▸ Baca selengkapnya: astra spark test
(2)Scala and Spark for Big Data Analytics
Tame big data with Scala and Apache Spark!
Md. Rezaul Karim
Sridhar Alla
Scala and Spark for Big Data Analytics
Copyright © 2017 Packt Publishing
All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or
transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews.
Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the authors, nor Packt Publishing, and its dealers and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book.
Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information.
First published: July 2017
Production reference: 1210717
Published by Packt Publishing Ltd.
Livery Place
35 Livery Street
Birmingham
B3 2PB, UK.
ISBN 978-1-78528-084-9
Credits
Authors
Md. Rezaul Karim Sridhar Alla
Copy Editor
Safis Editing
Reviewers
Andrea Bessi Sumit Pal
Project Coordinator
Ulhas Kambali
Commissioning Editor
Aaron Lazar
Proofreader
Acquisition Editor
Nitin Dasan
Indexer
Rekha Nair
Content Development Editor
Vikas Tiwari
Cover Work
Melwyn Dsa
Technical Editor
Subhalaxmi Nadar
Production Coordinator
About the Authors
Md. Rezaul Karim is a research scientist at Fraunhofer FIT, Germany. He is also a PhD candidate at RWTH Aachen University, Aachen, Germany. He holds a BSc and an MSc in computer science. Before joining Fraunhofer FIT, he had been working as a researcher at the Insight Centre for data analytics, Ireland. Previously, he worked as a lead engineer with Samsung Electronics' distributed R&D centers in Korea, India, Vietnam, Turkey, and Bangladesh. Earlier, he worked as a research assistant in the Database Lab at Kyung Hee University, Korea, and as an R&D engineer with BMTech21 Worldwide, Korea. Even before that, he worked as a software engineer with i2SoftTechnology, Dhaka, Bangladesh.
He has more than 8 years of experience in the area of research and development, with a solid
knowledge of algorithms and data structures in C/C++, Java, Scala, R, and Python-focused big data technologies: Spark, Kafka, DC/OS, Docker, Mesos, Zeppelin, Hadoop, and MapReduce, and deep learning technologies: TensorFlow, DeepLearning4j, and H2O-Sparking Water. His research
interests include machine learning, deep learning, semantic web, linked data, big data, and bioinformatics. He is the author of the following book titles with Packt:
Large-Scale Machine Learning with Spark Deep Learning with TensorFlow
I am very grateful to my parents, who have always encouraged me to pursue knowledge. I also want to thank my wife Saroar, son Shadman, elder brother Mamtaz, elder sister Josna, and friends, who have endured my long monologues about the subjects in this book, and have always been encouraging and listening to me. Writing this book was made easier by the amazing efforts of the open source community and the great documentation of many projects out there related to Apache Spark and Scala. Further more, I would like to thank the acquisition, content development, and technical editors of Packt (and others who were involved in this book title) for their sincere cooperation and coordination. Additionally, without the work of numerous researchers and data analytics practitioners who shared their expertise in publications, lectures, and source code, this book might not exist at all!
Sridhar Alla is a big data expert helping small and big companies solve complex problems, such as data warehousing, governance, security, real-time processing, high-frequency trading, and
establishing large-scale data science practices. He is an agile practitioner as well as a certified agile DevOps practitioner and implementer. He started his career as a storage software engineer at
Network Appliance, Sunnyvale, and then worked as the chief technology officer at a cyber security firm, eIQNetworks, Boston. His job profile includes the role of the director of data science and engineering at Comcast, Philadelphia. He is an avid presenter at numerous Strata, Hadoop World, Spark Summit, and other conferences. He also provides onsite/online training on several
Sridhar has over 18 years of experience writing code in Scala, Java, C, C++, Python, R and Go. He also has extensive hands-on knowledge of Spark, Hadoop, Cassandra, HBase, MongoDB, Riak, Redis, Zeppelin, Mesos, Docker, Kafka, ElasticSearch, Solr, H2O, machine learning, text analytics, distributed computing and high performance computing.
About the Reviewers
Andre Baianov is an economist-turned-software developer, with a keen interest in data science. After a bachelor's thesis on data mining and a master's thesis on business
intelligence, he started working with Scala and Apache Spark in 2015. He is currently working as a consultant for national and international clients, helping them build
reactive architectures, machine learning frameworks, and functional programming backends.
To my wife: beneath our superficial differences, we share the same soul.
Sumit Pal is a published author with Apress for SQL on Big Data - Technology, Architecture and Innovations and SQL on Big Data - Technology, Architecture and Innovations. He has more than 22 years of experience in the software industry in various roles, spanning companies from start-ups to enterprises.
Sumit is an independent consultant working with big data, data visualization, and data science, and a software architect building end-to-end, data-driven analytic systems.
He has worked for Microsoft (SQL Server development team), Oracle (OLAP development team), and Verizon (big data analytics team) in a career spanning 22 years.
Currently, he works for multiple clients, advising them on their data architectures and big data solutions, and does hands-on coding with Spark, Scala, Java, and Python.
www.PacktPub.com
For support files and downloads related to your book, please visit www.PacktPub.com.
Did you know that Packt offers eBook versions of every book published, with PDF and ePub files available? You can upgrade to the eBook version at www.PacktPub.com and as a print book customer,
you are entitled to a discount on the eBook copy. Get in touch with us at [email protected] for more details.
At www.PacktPub.com, you can also read a collection of free technical articles, sign up for a range of free
newsletters and receive exclusive discounts and offers on Packt books and eBooks.
https://www.packtpub.com/mapt
Why subscribe?
Fully searchable across every book published by Packt Copy and paste, print, and bookmark content
Customer Feedback
Thanks for purchasing this Packt book. At Packt, quality is at the heart of our editorial process. To help us improve, please leave us an honest review on this book's Amazon page at https://www.amazon.com/ dp/1785280848.
Table of Contents
PrefaceWhat this book covers What you need for this book Who this book is for
Conventions Reader feedback Customer support
Downloading the example code
Downloading the color images of this book Errata
I'm ; the hello world program, explain me well!
Methods, classes, and objects in Scala Methods in Scala
Comparing and contrasting: val and final Access and visibility
Abstract classes and the override keyword Case classes in Scala Functional Scala for the data scientists Why FP and Scala for learning Spark?
