Market and Business Drivers for Big Data Analytics
Separating the Big Data Reality from Hype
Big data are high-volume, high-velocity, and high-variety information assets that require cost-effective and innovative forms of information processing for enhanced insight and decision-making.1. Accessed from,http://blogs.gartner.com/doug-laney/deja-vvvue-others-claiming-gartners-volume-velocity-variety-construct-for-big-data/.
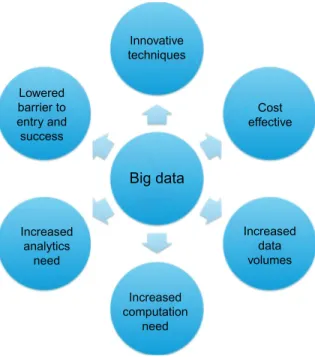
Understanding the Business Drivers
Rapid acceleration of data growth: Just 1 year later, the 2012 IDC Digital Universe study ("The Digital Universe in 2020") postulated. 4The Digital Universe in 2020, http://www.emc.com/collateral/analyst-reports/idc-the-digital-universe-in-2020.pdf.
Lowering the Barrier to Entry
As we will see, the facets of business intelligence and analytics technology have evolved to a point where a broad spectrum of companies can deploy capabilities that were historically limited to the largest companies with similarly large budgets. Applications that benefit from massive parallelism, developed by specialized developers skilled in high-performance computing, performance optimization and code tuning.
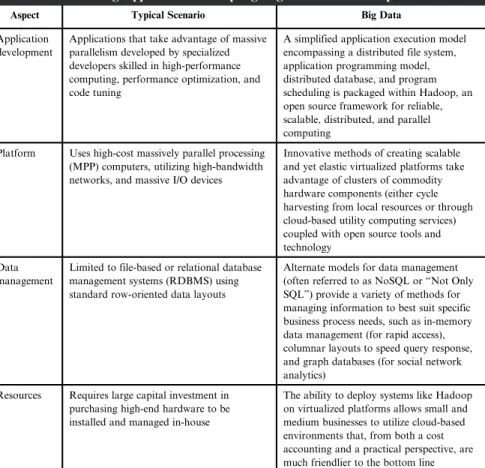
Considerations
How do you plan to fund the continued management and maintenance of the big data environment? In Chapter 2, we will begin to define the criteria for answering these questions as we explore the types of business problems that lend themselves to big data solutions.
Thought Exercises
There can be a wide range of users consuming the results of the spectrum of big data analytics applications. We followed the discussion of a strategic plan by reviewing some of the technical aspects of big data.
Business Problems Suited to Big Data Analytics
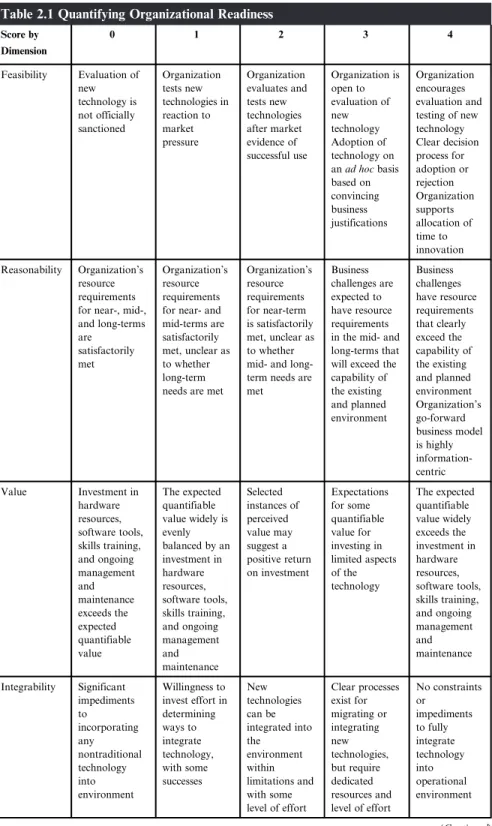
Validating (Against) the Hype: Organizational Fitness
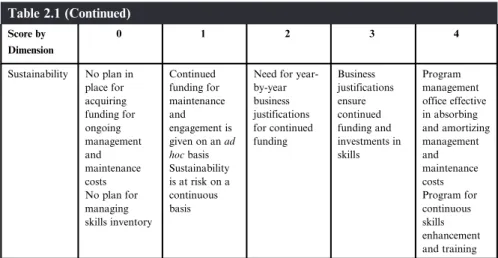
And as we speculated in Chapter 1, there are a number of factors to consider before making a decision to adopt that technology. Each of these variables is mostly somewhat subjective, but there are ways to introduce a degree of objectivity, especially when considering the value of big data.
