0 rtment of Higher Education as a Private Higher Education Institution under the Higher Education Act,
1997. Registration Certificate No. 2000/HE07/008
AC U L T Y O F B U S I N E S S ,
EC O N O M I C S &
A N A G EM EN T S C IEN C ES
Q U A L I F I C A T I O N T I T L E :
B A C H EL O R O F C O M M ER C E
L E A R N E R G U I D E
S : M A R K E T I N G M A N A G E M E N T 5 1 1 ( 1
S TS E M E S T E R )
PREPARED ON BEHALF OF
NI N G & B U S I N E S S C O L L E G E (P T Y ) L T D
U TH O R : D r . L a w r e n c e L e k h a n y a
I T O R : Mr . S i m b r a s h e M a g w a g w a
C U L T Y HE A D : P r o f . R o s h M a h a r a j
C o p y r i g h t © 2 0 1 3
T r a i n i n g & B u s i n e s s C o l l e g e (P t y ) L t d e g i s t r a t i o n N u m b e r : 2 0 0 0 / 0 0 0 7 5 7 / 0 7
rved; no part of this publication may be reproduced in r by any means, including photocopying machines, out the written permission of the Institution.
BUSINESS ADMINISTRATION, MANAGEMENT &
COMMERCIAL SCIENCES
BUSINESS STATISTICS 511
1 Previously
BUSINESS ADMINISTRATION, MANAGEMENT
& COMMERCIAL SCIENCES
LEARNER GUIDE
MODULE: BUSINESS STATISTICS 511
(1
STSEMESTER)
Copyright © 2017
Richfield Graduate Institute of Technology (Pty) Ltd Registration Number: 2000/000757/07
2
6. Lectures and Tutorials 5
7. Notices 5
8. Prescribed & Recommended Material 5
9. Assessment & Key Concepts in Assignments and Examinations 6
10.Specimen Assignment Cover Sheet 10
11.Work Readiness Programme 11
12.Work Integrated Learning 12
Section B:
TOPIC 1: INTRODUCTION TO DESCRIPTIVE STATISTICS
1.1 What Is Statistics? 17
1. 2 Descriptive Statistics 17
1.3. Inferential Statistics 18
2.10 Shape The Distribution 36
2.11 Skewness 36
2.12 Kurtosis 37
2.13 Types Of Graphs 38
Assessment questions 41
3
1.
WELCOMEWelcome to the Faculty of Business, Economics& Management Sciences at Richfield Graduate Institute of Technology (Pty) Ltd. We trust you will find the contents and learning outcomes of this module both interesting and insightful as you begin your academic journey and eventually your career in the business world.
This section of the study guide is intended to orientate you to the module before the commencement of formal lectures.
The following lecturers will focus on the study units described.
3.1. Scatter Plots 44
TOPIC 5: DISCRETE PROBABILITY DISTRIBUTION
5.1 Permutations And Combinations 60 5.2 Binomial Probability Distribution 62
5.3 The Poisson Distribution 64
Assessment questions 66
TOPIC 6: CONTINUOUS PROBABILITY DISTRIBUTION
6.1 What Is A Normal Distribution 67
6.2 The Standard Normal Distribution 68
6.3 Converting To Percentiles And Back 69
6.4 Area Under Portions Of The Curve 71
Assessment Questions 73
TOPIC 7: ADDENDUM 511 (A): REVISION QUESTIONS
78
TOPIC 8: ADDENDUM 511 (B): TYPICAL EXAMINATION
QUESTIONS
80
SECTION A: WELCOME & ORIENTATION
Study unit 1: Orientation Programme
Introducing academic staff to the students by academic head. Introduction of institution policies.
Lecture 1
4
2.
TITLE OF MODULES, COURSE, CODE, NQF LEVEL, CREDITS & MODE OF
DELIVERY
Semester 1
Title of Module Business Statistics 511
Code BUS_511
NQF level 5
Credits 10
Mode of delivery Contact/Distance
3.
PURPOSE OF THE MODULES
These introductory courses covers the concepts and techniques concerning explanatory data analysis, frequency distributions, central tendency and variation, probability, sampling, inference, regression and correlation. Students will be exposed to these topics and how each applies to and can be used in the business environment. Students will master problem solving both manual computations and statistical software
4.
LEARNING OUTCOMES
On completion of these modules the student will be able to:
Appreciate the role of statistics in management decision making.
develop an intuitive understanding of the techniques by giving an explanation for each method and interpretation of the solutions
Have a general understanding of basic probability concepts
Understand the statistical measures which condense and describe the characteristics of raw data
Introducing students to physical structures
Issuing of foundation learner guides and necessary learning material
Study unit 3: Distribution and Orientation of Business Statistics Learner
Guides, Textbooks and Prescribed Materials Lecture 3
Study unit 4: Discussion on the Objectives and Outcomes of Business
Statistics 511 Lecture 4
Study unit 5: Orientation and guidelines to completing Assignments
Review and Recap of Study units 1-4
Lecture 5
5
5.
METHOD OF STUDY
The sections that have to be studied are indicated under each topic. These form the basis for tests, assignments and examination.
To be able to do the activities and assignments for this module, and to achieve the learning outcomes and ultimately to be successful in the tests and examination, you will need an in-depth understanding of the content of these sections in the learning guide and prescribed book. In order to master the learning material, you must accept responsibility for your own studies. Learning is not the same as memorizing. You are expected to show that you understand and are able to apply the information. Use will also be made of lectures, tutorials, case studies and group discussions to present this module.
6.
LECTURES AND TUTORIALS
Students must refer to the notice boards on their respective campuses for details of the lecture and tutorial time tables. The lecturer assigned to the module will also inform you of the number of lecture periods and tutorials allocated to a particular module. Prior tables, assignments, examinations etc. will be displayed on the notice board located on your campus. Students must check the notice board on a daily basis.
Should you require any clarity, please consult your lecturer, or programme manager, or administrator on your respective campus.
8.
PRESCRIBED & RECOMMENDED MATERIAL
8.1 Prescribed Material
The prescribed text books for this module
Wegner, T. 2016. Applied Business Statistics: Methods and Excel-basic applications. 4th ed. Cape Town: Juta.
Business statistics 511 has a well balanced approach in that it is structured such that it not only informs and educates you about the theoretical back-ground required in the business world, but also has a powerful practical element / component. Our practical syllabus follows strongly in line with that of strong management principles and standards currently employed by many enterprises today.
8.2 Recommended Material
Willemse, I. and Nyelisani, P. 2015. Statistical Methods and Calculation Skills. 4th ed. Cape
Town: Juta & Company Ltd.