Scala and the Spark programming model
Memory usage by collection objects Java interoperability
Using Scala implicits
Implicit conversions in Scala Summary
5. Tackle Big Data – Spark Comes to the Party Introduction to data analytics
6. Start Working with Spark – REPL and RDDs Dig deeper into Apache Spark
Reading data from an external source Transformation of an existing RDD Streaming API
Actions and Transformations
Broadcast variables
Right outer join
9. Stream Me Up, Scotty - Spark Streaming A Brief introduction to streaming
10. Everything is Connected - GraphX A brief introduction to graph theory GraphX
11. Learning Machine Learning - Spark MLlib and Spark ML Introduction to machine learning
What is regression analysis? Binary and multiclass classification
Performance metrics
Binary classification using logistic regression
Breast cancer prediction using logistic regression of Spark ML Dataset collection
Developing the pipeline using Spark ML Multiclass classification using logistic regression Improving classification accuracy using random forests
Classifying MNIST dataset using random forest Summary
12. Advanced Machine Learning Best Practices Machine learning best practices
Beware of overfitting and underfitting Stay tuned with Spark MLlib and Spark ML Choosing the right algorithm for your application Considerations when choosing an algorithm
Accuracy Training time Linearity
Inspect your data when choosing an algorithm Number of parameters
How large is your training set? Number of features
Hyperparameter tuning of ML models Hyperparameter tuning
Grid search parameter tuning Cross-validation
Credit risk analysis – An example of hyperparameter tuning What is credit risk analysis? Why is it important? The dataset exploration Topic modelling - A best practice for text clustering
How does LDA work?
Topic modeling with Spark MLlib Scalability of LDA
Summary
13. My Name is Bayes, Naive Bayes Multinomial classification
Transformation to binary
Extension from binary My name is Bayes, Naive Bayes Building a scalable classifier with NB
Tune me up! The decision trees
Advantages and disadvantages of using DTs Decision tree versus Naive Bayes
Building a scalable classifier with DT algorithm Summary
14. Time to Put Some Order - Cluster Your Data with Spark MLlib Unsupervised learning
An example of clustering using K-means of Spark MLlib Hierarchical clustering (HC)
An overview of HC algorithm and challenges Bisecting K-means with Spark MLlib
Bisecting K-means clustering of the neighborhood using Spark MLlib Distribution-based clustering (DC)
Challenges in DC algorithm
How does a Gaussian mixture model work?
An example of clustering using GMM with Spark MLlib Determining number of clusters
A comparative analysis between clustering algorithms Submitting Spark job for cluster analysis
Summary
15. Text Analytics Using Spark ML Understanding text analytics
Text analytics
Sentiment analysis Topic modeling
TF-IDF (term frequency - inverse document frequency) Named entity recognition (NER)
Standard Transformer
Visualizing Spark application using web UI
Observing the running and completed Spark jobs Debugging Spark applications using logs
Common mistakes in Spark app development Application failure
Spark ecosystem in brief Deploying the Spark application on a cluster
Submitting Spark jobs
Running Spark jobs locally and in standalone Hadoop YARN
Configuring a single-node YARN cluster Step 1: Downloading Apache Hadoop Step 2: Setting the JAVA_HOME Step 3: Creating users and groups Step 4: Creating data and log directories Step 5: Configuring core-site.xml Step 6: Configuring hdfs-site.xml Step 7: Configuring mapred-site.xml Step 8: Configuring yarn-site.xml Step 9: Setting Java heap space Step 10: Formatting HDFS Step 11: Starting the HDFS Step 12: Starting YARN
Step 13: Verifying on the web UI Submitting Spark jobs on YARN cluster Advance job submissions in a YARN cluster Apache Mesos
Client mode Cluster mode Deploying on AWS
Step 1: Key pair and access key configuration Step 2: Configuring Spark cluster on EC2 Step 3: Running Spark jobs on the AWS cluster
Step 4: Pausing, restarting, and terminating the Spark cluster Summary
18. Testing and Debugging Spark
Testing in a distributed environment Distributed environment
Issues in a distributed system
Challenges of software testing in a distributed environment Testing Spark applications
Testing Scala methods Unit testing
Method 1: Using Scala JUnit test
Method 2: Testing Scala code using FunSuite
Method 3: Making life easier with Spark testing base Configuring Hadoop runtime on Windows
Debugging Spark applications
Logging with log4j with Spark recap Debugging the Spark application
Debugging Spark application on Eclipse as Scala debug Debugging Spark jobs running as local and standalone mode Debugging Spark applications on YARN or Mesos cluster Debugging Spark application using SBT
By setting PySpark on Python IDEs Getting started with PySpark
Working with DataFrames and RDDs Reading a dataset in Libsvm format Reading a CSV file
Reading and manipulating raw text files Writing UDF on PySpark
Let's do some analytics with k-means clustering Introduction to SparkR
Metrics Current features Integration with YARN
Alluxio worker memory Alluxio master memory CPU vcores
Using Alluxio with Spark Summary
21. Interactive Data Analytics with Apache Zeppelin Introduction to Apache Zeppelin
Installation and getting started Installation and configuration
Building from source
Starting and stopping Apache Zeppelin Creating notebooks
Configuring the interpreter Data processing and visualization Complex data analytics with Zeppelin
The problem definition
Dataset descripting and exploration Data and results collaborating
Preface
The continued growth in data coupled with the need to make increasingly complex decisions against that data is creating massive hurdles that prevent organizations from deriving insights in a timely manner using traditional analytical approaches. The field of big data has become so related to these frameworks that its scope is defined by what these frameworks can handle. Whether you're
scrutinizing the clickstream from millions of visitors to optimize online ad placements, or sifting through billions of transactions to identify signs of fraud, the need for advanced analytics, such as machine learning and graph processing, to automatically glean insights from enormous volumes of data is more evident than ever.
Apache Spark, the de facto standard for big data processing, analytics, and data sciences across all academia and industries, provides both machine learning and graph processing libraries, allowing companies to tackle complex problems easily with the power of highly scalable and clustered
computers. Spark's promise is to take this a little further to make writing distributed programs using Scala feel like writing regular programs for Spark. Spark will be great in giving ETL pipelines huge boosts in performance and easing some of the pain that feeds the MapReduce programmer's daily chant of despair to the Hadoop gods.
In this book, we used Spark and Scala for the endeavor to bring state-of-the-art advanced data analytics with machine learning, graph processing, streaming, and SQL to Spark, with their contributions to MLlib, ML, SQL, GraphX, and other libraries.
We started with Scala and then moved to the Spark part, and finally, covered some advanced topics for big data analytics with Spark and Scala. In the appendix, we will see how to extend your Scala knowledge for SparkR, PySpark, Apache Zeppelin, and in-memory Alluxio. This book isn't meant to be read from cover to cover. Skip to a chapter that looks like something you're trying to accomplish or that simply ignites your interest.
What this book covers
Chapter 1, Introduction to Scala, will teach big data analytics using the Scala-based APIs of Spark.
