APLIKASI
APLIKASIAPLIKASI DATAAPLIKASIDATADATADATA MININGMININGMININGMINING UNTUKUNTUKUNTUKUNTUK MENAMPILKANMENAMPILKAN INFORMASIMENAMPILKANMENAMPILKANINFORMASIINFORMASIINFORMASI TINGKATTINGKATTINGKATTINGKAT KELULUSANKELULUSANKELULUSANKELULUSAN MAHASISWA
MAHASISWA MAHASISWA MAHASISWA Akhmad
Akhmad Akhmad
Akhmad UlilUlilUlilUlil AlbabAlbabAlbabAlbab1111,,,, AdeAdeAdeAde Eviyanti,Eviyanti,Eviyanti,Eviyanti, S.Kom.S.Kom.S.Kom.S.Kom.2222
Teknik Informatika, Universitas Muhammadiyah Sidoarjo Jl. Raya Gelam 250, Candi – Sidoarjo
[email protected],[email protected]2
Abstrak AbstrakAbstrakAbstrak
Tingkat kelulusan program pendidikan akademik strata 1 memiliki beban studi sekurang-kurangnya 144 (seratus empat puluh empat) sks (satuan kredit semester) dan sebanyak-banyaknya 160 (seratus enam puluh ) sks yang dijadwalkan untuk 8 (delapan) semester dan dapat ditempuh dalam waktu kurang dari 8 (delapan) semester dan paling lama 14 (empat belas) semester. Data mining, sering juga disebut knowledge discovery in database (KDD), adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Keluaran dari data mining ini bisa dipakai untuk memperbaiki pengambilan keputusan di masa depan.
Metode Naive Bayes adalah suatu metode untuk memulai prediksi suatu data dari fakta-fakta yang ada menuju suatu kesimpulan. Berdasarkan uraian tersebut diatas, maka dilakukan penelitian penerapan metode Naive Bayes pada proses menampilkan tingkat kelulusan mahasiswa dengan menggunakan data master dan faktor-faktor yang mempengaruhi sehingga diharapkan akan mendapat suatu output yang berupa informasi bagi universitas maupun bagi mahasiswai,dengan adanya informasi tersebut kita dapat menyimpulkan apakah mahasiswa akan lulus tepat waktu ataupun terlambat.
Kata
KataKataKata Kunci:Kunci:Kunci:Kunci:Tingkat kelulusan, data mining, naive bayes
Abstract Abstract Abstract Abstract
The graduation rate academic education program strata 1 has a study load of at least 144 ( one hundred and forty-four ) SKS ( semester credit units ) and up to 160 ( one hundred and sixty ) credits which are scheduled for 8 ( eight ) semesters and can be reached within less than eight (8 ) semesters and a maximum of 14 ( fourteen ) semester. Data mining , often also called knowledge discovery in databases ( KDD ) , is an activity that includes the collection , use historical data to find regularities , patterns or relationships in large data sets . Output of data mining can be used to improve decision making in the future .
Naive Bayes method is a method to start the prediction of the data of facts that exist towards a conclusion . Based on the description above, the application of the research performed at the Naive Bayes method to show the graduation rate of students using the master data and the factors that influence which is expected to receive an output in the form of information to the university and for mahasiswai , with this information we can conclude whether students will graduate on time or late
Keyword Keyword
KeywordKeyword ::::Graduation rates , data mining , Naive Bayes
1. 1. 1.
1. LatarLatarLatarLatar BelakangBelakangBelakangBelakang
Perguruan tinggi saat ini dituntut untuk memiliki keunggulan bersaing dengan memanfaatkan semua sumber daya yang dimiliki. Selain sumber daya sarana, prasarana, dan manusia, sistem informasi adalah salah satu sumber daya yang dapat digunakan untuk meningkatkan keunggulan bersaing. Sistem informasi dapat digunakan untuk mendapatkan, mengolah dan menyebarkan informasi untuk menunjang kegiatan operasional sehari-hari sekaligus menunjang kegiatan pengambilan keputusan strategis.
