Discriminative Feature Extraction
Zhirong Yang and Jorma Laaksonen
Laboratory of Computer and Information Science⋆ Helsinki University of Technology
P.O. Box 5400, FI-02015 HUT, Espoo, Finland {zhirong.yang, jorma.laaksonen}@hut.fi
Abstract. We propose a fast fixed-point algorithm to improve the
Rel-evant Component Analysis (RCA) in two-class cases. Using an objective function that maximizes the predictive information, our method is able to extract more than one discriminative component of data for two-class problems, which cannot be accomplished by classical Fisher’s discrim-inant analysis. After prewhitening the data, we apply Newton’s opti-mization method which automatically chooses the learning rate in the iterative training of each component. The convergence of the iterative learning is quadratic, i.e. much faster than the linear optimization by gra-dient methods. Empirical tests presented in the paper show that feature extraction using the new method resembles RCA for low-dimensional ionosphere data and significantly outperforms the latter in efficiency for high-dimensional facial image data.
1
Introduction
Supervised linear dimension reduction, or discriminative feature extraction, is a common technique used in pattern recognition. Such a preprocessing step not only reduces the computation complexity, but also reveals relevant information in the data.
Fisher’s Linear Discriminant Analysis (LDA) [3] is a classical method for this task. Modeling each class by a single Gaussian distribution and assum-ing all classes share a same covariance, LDA maximizes the Fisher criterion of between-class scatter over within-class scatter and can be solved by Singular Value Decomposition (SVD). LDA is attractive for its simplicity. Nevertheless, it yields only one discriminative component for two-class problems because the between-class scatter matrix is of rank one. That is, the discriminative informa-tion can only be coded with a single number and a lot of relevant informainforma-tion may be lost during the dimensionality reduction.
Loog and Duin [2] extended LDA to the heteroscedastic case based on the simplified Chernoff distance between two classes. They derived an alternative
criterion which uses the individual scatter matrices of both classes. The gener-alized objective can still be optimized by SVD and their method can possibly output more than one projecting direction.
LDA and the above Chernoff extension, as well as many other variants such as [4, 7], only utilize up to second-order statistics of the class distribution. Pel-tonen and Kaski [5] recently proposed an alternative approach, Relevant Com-ponent Analysis (RCA), to find the subspace as informative as possible of the classes. They model the prediction by a generative procedure of classes given the projected values, and the objective is to maximize the log-likelihood of the supervised data. In their method, the predictive probability density is approxi-mated by Parzen estimators. The training procedure requires the user to specify a proper starting learning rate, which however is lacking theoretical instruc-tions and may be difficult in some cases. Moreover, the slow convergence of the stochastic gradient algorithm would lead to time-consuming learning.
In this paper, we propose an improved method to speed up the RCA training for two-class problems. We employ three strategies for this goal: prewhitening the data, learning the uncorrelated components individually, and optimizing the objective by Newton’s method. Finally we obtain a fast Fixed-Point Relevant Component Analysis (FPRCA) algorithm such that the optimization conver-gence is quadratic. The new method inherits the essential advantages of RCA. That is, it can handle distributions more complicated than single Gaussians and extract more than one discriminative component of the data. Furthermore, the user does not need to specify the learning rates because they are optimized by the algorithm.
We start with a brief review of RCA in Section 2. Next, we discuss the data preprocessing and the fast optimization algorithm of RCA in Section 3. Section 4 gives the experiments and comparisons on ionosphere and facial image data. Section 5 concludes the paper.
2
Relevant Component Analysis
Consider a supervised data set which consists of pairs (xj, cj), j = 1, . . . , n, where xj ∈ Rm is the primary data, and the auxiliary data cj takes values from binary categorical values.Relevant Component Analysis(RCA) [5] seeks a linearm×rorthonormal projectionWthat maximizes the predictive power of the primary data. This is done by constructing a generative probabilistic model of cj given the projected value yj = WTxj ∈ Rr and maximizing the total estimated log-likelihood overW:
maximize
W JRCA=
n X
j=1
In RCA, the estimated probability ˆp(cj|yj) is computed by the definition of conditional probability density function as:
ˆ
p(cj|yj) =
Ω(yj, cj) X
c
Ω(yj, c)
. (2)
Here
Ω(yj, c) = 1
n
n X
i=1
ψ(i, c)ω(yi,yj) (3)
is the Parzen estimation of ˆp(yj, c) and the membership function ψ(i, c) = 1 if
ci = c and 0 otherwise. Gaussian kernel is used in [5] as the Parzen window function
ω(yi,yj) = 1
(2πσ2)r/2exp
−kyi−yjk
2
2σ2
, (4)
whereσcontrols the smoothness of the density estimation.
