APLIKASI PERBAIKAN EJAAN PADA KARYA TULIS ILMIAH
DIPROGRAM STUDI TEKNIK INFORMATIKA DENGAN MENERAPKAN ALGORITMA LEVENSHTEIN DISTANCE
Roby Nur Hamzah
Artikel Skripsi Universitas Nusantara PGRI Kediri
Di Publish 12 Agustus 2016
LATAR BELAKANG MASALAH
REVISI BERULANG-ULANG
KARENA TYPOGRAPHICAL
ERROR
SOLUSI EXPERT
TUJUAN PENELITIAN
Expert system
Kualitas karya tulis
jadi lebih baik Meperbaiki
kesalahan pengetikan Mempermudah
pengetikan karya tulis
METODE/TEKNIK YANG DITERAPKAN
Metode yang diterapkan menggunakan algoritma levenshtein distance.
CARA KERJA
Menghitung jarak terdekat dari string sumber (s) dengan String
target (t). Jika selisih String sumber (s) dengan String target (t) memiliki jarak terendah, maka akan dijadikan saran perbaikan berdasarkan urutan jarak String terendah hingga terbesar.
HASIL DAN PEMBAHASAN/DISKUSI
PEMBAHASAN
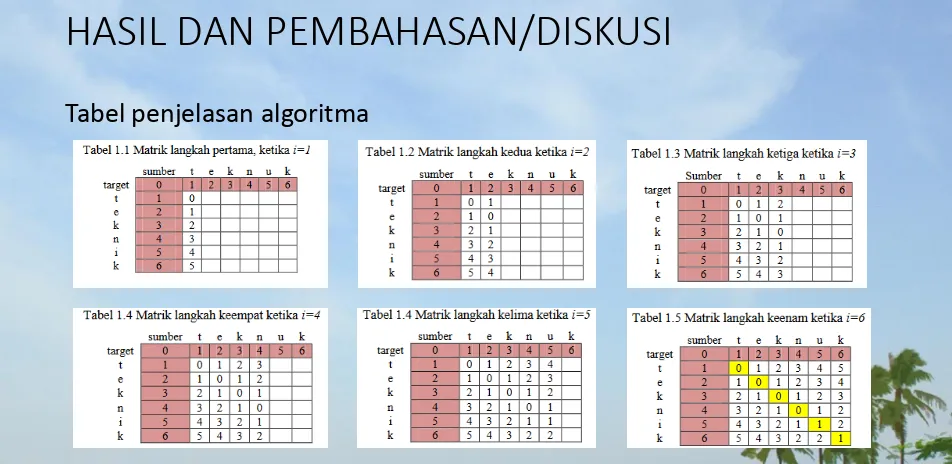
Untuk mengetahui proses perhitungan algoritma Levenshtein Distance dalam memperbaiki kesalahan ejaan. Maka akan dilakukan sebuah simulasi algoritma dengan contoh sebagai berikut :
Diketahui sebuah String sumber (s) = “teknuk” dan String target (t) = “teknik” untuk menyamakan
String maka akan dilakukan perhitungan: Rumus :
= d(t,t) + d(e,e) + d(k,k) + d(n,n) + d(u,i) + d(k,k)
= 0 + 0 + 0 + 0 + 1 + 0
= 1
HASIL DAN PEMBAHASAN/DISKUSI
KESIMPULAN
Berdasarkan hasil penelitian dan implementasi sistem, maka dapat diambil kesimpulan sebagai berikut :
1. Aplikasi ini dikhususkan pada karya tulis ilmiah yang berformat
*docx.
KAKAS BANTU PENDETEKSI KESALAHAN
TADA BACA PADA KARYA TULIS ILMIAH
Ratih Nur Esti Anggraini, Mohammad Ahmaluddin Zinni, dan Siti Rochimah
Abdullah Lubis 1441177004081
Jurusan Teknik Informatika
LATAR BELAKANG MASALAH
Dirjen DIKTI tahun 2012 :
“Karya ilmiah dijadikan sebagai syarat kelulusan mahasiswa S1, S2 dan S3.”
Namun demikian, tidak semua karya
ilmiah yang dihasilkan tersebut
memiliki kualitas yang baik.
