untuk menangani masalah tersebut seperti mereduksi data pelatihan. Kombinasi teknik reduksi data pada algoritma kNN yang sesuai akan dilakukan dalam penelitian ini menggunakan algoritma FCM dan Pearson correlation.
1.3. Batasan Masalah
Batasan masalah yang ditetapkan pada penelitian ini adalah sebagai berikut:
1. Permasalahan dalam penelitian ini memfokuskan pada teknik reduksi data pada algoritma kNN dan tidak menyelesaikan permasalahan lainnya pada algoritma tersebut.
2. Metode yang diterapkan untuk mereduksi data pada penelitian ini menggunakan algoritma FCM dan Pearson correlation dan tidak membandingkan teknik clustering ataupun similarity distance lainnya.
3. Penelitian akan menggunakan 3 buah jenis dataset yang berbeda sebagai pengujian metode dengan perbandingan data pelatihan dan data pengujian yang digunakan sebesar 70 : 30.
4. Penelitian ini memfokuskan untuk mencari hasil akurasi klasifikasi data sebagai perbandingan hasil kinerja metode yang diusulkan.
1.4. Tujuan Penelitian
Adapun tujuan dilakukan penelitian ini untuk menganalisis hasil klasifikasi data pengujian dengan mereduksi data pelatihan pada algoritma kNN menggunakan kombinasi algoritma FCM (fuzzy c-means clustering) dan Pearson correlation.
1.5. Manfaat Penelitian
Adapun manfaat yang diperoleh dari penelitian ini, antara lain:
1. Penelitian ini dapat menjadi sumber belajar dan referensi bagi mahasiswa dan peneliti lainnya dalam menangani permasalahan yang berkaitan dengan penelitian ini.
2. Penelitian ini dilakukan untuk mengetahui kinerja dari algoritma FCM (fuzzy c-means clustering) dan Pearson correlation untuk mereduksi data, sehingga dapat meningkatkan hasil akurasi klasifikasi data pada algoritma kNN.
5 BAB 2
LANDASAN TEORI
2.1. Data Mining
Data mining merupakan metode atau teknik yang digunakan untuk mendapatkan pengetahuan yang tersembunyi pada sekumpulan data dengan dimensi yang tinggi.
Teknik tersebut dilakukan untuk menggali informasi berupa pengetahuan dari sekumpulan data yang diuji. Di dalam data mining akan dilakukan proses menganalisis dari pemeriksaan sekumpulan data untuk memperoleh hubungan- hubungan yang tidak terduga serta merangkum data tersebut dengan cara yang lain dari sebelumnya, sehingga dapat dengan mudah untuk dimengerti dan memiliki manfaat (Larose, 2005).
Metode data miningmemiliki manfaatseperti dikemukakan oleh Turban et al., (2010) mengatakan bahwa data mining merupakan teknik yang diterapkan untuk mengemukakan temuan berupa pengetahuan atau informasi penting pada suatu database. Data mining pada dasarnya merupakan teknik gabungan berbagai bidang ilmu, seperti: matematika, statistik, machine learning dan artificial intelligence untuk mengekstraksi dan mengetahui informasi yang bernilai atau pemahaman yang berkaitan dengandatabase. Database sendiri merupakan kumpulan data yang terdapat pada sebuah sistem informasi yang disimpan dengan teknik dan fungsi tertentu. Data ini akan diolah dan dipelajari dengan teknik data mining sehingga dihasilkan informasi baru yang mudah dipahami dan dianalisis oleh pemilik data tersebut atau orang lain.
Berdasarkan penjelasan sebelumnya, maka data mining merupakan pengetahuan atau informasi yang tersembunyi di dalam database atau sekumpulan data dengan dimensi yang tinggi dalam menemukan pola dengan teknik berbagai cabang keilmuan, seperti: matematika, statistik, machine learning dan artificial intelligence untuk mengekstraksi dan mengetahui informasi yang bernilai atau pemahaman yang berkaitan dengan database tersebut.
Adapun berbagai bidang keilmuan di dalam data mining dapat diperlihatkan pada Gambar 2.1 berikut.
Gambar 2.1. Akar Ilmu Data Mining
Data mining adalah proses menganalisis dan menemukan informasi pada data yang besar agar didapatkan kebenaran, informasi yang baru serta mempunyai manfaat sampai dengan memperoleh pola di dalam data tersebut. Proses penemuan informasi pada data mining dengan menerapkan iterasi atau perulangan sampai mendapatkan hasil suatu pola atau model yang memiliki fungsi sesuai dengan tujuan. Data mining dapat dibagi menjadi dua kategori, yaitu (Tan et al, 2006):
1. Predictive mining adalah teknik untuk memperoleh suatu pola atau model pada data dengan melibatkan beberapa variabel yang bertujuan untuk memperkirakan variabel lain pada waktu selanjutnya. Teknik yang tergolong dalam predictive mining, yaitu: klasifikasi, deviasi dan regresi.
2. Descriptive mining adalah teknik untuk memperoleh ciri-ciri penting di dalam data pada suatu database. Teknik yang tergolong dalam descriptive mining, yaitu: clustering, association dan sequential mining.
2.2. Knowledge Discovery in Database (KDD)
Terdapat istilah lain pada data mining dengan pengertian yang sama, yaitu knowledge discovery in database (KDD). Data mining yaitu salah satu bagian dari teknik di dalam knowledge discovery in database (KDD). KDD merupakan teknik untuk menemukan informasi yang lebih bermanfaat, lebih mudah dimaknai serta baru dari penyimpanan data dengan dimensi yang tinggi atau kompleks. Proses KDD memaknai
Artificial
Intelligence Statistik
Machine Learning
Informasi
DATABASE
Matematika Data
Mining
7
bahwahasil yang didapatkan dengan menggabungkan ilmu lainnya dan dimulai dari menentukan tujuan dan diakhiri dengananalisis (Tomar & Agarwal, 2013).