6
8.3 Independent Research:
The student is encouraged to undertake independent research with emphasis on the Presentation and interpretation of the data collected.
8.4 Library Infrastructure
The following services are available to you:
Each campus keeps a limited quantity of the recommended reading titles and a larger variety of similar titles which you may borrow. Please note that students are required to purchase the prescribed materials.
Arrangements have been made with municipal, state and other libraries to stock our recommended reading and similar titles. You may use these on their premises or borrow them if available. It is your responsibility to safe keeps all library books.
RGI has also allocated one library period per week as to assist you with your formal research under professional supervision.
RGI has dedicated electronic libraries for use by its students. The computers laboratories, when not in use for academic purposes, may also be used for research purposes. Booking is essential for all electronic library usage.
9.
ASSESSMENT
Final Assessment for this module will comprise two CA tests, an assignment and an examination. Your lecturer will inform you of the dates, times and the venues for each of these. You may also refer to the notice board on your campus or the Academic Calendar which is displayed in all lecture rooms.
9.1CA Tests
There are two compulsory tests for each module (in each semester).
9.2Assignment
There is one compulsory assignment for each module in each semester. Your lecturer will inform you of the Assessment questions at the commencement of this module. It is therefore necessary to study on an ongoing basis.
9.3Examination
There is one two hour examination for each module. Make sure that you diarize the correct date, time and venue. The examinations FACULTY will notify you of your results once all administrative matters are cleared and fees are paid up.
The examination may consist of multiple choice questions, short questions and essay type questions. This requires you to be thoroughly prepared as all the content matter of lectures, tutorials, all references to the prescribed text and any other additional documentation/reference materials is examinable in both your tests and the examinations.
The examination FACULTY will make available to you the details of the examination (date, time and venue) in due course.
7
9.4 Final Assessment
The final assessment for this module will be weighted as follows:
CA Test 1 + CA Test 2 + Assignment = 40% Examination = 60% Total = 100%
9.5 Key Concepts in Assignments and Examinations
In assignment and examination questions you will notice certain key concepts (i.e.
words/verbs) which tell you what is expected of you. For example, you may be asked in a
question to list, describe, illustrate, demonstrate, compare, construct, relate, criticize,
recommend or design particular information/aspects/factors /situations. To help you to
know exactly what these key concepts or verbs mean so that you will know exactly what is
expected of you, we present the following taxonomy by Bloom, explaining the concepts and
stating the level of cognitive thinking that theses refer to.
Competence Skills Demonstrated
Knowledge
observation and recall of information knowledge of dates, events, places knowledge of major ideas
mastery of subject matter
Question Cues
list, define, tell, describe, identify, show, label, collect, examine, tabulate, quote, name, who, when, where, etc.
Comprehension
understanding information grasp meaning
translate knowledge into new context interpret facts, compare, contrast order, group, infer causes
predict consequences
Question Cues
summarize, describe, interpret, contrast, predict, associate, distinguish, estimate, differentiate, discuss, extend
Application
use information
use methods, concepts, theories in new situations solve problems using required skills or knowledge
Questions Cues
apply, demonstrate, calculate, complete, illustrate, show, solve, examine, modify, relate, change, classify, experiment, discover
Analysis
seeing patterns organization of parts
8
Question Cues
analyze, separate, order, explain, connect, classify, arrange, divide, compare, select, explain, infer
Synthesis
use old ideas to create new ones generalize from given facts
relate knowledge from several areas predict, draw conclusions
Question Cues
combine, integrate, modify, rearrange, substitute, plan, create, design, invent, what if?, compose, formulate, prepare, generalize, rewrite
Evaluation
compare and discriminate between ideas assess value of theories, presentations make choices based on reasoned argument verify value of evidence recognize subjectivity
Question Cues
9
10.
Specimen Assignment Cover Sheet
BUSINESS ADMINISTRATION, MANAGEMENT & COMMERCIAL SCIENCES
BUSINESS STATISTICS 511 ASSIGNMENT COVER SHEET
1
STSEMESTER ASSIGNMENT
Name & Surname: ______________________________ ICAS No: _________________
Qualification: ______________________ Semester: _____
Module Name: __________________________
Specialization: _____________________ Date Submitted: ___________
QUESTION NUMBER MARK ALLOCATION EXAMINER MARKS MODERATOR
MARKS
TOTAL
Examiner’s Comments:
Moderator’s Comments:
Signature of Examiner: Signature of Moderator:
The purpose of an assignment is to ensure that the student is able to:
make informed decisions based on data
correctly apply a variety of statistical procedures and tests
know the uses, capabilities and limitations of various statistical procedures
interpret the results of statistical procedures and testsInstructions and guidelines for writing assignments
10
2. All essay type assignments must include the following: 2.1 Table of contents
2.2 Introduction
2.3 Main body with subheadings 2.4 Conclusions and recommendations 2.5 Bibliography
3. The length of the entire assignment must have minimum of 5 pages, preferably typed with font size 12
3.1 The quality of work submitted is more important than the number of assigned pages.
4. Copying is a serious offence which attracts a severe penalty and must be avoided at all costs. If any student transgresses this rule, the lecturer will retain the assignments and ask the affected students to resubmit a new assignment which will be capped at 50%. 5. Use the Harvard referencing method.
ASSESSMENT CRITERIA
When the final mark is calculated the following criteria must be taken into account:
1. READING AND KNOWLEDGE OF SUBJECT MATTER
Wide reading and comprehensive knowledge in the application of theory
2. UNDERSTANDING, ANALYSIS AND ARGUMENT
Complete and perceptive awareness of issues and clear grasp of their wider significance. Clear evidence of independent thought and ability to defend a position logically and convincingly.
3. ORGANISATION AND PRESENTATION
Careful thought given to arrangement and development of material and argument.
Good English with appropriate referencing and comprehensive bibliography.
ASSIGNMENT GUIDELINES
The purpose of an assignment is to ensure that the student is able to:
Interpret, convert and evaluate text.
Have sound understanding of key fields viz principles and theories, rules, concepts and
awareness of how to cognate areas.
Solve unfamiliar problems using correct procedures and corrective actions.
Investigate and critically analyse information and report thereof.
Present information using Information Technology.
Present and communicate information reliably and coherently.
Develop information retrieval skills.
11
ASSESSMENT CRITERIA
When the final Mark is allocated the above criteria must be taken into account
A. Content- Relevance: Has the student Answered the Question
B. Research (A minimum of “TEN SOURCES” is recommended) Reference , books, Internet,
Newspapers, Text Books
C. Presentation : Introduction, Body, Conclusion, Paragraphs, Neatness, Integration,
Grammar / Spelling, Page Numbering, Diagrams, Tables, Graphs, Bibliography
NB: All Assignments are compulsory as they form part of continuous assessment that
counts towards the final mark
11.