Penulisan Kata
Tanda Baca
Tidak Sesuai Ejaan Yang Disempurnakan
TUJUAN PENELITIAN
Expert system Kualitas karya tulis
jadi lebih baik
Membantu dunia keilmiahan Indonesia dalam upaya meningkatkan kualitas tulisan
karya ilmiah Koreksi kesalahan
METODE/TEKNIK YANG DITERAPKAN
Metode yang diterapkan menggunakan Algoritma Boyer-Moore.
CARA KERJA
Heuristik looking-glass :
Perbandingkan suatu karakter akhir pada kata w dengan suatu karakter pada teks s. Jika karakter tersebut sama maka jendela karakter akan berjalan mundur pada kedua string dan memeriksa kembali kedua karakter.
Heuristik character-jump :
HASIL DAN PEMBAHASAN/DISKUSI
PEMBAHASAN
Untuk dapat mengetahui tingkat performansi suatu sistem yang mampu mendapatkan kembali informasi-informasi tertentu dapat diketahui menggunakan perhitungan presisi dan recall. Presisi merupakan probabilitas informasi yang relevan dari semua informasi yang didapatkan kembali oleh sistem. Rumus untuk menghitung presisi dan recall :
rumus presisi (P) berdasarkan table
contingency
rumus recall (R) berdasarkan tabel
contingency
Rumus perhitungan akurasi berdasarkan
HASIL DAN PEMBAHASAN/DISKUSI
KESIMPULAN
Berdasarkan hasil penelitian dan implementasi sistem,maka dapat diambil kesimpulan sebagai berikut :
1. Sistem dapat membangkitkan telaah kesalahan tanda baca berdasarkan kesalahan yang dideteksi dari karya ilmiah serta penggunaan algoritma pencarian kata (dalam kasus ini menggunakan algoritma Boyer-Moore) dapat digunakan pada kasus-kasus pendeteksian kesalahan tanda baca yang berhubungan dengan penggunaan spasi atau tidak, serta penggunaan huruf kapital atau huruf normal.
APLIKASI KOREKSI KESALAHAN BERBASIS PADA TULISAN BERBAHASA INDONESIA UNTUK MENINGKATKAN KUALITAS PENULISAN KARYA ILMIAH
Andri, Sunda Ariana, Margareta Andriani
Fakultas Ilmu Komputer
Universitas Bina Darma Palembang
Prosiding Seminar Nasional Aplikasi Sains & Teknologi (SNAST) 2014 ISSN: 1979-911X
Yogyakarta, 15 November 2014
LATAR BELAKANG MASALAH
Indikasi penguasaan Bahasa Indonesia yang rendah dapat dilihat dari rendahnya nilai rata-rata Bahasa Indonesia dibandingkan dengan bahasa Inggris pada Ujian Nasional (Ariana, 2010).
Kebiasaan berbicara sehari-hari dengan Bahasa
daerah
Kurang menguasai Bahasa Indonesia yang
TUJUAN PENELITIAN
Membuat sebuah
program aplikasi
berbasis komputer
Mengkoreksi
kesalahan
penggunaan EYD
Memperbaiki
kesalahan
Metode/Teknik Yang Diterapkan
Analisis kebutuhan sistem
Perancangan aplikasi
Implementasi dan penerapan
algoritma
Kesimpulan
HASIL DAN PEMBAHASAN
Bentuk user interface aplikasi pada penelitian ini
Metode yang digunakan untuk penentuan solusi kata yang tidak sesuai dengan EYD dalam penelitian ini menggunakan metode N-Gram.
N-Gram merupakan sebuah metode yang diaplikasikan untuk pembangkitan kata atau karakter. Menurut (Gergely, 2005) N Gram adalah substring sepanjangn karakter dari sebuah string. Metode N-Gram digunakan untuk mengambil potongan-potongan karakter huruf sejumlah n dalam sebuah kata yang secara kontinu dibaca dari kata sumber hingga akhir dari dokumen. Contoh pada kata “TEXT” dapat dijelaskan ke dalam beberapa N-Gram sebagai berikut:
Uni-gram : T,E,X,T
Bi-gram : TE,EX,XT
Tri-gram : TEX,EXT
Quad-gram : TEXT,EXT
Salah satu keunggulan menggunakan N-Gram dan bukan suatu kata utuh secara keseluruhan adalah bahwa N-Gram tidak terlalu sensitif terhadap kesalahan penulisan yang terdapat pada suatu dokumen (Hanafi, 2009).