Spark itself is written with Scala and naturally, as a starting point, we will discuss a brief
introduction to Scala, such as the basic aspects of its history, purposes, and how to install Scala on Windows, Linux, and Mac OS. After that, the Scala web framework will be discussed in brief. Then, we will provide a comparative analysis of Java and Scala. Finally, we will dive into Scala
programming to get started with Scala.
Chapter 2, Object-Oriented Scala, says that the object-oriented programming (OOP) paradigm provides
a whole new layer of abstraction. In short, this chapter discusses some of the greatest strengths of OOP languages: discoverability, modularity, and extensibility. In particular, we will see how to deal with variables in Scala; methods, classes, and objects in Scala; packages and package objects; traits and trait linearization; and Java interoperability.
Chapter 3, Functional Programming Concepts, showcases the functional programming concepts in
Scala. More specifically, we will learn several topics, such as why Scala is an arsenal for the data scientist, why it is important to learn the Spark paradigm, pure functions, and higher-order functions (HOFs). A real-life use case using HOFs will be shown too. Then, we will see how to handle
exceptions in higher-order functions outside of collections using the standard library of Scala. Finally, we will look at how functional Scala affects an object's mutability.
Chapter4, Collection APIs, introduces one of the features that attract most Scala users--the Collections
API. It's very powerful and flexible, and has lots of operations coupled. We will also demonstrate the capabilities of the Scala Collection API and how it can be used in order to accommodate different types of data and solve a wide range of different problems. In this chapter, we will cover Scala collection APIs, types and hierarchy, some performance characteristics, Java interoperability, and Scala implicits.
Chapter 5, Tackle Big Data - Spark Comes to the Party, outlines data analysis and big data; we see the
challenges that big data poses, how they are dealt with by distributed computing, and the approaches suggested by functional programming. We introduce Google's MapReduce, Apache Hadoop, and finally, Apache Spark, and see how they embraced this approach and these techniques. We will look into the evolution of Apache Spark: why Apache Spark was created in the first place and the value it can bring to the challenges of big data analytics and processing.
Chapter 6, Start Working with Spark - REPL and RDDs, covers how Spark works; then, we introduce
RDDs, the basic abstractions behind Apache Spark, and see that they are simply distributed
collections exposing Scala-like APIs. We will look at the deployment options for Apache Spark and run it locally as a Spark shell. We will learn the internals of Apache Spark, what RDDs are, DAGs and lineages of RDDs, Transformations, and Actions.
how these RDDs provide new functionalities (and dangers!) Moreover, we investigate other useful objects that Spark provides, such as broadcast variables and Accumulators. We will learn
aggregation techniques, shuffling.
Chapter 8, Introduce a Little Structure - SparkSQL, teaches how to use Spark for the analysis of
structured data as a higher-level abstraction of RDDs and how Spark SQL's APIs make querying structured data simple yet robust. Moreover, we introduce datasets and look at the differences between datasets, DataFrames, and RDDs. We will also learn to join operations and window functions to do complex data analysis using DataFrame APIs.
Chapter 9, Stream Me Up, Scotty - Spark Streaming, takes you through Spark Streaming and how we
can take advantage of it to process streams of data using the Spark API. Moreover, in this chapter, the reader will learn various ways of processing real-time streams of data using a practical example to consume and process tweets from Twitter. We will look at integration with Apache Kafka to do real-time processing. We will also look at structured streaming, which can provide real-real-time queries to your applications.
Chapter 10, Everything is Connected - GraphX, in this chapter, we learn how many real-world
problems can be modeled (and resolved) using graphs. We will look at graph theory using Facebook as an example, Apache Spark's graph processing library GraphX, VertexRDD and EdgeRDDs, graph operators, aggregateMessages, TriangleCounting, the Pregel API, and use cases such as the PageRank algorithm.
Chapter 11, Learning Machine Learning - Spark MLlib and ML, the purpose of this chapter is to
provide a conceptual introduction to statistical machine learning. We will focus on Spark's machine learning APIs, called Spark MLlib and ML. We will then discuss how to solve classification tasks using decision trees and random forest algorithms and regression problem using linear regression algorithm. We will also show how we could benefit from using one-hot encoding and dimensionality reductions algorithms in feature extraction before training a classification model. In later sections, we will show a step-by-step example of developing a collaborative filtering-based movie
recommendation system.
Chapter 12, Advanced Machine Learning Best Practices, provides theoretical and practical aspects of
some advanced topics of machine learning with Spark. We will see how to tune machine learning models for optimized performance using grid search, cross-validation, and hyperparameter tuning. In a later section, we will cover how to develop a scalable recommendation system using ALS, which is an example of a model-based recommendation algorithm. Finally, a topic modelling application will be demonstrated as a text clustering technique
Chapter 13, My Name is Bayes, Naive Bayes, states that machine learning in big data is a radical
powerful method to build a scalable classification model and concepts such as multinomial
classification, Bayesian inference, Naive Bayes, decision trees, and a comparative analysis of Naive Bayes versus decision trees.
Chapter 14, Time to Put Some Order - Cluster Your Data with Spark MLlib, gets you started on how
Spark works in cluster mode with its underlying architecture. In previous chapters, we saw how to develop practical applications using different Spark APIs. Finally, we will see how to deploy a full Spark application on a cluster, be it with a pre-existing Hadoop installation or without.
Chapter 15, Text Analytics Using Spark ML, outlines the wonderful field of text analytics using Spark
ML. Text analytics is a wide area in machine learning and is useful in many use cases, such as sentiment analysis, chat bots, email spam detection, natural language processing, and many many more. We will learn how to use Spark for text analysis with a focus on use cases of text classification using a 10,000 sample set of Twitter data. We will also look at LDA, a popular technique to generate topics from documents without knowing much about the actual text, and will implement text
classification on Twitter data to see how it all comes together.
Chapter 16, Spark Tuning, digs deeper into Apache Spark internals and says that while Spark is great in
making us feel as if we are using just another Scala collection, we shouldn't forget that Spark actually runs in a distributed system. Therefore, throughout this chapter, we will cover how to monitor Spark jobs, Spark configuration, common mistakes in Spark app development, and some optimization techniques.
Chapter 17, Time to Go to ClusterLand - Deploying Spark on a Cluster, explores how Spark works in
cluster mode with its underlying architecture. We will see Spark architecture in a cluster, the Spark ecosystem and cluster management, and how to deploy Spark on standalone, Mesos, Yarn, and AWS clusters. We will also see how to deploy your app on a cloud-based AWS cluster.
Chapter 18, Testing and Debugging Spark, explains how difficult it can be to test an application if it is
distributed; then, we see some ways to tackle this. We will cover how to do testing in a distributed environment, and testing and debugging Spark applications.
