i
PENGENALAN JENIS BUAH DENGAN MENGGUNAKAN METODE
BAYESIAN
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh:
Maria Fransiska Indah Aryanti Puspitarini
055314047
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
THE INTRODUCTION OF FRUITS USING
BAYESIAN METHODS
A THESIS
Presented as Partial Fulfillment of the Requirements
To Obtain the Computers Degree
In Department of Informatics Engineering
By:
Maria Fransiska Indah Aryanti Puspitarini
055314047
INFORMATICS ENGINEERING STUDY PROGRAM
INFORMATICS ENGINEERING DEPARTMENT
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
v
HALAMAN MOTTO
Tuhan membimbing kita dengan cara-Nya yang khas.
Tidak ada yang ‘kebetulan’ dalam hidup ini. Tuhan
mempunyai rencana dalam setiap peristiwa hidup kita.
vi
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa skripsi yang saya tulis ini tidak memuat karya
orang lain, kecuali yang telah disebutkan dalam kutipan dan daftar pustaka, sebagaimana
layaknya karya ilmiah.
Yogyakarta, Juli 2012
Penulis
vii
LEMBAR PERNYATAAN PERSETUJUAN
PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma : Nama : Maria Fransiska Indah Aryanti Puspitarini
NIM : 055314047
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Universitas Sanata Dharma karya ilmiah saya yang berjudul :
PENGENALAN JENIS BUAH DENGAN MENGGUNAKAN METODE BAYESIAN
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada Perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikan secara terbatas, dan mempublikasikannya di Internet maupun di media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun memberikan royalty kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini saya buat sebenarnya. Dibuat di Yogyakarta
Pada tanggal : Juli 2012 Yang menyatakan
viii ABSTRAK
Perkembangan teknologi saat ini mengalami kemajuan yang sangat pesat, segala
sesuatunya dilakukan serba otomatis. Salah satu contoh otomatisasi adalah mengenali suatu
obyek atau benda (pengenalan pola) dengan komputer. Contoh penggunaan otomatisasi untuk
mengenali suatu obyek adalah mengenali jenis buah – buahan.
Pada tugas akhir ini dibuat aplikasi untuk pengenalan jenis buah – buahan dengan
menggunakan metode Bayesian. Teori keputusan Bayesian adalah pendekatan statistik yang
fundamental dalam pengenalan pola (pattern recognition). Pendekatan ini di dasarkan pada kuantifikasi trade-off antara berbagai keputusan klasifikasi dengan menggunakan probabilitas dan ongkos yang ditimbulkan dalam keputusan – keputusan tersebut. Features analisis menggunakan perbandingan jarak horizontal : vertikal, perbandingan rata – rata Hue, nilai
rata – rata RGB ((R + G + B) / 3), rata – rata nilai R, rata – rata nilai G, rata – rata nilai B,
nilai (2R - (G + B)), nilai (2G – (R + B)), nilai (2B – (G + R)). Buah yang digunakan untuk
ix ABSTRACT
Technological developments are currently experiencing very rapid progress, everything done
completely automatic. One example of automation is to recognize an object or objects
(pattern recognition) with a computer. Examples of the use of automation to recognize an
object is to identify the type of fruits. At this final, application was made for recognize of
types of fruits by using Bayesian methods. Bayesian decision theory is a fundamental
statistical approach to pattern recognition (pattern recognition). This approach is based on the
quantification of trade-offs between the various classification decisions using probability and
costsincurred in the decisions. Features comparative analysis using horizontal distance:
vertical, comparison of average Hue, the mean of RGB((R +G+B) /3), average of value R,
average of value G, average of value B, value of (2R -(G +B)), value of (2G -(R +B)), value
x
KATA PENGANTAR
Puji syukur kepada Tuhan Yang Maha Esa karena atas segala berkat dan rahmat-Nya
yang melimpah, penulis dapat menyelesaikan skripsi dengan judul “Pengenalan Jenis Buah
dengan Menggunakan metode Bayesian” .
Penulisan skripsi ini bertujuan untuk memenuhi salah satu syarat memperoleh gelar
Sarjana Komputer Program Studi Teknik Informatika Universitas Sanata Dharma
Yogyakarta.
Penulis menyadari, bahwa selama proses penulisan skripsi ini penulis tidak lepas dari
bantuan dan dukungan banyak pihak baik berupa masukan dan saran. Oleh karena itu, pada
kesempatan ini penulis menyampaikan penghargaan dan ucapan terima kasih yang
sebesar-besarnya kepada :
1. Bunda Maria dan Tuhan Yesus Kristus atas segala mukzijat-Nya yang ajaib, penyertaan,
dan kasih karunia-Nya.
2. Ibu P.H. Prima Rosa, S.Si., M.Sc. selaku Dekan Fakultas Sains dan Teknologi
Universitas Sanata Dharma Yogyakarta.
3. Ibu Ridowati Gunawan, S.Kom., S.T. selaku Ketua Jurusan Teknik Informatika Fakultas
Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
4. Dr. C. Kuntoro Adi, S.J., M.A., M.Sc. selaku dosen pembimbing atas kesabaran,
bimbingan, waktu dan saran yang telah diberikan kepada penulis.
5. J.B. Budi Darmawan, S.T., M.Sc. selaku dosen pembimbing akademik Teknik
Informatika angkatan 2005 yang selalu sabar menghadapi penulis.
6. Eko Hari Parmadi, S.Si, M.Kom dan Drs. Johanes Eka Priyatma, M.Sc., Ph.D. sebagai
dosen penguji atas saran yang diberikan.
xi
8. Staf dan karyawan Fakultas Sains dan Teknologi Universitas Sanata Dharma
Yogyakarta.
9. Keluarga penulis, bapak Herman Joseph Supardal, ibu Fransisca Xaveria Sismaryanti,
dan emba’ Bernadet Noven Kurniastuti yang telah memberikan dukungan spiritual dan
material, kasih sayang, terima kasih untuk segala doanya untuk penulis.
10. Fransiskus Feritika Wibowo terima kasih untuk segala doa, dukungan dan kesabarannya.
11. Lucia Yuni Astuti terima kasih untuk persahabatan,segala doa dan dukungannya.
12. Soni, Nitnot, Orpa, Opiex, Bengz, Arimbi, Putri, Ganang, Simbah, Endah, Ar, Deri, Lita
dan semua teman-teman para pejuang akhir, terimakasih untuk dukungan, bantuan , dan
doa teman-teman semua.
13. Semua pihak yang telah membantu dalam penyusunan skripsi ini, yang tidak dapat
penulis sebutkan satu-persatu.
Dalam penulisan skripsi ini, dirasa masih banyak kekurangannya. Oleh karena itu
segala saran ataupun kritik yang bersifat membangun dari pembaca sekalian sangat
diharapkan guna menyempurnakan isi dari skripsi ini.
Akhir kata, semoga penulisan skripsi ini berguna bagi para pembaca sekalian
khususnya para mahasiswa Teknik Informatika, dan dapat menambah wawasan para pembaca
sekalian.
