Extraction of Predicate-Argument Structures
From Sentence Based of PICO Frames
Wiwin Suwarningsih
a,b, Iping Supriana
a, Ayu Purwarianti
a aSchool of Electrical Engineering and Informatics, Institut Teknologi Bandung, Jl. Ganesa 10 Bandung, Indonesia
b
Research Center for Informatics, Indonesian Institute of Science, Jl. Cisitu 21 Bandung, Indones [email protected]
Abstract—Identifying a logical relation between sentences and semantic role labelling requires a deeper knowledge of recognizing the relationship of various expressions. One method that can be used is by means of the extraction of predicate argument structure. This paper is purposely to describe a new automatic method for the extraction of Indonesian medical predicate-argument (P-A) structure analysis based upon PICO frame. Learning some relevant features, the method assigns some case roles (such as Problem/Population/Patient, Intervention, Compare/Control and Outcome) to the argument of the target predicate using the features of the words that are located closest to the target predicate. In this paper the illustration of their use in a pattern-based relation extraction component of PICO frame has been described. It is indicated from the test results that the use of the features with more semantic role categories in determining the P-A structure represents the respective results reaching at 89.35% for precision, 89.12% for recall and 89.98% for F1.
Keywords—PICO frame; predicate-argument structure; Indonesian medical text; semantic role category.
I. INTRODUCTION
Defining semantic role labeling in a natural language processing requires a deeper knowledge regarding the relations between logic statement and various expressions such as noun, verb, adjective, or some expression modalities. In the medical domain, for example, a question generation system requires the development of natural language processing technology in automatically detecting some logical relations such as similarity and contradiction between the statements. An approach that can be used to identify some logical relations between statements and semantic roles labeling is the extraction of predicate-argument structure. The analysis on predicate-argument structure consists of a number of recognizing arguments involved by predicates and labeling their semantic roles, such as Agent, Patient, or Theme [1]. Previously some researches have been conducted on this analysis on a variety of languages, such as English [2] [3]. In Japanese [4] included the database of logical relations between predicate-argument structures (PASs) to recognize the relations between statements. In Chinese, Lou et al. [1] divided PA structure analysis into three subtasks: predicate sense disambiguation, argument classification and argument identification.
We from these studies have obtained several things that can be further explored and improved to the extraction of predicate-argument structure from Indonesian medical sentences. In recognizing the logical relations between statements and semantic roles labeling, PICO frame was used. This paper has been designed to learn some relevant features to assign a number of case roles (such as Problem/Population, Intervention, Compare/Control and Outcome) to the argument of the target predicate using the words features located closest to the target predicate under various constraints as research conducted by Cali anda Joty[16]. Here, our extraction P-A structure system is called PASIm. Expectedly, the results of learning the P-A structure enable to determine which role will serve as a predicate and other role as an argument that later can be used for pattern generation question. For experiment we used a test coming from three popular health websites in Indonesia health.kompas.com/konsultasi ; http://health.detik. com/; www.tabloidnova.com/nova/kesehatan/konsultasi-kesehatan). These three websites have been chosen for providing a means to debriefing health counseling and possessing a variety of sentences that support the system which we will build.
Overall, this paper is aimed to provide following contributions:
1) A new method for the extraction of Indonesian medical predicate-argument (P-A) structure based on PICO frame. 2) Identification some relevant features to assign some case
roles for Indonesian medical sentences.
3) As an application the respective results reaching 89.35% for precision, 89.12% for recall and 89.98% for F1.
The rest of the paper is organized as follows: Section 2 describes some related work on predicate-argument structure analysis, followed by Section 3 presenting the details of the proposed method. Furthermore, Section 4 shows the evaluation and results and Section 5 describes the experiment. Finally, the conclusion and future directions are presented in Section 6.
II. RELATED WORK
Over the past decade, most of works in the field of predicate-argument structure analysis shifted from
broad-2015 International Conference on Automation, Cognitive Science, Optics, Micro Electro-Mechanical System, and Information Technology (ICACOMIT), Bandung, Indonesia, October 29–30, 2015
coverage corpora annotated with semantic role, argument structure, or information are available.