Teknik data mining dapat membantu mengatasi banyak permasalahan dalam pengolahan data dengan ukuran yang besar. Peran utama data mining dengan menerapkan berbagai prosedur dan algoritma untuk mengambil pola dari data yang diolah. Data dapat diambil dan diolah dari berbagai jenis dataset dalam berbagai format, seperti: gambar, teks, audio, video dan sebagainya. Data yang telah dikumpulkan dari berbagai sumbermemerlukan proses analisis data yang tepat untuk pengambilan keputusan yangefisien (Sumathi et al, 2016). Adapun tahapan-tahapan dari KDD dapat diperlihatkan padaGambar 2.2 berikut.
Gambar 2.2. Tahapan-Tahapan KDD
Pada Gambar 2.2, tahapan-tahapan knowledge discovery in database (KDD) memiliki beberapa tingkatan proses,antara lain:
a. Selection
Selection merupakan teknik penyeleksian data dari suatu kumpulan data sebelum melalui tahap menemukan informasi di dalam knowledge discovery database (KDD). Data yang telah diseleksi akan digunakan untuk pengolahan di dalamdata mining dan akan disimpan secara terpisah.
Data Target Data
Preprocessed Data
Transformed Data
Patterns
Knowledge
Selection
Preprocessing
Transformation
Data Mining
Interpretation/
Evaluation
b. Preprocessing
Proses preprocessing yaitu proses untuk menghilangkan data yang sama, memverifikasi data yang tidak konsisten dan membenarkan kesalahan pada data. Proses ini juga melakukan enrichment, yaitu proses untuk menambah data yang ada dengan informasi lainnya yang bermakna dan diperlukan.
Sebagai contoh proses enrichment, seperti informasi eksternal.
c. Transformation
Proses transformation yaitu proses untuk merubah wujud data yang belum mempunyai entitas yang jelas ke wujud data yang benar dan siap dipakai pada proses data mining. Salah satu contoh tahap transformasi tersebut adalah normalisasi data. Normalisasi digunakan untuk merubah sebuah atribut yang berisi nilai numerik menjadi skala dalam rentang nilai yang lebih kecil, seperti 0 sampai dengan 1. Teknik yang sering dipakai untuk normalisasi data adalah min-max normalization. Adapun persamaan untuk proses normalisasi menggunakan metode min-max dapat dilihat pada persamaan (2.1) sebagai berikut:
𝑁𝑜𝑟𝑚𝑎𝑙𝑖𝑠𝑎𝑠𝑖 =𝐷𝑎𝑡𝑎𝐷𝑎𝑡𝑎𝑥−𝐷𝑎𝑡𝑎𝑚𝑖𝑛
𝑚𝑎𝑥−𝐷𝑎𝑡𝑎𝑚𝑖𝑛 (2.1)
Keterangan :
Datax : data yang akan ditransformasi Datamin : data terkecil pada kolom Datax Datamax : data terbesar pada kolom Datax d. Data Mining
Data mining merupakan proses yang digunakan untuk menerapkan metode pencarian informasi atau pengetahuan di dalam kumpulan data.
e. Interpretation/Evaluation
Proses ini dilakukan untuk pembentukan output yang mudah dimaknai dari proses data mining. Teknik data mining dapat dilakukan untuk mendeteksi persoalan yang ditemui, seperti: clustering, klasifikasi, asosiasi, outlier dan masih banyak lagi. Klasifikasimerupakan teknik atau metode yang dilakukan untuk menentukan kelompok sejumlah data yang mempunyai struktur data yang hampir sama atau serupa akan menghasilkan klasifikasi yang sama.
Klasifikasi merupakan metode di dalam data mining yang banyak diterapkan diberbagai bidang (Sung et al, 2015).
9
2.3. Klasifikasi
Beberapa permasalahan yang dapat ditangani dengan teknik data mining, yaitu:
prediction, estimation, clustering, classificationdan association. Berdasarkan metode pembelajarannya data mining dapat dibagi menjadi 2 kategori, yaitu: supervised learning dan unsupervised learning (Santosa, 2007). Pada supervised learning harus mempunyai data training yang digunakan pada proses pembelajaran algoritma yang digunakan, sedangkan pada unsupervised learning tidak memerlukan data training.
Salah satu contohteknik supervised learning pada data mining adalah klasifikasi.
Klasifikasi adalah teknik untuk menemukan suatu model di dalam data serta mengelompokkan data tersebut ke dalam kelas-kelas data. Tujuan klasifikasi adalah agar model yang terbentuk nantinya dapat diterapkan untuk memprediksi kelas dari objek yang belum diketahui label kelasnya. Model yang diperoleh tersebut berdasarkan pada proses menganalisis data pelatihan atau data yang telah memiliki labelkelasnya. Proses pengelompokan dilakukan dengan membelajarkan data training menggunakansalah satualgoritma klasifikasi untuk mengenali pola tertentu pada data training terhadaptarget kelas. Selanjutnya, pola yang dihasilkan memungkinkan untuk melakukan prediksi target kelas pada data di luar data training atau disebut juga dengan data testing (Han & Kamber, 2006). Proses klasifikasi terdiri dari dua tahap, yaitu (Annasaheb & Verma, 2016):
1. Tahap Pembangunan Model atau Pola Klasifikasi
Pada tahap ini akan dibangun model klasifikasi berdasarkan data training yang disiapkan dan telah memiliki target kelas. Data training tersebut dikatakan sebagai data pembelajaran di dalam algoritma klasifikasi. Proses ini dikatakan sebagai proses induksi seperti pada Gambar 2.3 berikut.
Gambar 2.3. Tahap Pembangunan Model Klasifikasi Training Set
Algoritma Klasifikasi
Model Klasifikasi
Membangun Aturan
2. Tahap Penggunaan Model atau Pola klasifikasi
Pada tahap akan digunakan model yang telah dibangun untuk data yang tidak diketahui atau belum memiliki label kelasnya. Proses penggunaan model tersebut dilakukan untuk memprediksikan label kelas dari data testing atau data di luar data training. Proses ini disebut deduksi seperti pada Gambar 2.4 berikut.