Chapter 19, PySpark & SparkR, covers the other two popular APIs for writing Spark code using R and
Python, that is, PySpark and SparkR. In particular, we will cover how to get started with PySpark and interacting with DataFrame APIs and UDFs with PySpark, and then we will do some data analytics using PySpark. The second part of this chapter covers how to get started with SparkR. We will also see how to do data processing and manipulation, and how to work with RDD and DataFrames using SparkR, and finally, some data visualization using SparkR.
Appendix A, Accelerating Spark with Alluxio, shows how to use Alluxio with Spark to increase the
Appendix B, Interactive Data Analytics with Apache Zeppelin, says that from a data science
What you need for this book
All the examples have been implemented using Python version 2.7 and 3.5 on an Ubuntu Linux 64 bit, including the TensorFlow library version 1.0.1. However, in the book, we showed the source code with only Python 2.7 compatible. Source codes that are Python 3.5+ compatible can be downloaded from the Packt repository. You will also need the following Python modules (preferably the latest versions):
R 3.1+ and RStudio 1.0.143 (or higher) Eclipse Mars, Oxygen, or Luna (latest) Maven Eclipse plugin (2.9 or higher)
Maven compiler plugin for Eclipse (2.3.2 or higher) Maven assembly plugin for Eclipse (2.4.1 or higher)
Operating system: Linux distributions are preferable (including Debian, Ubuntu, Fedora, RHEL, and CentOS) and to be more specific, for Ubuntu it is recommended to have a complete 14.04 (LTS) 64-bit (or later) installation, VMWare player 12, or Virtual box. You can run Spark jobs on Windows (XP/7/8/10) or Mac OS X (10.4.7+).
Hardware configuration: Processor Core i3, Core i5 (recommended), or Core i7 (to get the best results). However, multicore processing will provide faster data processing and scalability. You will need least 8-16 GB RAM (recommended) for a standalone mode and at least 32 GB RAM for a
Who this book is for
Anyone who wishes to learn how to perform data analysis by harnessing the power of Spark will find this book extremely useful. No knowledge of Spark or Scala is assumed, although prior programming experience (especially with other JVM languages) will be useful in order to pick up the concepts quicker. Scala has been observing a steady rise in adoption over the past few years, especially in the fields of data science and analytics. Going hand in hand with Scala is Apache Spark, which is
Conventions
In this book, you will find a number of text styles that distinguish between different kinds of
information. Here are some examples of these styles and an explanation of their meaning. Code words in text, database table names, folder names, filenames, file extensions, pathnames, dummy URLs, user input, and Twitter handles are shown as follows: "The next lines of code read the link and assign it to the to the BeautifulSoup function."
A block of code is set as follows:
package com.chapter11.SparkMachineLearning
import org.apache.spark.mllib.feature.StandardScalerModel import org.apache.spark.mllib.linalg.{ Vector, Vectors } import org.apache.spark.sql.{ DataFrame }
import org.apache.spark.sql.SparkSession
When we wish to draw your attention to a particular part of a code block, the relevant lines or items are set in bold:
Any command-line input or output is written as follows:
$./bin/spark-submit --class com.chapter11.RandomForestDemo \
New termsand important words are shown in bold. Words that you see on the screen, for example, in menus or dialog boxes, appear in the text like this: "Clicking the Next button moves you to the next screen."
Warnings or important notes appear like this.
Reader feedback
Customer support
Downloading the example code
You can download the example code files for this book from your account at http://www.packtpub.com. If
you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the
files e-mailed directly to you. You can download the code files by following these steps:
1. Log in or register to our website using your e-mail address and password. 2. Hover the mouse pointer on the SUPPORT tab at the top.
3. Click on Code Downloads & Errata.
4. Enter the name of the book in the Search box.
5. Select the book for which you're looking to download the code files. 6. Choose from the drop-down menu where you purchased this book from. 7. Click on Code Download.
Once the file is downloaded, please make sure that you unzip or extract the folder using the latest version of:
WinRAR / 7-Zip for Windows Zipeg / iZip / UnRarX for Mac 7-Zip / PeaZip for Linux
Downloading the color images of this book
Errata
Although we have taken every care to ensure the accuracy of our content, mistakes do happen. If you find a mistake in one of our books-maybe a mistake in the text or the code-we would be grateful if you could report this to us. By doing so, you can save other readers from frustration and help us improve subsequent versions of this book. If you find any errata, please report them by visiting http://www.packtpub .com/submit-errata, selecting your book, clicking on the Errata Submission Form link, and entering the
details of your errata. Once your errata are verified, your submission will be accepted and the errata will be uploaded to our website or added to any list of existing errata under the Errata section of that title. To view the previously submitted errata, go to https://www.packtpub.com/books/content/support and enter
Piracy
Questions
Introduction to Scala
"I'm Scala. I'm a scalable, functional and object-oriented programming language. I can grow with you and you can play with me by typing one-line expressions and observing the results instantly"
- Scala Quote
In last few years, Scala has observed steady rise and wide adoption by developers and practitioners, especially in the fields of data science and analytics. On the other hand, Apache Spark which is
;written in Scala is a fast and general engine for large-scale data processing. Spark's success is due to many factors: easy-to-use API, clean programming model, performance, and so on. Therefore,
naturally, Spark has more support for Scala: more APIs are available for Scala compared to Python or Java; although, new Scala APIs are available before those for Java, Python, and R.
Now that before we start writing your data analytics program using Spark and Scala (part II), we will first get familiar with Scala's functional programming concepts, object oriented features and the Scala collection APIs in detail (part I). As a starting point, we will provide a brief introduction to Scala in this chapter. We will cover some basic aspects of Scala including it's history and purposes. Then we will see how to install Scala on different platforms including Windows, Linux, and Mac OS so that your data analytics programs can be written on your favourite editors and IDEs. Later in this chapter, we will provide a comparative analysis between Java and Scala. Finally, we will dive into Scala programming with some examples.
In a nutshell, the following topics will be covered:
History and purposes of Scala
Scala is a general-purpose programming language that comes with support of functional programming and a strong static type system. The source code of Scala is intended to be compiled into Java bytecode, so that the resulting executable code can be run on Java virtual machine (JVM).
Martin Odersky started the design of Scala back in 2001 at the École Polytechnique Fédérale de Lausanne (EPFL). It was an extension of his work on Funnel, which is a programming language that uses functional programming and Petri nets. The first public release appears in 2004 but with only on the Java platform support. Later on, it was followed by .NET framework in June 2004.
Scala has become very popular and experienced wide adoptions because it not only supports the object-oriented programming paradigm, but it also embraces the functional programming concepts. In addition, although Scala's symbolic operators are hardly easy to read, compared to Java, most of the Scala codes are comparatively concise and easy to read -e.g. Java is too verbose.
