David Stephenson consults and speaks internationally in the areas of data science and big data analytics. Key roles needed in big data and data science programs and considerations for hiring or outsourcing these roles.
Big data demystified
The story of big data
What changed towards the start of the twenty-first century?
Why so much data?
The proliferation of devices that generate
Its actual storage capacity is classified, but Utah's governor told reporters in 2012 that it would be "the first facility in the world expected to collect and house a yottabyte." We may hit a limit in the number of cell phones and personal computers we use, but we will continue to add network processors to devices around us.
Case study – The large hadron collider (particle physics)
Machines never tire of generating data, and the number of connected machines is growing rapidly. The number of such devices stood at around 5 billion in 2015 and is estimated to reach between 20 and 50 billion by 2020.
Case study – The square kilometre array (astronomy)
The plummeting cost of disk storage
For organizations to take full advantage of the drop in hard drive prices, they need to find a way to make a small army of medium-sized hard drives work together as if they were one very large hard drive. Google researchers saw the challenge and the opportunity and set about developing the solution that would eventually become Hadoop.
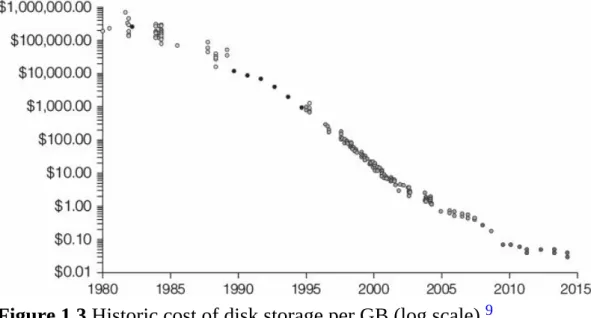
The plummeting cost of RAM
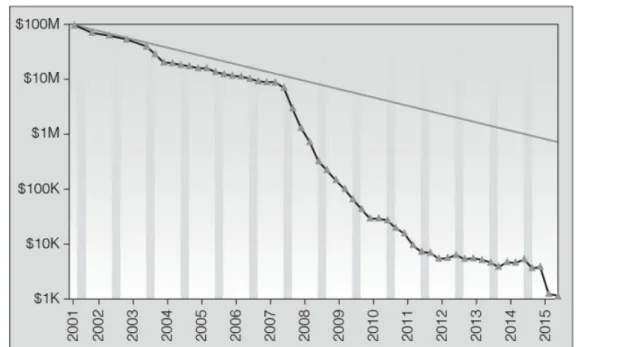
The plummeting cost of processing power
Why did big data become such a hot topic?
Hype Cycle for Emerging Technologies in 2012, made the unusual decision to drop it entirely from the Hype Cycle in 2015, thus acknowledging that big data had become so fundamental as to warrant henceforth being simply referred to as 'the data' (see Figure 1.6). Today, we have reached a point where we have the models and tools for almost any organization to start using big data.
Successful big data pioneers
Early adopters such as Google and Yahoo risked significant investments in hardware and software development. They could benefit from early adopter examples and leverage some shared code, but would still need to make significant hardware investments and develop significant internal expertise.
Open-source software has levelled the playing field for software developers
In January 2006, Yahoo made the decision to implement Hadoop on their systems.11 Yahoo was also doing quite well in those days, with a stock price that had slowly tripled over the previous five years. This gave eBay much more detailed customer insights and played an important role in the development of their platform, translating directly into revenue gains.
Keep in mind
Most of the technology you need to extract value from big data is already available. Affordable hardware and open source software were lowering the barrier for companies to start using big data.
Cloud computing has made it easy to launch and scale initiatives
If you're just getting started with big data, leverage existing technology as much as possible. But the problem remains that buying and setting up computers for a big data system was an expensive, complicated and risky process, and companies didn't know how much hardware to buy.
Takeaways
Ask yourself
Artificial intelligence, machine learning and big data
What are artificial intelligence and machine learning?
The origins of AI
Why the recent resurgence of AI?