Gambar 2.4. Tahap Penggunaan Model klasifikasi 2.4. K-Nearest Neighbour (KNN)
Algoritma k-Nearest Neighbour (kNN) adalah metode yang diterapkan untuk mengklasifikasi data (Cover & Hart, 1967). Algoritma kNN adalah metode untuk menghitung jarak kesesuaian antara data baru dengan sekumpulan data lama berdasarkan pada proses pencocokan bobot dari sejumlah atribut yang dimilikinya (Kusrini & Taufiq 2009). Tujuan utama dari algoritma kNN adalah untuk memprediksi suatu objek atau data, kemudian menggolongkan objek atau data tersebut ke dalam satu kelompok golongan tertentu. Parameter k pada algoritma kNN adalah banyaknya tetangga terdekat yang akan diambil untuk menentukan keputusan atau kelompok dari data yang ingin dicari labelnya.
Algoritma kNN merupakan upaya dalam melakukan pengelompokkan pada suatu data berdasarkan data training yang paling mendekati dengan data tersebut.
Keakuratan hasil pada algoritma kNN sangatditentukan dengan ada atau tidak atribut- atribut yang bersesuaian atau bobotatribut yang serupa dengan relevansinya terhadap pengelompokkan. Penelitian pada kNN sering kali membahas bagaimana dalam memilih ataupun memberi bobot pada atribut data agar kinerja klasifikasi menjadi lebih akurat. Menurut Wu (2007) mengatakan bahwa kNN adalah teknik lazy learning, yaitu teknik yang melakukan prosesnya sampai terdapat data input baru (query) agar dilakukan proses pembelajaran dengan data training.
Training Set
Model Klasifikasi
Unseen Data
Klasifikasi Data yang Belum Diketahui Kelasnya
11
Algoritma kNN dapat diartikan juga sebagai pendekatan untuk mencari kelompok data pada data baru melalui proses menghitung kedekatannya dengan data yang lamaberdasarkan pencocokan dari sejumlah atribut. Nilai kedekatan biasaberada pada rentang nilai 0 sampai dengan 1. Nilai 0 berarti bahwa kedua data tersebut mutlak tidak memiliki kemiripan, sedangkan nilai 1 data tersebut mutlak memiliki kemiripan (Kusrini & Taufiq, 2009). Proses perhitungan kedekatan dilakukan dengan persamaan Euclidean distance. Euclidean distance berfungsi untuk mencari ukuran kedekatan jarak antara dua objek atau data dengan menerapkan persamaan berikut:
𝐷(𝑎, 𝑏) = 𝑑(𝑋𝑗 − 𝑌𝑗)2 (2.2)
𝑎 = [𝑋1, 𝑋2, … , 𝑋𝑗] dan 𝑏 = [𝑌1, 𝑌2, … , 𝑌𝑗] (2.3) atau,
𝐷(𝑥,𝑦)2 = (𝑋1− 𝑌1)2+ (𝑋2− 𝑌2)2+ ⋯ + (𝑋𝑗− 𝑌𝑗)2 (2.4) Keterangan :
D : jarak kedekatan atau kemiripan antara vektor a dan b a/x : vektor pada data baru
b/y : vektor pada data lama
d : matriks dengan ukuran d dimensi X : atribut pada data baru
Y : atribut pada data lama
Saat nilai D semakin besar, maka tingkat kemiripan antara kedua data tersebut semakin jauh. Sebaliknya saat nilai D semakin kecil, maka tingkat kemiripan antara kedua data tersebut semakin dekat.
Nilai parameter k terbaik pada algoritma kNN tergantung kepada dataset yang akan digunakan. Nilai k yang besar dapat mengurangi efek noise pada proses klasifikasi, tetapi akan mengakibatkan batasannya semakin kabur. Nilai k yang baik dapat dilakukan pemilihan dengan menggunakan metode optimasi parameter, seperti menerapkan metode cross-validation. Pada masalah tertentu dimana klasifikasi diprediksikan berdasarkan data training yang paling dekat atau k=1, disebut juga algoritma Nearest Neighbor. Langkah-langkah untuk proses klasifikasi menggunakan algoritma k-Nearest Neighbor dapat dilakukan sebagai berikut:
1. Menentukan nilai k (banyaknya tetangga terdekat dengan data testing).
2. Menyiapkan data training sebagai data pembelajaran dan data yang akan dicari label kelasnya (data testing).
3. Menghitung kedekatan jarak menggunakan persamaan Euclidean distance antara setiap data testing dengan data training.
𝑑𝑒𝑢𝑐𝑙𝑖𝑑𝑒𝑎𝑛(𝑥, 𝑦) = √∑ (𝑥𝑖 𝑖− 𝑦𝑖)2 (2.5)
Keterangan :
i : banyaknya data x : data testing y : data training
4. Melakukan pengurutan pada data training yang telah ditentukan kelasnya ke dalam kelompok yang memiliki hasil perhitungan jarak Euclidean terkecil.
5. Melakukan voting atau pemilihan kelas pada data testing yang masuk peringkat sejumlah nilai k.
6. Menentukan hasil klasifikasi berdasarkan tahap kelima yang terbanyak.
2.5. Fuzzy C-Means Clustering (FCM)
Fuzzy c-means clustering (FCM) adalah teknik di dalam data mining dan termasuk ke dalam salah satu teknik clustering data. Teknik clustering adalah sebuah metode komputasi pada bidang matematika yang dapat diterapkan dalam menentukan model terkait kemiripan atau kesesuaian pada satu atau lebih data di dalam suatu kelompok.
Data akan dikelompokkan ke dalam satu cluster berdasarkan tingkat kemiripan yang identik. Metode FCM memperbolehkan tiap vektor pada atribut data dapat dimiliki lebih dari sebuah cluster dengan derajat keanggotaan yang berbeda. Derajat keanggotaan dibentuk menggunakan bilangan dengan rentang nilai 0 - 1.
