JENIS TIPE JANGKAUAN SUARA PADA PRIA DAN WANITA
MENGGUNAKAN METODA MEL-FREQUENCY CEPSTRAL COEFFICIENT
DAN JARINGAN SYARAF TIRUAN BACKPROPAGATION
Inung Wijayanto1), Reni Dwifebrianti2)
1,2) Fakultas Elektro dan Komunikasi, Insitut Teknologi Telkom Bandung
1)
[email protected], 2) [email protected]
Abstract: Human voice is one of the important thing in playing music. Human have different types of voices which can be classified into two classes, man and woman voice. Types of man voices are tenor, baritton and bass while woman voices are sopran, mezzo-sopran and alto. Generally, to determine the human voice type is done by the help of musical instrument, such as piano. In order to make a system which can detect the human voice, the first step is done by doing a feature extraction from the human voice using the Mel-Frequency Cepstral Coefficient. From the feature extraction, we can get the characteristics of the human voice. Besides, it also can give the information to differenciate the gender of the voice. Pitch information is also used to support the gender classification process. For the classification, a Backpropagation Neural Network is used. The testing result show that the detection system can detect woman voice type with 100% accuracy, while for the man voice is 95,47% accuracy. The detection for voice type are Alto 82,23%, Sopran 75%, Bass 97,56% and Tennor 73,45% .
Keywords: voice type, mel-frequency cepstral coefficient, backpropagation neural network 1. Pendahuluan
Musik sudah menjadi bagian yang tak terpisahkan dari kehidupan manusia. Banyak hobi yang berkaitan dengan musik, mulai dari hobi bermain instrumen sampai dengan hobi olah suara atau menyanyi. Dalam teori musik, manusa memiliki tipe suara yang berbeda-beda baik pria maupun wanita. Tipe suara pada pria dibagi menjadi tenor, bariton dan bass. Sedangkan pada wanita terbagi menjadi sopran, mezzo-osopran dan alto. Bagi orang awam yang baru belajar, biasanya akan mengalami kesulitan dalam menentukan tipe suara mereka. Dalam proses penentuan tipe suara, biasanya dilakukan dengan cara manual yaitu dengan menggunakan bantuan alat musik, umumnya piano, oleh seorang ahli atau pelatih vokal. Untuk membantu proses ini dibuatlah sebuah sistem pendeteksi dengan memanfaatkan teknologi pengolahan sinyal digital.
2. Dasar Teori
2.1 Mekanisme Produksi Suara
Produksi suara manusia memerlukan tiga elemen, yaitu sumber daya, sumber suara dan pemodifikasi suara. Ini adalah dasar dari teori source-filter pada produksi sinyal bicara. Sumber daya pada sinyal suara normal dihasilkan dari gerakan kompresi otot paru-paru. Sumber suara, selama sinyal voiced dan unvoiced, merupakan hasil dari getaran masing-masing pita suara. Pemodifikasi suara adalah artikulator, yang merubah bentuk vocal tract sehingga karakteristik frekuensi rongga akustik melewati apa yang dilalui suara.
Tiga kontrol utama pada produksi suara adalah paru-paru (sumber daya), posisi pita suara (sumber suara), dan bentuk
vocal tract (pemodifikasi suara). Vocal tract terdiri dari pharynx (koneksi antara esophagus dengan mulut) dan mulut. Nasal tract mulai dari bagian belakang langit-langit dan berakhir pada nostrils.
Gambar 2-1 Diagram Blok Produksi Suara Manusia[5]
Gambar 2.1 memperlihatkan model sistem produksi ucapan manusia yang disederhanakan. Pembentukan ucapan dimulai dengan adanya hembusan udara yang dihasilkan oleh paru-paru. Cara kerjanya serupa seperti piston atau pompa yang ditekan untuk menghasilkan tekanan udara. Pada saat vocal cords berada dalam keadaan tegang, aliran udara akan menyebabkan terjadinya vibrasi pada vocal cords dan menghasilkan bunyi ucapan yang disebut voiced sound. Pada saat vocal cord berada dalam keadaan lemas, aliran udara akan melalui daerah yang sempit pada vocal tract dan menyebabkan terjadinya turbulensi, sehingga menghasilkan suara yang dikenal dengan unvoiced sound
2.2 Tipe Suara[12]
Tipe suara adalah berbagai jenis suara yang diklasifikasikan menggunakan kriteria tertentu. Klasifikasi suara adalah proses dimana suara manusia dinilai, kemudian akan digolongkan menjadi tipe-tipe suara tertentu. Ada banyak perbedaan tipe suara berdasarkan berbagai macam sistem klasifikasi. Berikut ini jangkauan vokal sesuai dengan tipe suara dan representasinya dalam frekuensi berdasarkan scientific pitch notation:
Tabel 2.1 Jangkauan Frekuensi Tiap Tipe Suara[12]
Gender Tipe Suara Range Vokal Frekuensi
Range Vokal (Hz) Frequensi Fundamental (Hz) Pria Tenor C3 –C5 130.813 - 523.251 16.35 Bariton F2 – F4 87.3071 - 349.228 21.80 Bass E2– E4 82.4069 - 329.628 20.60 Wanita Soprano C4–A5 261.626 - 1046.50 16.35 Mezzo-Soprano A3–A5 220.000 - 880.000 27.50 Alto F3 – F5 174.614 - 698.456 21.80
2.3 Mel-Frequency Cepstral Coefficient
MFCC merupakan representasi terbaik dari analisis timbre sebagai metode ekstraksi ciri yang merupakan salah satu
feature dari sinyal suara. Pada MFCC, frekuensi bands diposisikan secara logaritmik yang mendekati respon dari sistem
pendengaran manusia.[13]
Secara umum langkah-langkah untuk menghitung MFCC adalah sebagai berikut:[4][6] a. Pre-emphasize Filtering
Filter ini mempertahankan frekuensi-frekuensi tinggi pada spektrum yang tereliminasi saat proses produksi suara. Filter pre-emphasis dapat dihitung dengan persamaan:
dimana 0.9 < α < 1. b. Frame Blocking
Frame blocking digunakan untuk memotong-motong sinyal suara menjadi beberapa frame agar dapat diproses secara short-time untuk memperoleh karakter frekuensi yang relatif stabil.