Yogyakarta, Juli 2012
xii
DAFTAR ISI
HALAMAN JUDUL ... i
HALAMAN JUDUL ... ii
HALAMAN PERSETUJUAN... iii
HALAMAN PENGESAHAN ... iv
HALAMAN MOTTO ... v
HALAMAN PERNYATAAN KEASLIAN KARYA ... vi
HALAMAN PERSETUJUAN PUBLIKASI ... vii
ABSTRAK ... viii
ABSTRACT ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
Bab I. PENDAHULUAN ... 1
I.1. Latar Belakang ... 1
I.2. Rumusan Masalah ... 3
I.3. Tujuan ... 3
I.4. Batasan Masalah ... 3
I.5. Manfaat Penelitian ... 4
I.6. Metodologi Penelitian ... 4
I.7. Sistematika Penulisan ... 5
Bab II. LANDASAN TEORI ... 7
II.1. Pengolahan Citra ... 7
xiii
II.2.1 Pengertian Pola dan Ciri. ... 9
II.2.2 Pengenalan Pola. ... 10
II.2.3 Teknik Pengenalan Pola. ... 12
II.3. Metode Bayesian ... 16
II.3.1 Contoh Perhitungan. ... 18
Bab III. METODOLOGI DAN PERANCANGAN SISTEM ... 21
III.1 Analisis Sistem... 21
III.2 Skema ... 23
III.2.1 Feature Analisis ... 23
III.2.2 Pengenalan dengan menggunakan Bayesian ... 24
III.2.2.1 Five folds ... 25
III.2.2.2 Tahap training ... 28
III.2.2.3 Tahap testing ... 30
III.2.3 Evaluasi ... 31
III.3 Studi Awal ... 32
III.4 Perancangan Desain Tampilan Program ... 33
III.4.1 Perancangan Form Halaman Utama ... 33
III.4.2 Perancangan Form Buka Gambar ... 34
III.4.3 Perancangan FormPengenalan Gambar ... 35
III.4.4 Perancangan Form Bantuan ... 36
III.4.5 Perancangan Form Tentang Program... 37
Bab IV. IMPLEMENTASI DAN ANALISIS SISTEM ... 38
xiv
IV.1.1 Kebutuhan Perangkat Keras ... 38
IV.1.2 Kebutuhan Perangkat Lunak... 39
IV.2 Implementasi sistem... 39
IV.2.1 Proses Training ... 39
IV.2.1.1 Ekstrak Feature ... 39
IV.2.1.2 Penghitungan Nilai Mean dan Standar Deviasi ... 44
IV.2.2 Proses Testing ... 46
IV.2.2.1 Penghitungan Nilai Probability Density Function ... 46
IV.2.2.2 Penghitungan Nilai Likelihood dan Probabilitas ... 47
IV.3 Analisis Hasil Pengujian ... 48
Bab V. PENUTUP ... 52
V.1 Kesimpulan ... 52
V.2 Saran ... 52
xv
DAFTAR GAMBAR
Gambar 2.1 Fungsi Kerapatan ... 15
Gambar 3.2 Garis Besar Proses Pengenalan Pola ... 21
Gambar 3.2 Skema Pengenalan pola Buah ... 23
Gambar 3.3 Skema Alur Pikir Tahap Training ... 26
Gambar 3.4 Skema Alur Pikir Tahap Testing ... 27
Gambar 3.5 Perancangan Form Halaman Utama ... 30
Gambar 3.6 Perancangan Form Buka Gambar ... 32
Gambar 3.7 Perancangan Form Pengenalan Gambar ... 33
Gambar 3.8 Perancangan Form Bantuan ... 34
Gambar 3.9 Perancangan Form Tentang Program ... 35
xvi
DAFTAR TABEL
Tabel 2.1 Contoh Perhitungan ... 18
Tabel 3.1 Karakteristik Buah ... 20
Tabel 3.2 Tabel Pembagian Sampel... 24
Tabel 3.3 Tabel Percobaan ... 25
Tabel 3.4 Confusion Matrix ... 29
1
BAB I
PENDAHULUAN
I.1. Latar Belakang & Deskripsi Topik
Perkembangan teknologi saat ini mengalami kemajuan yang sangat pesat, segala
sesuatunya dilakukan serba otomatis. Hal ini tidak lepas dari peranan komputer yang
dapat melakukan otomatisasi dengan penggunaan program – program yang terdapat di
dalamnya. Salah satu contoh otomatisasi adalah mengenali suatu obyek atau benda
(pengenalan pola) dengan komputer.
Contoh penggunaan otomatisasi untuk mengenali suatu obyek antara lain
pengenalan sidik jari, pengenalan suara, pengenalan angka serta proses pemisahan ikan
salmon dan ikan seabase dalam produksi ikan kaleng. Dalam penelitian ini akan dibahas
tentang pengenalan pola untuk membedakan jenis buah - buahan.
Terdapat banyak sekali jenis buah yang ada, tetapi dalam penelitian ini hanya akan
mengambil contoh buah apel, jeruk, mangga, pisang dan stroberi yang akan dibedakan
jenisnya. Masing – masing buah mempunyai varietas yang berbeda – beda. Sebagai
contoh buah jeruk, jeruk mempunyai lebih dari 160 varietas, beberapa diantaranya
adalah jeruk keprok, jeruk siem, jeruk Bali Merah dan jeruk siam madu. Buah – buahan
tersebut hanya akan dibedakan menurut jenisnya tanpa memperhatikan varietasnya.
Topik ini dipilih karena setiap jenis buah memilki karakteristik yang unik. Salah satu
contoh karakteristik unik dari buah dapat dilihat dari bentuknya. Disatu sisi buah-
buahan mempunyai bentuk yang sangat berbeda, misalnya buah apel dan salak. Tetapi
ada pula buah yang mempunyai bentuk yang sama atau mirip, misalnya apel dan jeruk.
Bagi penulis hal ini menarik untuk diteliti, terutama dalam pemilihan ciri – ciri
2
dilakukan dengan tepat maka nantinya penelitian ini dapat digunakan atau
diimplementasikan dalam dalam berbagai bidang, misalnya untuk pengelompokan buah
dalam proses pengalengan buah. Secara manual, meskipun buah apel dan jeruk
mempunyai bentuk yang mirip yaitu berbentuk bulat tetapi tetap bisa dibedakan. Jadi
tidak tertutup kemungkinan komputer juga bisa membedakannya. Walaupun secara
manual mata manusia dapat membedakan jenis buah – buahan dengan baik, tetapi
hanya dapat menangani data dengan jumlah yang terbatas. Untuk menangani data yang
jumlahnya sangat banyak tentu tidak akan efektif, karena mata akan mengalami
kelelahan yang dapat mengakibatkan kesalahan dalam mengenali jenis buah. Sedangkan
komputer dapat bekerja tanpa mengenal lelah dan tidak melihat jumlah maupun waktu.
Dalam pengenalan pola terdapat berbagai cara untuk mengenali karakteristik suatu
obyek. Dapat dicontohkan, dalam proses pemisahan ikan salmon dan ikan seabase
pengenalan karakteristiknya menggunakan features seperti panjang badan, lebar badan, bentuk badan, dll. Setelah features didapatkan dibutuhkan suatu algoritma untuk mengolah features tersebut sehingga akhirnya obyek dapat dikelompokan berdasarkan jenisnya. Dalam pengenalan jenis buah ini metode yang akan digunakan adalah metode
Bayesian.
I.2. Rumusan Masalah
Dari latar belakang diatas, dapat dirumuskan masalah yaitu bagaimana metode Bayesian
membantu pengenalan otomatis buah-buahan dan memberikan akurasi yang baik?
I.3. Tujuan Penulisan
Merancang dan mengimplementasikan metode Bayesian untuk mengenali gambar buah
3
I.4. Batasan Masalah
Dalam pengenalan jenis buah – buahan dilakukan beberapa batasan sebagai berikut :
i) Buah yang akan dikenali adalah buah apel, jeruk, mangga, pisang dan stroberi
dalam bentuk digital still image. ii) Image bertipe JPEG.
iii) Buah yang akan dikenali hanya berdasar jenis, tidak memperhatikan varietasnya.
iv) Jumlah sampel setiap satu buah ada 80 buah.
v) Di dalam image hanya ada satu buah utuh tidak terpotong dan tidak bergerombol,
dengan background berwarna putih.
vi) Pemodelan jenis buah menggunakan metode Bayesian.
vii)Program dibuat dengan bahasa Matlab.
I.5. Manfaat Penelitian
Penelitian ini akan memberikan sumbangan baru bagi ilmu pengetahuan, baik ilmu
komputer maupun bidang – bidang yang lain. Implementasi praktis dari sistem yang
dirancang akan memberikan sumbangan bagi banyak pengguna di kalangan pendidikan
maupun bisnis. Di kalangan pendidikan penelitian ini dapat digunakan untuk media
pembelajaran bagi siswa. Sedangkan untuk kalangan bisnis, penelitian ini dapat
digunakan dalam proses pemisahan buah – buahan untuk produksi buah kaleng.
I.6. Metodologi Penelitian
Untuk dapat melakukan penelitian ini, metode penelitian yang dilakukan adalah :
a. Studi pustaka tentang metode Bayesian.
4
b. Pengumpulan data
Pada tahap ini dilakukan pencarian dan pengumpulan data. Data didapat dari
memotret gambar buah dan pencarian di internet.
c. Desain
Pada tahap ini akan dibuat desain user interface yang akan digunakan untuk membangun aplikasi.
d. Implementasi dan Analisis
Pada tahap ini akan dibuat implementasi sistem sesuai dengan desain yang sudah
dibuat. Pada implementasi ini akan dihasilkan tampilan antar muka yang lengkap.
e. Pengujian dan Evaluasi
Pada tahap ini dilakukan pengujian untuk mengetahui jika ada kesalahan dalam
implementasi program. Evaluasi dilakukan dengan maksud mengetahui ketepatan
penggunaan algoritma dalam implementasi.
f. Kesimpulan
Kesimpulan dibuat berdasarkan hasil pengujian terhadap program yang telah
dibuat. Program dinyatakan berhasil, jika program tersebut dapat mengenali jenis
buah dengan benar.
I.7. Sistematika Penulisan
BAB 1, pendahuluan
Pada bagian ini digambarkan latar belakang yang mengarah pada deskripsi
topik, rumusan masalah, batasan sistem, tujuan penelitian, manfaat sistem atau
kontribusi yang dapat diberikan melalui penelitian yang akan dilakukan, metode
5
BAB 2, landasan teori
Pada bagian ini digambarkan dasar teoritis yang akan dipakai dalam
implementasi, yaitu pendekatan Bayesian dalam pembedaan pola.
BAB 3, metodologi dan perancangan sistem
Pada bagian ini digambarkan perancangan sistem dan metodologi yang
digunakan dalam penelitian.
BAB 4, implementasi dan analisis
Pada bagian ini digambarkan penerapan rancangan yang dibuat dalam suatu
program, hasil implementasi serta analisisnya.
BAB 5, kesimpulan dan saran
Pada bagian ini akan digambarkan kesimpulan yang menjawab permasalahan
6
BAB II
LANDASAN TEORI
Dalam bab ini akan dijelaskan mengenai teori – teori yang digunakan untuk mendukung
penulisan tugas akhir pengenalan jenis buah dengan menggunakan metode Bayesian. Teori –
teori yang akan dijelaskan adalah teori tentang pengolahan citra, pengenalan pola dan metode
Bayesian.
II.1. Pengolahan Citra
Pengolahan citra digital merupakan proses yang bertujuan untuk memanipulasi
dan menganalisis citra dengan bantuan komputer. Pengolahan citra digital dapat
dikelompokkan dalam dua jenis kegiatan :
1. Memperbaiki kualitas suatu gambar, sehingga dapat lebih mudah diinterpretasi
oleh mata manusia.
2. Mengolah informasi yang terdapat pada suatu gambar untuk keperluan pengenalan
objek secara otomatis.
Bidang aplikasi yang kedua sangat erat hubungannya dengan ilmu pengetahuan
pola (pattern recognition) yang umumnya bertujuan mengenali suatu objek dengan cara
mengekstrak informasi penting yang terdapat pada suatu citra. Bila pengenalan pola
dihubungkan dengan pengolahan citra, diharapkan akan terbentuk suatu sistem yang
dapat memproses citra masukan sehingga citra tersebut dapat dikenali polanya. Proses
ini disebut pengenalan citra atau image recognition.
Pengolahan citra dan pengenalan pola menjadi bagian dari proses pengenalan
citra. Kedua aplikasi ini akan saling melengkapi untuk mendapatkan ciri khas dari suatu
7
(Srini, 2006)
1. Akusisi citra
Pengambilan data dapat dilakukan dengan menggunakan berbagai media seperti
kamera analog, kamera digital, handycam, scanner, optical reader dan sebagainya.
Dalam proses akuisisi, citra yang akan diolah ditransformasikan ke dalam
representasi numerik. Pada proses selanjutnya representasi numerik tersebut yang
akan diolah dsecara digital oleh komputer.
2. Peningkatan kualitas citra
Tahap ini dikenal dengan proses pre-processing. Kualitas citra dapat
meningkatkan kemungkinan dalam keberhasilan pada tahap pengolahan citra
berikutnya. Untuk meningkatkan kualitas citra dapat dilakukan beberapa hal,
seperti perbaikan kontras gelap – terang, penajaman dan pemberian warna semu.
3. Segmentasi citra
Segmentasi bertujuan untuk memilih dan memisahkan suatu objek dari
keseluruhan citra dengan suatu kriteria tertentu.
4. Representasi dan uraian
Representasi mengacu pada data konversi dari hasil segmentasi ke bentuk yang
lebih sesuai untuk proses pengolahan pada komputer. Setelah data telah
direpresentasikan ke bentuk tipe yang lebih sesuai, tahap selanjutnya adalah
membentuk ulang data dari beberapa citra hasil segmentasi.
5. Pengenalan dan interpretasi
Pengenalan pola tidak hanya bertujuan untuk mendapatkan citra dengan suatu
kualitas tertentu, tetapi juga untuk mengklasifikasikan bermacam-macam citra.
Dari sejumlah citra diolah sehingga citra dengan ciri yang sama akan
8
dalam mengartikan objek yang dikenali.
II.2. Pengenalan Pola
II.2.1. Pengertian pola dan ciri
Pola adalah entitas yang terdefinisi dan dapat diidentifikasikan melalui ciri
– cirinya (features). Ciri – ciri tersebut akan digunakan untuk membedakan pola yang satu dengan pola yang lain. Ciri yang bagus adalah ciri yang mempunyai
tingkat pembedaan yang tinggi, sehingga pengelompokan suatu pola dengan ciri
yang dimiliki dapat dilakukan dengan menghasilkan nilai keakuratan yang
tinggi.
Sebagai contoh :
Pola Ciri
Huruf Tebal, tinggi, titik sudut, lengkungan garis, dll
Tanda tangan Panjang, kerumitan, tekanan, dll
Suara Frekuensi, amplitudo, intonasi, warna, nada, dll
Sidik jari Jumlah garis, lengkungan, dll
Ciri pada suatu pola dapat diperoleh dari hasil pengukuran terhadap suatu
obyek yang diuji. Khusus pada pola yang terdapat di dalam citra, ciri – ciri dapat
diperoleh dari informasi seperti dibawah ini :
• Spasial : intensitas pixel,histogram,dll
• Tepi : arah, kekuatan, dll
• Kontur : garis, elips, lingkaran, dll
• Wilayah / bentuk : keliling, luas,pusat masa,dll
9
II.2.2. Pengenalan Pola
Pengenalan pola merupakan suatu aktivitas yang sudah biasa dilakukan
oleh manusia. Manusia melakukannya hampir setiap saat, baik secara sadar
maupun tidak sadar. Informasi diperoleh melalui berbagai organ sensor yang
diproses secara langsung oleh otak, agar dengan segera manusia mampu
mengidentifikasi sumber informasi tersebut tanpa perlu usaha yang berarti.
Hampir setiap aktivitas manusia berdasarkan pada keberhasilan dalam berbagai
kegiatan pengenalan pola. Salah satu aplikasinya adal
klasifikasi teks dokumen dalam kategori (contoh. surat-E spam/bukan-spam),
surat, atau sistem
menggunaka
Disiplin pengenalan pola pada dasarnya berkenaan dengan masalah
pengembangan algoritma dan metodologi yang memungkinkan implementasi
oleh komputer terhadap berbagai kegiatan pengenalan yang biasa dilakukan
manusia. Motivasinya adalah untuk menjalankan kegiatan pengenalan tersebut
dengan lebih akurat, atau lebih cepat, dan mungkin lebih ekonomis dari
manusia. Ruang lingkup dari pengenalan pola ini juga termasuk hal-hal yang
tidak biasa dilakukan oleh manusia, seperti membaca bar code.
Adapun langkah – langkah dari pengenalan pola adalah sebagai berikut :
a. Pengumpulan data.
Pengumpulan data adalah proses pengambilan data gambar buah.
b. Feature Analisis.
10
menjadi file yang siap diekstraksi cirinya dengan cara konversi data
mentah ke data digital dalam format *.JPG.
c. Pengenalan.
Ekstraksi ciri adalah tahap untuk mendapatkan frekuensi kemunculan
dari masing-masing pola.
d. Pengambilan keputusan.
Tahap ini merupakan tahap penentuan keputusan, yang didasarkan pada
perhitungan yang dilakukan pada tahap ekstraksi ciri pola jenis buah.
e. Keputusan.
Tahap keputusan adalah tahap akhir dari proses pengelompokan jenis
buah yang diharapkan dapat memberikan hasil yang tepat.
II.2.3. Teknik Pengenalan Pola
Pengenalan pola bertujuan untuk menentukan kelompok atau kategori pola
berdasarkan ciri yang dimiliki oleh pola tersebut. Dengan kata lain pengenalan
pola akan membedakan suatu obyek dengan obyek yang lain. Terdapat tiga
pendekatan yang dilakukan dalam pengenalan pola, yaitu pendekatan melalui
jaringan saraf tiruan, pendekatan secara sintatik atau struktural dan pendekatan
secara statistik. (Eri Sasmadi, 2008)
i) Pendekatan melalui jaringan saraf tiruan
Pendekatan dengan pola jaringan saraf tiruan adalah pendekatan
dengan menggabungkan pendekatan sintaks dan statistik. Pendekatan
melalui pola-pola ini meniru cara kerja otak manusia. Pada pola ini sistem
membuat rule-rule tertentu disertai dengan data statistik sebagai dasar
11
Untuk pengenalan pola dengan pendekatan jaringan saraf tiruan
seolah – olah dibuat sebuah sistem yang kinerjanya sama dengan otak
manusia. Agar sitem tersebut bisa menjadi cerdas, harus diberikan
pelatihan selama rentang waktu yang ditentukan. Karena dengan melatih
sistem maka akan menambah rule-rule serta data statistik yang digunakan
oleh sistem untuk mengambil keputusan.
ii) Pendekatan secara sintatik
Pendekatan secara sintaks adalah pendekatan dengan menggunakan
aturan - aturan tertentu atau menggunakan teori bahasa formal. Pengenalan
pola secara sintatik lebih dekat ke strategi pengenalan pola yang dilakukan
oleh manusia, namun secara praktek penerapannya relatif sulit bila
dibandingkan dengan pendekatan secar statistik.
Misalnya baju si mamat mempunyai rule sebagai berikut, selalu
berwarna Biru, bahannya kaos, bermerek adidas, lengannya lengan
panjang dan berkerah. Jika ada sebuah baju dengan ciri-ciri 90% lebih dari
ciri-ciri tersebut dapat dikatakan bajunya mamat, dengan toleransi sekitar
10%.
iii) Pendekatan secara statistik
Pendekatan secara statistik menggunakan teori-teori ilmu peluang
dan statistik. Ciri-ciri yang dimiliki oleh suatu pola ditentukan distribusi
statistiknya. Pola yang berbeda memiliki distribusi yang berbeda pula.
Dengan menggunakan teori keputusan di dalam statistik, kita
12
Contoh teori keputusan:
Misalkan ada N pola yang dikenali, yaitu w1, w2, …, wN dan fungsi peluang atau kerapatan dari ciri-ciri pada pola diketahui. Jika x merupakan hasil pengukuran ciri-ciri, maka
p(x wi ) , i = 1, 2, …, N
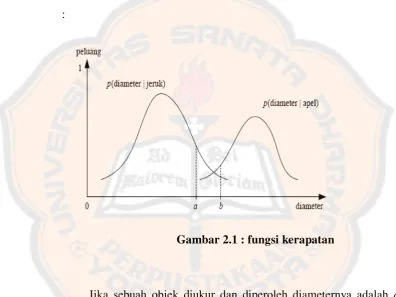
dapat dihitung. Sebagai contoh, misalkan diketahui fungsi kerapatan dari
diameter buah jeruk dan apel yang diperlihatkan pada Gambar 2.1 dibawah
:
Gambar 2.1 : fungsi kerapatan
Jika sebuah objek diukur dan diperoleh diameternya adalah a cm, maka kita mengklasifikasikan objek tersebut sebagai “jeruk”, karena
p(a | jeruk) > p(a | apel)
dan jika hasil pengukuran diameter adalah b cm, kita mengklasifikasikan objek tersebut sebagai “apel”, karena
13
II.3. Metode Bayesian
Teori keputusan Bayesian adalah pendekatan statistik yang fundamental dalam
pengenalan pola (pattern recognition). Pendekatan ini didasarkan pada kuantifikasi
trade-off antara berbagai keputusan klasifikasi dengan menggunakan probabilitas dan ongkos yang ditimbulkan dalam keputusan – keputusan tersebut. (Budi Santoso, 2007)
Dalam pembelajaran akan ditentukan hipotesis yang terbaik dari space H, dengan data yang diamati x. Untuk menetapkan hipotesis yang terbaik diperlukan hipotesis yang paling mungkin, data x sebagai pengetahuan awal tentang kemungkinan dari berbagai hipotesis dalam H. Teorema Bayes menyediakan suatu jalan/cara untuk mengkalkulasi kemungkinan suatu hipotesis berdasar pada kemungkinan awalnya,
kemungkinan dalam pengamatan berbagai data dapat memberikan hipotesis.
P(h) untuk menandakan kemungkinan awal bahwa hipotesis h dipegang. P(h) sering disebut dengan prior probablity (probabilitas prior) dari h, P(x) merupakan kemungkinan awal bahwa data training x akan diamati. P(x|h) untuk menandakan kemungkinan dimana data training x memberi banyak hipotesis h.
Dalam banyak kasus, keputusan diambil dengan menggunakan informasi yang
lebih banyak tidak hanya dengan probabilitas prior saja. Fungsi likelihood juga bisa digunakan sebagai tambahan informasi dalam pengambilan keputusan. Dalam Bayes
learning akan dimaksimalkan hipotesis yang paling mungkin, h, atau maximum apriori
(MAP).
Langkah – langkah perhitungan menggunakan metode Bayesian adalah sebagai
berikut:
1. Penghitungan mean dan standar deviasi (ditentukan dari nilai masing – masing
14
2. Penghitungannilai probability density function
(2.1)
3. Penghitungan nilai likelihood
(2.2)
4. Penghitungan nilai probabilitas
(2.3)
5. Penentuan probabilitas maksimum
(2.4)
II.3.1. Contoh perhitungan menggunakan metode Bayesian
Untuk lebih memahami perhitungan menggunakan metode Bayesian, akan
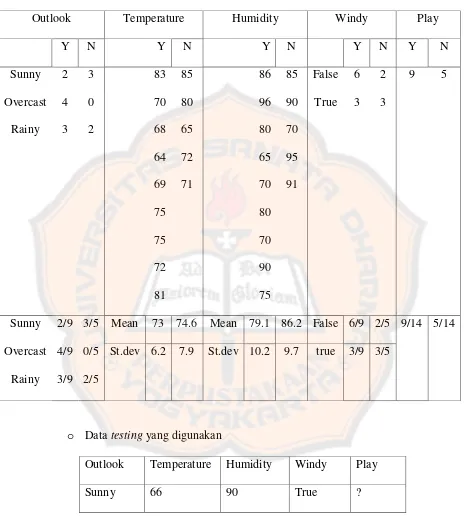
15 o Terdapat data training sebagai berikut
Tabel 2.1
Tabel Contoh Perhitungan
Outlook Temperature Humidity Windy Play
Y N Y N Y N Y N Y N
o Data testing yang digunakan
Outlook Temperature Humidity Windy Play
Sunny 66 90 True ?
o Pertanyaan : Berapa probabilitas yes?
16 o Jawab :
1. Nilai mean dan standar deviasi sudah dihitung dalam tabel training.
2. Perhitungan nilai probability density function
3. Perhitungan nilai likelihood
Likelihood of yes =2/9 x 0.1216 x 0.0692 x 3/9 x 9/14 = 0.00040
17
4. Perhitungan nilai probabilitas
o Jadi probabilitas yes adalah 43.48% dan probabilitas untuk no adalah
18
BAB III
METODOLOGI DAN PERANCANGAN SISTEM
Dalam bab ini akan dijelaskan analisis sistem, metodologi (skema alur sistem) dan
desain user interface. Metodologi dilakukan untuk menjelaskan setiap tahap yang dilakukan dalam proses pengenalan pola buah – buahan dengan menggunakan metode Bayesian
sehingga akan dihasilkan sistem yang maksimal.
IV.1. Analisis Sistem
Terdapat banyak sekali jenis buah yang ada, masing – masing buah mempunyai
varietas yang berbeda – beda. Buah – buahan tersebut hanya akan dibedakan menurut
jenisnya tanpa memperhatikan varietasnya. Setiap jenis buah memiliki karakteristik
yang unik. Salah satu contoh karakteristik unik dari buah dapat dilihat dari bentuknya.
Dengan mengenali buah dari ciri – cirinya (baik dari bentuk, warna maupun
teksturnya), maka dapat diketahui bahwa buah dengan ciri tertentu dikelompokan
dalam jenis yang sama.
Terdapat beberapa metode yang dapat digunakan untuk mengenali pola, salah
satunya adalah metode Bayesian. Metode Bayesian adalah pendekatan statistik yang
didasarkan pada keputusan klasifikasi dengan menggunakan probabilitas.
Data berupa image atau gambar yang didapat dengan memotret obyek buah – buahan, yaitu buah apel, pisang, jeruk, mangga dan buah stroberi. Data yang akan
digunakan adalah gambar buah yang utuh, tidak terpotong dan tidak bergerombol.
Untuk gambar buah yang bertumpuk atau bergerombol dilakukan pengeditan agar
menjadi satu buah saja dan yang lain dianggap sebagai noise yang harus dihilangkan.
19
Data yang digunakan 400 buah. Terdapat lima jenis buah, masing – masing jenis
buah sebanyak 80 buah. Setiap jenis buah diambil contoh yang berbeda – beda.
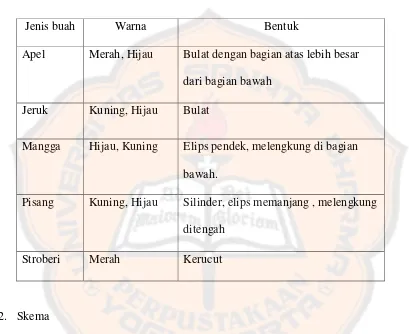
Karakteristik :
Tabel 3.1:
Tabel Karakteristik Buah
Jenis buah Warna Bentuk
Apel Merah, Hijau Bulat dengan bagian atas lebih besar
dari bagian bawah
Jeruk Kuning, Hijau Bulat
Mangga Hijau, Kuning Elips pendek, melengkung di bagian
bawah.
Pisang Kuning, Hijau Silinder, elips memanjang , melengkung
ditengah
Stroberi Merah Kerucut
IV.2. Skema
Proses pengenalan pola buah – buahan dengan menggunakan metode Bayesian
secara garis besar ditunjukan pada gambar 3.1 sebagai berikut :
gambar.jpg
20
Gambar 3.1 menunjukan garis besar proses pengenalan buah – buahan dengan
menggunakan metode Bayesian. Inputan berupa feature asli gambar buah bertipe JPG sebagai data mentah. Data akan diekstrak featuresnya yang kemudian akan menjadi data inputan dalam proses pengenalan pola sehingga menghasilkan output berdasarkan
data yang telah dikenali sebagai data hasil pengklasifikasian.
IV.1.1. Feature Analisis
Masing - masing buah mempunyai karakter yang berbeda, perbedaan karakter
buah dapat digunakan untuk membedakan jenis buah yang satu dengan yang lain.
Beberapa karakter yang sering digunakan untuk membedakan jenis buah antara lain
ukuran, warna, tekstur dan berat. Tetapi dalam penelitian ini hanya akan menggunakan
2 karakter saja yang akan dijadikan sebagai feature pembeda jenis buah, yaitu warna dan ukuran.
Dalam tahap ini, akan ditentukan perhitungan untuk masing - masing featurenya.
Feature yang digunakan adalah sebagai berikut :
• Perbandingan ukuran
Perbandingan ukuran yang akan digunakan adalah perbandingan jarak
horizontal dan vertikal.
• Menghitung rata – rata Hue
• Menghitung rata – rata RGB ((R + G + B) / 3)
• Menghitung rata – rata nilai R
• Menghitung rata – rata nilai G
• Menghitung rata – rata nilai B
• Menghitung nilai (2R - (G + B))
21 • Menghitung nilai (2B – (G + R))
IV.1.2. Pengenalan dengan menggunakan metode Bayesian
Setelah tahap feature analisis dilakukan, tahap selanjutnya adalah proses pengenalan pola buah – buahan dengan menggunakan metode Bayesian. Proses
pengenalannya ditunjukan dalam gambar berikut :
maksimum
Mean dan standar deviasi masing – masing feature
untuk setiap jenis buah
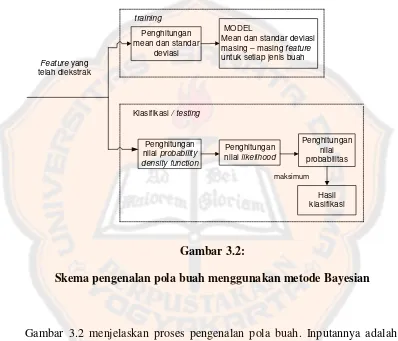
Skema pengenalan pola buah menggunakan metode Bayesian
Gambar 3.2 menjelaskan proses pengenalan pola buah. Inputannya adalah data
yang telah mengalami pengekstrakan feature kemudian dilakukan proses pengenalan dengan menggunakan metode Bayesian. Dalam proses ini terdapat 2 tahap yang harus
dilalui sebelum akhirnya data dapat diklasifikasikan, yaitu tahap training dan tahap
22
III.2.2.1. Five folds
Tahap ekstraksi feature menggunakan file JPEG yang diekstrak untuk mendapatkan model pada setiap jenis buah dan kemudian mengklasifikasikan
sampel-sampel buah ke dalam kelompok buah tertentu dengan model pola buah yang sesuai.
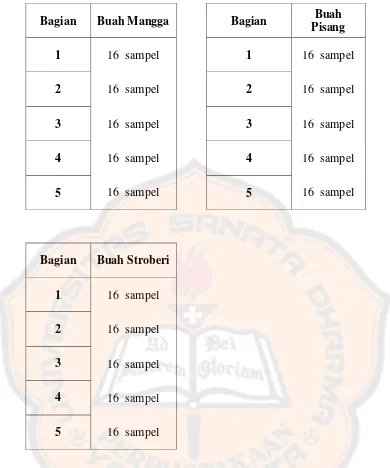
Metode five folds akan membagi data menjadi 5 bagian, 4 bagian untuk data
training dan 1 bagian untuk data testing. Terdapat 5 jenis buah, setiap jenis buah mempunyai 80 sampel buah. Penghitungan five folds sebagai berikut:
Dari hasil perhitungan didapatkan 16 sampel untuk setiap bagiannya. Jumlah
seluruh data adalah 400 sampel, maka untuk data training sebanyak 320 sampel (4 bagian sampel) sedangkan untuk data testing diambilkan dari 80 sampel sisanya (1 bagian sampel). Pembagian sampel ditunjukkan pada tabel 3.2 berikut :
Tabel 3.2
Tabel Pembagian Sampel
Bagian Buah Apel Bagian Buah Jeruk
1 16 sampel 1 16 sampel
2 16 sampel 2 16 sampel
3 16 sampel 3 16 sampel
4 16 sampel 4 16 sampel
23
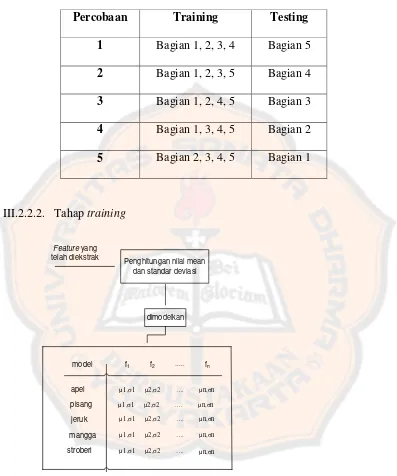
Tabel 3.3 dibawah menunjukan percobaan pada saat proses pengenalan pola. Jika
data training diambil dari sampel bagian 1, 2, 3 dan 4, maka bagian 5 akan dijadikan sebagai data testing. Begitu juga untuk percobaan selanjutnya, jika 4 bagian sudah
dijadikan data training 1 bagian sisanya digunakan untuk data testing.
Bagian Buah Mangga Bagian Buah
Pisang
1 16 sampel 1 16 sampel
2 16 sampel 2 16 sampel
3 16 sampel 3 16 sampel
4 16 sampel 4 16 sampel
5 16 sampel 5 16 sampel
Bagian Buah Stroberi
1 16 sampel
2 16 sampel
3 16 sampel
4 16 sampel
24 Tabel 3.3
Tabel Percobaan
Percobaan Training Testing
1 Bagian 1, 2, 3, 4 Bagian 5
telah diekstrak Penghitungan nilai mean dan standar deviasi
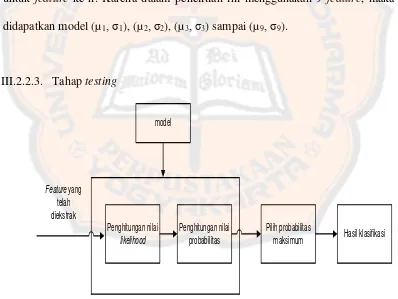
Skema alur pikir tahap training
Gambar 3.3 diatas menjelaskan skema alur pikir tahap training. f1, f2,…., fn
25
model untuk setiap jenis buah. Data untuk training sebanyak 320 buah, didapat dari perhitungan five fold.
= 320 sampel
Setelah dilakukan ekstraksi feature, kemudian data akan dimodelkan. Model data
diperoleh dari penghitungan mean (µ) dan standar deviasi (σ) untuk setiap jenis buah.
Dari gambar 3.3 ditunjukan hasil penghitungan µ dan σ dari masing - masing jenis
buah untuk setiap feature, model (µ1, σ1) adalah mean dan standar deviasi untuk
feature 1, (µ2, σ2) adalah mean dan standar deviasi untuk feature 2, (µ3, σ3) adalah
mean dan standar deviasi untuk feature 3, (µn, σn) adalah mean dan standar deviasi
untuk feature ke-n. Karena dalam penelitian ini menggunakan 9 feature, maka akan didapatkan model (µ1, σ1), (µ2, σ2), (µ3, σ3) sampai (µ9, σ9).
26
Gambar 3.4 menjelaskan skema alur pikir tahap testing. Tujuan dari tahap ini adalah mengenali obyek. Dalam tahap ini diperlukan data baru ( data testing ) yang harus berbeda dengan data training. Data untuk testing sebanyak 80 buah, didapat dari perhitungan five fold.
= 80 sampel
Langkah awal tahap ini sama dengan langkah awal pada tahap training, yaitu mengekstrak feature. Setelah pengekstrakan feature, langkah selanjutnya adalah pengenalan pola dengan metode Bayesian. Hasil dari pengenalan ini akan
dibandingkan dengan model yang sudah terbentuk pada tahap training. Pada saat proses pembandingan akan dihitung nilai likelihood dan nilai probabilitas. Dari hasil pembandingan dipilih nilai probabilitas yang maksimum, setelah nilai probabilitas
maksimum ditentukan maka dapat diketahui klasifikasinya.
IV.1.3. Evaluasi
Dalam tahap evaluasi ini akan dihitung tingkat keakurasian percobaan. Berdasar
pembagian data dengan metode five fold, maka akan terdapat 5 kali percobaan. Dari tahap testing dapat diketahui berapa banyak buah apel yang dikenali sebagai apel, pisang, jeruk, mangga, stroberi; buah pisang yang dikenali sebagai apel, pisang, jeruk,
mangga, stroberi; buah jeruk yang dikenali sebagai apel, pisang, jeruk, mangga,
stroberi; buah mangga yang dikenali sebagai apel, pisang, jeruk, mangga, stroberi;
buah stroberi yang dikenali sebagai apel, pisang, jeruk, mangga, stroberi.
27
berikut (percobaan diulang sebanyak 5 kali) :
Tabel 3.4
Confusion Matrix
Dari hasil percobaan diatas, dapat dihitung tingkat akurasi dari percobaan yang
telah dilakukan. Penghitungan tingkat akurasi :
Untuk kasus diatas, ∑ data benar adalah jumlah angka yang terdapat pada diagonal
matriks. Sedangkan ∑ data total adalah jumlah keseluruhan data yang digunakan
untuk testing / pengujian.
IV.3. Studi Awal
Dalam mata kuliah Pengenalan Pola, penelitian ini sudah pernah dilakukan.
Tetapi data dan feature yang digunakan tidak sebanyak data dan feature yang digunakan dalam penelitian ini. Dalam mata kuliah Pengenalan Pola data yang
digunakan adalah 50 buah yang terdiri dari 5 jenis buah (buah apel, pisang, jeruk,
mangga dan buah stroberi) setiap jenis buah terdiri dari 10 buah dan hanya
apel Pisang jeruk mangga stroberi apel
pisang
jeruk
mangga
28
menggunakan 4 buah feature, yaitu perbandingan jarak horizontal : vertikal, nilai rata – rata Hue, perbandingan warna hijau : merah, dan perbandingan warna kuning :
merah.
Dari data sebanyak 50 buah dan hanya menggunakan 4 buah feature, akurasi yang didapatkan sebesar 67%.
IV.4. Perancangan Desain Tampilan Program
III.4.1. Perancangan Form Halaman Utama
PENGENALAN JENIS BUAH MENGGUNAKAN METODE BAYESIAN
Gambar Asli
Buka Gambar
Pengenalan Gambar
Bant uan
Tent ang Program
Keluar
Gambar 3.5
Perancangan Form Halaman Utama
Dalam tampilan form halaman utama terdapat 5 tombol menu, yaitu tombol Buka
Gambar, Pengenalan Gambar, Bantuan, Tentang Program, Keluar) dan 1 plot untuk
menampilkan Gambar..
Kegunaan dari tiap – tiap tombol menu :
1. Buka Gambar
Tombol Buka Gambar berguna untuk mengambil file gambar dari folder
29
2. Pengenalan Gambar
Tombol Pengenalan Gambar akan didisable apabila tidak ada gambar yang
dibuka. Tombol Pengenalan Gambar akan aktif kembali jika user membuka
sebuah file gambar. Kegunaan dari tombol ini adalah untuk pengenali gambar
menggunakan metode Bayesian.
3. Bantuan
Tombol Bantuan digunakan untuk memperoleh informasi tentang penggunaan
program.
4. Tentang Program
Tombol Tentang program digunakan untuk meperoleh informasi tentang pembuat
program.
5. Keluar
Tombol Keluar digunakan untuk keluar dari program.
III.4.2. Perancangan Form Buka Gambar
Open File
Look in:
I si Folder
Open Cancel
File Name:
Files of Type:
Gambar 3.6
30
Form Buka Gambar berfungsi untuk mengambil gambar yang akan dikenali.
Field Look in, digunakan untuk mencari folder tempat gambar disimpan. Yang kemudian isi folder akan tertampil di kotak dibawahnya. Jika salah satu isi folder
disorot, nama file citra tersebut akan tertampil di field File Name. Field Files of Type
digunakan untuk mencari jenis file apa yang akan dibuka. Jika file citra telah
ditemukan klik tombol Open untuk membuka file citra. Jika ingin membatalkan gunakan tombol Cancel.
III.4.3. Perancangan Form Pengenalan Gambar
Pengenalan Gambar
Nama File : Proses
Hasil perhit ungan
feat ure Hasil perhit ungan bayes
Gambar yang akan dikenali
Kesimpulan :
Gambar disamping dikenali sebagai :
Gambar 3.7
Perancangan Form Pengenalan Gambar
Form pengenalan gambar berfungsi untuk mengetahui hasil penghitungan pada
31
proses ditekan maka akan muncul hasil perhitungan feature dan hasil perhitungan bayes yang akan tertampil dalam plot. Plot gambar yang akan dikenali digunakan
untuk menunjukan gambar yang mengalami proses pengenalan.
III.4.4. Perancangan Form Batuan
Bantuan
PENGENALAN JENI S BUAH MENGGUNAKAN METODE BAYESI AN
Tujuan program
Batasan program
Penggunaan program
Gambar 3.8
Perancangan Form Bantuan
Form bantuan berisi menu tujuan program, batasan program dan menu petunjuk
32
III.4.5. Perancangan Form Tentang Program
Tentang Program
PENGENALAN JENI S BUAH MENGGUNAKAN METODE BAYESI AN
Tugas Akhir :
MF. I ndah Aryanti Puspitarini 055314047
Jurusan Teknik I nformatika, Fakultas Sains dan Teknologi Universitas Sanata Dharma
Yogyakarta 2009
Gambar 3.9
Perancangan Form Tentang Program
Form Tentang Program menampilkan informasi tentang pembuatan program
Pengenalan Jenis Buah Menggunakan Metode Bayesian.
33
BAB IV
IMPLEMENTASI DAN ANALISIS SISTEM
Dalam bab ini akan dijelaskan kebutuhan sistem yang mencakup spesifikasi perangkat
keras dan perangkat lunak, implementasi sistem berupa analisis sistem dan analisis hasil
pengujian.
IV.1.Kebutuhan Sistem
Dalam pengimplementasian sistem pengenalan jenis buah ini diperlukan
perangkat keras dan perangkat lunak serta data yang akan digunakan dalam penelitian.
IV.1.1. Kebutuhan Perangkat Keras
Dalam pengimplementasian sistem pengenalan jenis buah ini, spesifikasi
perangkat keras yang diperlukan sebagai berikut :
1. Processor : Intel Core 2 Duo T6600
2. VGA : NVIDIA GeForce G105M
3. Harddisk : 320 GByte
4. Memory : 2 GByte
Adapun perangkat keras yang disebutkan di atas tidak bersifat mutlak, dapat
digantikan dengan perangkat keras spesifikasi lain yang sesuai.
IV.1.2. Kebutuhan Perangkat Lunak
Dalam pembuatan dan pengimplementasian sistem pengenalan jenis buah ini
diperlukan perangkat lunak dengan spesifikasi sebagai berikut :
1. Adobe Photoshop
34
Adobe Photoshop digunakan dalam tahap pre-processing untuk pemotongan buah yang bertumpuk atau bergerombol, sedangkan Matlab 6.5.1 digunakan untuk
pengenalan jenis buah.
IV.2. Implementasi Sistem
Implemetasi sistem ini meliputi proses training dan testing untuk semua data buah
serta analisis hasil pengujian.
IV.2.1. Proses Training
Proses training meliputi proses pengekstrakan ciri serta pembagian data menggunakan five folds dan penghitungan mean dan standar deviasi untuk setiap
feature dari setiap sampel buah. Output dari proses training ini adalah model untuk setiap jenis buah.
IV.2.1.1. Ekstak Feature
Setelah melalui tahap pre-processing, data buah akan diekstrak feature-nya. Pengekstrakan feature meliputi penghitungan perbandingan ukuran, rata-rata Hue, rata-rata RGB, rata-rata nilai R, rata-rata nilai G, rata-rata nilai B, nilai
(2R-(G+B)), nilai (2G-(R+B)) dan nilai (2B-(G+R)).
35
Dalam proses pengekstrakan ini akan menghasilkan data dengan angka apa
adanya yang disimpan dalam matrik h1 (untuk apel), h2 (untuk jeruk), h3 (untuk
mangga), h4 (untuk pisang), h5 (untuk stroberi). Dari data yang dihasilkan dalam
setiap matrik akan ada satu feature yang sangat dominan, sehingga hasil pengklasifikasian akan cenderung dalam hasil yang dominan tersebut. Untuk
menghindari hasil yang dominan dalam pengekstrakan ini, dibutuhkan
normalisasi. Normalisasi yang digunakan dalam pengekstrakan feature ini adalah
teori transformasi Z. Rumus untuk menghitung normalisasi menggunakan
transformasi Z sebagai berikut
36
Proses pengekstrakan normalisasi,menggunakan program berikut
Untuk proses normalisasi ini semua hasil pengekstrakan feature
digabungkan dalam satu matrik kosong yang sudah disiapkan. Kemudian dari
data yang tesimpan dalam matrik gabungan dihitung nilai mean dan standar
deviasinya. Setelah diketahui nilai mean dan standar deviasi, dihitung nilai Xn
dari masing-masing data dalam matrik gabungan untuk mendapatkan data baru
setelah proses normalisasi.
Setelah proses normalisasi, data gabungan kemudian dibagi dan
dikelompokan dalam masing-masing jenis buah. Dimana data ke-1 sampai data
80 menjadi data apel, data 81 sampai 160 menjadi data jeruk, data
ke-161 sampai ke-240 menjadi data mangga, data ke-241 sampai ke-320 menjadi
data pisang dan data ke-321 sampai ke-400 menjadi data stroberi.
Proses normalisasi akan menyimpan hasil pengekstrakan dengan nama
hasilApel, hasilJeruk, hasilMangga, hasilPisang dan hasilStroberi. Masing-masing
hasil akan mempunyai martik 80 x 9, yang berarti 80 sampel untuk setiap jenis
buah dengan 9 feature. Kemudian hasil ekstraksi tersebut akan dibagi menjadi 5 bagian, dengan menggunakan metode five folds. Jadi, dalam implementasi sistem
H=[h1;h2;h3;h4;h5]; % menggabungkan 5 jenis buah hasil ekstraksi
37
ini akan terdapat 5 kali percobaan dengan 5 kali five folds (fold1, fold2, fold3, fold4 dan fold5).
Proses pembagian data, menggunakan program berikut (sebagai contoh
fold1)
%matrik untuk data training dan testing setiap jenis buah trainA=[];
%matrix target seluruh data training untuk setiap jenis buah. targettrainA=[];
targettrainJ=[]; targettrainM=[]; targettrainP=[]; targettrainS=[];
38
Untuk proses five folds terlebih dahulu disiapkan matrik kosong untuk menyimpan data training dan testing serta matrik untuk target seluruh data training
dan target untuk seluruh data testing. Dalam fold1 ini data yang digunakan sebagai data training adalah data ke-1 sampai data ke-64, sedangkan data ke-65 sampai data ke-80 akan digunakan sebagai data testing. Hasil running fold1 akan terlihat dari matrik yang telah terbentuk sebelumnya. Matrik trainA, trainJ, trainM, trainP dan
trainS akan mempunyai matrik 64 x 9. Sedangkan tesA, tesJ, tesM, tesP dan tesS
masing-masing akan mempunyai matrik 16 x 9. Matrik-matrik hasil testing tersebut akan disimpan di dalam matrik data testing (DTS), sehingga DTS akan mempunyai
matrix 9 x 80. 80 sampel karena setiap jenis buah mempunyai data testing sebanyak 16 sampel.
targettrainA=[targettrainA,mmodelA]; targettrainJ=[targettrainJ,mmodelJ]; targettrainM=[targettrainM,mmodelM]; targettrainP=[targettrainP,mmodelP]; targettrainS=[targettrainS,mmodelS]; end
for j=1:16
39
IV.2.1.2. Penghitungan Nilai Mean dan Standar Deviasi
Setelah melakukan proses five folds, akan diketahui data mana yang akan digunakan sebagai data training atau data testing. Dari data training tersebut akan
dihitung nilai mean (µ) dan standar deviasinya (σ). Hasil penghitungan tersebut
akan dijadikan model untuk setiap jenis buah.
Proses penghitungan mean dan standar deviasi, menggunakan program
berikut (sebagai contoh menghitung mean dan standar deviasi untuk buah apel)
Hasil dari penghitungan mean dan standar deviasi ini akan disimpan di dalam
matrik kosong yang sudah disiapkan, yaitu MSA, MSJ, MSM, MSP dan MSP.
Setiap matrik tersebut akan menyimpan nilai mean dan nilai standar deviasi untuk
setiap feature. MSA, MSJ, MSM, MSP dan MSM akan mempunyai matrik 2 x 9. Matrik-matrik MSA, MSJ, MSM, MSP dan MSM inilah yang menjadi model
untuk setiap jenis buah.
% feature disimpan di variabel train [baris1,kolom1]=size(trainA);
[baris2,kolom2]=size(trainJ); [baris3,kolom3]=size(trainM); [baris4,kolom4]=size(trainP); [baris5,kolom5]=size(trainS);
% mean dan standar deviasi disimpan dalam variabel MS MSA=[];
MSJ=[]; MSM=[]; MSP=[]; MSS=[];
40
IV.2.2. Proses Testing
Setelah didapatkan model untuk setiap jenis buah, kemudian dilakukan tahap
testing. Dalam tahap testing ini data baru sebagai data testing akan dicocokan dengan model yang sudah ada.
Proses testing meliputi proses penghitungan nilai probability density function, penghitungan nilai likelihood, penghitungan nilai probabilitas dan penentuan nilai probabilitas terbesar. Output dari proses testing atau output yang ingin di tampilkan dari sistem ini adalah pengklasifikasian jenis buah.
IV.2.2.1. Penghitungan Nilai Probability Density Function
Langkah pertama dalam proses testing ini adalah penghitungan nilai density. Sebelum menghitung nilai density terlebih dahulu data testing diekstrak selanjutnya hasilnya dibandingkan dengan model yang sudah ada.
Proses penghitungan nilai probability density function, menggunakan program berikut
Model-model dari setiap buah akan disimpan dalam array. Hasil dari
penghitungan nilai denisity akan disimpan dalam matrik kosong yang sudah MATRIX={MSA MSJ MSM MSP MSS};
41
disiapkan yaitu MDEN. Matrik MDEN akan menyimpan nilai density semua data
untuk semua jenis buah. Jika satu data hasil penghitungan density mempunyai
matrik 5 x 9, maka matrik MDEN akan mempunyai matrik ((5 x 9) x 80).
IV.2.2.2. Penghitungan nilai Likelihood dan Probabilitas
Setelah nilai density didapat, kemudian dihitung nilai likelihood dan nilai probabilitas. Dari nilai probabilitas dapat ditentukan probabilitas maksimum dan
dapat diketahui jenis klasifikasinya.
Proses penghitungan nilai likelihood,menggunakan program berikut
Penghitungan nilai likelihood disimpan dalam matrik kosong L yang sudah disiapkan. Dari hasil penghitungan likelihood, maka matrik L akan mempunyai matrik 5 x 9 untuk 80 data.
Jenis buah dari data testing akan disimpan dalam matrik kosong yang sudah
42
IV.3. Analisis Hasil Pengujian
Penelitian ini bertujuan untuk mengklasifikasikan jenis buah dengan mengekstrak
feature untuk memperoleh hasil maksimal. Dalam penelitian ini terdapat 5 jenis buah yang akan diuji dengan 9 feature. Pada penelitian ini awalnya feature akan diekstrak satu per satu, kemudian data akan diuji lagi dengan menggunakan kombinasi feature.
Hasil dari pengekstrakan setiap feature akan ditampilkan pada tabel berikut.
Tabel 3.5
Tabel Hasil Ekstrak Setiap Feature
No Feature Hasil Akurasi ( dalam %)
1 Jarak 19.75 2 Rata Hue 18.75 3 Rata R 16.25 4 Rata G 10.25 5 Rata B 14.25 6 Rata RGB 16.5 7 Nilai 2RGB 4.25 8 Nilai 2GRB 1.5 9 Nilai 2BGR 20
43
dan rata-rata nilai 2BGR. Feature-feature tersebut dipilih karena mempunyai nilai yang berdekatan.
Untuk kombinasi feature dipilih dari feature yang mempunyai nilai akurasi terbesar hingga terkecil, yaitu nilai 2BGR, jarak, rata-rata Hue, rata-rata nilai RGB,
rata-rata nilai R, rata-rata nilai B dan rata-rata nilai G. Susunan kombinasi feature dan hasil pengkombinasian feature sebagai berikut (hasil kombinasi ditampilkan dalam bentuk grafik).
• Kombinasi 1 : nilai 2BGR dan jarak
• Kombinasi 2 : nilai 2BGR, jarak, rata-rata Hue
• Kombinasi 3 : nilai 2BGR, jarak, rata-rata Hue, rata-rata nilai RGB
• Kombinasi 4 : nilai 2BGR, jarak, rata-rata Hue, rata-rata nilai RGB, rata-rata
nilai R
• Kombinasi 5 : nilai 2BGR, jarak, rata-rata Hue, rata-rata nilai RGB, rata-rata
nilai R, rata-rata nilai B
• Kombinasi 6 : nilai 2BGR, jarak, rata-rata Hue, rata-rata nilai RGB, rata-rata
44
Gambar 4.1
Hasil Kombinasi Feature
Dari grafik diatas terlihat bahwa kombinasi 1 mempunyai nilai akurasi tertinggi,
sedangkan kombinasi 2 mempunyai nilai akurasi terendah. Kombinasi 3 mempunyai
nilai akurasi lebih tinggi dari kombinasi 2, dan untuk kombinasi 4,5 dan 6 mempunyai
nilai akurasi yang sama. Penambahan feature yang dalam pengekstrakan setiap
feature memiliki nilai akurasi yang baik ternyata tidak selalu memberikan hasil yang baik juga apabila dikombinasikan dengan feature yang lain, terlihat dalam kombinasi 2. Rata-rata Hue mempunyai nilai terbaik ketiga dalam pengekstrakan setiap feature, tetapi dalam pengkombinasian dengan feature yang lain justru mempunyai nilai akurasi terendah.
Akurasi terbaik yang diperoleh dari percobaan tersebut sebesar 20 %, hal ini
45
BAB V
KESIMPULAN DAN SARAN
IV.4. Kesimpulan
Berdasarkan hasil penelitian dan evaluasi yang telah dilakukan untuk pengenalan
/ klasifikasi jenis buah dengan menggunakan metode Bayesian, maka dapat ditarik
kesimpulan sebagai berikut
1. Buah yang paling banyak muncul dalam pengenalan ini adalah buah pisang dan
buah stroberi.
2. Hasil akurasi terbaik yang didapat dari pengkombinasian feature adalah 20%. 3. Kombinasi feature yang digunakan untuk memberikan hasil terbaik adalah
feature nilai 2BGR dan jarak.
4. Dari penelitian ini terbukti bahwa metode Bayesian dapat digunakan sebagai
metode pengenalan pola yang baik jika pemilihan buah dan pemilihan feature
tepat.
IV.5. Saran
Penelitian untuk pengembangan lebih lanjut, diperlukan data yang mungkin lebih
mempunyai karakteristik yang berbeda tidak hanya berdasarkan warna dan ukuran,
pemilihan jenis buah yang tepat dan pemilihan feature-feature yang digunakan untuk pengekstrakan ciri lebih kompleks sehingga akan memberikan hasil yang lebih
46
DAFTAR PUSTAKA
[1] Budi Santoso. 2007. Data Mining Teori & Aplikasi. Yogyakarta: Graha Ilmu, 75 - 78.
[2] Wikipedia Indonesia. 2007. Pengolahan Citra. Tersedia di: http://id.wikipedia.org/
wiki/Pengolahan_Citra [1 Februari 2009].
[3] Drs. Sahid, M.Sc. 2006. Panduan Praktis Matlab. Yogyakarta: Andi Offset. [4] Wahyu Agung Prasetyo. 2004. Tips dan Trik Matlab. Yogyakarta: Andi Offset. [5] Universitas Gunadarma. 2006. Pengolahan Citra : Konsep Dasar. Tersedia di:
[1 Februari 2009]