Optimasi PSO (Particle Swarm Optimization) pada Algoritma
Algortima Backpropagation
- Pendahuluan
- Kelebihan Algortima Backpropagation
- Kekurangan Algortima Backpropagation
- Langkah Penyelesaian Algortima Backpropagation
Dengan kata lain, pembelajaran terbimbing mempunyai tujuan (Goal) untuk memperkirakan fungsi petanya sehingga ketika kita mempunyai masukan baru, algoritma dapat memprediksi keluaran untuk masukan tersebut (Windarto dan Lubis, 2016). 1.3) dan mengirimkan sinyal ini ke semua unit di unit keluaran. Langkah 5: Setiap unit keluaran (yk, k=1,…., m) menambahkan sinyal.
PSO (Particle Swarm Optimization)
- Parameter yang digunakan dalam proses algoritma PSO
- Langkah Penyelesaian algoritma PSO
Hal ini tidak terlalu penting untuk perilaku konvergensi algoritma PSO. d) Jangkauan dan dimensi partikel. Istilah yang digunakan dalam implementasi algoritma PSO adalah sebagai berikut (Nikentari dkk a) Swarm : Suatu populasi yang terdiri dari sekumpulan partikel.
Implementasi Backpropagation
- Langkah Langkah Analisa
- Penerapan Software RapidMiner 5.3.015
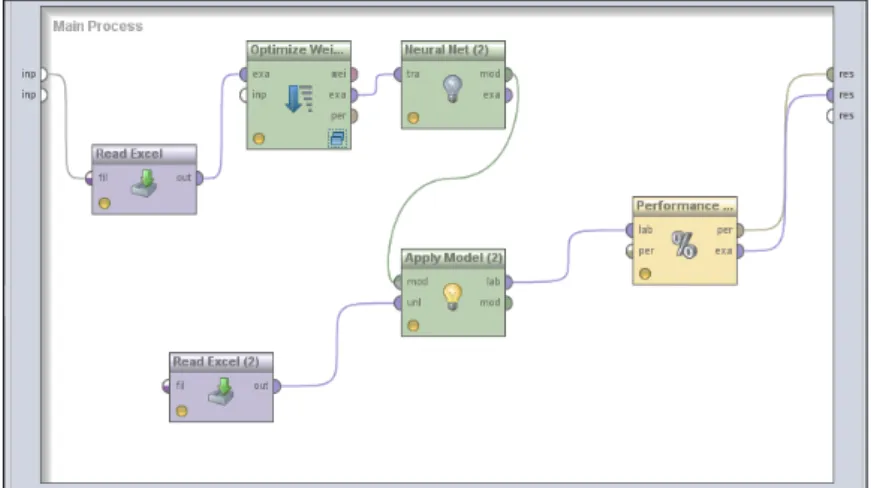
Pada Gambar 1.10, operator validasi x mempunyai port input yaitu training sample set (tra) sebagai port input untuk memperkirakan sample set untuk melatih suatu model (training data set). Model arsitektur akan dilatih untuk memilih model arsitektur terbaik dari perspektif Root Mean Square Error (RMSE).
Implementasi Backpropagation + PSO
Algoritma Perseptron dan Penerapan Aplikasi
Arsitektur Jaringan
Bentuk terkecil (minimal) dari JST adalah model arsitektur Perceptron yang hanya terdiri dari satu neuron (Sumijan et al., 2016). Jika berada pada satu kelas maka respon dari unit outputnya adalah 1, sedangkan jika tidak maka responnya adalah -1 (Yanto, 2017).
Fungsi Aktivasi
Proses Pembelajaran Perceptron
Contoh Perhitungan Perceptron
Penerapan Aplikasi
Algoritma Conjugate gradient Polak Rebiere untuk Prediksi Data
Conjugate gradient Polak-Ribiere
- Algoritma
- Deskripsi
Gradien konjugasi Polak-Ribiere merupakan fungsi pelatihan jaringan yang memperbarui nilai bobot dan nilai bias sesuai dengan gradien backpropagation konjugasi dengan pembaruan Polak-Ribiere (MathWorks, 1994). Untuk pembahasan lebih rinci tentang algoritma gradien konjugasi Polak-Ribiere, lihat pembahasan (Fletcher dan Reeves, 1964; Hagan, Demuth, dan Beale, 1996). Persyaratan penyimpanan untuk Polak-Ribiere (empat vektor) sedikit lebih besar dibandingkan Fletcher-Reeves (tiga vektor).