c. Windowing
Windowing dilakukan untuk mengurangi efek aliasing atau sinyal tak kontinyu pada awal dan akhir masing-masing frame yang dapat terjadi akibat proses frame blocking. Window yang biasanya digunakan adalah Hamming. Berikut
ini persamaan window Hamming:
( ) dengan N adalah jumlah sampel dalam masing-masing frame. d. FFT
FFT digunakan untuk mengkonversi masing-masing frame sinyal suara dari domain waktu ke domain frekuensi. Dalam sinyal bicara, sistem pendengaran sangat sensitif terhadap karakteristik frekuensi sehingga sinyal bicara lebih mudah dianalisis pada domain frekuensi. Perhitungan FFT didefinisikan pada kumpulan N sampel {X} sebagai berikut:
∑
, n = 0,1,2,..., N-1, x(n)= deretan sinyal aperiodik dengan nilai N dan N = jumlah
sampel.
e. Mel Frequency Wrapping
Sinyal bicara terdiri dari nada dengan frekuensi yang berbeda-beda. Untuk masing-masing nada dengan frekuensi aktual, f, diukur dalam Hz, pitch subjektif diukur dengan skala ‘mel’. Skala mel-frequency bersifat linier untuk frekuensi di bawah 1000 Hz dan logaritmik untuk frekuensi di atas 1000 Hz. Pendekatan persamaan untuk menghitung mel dalam frekuensi f (Hz) adalah: ( ) dengan f adalah frekuensi linier.
f. Discrete Cosine Transform (DCT)
Pada langkah terakhir, spectrum log mel harus dikonversikan kembali menjadi domain waktu menggunakan Discrete
Cosine Transform, hasilnya disebut mel frequency cepstral coefficients (MFCCs). MFCC dapat dihitung dengan
persamaan ∑ ( ( ) )
Sk = Keluaran dari proses filterbank pada indeks k K = Jumlah koefisien yang diharapkan
2.4 Penentuan Pitch Dengan Analisis Cepstrum
Teori dasar dari metode ini berpedoman pada fakta bahwa Transformasi Fourier sebuah sinyal biasanya mempunyai sejumlah puncak yang teratur yang merepresentasikan harmonic spectrum sinyal. Saat log magnitude dari spectrum diperoleh, nilai dari puncak tersebut direduksi. Hasilnya adalah bentuk sinyal periodik pada domain frekuensi, dimana periodenya berhubungan dengan frekuensi fundamental sinyal asli. Metode ini dikembangkan untuk penggunaan dengan sinyal bicara.[3] Cepstrum dapat diperoleh menggunakan persamaan [ | | ]
Pada cepstrum, memungkinkan adanya pemisahan representasi koefisien vocal tract (low indices) dan koefisien pembawa informasi pada frekuensi fundamental, pitch (high indices). Pitch bisa diprediksi dengan mengidentifikasi nilai maximum dari c(m).[2]
2.5 Jaringan Syaraf Tiruan Backpropagation
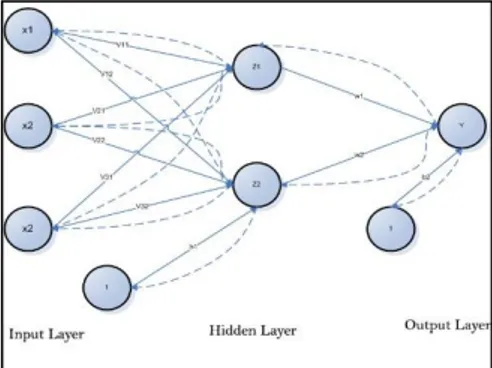
Jaringan Syaraf Tiruan Backpropagation memiliki beberapa unit yang ada dalam satu atau lebih layar tersembunyi. Gambar 2-2 adalah arsitektur Backpropagation dengan 3 buah masukan (ditambah sebuah bias), sebuah layar tersembunyi yang terdiri dari 2 unit (ditambah sebuah bias), serta 1 buah unit keluaran. vij merupakan bobot garis dari unit masukkan xi ke unit layar tersembunyi zj (vij merupakan bobot garis yang menghubungkan bias di unit masukan xi ke unit layar tersembunyi Zj ). Wj merupakan bobot dari unit layar tersembunyi zj ke unit keluaran y (wj merupakan bobot dari bias di layar tersembunyi ke unit keluaran zj)
Gambar 2-2 Arsitektur JST Backpropagation 2.5.1 Fungsi aktivasi
Dalam Backpropagation, fungsi aktivasi yang dipakai harus memenuhi beberapa syarat yaitu : kontinu, terdiferensial dengan mudah dan merupakan fungsi yang tidak turun. Salah satu fungsi yang memenuhi ketiga syarat tersebut sehingga sering dipakai adalah fungsi sigmoid biner yang memiliki range (0,1)..
