REGRESI LINIER BERGANDA (MULTIPLE REGRESSION)
Berbeda dengan regresi linier sederhana yang menguji pengaruh satu variabel independen terhadap satu variabel dependen, regresi linier berganda digunakan untuk memprediksi pengaruh lebih dari satu variabel independen berskala kuantitatif (interval, rasio) terhadap suatu variabel dependen. Agar proses uji regresi linier berganda ini dapat berjalan dengan sempurna peneliti sangat disarankan untuk menggunakan skala ukur Interval. Hal ini perlu agar data penelitian yang diperoleh terdistribusi secara normal. Data yang terdistribusi normal merupakan syarat untuk melakukan uji regresi linier berganda. Bila data tidak terdistribusi normal dapat menggunakan uji regresi binary logistic. Uji Normalitas
Sebelum melakukan uji regresli linier berganda, peneliti harus melakukan uji normalitas guna memastikan bahwa nilai residual dari variabel penelitian tersebut benar-benar terdistribusi secara normal.
Uji normalitas sekurang-kurangnya dapat ditentukan melalui Grafik P-Plot dan Uji Kolmogorof Smirnov. Berikut ini kita akan mendemonstrasikan uji normalitas menggunakan grafik P-Plot dan Uji Kolmogorof Smirnov. Uji lainnya lihat halaman 68 (Data Explore).
Grafik P-Plot Residual
Langkah pertama yang dilakukan adalah membuka file data spss anda; dalam hal ini kita mengambil file data dari master tabel pada halaman 162.
BAB 6
ANALISIS MULTIVARIAT
U
ji statistik multivariat digunakan untuk menguji hubungan simultan lebih dari dua variabel. Sama seperti statistik univariate, statistik multivariate juga dapat dibedakan menjadi uji parametrik dan nonparametrik. Dalam statistik multivariat, analisis dapat dibedakan menjadi analisis dependensi dan interdependensi. Dependensi berarti terdapat variabel bebas dan tidak bebas, sedangkan dalam interdependensi tidak terdapat perbedaan antar variabel.Terdapat banyak model dan uji statistik multivariat berdasarkan dependensi dan interdependensi variabel, diantaranya regresi linier berganda, regresi logistik, analisis faktor, cluster, multidimensional scaling, dan correspondence analysis.
Berikut ini adalah tahapan yang perlu anda lakukan: 1. Buka file data ASI.sav
2. Klik Analyze > Regression > Linear ....
3. Masukkan Asi ke dalam kolom Dependent, kemudian Usia, Didik, Kerja, dan Anak ke kolom Independent(s).
4. Klik tombol Save lalu pilih Residual, Unstandardized
5. Klik tombol Plots...lalu pilih Normal probability plot, dan klik tombol Continue, dan klik OK.
Berikut gambar grafik P-Plot
Data yang terdistribusi normal ditandai dengan titik-titik yang mengalir rapat pada garis.
Uji Kolmogorov-Smirnov
Setelah melakukan Uji normalitas menggunakan Grafik P-Plot untuk lebih meyakinkan peneliti; kita akan melakukan Uji KolmogoroV-Smirnov
1. Pilih menu Analyze, Nonparametric Tests, lalu pilih 1-Sample K-S (lihat gambar di bawah ini)
2. Dari daftar variabel, pilih variabel Unstandardized Residual yang berada pada urutan paling bawah., lalu klik tombol OK. Data terdistribusi normal bila nilai Asymp.Sig. (2-tailed) > 0,05.
Gambar dibawah menunjukkan nilai Asymp.Sig.(2-tailed) 0,512>0,05 berarti data terdistribusi normal.
CONTOH KASUS :
Seorang peneliti ingin mengetahui pengaruh umur, tingkat pendidikan, status kerja, dan jumlah anak terhadap pemberian asi, peneliti mengambil sampel 50 orang responden yang merupakan bersalin, variabel yang diuji antara lain ;
Umur
(X1), Didik (X2), Kerja (X3), Anak (X4) apakah
mem-pengaruhi variabel Independen Asi (Y).