Di dalam peraturan akademik Universitas MUHAMMADIYAH SIDOARJO “Program Sarjana (S1) reguler adalah program pendidikan akademik setelah pendidikan menengah, yang memiliki beban studi sekurang-kurangnya 144
(seratus empat puluh empat) sks (satuan kredit semester) dan sebanyak-banyaknya 160 (seratus enam puluh ) sks yang dijadwalkan untuk 8 (delapan) semester dan dapat ditempuh dalam waktu kurang dari 8 (delapan) semester dan paling lama 14 (empat belas) semester”. Berdasarkan buku panduan akademik tahun 2011/2012, peserta wisuda Program Sarjana (S1) reguler di Fakultas Teknik Jurusan Informatika menempuh masa studi lebih dari 8 semester. Hal ini menunjukkan bahwa masih banyak mahasiswa Program Sarjana (S1) reguler di Fakultas Teknik Informatika yang menempuh lama studi lebih dari 8 semester dari yang dijadwalkan 8 semester.
mendatang. Namun kebutuhan informasi yang tinggi kadang tidak diimbangi dengan penyajian informasi yang memadai, sering kali informasi tersebut masih harus di gali ulang dari data yang jumlahnya sangat besar. Kemampuan teknologi informasi untuk mengumpulkan dan menyimpan berbagai tipe data jauh meninggalkan kemampuan untuk menganalisis, meringkas dan mengekstrak pengetahuan dari data. Metode tradisional untuk menganalisis data yang ada, tidak dapat menangani data dalam jumlah besar.
Pemanfaatan data yang ada di dalam sistem informasi untuk menunjang kegiatan pengambilan keputusan, tidak cukup hanya mengandalkan data operasional saja, diperlukan suatu analisis data untuk menggali potensi-potensi informasi yang ada. Para pengambil keputusan berusaha untuk memanfaatkan gudang data yang sudah dimiliki untuk menggali informasi yang berguna membantu mengambil keputusan, hal ini mendorong munculnya cabang ilmu baru untuk mengatasi masalah penggalian informasi atau pola yang penting atau menarik dari data dalam jumlah besar, yang disebut dengan data mining.
Penggunaan teknik data mining diharapkan dapat memberikan pengetahuan-pengetahuan yang sebelumnya tersembunyi di dalam gudang data sehingga menjadi informasi yang berharga. Oleh karena itu, dengan memanfaatkan data induk mahasiswa dan data kelulusan mahasiswa, dapat diketahui informasi tingkat kelulusan mahasiswa melalui teknikdata mining.
Metode Naive Bayes adalah suatu metode untuk memulai prediksi suatu data dari fakta-fakta yang ada menuju suatu kesimpulan. Berdasarkan uraian tersebut diatas, maka dilakukan penelitian penerapan metode Naive Bayes pada proses menampilkan tingkat kelulusan mahasiswa sehingga diharapkan akan mendapat suatu output yang berupa informasi bagi universitas maupun bagi mahasiswai,dengan adanya informasi tersebut kita dapat menyimpulkan apakah mahasiswa akan lulus tepat waktu ataupun terlambat. Pada metode
Naive Bayes, pelacakan dimulai dari penelusuran
semua data dan faktor-faktor yang mempengaruhi tingkat kelulusan mahasiwa untuk mendapat informasi yang lebih akurat. Metode Naive Bayes
cocok untuk menampilkan informasi tingkat kelulusan mahasiswa dengan pelacakan dari faktor-faktor yang mempengaruhi tingkat kelulusan.
1.2 1.2 1.2
1.2 BatasanBatasanBatasanBatasan MasalahMasalahMasalahMasalah
Untuk menghindari pembahasan diluar permasalahan,berikut ini adalah batasan permasalahan :
1. Data yang diambil adalah data mahasiswa angkatan 2009 dan 2010 dengan ruang lingkup fakultas teknik informatika.
2. Pembahasan terfokus pada program sarjana S1 reguler di fakultas informatika MUHAMMADIYAH Sidoarjo.
3. Tingkat kelulusan diukur dari lama studi, IPK, jenis kelamin, status mahasiswa, mahasiswa masuk, dan asal sekolah
2. 2. 2.
