Laporan Tugas Akhir MK. Metode Kuantitatif (KOM332), Semester Ganjil 2015/2016
Penerapan Teknik K-Means Clustering pada Online News
Popularity
MUHAMMAD ARIEF KALBU ADI (G64154030)*
PENDAHULUAN
Latar Belakang
Dokumen elektronik sangat mudah untuk ditemui, karena dengan mudah dapat diakses melalui smartphone. Dokumen ini dapat ditemui melalu mesin pencari google atau saat berselancar di Facebook. Tiap dokumen pun dapat dikelompokan pada suatu kategori.
Kemudahan mendapatkan dokumen diimbangi dengan kemudahan pembaca untuk melakun berbagi informasi. Tidak semua dokumen dari tiap kategori menarik untuk di shares. Pada penelitian kali ini akan menganalisis kategori mana saja yang paling banyak di shares. Untuk mengklusterkan dokumen-dokumen tersebut digunakan algoritme k-means.
Tujuan
Tujuan dari tugas akhir ini adalah :
1. Mengetahui adakah pengaruh dari tipe dokumen terhadap tingkat share
Ruang Lingkup
Ruang lingkup dari pengambilan data adalah:
1. Data yang digunakan merupakan data Online News Popular.
2. Kolom yang digunakan adalah data_lifestyle, data_entertainment, data_bus, data_socmed, data_tech, data_world, n_tokens_title n_tokens_content, num_keywords, dan shares.
3. Metode yang digunakan dalam mengolah data adalah klustering dengan algoritme k-means.
__________________
Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor, Bogor 16680
TINJAUAN PUSTAKA
Data Mining (Penggalian Data) didefinisikan sebagai sebuah proses untuk menemukan hubungan, pola dan trend baru yang bermakna dengan menyaring data yang sangat besar, yang tersimpan dalam penyimpanan, menggunakan teknik pengenalan pola seperti teknik statistik dan matematika (Poniah, 2001). Hubungan yang dicari dalam data mining dapat berupa hubungan antara dua atau lebih dalam satu dimensi, misalnya dalam dimensi produk, kita dapat melihat keterkaitan pembelian suatu produk dengan produk yang lain. Selain itu hubungan juga dapat dilihat antara 2 atau lebih atribut dan 2 atau lebih obyek (Pramudiono, 2006).
Classification adalah proses untuk menemukan model atau fungsi yang menjelaskan atau membedakan konsep atau kelas data, dengan tujuan untuk dapat memperkirakan kelas dari suatu objek yang labelnya tidak diketahui. Decision tree adalah salah satu metode classification yang paling populer karena mudah untuk diinterpretasi oleh manusia (Pramudiono, 2006).
METODOLOGI
Data
Data yang digunakan dalam tugas akhir ini adalah Online News Popular. Data
tersebut dapat diperoleh dari website data set
(https://archive.ics.uci.edu/ml/datasets/Online+News+Popularity). Data tersebut memiliki 61 atribut.
Tahapan Kegiatan
Tahapan dalam melakukan analisis data terdiri atas 5 tahapan. Tahapan tesebut yaitu data selection, data pre-processing, transformation, data mining, dan evaluasi. Tiap tahapan akan menghasilkan keluaran yang dibutuhkan pada tahap selanjutnya.
1. Data Selection
Memilih kolom-kolom pada data dalam format .csv. Data dari hasil seleksi yang digunakan untuk memproses data disimpan dalam format .txt.
2. Data Pre-Processing
Setelah data diseleksi maka selanjutnya dilakukan praproses data tersebut. Praproses data terdiri atas mengkodekan tiap kategori kedalam kode unik dan menghapus pencilan.
3. Transformation
4. Data Mining
Menganalisis data hasil dari klustering pada setiap kategori dokumen terhadap jumlah share.
5. Interpretation/Evaluation
Setelah mendapatkan data mining tersebut, data akan kembali direpresentasikan ke dalam bentuk tabel agar lebih mudah untuk dibaca.
HASIL DAN PEMBAHASAN
Data Selection
Data yang digunakan adalah data yang diambil dari situs data set. Data yang
diambil berjudul ‘Online News Popular’. Pada data awal, atribut terdiri atas 61 atribut. Atribut yang akan digunakan sebanyak 10 atribut, yaitu data_lifestyle, data_entertainment, data_bus, data_socmed, data_tech, data_world, n_tokens_title n_tokens_content, num_keywords, dan shares. Data mentah yang sudah terkumpul sebanyak 100 records dan 10 atribut. Dari data mentah tersebut beberapa atribut hanya merepresentasikan data dalam bilangan biner sehingga diperlukan praproses data.
Data Pre-Processing
Pada tahap ini, beberapa atribut digabungkan menjadi satu atribut. Penggabungan ini didasarkan bahwa setiap data dalam atribut yang digabungkan tersebut berbentuk biner. Atribut-atribut yang akan digabungkan tersebut sebanyak 6 yaitu data_lifestyle, data_entertainment, data_bus, data_socmed, data_tech, dan data_world. Dari 6 atribut tersebut diperkecil menjadi 1 atribut.
Data pada atribut data_lifestyle, data_entertainment, data_bus, data_socmed, data_tech, dan data_world diberikan kode unik, atribut data_lifestyle diberi nilai 1, atribut data_entertainment diberi nilai 2, atribut data_bus diberi nilai 3, atribut data_socmed diberi nilai 4, atribut data_tech diberi nilai 5, dan atribut data_world diberi nilai 6. Setelah data pada atribut - atribut tersebut sudah dikodekan, tahap selanjutnya adalah menggabungkan ke 6 atribut tersebut menjadi 1 kolom, kolom ini diberi nama Data_Kategori.
Hasil penggabungan atribut ini menghasilkan data yang tidak terdefinisi. Data ini tidak berada di 6 atribut . Pada data ambigu ini diasumsikan mewakili 1 kategori dokumen yaitu uncategory atau dokumen yang tidak memiliki kategori secara spesifik. Hasil penggabungan atribut ini dapat dilihat pada Tabel 1.
Pada tahap yang sama, dihapus pencilan pada data shares. Data pencilan yang dihapus adalah data pencilan dengan rentang atau selisih 4000 terhadap data sebelumnya. Hasil akhir dari tahap ini menghasilkan 5 atribut, yaitu Data_Kategori, n_tokens_title, n_tokens_content, num_keywords, dan shares, serta mendapatkan 98
Tabel 1 Hasil Pengkodean Kategori Dokumen
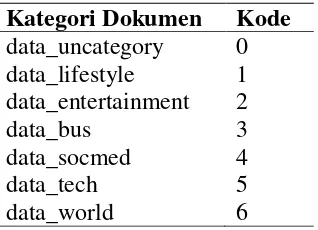
Kategori Dokumen Kode
data_uncategory 0 data_lifestyle 1 data_entertainment 2
data_bus 3
data_socmed 4
data_tech 5
data_world 6
Transformation
Setelah dilakukan praproses data maka data ditransformasikan ke bentuk yang sesuai untuk k-means. Data dikonversi formatnya menjadi file .txt untuk bisa digunakan dan diolah dalam RStudio. Berdasarkan pengolahan data yang dilakukan RStudio, berikut adalah hasil dari proses data menggunakan algoritme k-means dan Tabel 2 merupakan hasil dari klustering:
1 data1 <- read.delim("D:/KALBU/KULIAH/METKUAN/PROJECT/dataLatih.txt") 2 (kmeans.result <- kmeans(data1, 3, iter.max = 200, nstart = 1)) 3 table(data1$Data.Kategori ,kmeans.result$cluster)
4 table(data1$Data.Kategori ,kmeans.result$cluster)
Tabel 2 hasil klustering pada tiap kategori dokumen
1 2 3
0 3 13 1
1 0 2 1
2 0 16 1
3 1 11 0
4 0 5 0
5 3 8 1
6 6 26 0
Data Mining
Pada tabel diatas menunjukan bahwa kluster 2 menjadi kluster yang paling banyak. Setiap data pada kategori dokumen hampir seluruhnya masuk dalam kluster 2. Kluster 2 merupakan cluster dengan jumlah shares rata-rata 1404. Ini berarti suatu kategori dokumen tidak mempengaruhi jumlah share yang akan dibagi. Karena pada kluster 2 merupakan kluster dengan tingkat share lebih rendah dari kluster yang lain.
