PENGEMBANGAN ALAT BANTU
PENAMBANGAN ATURAN ASOSIASI LANGKA
MENGGUNAKAN PENDEKATAN
APIC (APRIORI INVERSE WITH CLUSTERING)
SKRIPSI
Diajukan untuk Memenuhi salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh:
Benediktus Heru Dwiwangga
NIM : 085314085
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
THE DEVELOPMENT OF A TOOL
FOR RARE ASSOCIATION RULE MINING
USING APIC (APRIORI INVERSE WITH CLUSTERING)
A THESIS
Presented as Partial Fulfillment of the Requirements
To Obtain the Sarjana Komputer Degree In Informatics Engineering Department
By:
Benediktus Heru Dwiwangga
NIM : 085314085
INFORMATICS ENGINEERING STUDY PROGRAM
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
v .
HALAMAN MOTTO
“
Percayalah Bahwa Tuhan Selalu Memberi
Yang Terbaik Dalam Hidup Kita
”
“Lebih Baik Gagal Karena Mencoba Dari
Pada Takut Untuk Mencoba”
vi
HALAMAN PERSEMBAHAN
Kupersembahkan Karya ku ini untuk :
Tuhan Yesus Kristus
Bapa (FX. Samiyo) Ibu (F. Martini)
Kakak (A. Fajar.Fk)
Adik (Priska Arsita.B)
Semua sahabat yang aku sayangi
vii
PERNYATAAN KEASLIAN KARYA
Saya menyatakan sesungguhnya bahwa skripsi yang saya tulis ini tidak memuat karya orang lain kecuali telah disebutkan dalam kutipan atau daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, 31 Maret 2013 Penulis,
viii
ABSTRAK
Metode penambangan aturan asosiasi langka muncul karena adanya perhatian khusus yang diberikan terhadap himpunan item langka yang terjadi dalam basis data. Item langka adalah item yang jarang muncul dalam basis data (Koh & Pears, 2010). Item langka menjadi penting karena adanya informasi penting yang terkandung di dalamnya.
Saat ini belum ada perangkat lunak generik yang bisa digunakan sebagai alat bantu untuk mendeteksi aturan langka. Kebanyakan perangkat lunak untuk proses penambangan data masih menerapkan aturan atau teknik untuk mencari aturan yang sering muncul dalam dataset.
Skripsi ini dimaksudkan untuk membangun sebuah perangkat lunak yang dapat digunakan sebagai alat bantu untuk mendeteksi aturan asosiasi langka dalam basis data. Algoritma untuk proses pendeteksian yang dilakukan adalah algoritma APIC (Apriori Inverse with Clustering).
ix
ABSTRACT
Rare association rule mining method appears because of perticular attentions to the set of rare items that occur in the database. Rare items are items that appears in a few transactions (Koh & Pears, 2010). Rare items become important because of the important of information contained.
Up to know, there is no generic software that can be used as a tool to detect rare rules. Most softwares for data mining process applying rules or techniques to search for rules that frequently appear in the dataset.
This thesis is intended to build a software that can be used as a tool to detect rare association rules in the database. Algorithm for the detection process is APIC (Apriori Inverse with Clustering) algorithm.
The software has been tested using three different datasets, namely congressional votes, zoo, and heart Cleveland taken from archive.ics.uci.edu website/ml/machine-learning-databases. The testing is intended to test the validity of the software. The results show that the software could find valid rare association rules from the datasets.
x
PERNYATAAN PERSETUJUAN
PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma:
Nama : Benediktus Heru Dwiwangga
NIM : 085314085
Demi pengembangan ilmu pengetahuan, saya memberikan kepada perpustakaan
Universitas Sanata Dharma karya ilmiah saya yang berjudul:
PENGEMBANGAN ALAT BANTU PENAMBANGAN ATURAN SOSIASI LANGKA
MENGGUNAKAN PENDEKATAN APIC (APRIORI INVERSE WITH CLUSTERING)
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan
kepada Perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengalihkan
dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data,
mendistribusikannya secara terbatas dan mempublikasikannya di internet atau media
lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun
memberikan royalty kepada saya selama tetap mencantumkan nama saya sebagai
penulis. Demikian pernyataan ini yang saya buat dengan sebenarnya.
Dibuat di Yogyakarta, Pada tanggal: 31 Maret 2013 Yang menyatakan
xi
KATA PENGANTAR
Puji syukur kepada Tuhan Yang Maha Esa karena atas segala berkat dan rahmat-Nya penulis dapat menyelesaikan skripsi dengan judul “Pengembangan Alat Bantu Penambangan Aturan Asosiasi Langka Menggunakan Pendekatan APIC (Apriori Inverse With Clustering)”.
Penulisan skripsi ini diajukan untuk memenuhi salah satu syarat memperoleh gelar Sarjana Komputer Program Studi Teknik informatika Universitas Sanata Dharma Yogyakarta.
Dengan terselesaikannya penulisan skripsi ini, penulis mengucapkan terima kasih kepada pihak-pihak yang telah membantu memberikan dukungan baik berupa masukan ataupun berupa saran. Ucapan terima kasih sebanyak-banyaknya ditujukan kepada :
1. Kedua Orang Tua Tercinta yang telah memberi dukungan kepada penulis baik moral, spiritual maupun material selama masa studi.
2. Ibu Paulina Heruningsih Prima Rosa,S.Si.,M.Sc. selaku dosen pembimbing yang telah memberikan dukungan, bantuan dan dorongan kepada penulis selama mengikuti proses perkuliahan sampai dengan penyelesaian skripsi ini.
3. Ibu Paulina Heruningsih Prima Rosa,S.Si.,M.Sc. selaku Dekan Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
4. Ibu Ridowati Gunawan,S.Kom.,M.T. selaku Ketua Jurusan Teknik Informatika Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
xii
6. Kakak, Adik, keponakan dan seluruh keluarga besar tersayang atas doa dan dukungannya.
7. Palus Herdiyatma, Maria Goreti S. putri, dan semua teman-teman Teknik Informatika angkatan 2008, terima kasih atas semangat dan bantuan yang sangat berarti sehingga akhirnya skripsi ini dapat terselesaikan.
Dalam penulisan skripsi ini, pastilah masih banyak kekurangan dan hal yang perlu diperbaiki. Oleh karena itu saran dan kritik dari pembaca yang sekiranya dapat membangun sangat penulis harapkan.
Akhir kata, semoga penulisan skripsi ini berguna untuk menambah wawasan ataupun menjadi referensi bagi para pembaca sekalian khususnya pada mahasiswa Teknik Informatika.