Research on the dual decomposition method can be found as in Rush et al. [4] [5], Lou et al. [1], and Samuelsson [7]. The application of dual decomposition is to combine the argument identification task and argument classification task. Rush et al. [4] [5] used such application to combine two independent models that were considerably different. Both models in our method are nearly equal. In contrast to research conducted by Lou et al. [1], PA structure has been divided into three sub-tasks: predicate sense disambiguation, arguments classification and identification arguments. They used a double decomposition method to combine two subtasks aimed to alleviate an error propagation to make a decision on two subtasks as consistent as possible. Meanwhile, Samuelsson [7] found that the most difficult problem in predicate-argument analysis is to find the arguments of a predicate. The dual decomposition method leverages the observation in which several complex inference problems can often be decomposed into efficiently solvable sub-problems.
Another research was more focused on the relations between predicate-argument structures on database as conducted by Matsuyoshi et al. [4] presenting a database of logical relations between predicate-argument structures (PASs) in Japanese language to recognize relations between statements. Inue et al. [8] have proposed some methods in collecting knowledge about logical relations between predicates from large corpus. The automatic knowledge acquisition from text here specifically is in the acquisition of causal relations. Abe et al. [9] proposed a two-phase approach, which first used some lexicon syntactic patterns to acquire predicate pairs before using two types of anchors to identify shared arguments.
Another related work is the research to information extraction using predicate-argument structures such as Surdeanu [10], Gildea and Palmer [11], Yangarber et al. [12] and Yoshino et al. [13]. Surdeanu [10] customized an information extraction paradigm taking the advantage of predicate-argument structures and introduced a new direction of automatically identifying predicate-argument structures. Some label predicate-argument has been generated by Gildea and Palmer [11] in which, the results of this labeling were then used on the system parser to extract information. The test results showed a very significant proposed method with a good performance. It is unequal with the case with Yoshino et al. [13] that defined the PA in the form of templates. PA templates have been built on a statistical measure to generate the target documents utilizing several existing documents for navigation information. The method proposed by Yoshino et al, outperformed some conventional methods in the performance of ASR, and the selection of a sentence based on a template PA found to be effective. Similarly, a research conducted by Yangarber et al. [12] showed, the performance of the PA structure and the design of the methods of automatically acquiring IE patterns for matching the patterns of against documents to identity and extract domain-relevant information with a rich literature.
III. PROPOSED METHOD
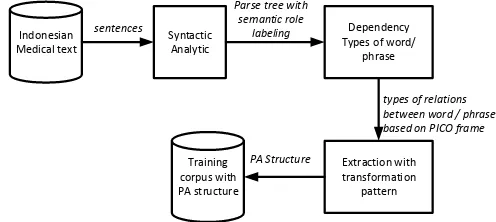
PASIm was originally designed to only cope with a relevant input for Indonesian medical sentences. In this section, we proposed a method to improve its ability to handle noisy input seeds. Figg.1. depicts the overall flow of the proposed method. First, the sentences of the Indonesian medical were parsed by shallow parser to syntactic analysis for the result of parse tree with the semantic role labeling of phrase. In the second step, a number of dependency types between words or phrase were generated. Here, it was focused on dependencies to verbs. The domain dependent word or phrase at the third step was trained for the extraction of the P-A structure analysis using a transformation pattern. The resultant training corpus was expected to provide a necessary and sufficient lexicon and expressions for Indonesian Medical question generation. between word / phrase based on PICO frame
Fig. 1. Overview of PASIm proposed method
IV. EVALUATION AND RESULTS
Information on verb in lexicons is essential in consideration to a fundamental role of verb in Natural Language Processing[10]. As a predicate, a verb identifies a relation between entities denoted by the subject and complements. In this paper, we addressed some of these questions, and offered a few of practical solutions within the context of an implemented system of knowledge acquisition from medical sentences.
A. Syntactic Analysis
Some of the most succesful argument predicate analysis techniques are built around a set of domain relevant linguistic patterns based on the selected verbs for predicate. The output from syntactic analysis consists of a single parse tree in which, the best analysis is in accordance with its surface-based heuristics. It was assumed that the system to select only one parse tree and only one semantic analysis for each input string analyzed.
appear in medical sentence as predicate-argument structures in which each of case is denoted by a syntactic marker and occupied by particular filler. Case-based analysis is appropriate because it goes well with syntax-centered approaches, and can be presented intuitively to the user.