2. LandasanLandasanLandasanLandasan TeoriTeoriTeoriTeori 2.2.1
2.2.1 2.2.1
2.2.1 ProdiProdiProdiProdi TeknikTeknikTeknikTeknik InformatikaInformatikaInformatikaInformatika
Seiring dengan perkembangan teknologi informasi prodi teknik informatika merupakan jurusan yang paling banyak diminati oleh para lulusan SMA,SMK, dan MA. Ini tercermin pada jumlah mahasiswa prodi teknik informatika yang terus meningkat pada tiap tahunnya. Program pendidikan akademik memiliki beban studi sekurang-kurangnya 144 (seratus empat puluh empat) sks (satuan kredit semester) dan sebanyak-banyaknya 160 (seratus enam puluh ) sks yang dijadwalkan untuk 8 (delapan) semester dan dapat ditempuh dalam waktu kurang dari 8 (delapan) semester dan paling lama 14 (empat belas) semester. Berdasarkan buku panduan akademik tahun 2011, peserta wisuda Program Sarjana (S1) reguler di Fakultas Teknik Jurusan Informatika menempuh masa studi lebih dari 8 semester. Hal ini menunjukkan bahwa masih banyak mahasiswa Program Sarjana (S1) reguler di Fakultas Teknik Informatika yang menempuh lama studi lebih dari 8 semester dari yang dijadwalkan 8 semester.
2.2.2 2.2.2 2.2.2
2.2.2 DataDataDataData MiningMiningMiningMining
Secara sederhana data mining adalah penambangan atau penemuan informasi baru dengan mencari pola atau aturan tertentu dari sejumlah data yang sangat besar (Davies, 2004).
Data mining juga disebut sebagai serangkaian
proses untuk menggali nilai tambah berupa pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data (Pramudiono, 2007). Data mining, sering juga disebut sebagai
knowledge discovery in database (KDD). KDD
adalah kegiatan yang meliputi pengumpulan, pemakaian data, historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar (Santoso, 2007).
Data miningadalah kegiatan menemukan pola
yang menarik dari data dalam jumlah besar, data dapat disimpan dalam database, data warehouse, atau penyimpanan informasi lainnya. Data mining
berkaitan dengan bidang ilmu – ilmu lain, seperti
database system, data warehousing, statistik,
machine learning, information retrieval, dan
komputasi tingkat tinggi. Selain itu, data mining
didukung oleh ilmu lain seperti neural network, pengenalan pola, spatial data analysis, image
mining didefinisikan sebagai proses menemukan pola-pola dalam data. Proses ini otomatis atau seringnya semiotomatis. Pola yang ditemukan harus penuh arti dan pola tersebut memberikan keuntungan, biasanya keuntungan secara ekonomi. Data yang dibutuhkan dalam jumlah besar (Witten, 2005).
Karakteristikdata miningsebagai berikut
1 Data mining berhubungan dengan penemuan
sesuatu yang tersembunyi dan pola data tertentu yang tidak diketahui sebelumnya.
2 Data mining biasa menggunakan data yang
sangat besar. Biasanya data yang besar digunakan untuk membuat hasil lebih dipercaya.
3 Data miningberguna untuk membuat keputusan
yang kritis, terutama dalam strategi (Davies, 2004). Berdasarkan beberapa pengertian tersebut dapat ditarik kesimpulan bahwadata miningadalah suatu teknik menggali informasi berharga yang terpendam atau tersembunyi pada suatu koleksi data (database) yang sangat besar sehingga ditemukan suatu pola yang menarik yang sebelumnya tidak diketahui. Kata mining sendiri berarti usaha untuk mendapatkan sedikit barang berharga dari sejumlah besar material dasar. Karena
itu data mining sebenarnya memiliki akar yang
panjang dari bidang ilmu seperti kecerdasan buatan
(artificial intelligent), machine learning, statistik
dan database. Beberapa metode yang sering
disebutsebut dalam literatur data mining antara
lain clustering, classification, association rules
mining, neural network, genetic algorithm dan
lain-lain (Pramudiono, 2007).
2.2.1.1 2.2.1.1 2.2.1.1
2.2.1.1 PengenalanPengenalanPengenalanPengenalan Pola,Pola,Pola,Pola, Data MiningDataDataData MiningMiningMining,,,, dandandandan Machine
Machine Machine
Machine LearningLearningLearningLearning
Pengenalan pola adalah suatu disiplin ilmu yang mempelajari cara-cara mengklasifikasikan obyek ke beberapa kelas atau kategori dan mengenali kecenderungan data. Tergantung pada aplikasinya, obyek-obyek ini bisa berupa pasien, mahasiswa, pemohon kredit,imageatausignalatau pengukuran lain yang perlu diklasifikasikan atau dicari fungsi regresinya (Santoso, 2007).