Traincgp merupakan fungsi pelatihan jaringan yang mengupdate nilai bobot dan nilai bias sesuai algoritma conjugate gradien backpropagation dengan update Polak-Ribiere. Catatan: Parameter yang tercantum pada Tabel 3.3 dan 3.4 pada pembahasan gradien konjugat Polak-Ribiere sama dengan yang tercantum pada Tabel 3.1.
Contoh Kasus : Prediksi Data dengan Algoritma Conjugate gradient
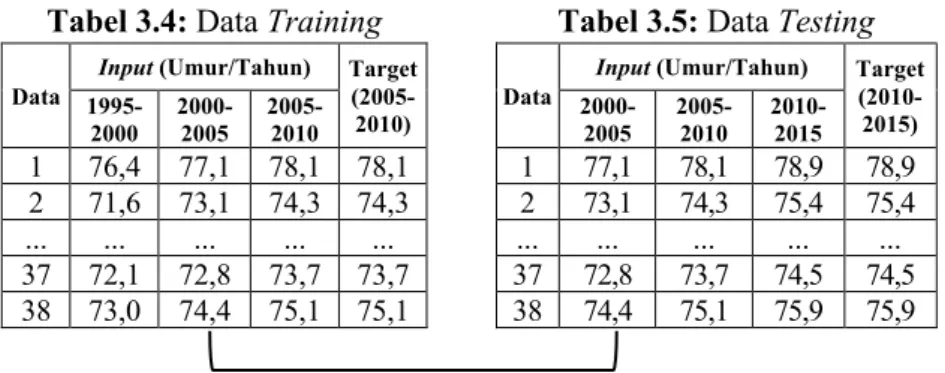
Normalisasi data latih dan data uji harus dilakukan untuk mengubah data ke nilai antara 0 dan. Sebelum melakukan normalisasi, kita perlu mengetahui nilai data tertinggi (b) dan data terendah (a) dari tabel data latih dan data uji. Langkah-langkah pelatihan dan pengujian data berdasarkan model arsitektur jaringan yang digunakan dapat dilakukan sebagai berikut: a.
Target = Diperoleh dari data target yang dinormalisasi Testing Output = Diperoleh dari nilai a data Hasil Testing Matlab Error = Diperoleh dari Target – Output atau dari nilai e. Target = Diambil dari data target yang dinormalisasi Test Output = Diambil dari nilai data Test hasil Matlab.
Pengenalan
Algoritma Habb
- Langkah Langkah Penyelesaian
- Contoh penyelesaian
- Kelebihan
- Kekurangan
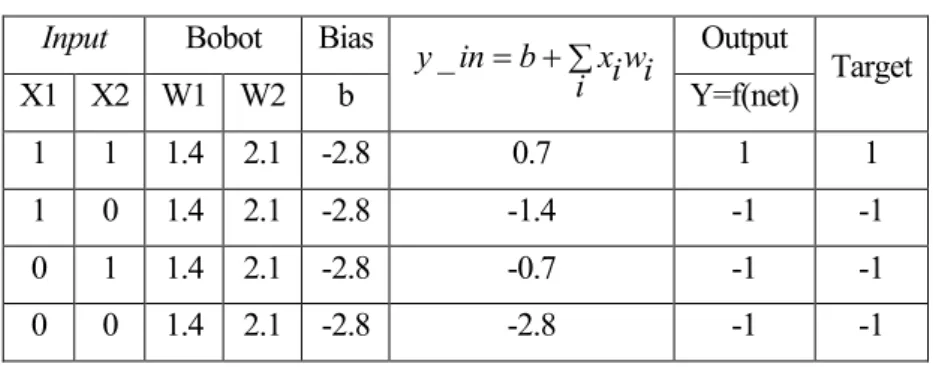
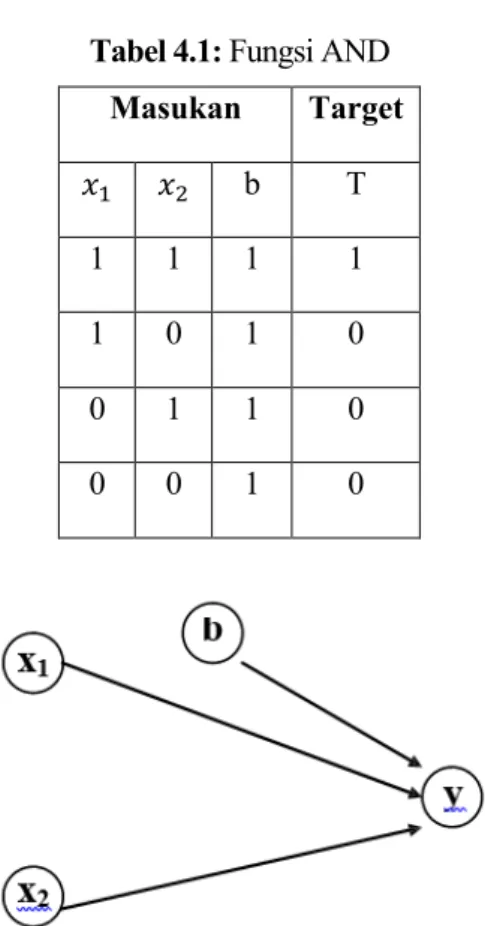
Dengan menggunakan rumus di atas, kami menguji bobot tersebut pada seluruh data masukan sehingga diperoleh data seperti pada Tabel 4.3 di bawah ini. Pada Tabel 4.3 di atas f(net) tidak sama dengan target yang dimasukkan pada fungsi “AND” sehingga dapat disimpulkan bahwa Habb tidak dapat mengenali pola ini dengan input biner dan output biner. Dengan menggunakan kembali rumus di atas, selanjutnya kita uji seluruh data masukan sehingga diperoleh data seperti pada Tabel 4.9 sebagai berikut.