WORK READINESS PROGRAMME (WRP)In order to prepare students for the world of work, a series of interventions over and above the formal curriculum, are concurrently implemented to prepare students. These include:
Soft skills
Employment skills
Life skills
End –User Computing (if not included in your curriculum)
The illustration below outlines some of the key concepts for Work Readiness that will be included in your timetable.
12
12.
WORK INTEGRATED LEARNING (WIL)Work Integrated Learning forms a core component of the curriculum for the completion of this programme. All modules which form part of this qualification will be assessed in an integrated manner towards the end of the programme or after completion of all other modules.
Prerequisites for placement with employers will include:
Completion of all tests & assignment
Success in examination
Payment of all arrear fees
Return of library books, etc.
Completion of the Work Readiness Programme.
Students will be fully inducted on the Work Integrated Learning Module, the Workbooks & assessment requirements before placement with employers.
13
SECTION B
LEARNER GUIDE
MODULE: BUSINESS STATISTICS 511, 1
stSEMESTER
TOPIC 1: INTRODUCTION TO DESCRIPTIVE STATISTICS
TOPIC 2: DESCRIBING UNIVARIATE DATA
TOPIC 3: CORRELATION SIMPLE LINEAR REGRESSION ANALYSIS
TOPIC 5: INTRODUCTION TO PROBALITY
TOPIC 6: CONTINUOUS PROBABILITY DISTRIBUTION
ADDENDUM 511 (A): REVISION QUESTIONS
ADDENDUM 511 (B): TYPICAL EXAMINATION QUESTIONS
1.7 Summation Notation Lecture 8
1.8 Measurement Scales Assessment questions
14
3.2 3.2. Introduction To Pearson's Correlation 3.3 3.3 Regression Analysis
Assessment questions
TOPIC 4: INTRODUCTION TO PROBALITY
4.1 Simple Probability
TOPIC 5: DISCRETE PROBABILITY DISTRIBUTION
5.1 Permutations And Combinations Lecture 36-37 5.2 Binomial Probability Distribution
5.3 The Poisson Distribution Assessment questions
TOPIC 6: CONTINUOUS PROBABILITY
DISTRIBUTION
6.1 What Is A Normal Distribution
Lecture 38- 41
6.2 The Standard Normal Distribution 6.3 Converting To Percentiles And Back 6.4 Area Under Portions Of The Curve
Assessment Questions
TOPIC 7: ADDENDUM 511 (A): REVISION
QUESTIONS
15
The following are guide icons that will be used throughout this learner guide:
Icon Description
Learning Outcomes
Study
Read
Writing Activity
Think Point
Research
Glossary
Key Points
16
Case Study
Bright Idea
Problem(s)
Multimedia Resource
Web Resource
TOPIC 1
17
Learning Outcomes:
In this topic you will learn about the term ‘statistics’
and the use of it.
Knowledge about two types of statistics namely descriptive and inferential.
An ability to use variables and parameters. You will learn about different measuring scales nominal, ordinal, interval, and ratio.
1.1 WHAT IS STATISTICS?
The word "statistics" is used in several different senses. In the broadest sense, "statistics" refers to a range of techniques and procedures for analyzing data, interpreting data, displaying data, and making decisions based on data. This is what courses in "statistics" generally cover.
In a second usage, a "statistic" is defined as a numerical quantity (such as the mean) calculated from a sample. Such statistics are used to estimate parameters.
The term "statistics" sometimes refers to calculated quantities regardless of whether or not they are from a sample. For example, one might ask about a baseball player's statistics and be referring to his or her batting average, runs batted in, number of home runs, etc. Or, "government statistics" can refer to any numerical indexes calculated by a governmental agency.
Although the different meanings of “statistics” have the potential for confusion, a careful
consideration of the context in which the word is used should make its intended meaning clear.
1. 2 DESCRIPTIVE STATISTICS
One important use of statistics is to summarize a collection of data in a clear and understandable way. For example, assume a psychologist gave a personality test measuring shyness to all 2500 students attending a small college. How might these measurements be summarized?
There are two basic methods: numerical and graphical. Using the numerical approach one might compute statistics such as the mean and standard deviation.
These statistics convey information about the average degree of shyness and the degree to which people differ in shyness. Using the graphical approach one might create a stem and
leaf display and a box plot. These plots contain detailed information about the distribution
18
Graphical methods are better suited than numerical methods for identifying patterns in the data. Numerical approaches are more precise and objective. Since the numerical and graphical approaches complement each other, it is wise to use both but not at the same time for the same data.
1.3. INFERENTIAL STATISTICS
Inferential statistics are used to draw inferences about a population from a sample.
Consider an experiment in which 10 subjects who performed a task after 24 hours of sleep deprivation scored 12 points lower than 10 subjects who performed after a normal night's sleep. Is the difference real or could it be due to chance? How much larger could the real difference be than the 12 points found in the sample? These are the types of questions answered by inferential statistics.
There are two main methods used in inferential statistics: estimation and hypothesis testing. In estimation, the sample is used to estimate a parameter and a confidence interval
about the estimate is constructed.
In the most common use of hypothesis testing, a "straw man" null hypothesis is put forward and it is determined whether the data are strong enough to reject it. For the sleep deprivation study, the null hypothesis would be that sleep deprivation has no effect on performance.
(Population: A population consists of an entire set of objects, observations, or scores that
have something in common. For example, a population might be defined as all males between the ages of 15 and 18.
Some populations are only hypothetical. Consider an experimenter interested in the possible effectiveness of a new method of teaching reading. He or she might define a population as the reading achievement scores that would result if all six year olds in the US were taught with this new method.
The population is hypothetical in the sense that it does not exist a group of students who have been taught using the new method; the population consists of the scores that would be obtained if they were taught with this method.
The distribution of a population can be described by several parameters such as the mean
and standard deviation. Estimates of these parameters taken from a sample are called
19
Quantitative and Qualitative
Variables can be quantitative or qualitative. Qualitative variables are sometimes called "categorical variables”. Quantitative variables are measured on an ordinal, interval, or ratio
scale; qualitative variables are measured on a nominal scale. If five-year old subjects were asked to name their favourite colour, then the variable would be qualitative. If the time it took them to respond were measured, then the variable would be quantitative.
Independent and Dependent variable
When an experiment is conducted, some variables are manipulated by the experimenter and others are measured from the subjects. The former variables are called "independent variables"; or "factors," the latter are called "dependent variables" or "dependent
measures."