Data mining, sering juga disebut
knowledge discovery in database (KDD), adalah
kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Keluaran dari data mining ini bisa dipakai untuk memperbaiki pengambilan keputusan di masa depan. Sehingga istilahpattern recognitionjarang
digunakan karena termasuk bagian dari data
mining(Santoso, 2007).
Machine Learningadalah suatu area dalam
artificial intelligenceatau kecerdasan buatan yang
berhubungan dengan pengembangan teknik-teknik yang bisa diprogramkan dan belajar dari data masa lalu. Pengenalan pola, data mining dan
machine learningsering dipakai untuk menyebut
sesuatu yang sama. Bidang ini bersinggungan dengan ilmu probabilitas dan statistik kadang juga optimasi. Machine learning menjadi alat analisis dalam data mining. Bagaimana bidangbidang ini berhubungan bisa dilihat dalam gambar 2.4 (Santoso, 2007).
2.2.2.2 2.2.2.2 2.2.2.2
2.2.2.2 Tahap-TahapTahap-TahapTahap-TahapTahap-TahapDataDataDataData miningminingminingmining
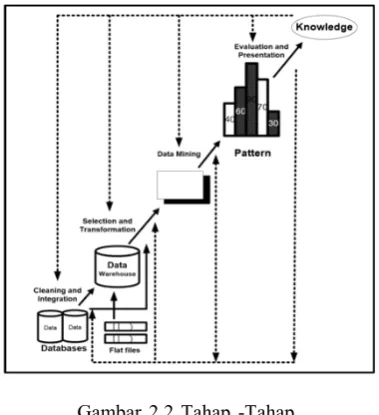
Sebagai suatu rangkaian proses,data mining
dapat dibagi menjadi beberapa tahap yang diilustrasikan di Gambar 2.5. Tahap-tahap tersebut bersifat interaktif, pemakai terlibat langsung atau dengan perantaraanknowledge base.
Gambar 2.2 Tahap -Tahap Data Mining
Tahap-tahapdata miningada 6 yaitu :
1.
Pembersihan data (data cleaning)Pembersihan data merupakan proses menghilangkan noise dan data yang tidak konsisten atau data tidak relevan. Pada umumnya data yang diperoleh, baik dari
database suatu perusahaan maupun hasil
lebih baik dibuang. Pembersihan data juga akan mempengaruhi performasi dari teknik data
mining karena data yang ditangani akan
berkurang jumlah dan kompleksitasnya.
2.
Integrasi data (data integration)Integrasi data merupakan penggabungan data dari berbagai databaseke dalam satudatabase
baru. Tidak jarang data yang diperlukan untuk
data mining tidak hanya berasal dari satu
database tetapi juga berasal dari beberapa
databaseatau file teks. Integrasi data dilakukan
pada atribut-aribut yang mengidentifikasikan entitas-entitas yang unik seperti atribut nama, jenis produk, nomor pelanggan dan lainnya. Integrasi data perlu dilakukan secara cermat karena kesalahan pada integrasi data bisa menghasilkan hasil yang menyimpang dan bahkan menyesatkan pengambilan aksi nantinya. Sebagai contoh bila integrasi data berdasarkan jenis produk ternyata menggabungkan produk dari kategori yang berbeda maka akan didapatkan korelasi antar produk yang sebenarnya tidak ada.
3.
Seleksi Data (Data Selection)Data yang ada pada database sering kali tidak semuanya dipakai, oleh karena itu hanya data yang sesuai untuk dianalisis yang akan diambil
dari database. Sebagai contoh, sebuah kasus
yang meneliti faktor kecenderungan orang membeli dalam kasus market basket analysis,
tidak perlu mengambil nama pelanggan, cukup dengan id pelanggan saja.
4.
Transformasi data (Data Transformation) Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalamdata mining. Beberapa metode data mining membutuhkan format data yang khusus sebelum bisa diaplikasikan. Sebagai contoh beberapa metode standar seperti analisis asosiasi dan clusteringhanya bisa menerima input data kategorikal. Karenanya data berupa angka numerik yang berlanjut perlu dibagibagi menjadi beberapa interval. Proses ini sering disebut transformasi data.
