Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 3 Agustus 2013
i
SUSUNAN DEWAN REDAKSI JELIKU
KETUA
AGUS MULIANTARA, S.KOM, M.KOM
PENYUNTING
DRA. LUH GEDE ASTUTI, M.KOM
NGURAH AGUS SANJAYA E.R., S.KOM, M.KOM
IDA BAGUS MAHENDRA, S.KOM, M.KOM
IDA BAGUS GEDE DWIDASMARA, S.KOM, M.CS
PELAKSANA
I KETUT GEDE SUHARTANA, S.KOM., M.KOM
I GEDE SANTI ASTAWA, S.T., M.CS
I MADE WIDIARTHA, S.SI., M.KOM
ALAMAT REDAKSI
JURUSAN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS UDAYANA
KAMPUS BUKIT JIMBARAN – BADUNG
TELEPON : 0361 – 701805
EMAIL : [email protected]
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 3 Agustus 2013
ii
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 3 Agustus 2013
iii
DAFTAR ISI
SUSUNAN DEWAN REDAKSI JELIKU ... i DAFTAR ISI ... iii PERANCANGAN SISTEM INFORMASI MOBILE SALES FORCE AUTOMATION (SFA) PT. ASTRA INTERNASIONAL TBK. –HONDA
Ni Made Dwi Arnita, Agus Muliantara ... 1 PENGENALAN POLA BREAST CANCER MENGGUNAKAN ALGORITMA NGUYEN WIDROW BACKPROPAGATION
I Gst Ag Indra Arthana, Agus Muliantara ... 11
PENERAPAN QUEUE TREE PADA ROUTER MIKROTIK DALAM MANAJEMEN BANDWITH
I Putu Ery Handika dan I Komang Ari Mogi ... 16
PERANCANGAN SISTEM INFORMASI KEANEKARAGAMAN HAYATI DI PT. PERTAMINA DEPOT PENGISIAN PESAWAT UDARA (DPPU) NGURAH RAI
I Gusti Putu Deviara Putra, I.B Made Mahendra ... 25 IMPLEMENTASI SISTEM OPERASI ROUTER MIKROTIK SEBAGAI PROXY SERVER BERBASIS TRANSPARENT PROXY
I Putu Iyasa Pringgagada Pecut, I Made Widhi Wirawan ... 33 PURWARUPA APLIKASI MESIN PENCARI REFERENSI
I Putu Sutria Narada, Agus Muliantara, Ida Bagus Dwidasmara ... 42
IMPLEMENTASI BANDWIDTH MANAGEMENT PADA PENGALOKASIAN HOTSPOT DI FAKULTAS HUKUM UNIVERSITAS UDAYANA
I Made Yuda Prasetia, I Made Widhi Wirawan, I Dewa Made Bayu Atmaja Darmawan ... 51
PERANCANGAN SISTEM TRACER STUDY BERBASIS WEB PADA FAKULTAS PARIWISATA UNIVERSITAS UDAYANA
Luh Sukma Widiasari, Ngurah Widyatmaja ... 59
PERANCANGAN DAN IMPLEMENTASI APLIKASI KLASIFIKASI PENYAKIT DIABETES DENGAN METODE NAÏVE BAYES
Putu Gerhans Prawira Risnawan, Ngurah Agus Sanjaya ER, I Made Widiartha ... 68
IMPLEMENTASI SPLIT DNS DENGAN MENGGUNAKAN BIND9 DALAM MEMBANGUN SISTEM CONTENT DELIVERY NETWORK
I Made Yoga Sattwika Darma
, I Made Widhi Wirawan, I Dewa Made Bayu Atmaja Darmawan ... 73 PERANCANGAN SISTEM INFORMASI SALES ACTIVITY PT. ASTRA INTERNATIONAL TBK. - HONDA
I Wayan Angga Pratama, Ida Bagus Gede Dwidasmara ... 78
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 3 Agustus 2013
iv
I Made Bayu Adi Utama, I Dewa Made Bayu Atmaja Darmawan ... 88 PENGENALAN WICARA KARAKTER INDONESIA MENGGUNAKAN HIDDEN MARKOV MODEL
I Wayan Adi Juliawan Pawana ... 96 IDENTIFIKASI KEKURANGAN UNSUR HARA PADA TANAMAN JAGUNG DENGAN METODE JARINGAN SARAF TIRUAN LEARNING VECTOR QUANTIZATION
Adinda Prisila Permatasari, Luh Gede Astuti, I Gede Santi Astawa... 101 ANALISA KINERJA ROUTING MENGGUNAKAN ROUTING INFORMATION PROTOCOL (rip) DAN OPEN SHORTEST PATH FIRST (OSPF)
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 3 Agustus 2013
42
PURWARUPA APLIKASI MESIN PENCARI REFERENSI
I Putu Sutria Narada, Agus Muliantara, Ida Bagus Dwidasmara
Program Studi Teknik Informatika, Jurusan Ilmu Komputer, Fakultas Matematika Dan Ilmu Pengetahuan Alam, Universitas Udayana
Email: [email protected]
ABSTRAK
Terdapat banyak sekali referensi yang dapat dijadikan dasar suatu penelitian, diperlukan banyak waktu untuk mensortirnya secara manual. Diperlukan suatu fasilitas agar pencarian referensi ini dapat dilakukan secara efisien, dan tidak memakan banyak waktu. Solusi dari masalah tersebut adalah penerapan bidang ilmu text mining yaitu sistem temu kembali informasi. Dengan menerapkan model ruang vektor, dokumen – dokumen referensi tersebut disimulasikan memiliki suatu posisi berdasarkan term penyusunnya. Dari posisi-posisi dokumen ini, dengan membandingkan posisi dari suatu dokumen terhadap kata kunci pencarian, akan ditemukan dokumen mana sajakah yang memiliki kesamaan dengan kata kunci yang diinginkan, dengan menghitung nilai cosine similarity yang mereprentasikan tingkat kesamaan antar dokumen, sehingga dokumen yang memiliki nilai similarity paling tinggi akan menduduki peringkat pertama dalam pencarian. Sistem ini dikembangkan menggunakan bahasa pemrograman PHP dan dokumen uji menggunakan 100 jurnal bahasa indonesia yang di ambil secara acak dari internet. Penelitian ini berhasil menerapkan model ruang vektor, dan hasil dari penelitian ini menunjukan bahwa aplikasi yang dibangun penulis dapat menangani masalah pencarian referensi ilmiah dengan baik, terlihat dari hasil evaluasi nilai dengan precision sebesar 62% dan nilai recall sebesar 100%.
Kata Kunci : Cosine similarity, model ruang vektor, sistem temu kembali informasi, STKI
ABSTRACT
Many refrence that can be used as study basis, but it takes a lot of time to sort those references manualy. A facilities needed to help sorting all those refrence in eficient way. The solution of those problems lays on Information retrival knowledge. With appliying vector space model, the position of the reference document can be simulated using terms that construct those references document. By comparing this posistion with the search query, will be found a similarity value that represent the level of similarity between refrence documents and the search query. This aplication developed using PHP programing language and using 100 Indonesian journal abstract that downloaded randomly from the internet. This research has been succsesfully implemented the vector space model, and the result of this research shows that the aplication that author build has able to handle the reference sorting problems well, seen from the evaluatin resul witht recall value 100% and precision value 62%.
Keywords: Cosine similarity, Information retrival, IR, Vector space model
PENDAHULUAN
Dalam perkembangan teknologi yang begitu pesat seperti saat ini, kebutuhan akan informasi sangatlah tinggi. Informasi yang tersedia sangatlah banyak, sehingga akan sangat menyulitkan jika dilakukan pencarian secara manual. Oleh sebab itu diperlukannya
suatu mesin pencari untuk membantu mencari informasi yang relevan dengan maksud yang dituju.
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 3 Agustus 2013
43 menentukan landasan dasar. Oleh karena itu, diperlukan suatu sistem yang dapat mengekstrak informasi dari kumpulan dokumen, dimana kumpulan dokumen ini hanya terfokus pada kumpulan dokumen referensi. Sehingga dapat membantu mempermudah pencarian referensi relevan untuk landasan penelitian.
LANDASAN TEORI
1. Sistem Temu Kembali Informasi
Sistem Temu Kembali Informasi (STKI) didefinisikan sebagai pencarian atau penemuan dokumen yang tidak terstruktur yang memenuhi kebutuhan informasi dari data dalam jumlah besar (Manning et al, 2009). Menurut Hasugian (2008) terdapat lima komponen yang memiliki peran penting dalam proses temu kembali informasi. yaitu :
1. Pengguna, yaitu orang yang menggunakan dan sistem
2. Query, yaitu format bahasa yang digunakan oleh pengguna kedalam Sistem Temu Kembali Informasi.
3. Dokumen, yaitu istilah yang digunakan untuk bahan pustaka..
4. Indeks dokumen, yaitu istilah atau kata yang disimpan kedalam database yang berfungsi sebagai representasi sebuah dokumen.
5. Pencocokan, yaitu pembandingan istilah yang dimasukkan oleh pengguna dengan indeks dokumen yang ada.
Pada tahapan pembangunan index dokumen suatu dokumen harus melalui tahapan berikut.
1. Tokenization adalah memecah dokumen menjadi kumpulan kata, dimana dalam proses pemecahan ini dilakukan pengubahan semua huruf kapital menjadi huruf kecil dan juga proses penghilangan tanda baca.
2. Filtering adalah proses penghilangan kata yang tidak relevan dengan suatu artikel, diantaranya adalah kata sambung dan kata tanya.
3. Stemming adalah proses pengembalian suatu kata menjadi kata dasar dengan
menggukan algoritma pemecah kata yang berbeda pada tiap bahasa.
4. Term weighting atau pembobotan kata adalah pembobotan dasar penghitungan nilai frekuensi kemunculan suatu kata (term). Frekuensi kemunculan term adalah petunjuk sejauh manakah suatu term tersebut mewakili suatu dokumen.
Gambar 1. Model ruang vektor
2. Vector space model
Vector space model (VSM) atau model
ruang vektor adalah suatu metode untuk merepresentasikan dokumen dan query dalam bentuk vektor pada ruang multidimensional (Singh dkk, 2012). Dimana tiap kata (term)
yang menyusun suatu dokumen menjadi banyak dimensi dari suatu dokumen. Dokumen sendiri diwujudkan dalam bentuk vektor berarah sesuai dengan term yang membentuknya dan nilai kedekatan antar dokumen dihitung dari nilai sudut antar vektor yang berdekatan.
Pada gambar 1 terlihat sudut θ1 yang dibentuk antara Q dan D1 dan θ2 untuk sudut yang dibentuk oleh Q dan D2, sudut inilah yang memperlihatkan nilai kedekatan vektor
query dan vektor dokumen, dimana semaki
kecil sudutnya semakin besar pula nilai kedekatannya. Sudut yang dibentuk oleh dua buah vektor dapat dihitung dengan melakukan perkalian dalam (inner product), sehingga rumus relevansinya, adalah:
. � = cos � = | |. |�|. � Dimana :
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 3 Agustus 2013
44 |D| = Panjang dokumen
Dari hasil persamaan diatas didapatkan nilai similarity antara query dan dokumen – dokumen pada koleksi, sehingga akan didapatkan hasil dokumen yang telah terangking berdasarkan nilai kesamaan tersebut.
3. Stemming Arifin
Steming arifin digunakan untuk pemotongan kata sehingga didapat kata dasar dari kata tersebut. Berikut langkah-langkah steming arifin.
Setiap kata diasumsikan memiliki 2 awalan (prefiks) dan 3 akhiran (sufiks), dengan susunan Prefiks 1 + Prefiks 2 + Kata dasar + Sufiks 3 + Sufiks 2 + Sufiks 1
Pemotongan dilakukan secara berurutan dari awalan (AW), akhiran (AK), dan kata dasar (KD)
Jika sampai pada pemotongan AKIII, belum juga ditemukan di kamus, maka dilakukan proses kombinasi. KD yang dihasilkan dikombinasikan dengan imbuhan-imbuhannya dalam 12 konfigurasi berikut:
4. Pembobotan term
Penulis menggunakan metode pembobotan yang dikembangkan oleh Chisholm (1999) yaitu kombinasi dari square root weighting,
global frequency IDF, cosine normalisation,
untuk pembobotan pada vektor dokumen, serta
binary weighting dan inverse document
frequency, dan non normalisasi untuk
pembobotan query. Dimana dalam dari
penelitian sebelumnya, kombinasi pembobotan ini, dibuktikan memiliki hasil yang lebih baik dibanding dengan pembobotan yang dilakukan pada umumnya.
4.1 Square root weighting
Square root term weighting (SQRT) adalah pembobotan term yang dikembangkan oleh Chisholm (1999) yang digunakan untuk pembobotan documen yang bersifat lokal. Dimana L adalah bobot lokal untuk term i pada dokumen j, dan f adalah frekuensi maka pembobotan square root dirumuskan dengan.
� = √ − , + jika, fij > 0 � = jika fij = 0
4.2 Global frequency IDF
Penulis menggunakan pembobotan global IDF untuk menghitung boboy global dari suatu dokumen, dimana jika suatu term muncul sekali pada setiap dokumen atau sekali pada satu dokumen, akan diberikan bobot paling kecil. Sebuah term yang secara relatif muncul pada beberapa dokumen akan mendapat bobot yang besar. Dirumuskan seperti berikut.
=
Dimana Gi adalah bobot global, Fi adalah frekuensi kemunculan term i pada suatu dokumen, dan ni adalah jumlah dokumen yang memuat term i
4.3 Cosine normalisation
Untuk normalisasi penulis menggunakan normalisasi cosine similarity berikut persamaannya.
=
√∑= �
Dimana Nj adalah nilai normalisasi suatu dokumen j, m adalah jumlah term pada dokumen j, Gi adalah bobot global dari term i, dan Lij adalah bobot lokal dari term i pada dokumen j.
4.4 Binary weighting
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 3 Agustus 2013
45 apabila term tersebut ada dalam dokumen. Sehingga banyaknya kemunculan term pada sebuah dokumen tidak berpengaruh dituliskan dalam persamaan dibawah ini.
� = , >
� = , =
4.5 Inverse document frequency(IDF)
Inverse document frequency (IDF) adalah pembobotan term yang menghitung seberapa besarkah penaruh suatu term terhadap seluruh koleksi dokumen. Berdasarkan konsep memberikan “nilai diskriminasi” pada term dimana semakin sedikit kemunculan term tersebut pada keseluruhan koleksi dokumen, maka semakin besar nilai diskriminasinya (Chisholm & Kolda, 1999) IDF diajukan oleh Sparck Jones, dimana terdapat dua varian IDF yaitu
= log
= log −
Dimana Gi adalah bobot global untuk term i, N adalah jumlah koleksi dokumen keseluruhan, dan ni adalah jumlah dokumen yang terdapat term i didalamnya. Dalam penelitian ini penulis menggunakan IDF pertama dikarenakan persamaan IDF kedua akan menghasilkan nilai negatif jika suatu term muncul lebih pada setengah dari keseluruhan koleksi.
5. Damerau Levenhstein metric
Metode Damereu Levenshtein metric
melakukan operasi perbandingan kata-kata dengan memeperhatikan empat macam kesalahan pengetikan. Sebagai contoh kata SALAH, yaitu :
a. Penyisipan sebuah huruf , sebagai contoh SALKAH.
b. Pengapusan sebuah huruf, sebagai contoh SAAH.
c. Penggantian sebuah huruf dengan huruf lain, sebagai contoh SAKAH.
d. Penukan urutan sebuah huruf, sebagai contoh SALHA
Damereu Levenshtein metric menghitung jumlah kesalahan minumum dari dua buah
kata, misalkan terdapat dua buah kata yang dinotasikan sebagai s dan t, dan variabel i dan j menyatakan posisi huruf yang dibandingkan pada suatu kata (Phiefer et al, 1994).
, = mengukur jarak huruf.
, = { , = , ≠
Fungsi f(i,j) menghitung jumlah minimum kesalahan – kesalahan dari perbandingan i karakter kata pertama dengan j karakter pada kata kedua. Jarak antara kedua string adalah f(m,n), dimana m merupakan panjang string pertama, dan n adalah panjang string kedua.
Term
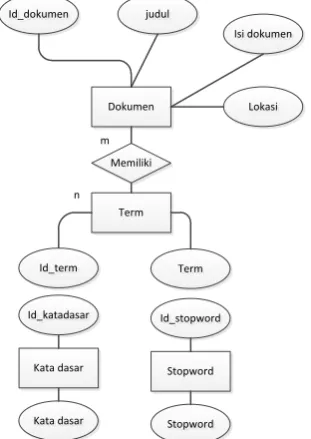
Gambar 2. ERD Sistem pencari referensi
PERANCANGAN
1. Entity Relatinship Diagram(ERD)
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 3 Agustus 2013
46 entitas term, entitas kata dasar, dan entitas stopword.
Seperti yang terlihat pada gambar 2, pada entitas dokumen taerdiri dari atribut id_dokumen, judul, isi_dokumen, dan lokasi. Untuk entitas term terdiri atribut id_term dan term. Entitas dokumen dan term memuliki relasi many to many.
Pada entitas kata dasar memiliki atribut id_katadasar dan kata_dasar. Pada entitas memiliki atribut id_stopword dan stopword.
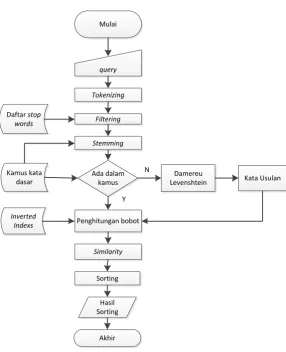
2. Flowchart mesin pencari
Flowchat mesin pencari dapat dilihat pada gambar 3, dimana prosesnya meliputi.
1. Penginputan query kata kunci yang akan dicari.
2. Proses tokenizing, proses dimana string inputan dibaca, dan dipecah kedalam bagian perkata.
3. Filtering, proses dimana tanda baca
dan kata hubung dihilangkan.
4. Stemming, proses pencarian kata dasar
dari suatu kata.
5. Dari hasil stemming akan dilakukan perbandingan dengan kamus bahasa, untuk memastikan ketepatan hasil
stemming.
6. Proses sugesti kata dilakukan bila kata
query tidak terdapat dalam kamus.
7. Kemudian dilakukan proses pembobotan untuk mengeetahui bobot
term-term pada query
8. Dilakukan perhitungan nilai similarity, untuk menentukan dokumen mana sajakah yang sesuai dengan kata kunci pencarian.
9. Sorting berdasarkan nilai similarity secara descending.
10. Tampilkan hasil pencarian.
Mulai
query
Tokenizing
Filtering
Stemming
Ada dalam kamus
Penghitungan bobot
Similarity
Damereu
Levenshtein Kata Usulan
Sorting
Hasil Sorting Kamus kata
dasar
Inverted Indexs
Daftar stop words
N
Y
Akhir
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 3 Agustus 2013
47 3. Diagram Konteks
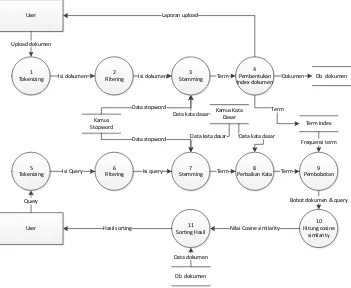
Diagram konteks ditunjukan pada gambar 4. Pada gambar tersebut menunjukan bahwa sistem menerima masukan dari 2 entitas yaitu user dan aplikasi client. Entitas user, menginputkan index dokumen yang dijadikan dasar pencarian. Sedangkan perintah pelaksanaan pencarian datang dari aplikasi client.
Data flow doagram dari aplikas mesin pencari ini dapat dilihat dari gambar 5. Terdapat 11 proses dalam aplikasi ini, dimana proses 1 sampai dengan 4 adalah proses pengunggahan index dokumen pencarian. Sedangkan proses pencarian dokumen berdasarkan kata kunci dilakukan dari proses 5 sampai dengan proses 11.
User
0 Web service mesin
pencari
Aplikasi client Upload Dokumen
Laporan dokumen terupload Hasil Pencarian
Input query
Gambar 4. Diagram konteks pencarian referensi
4. DFD
Isi dokumen Isi dokumen Term Dokumen
Term
Isi Query
Laporan upload
Query
Isi query Term Term
Frequensi term
Bobot dokumen & query
Nilai Cosine similarity Hasil sorting
Data stopword Data kata dasar Data kata dasar Data stopword
Db dokumen Data dokumen
Data kata dasar
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 3 Agustus 2013
48
HASIL DAN PERCOBAAN
Sesuai dengan penjelasan sebelumnya, tahapan pengmbangan mesin pencari ini adalah tokenization, filtering, stemming, term weighting, dan sorting. Berikut adalah pseudocode untuk proses tokenizing, filtering dan stemming yang termasuk dalam proses preprosessing.
Untuk proses pembobotan dokumen, seperti yang telah dijelaskan diatas, digunakan kombinasi pembobotan term baru yang menurut penelitian Chisholm (1999) memiliki tingkat ketepatan lebih tinggi dibandingkan dengan metode pembobotan pada umumnya. Dibawah ini adalah pseudocode dari proses pembobotan dan cosine similarity.
Setelah nilai cosine similarity didapat, maka dokumen hasil pencarian akan diurutkan secara descending berdasarkan nilai cosine similarity nya masing masing.
Sistem telah berhasil diimplementasikan dengan menggunakan bahasa pemrograman PHP. Pengujian aplikasi ini, menggunakan 100 dokumen abstrak jurnal berbagai bidang yang di unduh secara acak melalui internet. Pengujian dilakukan pada proses-proses utama dari sistem, antara lain : proses preprosessing, pembentukan index dokumen, fasilitas sugesti kata, pembobotan query, dan pengujian keseluruhan sistem dengan menginputkan 30 query yang telah ditentukan. Dari hasil pengujian didapatkan kesimpulan bahwa setiap elemen yang diujikan dapat berjalan dengan baik, dan memiliki nilai precision sebesar 62% serta nilai recall sebesar 100%.
SIMPULAN
Dari pembahasan dan perancangan sistem diatas, penulis menyimpulkan poin-poin penting sebagai berikut:
1. Penelitian ini telah berhasil pengembangkan mesin pencari referensi, dengan menggunakan metode vector space
model, algoritma Damereu Levensthein,
dan metode pembobotan baru oleh Chisholm (1999).
2. Dari hasil pengujian, didapat nilai Function prepros ($text){
$Angka = array(1,2,3,4,5,6,7,8,9,0)
$simbol = array (‘!’,’?’,’.’.’,’, ’(’ ,’)’,’+’,’=’,’%’,’&’,’*’,’/’
$isi=Hilangkan simbol dan angka dari $text
$Stopword[]= select stopword from tb_stopword
$Kata[]=explode $isi Foreach $kata as $term{
if $term != anggota array stopword{
$kmplkata=$term }
}
//Panggil fungsi stemming(kmplkata) Foreach $kmplkata as $kata{
$hslSteming[] = potong awalan dan akhiran $kata
}
Return $hslSteming }
Function bobotquery($hslstemquery[]){ $n= select count * from tb_dokumen Foreaach $hslstemquery as $term{
$ni= select count(distict iddok) from tb_index where term=$term If( $ni = Null ){
$dokterkait= select distinct iddok from tb_index where term in $sql Foreach $dokterkait as $iddok{
$termdok= select distict termfrom tb_index where id_dokumen = $iddok $b[iddok]=0
Foreach $termdok as $term{ $ni= select count(distict iddok) from tb_index where term=$term.
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 3 Agustus 2013
49
precision sebesar 62% yang menunjukan
kualitas himpunan hasil dan nilai recall
sebesar 100% yang menunjukan ketepatan hasil pencarian
3. Diperlukan penelitian lebih lanjut untuk algoritma stemming bahasa Indonesia,
karena proses pencarian kata dasar sangatlah penting dalam pengembangan sistem mesin pencari.
4. Algoritma sugesti kata dapat dikembangkan lebih lanjut, agar proses pencarian kata sugesti lebih cepat.
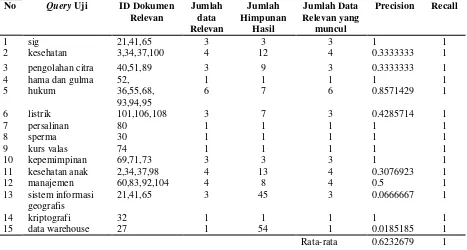
Tabel 4. Beberapa Query Hasil Pengujian Sistem
No Query Uji ID Dokumen
Relevan
Jumlah data Relevan
Jumlah Himpunan
Hasil
Jumlah Data Relevan yang
muncul
Precision Recall
1 sig 21,41,65 3 3 3 1 1
2 kesehatan 3,34,37,100 4 12 4 0.3333333 1
3 pengolahan citra 40,51,89 3 9 3 0.3333333 1
4 hama dan gulma 52, 1 1 1 1 1
5 hukum 36,55,68,
93,94,95
6 7 6 0.8571429 1
6 listrik 101,106,108 3 7 3 0.4285714 1
7 persalinan 80 1 1 1 1 1
8 sperma 30 1 1 1 1 1
9 kurs valas 74 1 1 1 1 1
10 kepemimpinan 69,71,73 3 3 3 1 1
11 kesehatan anak 2,34,37,98 4 13 4 0.3076923 1
12 manajemen 60,83,92,104 4 8 4 0.5 1
13 sistem informasi geografis
21,41,65 3 45 3 0.0666667 1
14 kriptografi 32 1 1 1 1 1
15 data warehouse 27 1 54 1 0.0185185 1
Rata-rata 0.6232679 1
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 3 Agustus 2013
50
DAFTAR PUSTAKA
[1] Chisholm, E., & Kolda, T. G. (1999). NEW TERM WEIGHTING FORMULAS FOR THE VECTOR SPACE. 20.
[2] Hasugian, J. (2008). Penelusuran Online dan Ketersediaan Sumber Daya Informasi Elektronik. Jurnal Studi Perpustakaan dan Informasi, Vol.4, No.1.
[3] Manning, C. D., Raghavan, P., & Schutze, H. (2009). An Introduction To Information Retreival. England: Cambridge University Press.
[4] Sutisna, U. (2009). Koreksi ejaan query bahasa indonesia dengan algoritma Damerau Levinstain.