Yogyakarta, 31 Maret 2013
xiii
DAFTAR ISI
HALAMAN JUDUL ... i
HALAMAN JUDUL ... ii
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ...v
HALAMAN MOTTO ...v
HALAMAN PERSEMBAHAN ... vi
PERNYATAAN KEASLIAN KARYA ... vii
ABSTRAK ... viii
ABSTRACT ... ix
PERNYATAAN PERSETUJUAN...x
KATA PENGANTAR ... xi
DAFTAR ISI ... xiii
DAFTAR TABEL ... xvii
DAFTAR GAMBAR ... xxiv
BAB I : PENDAHULUAN ...1
I. 1. Latar Belakang ... 1
I. 2. Rumusan Masalah ... 4
I. 3. Tujuan Penelitian ... 4
I. 4. Batasan Masalah ... 5
xiv
I. 6. Manfaat dan Kegunaan Penelitian ... 6
I. 7. Metodologi Penelitian ... 6
I.7. 1. Analisis ... 7
I.7. 2. Desain ... 7
I.7. 3. Implementasi ... 7
I.7. 4. Pengujian ... 8
I. 8. Sistematika Penulisan ... 8
BAB II : TINJAUAN PUSTAKA ...11
II. 1. Pengertian Penambangan Data ... 11
II. 2. Proses Penambangan Data ... 11
II. 3. Algoritma Penambangan Data ... 14
II.3 .1. Klasifikasi ... 14
II.3 .2. Klastering ... 15
II.3 .3. Asosiasi ... 16
II. 4. Algoritma Penambangan Aturan Asosiasi Langka ... 23
BAB III : ANALISA DAN PERANCANGAN ...61
III. 1. Identifikasi dan Analisis Sistem ... 61
III.1 .1. Use Case ... 63
III.1 .2. Narasi Use Case ... 66
III. 2. Perancangan Sistem Secara Umum ... 69
III.2 .1. Input ... 69
III.2 .2. Proses ... 70
xv
III.2. 2.2. Penerapan Algoritma Apriori Inverse ... 75
III.2 .3. Output ... 76
III. 3. Perancangan Sistem ... 78
III. 4. Desain Antarmuka ... 103
III.3.4. 1. Tampilan Halaman Utama Sistem ... 103
III.3.4. 2. Tampilan Halaman Deteksi Data... 104
III.3.4. 3. Tampilan Grafik Halaman Lihat Grafik ... 106
III.3.4. 4. Tampilan Tentang Program ... 107
III.3.4. 5. Tampilan Menu File ... 107
III.3.4. 6. Tampilan Menu Tentang ... 108
III.3.4. 7. Tampilan Open File ... 108
BAB IV : IMPLEMENTASI PENAMBANGAN DATA...110
IV. 1. Implementasi Antarmuka ... 110
IV.2. 1. Implementasi Halaman Utama ... 110
IV.2. 2. Implementasi Halaman Deteksi Data ... 112
IV.2. 3. Implementasi Pengecekan Masukan ... 114
IV.2. 4. Implementasi Halaman Lihat Grafik ... 118
IV.2. 5. Implementasi Halaman Tentang Program ... 119
IV.2. 6. Implementasi Halaman Open File ... 120
xvi
BAB V : ANALISIS HASIL ...123
V. 1. Fase Implementasi Pengujian ... 123
V. 2. Kelebihan dan Kekurangan Sistem ... 148
V.2. 1. Kelebihan Sistem ...149
V.2. 2. Kekurangan Sistem ...149
BAB VI : KESIMPULAN DAN SARAN ...150
DAFTAR PUSTAKA ...153
LAMPIRAN ...154
Lampiran 1 Narasi Use Case ... 154
Lampiran 2 Diagram Aktivitas ... 197
Lampiran 3 Sequence Diagram ... 204
Lampiran 4 Listing Program Halaman Utama ... 212
Lampiran 5 Listing Program Halaman Deteksi Data ... 215
Lampiran 6 Listing Halaman Lihat Grafik ... 269
Lampiran 7 Listing Halaman Diagram Batang Atribut ... 282
Lampiran 8 Listing Program Halaman Tentang Program ... 283
Lampiran 9 Hasil Aturan Asosiasi Langka Secara Hitung Manual, Sistem dan Jurnal Ilmiah ... 284
xvii
DAFTAR TABEL
Tabel 3.1 Tabel Kelas Itemset. ... 83
Tabel 3.2 Tabel Kelas Candidate. ... 84
Tabel 3.3 Tabel Kelas Largeitemset. ... 86
Tabel 3.4 Tabel Kelas Ls. ... 87
Tabel 3.5 Tabel Kelas ProsesAPIC. ... 87
Tabel 3.6 Tabel Kelas Centroid. ... 99
Tabel 3.7 Tabel Kelas DataBaseConnection. ... 99
Tabel 3.8 Tabel Kelas BarChart. ... 100
Tabel 3.9 Tabel Kelas Grafik. ... 100
Tabel 5.1 Tabel Rencana Pengujian. ... 124
Tabel 5.2 Tabel Pengujian DatabaseConnection. ... 125
Tabel 5.3 Tabel Pengujian ProsesAPIC. ... 128
Tabel 5.4 Tabel Pengujian Halaman_Lihat_Grafik. ... 130
Tabel 5.5 Tabel Perbandingan Hasil Aturan Asosiasi Langka. ... 133
Tabel 5.6 Tabel Variasi Minimum Support Threshold System ... 138
Tabel 5.7 Tabel Variasi Minimum Support ... 140
Tabel 5.8 Tabel Variasi Maximum Support ... 143
Tabel 5.9 Tabel Variasi Minimum Confidence ... 146
xviii
Tabel 5.11 Tabel Hitung Manual Dengan Minimum Support Threshold system = 5%, Minimum Support = 10%, Maximum Support = 30%, Minimum
Confidence = 90%. ... 286
Tabel 5.12 Tabel Hitung Manual Dengan Minimum Support Threshold system = 5%, Minimum Support = 15%, Maximum Support = 30%, Minimum Confidence = 90%. ... 286
Tabel 5.13 Tabel Hasil Perhitungan Sistem (1) ... 287
Tabel 5.14 Tabel Hasil Perhitungan Sistem (2) ... 289
Tabel 5.15 Tabel Hasil Perhitungan Sistem (3) ... 290
Tabel 5.16 Tabel Aturan Asosiasi Langka Dalam Jurnal Untuk Dataset Congressional Votes. ... 290
Tabel 5.17 Tabel Aturan Asosiasi Langka Dalam Jurnal Untuk Dataset Zoo. ... 291
Tabel 5.18 Tabel Aturan Asosiasi Langka Dataset Congressional Votes Dari Sistem Dengan Konfigurasi Minimum Support Threshold system = 5%, Minimum Support = 15%, Maximum Support = 30%, Minimum Confidence = 90%. ... 292
xix
xx
xxi
xxii
xxiii
xxiv
DAFTAR GAMBAR
Gambar 2.1. Tahap – Tahap Data Mining ... 13 Gambar 2.2. Data mining dan teknologi basisdata lainnya ... 14 Gambar 2.3. Algoritma Apriori Inverse ... 24 Gambar 2.4. Flow chart Garis Besar Algoritma Apriori Inverse with Clustering
(APIC) ... 28 Gambar 3.1. Use Case. ... 65 Gambar 3.2. Proses Umum Sistem Deteksi Aturan Langka. (a) Proses Apriori
inverse untuk deteksi rare rules. (b) Clustering untuk pengelompokan
transaksi. ... 71 Gambar 3.3 Algoritma Transaction Clustring. ... 74 Gambar 3.4. Proses Penentuan Rare Association Rules menggunakan algoritma
Apriori Inverse. ... 76 Gambar 3.5. Diagram Konteks... 78 Gambar 3.6. Diagram Kelas. ... 80 Gambar 3.7. Tampilan Antarmuka Pendeteksian Aturan Asosiasi Langka(Rare
xxv
xxvi
Gambar 5.1 Grafik uji coba dataset congressional votes dengan mengubah nilai minimum support threshold system ... 139 Gambar 5.2 Grafik uji coba dataset zoo dengan mengubah nilai minimum support
threshold system ... 139 Gambar 5.3 Grafik uji coba dataset heart cleveland dengan mengubah nilai
minimum support threshold system ... 139 Gambar 5.4 Grafik uji coba dataset congressional votes dengan mengubah nilai
minimum support ... 141 Gambar 5.5 Grafik uji coba dataset zoo dengan mengubah nilai minimum support
... 142 Gambar 5.6 Grafik uji coba dataset heart cleveland dengan mengubah nilai
minimum support ... 142 Gambar 5.7 Grafik uji coba dataset congressional votes dengan mengubah nilai
maximum support ... 144 Gambar 5.8 Grafik uji coba dataset zoo dengan mengubah nilai maximum support
... 144 Gambar 5.9 Grafik uji coba dataset heart cleveland dengan mengubah nilai
maximum support ... 145 Gambar 5.10 Grafik uji coba dataset congressional votes dengan mengubah nilai
minimum confidence ... 147 Gambar 5.11 Grafik uji coba dataset zoo dengan mengubah nilai minimum
xxvii
Gambar 5.12 Grafik uji coba dataset heart cleveland dengan mengubah nilai minimum confidence ... 147 Gambar 3.1. Diagram Aktivitas Memilih Data Bertipe Excel file. ... 197 Gambar 3.2. Diagram Aktivitas Memilih Data Dari Basis Data... 197 Gambar 3.3. Diagram Aktivitas Mengatur Konfigurasi Basis Data. ... 198 Gambar 3.4. Diagram Aktivitas Memasukan Query. ... 198 Gambar 3.5. Diagram Aktivitas Eksekusi Query. ... 199 Gambar 3.6. Diagram Aktivitas Memilih Atribut Data yang Akan Dilihat Dalam
Grafik. ... 199 Gambar 3.7. Diagram Aktivitas Melihat Detail Data per Atribut. ... 200 Gambar 3.8. Diagram Aktivitas Melihat Grafik Diagram Batang per Atribut. .. 200 Gambar 3.9. Diagram Aktivitas Mengatur Konfigurasi Proses Penambangan Data.