Adapun persamaan regresi linier dari kasus di atas adalah : Y = a + b1X1 + b2X2 + b3X3 + b4X4Tahapan SPSS yang perlu anda lakukan adalah sebagai berikut :
1. Buka file data ASI.sav, lalu
Output SPSS & interpretasi hasil adalah sebagai berikut:
Penjelasan Tabel
Model Summary :
a) Nilai R sebesar 0,663 menunjukkan bahwa korelasi antara variabel dependen (pemberian Asi/asi) dengan variabel independen (Usia, Pendidikan (didik), sta-tus kerja (kerja), dan jumlah anak (anak) adalah kuat. b) R Square 0,439 berarti variabel independen (Usia, Pendidikan (didik), status kerja (kerja) memberikan kontribusi pengaruh sebesar 43,90 % terhadap variabel independen pemberian Asi (asi).
ANOVA (Uji F / Uji Serempak)
Nilai F hitung diperoleh adalah 8.812 dengan signifikasi 0,000. Dengan probabilitas 0,000. Lebih kecil dari 0,05 (p=0,05) maka secara serempak (Uji F) terdapat pengaruh variabel bebas usia, pendidikan (didik), status kerja (kerja), dan jumlah anak (anak) terhadap variabel terikat yaitu pemberian Asi (asi).
3. Masukkan Asi ke dalam kolom Dependent, kemudian Usia, Didik, Kerja, dan Anak ke kolom Independent(s).
4. Klik Statistics ...
5. Aktifkan pilihan Estimate dan Model Fit seperti pada gambar di atas, kemudian klik Continue. Klik OK.
c) Dari hasil tabel coefficient untuk variabel Status Kerja (kerja) diperoleh nilai Sig 0,021 < dari p: 0,05; berarti terdapat pengaruh signifikan variabel Kerja dengan pemberian Asi (ASI).
d) Dari hasil tabel coefficient untuk variabel Jumlah Anak (anak) diperoleh nilai Sig 0,861 > dari p: 0,05; berarti tidak terdapat pengaruh variabel Jumlah Anak (Anak) dengan pemberian Asi (ASI).
e) Dari persamaan linier, bila semua variabel X nilainya null (0), maka Y = -0,434. Bila semua variabel X bernilai 1, maka Y = -0,359
REGRESI BERGANDA BINARY (LOGISTIC REGRESSION)
Logistic regression digunakan untuk memprediksi
probabilitas suatu dependent variabel dari sekelompok dependent variabel.Logistic regression mirip dengan linear
regression. Bedanya, dependen variabel padalogistic
regression adalah dichotomous dengan skala nominal
(misalnya: berminat – tidak berminat, sehat – tidak sehat, lulus - tidak lulus, dan lainnya). Untuk independen variabel, skala ukur dapat berupa ordinal atau interval.Asumsi Regresi Logistik antara lain:
1. Regresi logistik tidak membutuhkan hubungan linier antara variabel independen dengan variabel dependen. 2. Variabel independen tidak memerlukan asumsi
multi-variate normality (tidak perlu data normal). 3. Asumsi homokedastisitas tidak diperlukan Coefficient (Uji t / Uji Partial)
Uji T (Uji Partial) digunakan untuk mengetahui nilai
Constant
dan nilai koefisien untuk setiap variable bebas (variabel X1, X2, X3, dst) yang digunakan pada persamaan regresi linier.Persamaan regresi yang di peroleh dari tabel Coef-ficients di atas adalah sebagai berikut:
Y = -0,434+0,047 X1-0,258 X2+0,277 X3+0,009 X4 Interpretasi tabel
Coefficient di atas adalah sebagai berikut:
a) Dari hasil tabel coefficient untuk variabel Umur diperoleh nilai Sig 0,001 < dari p: 0,05; berarti terdapat pengaruh signifikan variabel Umur dengan pemberian Asi (ASI). b) Dari hasil tabel coefficient untuk variabel Pendidikan (Didik) diperoleh nilai Sig 0,000 < dari p: 0,05; berarti terdapat pengaruh signifikan variabel Didik dengan pemberian Asi (ASI).7 0 0 0 8 1 1 1 9 0 0 1 10 0 1 0 11 0 0 1 12 1 1 0 13 0 0 0 14 1 1 0 15 1 0 0 16 1 1 0 17 1 1 0 18 1 1 1 19 0 1 0 20 1 1 0 21 0 0 0 22 0 0 0 23 0 0 1 24 1 1 1 25 1 1 1 26 1 1 1 27 1 1 1 28 0 0 0 29 0 0 0 30 1 1 1 31 0 0 0 32 1 1 1 33 1 1 1 34 1 1 1 35 0 0 0 36 0 1 1 37 0 0 0 38 1 1 1 39 1 0 1 40 1 1 0 41 0 0 0
4. Variabel bebas tidak perlu diubah ke dalam bentuk metrik (interval atau ratio) bisa ordinal/nominal. 5. Variabel dependen harus bersifat dikotomi (2 kategori,
misal: tinggi dan rendah atau baik dan buruk) 6. Variabel independen tidak harus memiliki keragaman
yang sama antar kelompok variabel
7. Kategori dalam variabel independen harus terpisah satu sama lain atau bersifat eksklusif
8. Sampel yang diperlukan dalam jumlah relatif besar, minimum dibutuhkan lebih dari 50 sampel data untuk sebuah variabel prediktor (independen).
9. Regresi logistik dapat menyeleksi hubungan karena menggunakan pendekatan non linier log transformasi untuk memprediksi odds ratio. Odd dalam regresi logistik sering dinyatakan sebagai probabilitas.
Berikut ini diberikan contoh penggunaaan regresi logistik untuk mengkaji Pengaruh Kebiasaan Merokok X1 (0 merokok & 1 tidak merokok) dan Riwayat Kanker X2 (0 ada & 1 tidak ada riwayat) terhadap Kanker Paru (Y) Data 80 responden sebagai berikut :
No X1 X2 Y 1 0 0 0 2 0 1 0 3 1 0 0 4 1 1 1 5 1 1 0 6 0 0 0
42 1 1 1 43 0 0 0 44 0 0 1 45 0 0 1 46 0 0 0 47 1 1 1 48 0 0 1 49 1 1 1 50 0 0 0 51 1 1 1 52 1 1 1 53 1 1 1 54 0 0 0 55 0 1 0 56 0 0 1 57 0 0 1 58 1 0 0 59 0 0 1 60 0 0 0 61 0 0 0 62 0 0 0 63 1 1 1 64 1 1 1 65 0 0 0 66 0 0 0 67 0 0 0 68 1 1 1 69 0 0 0 70 1 1 1 71 1 1 1 72 0 0 0 73 0 1 0 74 1 1 1 75 1 1 1 76 1 1 1 77 1 1 1 78 0 0 0 79 1 1 1 80 0 0 0
Disini saya akan menjelaskan langkah Analisis Regresi Logistik Metode Enter . Metode Enter yaitu dengan cara memasukkan semua variabel bebas ke dalam model secara bersamaan untuk menentukan variabel bebas yang paling berpengaruh dan menentukan nilai Exp(B) atau dikenal dengan Odd Ratio (Probability).
Langkahnya sebagai berikut :
1. Klik Analyze > Regression > Binary logistic
2. Masukkan variabel Kanker Paru kekotak Dependent. 3. Masukkan variabel independen (X1: Merokok dan
X2: Riwayat Kanker Paru) ke kotak
Covariate.