B. Dependency Types
Dependency graph between words or phrase in this paper is illustrated as e1 and e2 representing two entities in the same
sentence in relation R, thus notated into R(e1, e2). For
example, R can be determined that the entity e1 is located
(AT) entity e2. Fig. 2 shows two simple sentences with an
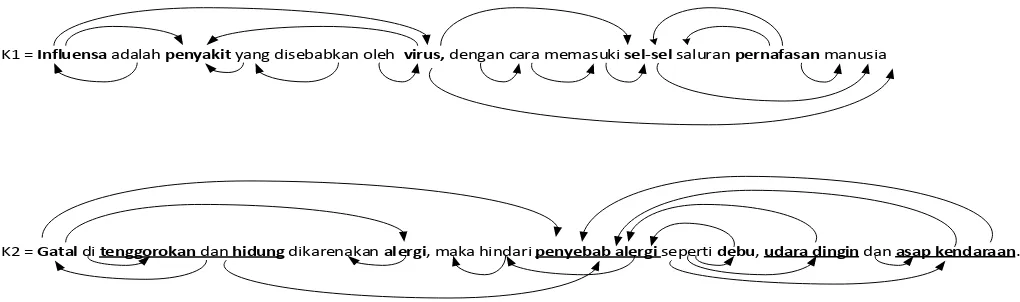
entity that a keyword is printed guess while key phrases are in bold and underlined. (Where K1 is Influensa adalah penyakit yang disebabkan oleh virus, dengan cara memasuki sel-sel saluran pernafasan manusia, In English: Influenza is a disease caused by a virus, by entering the cells of the human respiratory tract; while K2 is gatal di tenggorokan dan hidung dikarenakan alergi, maka hindari penyebab alergi seperti debu, udara dingin dan asap kendaraan, In English: itching in the throat and nose due to allergies, avoid allergens such as dust, cold air and fumes).
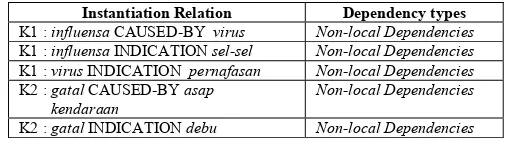
The dependency graph is assumed that a relation between words will be extracted only between entities in the same sentence. This means that the information is obtained only from the same sentence including two entities that have relevance to do a relation extraction process. Each sentence can be attributed graph dependence in which the word or phrase is described as nodes and dependencies between words or phrases as illustrated by the arrow, as shown in Fig. 2. These searches can be categorized based on instantiation relation, for example "Symptoms" using the relation "CAUSED BY” and "Problem" using the relation "INDICATION".
In this paper, the dependence of words or phrases has been categorized into two types [15]:
• Local Dependencies: the form of dependence between the keywords or key phrases instead of key words adjacent position. Examples of the K1 sentence: “memasukiÆsel-sel”, or “pernafasanÆsaluran”. • Non-local Dependencies: that form of long-range
dependence arising from various linguistic constructions. As an example of the K1 is ”gatalÆalergi”, or at K2
”influenzaÆvirus”.
TABLE I. REPRESENTATION RELATION BETWEEN WORDS
Instantiation Relation Dependency types
K1 : influensa CAUSED-BY virus Non-local Dependencies K1 : influensa INDICATION sel-sel Non-local Dependencies K1 : virus INDICATION pernafasan Non-local Dependencies K2 : gatal CAUSED-BY asap
kendaraan
Non-local Dependencies
K2 : gatal INDICATION debu Non-local Dependencies
Once the type of dependency phrases or words have been determined, phrases could then be in the transformation based on several semantic roles using PICO frames. This was
purposely to classify phrase or word in the frame PICO to facilitate the learning process of transformation.
C. Extration Sentence with Transformation Pattern
A number of simple transformation rules were applied to each unit to extraction Indonesian medical sentences. The other problem was related to the presence of many redundant phrases in documents, which would not be used for queries. We focused on phrases dependent upon the verbs to extraction natural sentences. Dependency graph that has been built could be used as a basis for learning transformation to determine the transformation rule predicate-argument structure. In fact, it is only a fraction of the patterns that is useful, and it is domain dependent. For example, key patterns include “([COMPARE] prevent [PROBLEM])”, “(Enhancement [COMPARE] prevent [PROBLEM])” and “([PROBLEM] Overcome-by improvement [COMPARE])”. The transformation rules as shown in Table II are applied according to the predicate type. When multiple rules are applicable, all of them are used to generate a variety of sentences [9].