5.
Prosesmining,Merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data.
6.
Evaluasi pola (pattern evaluation),Untuk mengidentifikasi pola-pola menarik kedalam knowledge based yang ditemukan. Dalam tahap ini hasil dari teknik data mining
berupa pola-pola yang khas maupun model prediksi dievaluasi untuk menilai apakah hipotesa yang ada memang tercapai. Bila ternyata hasil yang diperoleh tidak sesuai hipotesa ada beberapa alternatif yang dapat diambil seperti menjadikannya umpan balik untuk memperbaiki proses data mining, mencoba metode data mining lain yang lebih sesuai, atau menerima hasil ini sebagai suatu hasil yang di luar dugaan yang mungkin bermanfaat.
7.
Presentasi pengetahuan (knowledgepresentation),
Merupakan visualisasi dan penyajian pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna. Tahap terakhir dari proses data
mining adalah bagaimana memformulasikan
keputusan atau aksi dari hasil analisis yang didapat. Ada kalanya hal ini harus melibatkan orang-orang yang tidak memahamidata mining. Karenanya presentasi hasil data mining dalam bentuk pengetahuan yang bisa dipahami semua orang adalah satu tahapan yang diperlukan dalam prosesdata mining. Dalam presentasi ini, visualisasi juga bisa membantu mengkomunikasikan hasil data mining (Han, 2006).
2.2.3 2.2.3 2.2.3
2.2.3 PengertianPengertianPengertianPengertian MetodeMetodeMetodeMetode NaiveNaiveNaiveNaive BayesBayesBayesBayes
Naive Bayes Classifier merupakan salah
satu metode pengklasifikasian sederhana yang berdasarkan pada penerapan Teorema Bayes dengan asumsi antar variabel penjelas saling bebas
(independen). Algoritma ini memanfaatkan metode
probabilitas dan statistik yang dikemukakan oleh ilmuwan Inggris Thomas Bayes, yaitu memprediksi probabilitas di masa depan berdasarkan pengalaman di masa sebelumnya. Dua kelompok peneliti, satu oleh Pantel dan Lin, dan yang lain oleh Microsoft Research memperkenalkan metode statistik Bayesian ini pada teknologi anti spam filter. Tetapi yang membuat algoritma Bayesian filtering ini popular adalah pendekatan yang dilakukan oleh Paul Graham.
Algoritma Naive Bayes merupakan salah satu algoritma yang terdapat pada teknik klasifikasi.
Naive Bayes merupakan pengklasifikasian dengan
sebagai Teorema Bayes. Teorema tersebut dikombinasikan dengan Naive dimana diasumsikan kondisi antar atribut saling bebas. KlasifikasiNaive
Bayes diasumsikan bahwa ada atau tidak ciri
tertentu dari sebuah kelas tidak ada hubungannya dengan ciri dari kelas lainnya.
Persamaan dari teorema Bayes adalah :
Bayes' Teorema berhubungan dengan kondisi dan marjinal kendala peristiwa-peristiwaA dan B,dimanaBtelah non-vanishing kemungkinan:
PHX=
. (H)
(X)
PXH P
P
Di mana :
X:Data denganclassyang belum diketahui
H: Hipotesis data merupakan suatuclassspesifik
P(H|X):Probabilitas hipotesisHberdasar kondisiX
(posteriori probabilitas)
P(H): Probabilitas hipotesisH(prior probabilitas)
P(X|H) :Probabilitas X berdasarkan kondisi pada
hipotesisH
P(X): ProbabilitasX
Untuk menjelaskan metode Naive Bayes, perlu diketahui bahwa proses klasifikasi memerlukan sejumlah petunjuk untuk menentukan kelas apa yang cocok bagi sampel yang dianalisis tersebut. Karena itu, metodeNaive Bayesdi atas disesuaikan sebagai berikut :
P C F1...Fn=
(F1...Fn | C)
(F1...Fn)
PCP
P