( )
Fungsi lain yang sering dipakai adalah adalah fungsi sigmoid bipolar yang bentuk fungsinya mirip dengan fungsi sigmoid biner, tetapi dengan jarak (-1,1).
Fungsi sigmoid memiliki nilai maksimum = 1. Maka untuk pola yang targetnya >1, pola masukan dan keluaran harus terlebih dahulu ditransformasi sehingga semua polanya memiliki range yang sama seperti fungsi sigmoid yang dipakai. Alternatif lain adalah menggunakan fungsi aktifasi sigmoid hanya pada layar yang bukan layar keluaran. Pada layar keluaran, fungsi aktivasi yang dipakai adalah fungsi identitas : f(x) = x.
2.5.2 Pelatihan Backpropagation
Pelatihan Backpropagation meliputi 3 fase. Fase pertama adalah fase maju. Pola masukan dihitung maju mulai dari layar masukan hingga layar keluaran menggunakan fungsi aktivasi yang ditentukan. Fase kedua adalah fase mundur. Selisih antara keluaran jaringan target yang diinginkan merupakan kesalahan yang terjadi. Kesalahan tersebut dipropagasikan mundur, dimulai dari garis yang berhubungan langsung dengan unit-unit di layar keluaran. Fase ketiga adalah modifikasi bobot untuk menurunkan kesalahan yang terjadi.
Algoritma pelatihan untuk jarinan dengan satu layar tersembunyi (dengan fungsi aktivasi sigmoid biner) adalah sebagai berikut:
Langkah 0 : Inisialisasi semua bobot dengan bilangan acak kecil
Langkah 1 : Jika kondisi penghentian belum terpenuhi, lakukan langkah 2-9 Langkah 2 : Untuk setiap pasang data pelatihan, lakukan langkah 3-8 Fase I : Propagasi maju
Langkah 3 : Tiap unit masukkan menerima sinyal dan meneruskannya ke unit tersembunyi diatasnya Langkah 4 : Hitung semua keluaran di unit tersembunyi zj (j=1,2,...,p)
∑ ( )
Langkah 5 : Hitung semua keluaran jaringan di unit
∑ ( )
Fase II : Propagasi mundur
Langkah 6 : Hitung faktor δ unit keluaran berdasarkan kesalahan di setiap unit keluaran δ
merupakan unit kesalahan yang akan dipakai dalam perubahan bobot layar di bawahnya (langkah 7)
Hitung suku perubahan bobot (yang akan dipakai nanti untuk merubah bobot ) dengan laju percepatan
; k = 1,2,..., m ; j = 0, 1, ..., p
Langkah 7 : Hitung faktor δ unit tersembunyi berdasarkan kesalahan di setiap unit tersembunyi (j=1,2,...,p) ∑
Faktor unit tersembunyi :
δ
; j = 1,2,..., p ; i = 0, 1, ..., n
Fase III : Perubahan bobot
Langkah 8 : Hitung semua perubahan bobot Perubahan bobot garis yang menuju ke unit keluaran :
(baru) = (lama) + (k = 1,2, ..., m ; j = 0, 1, ..., p)
Perubahan bobot garis yang menuju unit tersembunyi :
(baru) = (lama) + (j = 1,2, ..., p ; i = 0, 1, ..., n)
Setelah pelatihan selesai dilakukan, jaringan dapat dipakai untuk pengenalan pola. Dalam hal ini, hanya propagasi maju (langkah 4 dan 5) yang dipakai untuk menentukan keluaran jaringan. Apabila fungsi aktivasi yang dipakai bukan sigmoid biner, maka langkah 4 dan 5 harus disesuaikan. Demikian juga turunannya pada langkah 6 dan 7.