In the previous study, the extraction method based on Naive Bayes classifier was shown to be effective [13] [14]. In this method [15] C (wi) was a count of word wi, and C(wi,t)
referres to a count of word wiin domain t. was a smoothing
factor[18] and Dtwas a normalization coefficient of the corpus
size of the domain t. The probability of Indonesian medical domain t given word wi is defined as,
(1)
The method of Naive Bayes was used in the extraction of the PA with the medical domain Indonesian language to classify some phrases or words into the frame PICO. To solve the problem of statistical method often encounters the problem of data sparseness due to mismatching. We conducted clustering to semantic role labeling based PICO frame appeared in the training set. The results of the calculation of probabilities by using K1 sentence in the previous section showed possibility to use Naive Bayes for the Indonesian medical domain (calculation results can be seen in Fig. 3).
K1 = Influensa adalah penyakit yang disebabkan oleh virus, dengan cara memasuki sel-sel saluran pernafasan manusia
K2 = Gatal di tenggorokan dan hidung dikarenakan alergi, maka hindari penyebab alergi seperti debu, udara dingin dan asap kendaraan.
Fig. 2. Dependency graph of words in an Indonesian medical sentence
Fig. 3. Example sentence with PA structure and scoring
V. EXPERIMENT
A. Experiment Data
Sentences that we used for the test came from three popular health websites in Indonesia of 200 sentences tagged with the Indonesian medical, we randomly split the data into 60% for training data and 40% for testing. Sentences used to have the variation of active sentences, passive sentences, and complex sentences. This was performed to observe the combination of any use of the word to be classified based on PICO frames.
B. Experiment Evaluation
A test strategy used was attempted to vary sentences predicate-argument structure with base frame PICO (see TABLE II). The variation of the sentences tested here consisted of active sentences, passive sentences and complex sentences. This test was performed to determine how many classifications based on semantic roles based PICO frames were to facilitate the learning process and analysis in determining the PA structure. From the test results, it was shown that the highest values were found in complex
sentences reaching at 89.11% for precision, 89.45% for recall and 90.12% for F1. These results then indicate that the compound sentence has a more varied classification of semantic roles.
Following the successful classification process, the testing was continued to extract a predicate-argument structure to achieve the relevance of features consisting of dependency types, categories and POS semantic roles. As a result of parsing, 1050 predicates were extracted from Indonesian medical sentences (723 words included into the category of [INTERVENTION] and 327 event-noun). The results based on the performance features can be seen in TABLE III.
TABLE II. PERFORMANCE BASED ON VARIATION SENTENCES
Feature based Measure (%)
Precision Recall F1
Active sentence 86,10 88,24 89,67
Passive Sentence 88,14 89,12 89,88
Complex Sentences 89,11 89,45 90,12
TABLE III. PERFORMANCE BASED ON FEATURES
Feature based Measure (%)
Precision Recall F1
Dependency type 88,11 88,24 89,67
Semantic role category 89,35 89,12 89,98
Part of speech 89,11 88,05 89.12
Test results showed that using the features with a more semantic role category in determining the structure PA was able to represent the respective results at 89.35% for precision, 89.12% for recall and 89.98% for F1.
VI. CONCLUSION
We proposed an PICO frame annotation where the semantic roles of arguments were represented through a semantic structure decomposed by several primitive predicates. Our experimental results have shown a significant improvement in the accuracy of predicate-argument extraction
K1 = Influensa adalah penyakit yang disebabkan oleh virus, dengan cara memasuki sel-sel saluran pernafasan manusia
PA-Structure = [“[POPULATION]/subject/adalah penyakit”, “[PROBLEM]/object/adalah penyakit”, “[ORGAN]/subject /memasuki”,
“[PATIENT]/object/memasuki”]
Based on the structure of the PA, it can be determined the value of the word as an argument and predicate.