Pada kluster 1, kategori dokumen 6 lebih banyak masuk pada kluster ini dari pada kategori dokumen lainnya. Tetapi, keseluruhan jumlah data pada kategori 6 adalah sebanyak 32, dan hanya 6 yang masuk pada kluster ini. Ini berarti persentase kategori 6 masuk ke klustering 1 sangat kecil, sekitar 18%. Berbeda dengan kategori dokumen 5, pada kategori ini, jumlah data yang masuk pada kluster 1 sebanyak 3 dari total data 8. Ini merupakan persentase terbesar dari seluruh kategori dokumen pada kluster 1, yaitu sebesar 37%.
Pada data kategori dokumen 5 pun terdapat data yang masuk dalam kluster 3. Walau jumlahnya kecil, yaitu 1, namun ini lebih baik dibandingkan kategori dokumen lain. Pada kluster 3 ini pun, data kategori 1 masuk dalam kluster ini. Data kategori 1 hanya memiliki 3 data, yang berarti perbedaan antara data sangat jauh. Jenis kategori dokumen 1 bisa mendapatkan share dengan kluster 1, yang berarti cukup atau masuk dalam kluster 3 yang berarti tingkat share nya sangat tinggi.
Interpretation/Evaluation
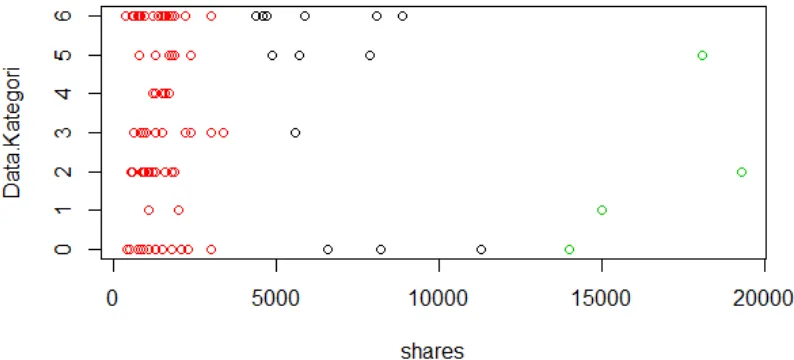
Pada tahap ini data hasil klustering diplotkan pada diagram plot. Hal ini bertujuan untuk mempermudah penggambaran hasil analisis pada tahapan data mining. Diagram plot yang dihasilkan dapat dilihat pada gambar 1
Gambar 1 Diagram plot hasil klustering
KESIMPULAN DAN SARAN
Dari database yang telah diperoleh dan dilakukan metode klustering dengan algoritme k-means. Hasil dari klustering menunjukan bahwa tidak ada kategori dokumen yang sangat mendominasi tingkat share paling tinggi. Namun, kategori dokumen 5 memiliki tingkat share yang secara data aman. Kategori dokumen 5 ini cenderung menyebar tiap kluster dan perbandingan data tiap kluster tidak terlalu berbeda jauh.
DAFTAR PUSTAKA
Ponniah, P., 2001. Datawarehouse Fundamentals : A comprehensive Guide for IT Professional. John Willey & Sons. Inc.