3. Perancangan Sistem
Secara umum sistem yang dirancang dapat dilihat pada diagram blok berikut:
Start Data Acquisition Pre-Processing Feature Extraction
Classification End
3.1 Akuisisisi Data
Akuisisi data merupakan tahap pengambilan data dengan proses perekaman suara. Proses perekaman suara di lakukan di dalam ruangan kedap suara menggunakan condensor. Frekuensi sampling yang digunakan 8000 Hz karena frekuensi maksimum yang diamati tidak lebih dari 1500 Hz sehingga dengan frekuensi sampling 8000 Hz sudah cukup memadai. Data berformat Waveform (*.wav), alasannya karena data suara pada format ini belum mengalami kompresi sehingga dapat dikatakan Waveform file adalah raw file atau data murni dari suara rekaman.
3.2 Preprocessing
Setelah diakuisisi, data masuk ke tahap pre-processing. Tahap ini bertujuan untuk membuang informasi-informasi yang tidak diperlukan agar sinyal berada dalam kondisi sama dengan sinyal yang lain.
Start End Get Signal 1 to 8000 samples Denoising Normalization Pre-processed Signal Signal Input
Pertama, data yang akan diproses disamakan panjangnya dengan hanya mengambil sampel ke 1-8000 untuk masing-masing data. Selanjutnya terdapat beberapa proses, yaitu:
1. Denoising
Proses ini diperlukan untuk menghilangkan noise yang tidak diinginkan yang ikut terbawa pada proses perekaman sehingga data suara yang menjadi masukan untuk diekstraksi cirinya memiliki kualitas yang lebih baik. Denoising yang digunakan adalah dengan Wavelet yang dilakukan pada level dekomposisi 5 (level yang umumnya digunakan pada data satu dimensi) dengan beberapa nilai wavelet decomposition filters daubechies.
2. Normalisasi
Proses ini bertujuan untuk menyamakan amplitudo dari setiap suara nyanyian yang direkam oleh sistem sehingga berada dalam rentang -1 dan +1. Data dinormalisasi amplitudanya dengan cara membagi sampel data dengan nilai tertingginya | |
3.3 Ekstraksi Ciri
Setelah melaui tahap pre-processing, data suara selanjutnya memasuki tahap ekstraksi ciri menggunakan metode MFCC. Proses untuk mendapatkan vektor ciri MFCC dapat dilihat di gambar berikut:
Pre Emphasize Frame Blocking Windowing FFT Mel Frequency Warping DCT Input Signal MFCC Coefficient Gambar 3-1 Proses MFCC
Langkah peratama adalah proses pre-emphasis terhadap sinyal hasil keluaran pre-processing dengan koefisien α yang digunakan pada penelitian ini adalah 0,95. Setelah itu sinyal suara dipotong dengan ukuran frame tertentu. Panjang frame yang diujikan adalah 256, 512 dan 1024 sampel dengan besar overlap yang diujikan sebesar 25%, 50%, dan 75% sehingga didapatkan sejumlah frame tertentu. Kemudian setiap frame yang telah didapat dikalikan dengan window hamming untuk mengurangi kebocoran spectral dan mengurangi efek diskontinuitas di awal dan akhir setiap frame. Selanjutnya frame dari domain waktu diubah ke domain frekuensi dengan mengunakan FFT. Spektrum frekuensi yang didapat dari proses FFT dilewatkan ke Mel-Filter Bank yang memiliki kesamaan pada persepsi pendengaran manusia. Jumlah Mel-Filter Bank yang digunakan menentukan hasil ciri dari suatu sinyal suara. Pada penelitian ini dilakukan percobaan dengan menggunakan beberapa jumlah mel filter bank sebanyak 24, 31, dan 64 buah filter untuk mengetahui kualitas filter yang menghasilkan ciri paling optimal. Pemilihan jumlah filter tersebut didasarkan pada penelitian yang sudah ada mengenai MFCC.[9] Langkah selanjutnya adalah komputasi harga logaritmik dari energi dari setiap band
output dari setiap filter. Kemudian logaritma energi tersebut diubah menjadi cepstrum dengan invers DCT. Pada DCT ini
ditentukan berapa jumlah koefisien keluaran MFCC yang diharapkan yang merupakan hasil akhir dari proses ekstraksi ciri menggunakan MFCC. Pada penelitian ini dilakukan pengambilan beberapa jumlah koefisien yaitu sebanyak 10, 12, 15, dan 20 buah koefisien, dengan default awal 20 koefisien yang biasa digunakan pada umumnya.[4] Hasil akhir inilah yang selanjutnya digunakan sebagai vektor ciri untuk masuk ke tahap klasifikasi.
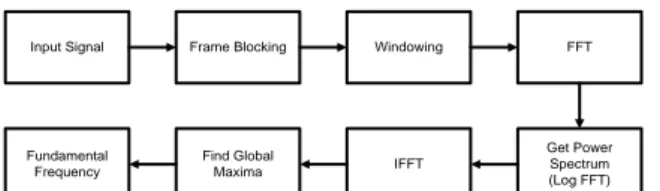
3.4 Penentuan Pitch
Pertama-tama sinyal input dipotong menjadi beberapa frame berukuran 256 sampel dengan overlapping sebesar 128 sample dan setiap frame dikalikan dengan window Hamming berukuran 256. FFT dari setiap frame tersebut akan menghasilkan spektrum frekuensi, lalu dihitung spektrum daya dari setiap frame. Spektrum daya ini kemudian dikembalikan ke domain waktu dengan proses inverse FFT (IFFT). Hasil IFFT inilah yang dinamakan cepstrum. Cepstrum akan memberikan nilai maksimum pada indeks waktu (t), yang memiliki pitch yang dominan.