Score Argument case Predicate
after exploiting dependency type and semantic role interdependence. The results for semantic role category for precision was at 89.35%, recall at 89.12% and F1 at 89.98%.
In future work we will address an incremental procedure to accelerate a rule extraction. The experiments will use transformation based learning and extracted rules that indicate the tendencies annotators have.
ACKNOWLEDGMENT
We would like to thank the anonymous reviewers for their helpful comments.
REFERENCES
[1] Luo,Y., Asahara, M.., Matsumoto, Y., “Dual decomposition method for chinese predicate-argument structure analysis”, in Proceeding of Natural Language Processing and Knowledge Engineering (NLP-KE), pp. 409-414. 2011.
[2] Ruppenhofer, J., Ellsworth, M., Petruck, M. R. L., Johnson, C. R., and Scheffczyk, J., “FrameNet II: Extended theory and practice”, http://framenet.icsi.berkeley.edu/. 2006.
[3] Chklovski, T., and Pantel, P., “VerbOcean: Mining the web for fine-grained semantic verb relations”. In Proceedings of Conference on Empirical Methods in Natural Language Processing (EMNLP-04), pp.33–40. 2004
[4] Matsuyoshi, S., Murakami, K., Matsumoto, Y., Inui, K., “A Database of Relations between Predicate-argument Structures for Recognizing Textual Entailment and Contradiction”, Second International Symposium on Universal Communication, IEEE computer society, 31, pp. 366-373. 2008
[5] Alexander, M. C., Rush, M., Sontag, D., and Jaakkola, T., “On dual decomposition and linear programming relaxations for natural language processing,” in Proc. of the 2010 Conference on Empirical Methods in Natural Language Processing (EMNLP’2010), Cambridge, Massachusetts, pp. 1–11. 2010.
[6] Koo,T., Rush, A.M., Jaakkola, T., and Sontag, D. “Dual decomposition for parsing with non-projective head automata,” in Proc. of the 2010
Conference on Empirical Methods in Natural Language Processing(EMNLP’2010), pp. 1288–1298. 2010.
[7] Samuelsson, Y., Täckström, O., Velupillai, S., Eklund, J., Filell, M., and Saers, M., “Mixing and blending syntactic and semantic dependencies,” in Proc. CoNLL-2008, pp. 248–252. 2008.
[8] Inui, T., Inui, K., and Matsumoto, Y., “Acquiring causal knowledge from text using the connective marker tame”. ACM Transactions on Asian Language Information Processing (TALIP), 4(4), pp. 435–474. 2005.
[9] Abe, S., Inui, K., and Matsumoto, Y., “Two-phased event relation acquisition: coupling the relation-oriented and argument-oriented approaches”. In Proceedings of the 22nd International Conference on Computational Linguistics (COLING2008), pp. 1–8. 2008.
[10] Surdeanu, M., Harabagiu, S., Williams, J., and Aarseth, P., “Using Predicate-Argument Structures for Information Extraction”, In Proceedings of ACL 2003, pp. 345-352. 2003.
[11] Gildea, D., and Palmer, M., “The Necessity of Parsing for Predicate-argument Recognition”. In Proceedings of the 40th Meeting of the Association for Computational Linguistics (ACL 2002), pp. 239-246. 2002.
[12] Yangarber, R., Grishman, R., Tapainen. P., and Huttunen, S., “Automatic Acquisition of Domain Knowledge for Information Extraction”. In Proceedings of the 18th International Conference on Computational Linguistics (COLING-2000), pp: 940-946. 2000. [13] Yoshino, K., Mori, S., and Kawahara, T., “Language Modeling for
Spoken Dialogue System based on Sentence Transformation and Filtering using Predicate-Argument Structures”, In Proceedings of IEEE Conference on Signal & Information Processing Association Annual Summit and Conference (APSIPA ASC), pp: 1–4. 2012. [14] Istvan, V., Otake, K., Torisawa, K., Saeger, S., Misu, T., Matsuda, S.,
and Kazama, J., “Similarity based language model construction for voice activated open-domain question answering”. In Proceedings of IJCNLP. 2011.
[15] Bunescu, R.C., and Mooney, R.J., “A Shortest Path Dependency Kernel for Relation Extraction”, In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, pp: 724-732. 2005