... 201 Gambar 3.10. Diagram Aktivitas Menghapus Data Dalam Tabel. ... 201 Gambar 3.11. Diagram Aktivitas Mendeteksi Aturan Asosiasi Langka. ... 202 Gambar 3.12. Diagram Aktivitas Melihat Hasil Pendeteksi Aturan Asosiasi
Langka. ... 202 Gambar 3.13. Diagram Aktivitas Melihat Hasil Pembacaan Data Dalam Sistem.
xxviii
Gambar 3.18. Diagram Sequence Eksekusi Query. ... 206 Gambar 3.19. Diagram Sequence Memilih Atribut Dataset yang Akan Dilihat
Dalam Grafik. ... 206 Gambar 3.20. Diagram Sequence Melihat Detail Data per Atribut. ... 207 Gambar 3.21. Diagram Sequence Melihat Grafik Diagram Batang per Atribut. 207 Gambar 3.22. Diagram Sequence Mengatur Konfigurasi Proses Penambangan
Data. ... 208 Gambar 3.23. Diagram Sequence Menghapus Data dalam tabel. ... 208 Gambar 3.24. Diagram Sequence Melihat Hasil Pendeteksian Aturan Asosiasi
Langka (Rare Association Rules). ... 209 Gambar 3.25. Diagram Sequence Mendeteksi Aturan Asosiasi Langka (Rare
Association Rule). ... 210 Gambar 3.26. Diagram Sequence Melihat Hasil Pembacaan Data Dalam Sistem.
1
BAB I
PENDAHULUAN
I. 1. Latar Belakang
Penambangan data (data mining) dapat diartikan sebagai “suatu proses ekstraksi informasi yang berguna dan potensial dari sekumpulan data yang
terdapat secara implisit dalam suatu sistem penyimpanan basis data” (Han &
Kamber, 2006). Terdapat beberapa teknik penambangan data diantaranya klastering, klasifikasi, dan asosiasi.
Asosiasi adalah salah satu teknik yang terkenal dan banyak digunakan. Salah satu kegunaanya adalah mendeteksi item, himpunan item, dan hubungan antar item dalam basis data yang memiliki frekuesi kemunculan tinggi. Fokus dari asosiasi adalah menemukan item dan himpunan item yang sering kali muncul dalam transaksi yang terjadi dalam basis data dan nantinya bisa diolah menjadi data penting yang bisa digunakan sebagai pertimbangan dalam mengambil kebijakan. Sebagai contoh pada bisnis perdagangan, asosiasi dapat membantu dalam hal menentukan jenis barang yang harus dijual dan merupakan jenis barang yang diminati oleh pelanggan. Perhatian seringkali difokuskan pada item yang sering muncul, padahal disamping item yang sering muncul juga terdapat item yang jarang muncul (rare item).
dalam basis data. Item langka yang ada dalam basis data dapat membentuk aturan langka yang penting untuk diketahui dan diamati.
Aturan langka (rare rules) adalah aturan yang bersifat jarang terjadi dalam sebuah basis data berukuran besar akan tetapi mengandung informasi penting yang kadang dilupakan oleh pengguna atau pengamat basis data. Aturan langka perlu ditambang karena aturan ini bisa jadi memuat informasi penting. Dalam aturan asosiasi fokus terhadap aturan langka sangat kecil karena item ini terjadi hanya pada lingkup transaksi yang kecil dan terbatas, sehingga bagian ini jarang tereksplorasi dalam proses penambangan aturan asosiasi bahkan item ini dipangkas dari proses penambangan aturan asosiasi. Namun dalam beberapa aplikasi terapan dari aturan asosiasi mulai memperhatikan item langka karena item yang berjumlah sedikit ini merupakan item penting dan perlu mendapat perhatian khusus. Sebagai contoh dalam bidang kedokteran, sudah banyak penyakit yang sudah ditemukan dan sering terjadi seperti batuk, flu akan tetapi ada penyakit yang jarang terjadi dan hanya terjadi dalam kurun waktu tertentu seperti fenomena manusia akar. Dalam dunia komunikasi, item langka dapat digunakan untuk mendeteksi kegagalan komunikasi (Koh & Pears, 2010). Berdasar pada alasan inilah maka muncul proses penambangan aturan asosiasi langka (rare association rule mining) yang digunakan untuk mendeteksi item, himpunan item, danhubungan antar item yang bersifat jarang atau langka.
pendekatan diantaranya APIC (Apriori Inverse with Clustering), APICW (Weighted Apriori Inverse), dan masih banyak algoritma lainnya.
Dari masalah yang muncul di atas mengenai item langka, cara menentukan apakah himpunan item termasuk benar-benar terjadi secara langka atau hanya kebetulan, maka perlu alat bantu untuk melakukan proses penambangan aturan asosiasi langka yang bisa membantu dalam proses pencarian aturan langka dan item langka yang terkait. Karena belum adanya alat bantu penambangan data yang dapat digunakan untuk menangani proses penambangan aturan asosiasi langka, dan item langka yang terkait (en.Wikipedia.org), maka penulis berinisiatif untuk mengatasi masalah tersebut dengan membangun sebuah perangkat lunak penambangan data. Fungsi perangkat lunak ini adalah untuk melakukan proses pendeteksian aturan asosiasi langka dalam kumpulan data dengan menerapkan algoritma APIC (Apriori Inverse with Clustering). Dengan aturan (rule) yang ditemukan menggunakan algoritma ini diharapkan agar permasalahan aturan langka bisa diselesaikan, dan sistem ini bisa membantu mempermudah proses penambangan aturan asosiasi langka yang masih belum adaalat bantunya.
algoritma APIC. Algoritma APIC mengatasi ledakan kombinatorial aturan yang dihasilkan dalam proses apriori inverse dengan cara mengkombinasikan algoritma apriori inverse dengan algoritma transaction clustering. Selain alasan tersebut, alasan utama memilih pendekatan APIC (Apriori Inverse with Clustering) adalah berdasarkan riset dan data set nyata yang dilakukan terbukti bahwa APIC (Apriori Inverse with Clustering) mempunyai kemampuan untuk menghasilkan aturan dengan tingkat keakuratan yang teliti dan tepat (Koh & Pears,2010).
I. 2. Rumusan Masalah
Rumusan masalah mendasar yang akan diselesaikan pada penelitian ini adalah :
1. Bagaimana membangun alat bantu penambangan data untuk menemukan atau mendeteksi aturan asosiasi langka dengan menggunakan algoritma APIC (Apriori Inverse with Clustering)?
2. Sejauh mana algoritma APIC (Apriori Inverse with Clustering) mampu menemukan aturan langka dalam kumpulan data yang tersimpan dalam media penyimpanan basis data?
I. 3. Tujuan Penelitian
Penelitian ini dilakukan dengan tujuan untuk:
2. Mengetahui akurasi algoritma APIC (Apriori Inverse with Clustering) dalam mendeteksi aturan asosiasi langka.
I. 4. Batasan Masalah
Batasan masalah dipakai sebagai pembatas terhadap ruang lingkup (scope) dari penelitian ini, apa yang dikerjakan dan apa yang tidak bisa dikerjakan dalam melakukan penelitian ini. Batasan masalah dari penelitian ini adalah sebagai berikut :
1. Data yang digunakan didapat dari sumber
http://www.archive.ics.uci.edu/ml/machine-learning-databases bukan berdasar data dari studi kasus tertentu.
2. Tidak sembarang format data dapat digunakan dalam penelitian ini, format data yang bisa diproses hanya data yang berformat excel file (excel 97-2003 workbook) dan data yang tersimpan dalam basis data.
3. Koneksi basis data yang digunakan dikhususkan untuk basis data MySql. 4. Sistem tidak menangani preproses data, data yang dimasukan dalam sistem
merupakan data yang sudah mengalami preproses sebelumnya seperti pembersihan data (data cleaning), konversi, dan lain-lain.
6. Hasil akhir penelitian difokuskan pada aspek penambangan aturan asosiasi langka bukan aspek efektivitas dan kemudahan pengguna dalam menggunakan sistem.
I. 5. Luaran Penelitian
Luaran dari penelitian ini adalah aplikasi pendeteksi aturan asosiasi langka yang diberi nama Sistem Deteksi Aturan Asosiasi Langka (SDAAL) dan mempunyai kemampuan untuk mendeteksi aturan asosiasi langka dalam kumpulan data yang tersimpan dalam media penyimpanan basis data.
I. 6. Manfaat dan Kegunaan Penelitian
Manfaat dan kegunaan penelitian ini meliputi :
1. Sistem aplikasi yang dihasilkan dari penelitian ini dapat digunakan untuk membantu menemukan aturan asosiasi langka dalam basis data.
2. Aturan yang dihasilkan bisa digunakan untuk pertimbangan dalam berbagai hal sesuai dengan konteks data yang diproses dalam sistem aplikasi.
