Fakultas Ilmu Komputer
Universitas Brawijaya
3648
Penerapan Algoritme
Support Vector Machine
(SVM) Pada
Pengklasifikasian Penyakit Kucing
Jumerlyanti Mase1, Muhammad Tanzil Furqon2, Bayu Rahayudi3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Kucing merupakan hewan peliharaan yang sering ditemukan di masyarakat. Pemeliharaan kucing memerlukan perhatian yang besar agar kucing tidak terserang penyakit yang dapat membahayakan kucing, pemiliknya ataupun orang yang melakukan interaksi langsung dengan kucing tersebut. Penyakit pada kucing biasanya disebabkan oleh virus, bakteri atau jamur. Kemiripan gejala yang muncul pada penyakit kucing membuat masyarakat umum sulit mendeteksi penyakit yang menyerang kucing tersebut. Sehingga dibutuhkan sistem yang dapat membantu pengklasifikasian terhadap gejala penyakit yang timbul pada kucing untuk mendiagnosis penyakitnya dengan tepat. Sistem yang digunakan untuk pengklasifikasian penyakit kucing ini mengunakan algoritme Support Vector Machine (SVM) dengan menerapkan strategi One-Against-All untuk permasalahan multi class. Penelitian ini menggunakan 220 data dengan 9 hasil klasifikasi yaitu Scabies, Gastritis, Helminthiasis, Rhinitis, Dermatitis, Dermaphytosis, Otitis, Enteritis dan kucing sehat. Hasil akurasi yang dihasilkan oleh sistem ini dengan menggunakan perbandingan rasio data 90%: 10% dan kernel RBF adalah 80,2%. Dengan hasil akurasi yang baik, maka penelitian ini dapat diterapkan untuk membantu melakukan pengklasifikasian penyakit kucing dengan menggunakan algoritme Support Vector Machine (SVM).
Kata kunci: One-Against-All, Penyakit Kucing, SVM
Abstract
Cats are usual pets in the community. Taking care of cat needs a great attention to avoid it from disease that will endanger the cat itself, its owner or the person who interact directly with it. Cat diseases are usually caused by viruses, bacteria, or fungal. Cat diseases that have similar symptoms can make it difficult for common people to diagnose the disease. So we need a system that capable to classify the symptoms of cat diseases in order to diagnose the disease properly. This cat diseases classification system used the Support Vector Machine (SVM) algorithm by applying the One-Against-All strategy for multi-class problems. This research used 220 data which is divided into 9 classification (Scabies, Gastritis, helminthiasis, rhinitis, dermatitis, Dermaphytosis, otitis, enteritis and healthy cat). The accuracy result obtained by thi systems (data rate ratio of 90%: 10% and using RBF kernel) are 80,2%. With good accuracy results, this research can be applied to help cat diseases classification by using the Support Vector Machine (SVM) algorithm.
Keywords: Cats Disease, One-Against-All, SVM
1. PENDAHULUAN
Kucing merupakan golongan famili
Felidae, yaitu golongan kucing domestik dan kucing liar (Slattery & O’Brien, 1998) dan salah satu hewan peliharaan yang sering dipelihara oleh kebanyakan orang. Sekitar 600 juta rumah yang ada di dunia memiliki hewan peliharaan yaitu kucing (Rahman, 2008). Berdasarkan penelitian yang pernah dilakukan di University
dini untuk mencegah penyakit kucing agar tidak semakin parah. Tetapi pengetahuan dari pemilik kucing atau masyarakat umum tentang penyakit pada kucing yang terbatas membuat penanganan secara dini sulit dilakukan. Maka diperlukan
adanya sebuah sistem yang mampu
mengklasifikasikan penyakit kucing
berdasarkan dari gejala yang muncul. Dengan adanya sistem cerdas untuk mendiagnosis penyakit kucing ini nantinya diharapkan bisa membantu dalam mendiagnosis penyakit kucing dengan cepat dan tepat.
Salah satu metode untuk melakukan klasifikasi adalah Support Vector Machine
(SVM). Metode SVM pada dasarnya digunakan untuk mengklasifikasikan data yang linier, namun telah dikembangkan untuk digunakan dalam bentuk data yang non-linier dengan menarapkan kernel trick. Metode ini memiliki kelebihan, salah satunya adalah menggunakan
support vector untuk menentukan jarak agar komputasi yang didapatkan lebih cepat (Octaviani, et al., 2014). Berdasarkan dari permasalahan yang ada dan penelitian yang telah dijelaskan diatas, maka penulis ingin melakukan penelitian dengan objek penyakit kucing yang akan diklasifikasikan menggunakan algoritme
Support Vector Machine. Sehingga dari penelitian yang dilakukan dapat menghasilkan sebuah sistem yang mampu mendiagnosis penyakit kucing dengan menggunakan algoritme
Support Vector Machine berdasarkan dari gejala-gejala penyakit yang muncul pada kucing.