KESIMPULAN
Dari proses implementasi dan pengujian dapat diambil beberapa kesimpulan sebagai berikut:
1. Aplikasi koreksi yang dibuat dapat mendeteksi kesalahan-kesalahan yang terjadi pada dokumen-dokumen Bahasa Indonesia.
APLIKASI PREDICTIVE TEXT BERBAHASA INDONESIA
DENGAN METODE N-GRAM
Silvia Rostianingsih, Sendy Andrian Sugianto, Liliana.
Program Studi Teknik Informatika Fakultas Teknologi Industri Universitas Kristen Petra.
E-mail: [email protected], [email protected]
LATAR BELAKANG MASALAH
PROSES PENGETIKAN LAMA
SERINGNYA TERJADI KESALAHAN KETIK (TYPO)
EXPERT SYSTEM
TUJUAN PENELITIAN
MEMPERCEPAT DALAM PENGETIKAN
SUATU KATA
KUALITAS KARYA TULIS JADI LEBIH
BAIK MEMPERMUDAH
PENGETIKAN KARYA TULIS ILMIAH
METODE/TEKNIK YANG DITERAPKAN
CARA KERJA
Metodologi penelitian dilakukan dengan mempelajari tentang metode N-Gram-Based, dilanjutkan dengan membuat perancangan sistem tentang pengolahan kata dan metode scoring kata. Pembuatan perangkat lunak yaitu dengan mengimplementasikan desain sistem yang telah dibuat ke dalam bahasa pemrograman, meliputi language model, frequency scoring, semantic scoring,
Ngram scoring. Selanjutnya dilakukan pengujian aplikasi dalam melakukan
DESAIN SISTEM
HASIL DAN PEMBAHASAN/DISKUSI
Pengujian dilakukan antara lain mengujibobot dari tiap metode scoring-nya, yakni
Keystroke Saving (KS) dan Score Prediksi Efektif (SPE). Pengujian dengan menghitung keystroke saving adalah untuk menghitung seberapa banyak karakter yang dapat dihemat untuk menghasilkan sebuah teks tertentu. SPE didapat dari jumlah prediksi efektif yang terjadi dibandingkan dengan jumlah total prediksi yang terjadi. Hasil perhitungan yang didapat dari pengujian pada Bigram (Tabel 1) dan Trigram (Tabel 2) menunjukkan nilai yang hampir sama. Sedangkan untuk
KESIMPULAN
Dari hasil penelitian dapat disimpulkan:
1. Rata-rata keystroke saving yang dihasilkan pada pengujian ini adalah 15 hingga 25 persen bergantung pada data training.
2. Rata-rata prediksi efektif terjadi di atas 30% dari total prediksi yang terjadi. Hal ini dikarenakan oleh pengaruh dari language model yang dapat langsung memprediksi kata dengan lebih efektif dan akurat.
3. Frekuensi dari language model yang tinggi sangat mempengaruhi scoring
sistem, karena semakin tinggi frekuensi language model suatu kata, maka akan semakin tinggi pula bobot / nilai dari kata itu sendiri.
Koreksi Ejaan Istilah Komputer Berbasis Kombinasi Algoritma
Damerau Levenshtein dan Algoritma Soundex
Akhmad Pahdi
STMIK Banjarbaru
Journal Speed – Sentra Penelitian Engineering dan Edukasi – Volume 8 No 2 - 2016 ISSN : 1979-9330 (Print) - 2088-0154 (Online)
LATAR BELAKANG MASALAH
TUJUAN PENELITIAN
METODE/TEKNIK YANG DITERAPKAN
Metode yang diterapkan menggunakan algoritma Damerau-Levenshtein dikombinasikan dengan algoritma Soundex..
CARA KERJA
Damerau-Levenshtein mencari jarak terpendak dalam
mentransformasi kata menjadi kata yang lain, selanjutnya
PEMBAHASAN
Algoritma Damerau-Levenshtein Algoritma Soundex
1.Inisialisasikan n sebagai panjang karakter dari s dan m sebagai panjang karakter dari t. Jika n = 0 atau m = 0, maka kembalikan nilai (return value) berupa jarak edit dengan rumusan:
jarak_edit = max(n, m) lalu lompat ke langkah 7.
