ABSTRACT
Murtiningtyas, Adreana Pritha 2015, English Code-Mixing in Presidential Candidate Debates. Yogyakarta: Sanata Dharma University.
English is one of the foreign languages which is commonly used in the Indonesia today. Since English is a language which is commonly used, many people are interested in using it in their communication. Sometimes, some people in Indonesia mix their language between English and Bahasa Indonesia when they have a conversation. This phenomenon is called as a code-mixing. Code-mixing is a phenomenon where someone mixes two languages in one sentence. It is commonly used by people who can speak at least two languages.
This research was conducted to identify the types of code-mixing, which is made by the participants of presidential candidate debate 2014. Furthermore, the researcher conducted this research based on the utterances made by the participants. Since the data which is used was taken from the presidential candidate debates, the reseacher made the transcription of the debates by taking all videos of the debates.
Then the research method which is used by the researcher was content analysis. In this research, the reseacher as the main instrument. Moreover, the researcher also used observation sheet in a form of checklist to help her in analyzing the data. First, the researcher organized the data by breaking down the large body of the text. Then the researcher re-read the data to check whether she had accurate analysis or not. Next, the researcher classified the utterances into the categories according to the types of code-mixing. The last step, the reseacher summarized all of the findings.
The findings showed two types of code-mixing which are frequently made by the participants. They were insertion and alternation. From all debates, there were 156 utterances of insertion and 37 utterances of alternation.
ABSTRAK
Murtiningtyas, Adreana Pritha 2015, English Code-Mixing in Presidential Candidate Debates. Yogyakarta: Sanata Dharma University.
Bahasa Inggris merupakan salah satu bahasa asing yang umum digunakan di Indonesia. Karena Bahasa Inggris adalah bahasa yang umum digunakan maka membuat banyak orang tertarik untuk menggunakannya secara bersamaan di dalam komunikasi sehari-hari. Bahasa Inggris juga sangat populer di Indonesia. Terkadang beberapa orang mencampur Bahasa Indonesia dan Bahasa Inggris ketika mereka dalam percakapan sehari-hari. Fenomena ini dikenal dengan campur kode. Compur kode merupakan fenomena dimana seseorang mencampur dua bahasa didalam satu kalimat. Biasanya ini digunakan oleh orang yang bisa menggunakan setidaknya dua bahasa.
Penelitian ini dilakukan untuk mengindentifikasi tipe dari campur kode yang dilakukan oleh para peserta debat presiden 2014. Selanjutnya, peneliti melakukan penelitian ini berdasarkan kalimat yang diucapkan oleh para peserta. Karena data diambil dari transkrip debat calon presiden 2014 peneliti membuat transkrip debat dengan mengambil semua video debat.
Metode yang digunakan dalam penelitian ini adalah content analysis. Dalam penelitian ini, peneliti menjadi instrument utama. Selanjutnya, peneliti menggunakan lembar observasi berupa checklist untuk membantunya dalam menganalisa data. Yang pertama, peneliti mengorganisir data yang didapat dengan cara membagi text utama menjadi bagian yang lebih kecil. Lalu peneliti membaca kembali datanya untuk memastikan bahwa ia melakukan analisis secara akurat atau tidak. Selanjutnya, peneliti mengklasifikasikan kalimat tersebut kedalam kategori tipe dari campur kode. Langkah terakhir adalah menyimpulkan semua hasil temuan.
ENGLISH CODE-MIXING IN PRESIDENTIAL CANDIDATE
DEBATES
A SARJANA PENDIDIKAN THESIS
Presented as Partial Fulfillment of the Requirements to Obtain the Sarjana Pendidikan Degree
in English Language Education
By
Adreana Pritha Murtiningtyas Student Number: 101214099
ENGLISH LANGUAGE EDUCATION STUDY PROGRAM DEPARTMENT OF LANGUAGE AND ARTS EDUCATION FACULTY OF TEACHERS TRAINING AND EDUCATION
SANATA DHARMA UNIVERSITY YOGYAKARTA
i
ENGLISH CODE-MIXING IN PRESIDENTIAL CANDIDATE
DEBATES
A SARJANA PENDIDIKAN THESIS
Presented as Partial Fulfillment of the Requirements to Obtain the Sarjana Pendidikan Degree
in English Language Education
By
Adreana Pritha Murtiningtyas Student Number: 101214099
ENGLISH LANGUAGE EDUCATION STUDY PROGRAM DEPARTMENT OF LANGUAGE AND ARTS EDUCATION FACULTY OF TEACHERS TRAINING AND EDUCATION
SANATA DHARMA UNIVERSITY YOGYAKARTA
iv
DEDICATION PAGE
“A dream doesn‟t become reality through magic; it takes
sweat, determination and hard work”
Colin Powell
“Genius is one percent inspiration, ninety-nine percent
perspirations”
Thomas A. Edison
I dedicated this thesis to:
v
STATEMENT OF WORK’S ORIGINALITY
I honestly declare that this thesis, which I have written, does not contain the work or parts of the work of other people, except those cited in the quotations and the references, as a scientific paper should.
Yogyakarta, 10 April 2015 The writer
vi
LEMBAR PERNYATAAN PERSETUJUAN
PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswi Universitas Sanata Dharma: Nama : Adreana Pritha Murtiningtyas
Nomor Mahasiswa : 101214099
Demi kepentingan ilmu pengetahuan, saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul:
ENGLISH CODE-MIXING IN PRESIDENTIAL CANDIDATE DEBATES Beserta perangkat yang diperlukan (bila ada). Dengan demikian, saya memberikan kepada Perpustakaan Sanata Dharma hak untuk menyimpan, mengalihkan dalam bentuklain, mengelolanya dalam bentuk pangkalan data, mendistribusikan secara terbatas, dan mempublikasikannya di Internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun memberikan royalty kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya.
Dibuat di Yogyakarta Pada tanggal: 10 April 2015
Yang menyatakan
vii ABSTRACT
Murtiningtyas, Adreana Pritha 2015, English Code-Mixing in Presidential Candidate Debates. Yogyakarta: Sanata Dharma University.
English is one of the foreign languages which is commonly used in the Indonesia today. Since English is a language which is commonly used, many people are interested in using it in their communication. Sometimes, some people in Indonesia mix their language between English and Bahasa Indonesia when they have a conversation. This phenomenon is called as a code-mixing. Code-mixing is a phenomenon where someone mixes two languages in one sentence. It is commonly used by people who can speak at least two languages.
This research was conducted to identify the types of code-mixing, which is made by the participants of presidential candidate debate 2014. Furthermore, the researcher conducted this research based on the utterances made by the participants. Since the data which is used was taken from the presidential candidate debates, the reseacher made the transcription of the debates by taking all videos of the debates.
Then the research method which is used by the researcher was content analysis. In this research, the reseacher as the main instrument. Moreover, the researcher also used observation sheet in a form of checklist to help her in analyzing the data. First, the researcher organized the data by breaking down the large body of the text. Then the researcher re-read the data to check whether she had accurate analysis or not. Next, the researcher classified the utterances into the categories according to the types of code-mixing. The last step, the reseacher summarized all of the findings.
The findings showed two types of code-mixing which are frequently made by the participants. They were insertion and alternation. From all debates, there were 156 utterances of insertion and 37 utterances of alternation.
viii ABSTRAK
Murtiningtyas, Adreana Pritha 2015, English Code-Mixing in Presidential Candidate Debates. Yogyakarta: Sanata Dharma University.
Bahasa Inggris merupakan salah satu bahasa asing yang umum digunakan di Indonesia. Karena Bahasa Inggris adalah bahasa yang umum digunakan maka membuat banyak orang tertarik untuk menggunakannya secara bersamaan di dalam komunikasi sehari-hari. Bahasa Inggris juga sangat populer di Indonesia. Terkadang beberapa orang mencampur Bahasa Indonesia dan Bahasa Inggris ketika mereka dalam percakapan sehari-hari. Fenomena ini dikenal dengan campur kode. Compur kode merupakan fenomena dimana seseorang mencampur dua bahasa didalam satu kalimat. Biasanya ini digunakan oleh orang yang bisa menggunakan setidaknya dua bahasa.
Penelitian ini dilakukan untuk mengindentifikasi tipe dari campur kode yang dilakukan oleh para peserta debat presiden 2014. Selanjutnya, peneliti melakukan penelitian ini berdasarkan kalimat yang diucapkan oleh para peserta. Karena data diambil dari transkrip debat calon presiden 2014 peneliti membuat transkrip debat dengan mengambil semua video debat.
Metode yang digunakan dalam penelitian ini adalah content analysis. Dalam penelitian ini, peneliti menjadi instrument utama. Selanjutnya, peneliti menggunakan lembar observasi berupa checklist untuk membantunya dalam menganalisa data. Yang pertama, peneliti mengorganisir data yang didapat dengan cara membagi text utama menjadi bagian yang lebih kecil. Lalu peneliti membaca kembali datanya untuk memastikan bahwa ia melakukan analisis secara akurat atau tidak. Selanjutnya, peneliti mengklasifikasikan kalimat tersebut kedalam kategori tipe dari campur kode. Langkah terakhir adalah menyimpulkan semua hasil temuan.
Hasil temuan menununjukan ada dua tipe campur kode yang sering digunakan oleh peserta debat. Kedua tipe itu adalah insertion dan alternation. Dari semua debat, ada 156 kalimat untuk insertion dan 37 kalimat untuk alternation.
ix
ACKNOWLEDGEMENTS
Writing a thesis is not an easy job for me. There were so many temptations
to finish this thesis. On the other hand, writing this thesis is a kind of challenge. I
need to control myself, manage my time and try to ignore those temptations. This
thesis could make me stressful and want to give up. When I have finished this
thesis, it feels like I have thrown all my pain away. I would thank Jesus Christ for his blessings during my writing process. He gave me spirit, strength, and
health in finishing this thesis.
I would like to thank the people who supported me during my thesis
writing process. Firstly, I would give my appreciation to my thesis advisor
Christina Kristiyani S.Pd., M.Pd. especially for her guidance, support and patience during my thesis writing period. I thank her because she helped me from
the beginning until the end of this thesis
Secondly, I would thank my family, especially my parents, Y.C. Eko Suharno and M.G. Puji Rahayu, who supported me when I got stuck or did not know what to do. They were my strength in finishing my thesis, and thanks for the
prayer. My greatest thanks also go to my beloved brother Benedictus Damar Nugroho Aji, who called and reminded me about the unfinished tasks. My deepest gratitude also goes to my grandparents, mbah Tri and eyang who always
x
I would thank my super-duper best friends in my college period Fransiska
Dwiningsih Renwarin, Ika Tyas Intani, and Silviana Piar. They encouraged, supported and listened to my story of thesis. My greatest gratitude also goes to my
senior high school friends, Rena Widyawinata and Fransiska Finishiana, who
always reminded me about my thesis. I also say thank my friends in batch 2010;
Marino, Satya, Dyah, Siwi, Narima, Tere, Heni and others who cannot be mentioned. My gratitude also goes to my „thesis-friends‟; Galang, Yoga, Chandra, Aurel, Mona, Jason, Gita, and Gabby.
Next, I would thank my brothers in batch 2008 mas Berlin Adi Pranendya and mas Adrian Bayuaji Wicaksono, who supported and listened about my thesis-story. My gratitude also goes to other brothers from batch 2012
Gheza Damara, Hilarius Raditya, Marcellus Gregorius and Dwittya Wiratama, who always reminded me about my thesis. They rarely said a good word, but they were good brothers who can be good-listeners. I would also thank
Erin, Eris, and Deta, who supported me during these last semesters.
There are many other people who supported me in writing this thesis that
cannot be mentioned such as all my pudding customers who bought my products
and it helped me finish my thesis. I would give my deepest gratitude and I hope
they are successful in their lives.
xi
TABLE OF CONTENTS
Page
TITLE PAGE ……… i
APPROVAL PAGES ……… ii
DEDICATION PAGE ……… iv
STATEMENT OF WORK‟S ORIGINALITY ……… v
PERNYATAAN PERSETUJUAN PUBLIKASI ……… vi
ABSTRACT ………. vii
ABSTRAK ………. viii
ACKNOWLEDGEMENTS ………. ix
TABLE OF CONTENTS ………. xi
LIST OF TABLES ………. xiv
LIST OF FIGURES ………. xv
LIST OF APPENDICES ………. xvi
CHAPTER I. INTRODUCTION ……… 1
A. Research Background ……… 1
B. Research Problem ……… 3
C. Problem Limitation ……… 3
D. Research Objective ……… 4
E. Research Benefits ……… 4
xii
CHAPTER II. REVIEW OF RELATED LITERATURE ...…… 8
A. Theoretical Description ……… 8
1. Sociolinguistics ... 8
2. Code-mixing ... 9
a. Typology of Code-mixing ... 10
1) Insertion ... 11
2) Alternation ... 12
3) Congruent Lexicalization ... 14
3. Debate ... 16
4. Presidential Candidate Debates ... 17
B. Theoretical Framework ……… 18
CHAPTER III. RESEARCH METHODOLOGY ……… 20
A. Research Method ………... 20
B. Research Setting ………... 22
C. Research Participants ………... 23
D. Instrument and Data Gathering ……… 23
E. Data Analysis Technique ……… 24
F. Research Procedure ……… 25
CHAPTER IV. RESEARCH RESULT AND DISCUSSION .... 29
A. Findings ………... 29
xiii
CHAPTER V. CONCLUSIONS AND RECCOMENDATIONS …. 47
A. Conclusions ……… 47
B. Recommendations ……… 49
C. Implication ... 50
REFERENCES ……… 51
xiv
LIST OF TABLES
Table Page
3.1. The list of Presidential Candidate Debate……….……….. 25
4.1. The total of code-mixing in the first debate…….…….………….. 30
4.2. The total and percentage of code-mixing cases... 31
in the second up to fifth debate...………….…………. 33
4.3. The number of insertion cases……… 34
4.4. The list of insertion on the first debate ………. 35
4.5. The list of insertion on the second debate ……….. 36
4.6. The list of insertion on the third debate ……….. 37
4.7. The list of insertion on the fourth debate ……… 38
4.8. The list of insertion on the fifth debate ……… 40
4.9. The number of alternation cases ……….. 41
4.10. The list of alternation on the first debate ………. 42
4.11. The list of alternation on the second debate ………. 43
4.12. The list of alternation on the third debate ………. 44
4.13. The list of alternation on the fourth debate ………... 45
xv
LIST OF FIGURES
Figure Page
xvi
LIST OF APPENDICES
Appendix Page
A. The list of the data ………. 54
B. Transcription of first debate ………. 73
C. Transcription of second debate ……..………. 103
D. Transcription of third debate ………. 123
E. Transcription of fourth debate ………. 148
1
CHAPTER I
INTRODUCTION
In this chapter, the researcher presents a brief discussion of research
background, research problem, problem limitation, research objective, research
benefits, and definition of terms.
A. Research Background
English is one of the languages which is usually used in the world
nowadays. There are many countries which have used English as the international
language in their communications. According to Kachru (1992) as cited by Lauder
(2008) Indonesia is a part of expanding circle where according to Crystall (2003)
as cited by Lauder (2008) expanding circle has 750 million speakers of English as
foreign language. This means that a lot of people are capable to use English.
Moreover, Lauder (2008) adds that English is important for Indonesia since
English is a global or international language. Since English becomes so important,
many people are interested in studying English.
English learners have different reasons to learn English; the first reason is
called as ‘instrumental’ reason and the second is called as ‘integrative’ reason. Instrumental reason means learners learn English because it was a requirement or
because they needed it to accomplish some other goal (Holmes, 2001). For
instance, in a job vacancy, it requires the job applicants to have the English skills
purpose. The other reason is integrative reason, learners learn English because
they want to know about the culture (Holmes, 2001). On the other side some
Indonesians who use English have one major reason, prestige. Hassall (2011)
describes that English carries a very high condition in Indonesia, and thus when a
speaker uses language which sound English, a certain prestige may attach to him
or her as a result. Hassal (2011) adds the speaker can sound moderns,
sophisticated, and highly educated.
As stated by the fact above, people start to realize that study English is a
must for them who have either an instrumental reason or integrative reason.
English is needed to assist people in many aspect, for instance, in education,
working place, or even in communication in daily life. In communication, English
has become very common. Sometimes people tend to mix English with Bahasa Indonesia. This phenomenon is called as code-switching or code-mixing. Based on Hoffmann (1991), code-switching involves the alternate use of two languages
or linguistics varieties within is the same utterance or during the same
conversation. Moreover, McLaughlin (1984), as cited by Hoffmann (1991) adds
that code-switching refers to language changes occurring across sentence
boundaries, whereas code-mixing sometimes takes place within in a sentence in
very short utterances. Code-mixing is commonly used by people who know at
least two languages.
According to Wardaugh (2010), code-mixing can arise from individual
choice or be used as a major identity marker for a group of speakers who must
case, people code-switch when they do not know the appropriate translation in the
target language (Wardaugh, 2010). On the other hand, according to Holmes
(2001), this kind of code-mixing called as lexical borrowing, which reflects a lack
of vocabulary in a language. People do code-mixing from their mother tongue
because they don’t know the appropriate word in their second language. It happens to express a concept or describe an object for which there is no obvious
word available in the language they are using.
Mixing language is commonly used because it often occurs in daily
conversation, such as on the radio, internet, and television. Television is one of
the common communication tools. From the programs on television, they give
many advantages for people because they contain much information. In television
programs such as presidential candidate debate 2014, people can find the
code-mixing. Code-mixing can be found in the debate because people who were
involved in the debate tended to mix between Bahasa Indonesia and English. In this case, the ones who used to mix between Bahasa Indonesia and English were
the participants of the debate.
The participants of the debate are the candidates of presidential election
2014. In the presidential candidate debates, the participants often did the
code-mixing and this phenomenon attracted the writer’s interest to identify the types of mixing which occurs in the debates. To see further explanations of
mixing made by the participants, this research will discuss the types of
B. Research Problems
There is one problem to be solved in this research, namely, what are the
types of code-mixing which occur in a presidential debate?
C. Problem Limitation
This research focused on the code-mixing, which is made by the
participants of presidential debate which is held five times. Moreover, the main
focus of this research is the types of code-mixing. In addition, the participants of
the debate are the candidates in the presidential election. To collect the data, the
researcher took all of the debate videos from youtube.com and made the transcription of the videos. The analysis of the data was done from how often the
participants made code-mixing in their utterances.
D. Research Objectives
Since this research intended to find out the answer to the problem, this
research has an objective. Based on the data, the researcher wants to find out the
code-mixing types which commonly occur in the debate.
E. Research Benefits
The result of this research is useful to the next researcher, the readers and
1. The next researcher
This research hopefully will help the next researcher who conducts the
same topic by giving information related to code-mixing. By doing research on
code-mixing, it will enrich the readers to understand more about code-mixing.
The next researcher can try to conduct research on code-mixing, but on different
issues such as code-mixing which occurs on twitter or magazines.
2. The readers
This research will be useful for those who are interested in code-mixing
topic. This research will give a deeper understanding about the types of
code-mixing. Then this research will provide the readers with information about types
of code-mixing.
3. ELESP students
This research is expected to help ELESP students who are interested in
sociolinguistics to give more information about code-mixing especially about the
types of code-mixing.
F. Definition of Terms
This part will define some terms which are used in this research. The
purpose is to avoid misunderstanding in perceiving some important terms in this
research.