Input Signal Frame Blocking Windowing FFT
Get Power Spectrum (Log FFT) IFFT Find Global Maxima Fundamental Frequency
Gambar 3-2 Diagram Blok Analisis Pitch Dengan Cepstrum 4. Pengujian dan analisis
4.1 Pengujian deteksi gender
Berdasarkan skenario yang dijalankan, diperoleh perbandingan tingkat akurasi dari masing-masing pengujian,yang hasilnya dapat dilihat pada tabel berikut:
Tabel 4-1 Hasil Akurasi Pengaruh Perubahan Panjang Frame, Overlap, dan Jumlah Mel Bank Filter
Frame Akurasi Overlap Akurasi
Mel
Filter Akurasi
256 69,71% 25% 66,81% 24 69,71%
512 68,46% 50% 69,71% 31 72,20%
1024 67,63% 75% 67,63% 64 68,46%
Pertama adalah pengaruh panjang frame. Sinyal suara yang digunakan pada penelitian ini adalah sinyal bicara. Dalam toeri pengolahan sinyal bicara, dikatakan bahwa panjang frame yang sesuai untuk sinyal bicara adalah sebesar 30-50 ms. Pada pengujian ini, terbukti bahwa panjang frame pada kisaran 30-50 ms, dimana dipilih 32 ms atau panjang frame 256
sample point memberikan hasil paling optimal.
Kedua adalah pengaruh panjang overlap, yaitu menentukan banyaknya sampel yang diproses kembali pada frame berikutnya untuk mengantisipasi apabila ada informasi yang tidak terproses. Pada deteksi gender, dengan overlap yang besar (75%) diperoleh hasil yang paling baik karena lebih banyak sampel yang diproses kembali pada frame berikutnya sehingga ciri keseluruhan sinyal suara dapat lebih terlihat. Namun pada deteksi tipe suara hasil yang paling optimal didapat pada overlap 50% karena lebih banyak terdapat kemiripan ciri antar tipe suara sehingga lebih rumit. Dengan
overlap yang terlalu besar dapat menyebabkan confuse pada sistem akibat terlalu banyak ciri yang diproses ulang.
Ketiga pengaruh penggunaan Mel Bank Filter yaitu, dengan sedikit Mel Bank Filter, maka sedikit pula informasi yang didapat dari setiap frekuensi karena tiap frekuensi memiliki karakteristik yang berbeda. Di sisi lain, penggunaan Mel
Bank Filter yang banyak membuat filter yang ada semakin rapat sehingga semakin teliti dalam mem-filter sinyal suara
yang masuk dan memprosesnya. Dalam penggunaannya, terlalu sedikit atau terlalu banyak jumlah Mel Bank Filter dapat memberikan hasil yang kurang baik sehingga perlu dicari jumlah yang memberikan hasil terbaik. Pada penelitian ini digunakan 31 Mel Bank Filter karena memberikan hasil paling optimal.
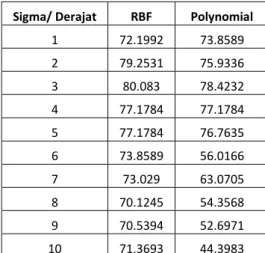
Tabel 4-2 Hasil Akurasi Pengaruh Perubahan Nilai Parameter Fungsi Kernel
Sigma/ Derajat RBF Polynomial
1 72.1992 73.8589 2 79.2531 75.9336 3 80.083 78.4232 4 77.1784 77.1784 5 77.1784 76.7635 6 73.8589 56.0166 7 73.029 63.0705 8 70.1245 54.3568 9 70.5394 52.6971 10 71.3693 44.3983
Berikutnya adalah pengaruh penggunaan fungsi kernel, peningkatan nilai derajat pada Polynomial maupun Sigma pada RBF dapat meningkatkan fleksibilitas batas pemisah dalam menentukan hasil klasifikasi, namun jika terlalu besar nilai parameter yang digunakan dapat menyebabkan overfitting yang dapat memperburuk hasil akurasi.
Tabel 4-3 Pengaruh Perubahan Koefisien MFCC
Koefisien MFCC Akurasi
10 63,07%
12 68,05%
15 65,56%
20 72,20%
Pengaruh perubahan jumlah koefisien MFCC menunjukan banyaknya vektor ciri yang akan digunakan. Pada umumnya, pangaruh perubahan jumlah koefisien MFCC yang digunakan adalah semakin banyak koefisien yang digunakan, akan memberikan hasil yang semakin baik karena informasi ciri yang dimiliki semakin banyak. Hasil yang optimal didapat pada jumlah koefisien 20.