The Promotion of the Value of Big Data
The expected quantifiable value is broadly balanced by an investment in hardware resources, software tools, skills training and ongoing management and maintenance. The expected quantifiable value far exceeds the investment in hardware resources, software tools, skills training and ongoing management and maintenance.
Big Data Use Cases
Enumeration functions are applied to large bodies of data that can be segmented and distributed among a set of computing and storage resources, such as document indexing, concept filtering, and aggregation (counts and sums). Parallel threadable scanning functions such as sorting, data transformations, semantic text analysis, pattern recognition, and search.
Characteristics of Big Data Applications
Benefits of data parallelization: Because of the reduced data dependencies, the application's runtime can be improved by task- or thread-level parallelization applied to independent data segments. These criteria can be used to determine the extent to which business problems are suitable for big data technology.
Perception and Quantification of Value
So what, how does this relate to business problems whose solutions are suitable for big data analytics applications. A good example: ETL processing is hampered by data throttling and computation throttling, can involve large data volumes, can consume a variety of different types of data sets, and can benefit from data parallelization.
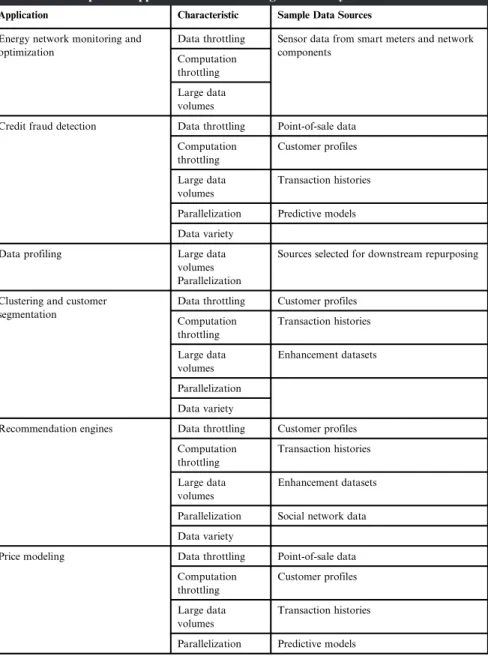
Forward Thinking About Value
Thought Exercises
Clearly defining performance expectations for big data reporting and analytics means linking business value to the business use of the technology. This allows a deterioration of the usability of the data and affects the synchronization and consistency of data and processes.
Achieving Organizational Alignment for
Two Key Questions
The first question is intended to channel the energy and effort of test driving big data technologies in the context of one or more real business problems to determine whether those technologies add value. But more importantly, assuming the technology is valuable, the goal of the first question is to devise a communication strategy to share the message with the right people within the organization to identify a champion, secure business sponsorship and bidirectional establish commitment. keep the business sponsors educated and aware of progress.
The Historical Perspective to Reporting and Analytics
These system expectations are mutually exclusive: optimizing for one can seriously affect the performance of the other. Maintaining optimal response time for transaction processing systems meant downgrading the priority of reporting and analysis tasks.
The Culture Clash Challenge
The result was a data warehouse model – a separate system designed to support querying and reporting on collected, consolidated and aggregated data in a way that does not affect the operation of transaction processing systems. So, while data warehouses are good for streaming data into spreadsheets, they are limited when it comes to undirected data discovery – creating analyst demand for “raw data access” in a big data environment instead of routing requests through business intelligence. the team assigned to query the data warehouse.
Considering Aspects of Adopting Big Data Technology
Data Purpose: Most data instances are created for specific purposes, but big data applications seek to reuse data for analysis. Size and duration: The desire to acquire and use massive data sets has direct implications for the "pure" aspects of data management.