Like any other programming languages, Scala was prosed and developed for specific purposes. Now, the question is, why was Scala created and what problems does it solve? To answer these questions, Odersky said in his blog: ;
"The work on Scala stems from a research effort to develop better language support for component software. There are two hypotheses that we would like to validate with the Scala
experiment. First, we postulate that a programming language for component software needs to be scalable in the sense that the same concepts can describe small as well as large parts. Therefore, we concentrate on mechanisms for abstraction, composition, and decomposition, rather than adding a large set of primitives, which might be useful for components at some level of scale but not at other levels. Second, we postulate that scalable support for components can be provided by a programming language which unifies and generalizes object-oriented and functional
programming. For statically typed languages, of which Scala is an instance, these two paradigms were up to now largely separate."
Nevertheless, pattern matching and higher order functions, and so on, are also provided in Scala, not to fill the gap between FP and OOP, but because ;they are typical features of functional programming. For this, it has some incredibly powerful pattern-matching features, which are an actor-based
Platforms and editors
Scala runs on Java Virtual Machine (JVM), which makes Scala a good choice for Java
programmers too who would like to have a functional programming flavor in their codes. There are lots of options when it comes to editors. It's better for you to spend some time making some sort of a comparative study between the available editors because being comfortable with an IDE is one of the key factors for a successful programming experience. Following are some options to choose from:
Scala IDE
Scala plugin for Eclipse IntelliJ IDEA
Emacs VIM
Scala support programming on Eclipse has several advantages using numerous beta plugins. Eclipse provides some exciting features such as local, remote, and high-level debugging facilities with semantic highlighting and code completion for Scala. You can use Eclipse for Java as well as Scala application development with equal ease. However, I would also suggest Scala IDE (http://scala-ide.org/
)--it's a full-fledged Scala editor based on Eclipse and customized with a set of interesting features (for example, Scala worksheets, ScalaTest support, Scala refactoring, and so on). ;
The second best option, in my view, is the IntelliJ IDEA. The first release came in 2001 as the first available Java IDEs with advanced code navigation and refactoring capabilities integrated.
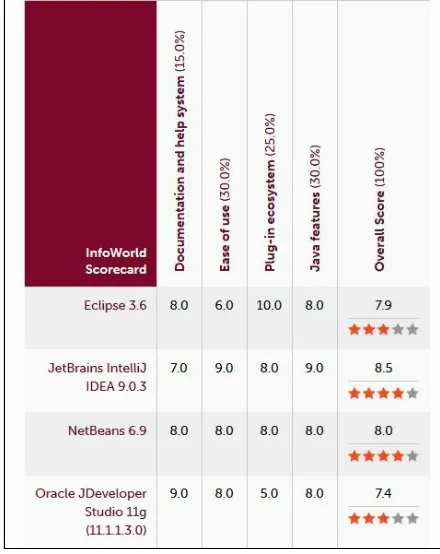
According to the InfoWorld report (see at http://www.infoworld.com/article/2683534/development-environments/infoworld -review--top-java-programming-tools.html), out of the four top Java programming IDE (that is, Eclipse, IntelliJ
IDEA, NetBeans, and JDeveloper), IntelliJ received the highest test center score of 8.5 out of 10.
Figure 1: Best IDEs for Scala/Java developers
From the preceding ;figure, you may be interested in using other IDEs such as NetBeans and
Installing and setting up Scala
As we have already mentioned, Scala uses JVM, therefore make sure you have Java installed ;on your machine. If not, refer to the next subsection, which shows how to install Java on Ubuntu. In this
Installing Java
For simplicity, we will show how to install Java 8 on an Ubuntu 14.04 LTS 64-bit machine. But for Windows and Mac OS, it would be better to invest some time on Google to know how. For a
minimum clue for the Windows users: refer to this link for details https://java.com/en/download/help/windows_ma nual_download.xml.
Now, let's see how to install Java 8 on Ubuntu with step-by-step commands and instructions. At first, check whether ;Java is already installed:
$ java -version
If it returns The program java cannot be found in the following packages, Java hasn't been installed yet. Then you would like to execute the following command to get rid of:
$ sudo apt-get install default-jre
This will install the Java Runtime Environment (JRE). However, if you may instead need the Java Development Kit (JDK), which is usually needed to compile Java applications on Apache Ant, Apache Maven, Eclipse, and IntelliJ IDEA.
The Oracle JDK is the official JDK, however, it is no longer provided by Oracle as a default installation for Ubuntu. You can still install it using apt-get. To install any version, first execute the following commands:
$ sudo apt-get install python-software-properties $ sudo apt-get update
$ sudo add-apt-repository ppa:webupd8team/java $ sudo apt-get update
Then, depending on the version you want to install, execute one of the following commands:
$ sudo apt-get install oracle-java8-installer
After installing, don't forget to set the Java home environmental variable. Just apply the following ;commands (for the simplicity, we assume that Java is installed at /usr/lib/jvm/java-8-oracle):
$ echo "export JAVA_HOME=/usr/lib/jvm/java-8-oracle" >> ~/.bashrc $ echo "export PATH=$PATH:$JAVA_HOME/bin" >> ~/.bashrc
$ source ~/.bashrc
Now, let's see the Java_HOME as follows:
$ echo $JAVA_HOME
You should observe the following result on Terminal:
Now, let's check to make sure that Java has been installed successfully by issuing the following command (you might see the latest version!):
$ java -version
You will get the following output:
java version "1.8.0_121"
Java(TM) SE Runtime Environment (build 1.8.0_121-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.121-b13, mixed mode)
Windows
This part will focus on installing Scala on the PC with Windows 7, but in the end, it won't matter which version of Windows you to run at the moment:
1. The first step is to download a zipped file of Scala from the official site. You will find it at https:// www.Scala-lang.org/download/all.html. Under the other resources section of this page, you will find a list
of the archive files from which you can install Scala. We will choose to download the zipped file for Scala 2.11.8, as shown in the following figure:
Figure 2: Scala installer for Windows
2. After the downloading has finished, unzip the file and place it in your favorite folder. You can also rename the file Scala for navigation flexibility. Finally, a PATH variable needs to be created for Scala to be globally seen on your OS. For this, navigate to Computer | Properties, as shown in the following figure:
Figure 3: Environmental variable tab on windows
append it to the PATH environment variable. Apply the changes and then press OK, ;as shown in the following screenshot:
Figure 4: Adding environmental variables for Scala
4. Now, you are ready to go for the Windows installation. Open the CMD and just type scala. If you were successful in the installation process, then you should see an output similar to the following screenshot:
Mac OS
Using Homebrew installer
1. At first, check your system to see whether it has Xcode installed or not because it's required in this step. You can install it from the Apple App Store free of charge.