Di mana Variabel C merepresentasikan kelas, sementara variabel F1 ... Fn merepresentasikan karakteristik petunjuk yang dibutuhkan untuk melakukan klasifikasi. Maka rumus tersebut menjelaskan bahwa peluang masuknya sampel karakteristik tertentu dalam kelas C (Posterior) adalah peluang munculnya kelas C (sebelum masuknya sampel tersebut, seringkali disebutprior), dikali dengan peluang kemunculan karakteristik karakteristik sampel pada kelas C (disebut juga
likelihood), dibagi dengan peluang kemunculan
karakteristik karakteristik sampel secara global ( disebut juga evidence). Karena itu, rumus diatas dapat pula ditulis secara sederhana sebagai berikut : Posterior=
priorxlikehood
evidence
NilaiEvidenceselalu tetap untuk setiap kelas pada satu sampel.Untuk klasifikasi dengan data kontinyu digunakan rumusDensitas Gauss:
2 Y: Kelas yang dicari
yi: Sub kelasYyang dicari
μ : mean, menyatakan rata – rata dari seluruh atribut
σ:Deviasi standar, menyatakan varian dari
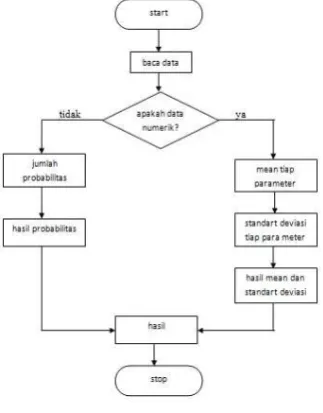
Hitung Jumlah dan probabilitas, namun apabila data numerik maka :
a. Cari nilaimean dan standar deviasi dari masing masing parameter yang merupakan data numerik. Adapun persamaan yang digunakan untuk menghitung nilai rata – rata hitung (mean ) dapat dilihat sebagai berikut :
1 n: jumlah sampel
dan persamaan untuk menghitung nilai simpangan baku ( standar deviasi ) dapat dilihat sebagai berikut:
σ: standar deviasi xi : nilai x ke -i μ: rata-rata hitung n : jumlah sampel
Mengingat data mempunyai banyak atribut, maka akan sangat sulit dalam mengkomputasi untuk menghitung P(X|Ci). Agar dapat mengurangi perhitungan dalam mengevaluasi P(X|Ci), asumsi
naïve independensi kelas bersyarat dibuat.
Dianggap bahwa nilai-nilai dari atribut adalah kondisional independen satu sama lain, diberikan kelas label dari tuple (yaitu bahwa tidak ada hubungan ketergantungan diantara atribut ) dengan demikian :
Maka dapat dengan mudah memperkirakan probabilitas P (x1 | Ci), P (x2 | Ci),. . . , P (xn | Ci) dari pelatihantuple.
3.1 3.1 3.1
3.1 PerancanganPerancanganPerancanganPerancangan SistemSistemSistemSistem 1.
1. 1.
1.PerancanganPerancanganPerancanganPerancangan MesinMesinMesinMesin InferensiInferensiInferensiInferensi
data mining dan nive bayesflowchartatau diagram alir
Gambar 3.1 Flowchat data mining
Gambar 3.2 flowchart naive bayes
4. 4. 4.
4. HASILHASILHASILHASIL DANDANDANDAN PEMBAHASANPEMBAHASANPEMBAHASANPEMBAHASAN
4444....1Pengujian1Pengujian1Pengujian1Pengujian AplikasiAplikasiAplikasiAplikasi DataDataDataData MiningMiningMiningMining UntukUntukUntukUntuk Menampilkan
Menampilkan Menampilkan
Menampilkan InformasiInformasiInformasiInformasi TingkatTingkatTingkatTingkat KelulusanKelulusanKelulusanKelulusan Mahasiswa
Mahasiswa Mahasiswa Mahasiswa Tampilan Tampilan Tampilan
Tampilan AplikasiAplikasiAplikasiAplikasi
Halaman yang pertama kali muncul dari aplikasi data mining untuk menentukan informasi tingkat kelulusan mahasiswa adalah. Pada tampilan awal aplikasi terdapat menu “Home, Data mining model probabilitas , Data distribusi normal dan Tentang”. Menu “Home” merupakan halamam utama aplikasi data minig untuk menentukan informasi tigkat kelulusan mahasiswa. Menu “Data mining model probabilias” digunakan oleh user untuk melakukan input data mahasiswa. Pada menu "data distribusi normal" menampilkan data mahasiswa master. Menu “Tentang” digunakan untuk menjelaskan dan memberi pengetahuan bagaimana alur perhitungan aloritma naive bayes.