2. Buat sebuah matriks d sebanyak m + 1 baris dan n + 1 kolom.
3. Isi baris pertama dengan 0..n dan isi kolom pertama dengan 0..m.
4. Periksa setiap karakter dari s terhadap t
Jika s[i] = t[j] maka cost = 0.
Jika s[i] ≠ t[j] maka cost = 1.
5. Isikan nilai dari setiap sel d[i, j] baris per baris dengan:
d[i, j] = min(x, y, z)
1. Ubah semua huruf menjadi huruf besar atau
uppercase, buang semua huruf vokal, tanda baca yang tidak ada hubungan dengan kata, konsonan H,W, dan Y, serta urutan huruf yang sama (misalnya. sss). Huruf pertama selalu dibiarkan seperti semula. 2. Gabung huruf pertama dengan angka pengganti
yang sesuai dengan kode numerik yang ditunjukkan pada Tabel 2.1.
PROSES PENCOCOKAN KATA
Pencarian kata yang sesuai
Kata kunci : getwey Jumlah karakter : 6
1. Inisialisasi n sebagai panjang karakter kata kunci, dan m sebagai panjang karakter kata-kata yang akan diukur jarak kedekatannya
(asumsi, kata “activity”), sehingga mendapatkan penghitungan jumlah n=6 dan jumlah m=8
2. Buat matrix d sebanyak m+1 dan n+1 kolom.
3. Pada matriks yang telah dibuat, isi baris pertama dengan 0..n dan isi kolom pertamadengan 0..m.
4. Periksa setiap karakter dari s terhadap t.
5. Isikan nilai dari setiap sel d[i, j] baris per baris. Langkah ini akan selalu berulang sampai semua matriks terisi.
d[1,1] = min((d[1-1,1]+1),(d[1,1-1]+1),(d[1-1,1-1]+cost)) = min((d[0,1]+1),(d[1,0]+1),(d[0,0] +1))
= min(2,2,1) = 1
d[1,2] = min((d[1-1,2]+1),(d[1,2-1]+1),(d[1-1,2-1]+cost)) = min((d[0,2]+1),(d[1,1]+1),(d[0,1]+1))
= min(3,2,2) = 2
6. Setelah langkah iterasi di atas selesai, maka jarak edit akan ditemukan pada sel d[n, m] yaitu sel pada pojok kanan baris terakhir.
KESIMPULAN
ARSITEKTUR UNTUK APLIKASI DETEKSI KESAMAAN DOKUMEN
BAHASA INDONESIA
Anna Kurniawati, Kemal Ade Sekarwati, I wayan Simri Wicaksana
Fakultas Ilmu komputer dan Teknologi Informasi Universitas Gunadarma
Konferensi Nasional Sistem Informasi 2012,STMIK - STIKOM
Bali , 23-25 Pebruari 2012
Latar Belakang
kata pada judulMencari kesamaan pada gabungan kata dan kalimat
Mencari kesamaan pada arti dari keseluruhan kata
paragraf dan dokumen
Aplikasi Tessy
Plagiat masih bisa
dilakukan dan ditemukan pada hasil karya tulis mahasiswa.
Belum mempertimbangan struktur kalimat dan
sinonim untuk
membandingkan kalimat.
Menggunakan Metode Keyword Similarity dengan teknik DOT. Objek Penelitian yang digunakan adalah
dokumen berbahasa Inggris. Dokumen yang digunakan sebanyak 20 data.
Menggunakan Metode Dokumen fingerprinting dengan algoritma
Winnowing.
Peneliti :
Saul Schleimer 2003, Noorzima 2005
Peneliti :
Parvati Iyer, 2005
Peneliti :
Sinta Agustina 2008, Hari Bagus, 2003.
Menggunakan metode String matching
dengan algoritma Karp Rabin. Objek Penelitian yang digunakan
adalah dokumen berbahasa Indonesia.
• Kemiripan kalimat
• Rata-rata kemiripan kalimat
• Rata-rata maksimum kemiripan dokumen