2. PENYAKIT KUCING
Kucing merupakan hewan mamalia karnivora yang diketahui berasal dari keturunan Felidae yang sering disebut dengan kucing rumah yang dalam bahasa ilmiah dikenal dengan
Felis Silvestris Catus atau Felis Catus (Anonim, 2016). Dalam penelitian ini, sistem hanya dapat melakukan pengklasifikasian terhadap 8 penyakit kucing. Berikut penyakit kucing yang dapat di klasifikasi dalam sistem ini: Scabies, Gastritis, Helminthiasis, Rhinitis, Dermatitis, Dermaphytosis, Otitis dan Enteritis.
3. SUPPORT VECTOR MACHINE (SVM)
Support Vector Machine merupakan sebuah algoritme yang dapat digunakan untuk
menyelesaikan permasalahan untuk
pengklasifikasian (Pratama, et al., 2017). Metode dari SVM biasanya digunakan untuk melakukan klasifikasi dengan masalah yang
linier, namun dalam perkembangannya metode SVM dapat digunakan untuk permasalahan yang non-linier dengan cara mencari hyperplane yang digunakan untuk jarak yang maksimal antar kelas data (Octaviani, et al., 2014). Permasalah yang ada dalam penelitian ini menggunakan data yang non-linier.
3.1. SVM Non-Linier
Permasalah dalam pengklasifikasian untuk data yang non-linier diselesaikan dengan fungsi
kernel (Pratama, et al., 2017). Fungsi kernel
dalam metode ini sering disebut dengan kernel trick. Kernel trick adalah fungsi yang mengelompokkan data dari dimensi rendah ke dimensi tinggi (Prasetyo, 2012). Ada beberapa pilihan fungsi kernel yang dipakai pada sebuah aplikasi untuk mengatasi masalah metode SVM non-linier yang akan ditunjukan dalam Tabel 1:
Tabel 1 Fungsi Kernel
Penggunaan fungsi kernel merupakan cara untuk mendapatkan hasil dari klasifikasi terbaik. Dalam penelitian pengklasifikasian penyakit pada kucing ini fungsi kernel yang dipakai adalah kernel RBF. Kernel RBF adalah sebuah
kernel yang memiliki performa yang baik dengan parameter tertentu yang hasil dari pelatihannya tidak menghasilkan kesalahan yang besar (Sangeetha & Kalpana, 2011).
3.2. Sequential Training SVM
Sequential Training SVM adalah salah satu algoritme yang digunakan untuk melakukan proses training. Selain algoritme Sequential Training dalam metode SVM, terdapat algoritme lain seperti proses Quadratic Programming juga proses Sequential Minimal Optimization (SMO). Untuk algoritme Sequential Training sendiri mempunyai kelebihan dari algoritme yang lain yaitu konsep dari Sequential Training mudah dimengerti dan dapat meminimalkan waktu. Algoritme yang ada pada Sequential Training
SVM akan ditunjukan dalam langkah-langkah berikut (Vijayakumar & Wu, 1999):
2. Melakukan proses perhitungan nilai matriks
hessian dengan rumus:
𝐷𝑖𝑗 = 𝑦𝑖𝑦𝑗(𝐾(𝑥𝑖𝑥𝑗) + 𝜆2 (1)
Keterangan :
𝑥𝑖 = Data yang ke-i 𝑥𝑗 = Data yang ke-j
𝑦𝑖 = Kelas yang ada pada data ke-i 𝑦𝑗 = Kelas yang ada pada data ke-j 𝑛 = Jumlah data
𝐾(𝑥𝑖, 𝑥𝑗)= Hasil dari nilai kernel
3. Mengulangi tahap ketiga sampai nilai iterasi memenuhi batas iterasi yang maksimum atau mencapai pada nilai max
(|δα_i |)< ε (epsilon).
𝜠𝒊= ∑𝟏𝒋=𝟏𝛂𝒊𝑫𝒊𝒋 (2)
𝜹𝜶𝒊= 𝐦𝐢𝐧{𝐦𝐚𝐱[𝜸(𝟏 − 𝑬𝒊), −𝜶𝒊] , 𝑪 −
𝜶𝒊}(3)
𝜶𝒊= 𝜶𝒊+ 𝜹𝜶𝒊 (4)
Keterangan :
𝛼𝑖 = Nilai parameter alpha 𝐷𝑖𝑗 = Hasil nilai matriks Hessian 𝐶 = nilai untuk parameter C
𝛿𝛼𝑖 = Parameter delta alfa untuk ke-i
4. Tahapan terakhir yaitu setelah mengetahui nilai Support Vector (SV), SV = (𝛼𝑖 >
TresholdSV). Nilai TresholdSV dilakukan berulang kali untuk mendapatkan nilai
TresholdSV, biasanya nilai TresholdSV
yang digunakan adalah TresholdSV≥ 0.
3.3. One-Against-All
One-Against-All (OAA)merupakan sebuah pendekatan untuk menjawab permasalahan pada
multi-class yang ada dalam metode Support Vector Machine. Selain pendekatan OAA, pendekatan yang dapat digunakan untuk permasalah multi-class SVM adalah pendekatan
One-Against-One. Dalam penelitian ini pendekatan yang digunakan adalah OAA. Pendekatan OAA ini bekerja dengan cara menjadikan kelas dari data ke-i bernilai positif dan untuk data yang tidak berasal dari kelas ke-i bernilai negatif. Pada Tabel 2 akan dijelaskan contoh permasalahan klasifikasi dengan menggunakan empat kelas (Sembiring, 2007).
Tabel 2 Contoh SVM Pendekatan One-Against-All
𝒚𝒊= 𝟏 𝒚𝒋= −𝟏 Hipotesis Kernel Kelas 1 Bukan kelas 1 𝑓1(𝑥) = (𝑤1)𝑥 +𝑏1 Kelas 2 Bukan kelas 2 𝑓2(𝑥) = (𝑤2)𝑥 +𝑏2 Kelas 3 Bukan kelas 3 𝑓3(𝑥) = (𝑤3)𝑥 +𝑏3
Kelas 4 Bukan kelas 4 𝑓4(𝑥) = (𝑤4)𝑥 +𝑏4
3.4. Proses Support Vector Machine
Langkah pertama yang ada dalam proses
Support Vector Machine (SVM) yaitu menginputkan data penyakit kucing. Langkah kedua setelah data didapatkan adalah menghitung kernel SVM, kernel yang digunakan adalah kernel RBF. Setelah nilai kernel
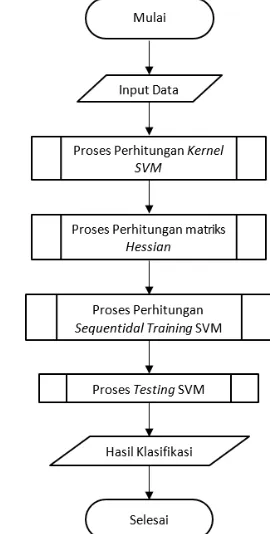
didapatkan maka proses perhitungan selanjutnya yaitu mencari nilai matriks Hessian, kemudian melakukan proses perhitungan Sequential Training SVM, proses testing SVM dan langkah akhir dari proses SVM adalah evaluasi dari klasifikasinya. Dalam Gambar 1 akan dijelaskan alur dari proses Support Vector Machine.
Gambar 1. Alur Proses Support Vector Machine
4. PENGUJIAN DAN ANALISIS
Pada penelitian mengenai penyakit kucing ini dilakukan proses pengujian terhadap sistem yang telah dibangun untuk mengetahui hasil yang diberikan. Pengujian yang dilakukan adalah pengujian rasio data, pengujian dari
kernel yang digunakan, pengujian terhadap parameter yang ada yaitu nilai lambda, gamma, sigma, complexity dan jumlah iterasinya.
4.1. Pengujian Rasio Data
dalam penelitian ini sebanyak 220 data yang akan dibagi kedalam data latih dan data ujinya. Nilai rasio dalam pengujian ini menggunakan perbandingan rasio 90%:10%, 80%:20%, 70%:30%, 60%:40%, 50%:50%, 40%:60%, 30%:70%, 20%:80%, dan 10%:90%. Untuk pengujian ini parameter yang digunakan adalah iterasi = 30, 𝜆= 0.1, σ = 2, C = 1, 𝛾= 0.01, ε = 1.10-5 dengan jenis kernel RBF.
Analisis yang dilakukan pada pengujian rasio data dilihat dari nilai akurasi yang diperoleh dan nilai akurasi yang didapatkan ditunjukkan pada Gambar 2.
Gambar 2. Hasil Pengujian Rasio
Berdasarkan dari Gambar 2 didapatkan nilai akurasi terbaik pada perbandingan rasio data 90%:10% yang nilai akurasinya adalah 74,6%. Data latih dan data ujinya didapatkan secara
random dari sistem. Data latih dan juga data uji yang diambil mewakili setiap kelas penyakit yang ada. Sehingga dari hasil yang didapatkan berupa pembagian data latih dan data uji dengan rasio 90% : 10% menunjukkan bahwa banyaknya data latih yang digunakan maka memberikan hasil akurasi tinggi, walaupun terjadi ketidakstabilan dalam nilai akurasi karena pemilihan datanya yang dilakukan secara
random.
4.2. Pengujian Jenis Kernel
Pengujian jenis kernel dilakukan untuk melihat perbedaan nilai akurasi yang dihasilkan berdasarkan dari penggunaan jenis kernel. Pegujian jenis kernel yang digunakan dalam penelitian ini adalah kernel linier, kernel polynomial, dan kernel RBF. Nilai parameter yang digunakan untuk pengujian ini adalah iterasi = 30, 𝜆= 0.1, σ = 2, C = 1, 𝛾= 0.01, ε = 1.10-5 dengan perbandingan datanya adalah
80%:20%.
Analisis yang dilakukan pada pengujian jenis kernel dilihat dari nilai akurasi yang diperoleh dan nilai akurasi yang didapatkan
ditunjukkan pada Gambar 3. Berdasarkan dari Gambar 3 dapat disimpulkan bahwa penggunaan jenis kernel terbaik ada pada penggunaan kernel
RBF yang menghasilkan nilai akurasi sebesar 72%. Sehingga dapat disimpulkan bahwa kernel
yang lebih baik untuk melakukan pengklasifikasi penyakit pada kucing adalah kernel RBF. Menurut Hsu dan Lin kernel RBF sangat cocok pada data yang non-linier, meskipun kernel ini untuk fitur yang besar mengalami ketidak cocokan (Hsu & Lin, 2008).
Gambar 3. Hasil Pengujian Jenis Kernel
4.3. Pengujian Iterasi
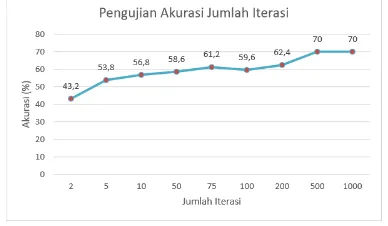
Pengujian selanjutnya adalah pengujian terhadap jumlah iterasi yang digunakan. Pengujian ini dilakukan untuk melihat pengaruh jumlah iterasi terhadap hasil nilai akurasi yang didapatkan. Jumlah iterasi yang diujikan adalah 2, 5, 10, 50, 75, 100, 200, 500 dan 1000. Untuk pengujian ini nilai parameter yang digunakan adalah 𝜆 = 0.1, σ = 2, C = 1, 𝛾 = 0.01 dengan menggunakan rasio data terbaik pada pengujian pertama yaitu 90% : 10% dan menggunakan jenis kernel Radical Basic Funtion.
Gambar 4. Hasil Pengujian Jumlah Iterasi
Pada Gambar 4 dapat dilihat bahwa akurasi tertinggi ada pada penggunaan jumlah iterasi = 500 dengan nilai akurasinya adalah 70%. Jumlah iterasi dapat mempengaruhi perubahan dari nilai
maka nilai dari alpha yang didapatkan telah mencapai nilai yang konvergen. Jumlah iterasi bertambah membuat support vector berjalan dengan seimbang dan posisi datanya tidak jauh dari bidang pemisahnya (hyperpelane)
(Puspitasari, et al., 2018).
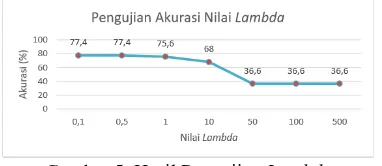
4.4. Pengujian Lambda
Pengujian berikutnya adalah menguji nilai parameter lambda. Pengujian ini dilakukan untuk mengetahui nilai akurasi terbaik berdasarkan dari nilai parameter lambda yang diujikan. Nilai lambda yang diujikan adalah 0.1, 0.5, 1, 10, 50, 100, 500 dan untuk pengujian ini nilai parameter yang digunakan adalah iterasi =
500, σ = 2, C = 1, 𝛾= 0.01, ε = 1.10-5 dengan
menggunakan rasio data terbaik pada pengujian pertama yaitu 90% : 10% dan jenis kernel yang dipakai adalah kernel RBF.