Gambar 4.7Tampilan halaman utama
1. 1. 1.
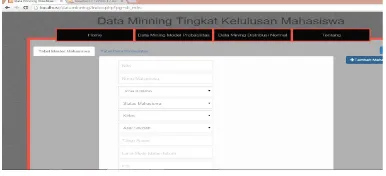
1. MenuMenuMenuMenu DataDataDataData MiningMiningMiningMining modelmodelmodelmodel ProbabilitasProbabilitasProbabilitasProbabilitas
Menu data mining model probabilitas digunakan oleh user untuk memasukkan data mahasiswa. Pada menu ini user harus memasukkan identitas berupa nama, jenis kelamin, status mahasiswa, kelas, asal sekolah dan IPK, dan Pada bagian bawah terdapat tombol “proses” kemudian hasil dari inputan tersebut di proses dan menunjukkan hasilnya apakah mahasiswa tersebut dapat lulus tepat waktu atau terlambat.
Mulai
Selesai
Basis Data Realisional
Transformasi Data
Ekstrasi Data
Pembersihan Data
Gambar 4.8 Tampilan inputan mahasiswa
2. 2. 2.
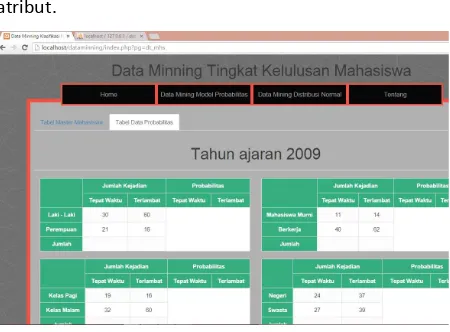
2. MenuMenuMenuMenu DataDataDataData MiningMiningMiningMining distribusidistribusidistribusidistribusi NormalNormalNormalNormal
Menu ini digunakan untuk menunjukkan data master. Data master adalah data mahasiswa yang digunakan utuk memproses data mahasiswa yang akan di inputkan.
4.9 Gambar Tampilan menu data distribusi normal
Tabel probabilitas adalah tabel untuk mengetahui perhitungan probabilitas setiap
atribut.
4.10 Gambar tampilan tabel probabilitas
3. 3. 3.
3. MenuMenuMenuMenu TentangTentangTentangTentang
Menu Tentang adalah petunjuk bagi user bagaimana cara perhitungan dari algoritma naive bayes.
Gambar 4.11 Tampilan menu tentang
5. 5. 5.
5. MenuMenuMenuMenu LoginLoginLoginLogin
Menu login merupakan menu yang digunakan oleh admin untuk masuk kesistem yang bertujuan untuk mengelola data mahasiswa.
Gambar 4.12 Tampilan menu login
6. 6. 6.
6. MenuMenuMenuMenu HalamanHalamanHalamanHalaman AdminAdminAdminAdmin
Gambar 4.13 Tampilan menu gejala halaman pakar
4.2.2 4.2.2 4.2.2
4.2.2 PengujianPengujianPengujianPengujian AplikasiAplikasiAplikasiAplikasi 6.
6. 6.
6. MenuMenuMenuMenu DataDataDataData MiningMiningMiningMining ModelModelModelModel ProbabilitasProbabilitasProbabilitasProbabilitas
Menu data mining model probabilitas digunakan oleh user untuk memasukkan data mahasiswa. Pada menu ini user harus memasukkan identitas berupa nama, jenis kelamin, status mahasiswa, kelas, asal sekolah dan IPK, disini IPK yang digunakan adalah hasil IPK maksimal IPK semester 8 lalu Pada bagian bawah terdapat tombol “proses” kemudian hasil dari inputan tersebut di proses berdasarkan data yang dimasukkan dan menampilkan hasilnya apakah mahasiswa tersebut dapat lulus tepat waktu atau terlambat.
Contoh dari proses data mining model probabilitas setelah data di inputkan.
Gambar 4.14 Input mahasiswa
Kemudian tekan tombol proses untuk mengetahui apakah mahasiswa tersebut lulus tepat waktu atau lulus terlambat.