Involving the Right Decision Makers
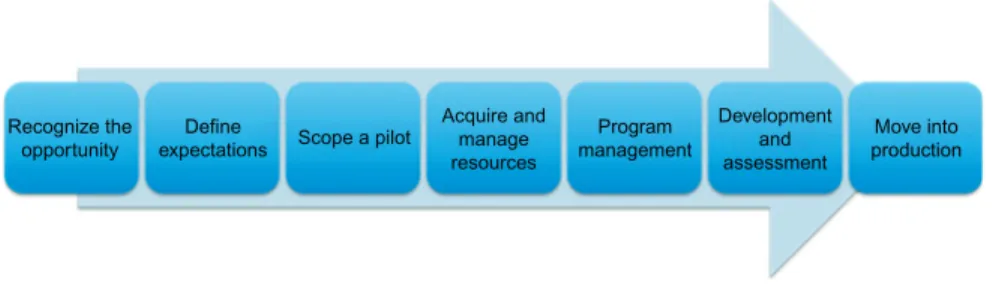
Recognize the opportunity: Use the criteria in Chapter 2 to identify business challenges that could benefit most from adopting one or more big data techniques. Program Management: Create a program plan for the pilot phase as well as anticipate tasks for migration to production.
Roles of Organizational Alignment
Business Analyst: This is the person who engages business process owners and solicits their needs and expectations. This process identifies some of the key quantifiable measures for evaluating the business benefits of the new technology, as well as outlines the technical requirements for any pilot project.
Thought Exercises
Asking for clear business requirements and specifying supporting success criteria and measures provides a degree of confidence that testing new technology such as big data analytics is not merely an intellectual exercise, but rather a repeatable process of bringing new ideas into inject into the company. The result is that pilot projects that are prematurely moved to "production" are effectively just point solutions that rely on islands of data that are neither scalable from a performance perspective nor fit into the enterprise from an architectural perspective.
Deciding What, How, and When Big Data Technologies
The Strategic Plan for Technology Adoption
Standardize Practices for Soliciting Business User Expectations 31
Use this to initially document business expectations as a prelude to the next phase where success criteria are defined. This method will solidify success criteria, benefiting both business users and technologists.

Prepare the Data Environment for Massive Scalability
Computation: Many statistical analysis algorithms have computational demands that are proportional to orders of magnitude of the data provided, and in exponential algorithms the demand increases very quickly. A small sandbox may not exhibit the same computational needs as a larger environment, so understand the need for computational performance and how to scale.
Promote Data Reuse
Considerations to be addressed include the use of high-speed networks; enabling high-performance data integration tools such as data replication, change data capture, compression, and alternate data layouts for fast data loading and access; and enabling comprehensive security systems. An organization's information and business strategy should include detailed plans for the availability and quality of large-scale data management as part of the enterprise's information architecture.
Institute Proper Levels of Oversight and Governance
Provide a Governed Process for Mainstreaming Technology
Considerations for Enterprise Integration
Instead, taking these steps will help ensure that design and development are fully integrated into the organization's project management, information technology management, and information governance frameworks. Using this approach helps ensure that new applications can be more easily integrated into existing business intelligence, reporting and analytics infrastructure and deliver maximum value to a broad range of users across the organization.
Thought Exercises
This is especially true when there is limited visibility into the reliability of the data sources. Of the three most valuable big data capabilities within your organization, which are most suitable for a graph analytics approach.
Data Governance for Big Data Analytics
The Evolution of Data Governance
Data governance describes the processes for defining the company's data policies, describes processes for operationalizing compliance with those policies, along with the organizational structures that include data governance councils and data stewards established to monitor and hopefully ensure compliance with those data policies. When focused internally, data governance not only enables some degree of control over data created and shared within an organization, it empowers data managers to take corrective action, either through communication with the original data owners or through direct data intervention (ie. "correction of bad data") when necessary.
Big Data and Data Governance
Remedy: Have data stewards take appropriate action when alerted to the existence of those issues. Currency, which checks the "freshness" of the data and whether the values are up to date or not.
The Difference with Big Datasets
When datasets are created internally and a downstream user recognizes a potential error, that problem can be communicated to the owners of the original system. The owners then have the opportunity to determine the root cause of the problems and then correct the processes that led to the errors.
Big Data Oversight: Five Key Concepts
With each successive reuse, data consumers must again reinterpret what the data means. Use data in its "unacceptable" state and modulate your users' expectations about the validation point.
Considerations
However, if the incorrect values are an obstacle to the analysis and the changes do not significantly change the data from their original form, except in a positive and expected way, data enhancement and enrichment may be a reasonable alternative. Address locations may be incomplete or even incorrect (eg zip code may be incorrect).