4. Pada pilihan Methode pilih Enter, Klik Optionsgambar di bawah ini menunjukkan Menu Logistic Regression Options, klik pada CI for exp(B) 95%, klik Continue. Lalu klik OK
Interpretasi Output (Penyajian Laporan) 1. Omnibus Tests of Model Coefficients
Pada tabelk Omnibus Test of Model Coefficient dapat dijelaskan sebagai berikut : (lihat halaman berikut).
Hipotesis
H0 : Tidak ada variabel X yang memengaruhi variabel Y Ha : Minimal ada satu variabel X yang memengaruhi
variabel Y
Tingkat Signifikasi a = 5%
Statistik Uji P-value (nilai Sig.) = 0,000 H0 ditolak jika P-value < 0,05
Nilai Sig. (0.000) < 0.05; Keputusan Tolak H0 Kesimpulan:
Dengan a=5% dapat disimpulkan bahwa minimal ada satu variabel X yang memengaruhi variabel Y.
2. Pseudo R Square
Pada tabel Model Summary di atas: Untuk melihat kemampuan variabel independen dalam menjelaskan variabel dependen, digunakan nilai Cox & Snell R Square dan Nagelkerke R Square. Nilai-nilai tersebut disebut juga dengan Pseudo R-Square atau jika pada regresi linear (OLS) lebih dikenal dengan istilah R-Square.
Nilai Nagelkerke R Square sebesar 0,323 menunjukkan bahwa kemampuan variabel independen dalam menjelaskan variabel dependen adalah sebesar 0,323 atau 32,3% dan terdapat 100% - 32,3% = 67,7% faktor lain di luar model yang menjelaskan variabel dependen.
3. Classification Result
Berdasarkan tabel Classification Table di atas, jumlah sampel yang tidak mengalami kanker 10 + 29 = 39 orang. Yang benar-benar tidak mengalami kanker Berdasarkan tabel Classification Table di atas, jumlah sampel yang tidak mengalami kanker 29 orang. Yang benar-benar tidak mengalami kanker sebanyak 29 orang dan yang seharusnya tidak mengalami kanker namun mengalami, sebanyak 10 orang. Jumlah sampel yang mengalami kanker 31 + 10 = 41 orang. Yang benar-benar mengalami kanker sebanyak 31 orang dan yang seharusnya mengalami kanker namun tidak mengalami, sebanyak 10 orang.
Tabel di halaman sebelumnya memberikan nilai overall percentage sebesar (29+31)/80 = 75% yang berarti ketepatan model penelitian ini adalah sebesar 75%; yang berarti ketepatan model penelitian ini sebesar 75% dapat menduga kemungkinan pengaruh merokok dan riwayat kanker terhadap kejadian kanker.
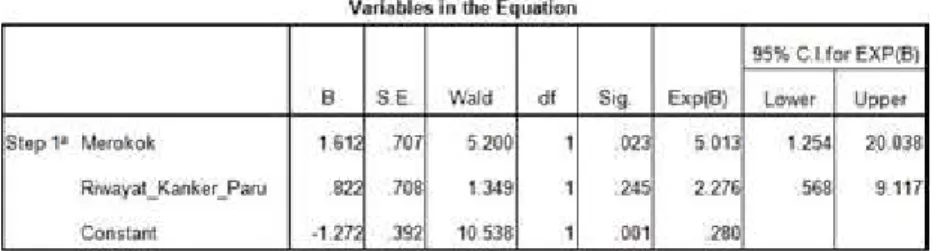
4. Variabel in the Equation (Pendugaan Parameter)
Lihat tabel Variabel in the equation di atas: hanya variabel Merokok (X1) yang nilai P value (Sig) < 0,05, artinya variabel Merokok (X1) mempunyai pengaruh yang signifikan terhadap Y di dalam model. X1 atau merokok mempunyai nilai Significant 0,023 < 0,05 sehingga menolak H0 atau yang berarti merokok memberikan pengaruh yang signifikan terhadap kejadian kanker paru. X2 atau riwayat kanker paru mempunyai nilai Significant 0,245>0,05 sehingga menerima H0 atau yang berarti riwayat kanker paru tidak memberikan pengaruh terhadap kejadian kanker paru.
