Experimental Setup
Task Design
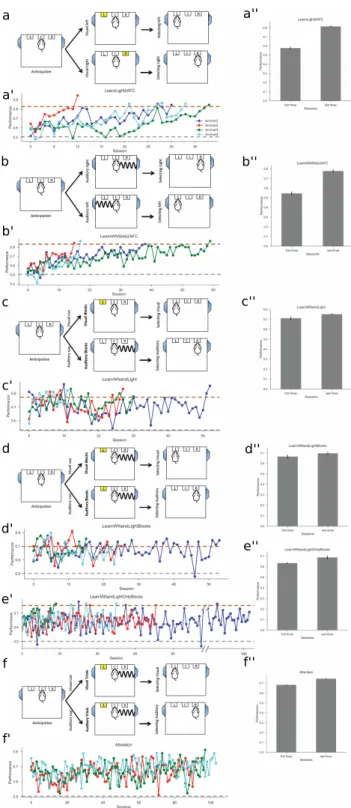
Aside from the technology required for sensing, the task itself is critical, as the displayed behavior can vary depending on the perceived difficulty of the task for the subject, which depends on many factors. However, for decision-making tasks in animals, a major challenge is that the animal may not understand the goal of the task, and thus perform arbitrarily poorly, especially when it comes to reward maximization, a human-defined skill. usually characterized by the percentage correct over many trials [11, 43].
Sensing Hardware
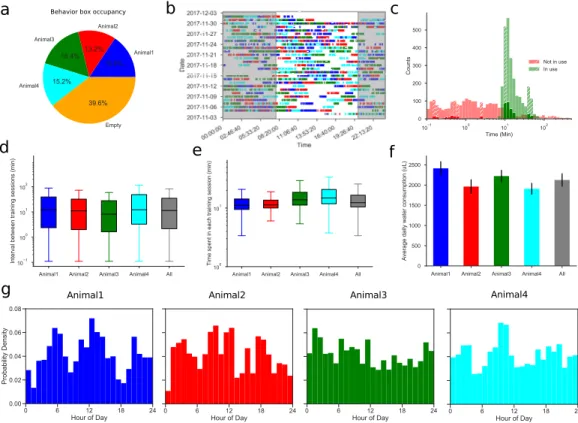
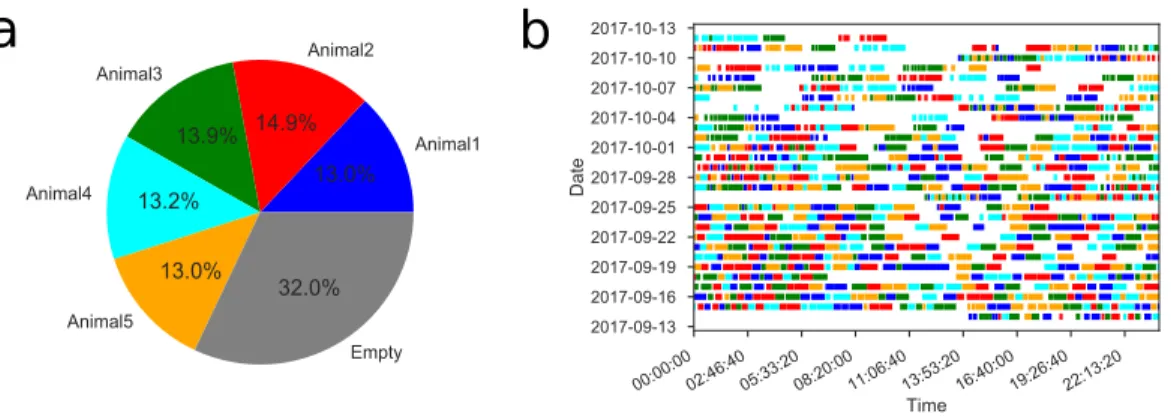
All but one of the mice moved easily and regularly between the cage and the maze (Figure 7.1–Figure 7.2). On average, the animals spent 46% of the time in the maze over the entire study period (Figure 7.1–Figure 7.3). However, even at this late stage, the animal continued to explore other parts of the maze (Figure 7.5D).
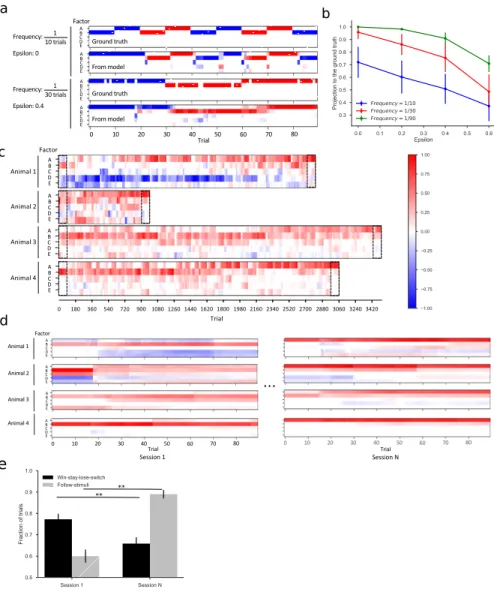
The transition from one node to the next is called a "step". The analysis in the remainder of the paper was performed on the nodal sequence of animals. In animals, there was very little variation in the balance of the three modes (Figure 7.15–Figure 7.16). Mean and standard deviation of the 4 biases in Figure 7.19A-B for animals in the rewarded and unrewarded groups.
They did not fully explain the mice's behavior (Figure 7.19D), which accounted for ~87% of the animal's efficiency (compared to 60% for the random walk). By all accounts, the animals spent much of the night exploring the maze (Figure 7.1–Figure 7.3). Indeed, many cells located in the rodent hippocampus appear within minutes of the animal entering an arena [ 18 , 52 ].

Hierarchy of Behavioral Feature Representations
Prediction and Theory
Neuroscience
In behavioral neuroscience, behavior is often first shaped by prior training for a specific task, which can then guide the search for neural changes in the brain when recording directly from the brain using imaging or electrodes [29]. More candidate neural mechanistic models than these models can then be used to guide the search for neural signals in the brain.
Other Disciplines
Review of Related Works
Introduction
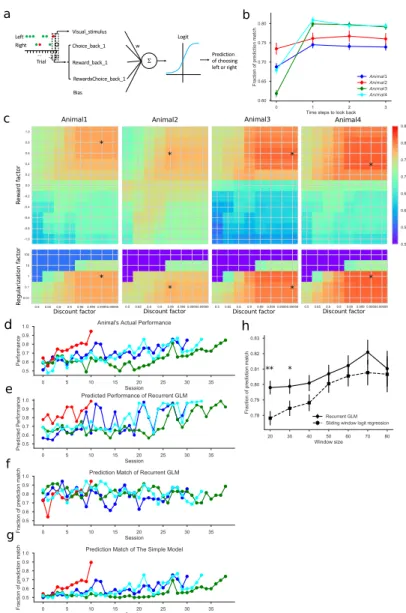
This model makes a prediction of the animal's choice in each trial and is updated based on the animal's actual choice. To analyze the animal's behavior during the task in greater detail, we calculated the movement trajectories of each mouse.
Results
The first model was fit to the animal's average performance in the task; its trial-by-trial match of the animal's actual choice was only ~59% (Figure 6.3g). Each animal has its own preference for a baseline position somewhere outside the centerline of the chamber (Figure 6.16a).
Discussion
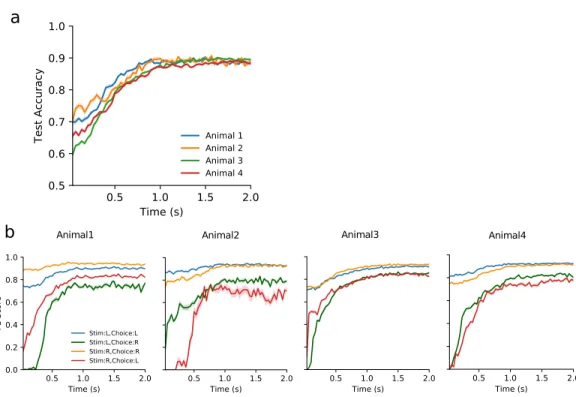
The behavioral trajectories can reveal complex aspects of the animal's decision-making process that are hidden from a mere record of the binary choices. The animal must then enter one of the two side gates within the decision period of 10 s. During the training, the time the animal had to keep in the center port was gradually increased to 0.5 s, and the duration of the stimuli was gradually shortened to 0.2 s.
From the nose and the center, we calculated the orientation as the angle of the line connecting the center and the nose. The actual performance and the performance predicted by the model, for each of the four animals.

Introduction
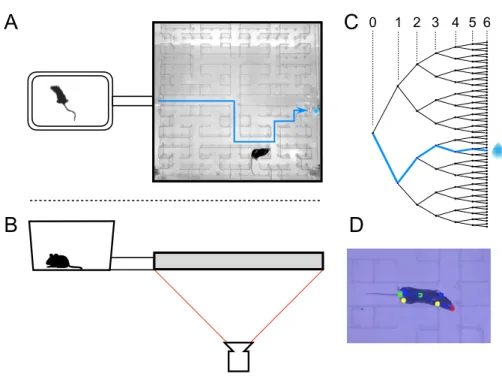
One way to formalize decision-making in the laboratory is to introduce structure into the environment in the form of a maze that defines straight paths and decision points. A single mouse is placed in a home cage from which it has free access to the maze for one night. With continuous video recording and automated tracking, we observe the animal's entire life experience in the labyrinth.
In many cases, unique moments of 'insight' can be identified when the animal's behavior changes discontinuously. At the heart of the rapid learning is an efficient way of exploring, driven by simple navigation rules.
Results
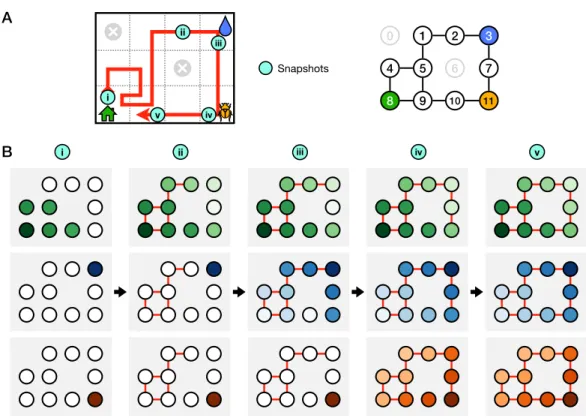
After rotating the maze 180 degrees, that gradient would lead to the image of the water port (blue dot). This conclusion holds for the rotation time point, several hours after the experiment. The longest distance between the water port and an end node in the opposite half of the maze spans 12 steps through 11 intersections (Figure 7.11A).
The animal behaves as if it gains a new insight at the time of the second step that allows it to travel directly from elsewhere in the maze to the water port. Transitions of 'leave' represent what the animal does at the start of the next bout in the maze.
Discussion
If the animal makes a mistake at any level of the tree, it can only find out after traveling to the last node. Due to the unstructured nature of the experiment, the mouse may adopt different policies to reach the water port. Presumably, this switch in performance reflects some discontinuous change in the animal's internal model of the maze, which Tolman called the "cognitive map" [2, 37].
These recordings are quite efficient: the animals cover all parts of the maze much faster than expected from a random walk (Figure 7.17). At the end of the fight, when the mouse decides to exit the maze, it can follow the heading vector to the exit.
Methods and Materials
For water deprivation, the animal was transferred from its home cage (generally in the group housing) to the maze cage ~22 h before the start of the experiment. All subsequent analysis was based on the trajectory of the animal's nose, consisting of the positions G(C) and H(C) in each video frame. There is a small increase in the rate at short time points among rewarded animals (Figure 7.1–Figure 7.4B top).
On a coarser level, one might wonder when the animal crosses the nodes of the binary tree, which are the decision points in the maze. The purpose of this analysis is to measure how effectively the animal explores all end nodes of the maze.
Introduction
A Circuit to Implement Endotaxis
2 The animal then follows its chemotaxis search strategy to increase this odor, leading it to the selected marked trait. A key insight is that the output of a target cell systematically declines with the animal's distance from that target. After this map learning, the resulting network of maps is a hump of activity centered on the animal's current locationG and decaying with distance along various paths in the graph (Figure 8.1C above).
If the animal moves to another location H, the map output is another bump of activity, now centered on H (Figure 8.1C bottom). When the animal subsequently moves to another location G, the target cell6 receives the current map outputE8(G) filtered by the previously stored synaptic templateE8(H).

Performance of the Endotaxis Algorithm
Because the map grid is already created along the path the agent took, that instantly creates a virtual "water smell" that spreads through the environment and decreases with distance from the water location (Figure 8.2B-iii). As the agent further explores the environment, the virtual odors propagate accordingly to the new locations visited (Figure 8.2B i-v). Now virtual odors are available at every point in the environment and they decrease monotonically with the distance of the shortest path to the corresponding target location (Figure 8.2B-v).
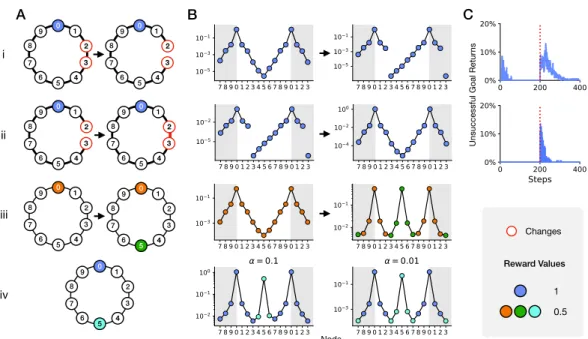
The topology of the maze was a binary tree with a single entry, 63 T-junctions, and 64 end nodes (Figure 8.3A-ii). After exploration covered the entire maze, both the entry odor and the water odor were available at all locations (Figure 8.3B-ii), allowing error-free navigation to the sources by endotaxis (Figure 8.3C-ii).
Adaptation to Change in the Environment
Instead, simulations on the ring show that the apparent odor peaks at both targets, and endotaxis reliably takes the agent to the nearest one (Figure 8.4B.iii). Suppose that one of the targets offering the same resource is more valuable than the other, for example because it provides a greater reward (Figure 8.4A.iv). In the endotaxis model (Figure 8.1B), a greater reward results in greater activity of the characteristic cell responding to that source, and thus stronger potentiation of synapses to the associated target cell (Equation 8.20).
The input template of the target cell thus becomes a weighted sum of map output from the two target locations with greater weight for the location with higher reward (Figure 8.4B.iv). In the endotaxis model (Figure 8.1B), this is set by UM, one of the two parameters of the synaptic learning rule in the map network (Equation 8.19).
Discussion
The value function is modified through reward experience when the agent reaches a valuable resource; in endotaxis this occurs through the updating of synapses in the target network (Gin Figure 8.1B). During exploration, the circuit learns the topology of the environment, specifically by updating the synapses in the mapping network (M in Figure 8.1B). Eventually, when the goal is reached, Gis is updated in one shot and the value function becomes nonzero over the entire known part of the environment.
In model-based reinforcement learning, the agent can learn a forward model of the environment and use it to update a value function. In contrast, the map matrix in the endotaxis mechanism is built on a policy of random exploration independent of reward.
Supplement
In numerical experiments, we found that the exponential dependence of the target signal ⇢8 9 on the distance (Equation 8.12) is actually valid in a wide range W (Figure 8.5A). This behavior can also be seen in some simulations of random exploration (Figure 8.3B). Finally, it determines the dependence of the target signal on the distance: for each step along the graph, the target signal is reduced by a factor W (equation 8.28).
UM has an absolute upper bound of Wc/F (equations that depend on the eigenspectrum of the graph. Evolution of the map matrix (kMk and kdMk) and the target matrix (kGk and kdGk) during exploration of the binary maze graph of Figure 8.3A-ii .

Discussion
Future Directions