2. Next, you need to install Homebrew from the terminal by running the following command in your terminal:
$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
Note: The preceding ;command is changed by the Homebrew guys from time to time. If the command doesn't seem to be working, check the Homebrew website for the latest incantation: http://brew.sh/.
3. Now, you are ready to go and install Scala by typing this command brew install scala ;in the terminal.
4. Finally, you are ready to go by simply typing Scala in your terminal (the second line) and you will observe the following on your terminal: ;
Installing manually
Before installing Scala manually, choose your preferred version of Scala and download the corresponding .tgz file of that version Scala-verion.tgz from http://www.Scala-lang.org/download/. After downloading your preferred version of Scala, extract it as follows:
$ tar xvf scala-2.11.8.tgz
Then, move it to /usr/local/share as follows:
$ sudo mv scala-2.11.8 /usr/local/share
Now, to make the installation permanent, execute the following commands:
$ echo "export SCALA_HOME=/usr/local/share/scala-2.11.8" >> ~/.bash_profile $ echo "export PATH=$PATH: $SCALA_HOME/bin" >> ~/.bash_profile
Linux
In this subsection, we will show you the installation procedure of Scala on the Ubuntu distribution of Linux. Before starting, let's check to make sure Scala is installed properly. Checking this is
straightforward using the following command:
$ scala -version
If Scala is already installed on your system, you should get the following message on your terminal:
Scala code runner version 2.11.8 -- Copyright 2002-2016, LAMP/EPFL
Note that, during the writing of this installation, we used the latest version of Scala, that is, 2.11.8. If you do not have Scala installed on your system, make sure you install it before proceeding to the next step. ; You can download the latest version of Scala from the Scala website at http://www.scala-lang.org/dow nload/ (for a clearer view, refer to Figure 2). For ease, let's download Scala 2.11.8, as follows: ;
$ cd Downloads/
$ wget https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz
After the download has been finished, you should find the Scala tar file in the download folder.
The user should first go into the Download directory with the following command: $ cd /Downloads/. Note that the name of the downloads folder may change depending on the
system's selected language.
To extract the Scala tar file from its location or more, type the following command. Using this, the Scala tar file can be extracted from the Terminal:
$ tar -xvzf scala-2.11.8.tgz
Now, move the Scala distribution to the user's perspective (for example, /usr/local/scala/share) by typing the following command or doing it manually:
$ sudo mv scala-2.11.8 /usr/local/share/
Move to your home directory issue using the following command:
$ cd ~
Then, set the Scala home using the following commands:
$ echo "export SCALA_HOME=/usr/local/share/scala-2.11.8" >> ~/.bashrc $ echo "export PATH=$PATH:$SCALA_HOME/bin" >> ~/.bashrc
Then, make the change permanent for the session by using the following command:
After the installation has been completed, you should better to verify it using the following command:
$ scala -version
If Scala has successfully been configured on your system, you should get the following message on your terminal:
Scala code runner version 2.11.8 -- Copyright 2002-2016, LAMP/EPFL
Well done! Now, let's enter into the Scala shell by typing the ;scala command on the terminal, as shown in the following figure:
Figure 7: Scala shell on Linux (Ubuntu distribution)
Finally, you can also install Scala using the apt-get command, as follows:
$ sudo apt-get install scala
This command will download the latest version of Scala (that is, 2.12.x). However, Spark does not have support for Scala 2.12 yet (at least when we wrote this chapter). Therefore, we would
Scala: the scalable language
Scala is object-oriented
Scala is functional
Functional programming treats functions like first-class citizens. In Scala, this is achieved with
syntactic sugar and objects that extend traits (like Function2), but this is how functional programming is achieved in Scala. Also, Scala defines a simple and easy way to define anonymous functions
(functions without names). It also supports higher-order functions and it allows nested functions. The syntax of these concepts will be explained in deeper details in the coming chapters.
Scala is statically typed
Unlike the other statically typed languages like Pascal, Rust, and so on, Scala does not expect you to provide redundant type information. You don't have to specify the type in most cases. Most
importantly, you don't even need to repeat them again.
A programming language is called statically typed if the type of a variable is known at compile time: this also means that, as a programmer, you must specify what the type of each variable is. For example, Scala, Java, C, OCaml, Haskell, and C++, and so on. On the other hand, Perl, Ruby, Python, and so on are dynamically typed
languages, where the type is not associated with the variables or fields, but with the runtime values.
Scala runs on the JVM
Just like Java, Scala is also compiled into bytecode which can easily be executed by the JVM. This means that the runtime platforms of Scala and Java are the same because both generate bytecodes as the compilation output. So, you can easily switch from Java to Scala, you can ;and also easily
integrate both, or even use Scala in your Android application to add a functional flavor. ;
Note that, while using Java code in a Scala program is quite easy, the opposite is very difficult, mostly because of Scala's syntactic sugar.
Scala can execute Java code
Scala can do concurrent and ;synchronized
processing
Scala for Java programmers
All types are objects
Type inference
If you are not familiar with the term, it is nothing but the deduction of types at compile time. Hold on, isn't that what dynamic typing means? Well, no. Notice that I said deduction of types; this is
Scala REPL
The Scala REPL is a powerful feature that makes it more straightforward and concise to write Scala code on ;the Scala shell. REPL stands for Read-Eval-Print-Loop also called the Interactive Interpreter. This means it is a program for:
1. ;Reading the expressions you type in.
2. Evaluating the expression in step 1 using the Scala compiler. 3. Printing out the result of the evaluation in step 2.
4. Waiting (looping) for you to enter further expressions.
Figure 8: Scala REPL example 1
From the figure, it is evident that there is no magic, the variables are inferred automatically to the best types they deem fit at compile time. If you look even more carefully, when I tried to declare: ;
i:Int = "hello"
Then, the Scala shell throws an error saying the following:
<console>:11: error: type mismatch; found : String("hello")
required: Int
val i:Int = "hello" ^
According to Odersky, "Mapping a character to the character map over a RichString should again yield a RichString, as in the following interaction with the Scala REP". The preceding statement can be proved using the following line of code:
scala> "abc" map (x => (x + 1).toChar) res0: String = bcd
"abc" map (x => (x + 1))
res1: scala.collection.immutable.IndexedSeq[Int] = Vector(98, 99, 100)
Both static and instance methods of objects are also available. For example, if you declare x as a string hello and then try to access both the static and instance methods of objects x, they are available. In the Scala shell, type x then . and <tab> and then you will find the available methods:
scala> val x = "hello" x: java.lang.String = hello scala> x.re<tab>
reduce reduceRight replaceAll reverse
reduceLeft reduceRightOption replaceAllLiterally reverseIterator reduceLeftOption regionMatches replaceFirst reverseMap reduceOption replace repr
scala>
Since this is all accomplished on the fly via reflection, even anonymous classes you've only just defined are equally accessible:
scala> val x = new AnyRef{def helloWord = "Hello, world!"} x: AnyRef{def helloWord: String} = $anon$1@58065f0c
scala> x.helloWord def helloWord: String scala> x.helloWord
warning: there was one feature warning; re-run with -feature for details res0: String = Hello, world!
The preceding two examples can be shown on the Scala shell, as follows:
Figure 9: Scala REPL example 2
"So it turns out that map yields different types depending on what the result type of the passed function argument is!"
Nested functions
Why will you require a nested functions support in your programming language? Most of the time, we want to maintain our methods to be a few lines and avoid overly large functions. A typical solution for this in Java would be to define all these small functions on a class level, but any other method could easily refer and access them even though they are helper methods. The situation is different in Scala, so you can use define functions inside each other, and this way, prevent any external access to these functions:
def sum(vector: List[Int]): Int = {
// Nested helper method (won't be accessed from outside this function def helper(acc: Int, remaining: List[Int]): Int = remaining match { case Nil => acc
case _ => helper(acc + remaining.head, remaining.tail) }
// Call the nested method helper(0, vector)
}
Import statements
In Java, you can only import packages at the top of your code file, right after the packages statement. The situation is not the same in Scala; you can write your import statements almost anywhere inside your source file (for example, you can even write your import statements inside a class or a method). You just need to pay attention to the scope of your import statement, because it inherits the same scope of the members of your class or local variables inside your method. The _ (underscore) in Scala is used for wildcard imports, which is similar to the * (asterisk) that you would use in java:
// Import everything from the package math import math._
You may also use these { } to indicate a set of imports from the same parent package, just in one line of code. In Java, you would use multiple lines of code to do so:
// Import math.sin and math.cos import math.{sin, cos}
Unlike the Java, Scala does not have the concept of static imports. In other words, the concept of static doesn't exist in Scala. However, as a developer, obviously, you can import a member or more than one member of an object using a regular import statement. The preceding example already shows this, where we import the methods sin and cos from the package object named math. To demonstrate an example, the preceding ;code snippet can be defined from the Java programmer's perspective as follows:
import static java.lang.Math.sin; import static java.lang.Math.cos;
Another beauty of Scala is that, in Scala, you can rename your imported packages as well.
Alternatively, you can rename your imported packages to avoid the type conflicting with packages that have similar members. The following statement is valid in Scala:
// Import Scala.collection.mutable.Map as MutableMap import Scala.collection.mutable.{Map => MutableMap}
Finally, you may want to exclude a member of packages for collisions or other purposes. For this, you can use a wildcard to do so:
Operators as methods
It's worth mentioning that Scala doesn't support the operator overloading. You might think that there are no operators at all in Scala.
An alternative syntax for calling a method taking a single parameter is the use of the infix syntax. The infix syntax provides you with a flavor just like you are applying an operator overloading, as like what you did in C++. For example:
val x = 45 val y = 75
In the following case, the + ;means a method in class Int. ; The following ;code is a non-conventional method calling syntax:
val add1 = x.+(y)
More formally, the same can be done using the infix syntax, as follows:
val add2 = x + y
Moreover, you can utilize the infix syntax. However, the method has only a single parameter, as follows:
val my_result = List(3, 6, 15, 34, 76) contains 5
There's one special case when using the infix syntax. That is, if the method name ends with a :
(colon), then the invocation or call will be right associative. This means that the method is called on the right argument with the expression on the left as the argument, instead of the other way around. For example, the following is valid in Scala:
val my_list = List(3, 6, 15, 34, 76)
The preceding ;statement signifies that: my_list.+:(5) rather than 5.+:(my_list) and more formally: ;
val my_result = 5 +: my_list
Now, let's look at the preceding examples on Scala REPL:
scala> val my_list = 5 +: List(3, 6, 15, 34, 76)
Methods and parameter lists
In Scala, a method can have multiple parameter lists or even no parameter list at all. On the other hand, in Java, a method always has one parameter list, with zero or more parameters. For example, in Scala, the following is the valid method definition (written in currie notation) where a method has two parameter lists:
def sum(x: Int)(y: Int) = x + y
The preceding ;method cannot be written as:
def sum(x: Int, y: Int) = x + y
A method, let's say ;sum2, can have no parameter list at all, as follows:
def sum2 = sum(2) _
Now, you can call the method add2, which returns a function taking one parameter. Then, it calls that function with the argument 5, as follows:
Methods inside methods
Sometimes, you would like to make your applications, code modular by avoiding too long and complex methods. Scala provides you this facility to avoid your methods becoming overly large so that you can split them up into several smaller methods.
On the other hand, Java allows you only to have the methods defined at class level. For example, suppose you have the following method definition:
def main_method(xs: List[Int]): Int = {
// This is the nested helper/auxiliary method
def auxiliary_method(accu: Int, rest: List[Int]): Int = rest match { case Nil => accu
case _ => auxiliary_method(accu + rest.head, rest.tail) }
}
Now, you can call the nested helper/auxiliary method as follows:
auxiliary_method(0, xs)
Considering the above, here's the complete code segment which is valid:
def main_method(xs: List[Int]): Int = {
// This is the nested helper/auxiliary method
def auxiliary_method(accu: Int, rest: List[Int]): Int = rest match { case Nil => accu
case _ => auxiliary_method(accu + rest.head, rest.tail) }
Constructor in Scala
One surprising thing about Scala is that the body of a Scala class is itself a constructor. ; However, Scala does so; in fact, in a more explicit way. After that, a new instance of that class is created and executed. Moreover, you can specify the arguments of the constructor in the class declaration line.
Consequently, the constructor arguments are accessible from all of the methods defined in that class. For example, the following class and constructor definition is valid in Scala:
class Hello(name: String) {
// Statement executed as part of the constructor println("New instance with name: " + name)
// Method which accesses the constructor argument def sayHello = println("Hello, " + name + "!") }
The equivalent Java class would look like this:
public class Hello {
private final String name; public Hello(String name) {
System.out.println("New instance with name: " + name); this.name = name;
}
public void sayHello() {
System.out.println("Hello, " + name + "!"); }
Objects instead of static methods
As mentioned earlier, static does not exist in Scala. You cannot do static imports and neither can you cannot add static methods to classes. In Scala, when you define an object with the same name as the class and in the same source file, then the object is said to be the companion of that class. Functions that you define in this companion object of a class are like static methods of a class in Java:
class HelloCity(CityName: String) {
def sayHelloToCity = println("Hello, " + CityName + "!") }
This is how you can define a companion object for the class hello:
object HelloCity { // Factory method
def apply(CityName: String) = new Hello(CityName) }
The equivalent class in Java would look like this:
public class HelloCity {
private final String CityName; public HelloCity(String CityName) { this.CityName = CityName;
}
public void sayHello() {
System.out.println("Hello, " + CityName + "!"); }
public static HelloCity apply(String CityName) { return new Hello(CityName);
} }
So, lot's of verbose in this simple class, isn't there? ; The apply method in Scala is treated in a different way, such that you can find a special shortcut syntax to call it. This is the familiar way of calling the method:
val hello1 = Hello.apply("Dublin")
Here's the shortcut syntax that is equivalent to the one earlier:
val hello2 = Hello("Dublin")
Traits
Scala provides a great functionality for you in order to extend and enrich your classes' behaviors. These traits are similar to the interface in which you define the function prototypes or signatures. So, with this, you can have mix-ins of functionality coming from different traits and, in this way, you enriched your classes' behavior. So, what's so good about traits in Scala? They enable the
composition of classes from these traits, with traits being the building blocks. As always, let's look at in an example. This is how a conventional logging routine is set up in Java:
Note that, even though you can mix in any number of traits you want. Moreover, like Java, Scala does not have the support of multiple inheritances. However, in both Java and Scala, a subclass can only extend a single superclass. For example, in Java:
class SomeClass {
//First, to have to log for a class, you must initialize it
final static Logger log = LoggerFactory.getLogger(this.getClass()); ...
//For logging to be efficient, you must always check, if logging level for current message is enabled //BAD, you will waste execution time if the log level is an error, fatal, etc.
log.debug("Some debug message"); ...
//GOOD, it saves execution time for something more useful if (log.isDebugEnabled()) { log.debug("Some debug message"); }
//BUT looks clunky, and it's tiresome to write this construct every time you want to log something. }
For a more detailed discussion, refer to this URL https://stackoverflow.com/questions/963492/in-log4j-does-checking-isd ebugenabled-before-logging-improve-performance/963681#963681.
However, it's different with traits. It's very tiresome to always check for the log level being enabled. It would be good, if you could write this routine once and reuse it anywhere, in any class right away. Traits in Scala make this all possible. For example:
trait Logging {
lazy val log = LoggerFactory.getLogger(this.getClass.getName) //Let's start with info level...
...
//Debug level here... def debug() {
if (log.isDebugEnabled) log.info(s"${msg}") }
def debug(msg: => Any, throwable: => Throwable) {
if (log.isDebugEnabled) log.info(s"${msg}", throwable) }
...
//Repeat it for all log levels you want to use }
If you look at the preceding code, you will see an example of using string starting with s. ; This way, Scala offers the mechanism to create strings from your data called String Interpolation. ;
String Interpolation, allows you to embed variable references directly in processed string literals. For example:
; ;scala> println(s"Hello, $name") ; // Hello, John Breslin.
Now, we can get an efficient logging routine in a more conventional style as a reusable block. To enable logging for any class, we just mix in our Logging trait! Fantastic! Now that's all it takes to add a logging feature to your class:
class SomeClass extends Logging { ...
//With logging trait, no need for declaring a logger manually for every class //And now, your logging routine is either efficient and doesn't litter the code! log.debug("Some debug message")
... }
It is even possible to mix-up multiple traits. For example, for the preceding ;trait (that is, Logging) you can keep extending in the following ;order:
trait Logging {
override def toString = "Logging " }
class A extends Logging {
override def toString = "A->" + super.toString }
trait B extends Logging {
override def toString = "B->" + super.toString }
trait C extends Logging {
override def toString = "C->" + super.toString }
class D extends A with B with C {
override def toString = "D->" + super.toString }
However, it is noted that a Scala class can extend multiple traits at once, but JVM classes can extend only one parent class.
Now, to invoke the above traits and classes, use new D() from Scala REPL, as shown in the following ;figure:
Figure 10: Mixing multiple traits
Scala for the beginners
In this part, you will find that we assume that you have a basic understanding of any previous
programming language. If Scala is your first entry into the coding world, then you will find a large set of materials and even courses online that explain Scala for beginners. As mentioned, there are lots of tutorials, videos, and courses out there.
There is a whole Specialization, which contains this course, on Coursera: https://www.co ursera.org/specializations/scala. Taught by the creator of Scala, Martin Odersky, this online class takes a somewhat academic approach to teaching the fundamentals of
functional programming. You will learn a lot about Scala by solving the
programming assignments. Moreover, this specialization includes a course on
Your first line of code
As a first example, we will use the pretty common Hello, world! program in order to show you how to use Scala and its tools without knowing much about it. Let's open your favorite editor (this example runs on Windows 7, but can be run similarly on Ubuntu or macOS), say Notepad++, and type the following lines of code:
object HelloWorld {
def main(args: Array[String]){ println("Hello, world!") }
}
Now, save the code with a name, say HelloWorld.scala, as shown in the following figure: ;
Figure 11: Saving your first Scala source code using Notepad++
Let's compile the source file as follows:
C:\>scalac HelloWorld.scala C:\>scala HelloWorld Hello, world!
I'm ; the hello world program, explain me well!
The program should be familiar to anyone who has some programming of experience. It has a main method which prints the string Hello, world! to your console. Next, to see how we defined the main function, we used the def main() strange syntax to define it. def is a Scala keyword to declare/define a method, and we will be covering more about methods and different ways of writing them in the next chapter. So, we have an Array[String] as an argument for this method, which is an array of strings that can be used for initial configurations of your program, and omit is valid. ;Then, we use the common println() method, which takes a string (or formatted one) and prints it to the console. A simple hello world has opened up many topics to learn; three in particular:
● ; ; ;Methods (covered in a later chapter)
● ; ; ;Objects and classes (covered in a later chapter)
Run Scala interactively!
The scala command starts the interactive shell for you, where you can interpret Scala expressions interactively:
> scala
Welcome to Scala 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_121). Type in expressions for evaluation. Or try :help.
scala>
scala> object HelloWorld {
| def main(args: Array[String]){ | println("Hello, world!") | }
| }
defined object HelloWorld scala> HelloWorld.main(Array()) Hello, world!
scala>
The shortcut :q stands for the internal shell command :quit, ;used to exit the
Compile it!
The scalac command, which is similar to javac command, compiles one or more Scala source files and generates a bytecode as output, which then can be executed on any Java Virtual Machine. To compile your hello world object, use the following:
> scalac HelloWorld.scala
By default, scalac generates the class files into the current working directory. You may specify a different output directory using the -d option:
> scalac -d classes HelloWorld.scala