Uji signifikansi parameter dapat pula dilakukan menggunakan nilai interval konfidensi 95%. Sebagai contoh nilai 95,0% C.I. for EXP(B) pada variabel Merokok adalah sebesar 1,254 (Lower) dan sebesar 20,038 (Upper), maka dapat disimpulkan bahwa Merokok berpengaruh nyata terhadap Kanker. Hal ini dikarenakan nilai 1 (satu) berada diluar rentang interval konfidensi tersebut. Sebaliknya, apabila nilai 1 (satu) berada di dalam rentang interval konfidensi, maka
variabel prediktor dapat dinyatakan tidak berpengaruh nyata terhadap variabel respon seperti terlihat pada hasil interval konfidensi variabel Riwayat_Kanker_Paru yang memiliki nilai Lower 0,568 dan Upper 9,117.
Besarnya pengaruh ditunjukkan dengan nilai EXP (B) atau disebut juga ODDS RATIO (OR). Variabel Merokok dengan OR 5,013 maka orang yang merokok (kategori 0 variabel independen), lebih beresiko mengalami kanker paru (kategori 0 variabel dependen) sebanyak 5,013 kali lipat di bandingkan orang yang tidak merokok (kode 1 variabel independen). Nilai B = Logaritma Natural dari Ln(5,013) = 1,612. Oleh karena nilai B bernilai positif, maka merokok mempunyai hubungan positif dengan kejadian kanker.
Variabel Riwayat Keluarga dengan OR 2,276 maka orang yang ada riwayat kanker paru (kode 0 variabel independen), lebih beresiko mengalami kanker paru (kode 0 variabel dependen) sebanyak 2,276 kali lipat di bandingkan orang yang tidak ada riwayat kanker paru (kode 1 variabel independen). Nilai B = Logaritma Natural dari Ln(2,276) = 0,822. Oleh karena nilai B bernilai positif, maka riwayat keluarga mempunyai hubungan positif dengan kejadian kanker.
Berdasarkan nilai-nilai B pada perhitungan di atas, maka model persamaan yang dibentuk adalah sebagai berikut: Ln P/1-P = -1,272 + 1,612 X1 + 0,822 X2 .
Atau bisa menggunakan rumus turunan dari persamaan di atas, yaitu:
Probabilitas = exp(-1,272 + 1,612 X1 + 0,822 X2) / 1 +exp (-1,272 + 1,612 X1 + 0,822 X2).
Misalkan sampel yang merokok dan ada riwayat keluarga, maka merokok=1 dan riwayat keluarga=1. Jika dimasukkan ke dalam model persamaan di atas, maka sebagai berikut:
Probabilitas atau Predicted = exp(-1,272 + (1,612 x 1) + (0,822 x 1)) / 1 + exp(-1,272 + (1,612 x 1) + (0,822 x 1)).
Probabilitas atau Predicted sebaiknya dihitung menggunakan MS-Excel =EXP(-1,272+(1,612) + (0,822))/(1+EXP(-1,272+(1,612)+(0,822))) = 0,761696.
Makna dari persamaan Regresi Logistik di atas adalah: Untuk setiap perubahan per 1 unit pada variabel merokok(0) (Coding untuk variabel merokok) dan perubahan per 1 unit pada variabel riwayat kanker (0) (Coding untuk variabel ada riwayat kanker), akan meningkatkan kemungkinan terjadinya kanker sebesar 0,761696 (atau 76,1%)
ANALISIS FAKTOR
Analisis faktor adalah salah satu teknik statistik multivariat yang digunakan untuk meringkas (data sumarization) dan mereduksi data (data reduction) sejumlah besar variabel ke dalam jumlah yang lebih kecil atau faktor. Dillon (1984) mendefinisikan analisis faktor sebagai metode analisis yang bertujuan untuk mendapatkan sejumlah faktor yang memiliki