For example, consider a hypothetical experiment on the effect of drinking alcohol on reaction time: Subjects drank water, one beer, three beers, or six beers and then had their reaction times to the onset of a stimulus measured. The independent variable would be the number of beers drunk (0, 1, 3, or 6) and the dependent variable would be reaction time.
Continuous and Discrete variable
Some variables (such as reaction time) are measured on a continuous scale. There are an infinite number of possible values these variables can take on.
Other variables can only take on a limited number of values. For example, if a dependent variable were a subject's rating on a five- point scale where only the values 1, 2, 3, 4, and 5 were allowed, then only five possible values could occur. Such variables are called "discrete" variables.
Nominal: Nominal measurement consists of assigning items to groups or categories. No
quantitative information is conveyed and no ordering of the items is implied. Nominal scales are therefore qualitative rather than quantitative. Religious preference, race, and sex are all examples of nominal scales. Frequency distributions are usually used to analyze data measured on a nominal scale. The main statistic computed is the mode. Variables measured on a nominal scale are often referred to as categorical or qualitative variables.
Ordinal: Measurements with ordinal scales are ordered in the sense that higher numbers
represent higher values. However, the intervals between the numbers are not necessarily equal. For example, on a five-point rating scale measuring attitudes toward gun control, the difference between a rating of 2 and a rating of 3 may not represent the same difference as the difference between a rating of 4 and a rating of 5. There is no "true" zero point for ordinal scales since the zero point is chosen arbitrarily. The lowest point on the rating scale in the example was arbitrarily chosen to be 1. It could just as well have been 0 or -5.
Interval: On interval measurement scales, one unit on the scale represents the same
20
measurement is somewhere between rare and non-existent in the behavioural sciences. No interval-level scale of anxiety such as the one described in the example actually exists. A good example of an interval scale is the Fahrenheit scale for temperature. Equal differences on this scale represent equal differences in temperature, but a temperature of 30 degrees is not twice as warm as one of 15 degrees.
Ratio: Ratio scales are like interval scales except they have true zero points. A good example
is the Kelvin scale of temperature. This scale has an absolute zero. Thus, a temperature of 300 Kelvin is twice as high as a temperature of 150 Kelvin.
1.5 PARAMETERS
A parameter is a numerical quantity measuring some aspect of a population of scores. For example, the mean is a measure of central tendency.
Greek letters are used to designate parameters. At the bottom of this page are shown several parameters of great importance in statistical analyses and the Greek symbol that represents each one. Parameters are rarely known and are usually estimated by statistics
computed in samples. To the right of each Greek symbol is the symbol for the associated statistic used to estimate it from a sample.
Quantity Parameter Statistic
Mean μ
x
Standard deviation σ s
Proportion π p
Correlation ρ r
Central tendency: Measures of central tendency are measures of the location of the middle
or the centre of a distribution. The definition of "middle" or "centre" is purposely left somewhat vague so that the term "central tendency" can refer to a wide variety of measures. The mean is the most commonly used measure of central tendency. The following measures of central tendency are discussed in this text:
Mean
Median
Mode
1.6 SUMMATION NOTATION
The Greek letter Σ (a capital sigma) is used to designate summation. For example, suppose
an experimenter measured the performance of four subjects on a memory task. Subject 1's score will be referred to as X 1 , Subject 2's as X 2 , and so on.
21
The way to use the summation sign to indicate the sum of all four X's is:
This notation is read as follows: Sum the values of X from X1 through X4. The index i (shown
just under the Σsign) indicates which values of X are to be summed. The index i takes on
values beginning with the value to the right of the "=" sign (1 in this case) and continues
sequentially until it reaches the value above the Σ sign (4 in this case). Therefore ‘i’ takes on
the values 1, 2, 3, and 4 and the values of X1, X2, X3, and X4 are summed (7 + 6 + 5 + 8 = 26).
In order to make formulas more general, variables can be used with the summation notation. For example,
means to sum up values of X from 1 to N where N can be any number but usually indicates
the sample size.
Often an abbreviated form of the summation notation is used. For example, ΣX means to
sum all the values of X. When only a subset of the values of X is to be summed then the full version is required. Thus, the sum of all elements of X except the first and the last (the N'th) would be indicated as:
which would be read as the sum of X with i going from 2 to N-1.
Some formulas require that each number be squared before the numbers are summed. This is indicated by:
and is equal to 72 + 62 + 52 + 82 = 174.
The abbreviated version is simply: ΣX2. It is very important to note that it makes a big
difference whether the numbers are squared first and then summed or summed first and
then squared. The symbol (ΣX) 2 indicates that the numbers should be summed first and
then squared. For the present example, this equals:
(7 + 6 + 5 + 8)2 = 262 = 676. This, of course, is quite different from 174.
22
Basic Theorems The following data will be used to illustrate the theorems:
X Y
Measurement is the assignment of numbers to objects or events in a systematic fashion. Four levels of measurement scales are commonly distinguished: nominal, ordinal, interval, and ratio.
23
For example, it would be silly to compute the mean of nominal measurements. However, the appropriateness of statistical analyses involving means for ordinal level data has been controversial. One position is that data must be measured on an interval or a ratio scale for the computation of means and other statistics to be valid. Therefore, if data are measured on an ordinal scale, the median but not the mean can serve as a measure of central tendency.
The arguments on both sides of this issue will be examined in the context of a hypothetical experiment designed to determine whether people prefer to work with colour or with black and white computer displays. Twenty subjects viewed black and white displays and 20 subjects viewed colour displays.
Displays were rated on a 7 point scale where a 1 was the lowest rating and a 7 was the highest rating. This rating scale is only an ordinal scale since there is no assurance that the difference between a rating of 1 and a rating of 2 represents the same degree of difference in preference as the difference between a rating of 5 and a rating of 6.
The mean rating of the colour display was 5.5 and the mean rating of the black and white display was 3.9. The first question the experimenter would ask is how likely is it that this big a difference between means could have occurred just because of chance factors such as which subjects saw the black and white display and which subjects saw the colour display. Standard methods of statistical inference can answer this question. Assume these methods led to the conclusion that the difference was not due to chance but represented a "real" difference in means. Does the fact that the rating scale was ordinal instead of interval have any implications for the validity of the statistical conclusion that the difference between means was not due to chance?
The answer is an unequivocal "NO." There is really no room for argument here. What can be questioned, however, is whether it is worth knowing that the mean rating of color displays is higher than the mean rating for B & W displays.