1. Code-mixing
Code-mixing or code-switching is defined as the use of two or more
commonly occurs in bilingual or multilingual society. According to Wardaugh
(2010), code-mixing arise from individual choice or be used as a major identity
maker for a group of speakers who must deal with more than one language in their
common pursuits (p. 98). In this study, code-mixing happens between English and
Bahasa Indonesia. The English words which are used in the utterances are not loan words from English to Bahasa Indonesia. For clearer explanation, it will be explained more in Chapter Three.
2. Debate
As stated by Freely (1969), debate is ubiquitous in our society at
decision-making level. Moreover, the debate is a method of rational decision-decision-making and
debate consists of arguments for against to a given proportion. Freely (1969) also
states that the debate will help us to make rational decisions and to secure rational
decisions from others. Since the subject of this research was the debates.
Therefore, in this study, the theory of debate is used to know the nature of the
debate itself.
3. Presidential Candidate Debate
Based on General Election Commission (KPU) websites (2014), presidential candidate debate is an event which is held by General Election
Commission (KPU) before the presidential election. This 2014 debate is the second debate which is held by the General Election Commission, the first debate
was held on 2009. Both first and second debates were divided into five parts with
a different topic for each part. The first debate was broadcasted by Trans Corp,
broadcasted by SCTV, Metro TV, TvOne, RCTI, MNCTV, Global TV, TVRI,
Kompas TV, and RTV. This event aims to give a chance for the presidential
8
CHAPTER II
REVIEW OF RELATED LITERATURE
This chapter consists of two parts, the first is the theoretical description
and the second is the theoretical framework. Theoretical description presents the
detailed discussions about mixing, types of mixing, reasons of
code-mixing, presidential candidate debate, and biography of a presidential candidate.
The theoretical framework presents the synthesis of important concepts which is
used in this research.
A. Theoretical Description
In this part, the researcher discusses the theories that underline the
research. There are some theories and information which have relation to this
research. The theory which is used is code-mixing -- it includes the definition of
code-mixing, types of code-mixing, and reasons of code-mixing. Furthermore, the
information is about presidential candidate debate -- it includes the biography of a
presidential candidate.
1. Sociolinguistics
According to Van Herk (2012), sociolinguistics is the scientific study of
the relationships between language and society. It means that the language has
relation with society since language is must be used in society. Hudson (1969) as
cited by Wardaugh (2000) also adds that sociolinguistics is the study of language
relation to language. Sometimes people can find two or more languages that are
used in one society. The society which has two languages is called as
bilingualism. Then the society which has more than two languages is called as
multilingualism. Such condition causes a phenomenon called code-switching or
code-mixing. Thus, code-switching or code-mixing is included in a
sociolinguistics study.
2. Code-mixing
According to Wardaugh (2010) a code is a language, a variety of language.
It is used since the term code is neutral rather than the terms such as dialect,
vernacular, style, standard language, pidgin, and creole. Code can be used to refer
to any kind of communication. Oladosu (2011) says that in communications, a
code is a rule for converting a piece of information into another form or
representation, not necessarily of the same sort. When people produce language, it
means people produce code. People can choose whether to use a single code or
more than one code. People in multilingualism or bilingualism, who use more
than one codes tend to mix or switch their first code or another code. Wardaugh
(2010) says that most of the multilingualism or bilingualism speakers command
several varieties of any language they speak. Wardaugh also adds that people are
usually required to select particular code whenever they speak and they may also
decide to switch or to mix from one code to another within sometimes very short
utterances, this process is called as code-switching or code-mixing.
Code-mixing which is also called as intra-sentential code-switching or
below clause within one social situation. Singh (1985), as quoted by Romaine
(1995) says that the term code-mixing is used for intra-sentential switching.
Intra-sentential switching means, switching that occurs within one sentence (Holmes,
1992). Code-mixing is the use of one language in another language, the mixing of
two or more languages or language varieties in a speech. Hamers and Blanc
(2000) define code-mixing as a type of insertion code-switching, where a
constituent of language A is embedded in an utterance in Language B and the
language B is clearly the dominant language. In addition, McCormick (1995)
suggests that code-switching involves the alternation of elements longer than one
word while code-mixing involves shorter elements, often just a single word.
Therefore, code-mixing is the use of two languages in one sentence where the
language A is embedded in language B which is dominant.
In conclusion, code-mixing is a part of code-switching which categorized
as intra-sentential code-switching. Code-mixing can occur only in short utterances
like one word, on the other hand, code-switching often occurs in more than one
word. In this thesis, the researcher used the term mixing rather than
switching since the data of the research are categorized as intra-sentential
code-switching.
a. Typology of Code-mixing
Code-mixing is related to grammatical theory. Pieter Muysken (2000) proposes three models of code-mixing since there is no such a model provided by
grammatical theory and language processing. Pieter Muysken (2000) also
code-mixing. They are; insertion, alternation, and congruent lexicalization. They
are described as below:
1)Insertion
For this type, Muysken (2000) explains that one way in which languages may be combined within the syntactic unit is such that language A is dominant
and language B is inserted into the grammatical frame defined by language A.
According to Myers-Scotton (2002) as cited by Auer and Muhamedova, linguists
call the dominant language as Matrix Language (ML) and inserted language as
Embedded Language (EL). The insertion itself can be only single lexical items
such a word. Cantone (2007) adds insertion is given when elements from one
language are mixed or inserted into another language.
Based on Muysken‟s account, Cantone (2007) says that inserting an
element comes close to lexical borrowing, but whereas borrowing only covers the
insertion of lexical items, insertion can imply larger structures, such as whole
phrases. Cantone (2007) also gives an example of insertion code-mixing, this
example involving English and German „I go to the movie with my fratello’. The
word fratello means friend in English, and it is clear that fratello is inserted into English grammatical structure in a sentence. The explanation will be explained by
A B A
…a…. ...b… …a…
Figure: 2.1 Insertion (Bilingual Speech: Typology of Code-mixing, Muysken, 2000.)
In this study
A : represents Bahasa Indonesia
a : shows grammatical structure of Bahasa Indonesia B : represents English
b : shows words in English which are inserted in an Indonesian sentence.
From the figure 2.1, it can be seen that language A is a Matrix Language
(ML) in the sentence and the language B which is an Embedded Language (EL) in
the sentence. Furthermore, it shows that a word in English (ML) is inserted in a
sentence in Bahasa Indonesia (EL). Therefore, it can be concluded that an insertion is a code-mixing, which happens in a sentence by adding a word in
another language that is different from the dominant language.
2)Alternation
This type is a little bit different from the previous type, insertion.
Insertion is dealing with how one word of one language is inserted into another
language pattern. On the other hand, alternation does not only insert some words
of a language into another language pattern, but also involves the grammar pattern
true switch from one language to another language, involving both grammar and
lexicon.” According to Poplack (1980), as cited by Cantone (2007), alternation
means code-switching under equivalences and involves and analysis of the
structural compatibility of two languages, in the sense of equivalence between
them at a given switching point. Thus, alternation is a mixing of two languages
which is not only one word inserted into another language, but also involves the
grammar pattern.
Since alternation is not only just inserted an element of a language to
another language, but also involve both grammar and lexicon. It is ending up in a
true switching from one language to another language (Muysken, 2000). Cantone
(2007) gives an example English-German alternation as follows: “She went to quel ristorante all’angolo,” which means “She went to that restaurant at the
corner.” From the example, it can be seen that the switching happens between
clauses. Figure 2.2 is the representation of the explanation.
A B
…a… …b…
Figure: 2.2 Alternation (Bilingual Speech: A Typology of Code-mixing, Muysken, 2000.)
In this study
A : represents Bahasa Indonesia
a : shows words in Bahasa Indonesia with its own sentence structure B : represents English
From the figure 2.2, it can be seen a group of words from language A
(with language A‟s grammatical structure) is followed by group of words from
language B (with language B‟s grammatical structure) (Muysken, 2000). Therefore, it is possible for any bilingual or multilingual speaker to start speaking
one language and finish in another language. Muysken (2000) adds that from the
sociolinguistics point of view, alternation should be found in „stable bilingual
communities with a tradition of language separation‟.
3)Congruent Lexicalization
In describing this type, Muysken (2000) says that congruent
lexicalization appears where there is a largely shared structure, lexicalization by
elements from either language. Moreover, Cantone (2007) adds that congruent
lexicalization is the type of mixing, which calls for social-linguistic constraint. It
involves material from different lexicons in a grammatical structure which is said
to be shared.
To be more understandable, Cantone (2007) takes example of English
and German mixing as follows: “Her Grandma is a typical familienmensch.” In
English, this utterances means “Her Grandma is a typical family person.” This
case belongs to congruent lexicalization since there is shared structure of English
and German in the word ”familiennmensch.” Cantone (2007) adds that this example involving two languages, English and German which are basically
similar with respect to grammatical structures. Thus, congruent lexicalization can
Cantone (2007) says “Congruent lexicalization is said to be found
among bilinguals with related languages as dialect/standard or post-creole.”
Muysken (2000) says that the term congruent lexicalization refers to a situation
where the two languages share a grammatical structure which can be filled
lexically with elements from either language. The explanation is represented in
figure 2.3 below.
A/B
…a… …b… …a… …b…
Figure: 2.3 Congruent Lexicalization (Bilingual Speech: A Typology of Code-mixing, Muysken, 2000.)
In this study
A : represents Bahasa Indonesia a : shows words in Bahasa Indonesia B : represents English
b : shows English words
In conclusion, the researcher believes that code-mixing is a case where
two elements of two languages are found in one utterance or a sentence. Based on
the previous explanation, it can be said that people can mix their language in one
utterance, but people cannot obey that code-mixing related to the grammatical
structure of a language. The researcher concludes that insertion is code-mixing
between words, alternation is code-mixing between clause, and congruent
lexicalization is code-mixing which share grammatical structure in one sentence.
in the speech of adults as observed in this study. Therefore, code-mixing is
possible to be found in adults‟ speech such as debates.
3. Debate
As stated by Freely (1969), debate is ubiquitous in our society at
making level. Moreover, the debate is a method of rational
decision-making and debate consists of arguments for against to a given proportion. Freely
(1969) also states that a debate will help us to make rational decisions and to
secure rational decisions from others.
According to Freely (1969), there are two kinds of debate; substantive
debate and educational debate. Substantive debate is conducted on propositions in
which the advocates have a special interest. The purpose of this debate is to
establish a fact, value or a policy. Besides, educational debate is conducted on
propositions in which the advocates usually have an academic interest. The
purpose of this debate is to provide educational opportunities for the participants.
Freely (1969) adds there are four kinds of debates inside the substantive
debate; special debate, judicial debate, parliamentary debate, and non-formal
debate. Special debate is a debate which is conducted under special rules and
drafted for a specific occasion. Judicial debate is a debate which is conducted in
the law court or before quasi-judicial bodies. Parliamentary debate is a debate
which is conducted under the rules of parliamentary procedure. Then, non-formal
4. Presidential Debate
Based on General Election Commission websites, presidential candidate
debate is a debate which is conducted once in a five time before the Election Day
by the General Election Commission. The first presidential candidate debate was
held on 2009. According to the Freely‟s theory (1969), the presidential candidate debate is included in the substantive debate that is parliamentary debate. It is
included in parliamentary debate because it has parliamentary procedure and its
own constitution.
Presidential candidate debate has its own regulations that regulate the
debate as a part of the campaign. According to a constitution number 42, article
38 of 2008 debate is a part of the campaign that the candidate did before the
Election Day. This article said that the presidential candidate campaign is
implemented through debate. Moreover, the article 39 from constitution number
42 regulated the technique of the debate. It is said that the debate is held by
General Election Commission in five times and it is broadcasted on national
television. The moderator of the debate is chosen by General Election
Commission. During and after the debate the candidate, moderator cannot give
any comment and conclusion about the material which is told by the candidate.
B.Theoretical Framework
In order to conduct the research, the researcher should look for some
theories which are appropriately used for the research. These theories support her
in solving the problem formulation. This section will be divided into two parts.
Each of the part provides explanation about the contribution of the theories in
answering the research problem.
Firstly, this research focuses on code-mixing, which occur in a
presidential candidate debate. In order to know the nature of the presidential
candidate debate, the researcher used information from the General Election
Commission. According to the constitution, the debates held for five times with
different themes. Consequently, the researcher took all of the debates to take the
data. Since the focus of the debate was only for the presidential candidate debate
2014, the researcher only focused on the five debates of presidential candidate
debate 2014. Since all data were taken from the videos, the researcher took the
data based on the way participants pronounced the words.
Secondly, to recognize the concept of code-mixing, the researcher used
the theory from Singh (1985) in Romaine‟s work (1995) states that code-mixing refers to intra-sentential code-switching. To solve the research problem about
types of code-mixing, the researcher combines the theories from Muysken (2000)
about the types of code-mixing to solve the problem. There are three types of
code-mixing; alternation, insertion, and congruent lexicalization. Alternation is
sentence. Meanwhile, insertion is the types of code-mixing where a word from
language A is embedded into language B in one sentence. Moreover, congruent
lexicalization is the types of code-mixing where there are two languages which
20
CHAPTER III
RESEARCH METHODOLOGY
This chapter presents the method of the study to solve the problem which
is stated in chapter I. This study intended to observe the code-mixing, which is
made by the participants of presidential candidate debate. This chapter presents
the discussion of research method, research setting, research participants,
instruments and data gathering, data analysis technique, and the last is a research
procedure.
A. Research Method
The researcher used qualitative research for this research. Qualitative
research is an approach to the study of social and behavioral phenomena (Ary, D.,
Jacobs, L. C., & Razavieh, A. 2002). In addition, the goal of this research is a “holistic picture and depth understanding, rather than a numeric analysis of data”
(Ary et al., 2002). Qualitative research and quantitative research are different.
According to Fraenkel and Wallen (2008), one of the differences is a qualitative
researcher collects the data in a form of words or pictures and seldom involve
numbers. Therefore, to analyze the data in a form of words, the researcher used
observation sheet and document. The researcher used observation sheet and the
transcript of the debates since it was difficult to interview the participants.
According to Fraenkel and Wallen (2008), content analysis is a primary method of
Fraenkel and Wallen (2008) say that content analysis is a technique that
enables researchers to study human behavior in an indirect way, through an
analysis their communications. The source of data can be from textbooks, essays,
newspapers, novels, magazines, cookbooks, songs, political speeches,
advertisement, and pictures. In this study, the sources of the data are videos of
presidential candidate debates 2014. The researcher did not record the videos by
herself, but she took it from www.youtube.com.
Furthermore, content analysis is a research method that uses a set of
procedures to make valid inferences from text (Weber, 1990). Moreover, Leedy
and Ormrod (2005) state, that content analysis is a detailed and systematic
examination of the content of a particular body and it typically performed on
forms of human communication. This method would support the researcher to
answer the problems which are stated in chapter I.
While conducting the research, the researcher used two kinds of content
analysis method. They were manifest content of communication and latent content
of a document. Faenkel and Wallen (2008) explain that a manifest content of
communication refers to the surface of the words, pictures, and images which
accessible to the naked eye or ear. Using the manifest content of a
communication, the researcher can find the types of code-mixing which is made
by the participants.
B. Research Setting
Presidential candidate debate is an event which is held by General Election
Day. The function of this debate is to tell the citizens about their mission and
vision. In 2009, there were three participants who joined the debate. There were
SBY, JK, and MSP who were included in the debate in 2009. In 2014, there were
four participants who were divided into two groups. The first group is the first
candidate in a presidential election PS and his running mate HR. The second
group consists of JW and his running mate JK.
The case of this research is the presidential candidate debates 2014 which
was held five times in June up to July. The first debate was held on Monday 9th of
June 2014, the second debate was held on 15th of June 2014, the third debate was
held on 22nd of June 2014, the fourth debate was held on 29th of June 2014, and
the last debate was held on 5th of July 2014. This program was aired on some
National television channels. In this thesis, the researcher took five videos of the
presidential candidate debate which came from all of the debates parts.
The researcher started downloading the videos on July 2014 and analyzed
them for the following months. The researcher could conduct the research
effectively, which means she could conduct the research in any place and time in
which required supports and equipment are available.
C. Research Participants
The subjects of this research are the participants of the presidential
candidate debates 2014. They were PS and his running mate HR the first
candidate in the presidential election. JW and his running mate as the second
candidate of the presidential election JK. All of them have different educational
language competency. This different background, language competency would
give significant influence to their speaking production. In giving their arguments,
they tend make code-mixing during the debate. It attracted the researcher’s to
conduct the research of code-mixing which are made by the participants. Between
the participants and the moderator tend to make code-mixing. However, the
researcher only focused on the code-mixing which are made by the participants
since they had the same role in that event. Therefore, it would be easier to
compare the speaking production from each participant.
D. Instrument and Data Gathering
In this research, the researcher was provided with a checklist. A checklist
was used to analyze whether the code-mixing made by the participants belonged
to alternation, insertion or congruent lexicalization.
Since the researcher conducted qualitative research where the researchers
are able to interpret and make sense of any social phenomenon (Leedy and
Ormrod, 2005), she was considered as the primary instrument. Moreover, Leedy
and Omrod (2005) suggest, “The researcher is an instrument in much the same
way that sociogram, raring scale or intelligence test in an instrument” (p. 133).
With the aim of getting the data about code-mixing which are made by the
participants, the researcher took five videos of the debate and made the
E. Data Analysis Technique
After collecting the data, the researcher started to analyze the data.
Creswell (1998) as cited by Leedy and Ormrod (2005) say that the data analysis
for qualitative research is using spiral data analysis. There are four steps in the
data analysis spiral as follows:
1. Organization
Creswell (1998), as cited by Leedy and Ormrod (2005), describes that the
researcher must break down a large body of the text into smaller units in the form
of a sentence or individual words. Therefore, the researcher searches the
utterances which contained the code-mixing in the transcription of the debate.
Then she made the list of the results as shown in the analysis of code-mixing
table.
2. Checking
In this step, the researcher should re-read the data carefully to check
whether she had done accurate analysis or not. According to Cresswell (1998), as
cited by Leedy and Ormrod (2005), check the entire data set several times to get a
sense of what it contains as a whole. By reread and recheck the data, the
researcher could find the incorrect parts and make a correction on it. This step
helped the researcher to make the data more valid and reliable.
3. Classification
According to Cresswell (1998), as cited by Leedy and Ormrod (2005), the
researcher should identify the general categories or themes and perhaps
accordingly. In this research, the researcher classified the utterances which
contain code-mixing into which types. Therefore, the particular utterances that
contain mixing should be given a checklist mark in particular types of
code-mixing.
4. Synthesis
After the researcher finished identifying the code-mixing, which is made
by the participants in the debate, she had to summarize and integrate the data. To
make it clearer and more understandable, she made it to the table and matrix. It
shows the important points which are discussed by the researcher.
F. Research Procedure
This section would explain the procedures that the researcher did in
conduction the research. The research was conducted in six steps:
1. Making the Transcription of Each Video
Before the researcher makes the transcription, the researcher took and
downloaded five videos of the debates from Youtube.com. The researcher downloaded the full version of the debates. The researcher used an application
from website, namely www.otranscribe.com for transcribing the debates. Those videos contained the utterances from the participants, which contain code-mixing.
Those videos were shown in the table 3.1.
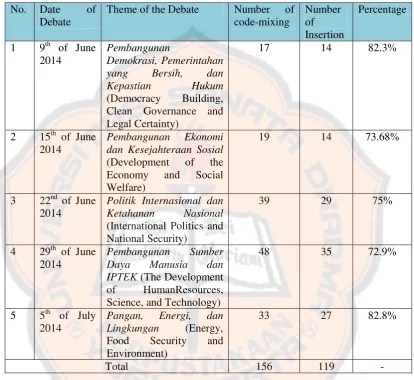
Table 3.1: The Topic List of Presidential Candidate Debate
No. The theme of the debate Date of the debate
1 Pembangunan Demokrasi, Pemerintahan yang Bersih, dan Kepastian Hukum (Democracy Building, Clean Governance and Legal
No. The theme of the debate Date of the debate
Certainty)
2 Pembangunan Ekonomi dan Kesejahteraan Sosial (Development of the Economy and Social Welfare)
June 15, 2014
3 Politik Internasional dan Ketahanan Nasional
(International Politics and National Security)
June 22, 2014 4 Pembangunan Sumber Daya Manusia dan
IPTEK (The Development of HumanResources, Science, and Technology)
June 29, 2014
5 Pangan, Energi, dan Lingkungan (Energy, Food Security and Environment)
July 5, 2014
The researcher downloaded five videos, then made the transcription of
each videos in order to collect the data. She watched the videos carefully to make
good transcription. It took two months to make the transcription. As stated before,
the reseacher used an application from website namely www.otranscribe.com. The
application is equipped with shortcuts buttons as a tool to make the transcription.
The shortcuts are on the keyboard such as esc, F1, F2, and ctrl+j. To play the videos, the researcher used the button esc on the keyboard. Then the button F1 is
used to make the videos play slower. While F2 is used to make the videos play faster. Last, the button ctrl+j is used to insert the current timestamp. With those shortcuts on her keyboard, the researcher was eased to make the transcription. She
wrote every single word which is spoken by the participants and the moderator.
The transcription would not only as the tool in analyzing the data, but also assist
2. Listing the sentences which contained Code-mixing utterance
Through the transcriptions, the researcher had to list code-mixing
utterances in order to complete the data analyzing. She picked all the utterances
which contain code-mixing.
3. Checking the words in Indonesian dictionary
After the researcher got all the utterances which contain code-mixing she
started to check the English words in the dictionary. She checked the English
words are not loan words from English to Indonesian. The researcher checked the
Indonesian dictionary (Kamus Besar Bahasa Indonesia) to find it out. Then the
researcher found the words such as credible, problem, export, import, and
management etc. as the loan words. The researcher omitted the utterances which
had those words and did not make them as the data.
4. Classifying the types of Code-mixing
The list of mixing utterances was identified to which types of
code-mixing. The researcher should put the checkmark in the A column if that utterance
belongs to the alternation type, in column B if that utterance belongs to the
insertion type and in column C if that utterance belongs to the congruent
lexicalization. Through the identification, the data would help the researcher in
understanding the code-mixing phenomenon in presidential candidate debate.
5. Analyzing the Data
Then, the researcher should analyze the tendency of code-mixing, which
occurs in a presidential debate. To find out the amount of the data and the
the most in the presidential debate. Then, researcher counted the percentage of
each type of code-mixing by using this formula:
1. P= 2. P= 3. P= Note:
P = the percentage
NA = the number of alternation NI = the number of insertion
NCL = the number of congruent lexicalization T = the total of code-mixing
The researcher would compare the occurrences of the code-mixing, which
is made by participants in the debate. From the comparison, the researcher
observed, which types of code-mixing got the highest number.
6. Drawing the Conclusions
The last step in this research was drawing the conclusion based on the
findings. It would give a clearer description as the answer to the problem
29
CHAPTER IV
RESEARCH RESULTS AND DISCUSSION
This chapter will discuss the findings of the research. The findings will be
discussed to solve the problem formulations. Since there are two questions, so it is
divided into two main sections. The first is about the types of code-mixing made
by the participants. Then the second is about the functions of code-mixing, which
is also made by the participants of the presidential debate 2014. The researcher
uses the theories from chapter II to reveal the answer to the problem.
A. Findings
In this part, the researcher would like to present the findings of the
research which were gathered from the checklist sheet. Previously, the researcher
will explain about the consideration of the meaning of code-mixing. The
researcher refers to Singh‟s theory (1985) which is cited by Romaine (1995) that
code-mixing is an intra-sentential code-switching. According to Holmes (1992),
intra-sentential switching here means switching that occurs within one sentence.
Moreover, McCormick (1995) suggests that code-switching involves the
alternation of elements longer than one word while code-mixing involves shorter
elements, often just a single word. In addition, Alabi (2007) states that the
code-mixing is often unconscious illocutionary act in naturally occurring conversation
(as cited in Oladosu, 2011). Therefore, the researcher concludes that the
utterances. It can occur in short utterances like one word and it is often a
spontaneous or unconscious illocutionary act in a conversation.
In order to understand more about code-mixing, which is made by the
participants, the researcher collected the data by using the checklist sheet.
Checklist sheet here is a part of the instruments from the content analysis method.
In order to dig deeper about the types of code-mixing, the researcher uses the
manifest content of a communication. Fraenekel and Wallen (2008) say that it
analyzes the surface of the words, pictures, and images which is accessible to the
naked eye or ear. The researcher uses it because it is very clear that the
participants did code-mixing while they are debating.
This research focused on the code-mixing utterances which are made by
the debate‟s participants. Then, the code-mixing is only focused on English –
Bahasa Indonesia utterances. The participants of the debate were: PS, HR, JW and JK. The researcher took five videos because every video has little examples of
code-mixing. The total cases of the code-mixing, which is made by the each
participant in the first debate would be presented in table 4.1.
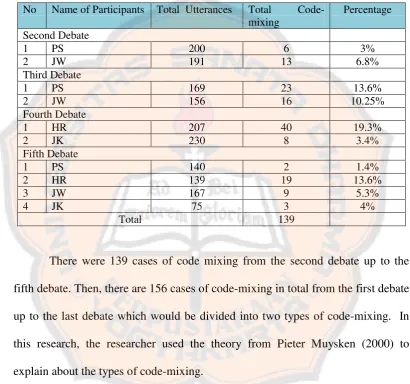
Table 4.1 Total of code-mixing cases in the first debate
No Name of Participants Total Utterances Total Code-mixing
Percentage
1 PS 136 4 2.94%
2 HR 56 5 8.92%
3 JW 103 5 4.85%
4 JK 111 3 2.70%
From the table above, it can be concluded that the cases of code-mixing from the
first debate is too little to be taken as examples in this research. Therefore, the
code-mixing cases from the second debate up to fifth debate will be presented in
table 4.2.
Table 4.2 Total and Percentage of code-mixing cases in the second up to fifth debate
No Name of Participants Total Utterances Total Code-mixing
Percentage Second Debate
1 PS 200 6 3%
2 JW 191 13 6.8%
Third Debate
1 PS 169 23 13.6%
2 JW 156 16 10.25%
Fourth Debate
1 HR 207 40 19.3%
2 JK 230 8 3.4%
Fifth Debate
1 PS 140 2 1.4%
2 HR 139 19 13.6%
3 JW 167 9 5.3%
4 JK 75 3 4%
Total 139
There were 139 cases of code mixing from the second debate up to the
fifth debate. Then, there are 156 cases of code-mixing in total from the first debate
up to the last debate which would be divided into two types of code-mixing. In
this research, the researcher used the theory from Pieter Muysken (2000) to
explain about the types of code-mixing.
The last type of code-mixing is congruent lexicalization. This type is
different with two other types. In this type, the two languages share the grammar
structure in one sentence. Unfortunately the last type of code-mixing called as
congruent lexicalization cannot be found in this research since there were no
B. Discussion of the Types of Code-mixing
According to Muysken (2000), there are three types of code-mixing. The
first type is called as an insertion; the researcher concluded it as code-mixing
which happened between words. The second type is called as alternation; the
researcher concluded it as code-mixing between clauses. Then, the last called as
congruent lexicalization, this type is different because it shares grammatical
structures from more than one language. In each type, the researcher also
presented the finding in five videos of presidential candidate debates.
1. Insertion
The first type of code-mixing is insertion. According to Musyken (2000),
insertion is code-mixing where the languages may be combined within a syntactic
unit that language A is dominant and language B is inserted into grammatical
frame defined by language A. The researcher concludes it as code-mixing where a
word in language B is inserted in language A. In this research the dominant
language is Bahasa Indonesia and the inserted language is English.
The researcher got the data after classifying the code-mixing utterances
based on the types. For instance, in the first debate there were 17 cases of code
mixing. Then the researcher divided it into three types of code-mixing; insertion,
alternation, and congruent lexicalization. Then the researcher found that in the
first debate, there were 14 cases of insertion code-mixing. The researcher did the
same for the rest of the videos and the number of cases would be presented in
Table 4.3 Number of Insertion Cases
The first debate which was conducted on the 9th of June 2014 with theme
Pembangunan Demokrasi Pemerintahan yang Bersih Dan Kepastian Hukum (Democracy Building, Clean Governance, and Legal Certainty) got 14 cases of
insertion which means there is 82.3% case of the total code-mixing cases. Some
findings can be seen from the table 4.4.
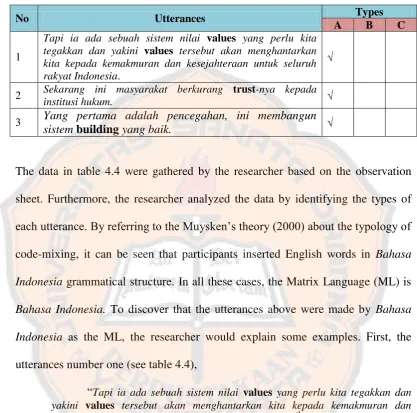
Table 4.4 List of Insertion on the First Debate
No Utterances Types
A B C
1
Tapi ia ada sebuah sistem nilai values yang perlu kita tegakkan dan yakini values tersebut akan menghantarkan kita kepada kemakmuran dan kesejahteraan untuk seluruh rakyat Indonesia.
2 Sekarang ini masyarakat berkurang trust-nya kepada
institusi hukum.
3 Yang pertama adalah pencegahan, ini membangun
sistem building yang baik.
The data in table 4.4 were gathered by the researcher based on the observation
sheet. Furthermore, the researcher analyzed the data by identifying the types of
each utterance. By referring to the Muysken‟s theory (2000) about the typology of
code-mixing, it can be seen that participants inserted English words in Bahasa Indonesia grammatical structure. In all these cases, the Matrix Language (ML) is Bahasa Indonesia. To discover that the utterances above were made by Bahasa Indonesia as the ML, the researcher would explain some examples. First, the utterances number one (see table 4.4),
“Tapi ia ada sebuah sistem nilai values yang perlu kita tegakkan dan yakini values tersebut akan menghantarkan kita kepada kemakmuran dan kesejahteraan untuk seluruh rakyat Indonesia.” (HR, 9th of June 2014)
“Nevertheless, there is a value system values that we need to run and believe which the values will deliver us to the prosperity and tranquility for all Indonesian citizens” (HR, 9th of June 2014)
There was an English noun „values‟ in this utterance which was identified as
Insertion with Bahasa Indonesia as the ML. Most of the code-mixing, which happened in the debate were insertion with Bahasa Indonesia as the ML. Another
“Kalau ada prestasi, berikan insentif, berikan reward kepada mereka.” (JW, 9th of June 2014)
“If there are achievements, give incentives, give rewards to them.” (JW, 9th of June 2014)
In the utterance above, there was an English noun „reward‟ which identified as
insertion and still Bahasa Indonesia as the ML. Moreover, in the first debate there
were a lot of insertions of English noun since the participants insert some English
nouns in their speech. In the first debate, JW produced a more code-mixing,
especially the insertion rather than the other participants.
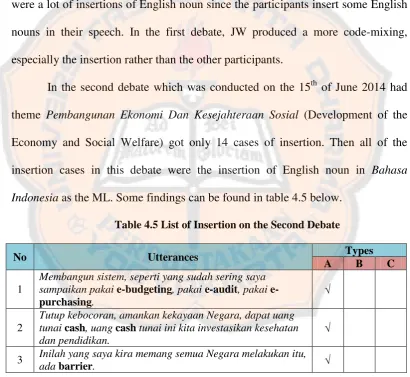
In the second debate which was conducted on the 15th of June 2014 had
theme Pembangunan Ekonomi Dan Kesejahteraan Sosial (Development of the Economy and Social Welfare) got only 14 cases of insertion. Then all of the
insertion cases in this debate were the insertion of English noun in Bahasa Indonesia as the ML. Some findings can be found in table 4.5 below.
Table 4.5 List of Insertion on the Second Debate
No Utterances Types
A B C
1
Membangun sistem, seperti yang sudah sering saya sampaikan pakai budgeting, pakai audit, pakai
e-purchasing.
2
Tutup kebocoran, amankan kekayaan Negara, dapat uang tunai cash, uang cash tunai ini kita investasikan kesehatan dan pendidikan.
3 Inilah yang saya kira memang semua Negara melakukan itu,
ada barrier.
The data from the table 4.5 was gathered from the checklist sheet of the second