4.2 Analisis Pengaruh Parameter JST Backpropagation
Pada JST Backpropagation, terdapat beberapa parameter yang dapat menentukan kinerja JST dalam memproses input yang baru. Pada penelitian ini diuji parameter JST yaitu Pengaruh jumlah hidden layer dan Jumlah Neuron pada masing-masing layer, pengaruh fungsi aktivasi pada hidden layer dan output layer.
4.2.1 Analisis Pengaruh Jumlah Hidden Layer
Pengujian ini dilakukan dengan mengubah jumlah hidden layer pada JST yang dibangun, pada sistem ini dibatasi hidden
layer yang diuji adalah hidden layer 1 sampai dengan 5. Nilai threshold yang digunakan adalah 0,2. Parameter JST lain
yang digunakan yaitu jumlah neuron yang digunakan 50, fungsi aktivasi hidden layer adalah tansig, dan fungsi aktivasi
output layer adalah purelin. Parameter lain pada Backpropagation yang digunakan yaitu nilai maksimum epoch sebanyak
20.000, batas toleransi error 10-4, learning rate 0.01, dan gradien minimum 1x10-6. Pada tabel di bawah ini dapat dilihat akurasi yang dihasilkan masing-masing jumlah hidden layer dan jumlah neuron.
Tabel 4-4 Akurasi akibat pengaruh jumlah hidden layer Jumlah
Hidden Layer
AKURASI (%)
Data Training Data Uji
1 96,8553 69,1824
2 100 77,3585
3 100 79,2453
4 100 83,6478
5 100 88,0503
Terlihat bahwa jumlah hidden layer dapat mempengaruhi kinerja sistem sehingga hasil akurasi yang didapatkan cukup beragam. Akurasi tertinggi pada deteksi jenis nada alat musik diperoleh saat hidden layer berjumlah 5. Hal tersebut dipengaruhi oleh besarnya hidden layer, karena untuk jaringan yang memiliki lebih dari 1 hidden layer maka dalam propagasi maju, keluaran dihitung untuk setiap layer mulai dari layer yang paling dekat dengan input. Sedangkan pada propagasi mundur faktor kesalahan akan terus diperbaiki pada setiap layer dimulai dari layer output. Sehingga jika jumlah hidden layer lebih dari 1, maka kesalahan pengenalan akan semakin kecil.
4.2.2 Analisis Pengaruh Jumlah Neuron
Pada pengujian ini diuji pengaruh dari jumlah neuron pada JST. Dari hasil analisis dicari jumlah neuron yang paling cocok untuk diterapkan pada sistem. Pengujian ini dilakukan dengan mengubah jumlah neuron pada JST yang dibangun. Jumlah neuron yang diuji dibatasi dari 10 sampai 50. Nilai threshold yang digunakan adalah 0,2. Parameter JST lain yang digunakan yaitu hidden layer yang digunakan 5, fungsi aktivasi hidden layer adalah tansig, dan fungsi aktivasi output layer adalah purelin. Parameter lain pada Backpropagation yang digunakan yaitu nilai maksimum epoch sebanyak 20.000, batas toleransi error 10-4, learning rate 0.01, dan gradien minimum 1x10-6. Pada tabel di bawah ini dapat dilihat akurasi yang dihasilkan masing-masing jumlah neuron.
Tabel 4-5 Akurasi akibat pengaruh jumlah neuron Jumlah
Neuron
AKURASI (%)
Data Training Data Uji
10 100 66,6667
20 100 76,1006
30 100 79,8742
40 100 78,6164
50 100 88,0503
Neuron mempengaruhi sistem dalam hal pelatihan jaringan saraf tiruan. Penambahan jumlah neuron membuat pelatihan
menjadi lebih mudah. Pada tabel 4-5 terlihat bahwa jumlah neuron dapat mempengaruhi kinerja sistem sehingga hasil akurasi yang didapatkan cukup beragam. Akurasi tertinggi pada deteksi nada alat musik diperoleh saat jumlah Neuron 50.
4.2.3 Analisis Pengaruh Fungsi Aktivasi Pada Hidden layer
Pengujian ini dilakukan dengan mengubah fungsi aktivasi hidden layer pada JST yang dibangun. Nilai thresholding yang digunakan adalah 0,2. Parameter JST yang digunakan yaitu dengan jumlah hidden layer 5, jumlah neuron masing-masing layer adalah 50, dan fungsi aktivasi output layer yang digunakan adalah purelin. Parameter lain pada
Backpropagation yang digunakan yaitu nilai maksimum epoh sebanyak 20.000, batas toleransi error 10-4, learning rate 0.01, dan gradien minimum 1x10-6.