The argument that it is not worth knowing assumes that means of ordinal data are meaningless.
Supporting the notion that means of ordinal data are meaningless is the fact that examples
(see below) can be made up showing that a difference between means on an ordinal scale
can be in the opposite direction of what they would have been if the "true" measurement scale had been used.
If means of ordinal data are meaningless, why should anyone care whether the difference between two meaningless quantities (the two means) is due to chance or not. Naturally enough, the answer lies in challenging the proposition that means of ordinal data are meaningless.
There are two counter arguments to the example showing that using an ordinal scale can reverse the direction of the difference between means.
24
experiment, it may not be the case that the difference between the ratings one and two is exactly the same as the difference between five and six, but it is unlikely to be many times larger either. The scale is roughly interval and it is exceedingly unlikely that the means on this scale would favor color displays while the means on the "true" scale would favor the B & W displays.
There are some cases where one can validly argue that the use of an ordinal instead of a ratio scale seriously distorts the conclusions. Consider an experiment designed to determine whether 5-year old children are more distractible than 10-year old children.
Children of both ages perform a memory task once with and once without distraction. The means are given below:
It looks as though the 10-year olds are more distractible since distraction cost them 4 points but only cost the 5-year olds 3 points. However, it might be that a change from 3 to 6 represents a larger difference than a change from 8 to 12. Consider that the performance of 5-year olds dropped 50% from distraction but the performance of 10-year olds dropped only 33%.
Which age group is "really" more distractible? Unfortunately, there is no clearly right or wrong answer. If proportional change is considered, then 5-year olds are more distractible; if the amount of change is considered then 10-year olds are more distractible. Keep in mind that statistical conclusions are not affected by the choice of measurement scale even though the all-important interpretation of these conclusions can be.
In this example, a statistical test could validly rule out chance as an explanation of the finding that 10-year olds lost more points from distraction than did 5-year olds. However, the statistical test will not reveal whether a greater drop necessarily means 10-year olds are more distractible. So the conclusion that distraction costs 10-year olds more points than it costs 5-year olds is valid. The interpretation depends on measurement issues.
In summary, statistical analyses provide conclusions about the numbers entered into them. Relating these conclusions to the substantive research issues depends on the measurement operations.
Examples: Assume there were a "true" measurement scale for job satisfaction and that it
25
Thus if someone's "true" job satisfaction were 55 he or she would have a rated score of 4. Now consider the following two sets of job satisfaction scores:
Group A Group B
True Scale Rating True Scale Rating
On the "true" scale the mean for Group B is 61.8, which is much higher than the mean for Group A that is 48.2. However on the 7-point rating scale, the mean for B is only 3.8 which is lower than the mean for A of 4.2.
Problems:
1. A teacher wishes to know whether the male in his/her class have more favorable attitudes toward gun control than do the female. All students in the class are given a questionnaire about gun control and the mean responses of the males and the females are compared. Is this an example of descriptive or inferential statistics?
2. A medical researcher is testing the effectiveness of a new drug for treating Parkinson's disease. Ten subjects with the disease are given the new drug and 10 are given a placebo. Improvement in symptomology is measured. What would be the roles of descriptive and inferential statistics in the analysis of these data?
3. What are the advantages and disadvantages of graphical as opposed to numerical approaches to descriptive statistics?
4. Distinguish between random and stratified sampling?
5. A study is conducted to determine whether people learn better with spaced or massed
practice. Subjects volunteer from an introductory psychology class. The first 10
26
6. Define independent and dependent variables.
7. Categorize the following variables as being qualitative or quantitative: -Response time
-Rating of job satisfaction -Favorite color
-Occupation aspired to
-Number of words remembered
8. Specify the level of measurement used for the items in Question 7.
9. Categorize the variables in Question 7 as being continuous or discrete.
10.Are Greek letters used for statistics or for parameters?
11.When would the mean score of a class on a final exam be considered a statistic? When would it be considered a parameter?
12.An experiment is conducted to examine the effect of punishment on learning speed in rats. What are the independent and dependent variables?
13.For the numbers 1, 2, 4, 8 Compute: SX, SX2 and (SX) 2
14.SX = 7 and SX2 = 21. A new variable Y is created by multiplying each X by 3. What are SY and SY2 equal to?
For additional reading on this topic, a student must refer to the recommended text book for Business Statistics [Applied Business Statistics, Methods and Excel-basic applications (3rd edition) by: Trevor
27
TOPIC 2
_______
2. DESCRIBING UNIVARIATE DATA
Learning Outcomes:
In this topic you will learn what is central tendency as well as its measures.
Knowledge about shapes, graphs, ranges etc.
2.1 CENTRAL TENDENCY
Measures of central tendency are measures of the location of the middle or the centre of a distribution. The definition of "middle" or "centre" is purposely left somewhat vague so that the term "central tendency" can refer to a wide variety of measures. The mean is the most commonly used measure of central tendency. The following measures of central tendency are discussed in this text: used without a modifier, it can be assumed that it refers to the arithmetic mean. The mean is the sum of all the scores divided by the number of scores. The formula in summation
notation is: μ = ΣX/N where μ is the population mean and N is the number of scores. If the
scores are from a sample, then the symbol M refers to the mean and n refers to the sample
size. The formula for M is the same as the formula for μ. The mean is a good measure of
central tendency for roughly symmetric distributions but can be misleading in skewed
distributions since it can be greatly influenced by extreme scores. Therefore, other statistics such as the median may be more informative for distributions such as reaction time or family income that are frequently much skewed.
The sum of squared deviations of scores from their mean is lower than their squared deviations from any other number.
For normal distributions, the mean is the most efficient and therefore the least subject to
sample fluctuations of all measures of central tendency.
The formal definition of the arithmetic mean is µ = E[X] where μ is the population mean of
28
Geometric Mean
The geometric mean is the nth root of the product of the scores. Thus, the geometric mean of the scores: 1, 2, 3, and 10 is the fourth root of 1 x 2 x 3 x 10 which is the fourth root of 60 which equals 2.78.
The formula can be written as: Geometric mean = ΠX where ΠX means to take the product
of all the values of X.
The geometric mean can also be computed by: 1. Taking the logarithm of each number
2. Computing the arithmetic mean of the logarithms
3. Raising the base used to take the logarithms to the arithmetic mean.
The example on the next page shows an example of this method using natural logarithms.
X Ln(X)
1 0
2 0.693147
3 1.098612
10 2.302585
Geometric mean = 2.78 Arithmetic mean = 1.024. EXP[1.024] = 2.78
The base of natural logarithms is 2.718. The expression: EXP [1.024] means that 2.718 is raised to the 1.024th power. Ln (X) is the natural log of X.