Metode FCM dapat beroperasi dalam mengklasifikasi data dengan menghitung tingkat kemiripan diantara pasangan kelompok data. Data yang memiliki kemiripan satu dengan yang lainnya akan mempunyai nilai derajat keanggotaan yang besar dan masuk pada cluster yang serupa. Konsep dasar metode FCM dengan menetapkan titik pusat cluster data dengan mengenali wilayah rata-rata untuk tiap cluster. Proses ini dapat dilakukan dengan cara memperbaiki titik pusat cluster data dan nilai derajat keanggotaan setiap titik data secara iterasi atau berulang-ulang, sehingga dapat dilihat bahwa titik pusat cluster akan melaju menuju lokasi yang sesuai. Perulangan ini dilakukan berdasarkan nilai minimal dari fungsi objektif yang ditentukan sebelumnya dengan menggambarkan jarak titik data yang diberikan ke titik pusat cluster data yang diberi bobot oleh nilai derajat keanggotaan titik data tersebut.
13
Hasil atau output metode FCM tersebut bukan merupakan fuzzy inference system, namun sederetan titik pusat cluster data dan nilai derajat keanggotaan untuk tiap-tiap data. Informasi yang diperoleh dapat diterapkan untuk membangun fuzzy inference system. Adapun prosedur yang dilakukan dalam penggunaan metode FCM dapat dijelaskan sebagai berikut:
1. Menyiapkan sejumlah data yang akan dilakukan proses clustering. Misalnya, sebuah dataset berupa matriks X dengan data yang berukuran i x j (i = banyaknya data dan j = banyaknya atribut).
[
𝑋11 𝑋12 𝑋21 𝑋22
… 𝑋1𝑗
… 𝑋2𝑗
⋮ ⋮
𝑋𝑖1 𝑋𝑖2
⋱ ⋮
… 𝑋𝑖𝑗]
Gambar 2.5. Data Matrik Berukuran i x j 2. Menentukan beberapa parameter sebagai berikut:
a. Jumlah cluster yang diinginkan (i > c ≥ 2) b. Bobot pada FCM (w ≥ 2)
c. Iterasi Maksimum (max i) d. Nilai treshold (ɛ)
e. Fungsi obyektif awal (P0)
3. Menginisialisasi matriks partisi awal atau u (nilai derajat keanggotaan) untuk tiap cluster dengan ukuran i x k, dengan i = banyaknya data dan k = banyaknya cluster. Matriks partisi biasanya dibuat acak dengan rentang nilai 0 sampai dengan 1.
[
𝑢11 𝑢12
𝑢21 𝑢22 … 𝑢1𝑘
… 𝑢2𝑘
⋮ ⋮
𝑢𝑖1 𝑢𝑖2 ⋱ ⋮
… 𝑢𝑖𝑘 ]
Gambar 2.6. Data Matrik u Berukuran i x k
4. Menghitung titik pusat cluster (C) data untuk setiap cluster, menggunakan persamaan (2.6) berikut.
𝐶𝑘𝑗 = ∑𝑛𝑖=1∑ (𝜇(𝜇𝑘𝑖)𝑤𝑋𝑖𝑗
𝑘𝑖)𝑤
𝑛𝑖=1 (2.6)
Keterangan :
Cjk = Titik pusat cluster data μki = Data partisi (u)
Xij = Data
w = Bobot FCM
5. Menghitung nilai obyektif (Pn) dengan persamaan (2.7) sebagai berikut.
𝑃𝑛 = ∑𝑛𝑖=1∑𝑚𝑘=1(𝜇𝑘𝑖)𝑤(𝑑𝑘𝑖)2 (2.7)
Keterangan :
μki = Data partisi (u) dki = Jarak Euclidean w = Bobot FCM Pn = Nilai obyektif
6. Memperbaiki nilai derajat keanggotaan untuk tiap data pada tiap cluster. Proses tersebut dapat dilakukan menggunakan persamaan (2.8) dan (2.9) berikut :
𝜇𝑘𝑖 = [∑ (𝑑𝑑𝑘𝑖
𝑗𝑖)2/(𝑤−1)
𝑚𝑗=1 ]
−1
(2.8) Dengan,
𝑑𝑖𝑘 = 𝑑(𝑋𝑖 − 𝐶𝑘) = [∑𝑚𝑗=1(𝑋𝑖𝑗 − 𝐶𝑘𝑗)2]1/2 (2.9) Keterangan :
μki = Data partisi (u) dki = Jarak Euclidean dji = Jarak Euclidean w = Bobot FCM Xij = Data
7. Menghentikan proses iterasi jika titik pusat cluster data tidak berubah lagi.
Alternatif penghentian lain, jika perubahan nilai error kurang dari treshold |Pn - Pn-1| < ɛ. Selain itu, dapat juga menggunakan kriteria ketika perulangan melebihi maksimum iterasi ( I > max i). Jika iterasi belum berhenti, maka proses harus kembali ke langkah 4.
8. Menentukan titik pusat cluster data tiap-tiap data jika iterasi berhenti. Titik pusat cluster data dipilih dari perolehan nilai matriks partisi terbesar.
2.6. Pearson Correlation
Setiap objek pada dasarnya antara satu dengan lainnya dapat diklasifikasikan ke dalam jenis yang sama ataupun berbeda berdasarkan nilai kemiripan yang dimilikinya. Nilai kemiripan suatu objek merupakan komponen yang mendasari hasil suatu metode
15
untuk mencocokkan antara data testing dengan data training. Ketepatan perhitungan nilai kemiripan memutuskan apakah antara data testing memiliki kemiripan dengan data training. Proses pencocokan kemiripan suatu data tersebut dilakukan dengan menerapkan metode pengukuran jarak. Metode tersebut adalah komponen penting dalam pembangunan metode untuk klasifikasi. Sebelum dilakukannya tahap pengklasifikasian data, terlebih dahulu dihitung ukuran jarak kedekatan antara elemen data tersebut.
Salah satu metode pengukuran jarak kemiripan antara satu data dengan data lainnya adalah Pearson correlation. Metode ini merupakan cara yang dilakukan untuk menghitung tingkat probabilitas bahwa terdapat korelasi linear antara dua kuantitas atau objek yang diukur. Karl Pearson mendefinisikan bahwa koefisien korelasi merupakan ukuran korelasi formal pertama dan secara luas banyak digunakan dalam analisis statistik, pengenalan pola dan pemrosesan citra digital (Kaur et al, 2012).
Nilai coefficient correlation antara dua buah objek atau data yang dihitung menggunakan persamaan sebagai berikut. (Thanuja & Shreedevi, 2013).
𝑟𝑥𝑦 =∑ 𝑥(𝑛−1)𝑠𝑖𝑦𝑖−𝑛𝑥̅𝑦̅
𝑥𝑠𝑦 = 𝑛 ∑ 𝑥𝑖𝑦𝑖−∑ 𝑥𝑖∑ 𝑦𝑖
√𝑛 ∑ 𝑥𝑖2−(∑ 𝑥𝑖)2√𝑛 ∑ 𝑦𝑖2−(∑ 𝑦𝑖)2 (2.10) Keterangan:
r = nilai coefficient correlation x = data objek pertama
y = data objek kedua
sx = standar deviasi objek pertama sy = standar deviasi objek kedua n = jumlah data
Hasil dari coefficient correlation memiliki nilai antara -1 s/d 1, sehingga jika hasilnya lebih besar dari 1 atau lebih kecil dari -1 dapat ditetapkan ada kesalahan di dalam proses perhitungan. Nilai coefficient correlation sama dengan -1 menunjukkan bahwa kedua variabel bergerak ke arah yang berlawanan, nilai coefficient correlation sama dengan 1 menunjukkan kedua variabel memiliki hubungan atau korelasi yang sempurna, sedangkan nilai koefisien korelasi yang bernilai 0 menunjukkan bahwa kedua variabel tidak memiliki korelasi atau tidak berhubungan sama sekali (Thanuja
& Shreedevi, 2013).
Pada algoritma kNN, proses ini diperlukan pada tahap pre-processing data untuk mempertahankan data dengan tingkat korelasi tertinggi. Sedangkan, data dengan tingkat korelasi terkecil akan direduksi atau dihilangkan. Data yang digunakan sebagai data pembanding diperoleh dari hasil clustering data yang sebelumnya dilakukan menggunakan algoritma FCM.
2.7. Penelitian-Penelitian Terkait
Beberapa penelitian yang berkaitan dengan penelitian pada tulisan ini telah dilakukan oleh peneliti-peneliti sebelumnya dan dapat dilihat pada Tabel 2.1 sebagai berikut:
Tabel 2.1: Penelitian-Penelitian Terkait No. Nama Peneliti Metode yang
Digunakan Hasil
1. Sjarif et al., (2019)
Pearson Correlation dan k-Nearest Neighbor Algorithm untuk kasus prediksi pelanggan pada industri
telekomunikasi
Berdasarkan percobaan didapatkan bahwa hasil kombinasi kedua metode tersebut memiliki kinerja lebih baik dibandingkan dengan algoritma lainnya dengan akurasi pelatihan 80,45% dan pengujian 97,78%.
2. Miloud- Aouidate &
Baba-Ali (2012)
Hybrid kNN-Ant Colony Optimization Algorithm untuk seleksi prototipe
Hasil yang diperoleh melalui uji coba dilakukan pada lima datasets dari UCI Machine Learning Repository menunjukkan peningkatan yang diperoleh pada algoritma yang diusulkan dibandingkan dengan algoritma kNN kondensasi lainnya.
3. Saadatfar et al., (2020)
K-Means Clustering dan kNN untuk data klasifikasi dan reduksi data
Hasil eksperimen menunjukkan bahwa pendekatan yang diusulkan memiliki akurasi klasifikasi yang lebih baik dibandingkan dengan metode lain yang relevan.
4. Balamurugan et al., (2017)
KNN - Data Reduction (Jaccard dan Dice)
Koefisien Jaccard dan Dice untuk reduksi data pada algoritma kNN yang digunakan dapat mengurangi dimensi data dan kompleksitas komputasi.
17
5. Li (2019) Tree Pruning-kNN model (TPKNN) untuk teknologi pemangkasan data
Metode ini dapat mengurangi data asli dan waktu yang berjalan dalam proses klasifikasi. Selain itu, TPKNN sangat mudah diimplementasikan dan dapat
dianggap sebagai preprocessing dari beberapa algoritma klasifikasi.
6. Tang et al., (2018)
PCA and kNN PCA dengan kNN yang digunakan tidak hanya dapat mengurangi dimensi data untuk mempercepat perhitungan kNN, tetapi juga mengurangi informasi redundansi.
Informasi yang tersisa tetap efektif meningkatkan kinerja prediksi kNN.
Pada penelitian ini akan dilakukan pengujian reduksi data pada algoritma kNN menggunakan algoritma FCM dan Pearson correlation. Algoritma FCM digunakan untuk proses clustering data dengan perolehan titik pusat cluster data. Selanjutnya, akan dilakukan pemilihan berdasarkan ukuran korelasi atau kemiripan pada data pelatihan untuk proses reduksi data menggunakan Pearson correlation. Hasil dari kedua metode tersebut berupa data hasil reduksi yang selanjutnya akan dijadikan data pelatihan dengan dimensi yang lebih kecil untuk proses klasifikasi pada algoritma kNN. Penggunaan metode ini diharapkan dapat meningkatkan kinerja algoritma kNN baik dari segi waktu ataupun hasil klasifikasi data.