Peltonen and Kaski [5] derived the gradient of JRCA with respect to W, based on which one can compute the gradients for Givens rotation angles and then update W for the next iteration. The RCA algorithm applies stochastic gradient optimization method and the iterations converge to a local optimum with a properly decreasing learning rate.
3
Two-Class Discriminant Analysis by RCA with a Fast
Fixed-Point Algorithm
3.1 Preprocessing the Data
Suppose the data has been centered to be zero mean. Our algorithm requires prewhitening the primary data, i.e. to find anm×msymmetric matrixV and to transformz=Vxsuch thatE{zzT}=I. The matrix Vcan be obtained for example by
V=ED−12ET, (5)
where [E,D,ET] = svd(E{xxT}) is the singular value decomposition of the scatter matrix of the primary data.
Prewhitening the primary data greatly simplifies the algorithm described in the following section. We can acquire a diagonal approximation of the Hessian matrix and then easily invert it. Another utility of whitening resides in the fact that for two projecting vectorswp andwq,
E{(wTpz)(wTqz)}=wTpE{zzT}wq =wpTwq, (6)
and therefore uncorrelatedness is equivalent to orthogonality. This allows us to individually extract uncorrelated features by orthogonalizing the projecting directions. In addition, selecting theσparameter in the Gaussian kernel function becomes easier because the whitened data has unit variance on all axes and σ
3.2 Optimization Algorithm
Let us first consider the case of a single discriminative component where yj =
yj =wTzj ∈R. Our fixed-point algorithm for finding the extreme point ofJRCA iteratively applies a Newton’s update followed by a normalization:
w† = w− then be expressed as
∂JRCA
Notice that the chain rule in the last step applies to the subscripti, i.e. treatingyi as an intermediate variable andyj as a constant. We writegij =dJj/d(yi−yj) for brevity. If the estimated predictive probability density ˆp(cj|yj) is obtained by Parzen window technique as in (2) and (3), we can then (see Appendix) write outgij as
For notational simplicity, denote
∆ij =∂(yi−yj)
We can then write
∂JRCA
where◦stands for element-wise product and∆consists ofn×nvectors of size
Based ong′
ij one can compute
∂2J RCA
∂w2 =n 2E{g′◦
∆∆T}. (15)
Notice thatE{∆∆T}= 2E{zzT}= 2I if the data is centered and prewhitened (see Appendix for a proof). Furthermore, if we approximate E{g′ ◦∆∆T} ≈ E{g′}E{∆∆T}, assumingg′and∆∆T are pair-wisely uncorrelated, the Hessian (15) can be approximated by
∂2J RCA
∂w2 = 2n
2E{g′}I (16)
withE{g′} ∈R. Inserting (13) and (16) into (7), we obtain
w†=w−n
2E{g◦∆}
2n2E{g′} =
1
2E{g′}(2E{g
′}w− E{g◦
∆}). (17)
Because the normalization step (8) is invariant to scaling and the sign of projec-tion does not affect the subspace predictiveness, we can drop the scalar factor in the front and change the order of terms in the parentheses. Then the update rule (7) simplifies to
w† =E{g◦∆} −2E{g′}w. (18)
In this work we employ a deflationary method to extract multiple discrim-inative components. Precisely, the Fixed-Point Relevant Component Analysis
(FPRCA) algorithm comprises the following steps:
1. Center the data to make its mean zero and whiten the data to make its scatter to an identity matrix.
2. Compute∆, the matrix of pair-wise sample difference vectors as in (11). 3. Chooser, the number of discriminative components to estimate, andσif the
Gaussian kernel (4) is used. Setp←1. 4. Initializewp (e.g. randomly).