Naturally; you get the same result using logs base 10 as shown below.
X Log(X)
1 0.0000
2 0.30103
3 0.47712
10 1.00000
29
If any one of the scores is zero then the geometric mean is zero. The geometric mean does
not make sense if any scores are less than zero.
The geometric mean is less affected by extreme values than is the arithmetic mean and is
useful as a measure of central tendency for some positively skewed distributions.
The geometric mean is an appropriate measure to use for averaging rates. For example,
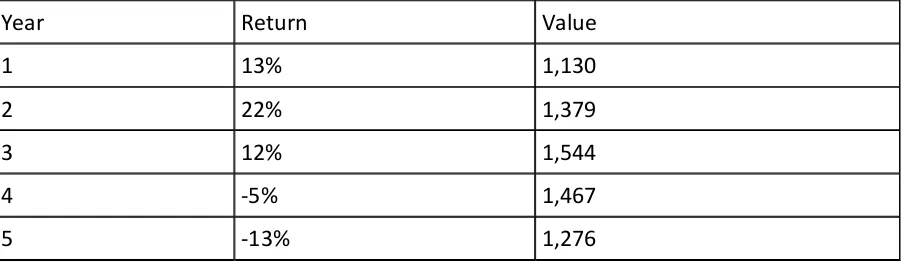
consider a stock portfolio that began with a value of $1,000 and had annual returns of 13%,
22%, 12%, -5%, and -13%. The table below shows the value after each of the five years.
Year Return Value
1 13% 1,130
2 22% 1,379
3 12% 1,544
4 -5% 1,467
5 -13% 1,276
The question is how to compute annual rate of return? The answer is to compute the geometric mean of the returns. Instead of using the percents, each return is represented as a multiplier indicating how much higher the value is after the year. This multiplier is 1.13 for a 13% return and 0.95 for a 5% loss.
The multipliers for this example are 1.13, 1.22, 1.12, 0.95, and 0.87. The geometric mean of these multipliers is 1.05. Therefore, the average annual rate of return is 5%. The following table shows how a portfolio gaining 5% a year would end up with the same value ($1,276) as the one shown above.
Year Return Value
1 5% 1,050
2 5% 1,103
3 5% 1,158
4 5% 1,216
5 5% 1,276
Harmonic Mean
30
For the numbers 1, 2, 3, and 10, the harmonic mean is:
= 2.069. This is less than the geometric mean of 2.78 and the arithmetic mean of 4.
Sample fluctuations: Sampling fluctuation refers to the extent to which statistic takes on
different values with different samples. That is, it refers to how much the statistic's value fluctuates from sample to sample.
A statistic whose value fluctuates greatly from sample to sample is highly subject to sampling fluctuation.
2.3 MEDIAN
The median is the middle of a distribution: half the scores are above the median and half are below the median.
The median is less sensitive to extreme scores than the mean and this makes it a better measure than the mean for highly skewed distributions. The median income is usually more informative than the mean income, for example.
The sum of the absolute deviations of each number from the median is lower than is the sum of absolute deviations from any other number.
The mean, median, and mode are equal in symmetric distributions. The mean is higher than the median in positively skewed distributions and lower than the median in negatively skewed distributions
Computation of Median
When there is an odd number of numbers, the median is simply the middle number. For example, the median of 2, 4, and 7 is 4. Remember to sort out the data values in ascending order first then calculate the median.
When there is an even number of numbers, the median is the mean of the two middle numbers. Thus, the median of the numbers 2, 4, 7, 12 is (4+7)/2 = 5.5.
2.4 MODE
The mode is the most frequently occurring score in a distribution and is used as a measure
of central tendency. The advantage of the mode as a measure of central tendency is that its
meaning is obvious. Further, it is the only measure of central tendency that can be used with
nominal data.
The mode is greatly subject to sample fluctuations and is therefore not recommended to be used as the only measure of central tendency. A further disadvantage of the mode is that many distributions have more than one mode. These distributions are called "multimodal."
31
Summary:
Of the five measures of central tendency discussed, the mean
is by far the most widely used. It takes every score into account, is the most efficient measure of central tendency for
normal distributions and is mathematically tractable making
it possible for statisticians to develop statistical procedures for drawing inferences about means.
On the other hand, the mean is not appropriate for highly
skewed distributions and is less efficient than other measures
of central tendency when extreme scores are possible. The geometric mean is a viable alternative if all the scores are positive and the distribution has a positive skew.
The median is useful because its meaning is clear and it is
more efficient than the mean in highly-skewed distributions. However, it ignores many scores and is generally less efficient than the mean, the trimean, and trimmed means.
The mode can be informative but should almost never be used as the only measure of central tendency since it is highly susceptible to sampling fluctuations.
2.5. SPREAD
A variable's spread is the degree scores on the variable differ from each other.
If every score on the variable were about equal, the variable would have very little spread.
There are many measures of spread. The distributions on the right side of this page have the same mean but differ in spread: The distribution on the bottom is more spread out. Variability and dispersion are synonyms for spread.
Range
Semi-Interquartile Range
Variance
32
2.6 RANGE
The range is the simplest measure of spread or dispersion: It is equal to the difference between the largest and the smallest values.
The range can be a useful measure of spread because it is so easily understood. However, it is very sensitive to extreme scores since it is based on only two values. The range should almost never be used as the only measure of spread, but can be informative if used as a supplement to other measures of spread such as the standard deviation or semi-interquartile range.
Dispersion:
A variable's dispersion is the degree to which scores on the variable differ from each other.
If every score on the variable were about equal, the variable would have very little dispersion. There are many measures of dispersion.
Example
The range of the numbers 1, 2, 4, 6,12,15,19, 26 = 26 -1 = 25
2.7 SEMI-INTERQUARTILE RANGE
The semi-Interquartile range is a measure of spread or dispersion. It is computed as one half the differences between the 75th percentile [often called (Q3)] and the 25th percentile (Q1). The formula for semi-interquartile range is therefore: (Q3-Q1)/2.
Since half the scores in a distribution lie between Q3 and Q1, the semi-interquartile range is 1/2 the distance needed to cover 1/2 the scores. In a symmetric distribution, an interval stretching from one semi-interquartile range below the median to one semi-interquartile above the median will contain 1/2 of the scores. However, this will not be true for a skewed
distribution.
The semi-interquartile range is little affected by extreme scores, so it is a good measure of spread for skewed distributions. However, it is more subject to sampling fluctuation in
normal distributions than is the standard deviation and therefore not often used for data
that are approximately normally distributed.
