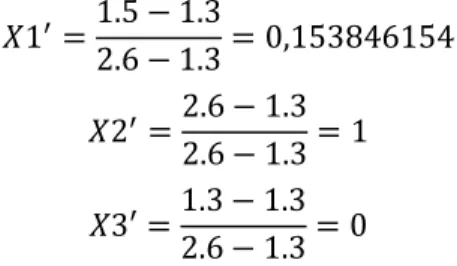Penelitian ini bertujuan untuk mengoptimalkan pendeteksian anomali menggunakan Algoritma Novel Genetic K-Means Clustering (GKMC). Permasalahan dalam penelitian ini adalah bagaimana mengoptimalkan deteksi anomali dalam pencarian geokimia seperti endapan mineral. Hasil penelitian dalam pencarian penyimpangan atau anomali dengan menggunakan metode GKMC dan TKMC terdapat perbedaan yang signifikan.
Penelitian ini bertujuan untuk meninjau laju pertumbuhan angkutan laut di setiap provinsi di Indonesia. Pada penelitian ini digunakan metode clustering K-Means karena tidak dipengaruhi oleh urutan objek yang digunakan dan juga pusat cluster ditentukan secara acak dari salah satu objek pada awal perhitungan. Penelitian ini menggunakan metode clustering algoritma K-Means dan analisis diskriminan dengan parameter tingkat pendidikan, angka kelahiran kasar, angka kematian dan rata-rata jumlah anggota keluarga.
Penelitian ini menggunakan metode algoritma genetika dengan parameter kendaraan, porter dan waktu dalam proses perencanaannya. Penelitian ini menggunakan metode clustering Algoritma K-Means dengan parameter sesuai jumlah mata pelajaran ujian nasional. Penelitian ini menggunakan metode algoritma K-Means, Sum of Square Error (SSE) dan Davies Boulding Index (DBI).
Berdasarkan tinjauan literatur, dilakukan pemetaan tinjauan literatur untuk mendukung penelitian ini seperti terlihat pada Gambar 2.1 di bawah ini.
Euclidean Distance
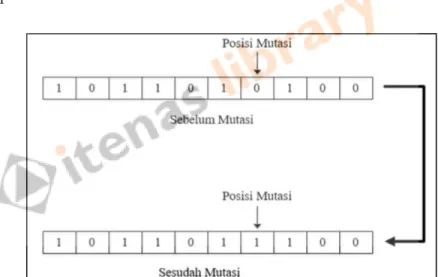
Institut Teknologi Nasional | 17 Crossing over merupakan salah satu operator dalam algoritma genetika yang bertujuan untuk melahirkan kromosom baru yang mewarisi sifat-sifat induknya seperti pada proses reproduksi yang terjadi pada kehidupan alami. Karena populasi pada algoritma genetika dimodelkan dengan ukuran yang tetap, maka kromosom keturunannya harus dapat dimasukkan ke dalam populasi baru (Suhartono, 2015). Pada representasi kromosom dengan kode biner, operasi mutasi dilakukan dengan mudah, yaitu dengan mengubah nilai gen pada operasi tertentu.
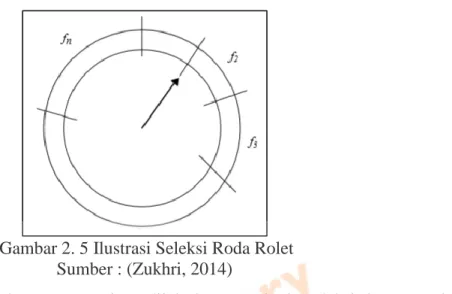
Artinya apabila suatu gen dipilih secara acak untuk dilakukan operasi mutasi, maka nilai gen tersebut akan berubah dari nol menjadi satu atau dari satu menjadi nol (Soehartono, 2015), seperti pada Gambar 2.5 di bawah ini. Algoritma K-Means merupakan suatu metode melakukan analisis cluster tanpa pengawasan atau non-hierarki, yaitu membagi data ke dalam kelompok-kelompok berdasarkan karakteristiknya sehingga jika ada data yang memiliki karakteristik yang sama, maka dikelompokkan menjadi satu cluster (Maguitman, 2010). Singkatnya, penggunaan algoritma K-Means saat melakukan proses clustering bergantung pada data yang ada dan kesimpulan yang ingin diambil.
Parameter yang harus dimasukkan ketika menggunakan algoritma ini adalah nilai K atau jumlah cluster yang biasanya ditentukan berdasarkan keinginan. Algoritma K-Means pertama-tama mengambil sebagian kecil dari jumlah komponen dari populasi untuk dijadikan pusat clustering awal. K-Means kemudian menguji setiap komponen dalam populasi data dan menilai komponen tersebut di salah satu pusat cluster yang ditentukan berdasarkan jarak minimum antara komponen dan setiap pusat cluster.
Posisi pusat cluster dihitung ulang hingga seluruh komponen data pada setiap cluster terklasifikasi dan akhirnya terbentuk posisi cluster baru. Institut Teknologi Nasional | 19 Untuk itu digunakan algoritma K-Means yang berisi proses dasar sebagai berikut. Hitung jarak setiap data ke pusat cluster dengan menggunakan metode Euclidean distance seperti pada persamaan 2.4 pada metode Euclidean distance.
Ulangi langkah 2 hingga 4 hingga tidak ada lagi data yang berpindah ke cluster lain.
Metode Elbow
Institut Teknologi Nasional | 20 Hasil persentase nilai masing-masing kelompok yang berbeda dapat ditunjukkan dengan bantuan grafik, jika nilai kelompok pertama dengan nilai kelompok kedua memberikan sudut pada grafik atau mengalami penurunan nilai yang paling besar, maka itu nilai cluster yang terbaik (Omran, Engelbrecht, & Salman, 2007) Dalam proses perbandingan dapat dihitung dengan menggunakan SSE (Sum of Square Error) masing-masing cluster sehingga semakin tinggi nilai K atau jumlah cluster maka semakin kecil nilai SSE. Setelah hal tersebut dilakukan maka ada suatu nilai atau bilangan k yang mengalami penurunan paling besar dan nilai k yang mengalami penurunan paling besar secara perlahan akan mulai stabil.
Metode Silhouette Coefficient
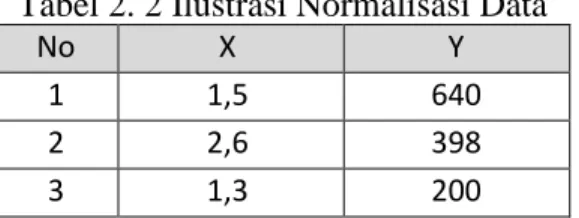
- Normalisasi Data
- Elbow
- Silhouette Coefficient
- Davies-Bouldin Index
- Algoritma Genetika
- Algoritma K-Means
Hitung jarak rata-rata antara data dengan data lain dalam suatu cluster seperti pada persamaan 2.8 dengan memisahkan i dari seluruh data lain dalam suatu cluster. Hitung jarak rata-rata data ini ke seluruh data di cluster lain seperti pada persamaan 2.9 di bawah. Untuk memperkirakan nilai Koefisien Silhouette dapat dilihat pada Tabel 2.1 yang dibuat oleh Kaufman dan Rousseeuw di bawah ini (Azuri et al., 2016).
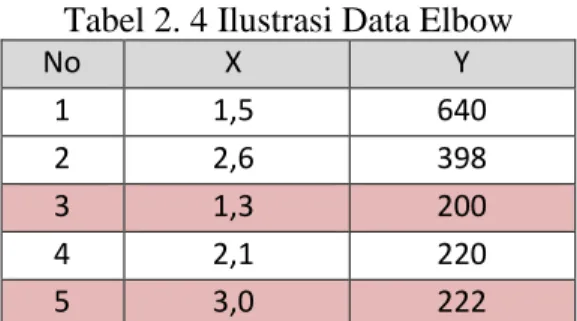
Seperti pada ilustrasi pada Tabel 2.4, mereka akan dikelompokkan menjadi dua menggunakan proses pengelompokan yang menentukan jarak lebih dekat ke pusat cluster yang ditentukan. Pusat cluster ditentukan secara acak seperti pada Tabel 2.4. Pusat cluster yang dipilih adalah data nomor 3 yang mewakili pusat cluster 1 dan data nomor 5 yang mewakili pusat cluster 2. Setelah proses pengelompokan dengan metode Elbow, proses selanjutnya adalah mencari nilai yang digunakan pada proses Sum of Square Error (SSE) pada Persamaan 2.7 sebagai berikut.
Mirip dengan proses Elbow, proses koefisien siluet terlebih dahulu mengelompokkan data seperti pada Tabel 2.5, kemudian melakukan proses penghitungan jarak rata-rata antara data tersebut dengan data lain dalam cluster seperti pada Persamaan 2.8. Proses perhitungan jarak rata-rata antara data nomor 1 dengan data lainnya pada Tabel 2.4 menghasilkan nilai sebesar 801.3372. Institut Teknologi Nasional | 28 Setelah menghitung rata-rata jarak antara data dengan data lain dalam suatu cluster, hitunglah rata-rata jarak antara data dengan data lain dalam cluster yang berbeda seperti pada Persamaan 2.9 sebagai berikut.
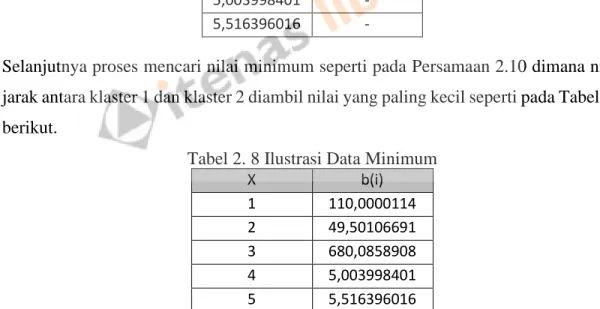
Kemudian proses mencari nilai minimumnya seperti pada persamaan 2.10 dimana nilai jarak antara cluster 1 dan cluster 2 diambil nilai terkecilnya seperti pada Tabel 28 dibawah ini. Untuk nilai keseluruhan, data hasil perhitungan koefisien siluet lainnya dirata-ratakan seperti pada Tabel 2.9 di bawah ini. Data koefisien siluet dikelompokkan terlebih dahulu seperti pada Tabel 2.5 kemudian dihitung jarak datanya ke pusat cluster seperti pada Tabel 10 di bawah ini.
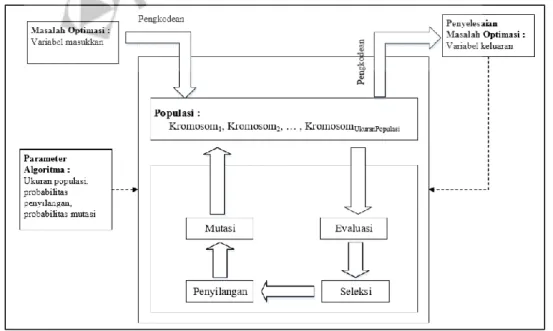
Proses selanjutnya adalah menghitung jumlah kuadrat dalam cluster untuk mencari nilai kohesi pada cluster i seperti pada persamaan 2.12 di bawah ini. Setelah diperoleh jumlah kuadrat dalam grup dan jumlah kuadrat antar nilai grup, selanjutnya lakukan perhitungan rasio seperti pada persamaan 2.14 di bawah ini. Terdapat beberapa input dalam proses Algoritma Genetika antara lain nilai probabilitas crossover, nilai probabilitas mutasi, jumlah individu, jumlah iterasi yang dilakukan, dan data yang digunakan dalam proses penentuan pusat cluster seperti tergambar pada tabel 2.11 berikut.
Nilai acak digunakan untuk membandingkan dengan nilai kumulatif, dimana dipilih nilai kumulatif yang mendekati nilai acak (Q>R) untuk menentukan nilai kromosom baru seperti pada Tabel 2.12 di bawah ini. Selanjutnya variabel-variabel tersebut diubah menjadi biner dengan cara pengkodean kemudian dilakukan one point crossover seperti pada Tabel 2.14 dan hasil crossover seperti pada Tabel 2.15, proses crossovernya adalah sebagai berikut. Kemudian ubah nilai decode sebelumnya dari biner ke desimal dengan hasil seperti pada Tabel 2.18 sebagai berikut.
Setelah melakukan mutasi dan hasilnya seperti pada Tabel 2.18, selanjutnya dilakukan evaluasi fitnes, dimana pada penelitian ini nilai child dengan nilai fitnes terbesar dijadikan sebagai pusat cluster dengan menggunakan algoritma K-Means sesuai dengan angka K yang dimasukkan pada saat mutasi. proses algoritma genetika awal.