Thought Exercises
One misconception about the big data phenomenon is the expectation of easily achievable, scalable high performance due to automated task parallelism. The byproduct of the brainstorming sessions is a value proposition that suggests the potential benefits of implementing big data applications.
Introduction to High-Performance Appliances for
Use Cases
Social media analytics applications that search through streams of social media channels looking for positive or negative sentiments that are correlated with the behavior of a collective of individuals. Website recommendation engines that use large sets of historical transaction patterns, combined with customer profiles, to identify suggested additional items to be offered to the customer as potential additional purchases.
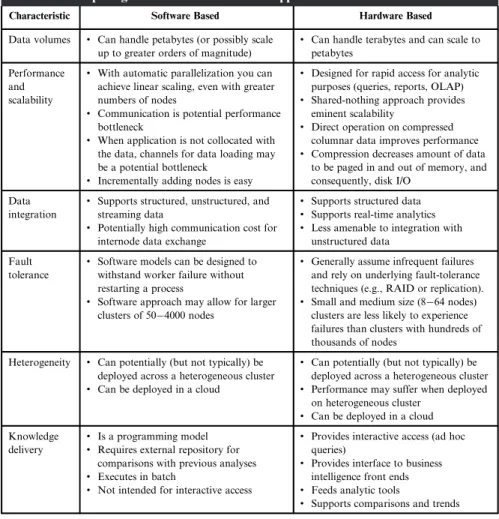
Storage Considerations: Infrastructure Bedrock for the
This points to the need for different analytical models that can be integrated with traditional relational data models. Integrability, which measures how well the storage environment can be integrated into the production environment.
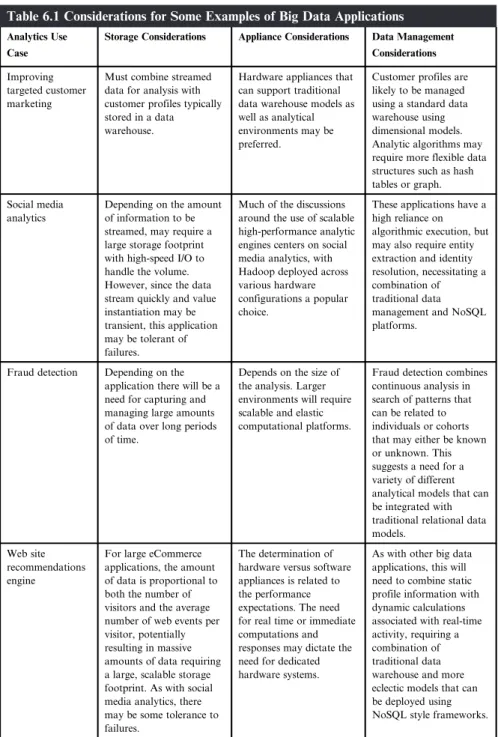
Big Data Appliances: Hardware and Software Tuned for
Fault tolerance, imbuing the storage environment with the ability to recover from intermittent failures. Often the storage framework involves a software layer for managing a collection of storage resources and providing many of these capabilities.
Architectural Choices
Considering Performance Characteristics
Vendors can round out the offering by providing application development tools, analytics capabilities, as well as enabling direct user setup with alternative data layouts for improved performance.
Row- Versus Column-Oriented Data Layouts and
Row-oriented layouts require reading the entire record to access the required attributes, reading significantly more data than necessary to fulfill the request. Next, row-oriented data formats will not allow the types of joins or aggregations typical of analytical queries to be performed with the expected level of performance (Figure 6.1).
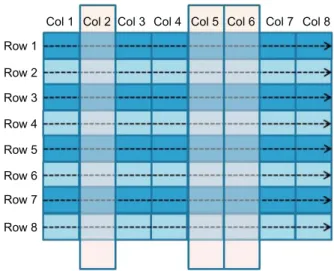
Considering Platform Alternatives
Next, examine how each of the architectures addresses the performance needs of different types of applications. In a row-based arrangement, all data values in each row must be stored together, and inherent dependencies prevent parallel loading.
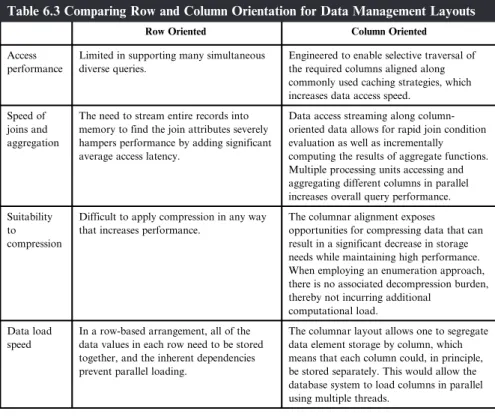
Thought Exercises
This also allows you to adapt the development of the platform to the business application development needs. The document representation embeds the model so that the meaning of the document values can be inferred by the application.
Big Data Tools and Techniques
Understanding Big Data Storage
Storage, which provides data persistence: the place where data sets are loaded and from where the data is loaded into memory for processing. Because single-node computers have limited capacity, they cannot easily process massive amounts of data.
A General Overview of High-Performance Architecture
HDFS
If a data node's heartbeat is not heard by the name node, the data node is considered to have failed and is no longer available. Rebalancing: It is a process of automatically migrating blocks of data from one data node to another when there is free space, when there is a greater demand for the data and it can improve performance (such as moving from a traditional disk drive to a solid-state drive that is much faster or can accommodate increased numbers of concurrent access), or a greater need for replication in response to more frequent node failures.
MapReduce and YARN
These concepts relate to the specific internal protocols and services that HDFS uses to enable a large-scale data management file system that can run on commodity hardware components. Finally, the YARN approach allows applications to be more aware of the distribution of data across the resource topology within a cluster.
Expanding the Big Data Application Ecosystem
Delegating this responsibility to the application environment allows greater flexibility in resource allocation and is more efficient in scheduling to improve node utilization. Our examination of a prototypical big data platform built using Hadoop continues by looking at a number of additional components that might typically be considered part of an ecosystem.
Zookeeper
There is a need to expand the ecosystem to incorporate a number of additional capabilities, such as configuration management, data organization, application development and optimization, as well as additional capabilities to support analytical processing.
HBase
As discussed in Chapter 6, data stored in a columnar layout is susceptible to compression, which increases the amount of data that can be represented while reducing the actual storage footprint. Because it can be used to organize datasets, along with the performance provided by the column orientation aspects, HBase is a reasonable alternative as a persistent storage paradigm when running MapReduce applications.
Hive
Hadoop, it enables native access to the MapReduce model, allowing programmers to develop custom Map and Reduce functions that can be integrated directly into HiveQL queries. Hive provides scalability and extensibility for batch-style queries for reporting over large datasets that typically scale while relying on the fault-tolerant aspects of the underlying Hadoop execution model.
Pig
Mahout
Frequent pattern mining used for market basket analysis, comparative health analysis and other correlation patterns within large data sets. The availability of implemented libraries for these types of analysis frees the development team to consider the types of problems to be analyzed and, more specifically, what types of analytical models can be applied to find the best answers.
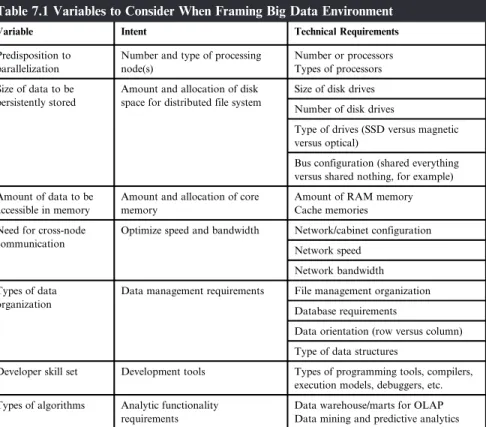
Considerations
Thought Exercises
Acquiring this knowledge will help to understand the simplicity of the model and how it can be used effectively. Alternatively, propose specific value improvements to be achieved through the use of the big data analysis activity, together with improvement targets and use these as the success criteria.
Developing Big Data Applications
Parallelism
Part of the analysis involves looking for certain types of patterns among collections of call detail records among household members for households that fit the target model of the marketing campaign. The collections of call detail records can be "clustered" into smaller sets and analyzed in parallel for intermediate results, which can later be aggregated to provide the desired insight.
The Myth of Simple Scalability
The Application Development Framework
Typically, a big data platform will consist of a collection (or a "pool") of processing nodes; optimal performance can be achieved when all processing nodes are kept busy, and this means maintaining a healthy distribution of tasks for idle nodes within the cluster. Any large application to be developed must be designed in this context, and this is where the programming model comes in.
The MapReduce Programming Model
These data items are logically organized in a way that allows the MapReduce execution model to assign tasks that can be executed in parallel. Employee processing nodes output their final results to output files, which can be used as input to other business processes.
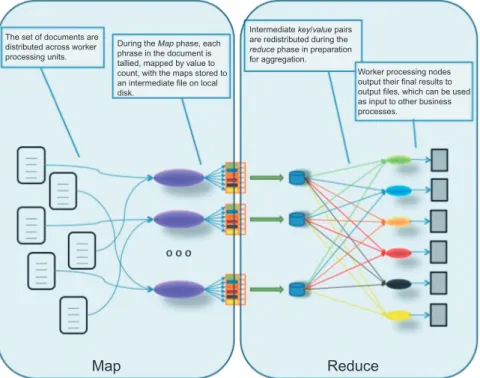
A Simple Example
More on Map Reduce
If the data is already distributed (such as stored in a distributed file system), this is not necessary and only the key assignment is critical. At the same time, the Map and Reduce steps show where most of the execution parallelism comes in.
Other Big Data Development Frameworks
MapReduce resembles a functional programming model, and MapReduce applications can be developed using programming languages with library support for the execution model. This means that we need the execution model to automatically transform the "logical" parallelism into real parallel tasks that can be executed as individual threads.
The Execution Model
This basic approach has been adapted in various ways by runtime model developers to support the respective programming model. The devil is in the details and it is up to anyone considering using a big data development framework like Hadoop and MapReduce to be properly trained in awareness of the various aspects of parallel and distributed programming and how they can affect the performance.
Thought Exercises
Answering that question requires a better understanding of some of the complexities of graph analysis problems and topologies. This largely surrounds the organization and sizing of hardware and software aspects of the platform.
NoSQL Data Management for Big Data
What is NoSQL?
However, the availability of a high-performance, elastic distributed data environment allows creative algorithms to exploit different ways of managing data in different ways. Indeed, some algorithms will not be able to consume data in traditional RDBMS systems and will be heavily dependent on alternative means of data management.
Key Value Stores
A critical characteristic of a key-value store is key uniqueness—to find the values you're looking for, you must use the correct key. For example, you might want to associate a list of attributes with a single key, which might suggest that the value stored with the key is another key value storage object.

Document Stores
Alternatively, the keys can be hashed using a hash function that maps the key to a specific location (sometimes a . "bucket") in the table. One is that the model will not inherently provide any kind of traditional database capabilities (such as atomicity of transactions, or consistency when multiple transactions are executed concurrently)—those capabilities must be provided by the application itself.
Tabular Stores
As an example, in Figure 9.1 we have some examples of documents stored in connection with the names of specific dealer locations. For example, using the example in Figure 9.1, one could perform a FIND (MallLocation: "Westfield Wheaton") that would retrieve all documents associated with the retail stores in that mall.
Object Data Stores
Timestamping can be used to maintain history - each time the content changes, new column associations can be created with the timestamp of when the content was downloaded.
Graph Databases
Considerations
Thought Exercises
We initially discussed the relevant roles in Chapter 3, but upon review, the roles of the members of the big data use group can be organized into different categories. This will help to reduce and control the ongoing costs of development, operation and ongoing management and maintenance of the big data platform.
Using Graph Analytics for Big Data
What Is Graph Analytics?
This motivates an understanding of its utility and flexibility for discovery-style analysis regarding specific types of business problems, how common those types of problems are, and why they abstract nicely to the graph model. In addition, we will discuss the challenges of trying to perform graph analysis on conventional hardware and consider aspects of specialty platforms that can help achieve the right level of scalability and performance.
The Simplicity of the Graph Model
Representation as Triples
A collection of these triples is called a semantic database, and this type of database can record additional properties of each triple relationship as attributes of the triple. Almost any type of entity and relationship can be represented in a graph model, which means two important things: the process of adding new entities and relationships is not hindered when new data sets need to be included, with new types of entities and relationships. connections need to be included, and the model is particularly suitable for types of discovery analytics that look for new patterns embedded in the graph that are of critical business importance.
Graphs and Network Organization
Collaborative communities: Isolation of groups of individuals who share similar interests, such as groups of healthcare professionals working in the same specialty area, buyers with similar product tastes, or individuals with a precise set of employment skills. Influence modeling: Looking for entities that hold positions of influence in a network for periodic periods, such as computer nodes that have been hijacked and put to work as proxies for distributed denial-of-service attacks or for new cybersecurity threats, or individuals recognized as authorities within a particular territory.
Choosing Graph Analytics
Distance modeling: Analyze the distances between sets of entities, such as looking for strong correlations between the occurrences of sets of statistically improbable phrases among large sets of search engine queries, or the amount of effort required to spread a message between a set of different communities . As a result, it is less suitable for pattern searches of relational database systems, such as a data warehouse or data mart, and is better suited for a more dynamic representation such as the graph model.
Graph Analytics Use Cases
Adaptive Semantics: A business problem exhibits a dependency on contextual semantics that can be attributed to connections and relevant relationships. Ad hoc nature of analysis: Ad hoc queries must be performed to track inference.
Graph Analytics Algorithms and Solution Approaches
Technical Complexity of Analyzing Graphs
The advantage of having hubs is that it generally shortens the distances between collections of nodes in the graph. However, while one of the advantages of big data platforms is the expectation of distribution of data and computations, the existence of hubs makes it difficult to partition the graph between different processing units due to the many connections.
Features of a Graph Analytics Platform
Graph representation using RDF allows the use of the SPARQL query language standard (see http://www.w3.org/TR/rdf-sparql-query/) for executing queries against a database-based management environment. triple. Finally, while all of the following are reasonable expectations for any big data platform, these criteria are particularly important for.
Considerations: Dedicated Appliances for Graph Analytics
Software approaches may be satisfactory for smaller graph analysis problems, but as data volumes and network complexity grow, the most effective means of return on investment may necessitate moving to a dedicated graph analysis appliance.
Thought Exercises
Developing the Big Data Roadmap
Introduction
The purpose of this book is to influence rational thinking when it comes to big data and big data analysis. Not every business problem is a big data problem, and not every big data solution is suitable for all organizations.
Brainstorm: Assess the Need and Value of Big Data
The purpose of this final chapter is to bring together the ideas presented and motivate the development of a roadmap for the evaluation and potential implementation of big data in the organization. The purpose of these sessions is to determine whether there is value in testing big data compared to the resource costs.
Organizational Buy-In
Attendees: First determine the roles to invite to the meeting and identify the specific people to request to attend, then send the invitations. Input: Identify the information to be collected and then disseminated prior to the brainstorming sessions, collect this data and release it to the participants.
Build the Team
The technical evangelist, who understands the computer science aspects of big data platforms, is aware of the details of the architecture behind big data technology and is familiar with the business domains. The technical evangelist must combine in-depth knowledge of technology in general and big data techniques with good communication and presentation skills, and have in-depth contextual business knowledge and fundamental knowledge of the business.
Scoping and Piloting a Proof of Concept
Ensure that the appropriate tests are developed and that there are processes for running the tests and sharing the results. Other questions remain to be answered, such as whether production implementation is feasible, and how to go about the process of developing a reasonable plan for migration to production, or whether the technology will scale from a grassroots perspective. of users as well as from the perspective of the user base and others. their anticipated performance requirements.
Technology Evaluation and Preliminary Selection
For each area of the technology, list the most important expectations and requirements for design, development and implementation. For each area of technology, specify the limitations, restrictions, and enterprise technology standards that any selected vendor's product must adhere to.
Application Development, Testing, Implementation Process . 114
One of the challenges in developing big data applications is “scalability” – how do you create a test environment and a production environment that can accommodate both data volumes and expectations for computational scalability. Computational complexity: What are the types of computations that need to be performed, what are the scaling factors of the algorithms in relation to the computation required, and how does this compare to the volume of data.
Big Data Analytics Integration Plan
Storage capacity configurations: How much data should be available in storage nodes at the same time. How should business processes be adapted to make optimal use of big data analyses?
Management and Maintenance
Reviewing the answers to these questions will guide the technical teams to properly utilize big data within the business context.
Assessment
Summary and Considerations
Thought Exercises