Gambar 4.15 Hasil Proses
Gambar 4.10 Hasil Proses
5.1 5.1 5.1
5.1 KesimpulanKesimpulanKesimpulanKesimpulan
Setelah penulis menguraikan secara menyeluruh tentang perancangan dan implementasi dari Aplikasi Data Mining Untuk Menampilkan Informasi Tingkat Kelulusan Mahasiswa ini, maka penulis mengambil beberapa kesimpulan yaitu :
1. Penggunan teknik data mining diharapkan dapat memberikan pengetahuan yang sebelumnya tersembunyi di dalam gudang data sehingga menjadi informasi yang berharga, oleh karena itu dengn memanfaatkan data master mahasiswa dan data kelulusan mahasiswa, sehingga dapat diketahui informasi tigkat kelulusan mahasiswa melalui teknik data mining. Kebanyakan mahsiswa sekarng tidak mengetahui apakah mereka lulus tepat waktu atau lulus terlambat. Oleh karena itu, dengan mengandalkan kemajuan teknologi dan informasi, Sistem Aplikasi Data Mining Untuk Menentukan Informasi Tigkat Kelulusan Mahasiswa diharapkan mampu memprediksi tingkat kelulusan mahsiswa secara cepat, tepat, dan akurat. Penulis berharap agar kedepannya maahsiswa mendapatkan informasi tentang tingkat kelulusannya. 2. Aplikasi Data Mining Untuk Menentukan
Informasi Tigkat Kelulusan Mahasiswa bisa melacak melalui penelusuran data dan faktor-faktor yang mempengruhi tingkat kelulusan mahasiswa untuk mendapat informasi yang lebih akurat. 3. Dengan adanya Aplikasi Data Mining
Untuk Menentukan Informasi Tigkat Kelulusan Mahasiswa ini maka dapat memberikan informasi bagi mahasiswa dan universitas berapa persen mahasiswa yang akan lulus tepat waktu dn lulus terlambat.
5.2 5.2 5.2 5.2 SaranSaranSaranSaran
memiliki beberapa kekurangan. Saran yang dapat diberikan untuk pengembangan penelitian selanjutnya antara lain :
1. Untuk pengembangan lebih lanjut, sistem ini dapat dikembangkan dengan menggunakan metode yang berbeda atau mengkombinasikan algoritma naive bayes dengan metode lain.
2. Sistem dapat dikembangkan untuk kasus pada domain lain, yang memiliki data dan faktor-faktor lain.
3. Dapat dikembangkan ke platform yang lain seperti IOS dan android.
DAFTAR DAFTAR DAFTAR
DAFTAR PUSTAKAPUSTAKAPUSTAKAPUSTAKA
Huda Nuqson Masykur (2010), "Aplikasi Data Minning untuk Menampilkan Tingkat
Kelulusan Mahasiswa". Fakultas MIPA. Fachrurozi Much. (2012), "Penerapan Data Minning Untuk Menganalisa Tingkat Kelulusan Mahasiswa Terhadap Matakuliah Dengan MetodeKernel Means clustering". Universitas Muhammadiyah Sidoarjo.
Pramudiono, I. 2007.Pengantar Data Mining : Menambang Permata Pengetahuan di Gunung
Data.
http://www.ilmukomputer.org/wp-content/uploads/2006/08/iko-datamining.zip
Diakses pada tanggal 15 Maret 2009 jam 08.54 Santosa, Budi, 2007, “Data Mining Teknik Pemanfaatan Data untuk Keperluan Bisnis”,
Graha Ilmu, Yogyakarta.
Witten, I. H and Frank, E. 2005.Data Mining : Practical Machine Learning Tools and
Techniques Second Edition. Morgan Kauffman :
San Francisco.
Han, J. and Kamber, M, 2006, “Data Mining
Concepts and Techniques Second Edition”.
Morgan Kauffman, San Francisco.
Darmanto Eko, Fithri Diana Laily (2014),"Sistem Pendukung Keputusan untuk Memprediksi Kelulusan Mahasiswa Menggunakan Metode Naive Bayes". Universitas Muria Kudus.
Bustami (2013), "Penerapan Algoritma Naive
Bayes Untuk Mengklasifikasi Data Nasabah
Asuransi". Universitas Malikussaleh. (jurnal penelitian)