18 3.1. Tahapan-Tahapan Penelitian
Metodologi adalah proses menguraikan konsep-konsep ke dalam bagian-bagian yang lebih sederhana, sehingga struktur logisnya menjadi lebih jelas. Proses ini dilakukan untuk menguji, menilai serta memahami sistem pemikiran yang kompleks dengan memecahnya ke dalam bagian unsur-unsur yang lebih sederhana, sehingga hubungan antar unsur-unsur tersebut menjadi jelas. Adapun metodologi yang dilakukan dalam penelitian ini, yaitu:
a) Studi pustaka
Mencari referensi yang berkaitan dengan permasalahan pada penelitian ini.
Proses pencarian tersebut dimulai dari mencari buku-buku, jurnal maupun artikel-artikel yang terdapat di internet yang berhubungan dengan data reduction pada algoritma kNN.
b) Pengumpulan data
Mencari kumpulan dataset klasifikasi yang terdapat pada laman internet dengan alamat https://archive.ics.uci.-edu/ml. Data yang dipakai pada penelitian ini terdiri dari 3 dataset klasifikasi yang berbeda dimensinya. Hal ini dilakukan untuk melihat sejauhmana metode yang diusulkan dapat mereduksi data yang tidak relevan dan tidak berpengaruh terhadap hasil klasifikasi menggunakan algoritma kNN.
c) Uji Coba
Dataset yang diperoleh akan dinormalisasi dan dihilangkan redundansinya.
Kemudian, dataset akan diujicobakan menggunakan algoritma kNN tanpa melakukan reduksi data. Hasil akurasinya akan disimpan sebagai bahan perbandingan dengan metode reduksi data yang diusulkan. Langkah selanjutnya, akan dilakukan reduksi data menggunakan metode fuzzy c- means clustring dan Pearson correlation.
19
d) Analisis
Proses reduksi data menggunakan metode FCM dan Pearson correlation pada algoritma kNN yang diusulkan akan dibandingkan dengan algoritma kNN tanpa reduksi data dan dianalisis serta dilihat persentase akurasi dari masing-masing metode tersebut.
e) Penarikan Kesimpulan
Pada tahap ini peneliti akan menyimpulkan hasil analisis penggunaan metode fuzzy c-means clustering dan Pearson correlation untuk reduksi data pada algoritma kNN. Hasil reduksi data dapat dilihat dari persentase sebelum dan sesudah dilakukannya reduksi harus mendekati atau terjadi peningkatan akurasi. Hal ini memiliki pengertian bahwa data yang direduksi dapat menyebabkan hasil klasifikasi yang tidak sesuai atau tidak memiliki pengaruh yang besar terhadap hasil klasifikasi data sehingga dapat dihilangkan.
3.2. Data yang Digunakan
Dalam menganalisis akurasi reduksi data pada algoritma kNN menggunakan metode FCM dan Pearson correlation dipilih data sebanyak 3 buah dataset yang diperoleh dari laman internet dengan alamat: https://archive.ics.uci.edu/ml/datasets/ dan dapat dilihat pada Tabel 3.1 sebagai berikut.
Tabel 3.1. Dataset yang Digunakan
No. Nama Dataset Jumlah
Intances
Jumlah Features
Jumlah Kelas Data
1. Iris Data set 150 5 3
2. Pima Indians Diabetes 768 9 2
3. Breast Cancer Wisconsin 569 32 2
Setiap dataset pada Tabel 3.1 di atas akan dibagi menjadi 2 bagian, yaitu data training dan data testing dengan persentase pembagian sebesar 70 : 30. Data training merupakan data penentu dalam pembentukan kelas untuk data testing melalui proses pembelajaran pada algoritma kNN. Pada penelitian ini, metode yang diusulkan akan mereduksi jumlah data training, sehingga dihasilkan dimensi yang lebih kecil dari sebelumnya. Metode reduksi yang digunakan juga akan mencari data training yang dapat menyebabkan hasil klasifikasi tidak sesuai atau tidak memiliki pengaruh yang besar terhadap hasil klasifikasi data sehingga dapat dihilangkan.
3.3. Langkah-Langkah Penelitian
Adapun langkah-langkah penelitian dengan metode yang diusulkan dapat dilihat pada blok diagram Gambar 3.1 sebagai berikut.
Gambar 3.1. Blok Diagram Langkah-Langkah Penelitian Input Dataset
Normalisasi Data
Data Pelatihan
Clustering dengan Algoritma FCM Data Pengujian
Titik Pusat Data
Pearson Correlation
Nilai Korelasi
Hapus Data dengan Korelasi Terkecil
Data Pelatihan Baru dengan Dimensi Berbeda Hitung Jarak Euclidean
Distance
Urutkan Data dan Cari Nilai Minimum Sebanyak Jumlah k
Akurasi Klasifikasi
Menentukan kelompok data hasil uji berdasarkan label mayoritas dari nilai k
Tentukan Nilai k
Keterangan :
= Proses reduksi data dengan metode yang diusulkan
= Proses klasifikasi dengan kNN Metode yang diusulkan
21
Adapun penjelasan pada Gambar 3.1 dapat diuraikan sebagai berikut:
1. Input Dataset, merupakan proses memasukkan data yang akan diolah dan diklasifikasi menggunakan algoritma kNN.
2. Tentukan nilai k, merupakan proses dalam penentuan nilai ketetanggaan pada algoritma kNN untuk proses klasifikasi.
3. Normalisasi data, merupakan proses dalam melakukan perubahan nilai data dengan rentang nilai 0 sampai dengan 1. Proses ini dilakukan untuk mendapatkan nilai yang sama pada setiap atribut data.
4. Data pengujian, merupakan data yang dipilih dan diklasifikasi untuk mengetahui kinerja dari metode yang diusulkan dengan jumlah sebanyak 30%
dari total dataset yang digunakan.
5. Data pelatihan, merupakan data yang dipilih untuk proses pembelajaran algoritma kNN dengan jumlah sebanyak 70% dari total dataset yang digunakan. Pada metode yang diusulkan, data ini akan direduksi berdasarkan nilai korelasi yang ditentukan.
6. Clustering data dengan FCM, merupakan proses menggelompokkan data berdasarkan fitur yang terdapat pada data pelatihan. Proses ini akan mengelompokkan data pelatihan sesuai dengan banyaknya kelas data.
7. Titik pusat data, merupakan hasil dari proses clustering dengan algoritma FCM berupa titik pusat cluster data. Banyaknya pusat cluster data yang dihasilkan yaitu sejumlah kelas yang ditentukan sebelumnya.
8. Pearson correlation, merupakan proses untuk mengukur jarak korelasi antara data pelatihan dan titik pusat cluster data.
9. Nilai korelasi, merupakan nilai yang terbentuk dari pengukuran korelasi antara data pelatihan dengan titik pusat cluster data. Nilai ini akan menjadi patokan untuk mereduksi data pelatihan.
10. Hapus data dengan korelasi terkecil, merupakan proses mereduksi data pelatihan berdasarkan nilai korelasi yang ditentukan. Data pelatihan yang direduksi merupakan data dengan nilai korelasi minimum yang ditentukan.
11. Data pelatihan baru, merupakan data yang diperoleh berdasarkan proses reduksi data sebelumnya. Data dengan nilai korelasi di atas ketentuan akan dipertahankan dan dijadikan sebagai data pelatihan baru dengan dimensi data yang berbeda dari sebelumnya.
12. Euclidean distances, merupakan proses mengukur jarak data berdasarkan nilai minimum Euclidean. Proses ini dilakukan dengan menghitung nilai kuadrat jarak antara data pengujian dengan setiap data pelatihan.
13. Urutan data, merupakan hasil dari proses pengukuran jarak dengan persamaan Euclidean. Proses ini dilakukan dengan mengurutkan nilai jarak minimum yang dihasilkan antara data pengujian dan setiap data pelatihan dengan asumsi nilai jarak minimum sebagai hasil yang paling memiliki kedekatan. Proses ini juga menandai label kelas dari data pelatihan berdasarkan urutan pada nilai jarak minimum yang dihasilkan.
14. Menentukan kelompok data, merupakan proses yang dilakukan untuk menentukan label atau kelompok dari data pengujian berdasarkan nilai label mayoritas sebanyak k yang telah diurutkan.
15. Akurasi klasifikasi, merupakan proses menghitung jumlah data yang terklasifikasi benar pada data pengujian menggunakan algoritma kNN. Akurasi dihasilkan dengan membandingkan jumlah data yang benar dibagi dengan total data pengujian.
3.4. Normalisasi Data
Proses normalisasi dilakukan pada penelitian ini untuk memperoleh nilai yang sama dengan rentang 0 sampai dengan 1. Metode untuk memperoleh nilai tersebut adalah metode max-min normalization. Adapun proses perhitungan normalisasi data dapat dijelaskan pada langkah-langkah sebagai berikut.
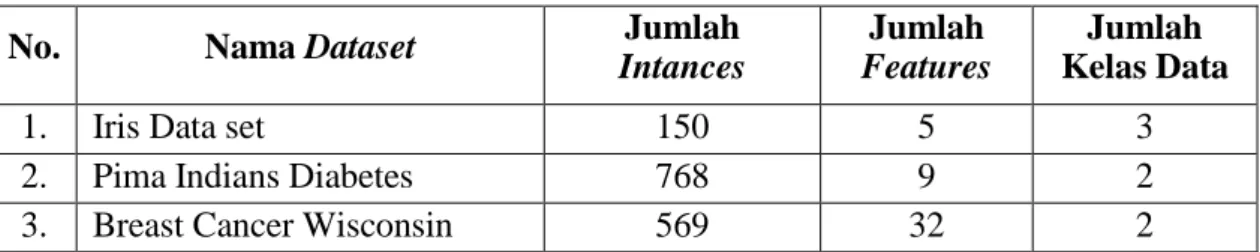
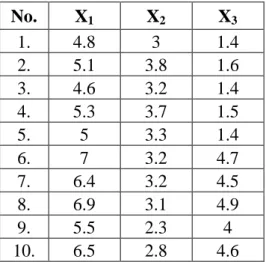
1. Menyiapkan data yang akan dinormalisasi. Pada contoh ini akan digunakan 10 sampel data dengan 3 buah atribut. Perhatikan Tabel 3.2 berikut.
Tabel 3.2. Data Sebelum Normalisasi
No. X1 X2 X3
1. 4.8 3 1.4
2. 5.1 3.8 1.6
3. 4.6 3.2 1.4
4. 5.3 3.7 1.5
5. 5 3.3 1.4
6. 7 3.2 4.7
7. 6.4 3.2 4.5
8. 6.9 3.1 4.9
9. 5.5 2.3 4
10. 6.5 2.8 4.6
23
2. Menentukan beberapa parameter sebagai berikut.
Nilai maksimum baru : 1 Nilai minimum baru : 0
Di dalam data akan dicari nilai maksimum dan minimum sesuai nilai yang terdapat pada masing-masing atribut, perhatikan Tabel 3.3 berikut:
Tabel 3.3. Nilai Maksimum dan Minimum Data
Keterangan X1 X2 X3
Data Maksimum 7 3.8 4.9
Data Minimum 4.6 2.3 1.4
3. Hitung nilai hasil normalisasi setiap data dengan menggunakan persamaan (2.1) dan hasilnya dapat dilihat sebagai berikut.