I. 7. Metodologi Penelitian
I.7. 1. Analisis
Analisis dilakukan untuk mengetahui hal-hal apa saja yang dibutuhkan untuk pengembangan sistem. Studi literatur dilakukan untuk mengetahui kebutuhan-kebutuhan mengenai pendeteksian aturan langka dalam basis data yang berukuran besar, teknik-teknik pendeteksiannya serta perbandingan terhadap penelitian lain yang pernah dilakukan sebelumnya. Selain itu dalam tahap ini juga terdapat diagram use case yang digunakan untuk menggambarkan hasil analisis kebutuhan terkait dengan proses pendeteksian aturan asosiasi langka.
I.7. 2. Desain
Desain yang dilakukan meliputi desain pengembangan sistem pendeteksi aturan asosiasi langka seperti desain diagram aktivitas, desain kelas (UML), diagram sekuen, desain antar muka pengguna, dan algoritma yang akan digunakan.
I.7. 3. Implementasi
I.7. 4. Pengujian
Pada penelitian ini dilakukan 3 jenis pengujian yaitu pengujian validitas sistem, pengujian efek perubahan nilai atribut penambangan data, dan black box. Pengujian validitas sistem dilakuan dengan cara membandingkan aturan yang dihasilkan dari perhitungan secara manual, perhitungan menggunakan sistem dan hasil dari jurnal ilmiah (Koh & Pears, 2010). Pengujian validitas sistem menggunakan tiga dataset yang akan diuji satu per satu. Dataset yang akan digunakan adalah dataset congressional votes, zoo, heart Cleveland yang didapat dari UCI Machine Learning Repository yang berada pada website archive.ics.uci.edu/ml/machine-learning-databases. Sedangkan untuk uji efek perubahan nilai atribut penambangan data adalah dengan cara merubah – rubah setiap nilai dari atribut penambangan data yaitu minmum support threshold system, minimum support, maximum support, minimum confidence. Untuk metode pengujian blackbox, metode yang digunakan adalah metode yang berfokus pada persyaratan fungsional perangkat lunak yang dibuat, sehingga tidak tergantung pada proses yang dilakukan oleh sistem secara internal.
I. 8. Sistematika Penulisan
Adapun sistematika penulisan tugas akhir ini adalah sebagai berikut: 1. Bab I Pendahuluan
2. Bab II Tinjauan Pustaka
Tinjauan Pustaka berisi tentang teori yang akan digunakan dalam penulisan tugas akhir dan proses penyelesaiannya. Teori yang digunakan adalah pertama penambangan data (data mining), ke dua proses penambangan data yang terdiri dari Pembersihan Data (Data Cleaning), Penggabungan Data (Data Integration ), Seleksi Data ( Data Selection), Transformasi Data ( Data Transformation ), Penambangan Data ( Data Mining ), Evaluasi Pola ( Pattern Evaluation ), Presentasi Pengetahuan ( Knowledge Presentation ). Teori yang ke tiga adalah mengenai algoritma penambangan data yang terdiri dari klasifikasi, klastering, asosiasi, algoritma apriori, dan penambangan aturan asosiasi langka. Teori yang ke empat adalah teori mengenai algoritma penambangan aturan asosisasi langka yang terdiri dari apriori inverse, algoritma APIC (Apriori Inverse with Clustering), dan contoh penerapan algoritma APIC.
3. Bab III Analisis dan Perancangan
4. Bab IV Implementasi Penambangan Data
Implementasi program berisi tentang implementasi antar muka sistem, implementasi pengecekan masukan, implementasi dataset dan analisa dari masing masing tampilan program.
5. Bab V Pengujian Dan Analisa Hasil Pengujian
Pengujian berisi tentang pengujian validitas program dengan menggunakan uji coba terhadap berbagai jenis dataset. Sedangkan untuk analisa hasil pengujian berisi tentang pembahasan umum mengenai program, hasil analisa, dan pemaparan hasil pengujian.
6. Bab VI Kesimpulan dan Saran
Kesimpulan dan saran berisi tentang kesimpulan dan saran dari penulis tugas akhir mengenai penelitian yang dilakukan.
7. Daftar Pustaka
11
BAB II
TINJAUAN PUSTAKA
II. 1. Pengertian Penambangan Data
Istilah Penambangan data (data mining) sudah berkembang jauh dalam mengadaptasi setiap bentuk analisa data. Pada dasarnya data mining berhubungan dengan analisa data dan penggunaan teknik-teknik perangkat lunak untuk mencari pola dan keteraturan dalam himpunan data yang sifatnya tersembunyi. Namun saat ini penambangan data jauh berkembang dengan adanya algoritma penambangan data yang membantu dalam melakukan ekstraksi informasi penting dari jumlah data yang besar.
Penambangan data dapat diartikan sebagai “suatu proses ekstraksi informasi berguna dan potensial dari sekumpulan data yang terdapat secara
implisit dalam suatu basis data” (Han & Kamber, 2006). Penambangan data merupakan bagian dari knowledge discovery in databases (KDD), dimana penambangan data berfungsi sebagai proses untuk mengekstrak data menjadi informasi yang berguna.
II. 2. Proses Penambangan Data
Menurut Jiawei Han dan Kamber dalam bukunya “Data Mining: Concepts
1. Pembersihan Data ( Data Cleaning )
Pada tahap ini dilakukan proses membuang data yang tidak konsisten dan noise. Contohnya: data yang kadaluarsa, salah pengetikan maupun data yang kosong.
2. Penggabungan Data ( Data Integration )
Penggabungan data dari beberapa sumber agar seluruh data terangkum dalam satu tabel yang utuh.
3. Seleksi Data ( Data Selection
Menyeleksi data dimana data yang relevan diambil dari database. 4. Transformasi Data ( Data Transformation )
Mentranformasikan atau merubah data kedalam bentuk yang sesuai untuk ditambang.
5. Penambangan Data ( Data Mining )
Penerapan teknik penambangan data untuk mengekstrak pola. 6. Evaluasi Pola ( Pattern Evaluation )
Pola yang didapat dari proses penambangan data akan dievaluasi dengan hipotesa yang telah dibentuk sebelumnya. Akhir dari tahap ini adalah diperolehnya persentase akurasi data.
7. Presentasi Pengetahuan ( Knowledge Presentation )
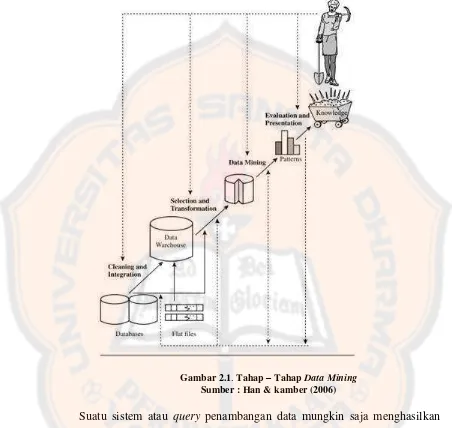
Tahap – tahap tersebut diilustrasikan pada gambar 2.1 di bawah ini :
Gambar 2.1. Tahap – Tahap Data Mining
Sumber : Han & kamber (2006)
Suatu sistem atau query penambangan data mungkin saja menghasilkan ribuan pola, namun tidak semua pola tersebut adalah pola yang menarik atau penting. Ukuran suatu pola yang menarik atau penting adalah jika pola tersebut mudah dimengerti oleh manusia, bermanfaat, valid / benar pada data baru atau data tes dan membenarkan beberapa hipotesis.
yang akan digunakan untuk analisa data menggunakan teknik penambangan data sedangkan OLAP adalah basisdata yang khusus digunakan untuk menunjang proses pengambilan keputusan (decision making). Teknologi yang ada di gudang data dan OLAP dimanfaatkan penuh untuk melakukan penambangan data. Gambar di bawah ini menunjukkan posisi masing – masing teknologi basisdata tersebut :
Gambar 2.2. Data mining dan teknologi basisdata lainnya Sumber : Jiawei Han and Micheline Kamber
www.cs.uiuc.edu/~hanj
II. 3. Algoritma Penambangan Data
Dalam penambangan data ada beberapa algoritma untuk melakukan penambangan data diantaranya:
II.3 .1. Klasifikasi
himpunan obyek di dalarn sebuah basis data, dan mengklasifikasikannya ke dalam kelas-kelas yang berbeda menurut model klasifikasi yang ditetapkan.