5. Computegandg′ and then update w
p← E{g◦∆} −2E{g′}wp. 6. Do the following orthogonalization:
wp←wp− p−1 X
q=1
(wpTwq)wq. (19)
7. Normalize wp←wp/kwpk.
4
Experiments
We have tested the FPRCA algorithm on facial images collected under the FERET program [6] and ionosphere data which is available at [1]. The iono-sphere data consists of 351 instances, each of which has 34 real numeric at-tributes. 225 samples are labeledgood and the other 126 asbad. For the FERET data, 2409 frontal facial images (poses “fa” and “fb”) of 867 subjects were stored in the database after face segmentation. In this work we obtained the coordi-nates of the eyes from the ground truth data of the collection, with which we calibrated the head rotation so that all faces are upright. Afterwards, all face boxes were normalized to the size of 32×32, with fixed locations for the left eye (26,9) and the right eye (7,9). Two classes, mustache (256 images, 81 subjects) and no mustache (2153 images, 786 subjects), have been used in the following experiments.
4.1 Visualizing Discriminative Features
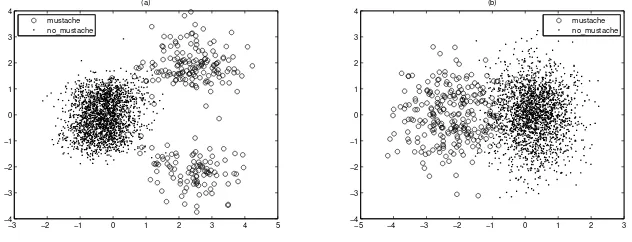
First we demonstrate the existence of multiple discriminative components in two-class problems. For illustrative purpose, we use two-dimensional projections. The first dimension is obtained from LDA as w1 and the second is trained by FPRCA asw2 and orthogonal tow1as in (19). All the experiments of FPRCA in this paper use one-dimensional Gaussian kernel (4) withσ= 0.1 as the Parzen window function.
Figure 1 (a) shows the projected values of the two classes of facial images. The plot illustrates that the verticalw2axis provides extra discriminative infor-mation in addition to the horizontalw1 axis computed by the LDA method. It can also be seen that the mustache class along the vertical axis comprises two separate clusters. Such projecting direction can by no means be found by LDA and its variants because they limit the projected classes to be single Gaussians. For comparison, the result of HLDR using Chernoff criterion [2] (CHER-NOFF) is shown in Figure 1 (b). The first (horizontal) dimension resembles the LDA result, while the second (vertical) provides little discriminative information. It can be seen that the clusters are more overlapping in the latter plot.
4.2 Discriminative Features for Classification
Next we compared the classification results on the ionosphere data using the discriminative features extracted by FPRCA and three other methods: LDA, CHERNOFF [2], and RCA. Two kinds of FPRCA features were used. Forr= 1, the one-dimensional projection was initialized by LDA and then trained by FPRCA. Forr= 2, the first component was the training result ofr= 1 and the additional component was initialized by a random orthogonal vector, and then trained by FPRCA.
−3 −2 −1 0 1 2 3 4 5 −4
−3 −2 −1 0 1 2 3 4
(a)
mustache no_mustache
−5 −4 −3 −2 −1 0 1 2 3
−4 −3 −2 −1 0 1 2 3 4
(b)
mustache no_mustache
Fig. 1.Projected values of the classesmustacheandno mustache. (a) The horizontal
axis is obtained by LDA and the vertical by FPRCA. (b) Both dimensions are learned by HLDR with the Chernoff criterion [2].
samples are for training and the other half for testing. Both LOO and HALF measure the generalization ability. The latter mode is stochastic and tests the performance with a much smaller training set. For it, we repeated the experiment ten times with different random seeds and calculated the mean accuracy.
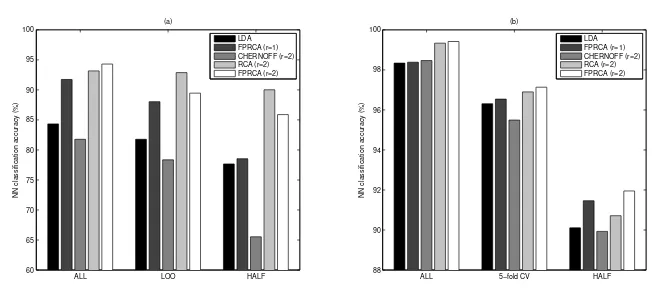
Figure 2 (a) illustrates the Nearest-Neighbor (NN) classification accuracies for the compared methods in the above three testing modes with the ionosphere data. The left two bars in each group show that FPRCA outperforms LDA in all the three modes when a single discriminative component is used. This verifies that the high-order statistics involved in the information theoretic objective can enhance the discrimination. The right three bars demonstrate the performance of two-dimensional discriminative features. It can be seen that the additional component learned by CHERNOFF even deteriorates the classification from that of LDA. Furthermore, CHERNOFF shows poor generalization when the amount of training data becomes small. In contrast, RCA and FPRCA (r= 2) exceed LDA and FPRCA (r= 1) with the second component added. The accuracies of FPRCA (r = 2) are comparable to those of RCA as the differences are within 3.5% units. RCA performs slightly better than FPRCA (r= 2) in the LOO and HALF modes because we applied a grid search for optimal parameters of RCA while we did not for FPRCA.