Dispersion: A variable's dispersion is the degree to which scores on the variable differ from
each other. If every score on the variable were about equal, the variable would have very little dispersion. There are many measures of dispersion.
2.8 VARIANCE
The variance is a measure of how spread out a distribution is. It is computed as the average squared deviation of each number from its mean.
For example, for the numbers 1, 2, and 3, the mean is 2 and the variance is:
33
The formula (in summation notation) for the variance in a population is
where μ is the mean and N is the number of scores.
When the variance is computed in a sample, the statistic
(where is the mean of the sample) can be used. S2 is a biasedestimate of σ2, however. By
far the most common formula for computing variance in a sample is:
Which gives an unbiased estimate of σ2? Since samples are usually used to estimate
parameters, s2 is the most commonly used measure of variance. Calculating the variance is an important part of many statistical applications and analyses.
Bias: A statistic is biased if, in the long run, it consistently over or underestimates the
parameter it is estimating. More technically it is biased if its expected value is not equal to
the parameter. A stopwatch that is a little bit fast gives biased estimates of elapsed time. Bias in this sense is different from the notion of a biased sample. A statistic is positively biased if it tends to overestimate the parameter; a statistic is negatively biased if it tends to underestimate the parameter. An unbiased statistic is not necessarily an accurate statistic. If a statistic is sometimes much too high and sometimes much too low, it can still be unbiased. It would be very imprecise, however. A slightly biased statistic that systematically results in very small overestimates of a parameter could be quite efficient.
Biased sample: A biased sample is one in which the method used to create the sample
results in samples that are systematically different from the population. For instance, consider a research project on attitudes toward sex. Collecting the data by publishing a questionnaire in a magazine and asking people to fill it out and send it in would produce a biased sample. People interested enough to spend their time and energy filling out and sending in the questionnaire are likely to have different attitudes toward sex than those not taking the time to fill out the questionnaire.
34
2.9 STANDARD DEVIATION
The formula for the standard deviation is very simple: it is the square root of the variance. It is the most commonly used measure of spread.
An important attribute of the standard deviation as a measure of spread is that if the mean and standard deviation of a normal distribution are known, it is possible to compute the
percentile rank associated with any given score. In a normal distribution, about 68% of the
scores are within one standard deviation of the mean and about 95% of the scores are within two standards deviations of the mean.
The standard deviation has proven to be an extremely useful measure of spread in part because it is mathematically tractable. Many formulas in inferential statistics use the standard deviation.
Although less sensitive to extreme scores than the range, the standard deviation is more sensitive than the semi-interquartile range. Thus, the standard deviation should be supplemented by the semi-interquartile range when the possibility of extreme scores is present.
Standard Deviation as a Measure of Risk
The standard deviation is often used by investors to measure the risk of a stock or a stock portfolio. The basic idea is that the standard deviation is a measure of volatility: the more a stock's returns vary from the stock's average return, the more volatile the stock. Consider the following two stock portfolios and their respective returns (in per cent) over the last six months.
35
Summary:
The standard deviation is by far the most widely used
measure of spread. It takes every score into account, has extremely useful properties when used with a normal
distribution, and is tractable mathematically and,
therefore; it appears in many formulas in inferential statistics.
The standard deviation is not a good measure of spread in highly-skewed distributions and should be supplemented in those cases by the semi-interquartile range.
The range is a useful statistic to know, but it cannot
stand alone as a measure of spread since it takes into account only two scores.
The semi-interquartile range is rarely used as a measure of spread, in part because it is not very mathematically tractable. However, it is influenced less by extreme scores than the standard deviation, is less subject to
sampling fluctuations in highly-skewed distributions,
36
2.10 SHAPE OFTHE DISTRIBUTION
The concept of the shape of the distribution refers to the shape of a probability distribution and it most often arises in questions of finding an appropriate distribution to use to model the statistical properties of a population, given a sample from that population. The shape of a distribution may be considered either descriptively, using terms such as "J-shaped", or numerically, using quantitative measures such as skewness and kurtosis.
2.11 SKEWNESS
A distribution is skewed if one of its tails is longer than the other. The first distribution shown has a positive skew. This means that it has a long tail in the positive direction. The distribution below it has a negative skew since it has a long tail in the negative direction. Finally, the third distribution is symmetric and has no skew. Distributions with positive skew are sometimes called "skewed to the right" whereas distributions with negative skew are called "skewed to the left."
Distributions with positive skew are more common than distributions with negative skews. One example is the distribution of income.
Most people make under $40,000 a year, but some make quite a bit more with a small number making many millions of dollars per year. The positive tail therefore extends out quite a long way whereas the negative tail stops at zero.
For a more psychological example, a distribution with a positive skew typically results if the time it takes to make a response is measured. The longest response times are usually much longer than typical response times whereas the shortest response times are seldom much less than the typical response time. A histogram of the author's performance on a
perceptual motor task in which the goal is to move the mouse to and click on a small target
37
Negatively skewed distributions do occur, however. Consider the following
frequency polygon of test grades on a statistics test where most students did very well but a
few did poorly. It has a large negative skew.
Skew can be calculated as:
where μ is the meanand σ is the standard deviation.
The normal distribution has a skew of 0 since it is a symmetric distribution.
As a general rule, the mean is larger than the median in positively skewed distributions and less than the median in negatively skewed distributions. Although counter examples can be found, they are very rare in real data.
2.12 KURTOSIS
Kurtosis is based on the size of a distribution's tails. Distributions with relatively large tails are called "leptokurtic"; those with small tails are called "platykurtic”. A distribution with the same kurtosis as the normal distribution is called "mesokurtic”.
The following formula can be used to calculate kurtosis:
where σ is the standard deviation. The kurtosis of a normal distribution is 0.
The following two distributions have the same variance; approximately the same skew, but differ markedly in kurtosis.
2.13 TYPES OF GRAPHS
a. Frequency Polygons
38
A frequency table and a relative frequency polygon for response times in a study on
weapons and aggression are shown below. The times are in hundredths of a second.
Lower
Note: Values in each category are > the lower limit and ≤ to the upper limit.
Frequency polygons can be based on the actual frequencies or the relative frequencies. When based on relative frequencies, the percentage of scores instead of the number of scores in each category is plotted.
In a cumulative frequency polygon, the number of scores (or the percentage of scores) up to and including the category in question is plotted. A cumulative frequency polygon is shown below.
b. Histograms
39
Histogram
The shapes of histograms will vary depending on the choice of the size of the intervals. A bar graph is much like a histogram, differing in that a small distance separates the columns from each other. Bar graphs are commonly used for qualitative variables.
c. Stem and Leaf Displays
A stem and leaf plot is much like a histogram except it portrays a little more information. A stem and leaf plot of the tournament players from the dataset "chess" as well as the data themselves are shown to the right.