Artificial neural networks and deep learning
For example, to train an ANN to recognize animals, I need to show it millions of images and label the images with the names of the animals in them. Before the age of big data, researchers said that neural networks were “the second best way to solve any problem.”

Case study – The world’s premier image recognition challenge
RankBrain, a neural network for search, has proven to be the biggest improvement in ranking quality that Google has seen in several years. According to Google, it has become the third most important of the hundreds of factors that determine search ranking.14.
How AI helps analyse big data
In addition to improving image recognition, language translation, and spam filtering, Google incorporated ANNs into core search functionality with the implementation of RankBrain in 2015.
Some words of caution
Deep learning, a modern improvement on an older method known as neural networks, is used in much of today's AI technology. If you multiply the estimated probability of success by the estimated ROI, you should get a number that exceeds the estimated cost.
Why is big data useful?
Completely new ways to use data
A new way of thinking about data
Following a data-driven approach
Case study – Tesco’s Clubcard
But if someone asks me for details about color, time of day, or maybe another type of vehicle, I will need another month before I can give an answer. Others you will have to dig, perhaps using statistical methods for predictions or correlations.
Case study – Target’s marketing to expecting mothers
Are you trying to encourage her to get pregnant?' The father soon learned that the girl was actually pregnant. The story made headlines, and the world marveled at how Target had hit a financial goldmine and a PR landmine.
Better data tooling
The reason you will want to develop big data capabilities is that big data gives you additional types of data (such as customer journey data) for the first dependency and additional amounts of data for the third dependency. You will see which filters the customer (de-)selects and the selected order (ascending or descending price, rating, etc.).
Case study – Cancer research
But not all applications of big data methods to cancer research have been successful, as we will see in a case study in Chapter 12. The online customer journey is an example of big data that has proven valuable in many applications.
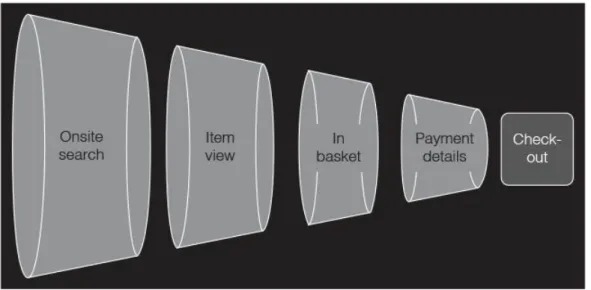
Use cases for (big) data analytics
A/B testing
The third way, which we touched on in the last chapter, is that big data allows you to answer new questions using the data you've already collected. If they used a big data system instead, they could immediately comb through historical data and identify such product pairs that had already been sold.
Recommendation engines/next best offer
The second way big data improves A/B testing is that by being able to keep all customer journey data for each testing session, you can go beyond KPIs and ask nuanced questions about how test variants impacted the customer journey. After adding a test variant ID to the customer journey big data store, you can ask questions such as "which variant had the shorter average path length?" or "in which variant did the customer purchase the most expensive product." .
Case study – Predicting news popularity at The Washington Post 30
If you're building a recommendation engine, you'll want to calibrate it using large, detailed data, including browsing data, and your big data stores provide that. Second, big data will provide you with additional explanatory variables to engineer features into your current prediction models.
IT cost savings
You can continue to use your standard statistical models, and you can also experiment using a neural network trained on a cluster of cloud-based graphics processing units (GPUs) and calibrated using all available data, not just ' a few pre-selected explanatory variables. A basic example would be sales of big ticket items, where increasingly frequent product views would be a strong predictor of an impending sale.
Marketing
Marketing professionals have traditionally been among the biggest users of web analytics, which in turn is one of the first entry points for online businesses that choose to store and analyze rather than store entire customer journey data. Marketing professionals depend on the online data to understand the behavior of customer cohorts resulting from different marketing campaigns or keyword searches, to reallocate revenue back to different acquisition sources, and to identify the points in the online journey where customers tend to churn . of the funnel and exit the purchasing process.
Social media
Once customers engage with your product, usually by visiting your website or interacting with your mobile application, they begin to leave digital trails, which you can process with traditional web analytics tools or fully analyze with a big data tool. Take Twitter, where 6,000 tweets are created every second, which equates to 200 billion tweets per year.34 You may want to consider a range of social channels, as each can play an important role in understanding your customer base, and each has its own mix. of images, links, tags and free text, appealing to slightly different customer segments and allowing different applications.
Pricing
Customer retention/customer loyalty
Cart abandonment (real time)
Conversion rate optimization
Product customization (real time)
Retargeting (real time)
Fraud detection (real time)
Churn reduction
Predictive maintenance
Supply chain management
Customer lifetime value (CLV)
Lead scoring
If the lead isn't a current customer and conversions are infrequent, you'll generally have much less data for them, so you'll need to choose and calibrate models that work with more limited data (eg machine learning models won't usually work ).
Human resources (HR)
Sentiment analysis
You usually have to build your first solutions using traditional data and then use big data to build even better solutions. We'll then move on to Part 2, which focuses on practical steps you can take to use big data within your organization.
Understanding the big data ecosystem
What makes data ‘big’?
Case study – Genomic data
The three Vs describe big challenges you'll have to overcome, but they also open up huge opportunities for you to take advantage of data in ways that weren't possible before. As a rule of thumb, 'big data' refers to data challenges that could not be handled in an affordable, scalable way prior to recent developments in how we program.
Distributed data storage
Buy a more expensive device with more storage space, although twice the storage space can cost five times as much. You no longer had to spend five times as much money for a larger machine with twice the storage space, but could get double the amount.
Distributed computations
As we'll discuss later, there are now several alternatives to Hadoop's HDFS for low-cost, scalable storage. Consider that in a 2015 Dell survey,1 73 percent of organizations reported having big data that could be analyzed, with 44 percent still unsure how to approach big data.
Fast/streaming data
You will see more streaming data with IoT (Internet of Things) technology, such as from moving vehicles or manufacturing systems. Because you will have tight latency (time) and bandwidth (volume) constraints in such applications, you will have to make tighter choices about what to process in real time or to store for later analysis.
Fog computing/edge computing
Open-source software
History of open-source
In 1999, the creators of the now widely used Apache HTTP server founded the Apache Software Foundation, a decentralized open source community of developers. The Apache Software Foundation is now the leading place for releasing open source big data software.
Licensing
Thus, both proprietary and open source streams of software development continued to grow in parallel. Hadoop was released for Apache in 2006, and much of the software that runs on top of Hadoop's HDFS has been licensed under the terms of the Apache Foundation.
Code distribution
Advantages of open-source
Open-source for big data
Cloud computing
There are several reasons why cloud computing is such an important part of the big data ecosystem. Cloud computing is a major enabler for companies to initiate and scale their data and analytics efforts.
Making the big data ecosystem work for your organization
How big data can help guide your strategy
Your customers
Getting the data
You'll probably already have some web analytics tags on your website that log high-level events. You'll need a large data storage system, such as HDFS, and you'll need to implement code (usually JavaScript) that sends events to that storage.
Using the data
You will also use this information to guide which items you market to the customer. Apply both basic analytics and advanced machine learning to your customer data and you're likely to find ways to reduce sales and increase sales.
Case study – Actionable customer insights from in- store video feeds
Basic analysis of where and when your customers are active will help you plan shifts and skill sets for your support staff. At an even more advanced level, machine learning techniques could detect pending account cancellation or the likelihood of a sale based on an analysis of text, audio or video.
Your competitors
External factors
Your own product
Use modern data and data science (analytics) to get the insights you need to determine and refine your strategy. Companies operating with a data-driven mindset may be exploring innovative ways to grow their use of data and analytics.
The programme team
The business experts usually have the best insights into what data is reliable and what data should be disregarded. This will be someone with an understanding of data collection and transfer technology, general infrastructure and corporate databases.
The kick-off meeting
Others measure its success in terms of creativity and innovation, even if the new features aren't perfect. They may be able to describe this in terms of data and analytics, or they may simply describe this in terms of projected product offerings and business outcomes.
Output of the kick-off
When this is done, return to the program sponsor to discuss the Impact Areas for Analytics document. Work with the program sponsor to prioritize the projects, referring to the Analytics effort document and taking into account the company's strategic priorities, financial landscape, scope for capital expenditure and headcount growth, risk appetite and the different dynamics that occur at a personal or departmental level can function. levels.
Scoping phase
Evaluate MVP results to determine next steps for that analytics project. It is very important to note that analytics applications are often a form of Research and Development (R&D).
Case study – Order forecasting for a German online retailer
Otto didn't stock many of the products she offered herself, hence the shipping delays. The first way was to diagnose the source of the problem, the second was to create a tool that they could put operationally.
Implementing data science –
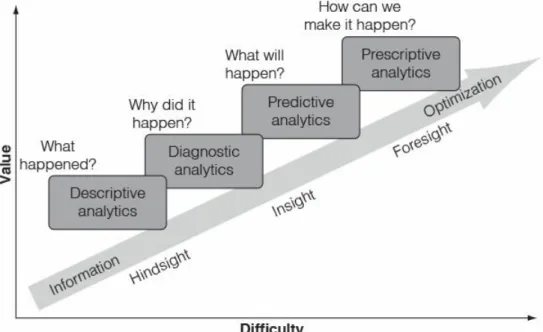
Four types of analytics
You will first need to train in descriptive analytics and then quickly move on to diagnostic analytics. To implement a self-service system, you will need to establish additional data access and management policies (see Chapter 11).
Models, algorithms and black boxes
Interestingly, models like neural networks work in a very similar way, trained on millions of sample data points for recognition. Although an ML method such as neural networks can recognize patterns with extensive training, it cannot "explain" its pattern recognition abilities.
Artificial intelligence and machine learning
AI models such as ANNs are not silver bullets and are still only one part of a larger analytical toolkit. AI models like deep learning are not silver bullets and are still only one part of a larger analytical toolkit.
Analytic software
In addition to personal preferences, check the limitations of the IT environment you work in and the third-party software you may be using. For example, Python is usually one of the first languages supported by open source big data projects (such as TensorFlow and Hadoop streaming), but many analysts come from academia with extensive R experience.
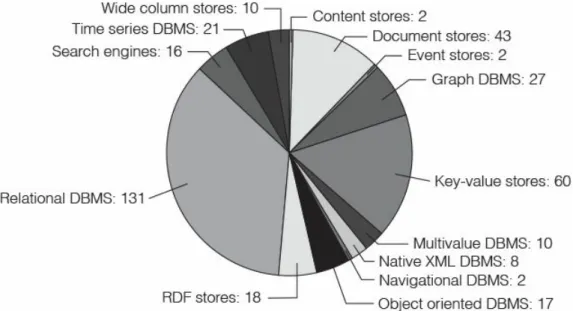
Analytic tools
Some companies allow analysts to choose their own language for prototyping models, but require that any model deployed in a production environment be first coded in a compiled language such as C++ or Java and subject to the same stringent testing and documentation requirements like all other production environments. code. But your visualization tools only come into their own in the hands of specialized experts.
Agile analytics
Spend two weeks building a 60 percent solution using 10 percent of the data, then solicit feedback on the results. For those you aren't using yet, are you being held back by a lack of skills, use cases, or priority.
Choosing your technologies
We introduced cloud computing in Chapter 5, where we described public and private clouds, the latter occurring when a large company dynamically allocates centralized computing resources to internal business units. A Dell study reported that 82 percent of mid-market organizations worldwide were already using cloud resources in 2015, of which 55 percent.
Case study – 984 leftover computers
Cloud technology includes hardware and software applications such as email, databases, CRM systems, HR systems, disaster recovery systems, etc. time (eg Kafka, RabbitMQ, etc.).
Delivery to end users
Considerations in choosing technologies
Open Source vs. Proprietary If you use open source technology, you will be able to quickly benefit from the efforts of the wider community and save. You will need to make decisions about hardware, cloud usage, data transfer, analytics tools and data delivery (BI).
Building your team
Data scientists
Today, we use the term “data scientist” not only for the experts who are creatively expanding the use of data, but also for anyone who a decade ago might have been called a statistician, a marketing analyst, or a financial analyst. Focus your recruiting efforts internally on the specific competencies you need, rather than on the term “data scientist.”

Data and anaytics roles you should fill Platform engineers
Now let's look at the specific job roles you'll want to fill for your big data and data science initiatives. You will benefit greatly if you hire or train staff who are skilled at creating top-of-the-line graphs and tables.
Leadership
However, filling an analytics leadership role is particularly challenging due to the complex requirements the candidate must meet. Offer a competitive salary and follow up closely with the candidate to quickly address any support concerns.
Recruiting the data team
Create a set of general and detailed questions that cover the competencies you believe are most important for the job, and give the candidate space in the interview to share their passions, ambitions and experience. Bring in your technology team to assess the candidate's understanding of technology and your business leaders to ensure they are comfortable with communication and business acumen.
Case study – Analytics staffing at ‘the most promising company in America’
Some third-party recruiters I've spoken to can't tell the difference between a data engineer and an algorithm developer. They should rethink their traditional candidate sourcing methods, expand their network of third-party recruiters, and make a conscious effort to help internal recruiters understand the nature of the new roles and the target's preferences and idiosyncrasies.
Hiring at scale and acquiring startups
Giving back to the community through open source projects and datasets and by hosting competitions. They hired the co-founder of key technology provider Nurego as CEO of Predix and then bought the entire company.83 Figure 10.3 illustrates the increasing rate of acquisitions of AI companies over the past few years.
Outsourcing
While you don't typically start in-house machine learning projects, at this point you can still take advantage of the pay-per-use offerings from some of the larger vendors without having to understand how they work. Which of your recruiters (internal or external) understands the requirements for each of the seven data roles described in this chapter.
Governance and legal compliance
Personal data
There are two areas of concern for the appropriate use of sensitive personal data: data privacy and data protection. Data protection concerns the protection and redistribution of data that you have legally collected and stored.
Privacy laws
Jurisdictions vary in their laws governing what personal information must be protected (health records, ethnicity, religion, etc.). Organizations can violate the law by mishandling personal information, even if it is not PII and cannot be linked to PII.
Data science and privacy revelations
Case study – Netflix gets burned despite best intentions
To illustrate, the Proceedings of the National Academy of Sciences documented a study conducted on Facebook Likes by 58,000 volunteers. By analyzing users' Facebook likes, the model was able to distinguish between Caucasians and African Americans with 95 percent accuracy.88 So we see that two of the most fundamental tools in data science: the.
Data governance
Governance for reporting
Make sure you comply with regional laws in this area and that you do not jeopardize your reputation by invading privacy, even if it is legal. If you have customers in Europe, what additional steps do you need to take to comply with GDPR?
Launching the ship – successful deployment in the organization
Case study – The 62-million-dollar failure
In retrospect, experts realized that there apparently wasn't enough data for Watson in this application, even though it had been successfully integrated with Anderson systems. Mary Chris Jaklevic, a healthcare journalist who reported on Watson-Anderson's failure in 2016, highlighted the extreme discrepancy between media hype about the project's potential and the project's complete inability to deliver results.
Why our projects fail
Don't start a data science project unless you know why you're doing it and what it looks like if it succeeds. If you start collecting and cleaning all the data you can, you will no longer be working with an MVP and will waste weeks or months before you get far enough to discover any pitfalls in your approach.
In conclusion
See https://www.quora.com/Will-deep-learning-make-other-machine-learning-algorithms-obsolete (accessed 29 September 2017). See https://www.mckinsey.com/business-functions/digital-mckinsey/our-insights/straight-talk-about-big-data (accessed 29 September 2017).
Glossary
Hadoop (Apache): The fundamental open source software framework for distributed storage and data processing. Unstructured data: Data such as free text or video that is not separated into predefined data fields.
Index
Praise for Big Data Demystified
Any unauthorized distribution or use of this text may be a direct violation of the rights of the author and publisher, and those responsible may be held liable accordingly. A catalog record for the printed edition is available in the British Library of Congress Cataloging-in-Publication Data.