ALL LOO HALF 60
65 70 75 80 85 90 95 100
NN classification accuracy (%)
(a)
LDA FPRCA (r=1) CHERNOFF (r=2) RCA (r=2) FPRCA (r=2)
ALL 5−fold CV HALF
88 90 92 94 96 98 100
NN classification accuracy (%)
(b)
LDA FPRCA (r=1) CHERNOFF (r=2) RCA (r=2) FPRCA (r=2)
Fig. 2.Nearest-Neighbor (NN) classification accuracies for the compared methods in
three testing modes: (a) the ionosphere data and (b) the FERET data.
RCA and FPRCA attain not only the least training errors, but also better gener-alization. The additional dimension introduced by FPRCA is more advantageous when the training data become scarce. The accuracies of FPRCA (r= 2) exceed the other compared methods and the difference is especially significant in the HALF mode. The result for the RCA method may still be suboptimal due to its computational difficulty which will be addressed in the next section.
4.3 RCA vs. FPRCA in Learning Time
We have recorded the running times of RCA and FPRCA using a Linux ma-chine with 12GB RAM and two 64-bit 2.2GHz AMD Opteron processors. For the 34-dimensional ionosphere data, both RCA and FPRCA converged within one minute. The exact running times were 38 and 45 seconds, respectively. How-ever, the calculation is very time-demanding for RCA when it is applied to the 1024-dimensional facial image data. Ten iterations of RCA learning on the FERET database required 598 seconds. A 5,000-iteration RCA training, which merely utilizes each image roughly twice on the average, took about 83 hours, i.e. more than three days. In contrast, the FPRCA algorithm converges within 20 iterations for the mustache classification problem and the training time was 4,400 seconds.
5
Conclusions
The objective of maximizing predictive information is known to yield better discriminative power than methods based on only second-order statistics. We presented a fast fixed-point algorithm that efficiently learns the discriminative components of data based on an information theoretic criterion. Prewhitening the primary data facilitates the parameter selection for the Parzen windows and enables approximating the inverse Hessian matrix. The learning rate of each iteration is automatically optimized by the Newton’s method, which eases the use of the algorithm. Our method converges quadratically and the extracted discriminative features are advantageous for both visualization and classification. Like other linear dimensionality reduction methods, FPRCA is readily ex-tended to its kernel version. The nonlinear discriminative components can be obtained by mapping the primary data to a higher-dimensional space with ap-propriate kernels.
Inserting (21) and (2) into (20), we obtain
gij = Finally we have (10).
where the step (23) is obtained if the primary data is centered, i.e. of zero mean.
References
1. C.L. Blake D.J. Newman, S. Hettich and C.J. Merz. UCI repository of machine learning databaseshttp://www.ics.uci.edu/∼mlearn/MLRepository.html, 1998. 2. R.P.W Duin and M. Loog. Linear dimensionality reduction via a heteroscedastic extension of lda: the chernoff criterion. IEEE Transaction on Pattern Analysis and Machine Intelligence, 26(6):732–739, 2004.
3. R. A. Fisher. The use of multiple measurements in taxonomic problems. Annals of Eugenics, 7, 1963.
4. Peg Howland and Haesun Park. Generalizing discriminant analysis using the gen-eralized singular value decomposition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 26(8):995–1006, 2005.
5. Jaakko Peltonen and Samuel Kaski. Discriminative components of data. IEEE Transactions on Neural Networks, 16(1):68–83, 2005.
6. P. J. Phillips, H. Moon, S. A. Rizvi, and P. J. Rauss. The FERET evaluation methodology for face recognition algorithms. IEEE Trans. Pattern Analysis and Machine Intelligence, 22:1090–1104, October 2000.