The largest value, 85.3, is approximated as 10 x 8 + 5. This is represented in the plot as a stem of 8 and a leaf of 5. It is shown as the "5" in the first line of the plot. Similarly, 80.3 is approximated as 10 x 8 + 0; it has a stem of 8 and a leaf of 0. It is shown as the "0" in the first line of the plot.
Depending on the data, each stem is displayed 1, 2, or 5 times. When a stem is displayed only once (as on the plot shown here), the leaves can take on the values from 0-9.
40
Finally, when a stem is displayed five times, the first has the leaves 8-9, the second 6-7, the third 4-5, and so on.
If positive and negative numbers are present, +0 and -0 are used as stems as they are in the plot to the right. A stem of -0 and a leaf of 7 is a value of (-0 x 1) + (-.1 x 7) = -.7.
d. Box Plots
A box plot provides an excellent visual summary of many important aspects of a distribution. The box stretches from the lower hinge (defined as the 25th percentile) to the upper hinge (the 75th percentile) and therefore contains the middle half of the scores in the distribution.
The median is shown as a line across the box. Therefore 1/4
of the distribution is between this line and the top of the box and 1/4 of the distribution is between this line and the bottom of the box.
The "H-spread" is defined as the difference between the hinges and a "step" is defined as 1.5 times the H-spread. Inner fences are 1 step beyond the hinges. Outer fences are 2 steps beyond the hinges.
There are two adjacent values: the largest value below the upper inner fence and the smallest value above the lower inner fence.
For the data plotted in the figure, the minimum value is above the lower inner fence and is therefore the lower adjacent value. The maximum value is the inner fences so it is not the upper adjacent value.
41
Every score between the inner and outer fences is indicated by an "o"; a score beyond the outer fences is indicated by a "*".
It is often useful to compare data from two or more groups by viewing box plots from the groups side by side. Plotted are data from Example 2a and Example 2b. The data from 2b are higher; more spread out, and have a positive skew. That the skew is positive can be determined by the fact that the mean is higher than the median and the upper whisker is longer than the lower whisker.
Some computer programs present their own variations on box plots. For example, SPSS
does not include the mean. JMP distinguishes between "outlier" box plots which are the same as those described here and quantile box plots that show the 10th, 25th, 50th, 75th, and 90th
Percentiles.
REVIEW QUESTIONS
42
2. Which of the box plots on has a large positive skew? Which has a large negative skew?
3. Make up a dataset of 20 numbers with a positive skew. Use a statistical program to compute the skew and to create a box plot. Is the mean larger than the median as it should be for distributions with a positive skew? What is the value for skew? Plot a frequency polygon with these data.
4. Repeat Problem 3 only this time make the dataset have a negative skew.
5. Make up two data sets that have:
(a) the same mean but differ in standard deviations. (b) the same mean but have different medians. (c) the same median but different means.
(d) the same semi-interquartile range but differ in standard deviations
6. Assume the variable X has a mean of 10 and a standard deviation of 2. What would be the mean and standard deviation of a new variable (Y) that was created by multiplying each element of X by 5 and then adding 4.
43
Non players Beginners Tournament Players
9. Experiment with the sampling distribution simulation and do the exercises associated with it.
10. What is more likely to have a skewed distribution: time to solve an anagram problem or scores on a vocabulary test?
For additional reading, a student must refer to the recommended text book for Business Statistics [Applied Business Statistics, Methods and Excel-basic applications (3rd edition) by: Trevor Wegner (page 70 to page 89)]
44
TOPIC 3
__
3. CORRELATION AND SIMPLE LINEAR REGRESSION ANALYSIS
__
Learning Outcomes:
In this topic you will learn about Pearson's Correlation and its computational formula.
Effects of restricted range and linear transformations on Pearson's Correlation
Knowledge on Spearman's rho
3.1. SCATTER PLOTS
A scatter plot shows the scores on one variable plotted against scores on a second variable. Below is a plot showing the relationship between grip strength and arm strength for 147 people working at physically-demanding jobs. The data are from a case study in the Rice Virtual Lab in Statistics. The plot shows a very strong but certainly not a perfect relationship between these two variables.
45
3.2. INTRODUCTION TO PEARSON'S CORRELATION
The correlation between two variables reflects the degree to which the variables are related. The most common measure of correlation is the Pearson Product Moment Correlation (called Pearson's correlation for short). When measured in a population the Pearson Product Moment correlation is designated by the Greek letter rho (ρ). When computed in a sample, it is designated by the letter "r" and is sometimes called "Pearson's r." Pearson's correlation reflects the degree of linear relationship between two variables. It ranges from +1 to -1. A correlation of +1 means that there is a perfect positive linear relationship between variables. The scatter plot shown on this page depicts such a relationship. It is a positive relationship because high scores on the X-axis are associated with high scores on the Y-axis.
A correlation of -1 means that there is perfect negative linear relationship between
variables. The scatter plot shown to the right depicts a negative relationship. It is a negative relationship because highscores on the X-axis are associated with low scores on the Y-axis. A correlation of 0 means there is no linear relationship between the two variables.
The second graph shows a Pearson correlation of 0.
46
The scatter plot below shows arm strength as a function of grip strength for 147 people working in physically-demanding jobs. The plot reveals a moderate positive relationship. The value of Pearson's correlation is 0.63.
Computing Pearson's correlation coefficient
The formula for Pearson's correlation takes on many forms. A commonly used formula is shown on the right. The formula looks a bit complicated, but taken step by step as shown in
the numerical example, it is simple.
A simpler looking formula can be used if the numbers are converted into z scores:
where zx is the variable X converted into z scores and zy is the variable Y converted into z scores.
(Numerical example:
X Y
47
Example values of r
Effect of restricted range on Pearson's Correlation
48
Whenever a sample has a restricted range of scores, the correlation will be reduced. To take the most extreme example, consider what the correlation between high-school GPA and college GPA would be in a sample where every student had the same high-school GPA. The correlation would necessarily be 0.0.
How would you interpret r values? When do we say there is week, moderate or strong relationship exists?
Effect of linear transformations on Pearson's Correlation
A linear transformation of a variable involves multiplying each value of the variable by one
number and then adding a second number. For example, consider the variable X with the following three values:
X 2 3 7
One linear transformation of the variable would be to multiply each value by 2 and then to add 5. If the transformed variable is called Y, then Y = 2X+5. The values of Y are: