Permodelan Proporsi Pengeluaran Makanan
Rumah Tangga di Kota Jayapura
Pendekatan Regresi Kuantil Aditif
Doni Hermawan1, Yudhie Andriyana2, Sri Winarni3Prodi Magister Statistik UNPAD1
Prodi Magister Statistik UNPAD 2
Prodi Magister Statistik UNPAD 3
ABSTRAK
Pendekatan nonparametrik digunakan jika hubungan antara dua variabel sulit ditentukan (masalah prespesifikasi
.
Regresi kuantil merupakan perluasan dari regresi median (pada kuantil 0,5) pada berbagai nilai kuantil. Metode ini dapat digunakan mengukur efek variabel prediktor tidak hanya di pusat sebaran data, tetapi juga pada bagian atas atau bawah ekor sebaran. Analisis ini sangat berguna dalam penerapan, khususnya bila nilai ekstrim merupakan permasalahan penting. Pada penelitian dikembangan model regresi kuantil aditif dengan pemulus spline. Data yang digunakan penelitian ini adalah data Susenas 2016 Kota Jayapura. Pemodelan diawali dengan penentuan parameter pemulus spline, kemudian dilanjutkan dengan model regresi kuantil aditif, dan evaluasi model. Hasil penelitian menunjukkan Mean Square Error terkecil diperoleh dari model regresi kuantil aditif dengan pemulus spline sebesar 145,561 dibandingkan dengan regresi kuantil tanpa pemulus.Kata kunci: regresi kuantil, aditif, SIC, konsumsi
1. PENDAHULUAN
Konsep konsumsi berkaitan dengan pembelanjaan yang dilakukan oleh rumah tangga atas barang dan jasa dengan tujuan untuk memenuhi kebutuhan dari orang-orang yang melakukan pembelanjaan tersebut. Dalam Survei Sosial Ekonomi Nasional (SUSENAS) yang dilakukan oleh Badan Pusat Statistik (BPS), terdapat dua jenis pengelompokan pengeluaran konsumsi rumah tangga, pengelompokan konsumsi makanan dan non makanan. Pola konsumsi khususnya konsumsi rumah tangga untuk makanan menjadi salah satu faktor penentu tingkat kesehatan dan produktivitas rumah tangga serta dapat dijadikan indikator sosial ekonomi rumah tangga. Semakin tinggi pengeluaran makanan dari porsi pendapatan maka rumahtangga tersebut dapat dikategorikan miskin. Begitu pula sebaliknya bila porsi pengeluaran untuk bukan makanan tinggi dari pada makanan maka rumah tangga tersebut dikategorikan tidak miskin.
Dalam upaya mempelajari pola pengeluran konsumsi rumah tangga, maka perlu diketahui faktor-faktor apa saja yang mempengaruhinya. Data BPS tahun 2016 menunjukan bahwa di Kota Jayapura persentase pengeluaran konsumsi makanan masih lebih besar dari pengeluaran bukan makanan dan merupakan yang terbesar dari provinsi lainnya di Indonesia, hal ini tentu saja menarik untuk diteliti untuk melihat kaitan faktor lain yang mempengaruhi pola pengeluaran konsumsi makanan di Kota Jayapura Provinsi Papua.
Salah satu metode untuk menganalisis data adalah analisis regresi. Analis merupakan salah satu alat statistik yang banyak digunakan untuk mengetahui hubungan antara dua variabel acak atau lebih. Regresi mean adalah metode statistik untuk menjelaskan hubungan antara variabel respon dan variabel prediktor berdasarkan kecenderungan sentral data (mean) dari variabel respon Pendekatan standar penentuan model regresi mean dan pendugaan parameternya adalah
metode kuadrat terkecil (OLS). Estimasi parameter dalam regresi mean (dengan Ordinary Least Square atau OLS) menghasilkan masalah jika kita menerapkannya pada data dengan asimetris, skewness, atau mengandung outlier. Oleh karena itu, metode alternatif perlu digunakan untuk jenis data tersebut, misalnya metode regresi kuantil. Regresi kuantil adalah teknik yang kuat untuk outlier.
Model ini dapat menjelaskan hubungan antara variabel respon dan variabel prediktor, tidak hanya pada kecenderungan pemusatan data (median) tetapi juga pada berbagai kuantil, untuk mendapatkan informasi lengkap tentang hubungan tersebut.
Regresi kuantil dikemukakan oleh Koenker dan Bassett pada tahun 1978 (Djuaridah, 2009), merupakan perluasan model regresi pada kuantil bersyarat variabel respon. Pendekatan ini memungkinkan menduga fungsi kuantil dari sebaran bersyarat respon pada berbagai nilai kuantil yang diinginkan. Setiap kuantil mencirikan titik tertentu (pusat atau ekor) dari sebaran bersyarat. Dalam penelitian ini, regresi kuantil dengan lebih dari satu variabel prediktor dikembangkan dengan pendekatan nonparametrik yaitu dengan smoothing spline.
2. METODE PENELITIAN
Regresi Kuantil
Regresi kuantil sangat baik digunakan pada sebaran data yang berdistribusi asimetris, padat pada ujung sebaran data, maupun terdapat outlier, karena estimator yang dihasilkan akan lebih efisien [1]
Misalkan
F
y
y
merupakan fungsi kumulatif dari data set {𝑦1, 𝑦2, 𝑦3, … , 𝑦𝑛}, maka dapat dituliskan𝐹𝑦(𝑦) = 𝑃(𝑌 ≤ 𝑦) = 𝜏
Untuk 𝜏 ∈ [0,1], kuantil ke-𝜏 dari y yang didasarkan pada fungsi objektif 𝐿1 (loss-function), menunjukan lokasi-lokasi khusus dari suatu distribusi. Fungsi 𝐿1 didefinisikan
𝑞𝑦(𝜏) = 𝐹𝑦−1(𝜏) inf{𝑐: 𝐹𝑌(𝑦) ≥ 𝜏}
Secara umum kuantil ke-𝜏 dari Y dapat diekspresikan dengan meminimumkan 𝑞𝜏(𝑌) = 𝑎𝑟𝑔𝑚𝑖𝑛𝑐𝐸[𝜌𝜏(𝑌 − 𝑐)]
Dengan fungsi 𝜌𝜏(. ) disebut sebagai “check-function” yang didefinisikan 𝜌𝜏= {−(1 − 𝜏)𝑧 yang lainnya𝜏𝑧 jika z > 0
maka untuk memperoleh penduga regresi kuantil dapat dilakukan dengan meminimumkan fungsi tujuan:
𝑚𝑖𝑛
𝛽 𝐸[𝜌𝜏(𝑌 − 𝑋𝑇𝛽)] (1)
Misalkan kita memiliki sebanyak 𝑛 observasi yang i.id.
(𝑋11, 𝑋12, … , 𝑋1𝑝, 𝑌1), … , (𝑋𝑛1, 𝑋𝑛2, … , 𝑋𝑛𝑝, 𝑌𝑛)
dari (𝑋11, 𝑋12, … , 𝑋1𝑝, 𝑌) maka fungsi tujuan diatas dapat ditulis dalam bentuk empiris: 𝑚𝑖𝑛
𝛽 1𝑛∑ 𝜌𝜏(𝑌 − 𝑋 𝑇𝛽) 𝑛
𝑖=1 (2)
Metode regresi kuantil smoothing splines merupakan pemodelan regresi yang mengestimasi kurva tidak hanya pada ukuran pemusatan (bersyarat median) variabel respon, namun pada berbagai kuantil dengan menggunakan teknik smoothing splines. Solusi dari regresi kuantil smoothing splines adalah dengan meminimumkan
∑𝑛𝑖=1𝜌𝜏(𝑦𝑖− 𝑓(𝑥𝑖))+ 𝜆 ∫ |𝑓01 ′′(𝑥)|𝑑𝑥 [7]
Dimana 𝜌𝜏(𝑢) = (𝜏 − 𝐼(𝑢 < 0))𝑢 adalah “Check function” dari Koenker dan Bassett (1978). Disini parameter 𝜏 ∈ [0,1] mengontrol “quantile of interest” dan 𝜆 ∈ 𝑅+ mengontrol pemulusan hasil dari estimasi. Dalam Eubank (1988) and Utreras (1981) pada kasus median 𝜌1/2(𝑢) = |𝑢|. Dengan 0 = 𝑥0< 𝑥1< ⋯ < 𝑥𝑛< 𝑥𝑛+1= 1, dimana 𝑥𝑖 adalah titik knot dan 𝑓′′ adalah fungsi kontinu dalam selang [0,1] dan berupa splines linier natural dengan bentuk fungsi:
𝑓(𝑥) = {𝑎𝑎𝑖+ 𝑏𝑖(𝑥 − 𝑥𝑖); 𝑥 ∈ [𝑥𝑖, 𝑥𝑖+1) 0+ 𝑏0(𝑥 − 𝑥1); 𝑥 ∈ [𝑥0, 𝑥1) dengan 𝑖 = 1, … , 𝑛 dan koefisien didefinisikan:
𝑎𝑖 = 𝑦𝑖 𝑏𝑖 =
𝑎𝑖+1− 𝑎𝑖 𝑥𝑖+1− 𝑥𝑖
Jika ℎ𝑖= 𝑥𝑖+1− 𝑥𝑖, 𝑖 = 1, … , 𝑛 − 1, maka koefisien 𝑏𝑖 dapat juga ditulis: 𝑏𝑖 =𝑎𝑖+1− 𝑎𝑖
ℎ𝑖
dengan memperhatikan constraint, maka 𝑎0 = 𝑎1; 𝑏0 = 𝑏1; dan 𝑏𝑛−1= 𝑏𝑛, maka: 𝑓(𝑥𝑖+1) = 𝑎𝑖+ 𝑏𝑖ℎ𝑖 = 𝑎𝑖+1
Fungsi objektif kuantil ke-𝑏𝑖 atau 𝐿1 untuk regresi kuantil smoothing splines didefinisikan: min ∑𝑛𝑖=1𝜌𝜏(𝑦𝑖− 𝑓((𝑥𝑖))+ 𝜆 ∑𝑛−1𝑖=1|𝑓′(𝑥𝑖+1) − 𝑓′(𝑥𝑖) |
dengan 𝐿1𝑟𝑜𝑢𝑔ℎ𝑛𝑒𝑠𝑠 pada persamaan diatas didefinisikan sebagai: 𝐿1𝑟𝑜𝑢𝑔ℎ𝑛𝑒𝑠𝑠 = ∑|𝑓′(𝑥𝑖+1) − 𝑓′(𝑥𝑖) |
𝑛
𝑖=1
= 𝑉(𝑓′)
Fungsi obyektif kuantil atau 𝐿1 mempunyai sifat tidak dapat diturunkan/diminumkan (not differentiable) pada titik nol, sehingga tidak diperoleh solusi yang eksplisit. Oleh sebab itu, solusi kuantil dapat diperoleh dengan mengubah fungsi 𝐿1 ke dalam bentuk sistem persamaan linier yang dapat dipecahkan dengan linier programing.
Koenker et al. (1994) and Li et al. (2007) mengusulkan Bayesian Information Criterion (BIC) or Schwarz Information Criterion (SIC) sebagai kriteria dalam pemilihan parameter pemulus (𝜆) pada regresi kuantil.
Regresi Kuantil Aditif
Regresi nonparametrik biasa disebut sebagai scatterplot smoothing karena dalam aplikasinya dilakukan pencarian kurva berdasarkan scatterplot dari variabel y terhadap x. Tetapi ketika ada lebih dari satu variabel prediktor maka menjadi hal yang sulit untuk melakukan prediksi model berdasarkan scatter plot. Model dengan lebih dari satu variabel prediktor ini disebut model regresi aditif, dengan bentuk umum adalah
𝑦 = 𝛽0+ 𝑚1(𝑥1) + 𝑚2(𝑥2) + ⋯ + 𝑚𝑝(𝑥𝑝) + 𝜀
Metode model kuantil aditif merupakan permodelan regresi yang mengestimasi kurva tidak hanya pada ukuran pemusatan (bersyarat median) dari variabel respon, namun juga pada berbagai ukuran kuantil dengan menggunakan fungsi pemulus smoothing splines pada masing-masing variabel prediktor. Menurut Koenker, (2011) model kuantil aditif dalam bentuk conditional kuantil umumnya dapat dituliskan
Dimana 𝑔𝑗 merupakan fungsi pemulus yang kontinyu, dan solusi untuk model kuantil aditif diperoleh dengan meminimumkan:
𝑚𝑖𝑛
(𝜃0, 𝑔) ∑ 𝜌𝜏(𝑦𝑖− 𝑥𝑖𝑇𝜃0− ∑ 𝑔𝑗(𝑧𝑖𝑗)) + 𝜆0‖𝜃0‖1+ ∑𝐽𝑗=1𝜆𝑗𝑉(𝑔′(𝑧))
dimana 𝜌𝜏(𝑢) = 𝑢(𝜏 − 𝐼(𝑢 < 0)) adalah fungsi objectif kuantil, ‖𝜃0‖1= ∑𝐾𝑘=1|𝜃0𝑘| dan 𝑉(𝑔′(𝑧)) adalah total variasi dari derivative atau gradient dari fungsi g. Kemudian dapat dinyatakan sebagai
𝑉(𝑔′(𝑧)) = ∫‖𝑔"(𝑧)‖𝑑𝑧
Dalam pendekatan kuantil, nilai 𝜆 optimal diperoleh dari nilai SIC paling minimum dengan menggunakan persamaan. Dinotasikan residual yang mempertimbangkan kuantil ke-𝜏,
𝑆𝐼𝐶(𝜆) = 𝑛𝑙𝑜𝑔𝜎̂(𝜆) +1
2𝑝(𝜆)log (𝑛) (4) dimana 𝜎̂(𝜆) = 𝑛−1∑ 𝜌
𝜏(𝑦𝑖− 𝑔̂(𝑥, 𝑧)) 𝑛
𝑖=1 dan 𝑝(𝜆) adalah derajat bebas efektif dari fit model 𝑔̂(𝑥, 𝑧) = 𝑥𝑖𝑇𝜃̂0+ ∑ 𝑔𝑗
𝐽
𝑗=1 (𝑧)
Data yang digunakan dalam penelitian ini adalah data yang bersumber dari Survei Sosial Ekonomi Nasional (Susenas) 2016 Kota Jayapura. Set data yang digunakan merupakan data rumah tangga sebanyak 429 rumah tangga. Variabel-variabel yang digunakan dalam penelitian ini adalah Proporsi pengeluaran rumah tangga untuk konsumsi makanan sebagai variabel respon sedangkan variabel prediktor adalah jumlah anggota rumah tangga dan rata-rata lama sekolah.
Langkah-langkah Penelitian
Langkah-langkah dalam penelitian ini mencakup:
1. Membuat scatter plot antar variabel respon dan variabel prediktor
2. Pengecekan outlier pada hasil scatter plot dan bila terdapat outlier maka digunakan kuantil.
3. Menentukan parameter smoothing (λ). Pada penelitian ini digunakan fungsi smoothing Splines dengan parameter smoothing (λ) ditentuan berdasarkan nilai Schawrz Information Criterion (SIC) yang terkecil pada masing-masing prediktor.
4. Menaksir kurva regresi kuantil aditif berdasarkan nilai parameter penghalus (λ) yang optimal pada titik kuantil pada τ = 0,5 dengan acuan nilai AIC pada model aditif secara keseluruhan.
5. Membandingkan nilai Mean Square Error
3. HASIL DAN PEMBAHASAN
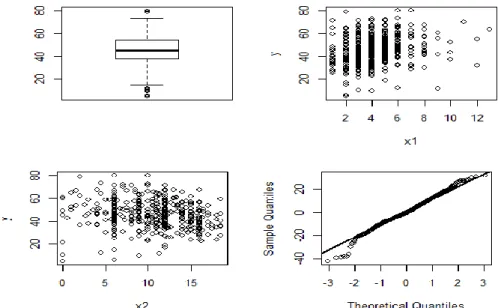
Data persentase pengeluaran rumah tangga memiliki outlier, hal ini dapat dilitah pada gambar 1 pada bagian boxplot terdapat titik-titik di bawah dan di atas garis garis (whisker). Selanjutnya data dilakukan pengecekan normalitasnya dengan menggunakan normal QQ plot.
Gambar 1. Plot Data
Normal Q-Q Plot merupakan alat deteksi sederhana yang dapat menunjukkan residual berdistribusi normal atau tidak. Semakin banyak residual (yang ditunjukkan dengan bulatan-bulatan kecil) menyinggung garis linier atau garis lurus, maka semakin besar kemungkinan bahwa residual berdistribusi normal. Deteksi normalitas dengan normal Q-Q Plot tergantung subjektifitas peneliti, oleh karena itu perlu dilakukan uji normalitas dengan alat statistik seperti uji Shaphiro-Wilk.
1. Uji Shaphiro-Wilk.
Uji Shapiro-Wilk yang dilakukan di dalam penelitian ini melalui pengujian hipotesis sebagai berikut:
𝐻0 : residual berdistribusi normal 𝐻1: residual tidak berdistribusi normal
Apabila 𝑝−𝑣𝑎𝑙𝑢𝑒 yang dihasilkan dari statistik uji lebih besar dari nilai taraf signifikansi 𝛼 (0.05), maka tidak cukup bukti untuk menerima 𝐻0artinya residual berdistribusi normal dan asumsi normalitas terpenuhi. Namun jika 𝑝−𝑣𝑎𝑙𝑢𝑒 yang dihasilkan dari statistik uji lebih kecil dari nilai taraf signifikansi 𝛼 (0.05) maka 𝐻0 ditolak artinya residual tidak berdistribusi
normal dan asumsi normalitas tidak terpenuhi.
Pengujian asumsi normalitas dilakukan dengan uji Saphiro Wilks menghasilkan nilai statistik S-W sebesar 0,98827 dan nilai p-value kurang dari 𝛼 (0.05), artinya residual tidak berdistribusi normal dan asumsi normalitas tidak terpenuhi sehingga pendekatan parametrik tidak dapat dilakukan.
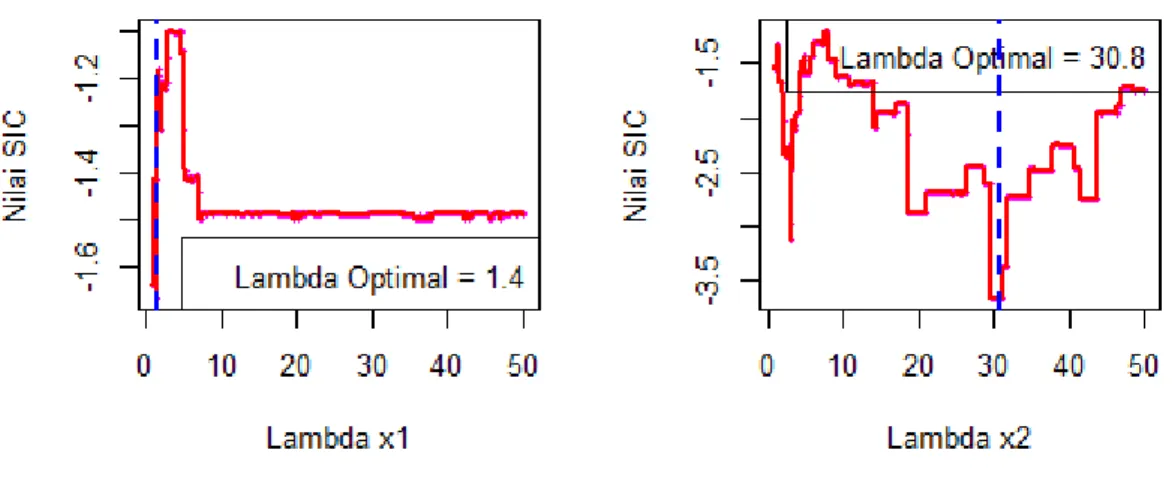
Pada regresi kuantil aditif pada nilai median dilakukan pencarian parameter lamda optimum untuk masing-masing prediktor dengan menggunakan kriteria nilai SIC secara individual. Diperoleh nilai masing-masing lambda adalah 1,4 dan 30,8 dapat dilihat pada gambar 2.
Nilai lambda ini digunakan sebagai nilai awal untuk prespesifikasi model regresi kuantil aditif. Nilai AIC digunakan sebagai ukuran untuk memilih model terbaik. Nilai AIC terkecil diperoleh sebesar 3369.748 dengan lambda optimal masing-masing prediktor adalah 4,61 dan 25,57.
Gambar 2. Plot Pemilihan lamda
Output r dengan menggunakan package Quantreg diperoleh sebagai berikut
Parametric coefficients:
Estimate Std. Error t value Pr(>|t|) (Intercept) 46.70 3.01 15.51 <2e-16 *** ---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Approximate significance of qss terms:
EDF Lambda Penalty F value Pr(>F) x1 1 4.6 0.361 17.38 3.72e-05 *** x2 1 25.6 0.192 102.71 < 2e-16 *** ---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Quantile Fidelity at tau = 0.5 is 1984.82
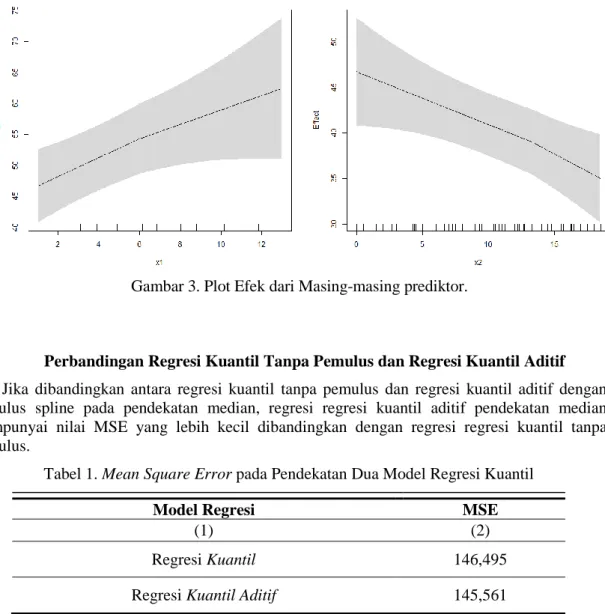
Gambar 3. Plot Efek dari Masing-masing prediktor.
Perbandingan Regresi Kuantil Tanpa Pemulus dan Regresi Kuantil Aditif
Jika dibandingkan antara regresi kuantil tanpa pemulus dan regresi kuantil aditif dengan pemulus spline pada pendekatan median, regresi regresi kuantil aditif pendekatan median mempunyai nilai MSE yang lebih kecil dibandingkan dengan regresi regresi kuantil tanpa pemulus.
Tabel 1. Mean Square Error pada Pendekatan Dua Model Regresi Kuantil
Model Regresi MSE
(1) (2)
Regresi Kuantil 146,495
Regresi Kuantil Aditif 145,561
4. KESIMPULAN
Pada penelitian ini disimpulkan bahwa kinerja regresi kuantil aditif dengan pemulus spline pada pendekatan median lebih optimal dibandingkan dengan regresi kuantil tanpa pemulus. Ini dibuktikan perbandingan nilai MSE regresi kuantil aditif dengan pemulus spline pada pendekatan median lebih kecil daripada MSE regresi kuantil tanpa pemulus. Ini dikarenakan adanya pemulus yang dapat mengikuti sebaran pola data dengan lebih baik.
5. DAFTAR PUSTAKA
[1] Koenker R, Machado AF. 1999. Goodness of Fit and Related Inference Processes for Quantile Regression. JASA 94: 1296–1310..
[2] Koenker R. 2011 Additive models for quantile regression: Model selection and confidence bandaids. Brazilian Journal of Probability and Statistics. Vol. 25, No. 3, 239–262
[3] Anik Djuraidah. 2009. Regresi Kuantil Spline Untuk Pemodelan Nilai Ekstrem Pada Pencemar Udara Pm10 Di Kota Surabaya. Seminar Nasional Statistika IX Institut Teknologi Sepuluh Nopember.
[4] Andriyana, Yudhie. 2015. P-Splines Quantile Regression in Varying Coefficient Models. Dissertation. KU Leuven.
[5] Hastie, T.J. and R.J. Tibshirani. 1990. Generalized Additive Models. Chapman and Hall, London.
[6] Hudoyo, L.P. 2017. Pemodelan Hubungan Antara Rata-Rata Lama Sekolah dan Pengeluaran Rumah Tangga Menggunakan Constained B-Splines (COBS) Pada Regresi Kuantil. Tesis: Tidak Dipublikasikan. Bandung: Universitas Padjadjaran.
[7] Koenker, R., Ng, P.T, and Portnoy, S.L. 1994. Quantile Smoothing Splines. Biometric, 81, 673–680.
[8] Mulyani, Sri. 2017. Pemodelan Hubungan Indeks Pembangunan Manusia dan Persentase Penduduk Miskin Menggunakan Regresi Kuantil Smoothing Splines. Tesis: Tidak Dipublikasikan. Bandung: Universitas Padjadjaran.