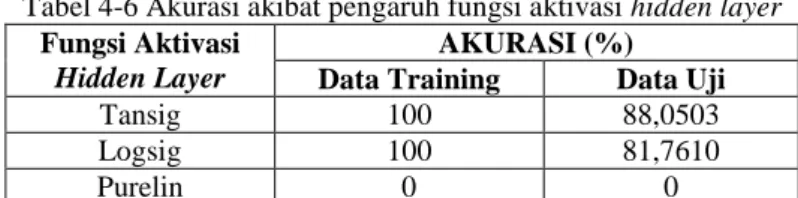
Tabel 4-6 Akurasi akibat pengaruh fungsi aktivasi hidden layer Fungsi Aktivasi
Hidden Layer
AKURASI (%)
Data Training Data Uji
Tansig 100 88,0503
Logsig 100 81,7610
Purelin 0 0
Pada tabel 4-6 dapat disimpulkan bahwa fungsi aktivasi hidden layer yang cocok adalah fungsi Tan-Sigmoid (tansig), karena menghasilkan akurasi tertinggi yaitu sebesar 88,0503%. Dari data yang diperoleh, juga dapat disimpulkan bahwa fungsi aktivasi purelin tidak cocok untuk dipakai pada hidden layer karena fungsi aktivasi ini menghasilkan akurasi yang sangat buruk yaitu nol.
4.2.4 Analisis Pengaruh Fungsi Aktivasi Output Layer
Pengujian ini dilakukan dengan mengubah fungsi aktivasi output layer pada JST yang dibangun. Nilai threshold yang digunakan adalah 0,2. Parameter JST yang digunakan yaitu dengan jumlah hidden layer 5, jumlah neuron masing-masing
layer adalah 20, dan fungsi aktivasi hidden layer yang digunakan adalah fungsi Tan-Sigmoid (tansig). Parameter lain
pada Backpropagation yang digunakan yaitu nilai maksimum epoh sebanyak 20.000, batas toleransi error 10-4, learning
rate 0.01, dan gradien minimum 1x10-6.
Tabel 4-7 Akurasi akibat pengaruh fungsi aktivasi output layer Fungsi Aktivasi
Output Layer
AKURASI (%)
Data Training Data Uji
Tansig 100 84,9057
Logsig 0 0
Purelin 100 88,0503
Pada tabel 4-7 dapat disimpulkan bahwa fungsi aktivasi yang cocok untuk output layer adalah Pure-Linier (Purelin) karena menghasilkan akurasi tertinggi yaitu sebesar 88,0503%. Dari data yang diperoleh, juga dapat disimpulkan bahwa fungsi aktivasi logsig tidak cocok untuk dipakai pada output layer, karena fungsi aktivasi ini menghasilkan akurasi yang sangat buruk yaitu nol.
4.3 Hasil Akhir Deteksi Gender
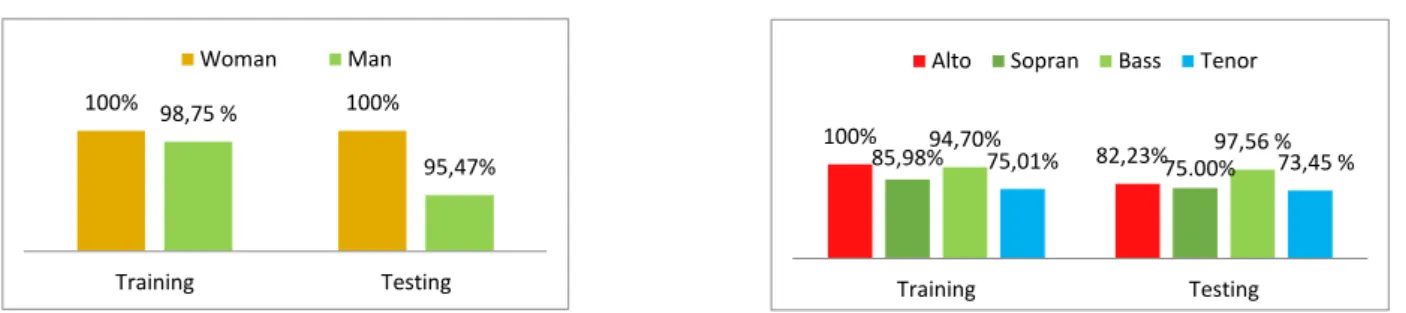
Berdasarkan hasil skenario pengujian yang telah dilakukan, nilai parameter-parameter yang memberi hasil paling optimal untuk deteksi gender yaitu panjang frame 256 sampel, overlap 75%, jumlah Mel Bank Filter 31, jumlah koefisien MFCC 20, dan parameter JST Backpropagation jumlah hidden layer 5, jumlah neuron 50, fungsi aktifvasi hidden layer Tan-Sigmoid, fungsi aktivasi output layer adalah Pure-Linier. Hasil akurasi yang diperoleh dapat dilihat di gambar berikut, untuk proses uji coba pada suara wanita memperoleh hasil akurasi 100% sementara untuk pria memperoleh hasil akurasi sebesar 95,47%
Gambar 4.1 Grafik Perbandingan Akurasi Hasil Deteksi Gender Gambar 4.2 Perbandingan Akurasi Hasil Deteksi Tipe Suara Kemampuan sistem dalam mendeteksi gender wanita lebih baik dibandingkan pria. Error banyak terjadi pada pria bertipe suara tenor yang terdeteksi sebagai gender wanita. Hal ini disebabkan oleh adanya suara pria dengan karakteristik yang terdengar menyerupai suara wanita.