Atribut 1 (X1)
Data − 1 =(4.8 − 4.6)
7 − 4.6 = 0.08 Data − 2 =(5.1 − 4.6)
7 − 4.6 = 0.21 Data − 3 =(4.6 − 4.6)
7 − 4.6 = 0 Data − 4 =(5.3 − 4.6)
7 − 4.6 = 0.29 Data − 5 =(5 − 4.6)
7 − 4.6 = 0.17 Data − 6 =(7 − 4.6)
7 − 4.6 = 1 Data − 7 =(6.4 − 4.6)
7 − 4.6 = 0.75 Data − 8 =(6.9 − 4.6)
7 − 4.6 = 0.96 Data − 9 =(5.5 − 4.6)
7 − 4.6 = 0.38 Data − 10 =(6.5 − 4.6)
7 − 4.6 = 0.79
Atribut 2 (X2) Data − 1 =(3 − 2.3)
3.8 − 2.3 = 0.47
Data − 2 =(3.8 − 2.3) 3.8 − 2.3 = 1 Data − 3 =(3.2 − 2.3)
3.8 − 2.3 = 0.60 Data − 4 =(3.7 − 2.3)
3.8 − 2.3 = 0.93 Data − 5 =(3.3 − 2.3)
3.8 − 2.3 = 0.67 Data − 6 =(3.2 − 2.3)
3.8 − 2.3 = 0.60 Data − 7 =(3.2 − 2.3)
3.8 − 2.3 = 0.60 Data − 8 =(3.1 − 2.3)
3.8 − 2.3 = 0.53 Data − 9 =(2.3 − 2.3)
3.8 − 2.3 = 0 Data − 10 =(2.8 − 2.3)
3.8 − 2.3 = 0.33
Atribut 3 (X3)
Data − 1 =(1.4 − 1.4) 4.9 − 1.4 = 0 Data − 2 =(1.6 − 1.4)
4.9 − 1.4 = 0.06 Data − 3 =(1.4 − 1.4)
4.9 − 1.4 = 0 Data − 4 =(1.5 − 1.4)
4.9 − 1.4 = 0.03 Data − 5 =(1.4 − 1.4)
4.9 − 1.4 = 0 Data − 6 =(4.7 − 1.4)
4.9 − 1.4 = 0.94 Data − 7 =(4.5 − 1.4)
4.9 − 1.4 = 0.89 Data − 8 =(4.9 − 1.4)
4.9 − 1.4 = 1 Data − 9 =(4 − 1.4)
4.9 − 1.4 = 0.74 Data − 10 =(4.6 − 1.4)
4.9 − 1.4 = 0.91
4. Susunlah hasil normalisasi data ke dalam bentuk Tabel 3.4 seperti berikut.
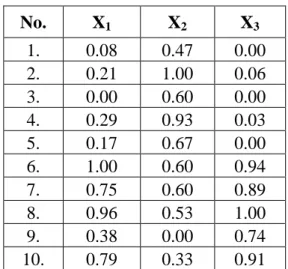
25
Tabel 3.4. Data Hasil Normalisasi
No. X1 X2 X3
1. 0.08 0.47 0.00
2. 0.21 1.00 0.06
3. 0.00 0.60 0.00
4. 0.29 0.93 0.03
5. 0.17 0.67 0.00
6. 1.00 0.60 0.94
7. 0.75 0.60 0.89
8. 0.96 0.53 1.00
9. 0.38 0.00 0.74
10. 0.79 0.33 0.91
3.5. Perhitungan Algoritma Fuzzy C-Means Clustering (FCM)
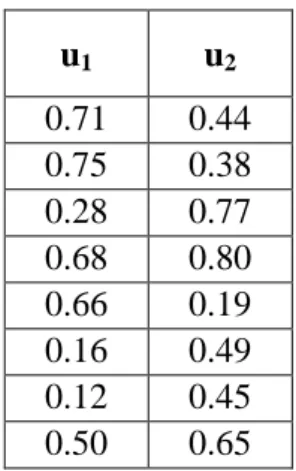
Algoritma FCM merupakan metode untuk melakukan clustering data berdasarkan atribut yang dimiliki. Pada penelitian ini metode FCM digunakan sebagai pembentukan cluster dari setiap data pelatihan dengan hasil berupa titik pusat cluster yang dijadikan sebagai acuan dalam melakukan proses reduksi data. Data yang akan di-cluster merupakan data pelatihan yang telah dinormalisasi sebelumnya dan akan direduksi. Adapun langkah-langkahnya dapat dijelaskan sebagai berikut.
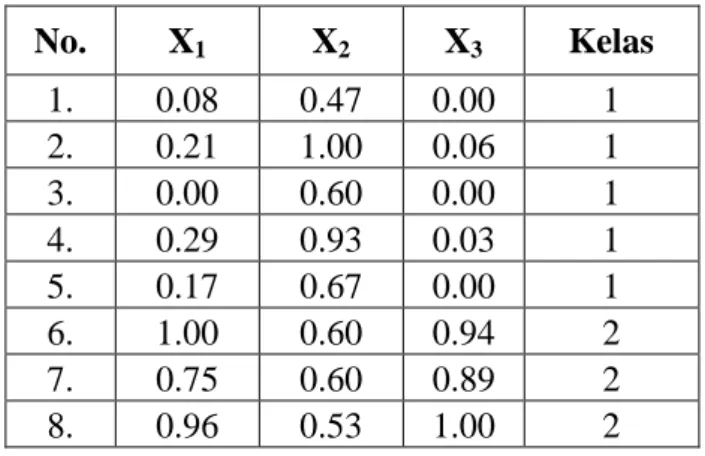
1. Menyiapkan data pelatihan yang akan di-cluster. Sebagai contoh, dapat dilihat pada Tabel 3.5 sebagai berikut.
Tabel 3.5. Data Pelatihan
No. X1 X2 X3
1. 0.08 0.47 0.00
2. 0.21 1.00 0.06
3. 0.00 0.60 0.00
4. 0.29 0.93 0.03
5. 0.17 0.67 0.00
6. 1.00 0.60 0.94
7. 0.75 0.60 0.89
8. 0.96 0.53 1.00
2. Melakukan inisialisasi awal pada matriks fuzzy pseudo-partition dengan memberikan nilai sembarang 0 - 1 untuk u1 dan u2. Banyak u tergantung pada jumlah cluster yang telah ditentukan. Selain itu, penetapan nilai w yang merupakan parameter bobot pangkat (weighting exponent) sebesar 2. Nilai yang dapat ditetapkan sebesar w ≥ 2, namun umumnya diberi nilai 2.