BAB 2
LANDASAN TEORI
2.1. Sistem Rekomendasi
Sistem rekomendasi merupakan sebuah perangkat lunak yang bertujuan untuk membantu pengguna dengan cara memberikan rekomendasi kepada pengguna ketika pengguna dihadapkan dengan jumlah informasi yang besar. Rekomendasi yang diberikan diharapkan dapat membantu pengguna dalam proses pengambilan keputusan, seperti barang apa yang akan dibeli, buku apa yang akan dibaca, atau musik apa yang akan didengar, dan lainnya (Ricci et al, 2011).
Sistem rekomendasi pribadi (personalized recommender system) harus mengenal terlebih dahulu setiap pengguna yang ada. Setiap sistem rekomendasi harus membangun dan memelihara user model atau user profile yang berisi ketertarikan pengguna (Jannach et al, 2010). Sebagai contoh, sistem rekomendasi di website Amazon menyimpan setiap transaksi pembelian pelanggan, komentar pelanggan, dan
review / rating yang diberikan oleh pelanggan terhadap suatu produk.
2.2. Tagging
Proses penandaan suatu konten dengan sebuah keyword atau kata kunci disebut dengan tagging. Kata kunci atau tag dapat digunakan pada segala aplikasi seperti foto, artikel, blog, video dan lainnya(Alag,2007).
Penandaan suatu item atau konten oleh pengguna dapat digunakan untuk mengetahui minat dari pengguna, untuk mengetahui item atau konten yang sama dan untuk memberikan rekomendasi item atau konten yang sesuai dengan minat pengguna(Alag,2007).
Tagging dapat dibedakan menjadi dua yaitu : user-generated tags dan
machine-generated tags.
2.2.1 User-Generated Tags
Tag yang dibuat oleh pengguna disebuah sistem dapat dikategorikan sebagai user-generated tags dan proses penandaan tag oleh pengguna terhadap suatu item disebut dengan tagging (Alag,2007).
2.2.2 Machine-Generated Tags
Tag yang dibuat oleh sebuah machine dinamakan dengan machine-generated tags. Tag dibuat dengan menggunakan stemming dengan menganalisa teks dari sebuah konten atau item (Alag,20007).
Pengguna melakukan tagging yaitu dengan tujuan untuk mengatur dan mengingat sebuah item yang menarik bagi mereka. Selain itu dengan melakukan proses tagging
terhadap suatu konten, pengguna dapat saling berbagi informasi dengan pengguna yang lain, menemukan item atau konten yang sama dan mendapatkan rekomendasi
2.3. Collaborative Tagging
Collaborative tagging adalah sebuah proses dimana seorang pengguna secara bebas menggunakan sebuah tag sebagai keyword untuk sebuah item atau konten (Golder et al, 2006). Tag yang dilakukan oleh pengguna pada suatu menunjukkan ketertarikan atau minat dari pengguna terhadap suatu item atau konten.
Salah satu metode yang digunakan pada collaborative tagging adalah vector space model. Vector space model digunakan karena kemudahannya. Tag yang dilakukan oleh pengguna direpresentasikan dalam bentuk vektor dan untuk menghitung similarity dan memberikan rekomendasi digunakan dengan menggunakan cosine based similarity (Alag,2007).
2.4. Vector Space Model
Vector Space Model (VSM) adalah metode untuk melihat tingkat kedekatan atau kesamaan (smilarity) term dengan cara pembobotan term. Dokumen dipandang sebagi sebuah vektor yang memiliki magnitude (jarak) dan direction (arah). Pada Vector Space Model, sebuah istilah direpresentasikan dengan sebuah dimensi dari ruang vektor (Alag,2007).
- Dot Product
Dimisalkan (d) adalah merupakan nilai sebuah vektor dari sebuah dokumen . Untuk menghitung kesamaan dua buah vektor adalah dengan menggunakan cosine similarity. Tahap awal adalah dengan menghitung vector normalizer atau vector length dari setiap vektor yang ada pada dokumen (Alag,2007). Untuk menghitung
similarity antara dua vektor dihitung menggunakan rumus :
Sim (d1,d2) =
Dimana :
• (d1) merupakan nilai vektor dari dokumen 1
• (d2) merupakan nilai vektor dari dokumen 2
• | (d1) | | (d2)| merupakan nilai Euclidean length
Nilai Euclidean Distance merupakan nilai jarak antara suatu vektor dengan vektor yang lain(Alag,2007). Nilai Euclidean Distance dihitung dengan rumus :
Dimana :
• n adalah banyaknya jumlah vektor • vi adalah nilai yang ada pada vektor
Dari rumus 2.1 , akan didapat nilai length-normalize dari setiap vektor. Rumus untuk menghitung length-normalize adalah :
(d1) =
Dimana :
• adalah nilai dari vektor pada dokumen 1
• | adalah nilai euclidean length dari vektor dokumen 1
Rumus untuk menghitung cosine similarity untuk vector :
Sim (d1,d2) = (d1) . (d2)
Dimana :
• (d1) adalah nilai dari length-normalize vektor pada dokumen 1 • (d2) adalah nilai dari length-normalize vektor pada dokumen 2
(2.2)
(2.3)
Pada sistem rekomendasi dengan tag, setiap tag yang dilakukan oleh pengguna direpresentasikan kedalam bentuk vector.
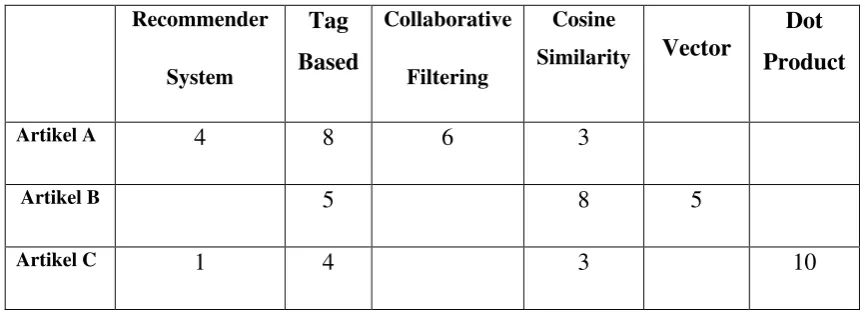
Sebagai contoh, terdapat tiga buah artikel yaitu artikel A, artikel B dan artikel C telah diberikan tag oleh user sebagai berikut:
• Artikel A telah diberikan tag dengan kata Recommender System oleh 4 user, Tag Based oleh 8 user, Collaborative Filtering oleh 6 user,Cosine Similarity oleh 3 user.
• Artikel B telah diberikan tag dengan kata Tag Based oleh 5 user,
Cosine Similarity oleh 8 user,vector oleh 5 user.
• Artikel C telah diberikan tag dengan kata Recommender System oleh 1 user, Tag Based oleh 4 user, Cosine Similarity oleh 3 user, Dot Product 10 user.
Tabel 3.1 Data artikel yang telah diberikan tagging oleh pengguna.
Recommender
Dari tabel 3.1 dapat diketahui bahwa terbentuk 6 vector berdasarkan dari semua jumlah term yang ada.kemudian dihitung normalizer untuk setiap jurnal .
Normalizer merupakan nilai dari Euclidean distance dan untuk menghitung nilai Euclidean Distance digunakan rumus 2.2 . Nilai normalizer untuk artikel A adalah = 11,18. Nilai normalizer untuk artikel B adalah =10,68 dan Nilai normalizer untuk artikel C adalah
Tabel 3.2 Raw Data Jurnal.
Setelah data normalizer didapatkan kemudian akan dihitung normalize dari setiap vector untuk setiap raw data jurnal. Untuk mendapatkan nilai normalized vector dihitung dengan menggunakan rumus 2.3. Sebagai contoh nilai normalized tag
Recommender System pada artikel A adalah = 0,3578, nilai normalized tag Tag Based pada artikel A adalah = 0,7156 , nilai normalized tag Collaborative Filtering pada artikel A adalah = 0,5367. Nilai semua normalized diterangkan dengan tabel 3.3
Tabel 3.3 Normalized Vector jurnal
Recommender
Sim(jurnal A dan jurnal B) = (0,7156*0,4682 + 0,2683*0,7491 ) = 0,5360
Sim(jurnal A dan jurnal C) = (0,3578*0,0891 + 0,2683*0,2673 ) = 0,3586
Sim(Jurnal B dan Jurnal C) = (0,4682*0,3563 + 0,7491*0,2673 ) = 0,3671
Dari contoh diatas dapat diketahui bahwa artikel B lebih relevan dengan artikel A dibandingkan dengan artikel C dan artikel C lebih relevan dengan artikel B dibandingkan dengan artikel A.
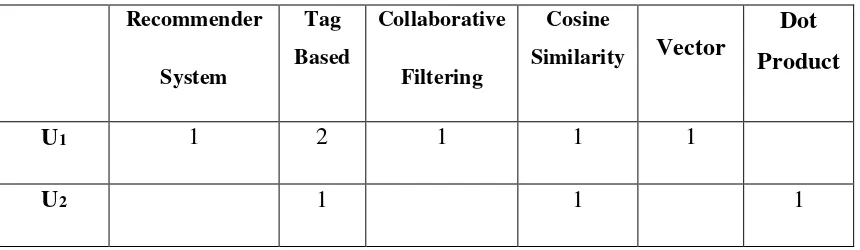
Selain untuk menghitung similarity antara suatu artikel dengan artikel lainnya, juga dapat juga digunakan untuk memberikan rekomendasi artikel kepada user. Sebagai contoh, terdapat dua buah pengguna yaitu dan telah memberikan tag
pada tiga buah artikel dengan tag sebagai berikut:
• telah memberikan tag pada artikel A dengan kata : Recommender System, Tag Based, Collaborative Filtering.
• telah memberikan tag pada artikel B dengan kata : Cosine Similarity, Vector, Tag Based
• telah memberikan tag pada artikel C dengan kata : Dot Product, Cosine Similarity, Tag Based.
Dari data tag yang dilakukan oleh dan dapat diketahui jumlah tag yang terdapat pada sistem berjumalah enam yaitu : Recommender System, Tag Based,
Collaborative Filtering, Cosine Similarity, Vector dan Dot Product.
Tabel 3.4 Data Tagging user
Kemudian setelah data dari tag user didapatkan langkah selanjutnya adalah dengan menghitung normalizer atau jarak antara suatu vektor dengan vektor lainnya. Untuk menghitung nilai normalizer setiap vektor dihitung dengan menggunakan rumus 2.2. Sebagai contoh nilai normalizer untuk user A adalah
= 2,83 dan nilai normalizer untuk user B adalah = 1,73. Hasil dari normalizer akan dijelaskan pada tabel 3.5
Tabel 3.5 Raw Data User Recommender
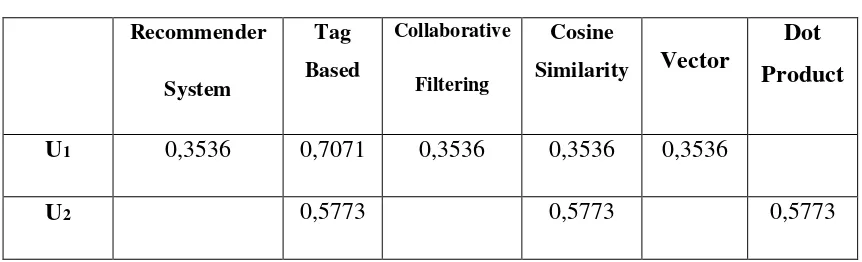
Setelah data normalizer/length untuk setiap user didapatkan kemudian dihitung
normalized untuk user. Untuk menghitung nilai normalized vektor dapat dihitung dengan menggunakan rumus 2.3. Hasil nilai dari normalized vektor pengguna dapat dilihat pada tabel 3.6.
Tabel 3.6 Normalized vector User
Recommender
Tabel 3.7 Dot Product User x Jurnal
Artikel A Artikel B Artikel C
U1 0,917 0,7616 0,378
U2 0,568 0,703 0,874
2.4. Bahasa Pemrograman PHP
Sibero (2011) mengatakan PHP (Hypertext Preprocessor) adalah pemrograman
interpreter yaitu proses penerjemahan dari kode sumber menjadi kode mesin yang dimengerti komputer pada saat baris kode dijalankan secara langsung. PHP pada awalnya ditulis menggunakan bahasa PERL (Perl Script), kemudian ditulis ulang dengan menggunakan bahasa C CGI-BIN (Common Gateway Interface-Binnary) yang bertujuan agar halaman website dapat mendukung formulir dan penyimpanan data. PHP adalah bahasa pemrograman Server Side Programming, memungkinkan sebuah
website yang dibangun bersifat dinamis (Sibero, 2011).
2.5. Database
Database adalah koleksi data item yang saling terkait terkelola sebagai satu unit. Beberapa defenisi lain tentang database yaitu sebagai berikut:
• Suatu pengorganisasian sekumpulan data yang saling berhubungan sehingga memudahkan aktivitas untuk memperoleh informasi (Sutanta, 2004).
• Database merupakan data yang saling terhubung dan deskripsi dari data yang dirancang untuk kebutuhan organisasi (McLeod dan Schell, 2004).
Penerapan database dalam sistem informasi disebut database system. Dari teori-teori tersebut dapat disimpulkan bahwa database adalah sekumpulan data yang terorganisasi dan saling terhubung untuk menyediakan informasi yang diperlukan.
Basis data (database), atau sering pula dieja basis data, adalah kumpulan informasi yang disimpan didalam komputer secara sistematik sehingga dapat diperiksa menggunakan suatu program komputer untuk memperoleh informasi dari basis data tersebut. Perangkat lunak yang digunakan untuk mengelola dan memanggil kueri (query) basis data disebut sistem manajemen basis data (Database Management System, DBMS) (Sutanta, 2004).
Sistem basis data (database system) didefinisikan sebagai sekumpulan subsistem yang terdiri atas basis data dengan para pemakai yang menggunakan basis data secara bersama-sama, personal-personal yang merancang dan mengelola basis data, teknik- teknik untuk merancang dan mengelola basis data, serta sistem komputer untuk mendukungnya (Kadir, 2003). Database system adalah sistem penyimpanan informasi yang terorganisasi dengan suatu cara sehingga memudahkan untuk proses pengolahan data (McLeod dan Schell, 2004).
DBMS adalah sebuah sistem perangkat lunak yang mengizinkan pengguna untuk mendefinisikan, membuat, memelihara, dan mengatur akses ke database.
Sedangkan menurut McLeod dan Schell (2004), DBMS adalah aplikasi perangkat lunak yang menyimpan struktur database, hubungan antardata dalam database, serta berbagai formulir laporan yang berkaitan dengan database tersebut.
2.6. Unified Modelling Language (UML)
Untuk membantu dalam pengembangan perangkat lunak dikenal istilah pemodelan. Salah satu pemodelan yang saat ini paling banyak digunakan oleh pengembang perangkat lunak adalah UML (Unified Modelling Language). UML adalah standar
bahasa yang sering digunakan dalam bidang industri untuk mendefinisikan
Ada beberapa hal yang dimaksud dalam kompleksitas pada perangkat lunak (Rosa et al, 2011):
1. Kompleksitas domain atau permasalahan perangkat lunak 2. Kesulitas mengelola proses pengembangan perangkat lunak 3. Kemungkinan fleksibilitas perubahan perangkat lunak
4. Permasalahan karakteristik bagian-bagian perangkat lunak secara diskrit
UML terbagi atas 3 (tiga) kategori, yaitu diagram struktur (structure diagram), diagram kelakuan sistem (behaviour diagram), dan diagram interaksi (interaction diagram)(Rosa, et al. 2011).
2.8. Penelitian Terdahulu
Sistem rekomendasi telah ada semenjak awal tahun 1990. Berbagai penelitian telah dilakukan untuk menyempurnakan, menggabungkan, dan bahkan menemukan teknik rekomendasi baru untuk mengatasi permasalahan di dalam sistem rekomendasi yang terus berkembang.
Penulis menggunakan penelitian yang telah dibuat sebelumnya sebagai rujukan maupun pertimbangan metode yang tepat untuk digunakan di dalam permasalahan penelitian ini.. Beberapa penelitian terdahulu di bidang sistem rekomendasi, diantaranya :
No Peneliti Keterangan
1 Hayati menggunakan metode hybrid (content based dan
collaborative filtering) dengan algoritma k-Nearest Neighbor
pada sistem rekomendasi pariwisata. Hayati menggunakan kombinasi sekuensial untuk menggabungkan kedua metode tersebut.
2 Wildan menggunakan metode hybrid ( content based dan
No Peneliti Keterangan
3 Uyun menggunakan metode item based collaborative filtering untuk memberikan rekomendasi pada pembelian buku secara online. Pada penelitian menggunakan rating dari pengguna untuk memberikan rekomendasi buku yang tertarik kepada pengguna.
2.9 Perbedaan dengan penelitian terdahulu
Perbedaan pada penelitian yang penulis lakukan adalah pada penelitian terdahulu yang digunakan untuk memberikan rekomendasi adalah dengan menggunakan rating oleh pengguna, sedangkan pada penelitian yang penulis lakukan dengan menggunakan tag