4.4.2 Hasil Akhir Deteksi Tipe Suara
Berdasarkan hasil skenario pengujian yang telah dilakukan, dengan nilai parameter-parameter yang sama seperti deteksi gender. Hasil yang diperoleh adalah sebagai berikut
Dapat dilihat bahwa hasil deteksi tipe suara yang memiliki akurasi tertinggi adalah suara bass, diikuti oleh tipe suara alto, sopran, dan yang paling rendah adalah tenor. Hal ini menunjukkan bahwa sistem mendeteksi lebih baik pada tipe suara dengan frekuensi nada rendah, yaitu bass dan alto. Hal ini berkaitan dengan filter pada MFCC yang tersebar tidak merata, yaitu banyak filter pada daerah frekuansi rendah dan sedikit filter pada daerah frekuensi tinggi, dimana banyak filter dapat mempengaruhi banyaknya informasi yang diperoleh. Selain itu, pada suara rendah apabila didengar secara langsung terdengar lebih berkarakter dan lebih dapat dibedakan. Sementara pada suara tinggi, antara suara satu dengan yang lain kurang terdengar perbedaan karakternya.
5. Kesimpulan
Setelah dilakukan pengujian dan analisis terhadap sistem deteksi tipe suara pria dan wanita pada penelitian ini, maka dapat diambil beberapa kesimpulan sebagai berikut:
1. Sistem dapat mendeteksi gender dengan akurasi pada wanita 100% sedangkan pada pria 95,47% 2. Sistem dapat mendeteksi tipe suara alto 82,23%, sopran 75%, bass 97,56 dan tenor 73,45%.
3. Spesifikasi nilai parameter yang memberikan akurasi paling optimal pada deteksi tipe suara pria dan wanita adalah panjang frame 256 sampel, overlap 75%, jumlah Mel Bank Filter 31, jumlah koefisien MFCC 20, dan parameter JST Backpropagation jumlah hidden layer 5, jumlah neuron 50, fungsi aktifvasi hidden layer Tan-Sigmoid, fungsi aktivasi output layer adalah Pure-Linier
6. Daftar Pustaka
[1] Ben-Hur, Asa and Jason Weston. A User’s Guide to Support Vector Machines. Colardo State University and Princenton, NJ 08540 USA.
[2] Cernocky, Jan dan Valentina Hubeika. Fundamental Frequency Detection. DCGN FIT BUT Brno.
[3] Gerhard, David. 2003. Pitch Extraction and Fundamental Frequency: History and Current Techniques. Departement of Computer Science University of Regina, Canada.
[4] Hasan, Rashidul Md., Mustafa Jamil, Md. Golam Rabbani, dan Md. Saifur Rahman. 2004. Speaker Identification
Using Mel Frequency Cepstral Coefficients. Bangladesh University of Engineering and Technology, Dhaka.
[5] Kura, Vijay B. 2003. Novel Pitch Detection Algorithm With Application to Speech Coding. B. Tech Jawaharlal Institute of Technological University.
[6] Mustofa, Ali. 2007. Sistem Pengenalan Penutur dengan Metode Mel-frequency Wrapping. Jurnal Teknik Elektro. Vol. 7. No. 2: 88 – 96.
[7] Nugroho, Anto Satriyo, dkk. 2003. Support Vector Machine-Teori dan Aplikasinya dalam Bioinformatika. Kuliah Umum Ilmu Komputer.com.
[8] Prahallad, Kishore. Speech Technology : A Practical Introduction, topic : Spectrogram, Cepstrum and
Mel-Frequency Analysis. Carnegie Mellon University & International Institute of Information Technology Hyderabad.
Slide.
[9] Purwanto, Kristiawan dan Tutug Dhanardono. Simulasi Reduksi Derau Sinyal Suara Pada Gedung Kebun Raya
Purwodadi Dengan Metode DWT. ITS, Surabaya.
[10] Santosa, Budi. 2007. Data Mining Teknik Pemanfaatan Data untuk Keperluan Bisnis. Yogyakarta: Graha Ilmu. [11] Simanungkalit, Nortier. 2008. Teknik Vokal Paduan Suara. Jakarta: Gramedia Pustaka Utama.
[12] Yen, Joe. Wavelet for Acoustics, Technical Report R98942097 (citation for B3). 100% 98,75 % 100% 95,47% Training Testing Woman Man 100% 82,23% 85,98% 94,70% 75,01% 75.00% 97,56 % 73,45 % Training Testing
[13] Yudha, Indrajit Prawira. 2012. Sistem Identifikasi Jenis Suara Manusia Berdasarkan Jangkauan Vokal
![Gambar 2-1 Diagram Blok Produksi Suara Manusia [5]](https://thumb-ap.123doks.com/thumbv2/123dok/4236079.2871410/1.892.368.575.855.1047/gambar-diagram-blok-produksi-suara-manusia.webp)
![Tabel 2.1 Jangkauan Frekuensi Tiap Tipe Suara [12]](https://thumb-ap.123doks.com/thumbv2/123dok/4236079.2871410/2.892.86.753.217.377/tabel-jangkauan-frekuensi-tiap-tipe-suara.webp)