Analisis yang dilakukan pada pengujian nilai parameter lambda dilihat dari nilai akurasi yang diperoleh berdasarkan dari Gambar 5.
Gambar 5. Hasil Pengujian Lambda
Pada penelitian sebelumnya mengatakan nilai parameter lambda memiliki pengaruh terhadap jarak margin agar nilai hyperplane
yang didapatkan menghasilkan nilai yang baik (Hasanah, et al., 2016), sehingga jika nilai parameter λ bernilai kecil maka jarak margin
akan mengecil dan membuat nilai hyperplane
semakin baik karena perpotongan antar margin
berpengaruh terhadap garis hyperplane.
4.5. Pengujian Gamma
Pengujian selanjutnya adalah pengujian parameter gamma. Uji gamma dilakukan untuk mengetahui nilai skenario gamma dapat mempengaruhi nilai akurasi yang didapatkan. Nilai gamma yang diujikan adalah 0.0001, 0.001, 0.01, 0.1, 0.5, 1, 5, 10 dan untuk pengujian ini nilai parameter yang digunakan adalah iterasi = 500, 𝜆= 0.1, σ = 1, C = 1, ε = 1.10-5 dengan menggunakan rasio data terbaik
pada pengujian pertama yaitu 90% : 10% dan
kernel yang dipakai adalah kernel RBF.
Gambar 6. Hasil Pengujian Gamma
Dari Gambar 6 dapat dilihat bahwa nilai akurasi tertinggi dalam pengujian gamma ada pada nilai gamma = 0,01 dengan hasil akurasinya sebesar 77,4%. Berdasarkan hasil yang ditunjukan dalam Gambar 6 disimpulkan bahwa semakin besar nilai parameter gamma
maka nilai learning rate akan semakin besar dan nilai akurasi yang dihasilkan akan tidak stabil.
Learning rate adalah proses laju pembelajaran, dimana jika nilai learning rate semakin besar maka proses laju pembelajarannya akan semakin cepat, namun hasil ketelitian pada sistem yang didapatkan akan semakin berkurang begitupun sebaliknya.
4.6. Pengujian Sigma
Untuk pengujian sigma ini dilakukan untuk melihat hasil akurasi tertinggi didapatkan dari nilai skenario parameter gamma yang ada dalam pengujian ini. Nilai parameter yang digunakan pada pengujian ini adalah iterasi = 500, 𝜆 = 0.1, C = 1, 𝛾= 0.01, ε = 1.10-5 dengan menggunakan
rasio data terbaik pada pengujian pertama yaitu 90% : 10% dan kernel yang dipakai adalah
kernel RBF. Untuk nilai parameter sigma yang diujikan adalah 0.01, 0.1, 0.5, 1, 1.5, 2, 2.5, 3 dan 5.
Gambar 7. Hasil Pengujian Sigma
Analisis yang dilakukan dalam pengujian
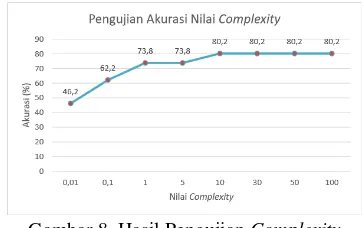
4.7. Pengujian Complexity
Pengujian terakhir dalam penelitian ini adalah pengujian terhadap parameter complexity. Pengujian ini dilakukan untuk melihat skenario mana yang memberikan hasil akurasi terbaik. Nilai parameter yang digunakan pada pengujian terhadap nilai parameter C (complexity) adalah iterasi = 500, 𝜆= 0.1, σ = 1, 𝛾= 0.01, ε = 1.10-5
dengan menggunakan rasio data terbaik pada pengujian pertama yaitu 90% : 10% dan kernel
yang dipakai adalah kernel RBF. Untuk nilai parameter complexity yang diujikan adalah 0.01, 0.1, 1, 5, 10, 30, 50, dan 100.
Gambar 8. Hasil Pengujian Complexity
Analisis yang dilakukan pada pengujian
complexity dilihat dari nilai akurasi yang dihasilkan. Pada Gambar 8 dapat dilihat bahwa hasil nilai akurasi terbaik ada pada saat penggunaan complexity = 10 yang memiliki hasil akurasi sebesar 76,4%. Tujuan dari pengujian nilai parameter C (complexity) ini adalah untuk
mengurangi nilai error. Nilai parameter
complexity memberikan pengaruh terhadap waktu komputasinya, jika nilai complexity besar maka akan memberikan waktu yang lama terhadap proses komputasi yang ada dalam perhitungan data training (Hasanah, et al., 2016).
5. KESIMPULAN
Dari penelitian ini dapat ditarik sebuah kesimpulan bahwa metode Support Vector Machine mampu diimplementasikan dalam permasalahan klasifikasi penyakit kucing dengan menggunakan dataset yang masih terbatas yaitu sebanyak 220 data yang dibagi kedalam 9 kelas. Penyakit yang di klasifikasikan dalam sistem yang dibangun adalah Scabies, Gastritis, Helminthiasis, Rhinitis, Dermatitis, Dermaphytosis, Otitis, Enteritis dan 1 kelas sehat. Nilai akurasi terbaik dari penelitian ini dihasilkan dengan menggunakan nilai parameter iterasi = 500, 𝜆= 0.1, σ = 1, C = 10, 𝛾= 0.01, ε = 1.10-5, sehingga nilai tertinggi dari akurasi
yang didapatkan adalah 85% dan rerata dari nilai
akurasinya adalah 80,2%.
6. DAFTAR PUSTAKA
Anonim, 2016. Mania Kucing. [Online]
Available at:
http://www.maniakucing.com/kucing-adalah/# [Diakses 29 September 2017]. Diani, R., Wisesty, U. N. & Aditsania, A., 2017.
Analisis Pengaruh Kernel Support Vector Machine (SVM) pada Klasifikasi Data Microarray untuk Deteksi Kanker. Ind. Journal On Computing, Volume 2. Hasanah, U., M., L. R., Pratama, A. &
Cholissodin, I., 2016. Perbandingan Metode SVM, Fuzzy-KNN dan BDT-SVM Untuk Klasifikasi Detak Jantung Hasil Elektrokardiografi. Teknologi Informasi dan Ilmu Komputer, Volume 3, pp. 201-207.
Hsu, C.-W. & Lin, C.-J., 2008. A Comparison of Methods for Multi-class Support Vector Machines.
Octaviani, P. A., Wilandari, Y. & Inspriyanti, D., 2014. Penerapan Metode Klasifikasi Support Vector Machine (SVM) Pada Data Akreditasi Sekolah Dasar (SD) di Kabupaten Magelang. Gaussian, Volume 3, pp. 811-820.
Prasetyo, E., 2012. Data Mining KOnsep dan Aplikasi Menggunakan MATLAB.
Yogyakarta: Andi Offset.
Pratama, A., Cahya, R. & Ratnawati, D. E., 2017. Implementasi Algoritme Support Vector Machine (SVM) untuk Prediksi Ketepatan Waktu Kelulusan Mahasiswa.
Pengembangan Teknologi Informasi dan Ilmu Komputer, Volume 2, pp. 1704-1708.
Puspitasari, A. M., Ratnawati, D. E. & Widodo, A. W., 2018. Klasifikasi Penyakit Gigi
Dan Mulut Menggunakan Metode
Support Vector Machine. Pengembangan Teknologi Informasi dan Ilmu Komputer,
Volume 2.
Rahman, A., 2008. Morfogenetika Kucing Rumah (Felis domesticus) di Desa Jagobayo Kecamatan Lais Bengkulu Utara Bengkulu. Exacta, Volume 6. Sangeetha, R. & Kalpana, B., 2011. Performance
Evaluation of Kernels in Multiclass Support Vector Machines. International Journal of Soft Computing and Engineering (IJSCE), 1(5).
Vector Machine untuk Pendeteksian Intrusi pada Jaringan.
Slattery, J. P. & O’Brien, S. J., 1998. Patterns of
Y and X Chromosome DNA Sequence Divergence During the Felidae Radiation.
Genetics Society of America.
Sufyan, M., 2016. Liputan6. [Online] Available
at: http:
//health.liputan6.com/read/2516695/ini- manfaat-memelihara-kucing-untuk-kesehatan [Diakses 29 September 2017]. Vijayakumar, S. & Wu, S., 1999. Sequential