Untuk membentuk sebuah model klasifikasi, suatu sampel basis data 'E' diperlakukan sebagai training set, dimana setiap baris terdiri dari himpunan yang sama yang memuat atribut yang beragam seperti baris - baris yang terdapat dalam suatu basis data yang besar 'W'. Setiap tupel diidentifkasikan dengan sebuah label atau identitas kelas. Tujuan dari klasifikasi ini adalah untuk menganalisa training data dan membentuk sebuah deskripsi yang akurat atau sebuah model untuk setiap kelas berdasarkan fitur yang tersedia di dalam data itu. Deskripsi dari masing-masing kelas itu nantinya akan digunakan untuk mengklasifikasikan data yang hendak di test dalam basis data 'W', atau untuk membangun suatu deskripsi yang lebih balk untuk setiap kelas dalam basis data.
II.3 .2. Klastering
suatu sistem skala besar, menjadi komponen-komponen yang lebih kecil, untuk menyederhanakan proses desain dan implementasi.
II.3 .3. Asosiasi
Penambangan aturan asosiasi merupakan proses pencarian aturan-aturan hubungan antar item dari suatu basis data transaksi atau basis data relasional, telah menjadi perhatian utama dalam basis data. Tugas utamanya adalah untuk menemukan suatu himpunan hubungan antar item dalam bentuk A => B dimana A dan B adalah himpunan atribut nilai, dari sekumpulan data yang relevan dalam suatu basis data.
Oleh karena proses untuk menemukan hubungan antar item ini mungkin memerlukan pembacaan data transaksi secara berulang-ulang dalam sejumlah besar data-data transaksi untuk menemukan pola-pola hubungan yang berbeda-beda, maka waktu dan biaya komputasi tentunya juga akan sangat besar, sehingga untuk menemukan hubungan tersebut diperlukan suatu algoritma yang efisien dan metode – metode tertentu.
yang melebihi batas tertentu. Suatu aturan asosiasi dirasa valid apabila mempunyai nilai confidence/ nilai kepastian ≥ 50 % (López-Cózar, 2000).
Support dari aturan adalah rasio dari record yang mengandung dengan total record dalam basisdata. Untuk mendapatkan nilai support dapat menggunakan rumus :
...(2.1) Sedangkan Minsup (minimum support) atau biasa disebut dengan istilah lower bound support menandakan ambang batas (threshold) yang menentukan apakah sebuah itemset akan digunakan pada perhitungan selanjutnya untuk pencarian aturan asosiasi.
Confidence dari aturan asosiasi adalah rasio dari record yang mengandung dengan total record yang mengandung . Untuk mendapatkan nilai confidence dapat menggunakan rumus :
.......(2.2)
Atau dapat ditulis sebagai berikut:
...(2.3). Sedangkan Minconf (minimum confidence) menandakan ambang batas (threshold) dari sebuah aturan asosiasi untuk menentukan aturan asosiasi yang kuat (strong association rule).
Tabel 2.1 Contoh Tabel Transaksi D
TID Itemset
1 Bread, Milk
2 Bread,Diaper,Beer,Eggs
3 Milk,Diaper,Beer,Coke
4 Bread,Milk,Diaper,Beer
5 Bread,Milk,Diaper,Coke
Misalkan akan dihasilkan rule: {Milk,Diaper}→Beer Maka support menjadi
Confidence menjadi
Secara umum yang dilakukan dalam proses pencarian aturan asosiasi ini dapat dibagi menjadi 2 tahapan, yang terdiri dari :
o Pencarian frequent itemset
Yaitu proses pencarian semua itemset yang memiliki nilai support minsup. Itemset ini disebut frequent itemset atau large itemset (l-itemset). Dalam tugas akhir ini proses pencarian frequent itemset menggunakan algoritma apriori.
o Pembentukan strong association rule
II.3 .4. Algoritma Apriori
Algoritma apriori merupakan algoritma untuk mencari frequent itemset yang berdasarkan prinsip apriori, yaitu jika suatu itemset merupakan frequent itemset maka semua subset-nya akan berupa frequent itemset (Tan, et.al. 2006). Pembentukan frequent itemset dilakukan dengan mencari semua kombinasi item – item yang memiliki support lebih besar atau sama dengan minsup yang telah ditentukan.
Pseudocode untuk pencarian frequent itemset menggunakan algoritma apriori adalah sebagai berikut (Gunawan, 2003) :
= candidate itemset untuk ukuran k
= frequent itemset / large itemset untuk ukuran k = {candidate 1-itemset}
= {large 1-itemset}
for ( ) do begin
// new candidate
for all transaction do begin
//candidate contained in
for all candidates do
end
end
Algoritma diatas dapat dijelaskan sebagai berikut :
a. Pada iterasi pertama dihitung jumlah kemunculan setiap item dalam transaksi untuk menentukan large 1-itemset. Pada iterasi selanjutnya akan dihasilkan candidate k-itemset ( ) menggunakan frequent (k-1)-itemset yang ditemukan pada iterasi sebelumnya. Candidate generation diimplementasikan menggunakan sebuah fungsi yang disebut apriori-gen. Apriori-gen digunakan untuk menghasilkan candidate itemset, yang menyebabkan tidak seluruh itemset diolah pada proses selanjutnya, hanya yang memenuhi persyaratan saja yaitu sesuai dengan support yang telah ditentukan. Hal ini mempersingkat waktu proses pencarian seluruh aturan asosiasi.
b. Setelah itu, dilakukan penelusuran dalam basisdata untuk menghitung support bagi setiap candidate itemset dalam . Untuk setiap transaksi t, dicari semua candidate itemset t dalam set yang terkandung dalam transaksi tersebut. Kumpulan dari semua candidate itemset dalam yang terkandung dalam transaksi t disebut dan ditulis dengan notasi .
c. Selanjutnya nilai support dari semua candidate k-itemset dalam Ct dinaikkan. Penelusuran dilanjutkan pada transaksi berikutnya sampai semua
transaksi dalam basisdata ditelusuri. Lalu akan dilakukan eliminasi candidate itemset yang memiliki nilai support lebih kecil dari minsup. Sedangkan semua candidate k-itemset yang memenuhi minsup disimpan dalam yang akan digunakan untuk membentuk large (k+1)-itemset. Algoritma berakhir ketika tidak ada large itemset baru yang dihasilkan.
Pencarian frequent itemset menggunakan algoritma apriori memiliki 2 karakteristik penting. Pertama, apriori merupakan algoritma level-wise dimana proses pada algoritma ini membangkitkan frequent itemset per level, dimulai dari level 1-itemset sampai ke itemset terpanjang dan candidate level yang baru, dibentuk dari frequent itemset yang ditemukan di level sebelumnya lalu menentukan nilai supportnya. Kedua, algoritma ini menggunakan strategi generate and test untuk menemukan frequent itemset. Pada tiap iterasi, candidate itemset yang baru, dihasilkan dari frequent itemset yang ditemukan pada iterasi sebelumnya. Nilai support tiap candidate dihitung dan di bandingkan kembali dengan ambang batas minsupnya. Jumlah iterasi yang dibutuhkan algoritma ini adalah , dimana merupakan ukuran maksimum dari frequent itemset.
II.3 .5. Penambangan Aturan Asosiasi Langka (Rare Association Rule)
Aturan asosiasi langka ditandai dengan adanya aturan yang memiliki nilai support rendah akan tetapi confidence tinggi. Menghasilkan aturan seperti itu adalah masalah yang sulit dalam proses penambangan data. Dalam rangka untuk mencari aturan-aturan yang bersifat langka, maka digunakan pendekatan tradisional seperti algoritma Apriori. Dengan menggunakan algoritma Apriori upper bound support threshold harus diset dengan nilai rendah, agar bisa mendapatkan aturan langka yang diinginkan, akan tetapi tindakan tersebut akan menghasilkan kombinasi yang banyak dari aturan maupun dari item yang ditambang, yang akan memakan banyak memori.
Untuk menemukan aturan asosiasi minsup harus diset sangat rendah. Namun pengaturan ambang batas ini akan menyebabkan ledakan kombinatorial dalam hal jumlah himpunan item yang dihasilkan. “Item yang sering terjadi (frequent item) akan terkait satu sama lain, hal ini karena item-item tersebut tidak
bisa tidak muncul secara bersamaan. Hal semacam ini dikenal sebagai masalah
item langka” (Koh & Pears, 2010). Ini berarti bahwa dengan menggunakan algoritma Apriori, kita tidak mungkin menghasilkan rule yang efektif dan dapat digunakan untuk mengindikasikan peristiwa langka karena adanya potensi ledakan kombinatorial item yang dihasilkan akibat adanya modifikasi ambang batas.
“Item individu dapat memiliki support yang rendah sehingga mereka
tidak dapat berkontribusi pada rule yang dihasilkan oleh Apriori, meskipun
tinggi ” (Koh & Pears,2010). Untuk mengatasi masalah ini digunakan pendekatan yang disebut apriori inverse untuk menemukan aturan langka dengan kandidat himpunan item yang berada di bawah nilai maxsup (maximum support) akan tetapi berada di atas tingkat absolut support value. Algoritma ini menggunakan fisher test untuk menyaring item langka yang terjadi bersamaan secara murni berdasar kebetulan, sehingga tidak masuk dalam tahap untuk menghasilkan aturan.
Pendekatan apriori inverse memanfaatkan metode yang lebih ketat seperti fisher test untuk menentukan co-occurrence dari item langka. Penggunaan fisher test dianggap menarik dari sudut pandang konseptual karena untuk proses perhitungannya dibutuhkan subjektivitas pertimbangan untuk setiap item. Ditambah dengan fakta bahwa kualitas aturan yang dihasilkan terbukti unggul namun memiliki waktu eksekusi yang lebih baik daripada algoritma yang lainnya. Apriori Inverse adalah pilihan yang logis menghasilkan aturan langka dari basis data yang besar.
II. 4. Algoritma Penambangan Aturan Asosiasi Langka
kelemahan masing-masing. Penambangan aturan asosiasi langka memiliki beberapa pendekatan diantaranya:
II. 4.1 Apriori Inverse
Misal I = { } merupakan semesta dari item dan D adalah himpunan transaksi, di mana setiap transaksi T berisi satu set item yang memenuhi aturan T I.
Gambar 2.3. Algoritma Apriori Inverse
Sumber : Koh & Pears (2010)
C(R) ≥ CLower dimana CLower adalah lower bound confidence threshold atau biasa disebut sebagai minimum confidence yang didefinisikan nilainya oleh pengguna yang melakukan penambangan data. Minimum confidence menandakan ambang batas (threshold) dari sebuah aturan asosiasi untuk menentukan aturan asosiasi yang kuat (strong association rule).
S(R) ≤ SUpper dimana SUpper adalah upper bound support threshold atau biasa disebut maximum support threshold yang digunakan sebagai batas atas support dari himpunan item yang ada dalam kandidat aturan. Maximum support digunakan untuk membatasi nilai support dari aturan yang ada sehingga hanya aturan tertentu saja yang bisa dijadikan atau diputuskan sebagai aturan asosiasi dari sebuah dataset.
Selain yang dijelaskan diatas, dalam algoritma Apriori Inverse juga menerapkan penggunaan support constraint lain, yang disebut MinAbsSup yang didefinisikan sebagai jumlah minimum kemunculan dari itemset (A, B) agar bisa dipertimbangkan dalam prose pembentukan aturan. Batasan (constraint) ini berasal dari fisher test untuk signifikansi co-occurrence darisetiap item.
maka semua ekstensi nilai support diperbolehkan kecuali yang termasuk di bawah nilai minimum absolut support. Itemset yang masuk dalam pengecualian ini akan dipangkas atau dihapus dari candidate itemset, dan tidak digunakan untuk memperluas himpunan item pada putaran berikutnya. Berikut adalah proses perhitungan MinAbsSup dihitung menggunakan fungsi fisher test. Pertama hitung probabilitas dari dua transaksi (A dan B) dapat terjadi bersamaan secara kebetulan dalam satu waktu tertentu (c) atau dikenal dengan istilah "probability of chance collision". Kita bisa menghitung probabilitas ini menggunakan PCC dalam (2.4). Probabilitas bahwa A dan B akan terjadi bersama-sama persis sebanyak c kali adalah:
.........(2.4)
Dimana :
C = prediksi jumlah minimum kemunculan itemset a dan b dalam transaksi di dataset agar tidak dianggap sebagai kemunculan yang bersifat kebetulan, dengan aturan 0 ≤ c ≤ a.
N = jumlah keseluruhan transaksi dalam dataset, sedangkan a dan b adalah jumlah kemunculan masing – masing items yang akan digabungkan menjadi sebuah itemset baru. Persamaan ini adalah perhitungan biasa untuk probabilitas yang sesuai untuk sebuah table dengan kontingensi 2 × 2.
Dimana :
N = jumlah keseluruhan transaksi dalam dataset.
a dan b = jumlah kemunculan masing – masing item yang akan digabungkan menjadi sebuah itemset baru.
p = memiliki nilai tetap yaitu 0,001,
m dan i = merupakan prediksi jumlah minimum kemunculan itemset a dan b dalam transaksi di dataset agar tidak dianggap sebagai kemunculan yang bersifat kebetulan, dengan aturan 0 ≤ m ≤ a.
Minimum absolute support dihitung berdasarkan nilai pcc dari setiap itemset yang akan digabungkan menjadi large itemset. Perluasan untuk setiap item menggunakan cara yang sama dalam algoritma Apriori. Sebagai contoh, 3-itemset {1, 3, 4} dan {1, 3, 6} dapat diperluas untuk membentuk 4-itemset {1, 3, 4, 6}, tetapi {1, 3, 4} dan {1, 2, 5} tidak akan menghasilkan 4-itemset karena tidak ada kesamaan prefik pada item kedua.
II. 4.2 Algoritma Apriori Inverse With Clustring (APIC)
Dataset
Transaction Clustering
Apriori Inverse
Rare Association
Rules Start
End
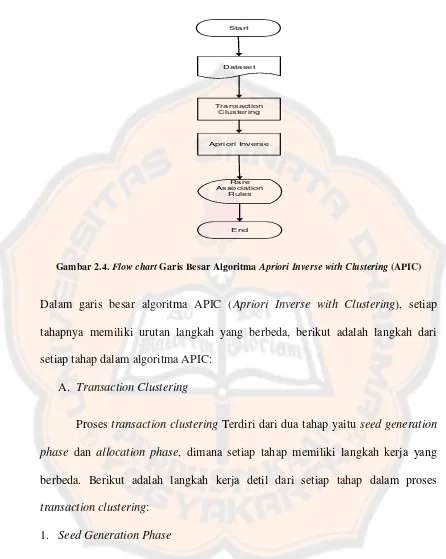
Gambar 2.4. Flow chart Garis Besar Algoritma Apriori Inverse with Clustering (APIC)
Dalam garis besar algoritma APIC (Apriori Inverse with Clustering), setiap tahapnya memiliki urutan langkah yang berbeda, berikut adalah langkah dari setiap tahap dalam algoritma APIC:
A. Transaction Clustering
Proses transaction clustering Terdiri dari dua tahap yaitu seed generation phase dan allocation phase, dimana setiap tahap memiliki langkah kerja yang berbeda. Berikut adalah langkah kerja detil dari setiap tahap dalam proses transaction clustering:
1. Seed Generation Phase
a. Cari 1-large itemset sebagai inisialisasi seed yang akan digunakan sebagai kandidat titik pusat klaster dengan cara mencari item dari setiap transaksi dalam dataset yang memiliki support count >=
, dimana:
|D| = jumlah transaksi yang ada dalam dataset,
= minimum support threshold sistem yang memiliki nilai 0< <1. b. Cari k-large itemset dalam transaksi yang ada di dataset yang nantinya akan dijadikan sebagai seed atau centroid dalam klaster.
Dimana k bernilai 2,3,…,k. Proses pencarian large itemset ini sama dengan proses pencarian large item dalam algoritma apriori hanya saja ada tambahan batasan saat melakukan perluasan dari itemset, batasan tersebut dihitung dengan aturan di bawah ini:
.........(2.7) .........…………..(2.8)
.........(2.9) Dimana:
= koefisien korelasi chi square,
= chi square cut-off threshold pada c% confidence level dengan nilai 3,84,
= nilai relative support dari kandidat gabungan itemset baru,
dan = nilai relative support dari masing – masing item yang akan diperluas menjadi itemset baru.
c. Dapatkan anggota dari k-large itemset terakhir. Anggota large itemset ini merupakan large itemset yang didalamnya terdapat itemset yang akan digunakan sebagai titik pusat (centroid) awal untuk klaster. Untuk langkah tahap seed generation phase secara sederhana dapat dilihat dalam pseudo code yang diambil dari jurnal (Koh & Pears,2010) di bawah ini:
2. Allocation Phase
a. Berdasar inti dari klaster yang telah terbentuk dalam tahap seed generation phase, lakukan alokasi semua transaksi dalam dataset kedalam setiap klaster dengan cara melakukan penghitungan similarity antara titik pusat (centroid) dari klaster dengan seluruh transaksi dalam dataset menggunakan persamaan similarity dibawah ini :
......... (2.10)
Dimana :
t = transaksi dalam dataset,
Cĸ = titik pusat dari klaster,
|t Cĸ| = jumlah item yang sama antara transaksi dengan item dalam titik pusat klaster,
|t Cĸ| = jumlah gabungan dari item yang ada di dalam transaksi dengan item yang ada dalam titik pusat klaster.
Semakin besar nilai similarity antara centroid dan transaksi maka transaksi akan dialokasikan kedalam klaster yang memiliki centroid tersebut. Klaster yang tidak memiliki anggota langsung dihapus dalam langkah ini.
b. Hitung nilai optimum dari klaster yang dihasilkan dengan menggunakan persamaan di bawah ini :
Dimana :
J = nilai fitness function, k = banyaknya klaster,
sim(t, cj) = nilai similarity antara transaksi dalam dataset dengan centroid yang ada dalam setiap klaster,
|Cj| = jumlah item dalam centroid dalam klaster.
Perhitungan ini menggunakan rata - rata nilai similarty terhadap centroid dari klaster. Nilai optimum awal sebelumnya dideklarasikan dengan nilai 0 pada putaran pertama.
c. Bandingkan nilai optimum yang didapat dalam langkah 2, Jika nilai optimum sekarang <= nilai optimum sebelumnya proses pengelompokan transaksi (allocation transaksi) berhenti, jika nilai optimum sekarang > nilai optimum sebelumnya, maka dilakukan tahap pengubahan centroid. Centroid lama digantikan dengan centroid yang baru yang berasal dari 1-large itemset yang ada dalam transaksi dari masing – masing klaster dengan cara mencari item dalam transaksi yang ada dalam klaster yang memiliki support count >= , dimana :
|D| = jumlah transaksi yang ada dalam klaster,
= minimum support threshold sistem yang memiliki nilai 0< <1. d. Lakukan langkah 1 sampai 3, hingga syarat dalam langkah 3 yaitu
proses alokasi transaksi berhenti dan simpan semua klaster yang dihasilkan dalam tahap alokasi transaksi.
Untuk lebih jelasnya berikut adalah pseudo code dari langkah – langkah pada tahap allocation phase yang diambil dari jurnal (Koh & Pears,2010):
B. Apriori Inverse
itemset dan membatasi agar tidak terjadi pembengkakan jumlah itemset, dan menggunakan MinAbsSup untuk melakukan pemangkasan itemset yang tidak diperlukan dalam proses pembentukan aturan.
Berikut adalah langkah kerja detil dari setiap tahap dalam proses apriori inverse:
1. Cari 1-large itemset dengan cara mencari item dari setiap transaksi dalam dataset yang memiliki support count <= |D| x Maxsup, dimana :
|D| = jumlah transaksi yang ada dalam klaster,
Maxsup = maximum support threshold sistem yang nilainya ditentukan oleh pengguna.
2. Cari k-large itemset dalam transaksi yang ada di dalam klaster, dimana k
bernilai 2,3,…,k. Cara mencari k-large itemset ini sama dengan proses pencarian large item dalam algoritma apriori, hanya saja nilai support digantikan dengan nilai MinAbsSup dengan menggunakan persamaan di bawah ini:
... (2.5)
Dimana :
N = jumlah keseluruhan transaksi dalam dataset,
a dan b = jumlah kemunculan masing – masing items yang akan digabungkan menjadi sebuah itemset baru,
m dan I = merupakan prediksi jumlah minimum kemunculan itemset a dan b dalam transaksi di dataset agar tidak dianggap sebagai kemunculan yang bersifat kebetulan, dengan aturan 0 ≤ m ≤ a.
Untuk menghitung MinAbsSup lakukan perhitungan pcc dari setiap pasangan item yang akan digabungkan menjadi itemset baru dengan menggunakan persamaan dibawah ini:
.........(2.4)
Dimana :
C = prediksi jumlah minimum kemunculan itemset a dan b dalam transaksi di dataset agar tidak dianggap sebagai kemunculan yang bersifat kebetulan, dengan aturan 0 ≤ c ≤ a.
N = jumlah keseluruhan transaksi dalam dataset, sedangkan a dan b adalah jumlah kemunculan masing – masing items yang akan digabungkan menjadi sebuah itemset baru
3. Hapus Semua itemset yang memiliki nilai support count < MinAbsSup dan memiliki nilai support count > maximum support.
5. Dapatkan semua k-large itemset yang memenuhi syarat perluasan item pada langkah 2, dan hitung nilai confidence masing – masing itemset dalam setiap large itemset dengan persamaan dibawah ini :
...(2.3). Dimana confidence dari aturan asosiasi adalah rasio dari record yang mengandung dengan total record yang mengandung .
6. Simpan itemset dengan nilai confidence >= minimum confidence yang ditentukan oleh pengguna.
II. 4.3 Contoh Penerapan Algoritma APIC (Apriori Inverse with Clustering)
Dataset zoo terdiri dari 101 transaksi, dan 18 atribut. Dataset zoo merupakan dataset yang berisi data tentang hewan. Berikut adalah proses penambangan data pada dataset zoo menggunakan algoritma APIC:
A. Transaction Clustering 1. Seed Generation Phase
Hasil dari setiap langkah dalam tahap seed generation phase adalah: a. Cari 1-large itemsets dengan nilai minimum support threshold
( ) = 0.04950495. Sebagai contoh item TRUE, memiliki jumlah dalam transaksi sebanyak 43 transaksi sehingga memiliki support sebesar 0.425742574 yang berasal dari Supp(TRUE) = freq(TRUE) / Jumlah transaksi yaitu 101, maka hasilnya adalah 0.425742574 dan item TRUE masuk menjadi anggota 1-Large itemset. Semua itemset yang memiliki nilai support <= 0.04950495 dihapus dari kandidat Frequent 1-Itemsets. Dengan demikian didapat anggota Frequent 1-Itemsets seperti dibawah ini:
Frequent 1-Itemsets:
30. Support: 0.7425742574257426 {true(Tail)}, 31. Support: 0.8712871287128713 {false(Domestic)}, 32. Support: 0.12871287128712872 {true(Domestic)}, 33. Support: 0.43564356435643564 {true(Catsize)}, 34. Support: 0.5643564356435643 {false(Catsize)}, 35. Support: 0.40594059405940597 {mammal(Type)}, 36. Support: 0.12871287128712872 {fish(Type)}, 37. Support: 0.19801980198019803 {bird(Type)},
38. Support: 0.09900990099009901 {invertebrate(Type)}, 39. Support: 0.07920792079207921 {insect(Type)}. Frequent 1-Itemsets ini akan dianggap sebagai seed cluster 1. b. Cari k-large itemset dimana nilai k = 2, 3, 4,..,k dan nilai user
relative support dari itemset {TRUE,FALSE(T)}, maka relative support nya dihitung sebagi berikut:
RS(TRUE,FALSE(T)) =
Support(TRUE,FALSE(T))/support(TRUE), karena TRUE adalah subset dari itemset gabungan {TRUE,FALSE(T)} yang memiliki nilai support paling besar. Setelah nilai dari relative support ditetapkan cek nilai relative support apakah lebih dari user define support threshold atau tidak dengan cara mengurangkan nilai dari relative support himpunan item gabungan dengan nilai relative support dari subset nya, hasil pengurangan ini harus lebih besar dari nilai support threshold yang dimasukan. Sebagai contoh pembandingan relative support dengan user define support threshold adalah sebagai berikut:
Uji Chi square FALSE(E)
FALSE(E) Not FALSE(E) total
TRUE 38 5 43
NOT TRUE 4 54 58
total 42 59 101
X² 67.47937164
status Chi Yes Cut off 3.84
Hitung berapa kali itemset {TRUE, FALSE(E)} muncul, berapa kali masing – masing subset dari itemset gabungan muncul dalam transaksi. Setelah itu lakukab perhitungan dengan rumus dibawah ini:
, dari rumus ini maka dapat dihitung X² = ((38-43*42/101)²/(43*42/101)) + ((5-43*59/101)²/(43*59/101)) + ((4-58*42/101)²/(58*42/101)) + ((54-58*59/101)²/(58*59/101)) = 67.47937164.
setelah mengalami proses perhitungan dan penerapan batasan dalam setiap gabungan itemset.
Frequent 2-Itemsets:
1. Support: 0.8837209302325582{true(Hair), false(Eggs)} 2. Support: 0.9069767441860466{true(Hair), true(Milk)} 3. Support: 0.7209302325581396{true(Hair), 4(Legs)} 4. Support: 0.6818181818181818{true(Hair), true(Catsize)} 5. Support: 0.9069767441860466{true(Hair), mammal(Type)} 6. Support: 0.9152542372881357{false(Hair), true(Eggs)} 7. Support: 0.9333333333333335{false(Hair), false(Milk)}, 8. Support: 0.7586206896551725{false(Hair), false(Catsize)} 9. Support: 0.6666666666666667{true(Feathers),
true(Airborne)}
10. Support: 0.5{true(Feathers), false(Toothed)}
11. Support: 0.7407407407407407{true(Feathers), 2(Legs)} 12. Support: 1.0{true(Feathers), bird(Type)}
13. Support: 0.9523809523809524{false(Eggs), true(Milk)} 14. Support: 0.7142857142857143{false(Eggs), 4(Legs)} 15. Support: 0.7045454545454546{false(Eggs), true(Catsize)} 16. Support: 0.9523809523809524{false(Eggs),
mammal(Type)}
19. Support: 0.7560975609756097{true(Milk), 4(Legs)} 20. Support: 0.7272727272727273{true(Milk), true(Catsize)} 21. Support: 1.0{true(Milk), mammal(Type)}
22. Support: 0.8{false(Milk), false(Catsize)} 23. Support: 0.5499999999999999{true(Airborne), false(Toothed)}
24. Support: 0.6666666666666666{true(Airborne), 2(Legs)} 25. Support: 0.6666666666666667{true(Airborne), bird(Type)} 26. Support: 0.5555555555555556{true(Aquatic),
false(Breathes)}
27. Support: 0.47222222222222227{true(Aquatic), true(Fins)} 28. Support: 0.5{true(Aquatic), 0(Legs)}
29. Support: 0.5{false(Toothed), 2(Legs)} 30. Support: 0.5{false(Toothed), bird(Type)}
31. Support: 0.33333333333333337{false(Backbone), false(Breathes)}
32. Support: 0.5555555555555556{false(Backbone), 6(Legs)} 33. Support: 0.6538461538461539{false(Backbone),
false(Tail)}
34. Support: 0.5555555555555556{false(Backbone), invertebrate(Type)}
36. Support: 0.6190476190476191{false(Breathes), true(Fins)} 37. Support: 0.6956521739130435{false(Breathes), 0(Legs)} 38. Support: 0.6190476190476191{false(Breathes),
fish(Type)}
39. Support: 0.33333333333333337{false(Breathes), invertebrate(Type)}
40. Support: 0.6956521739130435{true(Fins), 0(Legs)} 41. Support: 0.7647058823529411{true(Fins), fish(Type)} 42. Support: 0.5909090909090909{4(Legs), true(Catsize)} 43. Support: 0.7560975609756097{4(Legs), mammal(Type)} 44. Support: 0.5652173913043478{0(Legs), fish(Type)} 45. Support: 0.7407407407407407{2(Legs), bird(Type)} 46. Support: 0.38461538461538464{6(Legs), false(Tail)} 47. Support: 0.7999999999999999{6(Legs), insect(Type)} 48. Support: 0.7272727272727273{true(Catsize),
mammal(Type)}
Frequent 2-Itemsets ini akan dianggap sebagai seed cluster 2. c. Pada 3-large itemset, proses penerapan batasan dan
perhitungannya sama dengan perhitungan dan penerapan batasan pada Frequent 2-Itemsets. Berikut adalah hasil dari Frequent 3-Itemsets:
2. Support: 1.0{true(Feathers), false(Toothed), 2(Legs)} 3. Support: 0.888888888888889{true(Airborne), 2(Legs), bird(Type)}
4. Support: 0.7499999999999999{true(Aquatic), false(Breathes), 0(Legs)}
5. Support: 0.888888888888889{true(Aquatic), true(Fins), 0(Legs)}
6. Support: 1.0{false(Toothed), 2(Legs), bird(Type)} 7. Support: 0.7000000000000001{false(Backbone), false(Breathes), invertebrate(Type)}
8. Support: 0.7999999999999999{false(Backbone), 6(Legs), insect(Type)}
akan menjadi centroid dalam setiap klaster. Banyaknya klaster tergantung pada banyaknya anggota dari large itemset terakhir, pada contoh ini terletak pada jumlah anggota dari 3-large itemset yaitu 11 klaster.
2. Allocation Phase
Tahap berikutnya adalah tahap allocation phase, yaitu tahap melakukan alokasi transaksi dalam dataset kedalam klaster. Berikut adalah contoh penerapan langkah tahap allocation phase kedalam dataset zoo.
a. Lakukan alokasi transaksi kedalam setiap klaster yang tersedia, tahap ini dilakukan dengan menghitung nilai similarity antara transaksi dalam dataset dengan centroid dari klaster. Perhitungan similarity menggunakan persamaan pada langkah 1 tahap allocation phase.
Berikut adalah contoh perhitungan similarity antara transaksi ke 12 dalam dataset dengan centroid {True(F), TRUE(A), FALSE(T)}.
antara transaksi dan centroid) / ( jumlah gabungan itemset anatara transaksi dan centroid – jumlah itemset yang sama antara transaksi dan centroid + 1).
Maka similarity = (3)/(18-3+1) = 0.1875. Perhitungan similarity dilakukan terhadap semua transaksi terhadap semua centroid dari klaster, transaksi akan dialokasikan terhadap semua klaster yang memberikan nilai similarity tertinggi dibandingkan klaster lainnya. Berikut adalah hasil dari alokasi transaksi pada putaran pertama.
Anggota klaster 2
Anggota klaster 4
Anggota klaster 6
Anggota klaster 7
Anggota klaster 9
Anggota klaster 11
b. Hitung nilai optimum klaster menggunakan fitness function yang terdapat pada langkah 2 dalam tahap allocation phase. Dari 11 klaster yang terbentuk, dihitung nilai optimum klasternya dengan persamaan pada (2.11). nilai optimum klaster awal dinisialisasi dengan nilai 0. Berikut adalah contoh perhitungan nilai optimum dari klaster pada putaran ini:
J = (1/jumlah klaster) * ( jumlah rata - rata dari nilai similarity antara transaksi dengan centroid klaster dari setiap klaster yang ada), maka J = (1/11) * ((0.1722222222222222) + (0.15576923076923072) + (0.15555555555555556) + (0.13967391304347826) + (0.14044444444444443) + (0.15576923076923072) + (0.16458333333333336) + (0.1875)
+ (0.16916666666666666) + (0.1875) +
0.15576923076923072, 0.15555555555555556, 0.13967391304347826, 0.14044444444444443, 0.15576923076923072, 0.16458333333333336, 0.1875, 0.16916666666666666, 0.1875, 0.16916666666666666 adalah nilai rata - rata similarity dari setiap klaster.
c. Bandingkan nilai optimum klaster yang terbentuk dengan nilai optimum klaster sebelumnya. Dari putaran pertama ini didapat bahwa nilai optimum awal dibandingkan nilai optimum sekarang adalah lebih kecil sehingga perlu dilakukan perombakan centroid dari setiap klaster pada iterasi berikutnya, dengan cara mengganti centroid klaster dengan large itemset yang dimiliki oleh transaksi pada setiap klaster. Perhitungan large itemset dari setiap klaster memiliki proses yang sama dengan awal tahap inisial 1-large itemset pada tahap seed generation phase yang membedakan adalah |D|, nilai |D| dalam langkah ini adalah banyaknya transaksi yang terdapat dalam klaster yang akan diperbaharui centroid nya bukan jumlah transaksi dalam dataset.
d. Pada setiap iterasinya, hapus klaster yang tidak memiliki anggota
f. Setelah proses transaction clustering selesai dengan terpenuhinya syarat dalam langkah c yaitu nilai optimum sekarang <= nilai optimum awal, maka klaster yang terbentuk pada putaran terakhir inilah yang akan digunakan sebagai klaster yang akan di tambang datanya sehingga dapat menghasilkan aturan asosiasi langka.
B. Apriori Inverse
Klaster 1
Klaster 3
Klaster 4
Klaster 6
Klaster 7
Klaster 8
Berikut adalah contoh penerapan apriori inverse kedalam datasetzoo yang telah mengalami proses transaction clustering:
Untuk setiap klaster, lakukan langkah dibawah ini: