BAB 2
TINJAUAN PUSTAKA
Pada bab ini penulis memaparkan teori-teori ilmiah yang didapat dari metode pencarian fakta yang digunakan untuk mendukung penulisan skripsi ini dan sebagai dasar pengembangan sistem sehingga dapat diimplementasikan dengan baik dan benar.
2.1 Kompresi Data
Disamping usaha pengaman, sekarang ini orang juga berusaha melakukan proses pengecilan ukuran suatu data (kompresi suatu data). Tujuan dari kompresi ini adalah untuk mempercepat pengiriman data atau informasi tersebut. Keamanan dan kecepatan merupakan hal yang penting dalam komunikasi menggunakan komputer dan jaringan komputer.
Kompresi data adalah ilmu atau seni merepresentasikan informasi dalam bentuk yang lebih compact (Pu, 2006).
Kompresi adalah sebuah usaha untuk memperkecil ukuran data pada suatu file, dimana informasi yang terdapat didalam file tersebut tidak berubah. Untuk membuat suatu data menjadi lebih kecil ukurannya dari pada data asli, diperlukan algoritma tertentu. Dalam algortima kompresi data, tidak ada algoritma yang cocok untuk semua jenis data. Hal ini disebabkan karena data yang akan dikompres harus dianalisis terlebih dahulu, dan berharap menemukan pola tertentu yang dapat digunakan untuk memperoleh data dalam bentuk yang lebih kecil, karena itu muncul banyak algoritma-algoritma kompresi data.
Kompresi data adalah sebuah cara untuk memadatkan data sehingga hanya memerlukan ruang penyimpanan lebih kecil sehingga lebih efisien dalam menyimpannya atau mempersingkat waktu pertukaran data tersebut (Zhang, 1996).
Teknik kompresi dikenal dengan beberapa nama. Inisialisasi burrows dan wheeler digambarkan sebagai pengurutan perblok atau block shorting, kemudian wheeler dengan istilah pengurutan blok dan perluasan blok (block expantion) untuk kompresi dan perluasan operasinya (Fenwick, 1996).
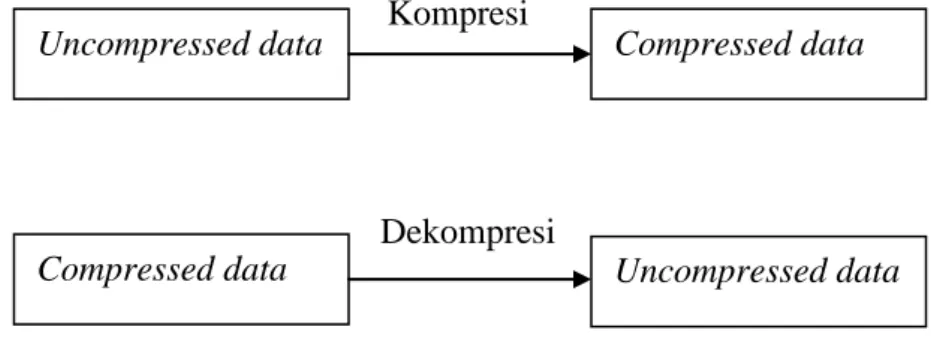
Proses kompresi dan dekompresi data dapat ditunjukkan melalui diagram blok seperti pada Gambar 2.1.
Gambar 2.1 Diagram Blok Proses Kompresi dan Dekompresi Data (Pu, 2006) 2.2. Penggolongan kompresi
Secara umum kompresi dibagi menjadi 2 golongan, yaitu : 2.2.1. Kompresi Lossy (Lossy Compression)
Algoritma kompresi lossy mengakibatkan perubahan data dibandingkan dengan sebelum dilakukan kompresi. Tipe ini cocok untuk kompresi file suara digital dan gambar digital. File suara dan gambar secara alamiah masih bisa digunakan walaupun tidak berada pada kondisi yang sama sebelum dilakukan kompresi. Contoh algoritma yang tergolong kompresi lossy yaitu, DCT, LPC, dan sebagainya. Konsep dasar kompresi lossy dapat dilihat pada Gambar 2.2 (Sayood, 2006). Lossy compression disebut juga dengan irreversible compression karena data asli tidak bisa dikembalikan dengan sempurna. Oleh karena itu sangat kecil kemungkinan dan bahkan tidak akan pernah bisa data yang dikompresi dengan teknik Lossy dapat dikembalikan seperti data sebelum dikompresi atau data aslinya. Contoh data yang cosok adalah gambar, suara dan video. Karena cara kerja sistem penglihatan dan pendengaran manusia yang terbatas, beberapa detail dapat dihilangkan, sehingga didapat data hasil kompresi yang seolah-olah sama dengan data asli. Contoh algoritma lossy pada kompresi data adalah Wavelet Compression, Fractal Compression, Wyner-Coding (WZC) dan lain-lain. Teknik kompresi lossy dapat digambarkan seperti gambar 2.3.
Gambar 2.2. Ilustrasi Kompresi Lossy (Sayood, 2006)
Uncompressed data Compressed data
Compressed data Uncompressed data
Kompresi
Kompresi ini tidak hanya menghapus atau mengurangi redudansi data, tetapi juga mengabaikan beberapa rincian kurang penting, yang memiliki rasio kompresi yang signifikan. Tetapi metode kompresi ini bisa menghilangkan beberapa informasi dari dokumen yang asli, yang menunjukkan bahwa file yang diunzziped memiliki perbedaan dengan file yang aslinya (Zhong & Wen, 2010).
Gambar 2.3 Teknik Kompresi Lossy (Pu, 2006)
2.2.2. Kompresi lossless (Lossless Compression)
Algoritma kompresi lossless menghasilkan data yang sama dengan data sebelum dilakukan kompresi. Kompresi ini cocok untuk basis data, dokumen atau spreadsheet. Pada lossless compression ini tidak diijinkan ada bit yang hilang dari data pada proses kompresi. Contoh algoritma yang tergolong kompresi lossless, yaitu Levenstein, Elias Gamma code, Fibonacci, dan sebagainya. Konsep dasar kompresi lossless dapat dilihat pada Gambar 2.4. (Sayood, 2006). Losseless compression disebut juga dengan reversible compression karena data asli bisa dikembalikan dengan sempurna. Akan tetapi rasio kompresinya sangat rendah, misalnya pada gambar seperti GIF dan PNG . Contoh data yang cocok adalah gambar medis, teks, program, spreadsheet dan lain-lain. Teknik ini digunakan jika data tersebut sangat penting, jadi tidak dimungkinkan untuk menghilangkan beberapa detail. Teknik kompresi lossless dapat digambarkan seperti gambar 2.5.
Metode kompresi lossless ini merupakan kombinasi data redudansi, yang mekanisme kerjanya adalah untuk menghapus atau mengurangi redudansi data, oleh karena itu tidak menyebabkan hilangnya data yang asli (Zhong & Wen, 2010).
Gambar 2.5 Teknik Kompresi Lossless (Pu, 2006) 2.2.3. Pengukuran Kinerja Kompresi Data
Pada suatu teknik yang digunakan dalam proses kompresi data terdapat beberapa faktor atau variabel yang biasa digunakan untuk mengukur kualitas dari suatu teknik kompresi data tersebut, yaitu :
1. Ratio of compression (Rc)
Ratio of compression (Rc) adalah perbandingan antara ukuran data sebelum dikompresi dengan ukuran data setelah dikompresi.
(Salomon & Motta, 2010)
Misalkan didapat sebuah nilai Ratio of Compression sebesar 1.30. Itu berarti besar data sebelum kompresi adalah 1.30 kali lipat dari besar data setelah dikompresi.
2. Compression ratio (Cr)
Compression ratio (Cr) adalah persentasi besar data yang telah dikompresi yang didapat dari hasil perbandingan antara ukuran data setelah dikompresi dengan ukuran data sebelum dikompresi.
(Salomon & Motta, 2010)
Misalkan didapat sebuah nilai Compression Ratio sebesar 76,47%. Itu berarti setelah dikompresi ukuran data adalah 76,4% dari data sebelum dikompresi.
3. Redundancy (Rd)
Redundancy (Rd) adalah kelebihan yang terdapat di dalam data sebelum dikompresi. Jadi setelah data dikompresi dapat dihitung Redundancy data yaitu persentasi dari hasil selisih antara ukuran data sebelum dikompresi dengan data setelah dikompresi.
(Salomon & Motta, 2010)
Misalkan didapat sebuah nilai Redundancy sebesar 23,53%. Itu berarti besarnya kelebihan data sebelum dikompresi adalah 23,53%.
4. Waktu Kompresi dan Dekompresi
Waktu kompresi dan dekompresi adalah waktu yang dibutuhkan oleh sebuah sistem untuk melakukan proses kompresi dan dekompresi dari mulai pembacaan data hingga proses encoding pada data tersebut. Semakin kecil waktu yang diperoleh maka semakin efisien metode yang digunakan dalam proses kompresi dan dekompresi itu.
2.3. Dekompresi
Dekompresi merupakan proses pengembalian data kebentuk semula. Proses dekompresi secara harfiah merupakan proses yang dilakukan bila data hasil kompresi ingin dikembalikan ke ukuran dan bentuknya semula. Dengan demikian, dekompresi adalah kebalikan dari kompresi data, yaitu dapat mengembalikan data kebentuk semula. Apabila data hasil dekompresi sama seperti data sebelum dikompresi, maka teknik kompresi yang digunakan adalah kompresi loseless. Sedangkan hasil dekompresi tidak sama dengan data sebelum dikompresi, maka teknik yang digunakan adalah kompresi lossy.
Tujuan dari dekompresi data adalah untuk mengembalikan data yang telah dikompresi ke bentuk semula. Karena data yang telah dikompresi tidak dapat dibaca tanpa dikembalikan ke dalam bentuk semula (Erdiansyah, 2014).
2.3.1 Algoritma
Defenisi Algoritma :
1. Algoritma adalah urutan langkah – langkah berhingga untuk memecahkan masalah logika atau matematika.
2. Algoritma adalah logika, metode dan tahapan (urutan) sistematis yang digunakan untuk memecahkan suatu permasalahan.
3. Algoritma adalah urutan langkah – langkah logis penyelesaian masalah yang disusun secara sistematis dan logis.
2.4 Algoritma Ternary Comma Code
Ternary Comma Kode adalah bilangan biner (basis 2) yang didasarkan pada dua nomor bit 0 dan 1. Demikian pula dengan terner bilangan (basis 3) dengan nomor bit 0, 1, dan 2. Setiap trit dapat dikodekan dalam dua bit, setiap dua bit terdiri dari empat nilai. Nilai yang terdapat didalam trit akan sejalan dengan nilai terner (0,1,2) jumlah sebuah sistem trit diwakili oleh dua bit dan memiliki simbol yang disebut comma c, comma c dapat dibangun dengan bilangan kode pada terner untuk bilangan bulat. kode comma berkaitan dengan representasi pada terner (Salomon, 2007).
Menurut Fenwick pada tahun 1996 daftar beberapa kode comma terner berkaitan dengan panjang kode didalam bit, dan cocok dengan aplikasi yang memiliki bilangan bulat. Kode comma c juga mudah untuk mengetahui penandaan akhir dari sebuah kode yang ada (Salomon, 2007).
Dengan cara decode dan downside. kode ini berdasarkan jumlah basis yang lebih besar. Dalam basis kode terdapat 15 digit, 15 digit tersebut membutuhkan empat bit dan comma pola 4 bit , setiap kode ujungnya harus berkaitan dengan 4 bit, dan fitur ini membuat kode seperti tidak efisien untuk basis yang jumlahnya besar maka salah satu ujung pada kode akan menjadi minimum terendah (Salomon, 2007).
2.5. Algoritma levenstein
Pada tahun 1968 Vladimir Levenstein mengembangkan kode Levenstein yang dapat digunakan untuk bilangan bulat non-negatif. Proses encoding dan decoding dilakukan dibeberapa tahap( Antoni, et al.2014).
Levenstein kode untuk nol adalah 0 tunggal. Untuk kode angka positif n, berikut adalah langkah encode-nya:
1. Set angka pertama dari C dengan 1. Letakkan kode-sejauh-ini pada string kosong. 2. Ambil nilai biner dari n tanpa angka 1 di awal dan tambahkan pada kode-sejauh-ini. 3. Nyatakan M sebagai jumlah bit yang ditambahkan pada tahap 2.
4. Jika M ≠ 0, tambahkan C dengan 1 dan lakukan langkah 2 kembali, tetapi dengan nilai M, bukan n.
5. Jika M = 0, tambahkan 1 diikuti dengan 0 pada C ke kode-sejauh-ini dan berhenti.
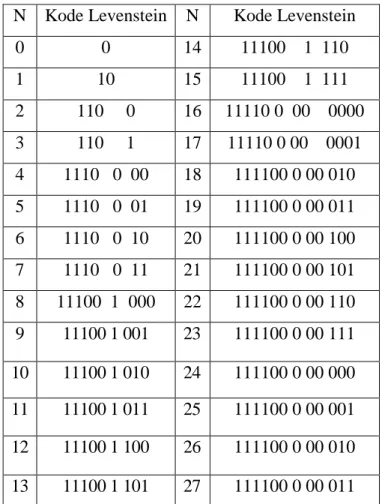
ambil 0101 dan tambahkan dibelakang 1. Tambahkan 1 pada kode, kemudian hitung jumlah karakter pada 0010, kita dapatkan 4. Tambahkan kembali 1, Ambil nilai 00, tambahkan di belakang penambahan tadi. Ulangi langkah tersebut sampai kita dapati nilai M = 0, kemudian tambahkan 10. Sehingga 21 pada kode Levenstein adalah 11110|0|00|0101 (Erdiansyah, 2014).
Tabel 2.1 Tabel Kode Levenstein (Salomon, 2007) N Kode Levenstein N Kode Levenstein
0 0 14 11100 1 110 1 10 15 11100 1 111 2 110 0 16 11110 0 00 0000 3 110 1 17 11110 0 00 0001 4 1110 0 00 18 111100 0 00 010 5 1110 0 01 19 111100 0 00 011 6 1110 0 10 20 111100 0 00 100 7 1110 0 11 21 111100 0 00 101 8 11100 1 000 22 111100 0 00 110 9 11100 1 001 23 111100 0 00 111 10 11100 1 010 24 111100 0 00 000 11 11100 1 011 25 111100 0 00 001 12 11100 1 100 26 111100 0 00 010 13 11100 1 101 27 111100 0 00 011
Decoding dilakukan sebagai berikut:
1. Set C dengan jumlah berturut-turut angka1 sebelum angka 0 yang pertama. 2. Jika C = 0, nilai di-decode adalah nol, berhenti.
3. Set N = 1, dan ulangi langkah 4 (C-1) kali.
4. Baca N bit, tambahkan 1, dan tetapkan hasil bitstring ke N (dengan demikian menghapus nilai sebelumnya dari N). String ditugaskan untuk N dalam iterasi terakhir adalah nilai decode-nya.
2.6. File Teks
Teks yang memuat banyak karakter didalamnya selalu menimbulkan masalah pada media penyimpanan dan kecepatan waktu pada saat transmisi data. File teks merupakan file yang berisi informasi-informasi dalam bentuk teks. Data yang berasal dari dokumen pengolah kata, angka yang digunakan dalam perhitungan, nama dan alamat dalam basis data merupakan contoh masukan data teks yang terdiri dari karakter, angka dan tanda baca (Pramilo, 2008).
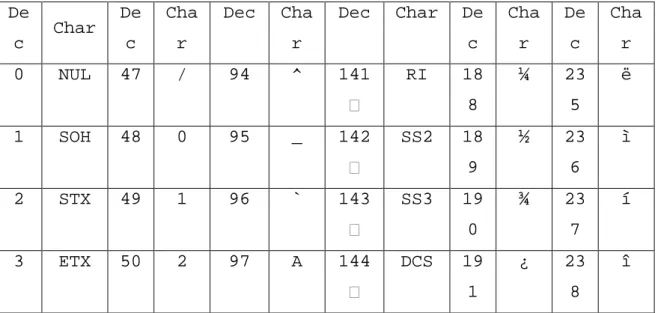
Masukan dan keluaran data teks direpresentasikan sebagai set karakter atau sistem kode yang dikenal oleh sistem komputer. Ada tiga macam set karakter yang umum digunakan untuk masukan dan keluaran pada komputer, yaitu ASCII, Unicode, dan EBCDIC. ASCII (American Standard Code for Information Interchange) merupakan suatu standar internasional dalam kode huruf dan simbol seperti Hex, dan Unicode tetapi ASCII bersifat lebih universal. ASCII digunakan oleh komputer dan alat komunikasi lain untuk menunjukkan teks. Kode ASCII memiliki komposisi bilangan biner sebanyak 8 bit, dimulai dari 00000000 dan 11111111. Total kombinasi yang dihasilkan sebanyak 256, dimulai dari kode 0 hingga 255 dalam sistem bilangan desimal. Unicode adalah suatu standar industri yang dirancang untuk mengizinkan teks dan simbol dari semua sistem tulisan di dunia untuk ditampilkan dan dimanipulasi secara konsisten oleh komputer. EBCDIC (Extended Binary Code Decimal Interchange Code) merupakan set karakter yang diciptakan oleh komputer merk IBM. EBCDIC terdiri dari 256 karakter yang masing-masing berukuran 8 bit (Erdiansyah, 2014). Tabel ASCII dapat dilihat pada Tabel 2.2.
Tabel 2.2 Tabel ASCII
De c Char De c Cha r Dec Cha r Dec Char De c Cha r De c Cha r 0 NUL 47 / 94 ^ 141 RI 18 8 ¼ 23 5 ë 1 SOH 48 0 95 _ 142 SS2 18 9 ½ 23 6 ì 2 STX 49 1 96 ` 143 SS3 19 0 ¾ 23 7 í 3 ETX 50 2 97 A 144 DCS 19 1 ¿ 23 8 î
4 EOT 51 3 98 B 145 PU1 19 2 À 23 9 ï 5 ENQ 52 4 99 C 146 PU2 19 3 Á 24 0 ð 6 ACK 53 5 100 D 147 STS 19 4 Â 24 1 ñ 7 BEL 54 6 101 E 148 CCH 19 5 Ã 24 2 ò 8 BS 55 7 102 F 149 MW 19 6 Ä 24 3 ó 9 TAB 56 8 103 G 150 SPA 19 7 Å 24 4 ô 10 LF 57 9 104 H 151 EPA 19 8 Æ 24 5 õ 11 VT 58 : 105 I 152 SOS 19 9 Ç 24 6 ö 12 FF 59 ; 106 J 153 SGCI 20 0 È 24 7 ÷ 13 CR 60 < 107 K 154 SCI 20 1 É 24 8 ø 14 SO 61 = 108 L 155 CSI 20 2 Ê 24 9 ù 15 SI 62 > 109 M 156 ST 20 3 Ë 25 0 ú 16 DLE 63 ? 110 N 157 OSC 20 4 Ì 25 1 û 17 DC1 64 @ 111 O 158 PM 20 5 Í 25 2 ü 18 DC2 65 A 112 P 159 APC 20 6 Î 25 3 ý 19 DC3 66 B 113 Q 160 Spac e 20 7 Ï 25 4 þ 20 DC4 67 C 114 R 161 ¡ 20 Ð 25 ÿ
8 5 21 NAK 68 D 115 S 162 ¢ 20 9 Ñ 22 SYN 69 E 116 T 163 £ 21 0 Ò 23 EBT 70 F 117 U 164 ¤ 21 1 Ó 24 CAN 71 G 118 V 165 ¥ 21 2 Ô 25 EM 72 H 119 W 166 ¦ 21 3 Õ 26 SUB 73 I 120 X 167 § 21 4 Ö 27 ESC 74 J 121 Y 168 ¨ 21 5 × 28 FS 75 K 122 Z 169 © 21 6 Ø 29 GS 76 L 123 { 170 ª 21 7 Ù 30 RS 77 M 124 | 171 « 21 8 Ú 31 US 78 N 125 } 172 ¬ 21 9 Û 32 SPAC E 79 O 126 ~ 173 - 22 0 Ü 33 ! 80 P 127 174 ® 22 1 Ý 34 " 81 Q 128 PAD 175 ¯ 22 2 Þ 35 # 82 R 129 HOP 176 ° 22 3 ß 36 $ 83 S 130 BPH 177 ± 22 4 à
37 % 84 T 131 NBH 178 ² 22 5 á 38 & 85 U 132 IND 179 ³ 22 6 â 39 ' 86 V 133 NEL 180 ´ 22 7 ã 40 ( 87 W 134 SSA 181 µ 22 8 ä 41 ) 88 X 135 ESA 182 ¶ 22 9 å 42 * 89 Y 136 HTS 183 · 23 0 æ 43 + 90 Z 137 HTJ 184 ¸ 23 1 ç 44 , 91 [ 138 VTS 185 ¹ 23 2 è 45 - 92 \ 139 PLD 186 º 23 3 é 46 . 93 ] 140 PLU 187 » 23 4 ê
2.7 Black Box Testing
Black-Box Testing merupakan pengujian yang berfokus pada spesifikasi fungsional dari perangkat lunak, tester dapat mendefinisikan kumpulan kondisi input dan melakukan pengetesan pada spesifikasi fungsional program (Pressman, 2012). Sistem (atau bagian) menanggapi ranggsangan stimulan tertantu (peristiwa) dengan menerapkan seperangkat aturan transmisi yang memetakan perangsangan stimulan ke respons Black Box menentukan perilaku sistem atau bagian sistem. Cara ini melihat bagaiman sistem merespon user dalam menerima inputan yang berbeda (Pressman, 2012).