Sedangkan perubahan bobot (Δwi) dan bias setelah memasukkan sampel 1 dan 2 pada Tabel 4.11 adalah sebagai berikut. Dan bobot akhir (wi) dan bias b dapat ditentukan dari penjumlahan kedua perubahan bobot di atas seperti terlihat pada Tabel 4.12 di bawah ini.
Penerapan algoritma Habb dengan Software
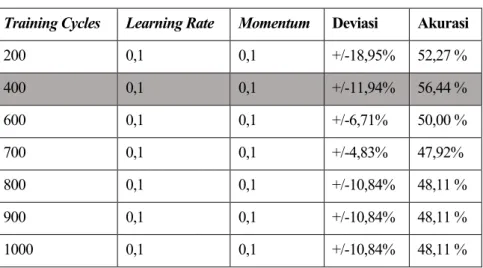
Pengujian selanjutnya yang dilakukan setelah learning rate adalah uji nilai momentum yang dapat dilihat pada tabel 5.11. Selanjutnya setelah dilakukan pengujian nilai momentum dilakukan pengujian terhadap nilai lapisan tersembunyi yang dapat dilihat pada tabel 5.12.
Prediksi Gaya Belajar VARK dengan Artificial Neural Network
Pengujian dengan Data Behavior
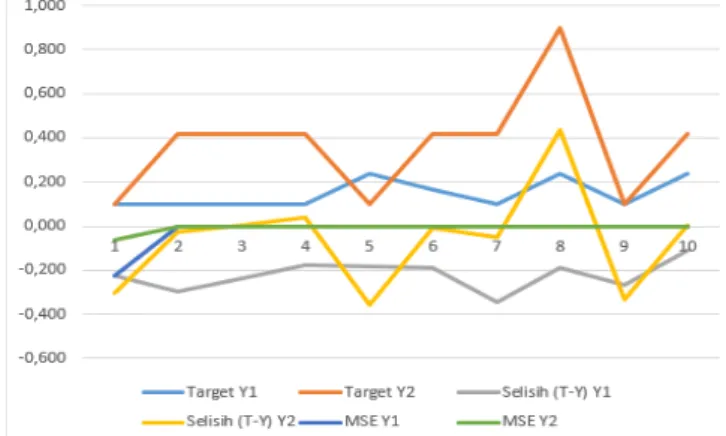
Pada Tabel 5.13 diatas dapat dikatakan bahwa hasil pendeteksian menggunakan data behavioral hanya mempunyai nilai akurasi maksimal sebesar 56,44%. Untuk membandingkan hasil pengujian lainnya digunakan uji error absolut dan median error absolut yang dapat dilihat pada Tabel 5.14. Dengan dataset pembelajaran ini, selanjutnya kita sesuaikan dengan data target yang ditentukan pada Tabel 7.4 untuk mengubah nilai bobot jika selisih antara nilai keluaran dengan nilai target belum konvergen.
Dengan kumpulan data latih ini, selanjutnya kita sesuaikan dengan data target yang diberikan pada Tabel 7.5 untuk mengubah nilai bobot jika selisih antara nilai keluaran dengan nilai target belum konvergen. Pada Tabel 7.11 selisih nilai target dengan keluaran dataset latih adalah nilai error dengan cara menghitung selisih nilai target dengan keluaran (t-y), kemudian membagi selisihnya dengan banyaknya dataset latih yang akan dihasilkan MSE (Mean Square Error) dari kumpulan data pelatihan.
Prediksi dengan Algoritma Levenberg-Marquardt
Tahapan Pelatihan dengan Algoritma Lavenberg-Marquardt
Penerapan algoritma Levenberg-Marquardt untuk pelatihan jaringan saraf tiruan harus menyelesaikan dua permasalahan yaitu perhitungan matriks Jacobian dan bagaimana mengatur proses pelatihan berulang untuk memperbarui bobot. Algoritma Levenberg-Marquardt menyelesaikan permasalahan metode penurunan gradien dan metode Gauss Newton untuk melatih jaringan syaraf tiruan.Dengan menggabungkan kedua algoritma tersebut, algoritma ini dianggap sebagai salah satu algoritma pelatihan yang paling efisien (Sylvia Jane Annatje Sunarauw, 2018). Bobot awal dilatih melalui tahap maju untuk memperoleh kesalahan keluaran, kemudian kesalahan ini digunakan dalam tahap mundur untuk memperoleh nilai bobot yang sesuai guna memperkecil nilai kesalahan guna mencapai target keluaran yang diinginkan.
Tujuan dari model ini adalah untuk mencapai keseimbangan antara kemampuan jaringan dalam mengenali pola yang digunakan selama proses pelatihan dan kemampuan jaringan dalam merespons dengan benar pola masukan yang berbeda dengan pola masukan selama pelatihan. Parameter faktor Tau (𝜏), parameter ini berguna untuk membagi atau mengalikan dengan parameter Marquardt. 𝑛) menerima sinyal masukan dan meneruskannya ke seluruh unit pada lapisan tersembunyi.
Proses Pelatihan dengan Algoritma Lavenberg-Marquardt
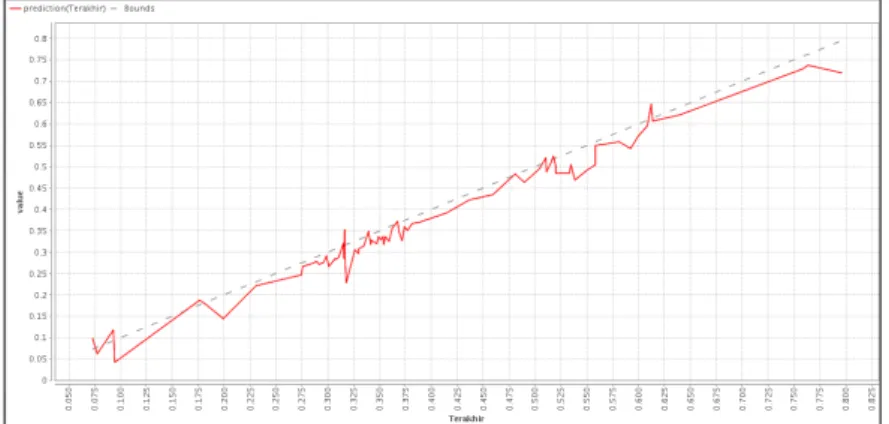
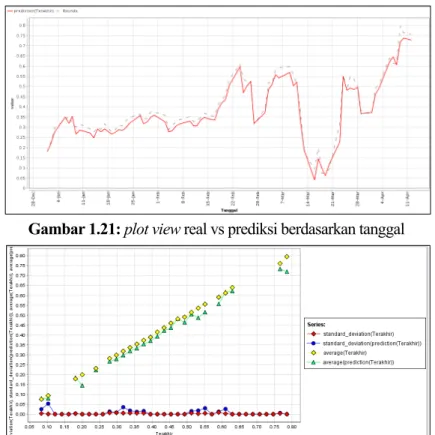
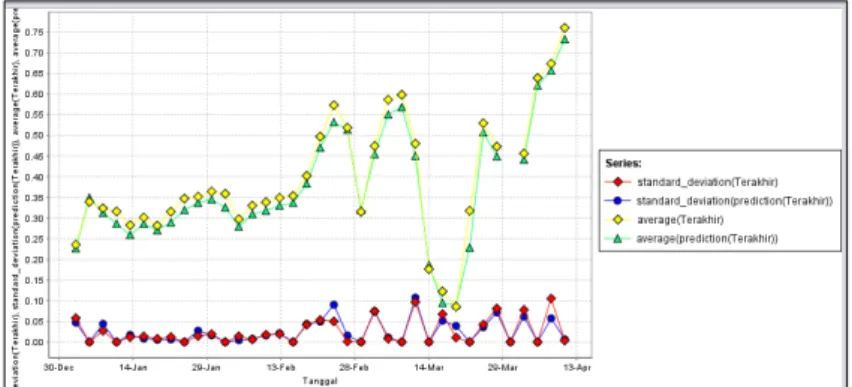
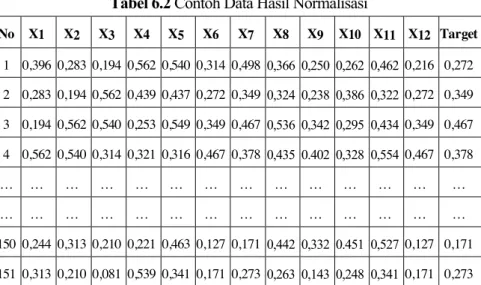
Pada Tabel 6.2, data telah dinormalisasi dan menggunakan arsitektur jaringan syaraf tiruan Levenberg Maquardt pada Gambar 6.2. Data latih yang dilatih algoritma LM nantinya akan dijadikan acuan untuk menemukan pola data prediksi yang akan muncul di masa yang akan datang. Jaringan saraf kuantum (QNN) adalah jaringan saraf klasik yang digunakan untuk menghubungkan neuron dan memilih input, bobot, dan output pada setiap lapisan yang ada sehingga fungsinya dapat direduksi menjadi nilai antara 0 dan 1, yang dalam algoritma kuantum diubah menjadi angka bit kuantum (Gultom, 2017). Pada Tabel 7.8, selisih nilai target dengan keluaran kumpulan data pelatihan adalah nilai error dengan cara menghitung selisih nilai target dengan variabel keluaran (T-Y), kemudian membagi selisih keduanya dengan banyaknya kumpulan data.
Jaringan saraf kuantum (QNN) merupakan salah satu bentuk jaringan saraf tiruan yang menggunakan konsep komputasi kuantum (Daskin, 2018), (Ying, Ying, & Feng, 2017). Pengkodean ke data biner untuk usia atribut pasien Tabel 8.3: Kode atribut Usia pasien.
Prediksi dengan Quantum Neural Network
Menentukan Arsitektur Jaringan
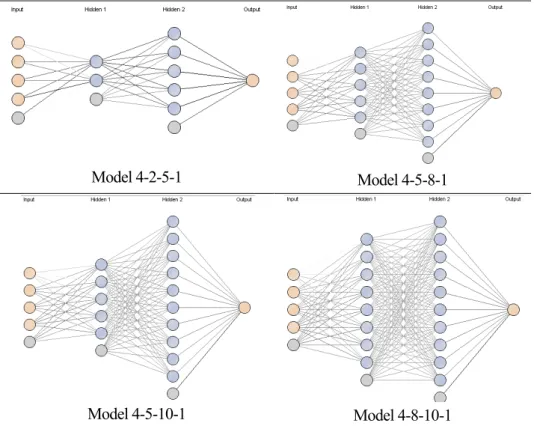
Jumlah neuron pada lapisan tersembunyi harus berada di antara jumlah neuron pada lapisan masukan dan lapisan keluaran. Jumlah neuron pada lapisan tersembunyi harus kurang dari dua kali jumlah neuron pada lapisan masukan. Berikut dataset yang digunakan untuk memprediksi hasil pertandingan sepak bola dengan Quantum Neural Network.
Hasil pembelajaran dilakukan dengan menghubungkan neuron-neuron pada lapisan tersembunyi sebanyak 6 titik ke lapisan keluaran dengan jumlah variabel 2 (Y1 dan Y2) dan hasil keluaran diperoleh setelah diaktivasi menggunakan fungsi sigmoid. Pada proses pembelajaran dengan jaringan saraf kuantum, hasil atau keluaran diperoleh dengan menghubungkan neuron-neuron pada lapisan tersembunyi yang berjumlah 6 titik ke lapisan keluaran dengan jumlah variabel 2 dan hasil keluaran yang diperoleh diaktifkan menggunakan.

Hasil dan Evaluasi
Fungsi aktivasi nonlinier seperti fungsi hiperbolik dan sigmoid paling sering digunakan untuk menghasilkan keluaran neuron yang lebih halus, misalnya setiap perubahan kecil pada berat badan menyebabkan perubahan kecil pada keluaran. Penggunaan logika fuzzy juga sangat cocok untuk mengambil nilai yang tepat dari masukan yang diterima berupa bahasa dan mengubahnya menjadi angka dengan mengubahnya menjadi nilai keanggotaan pada himpunan Fuzzy (Jyh dkk, 1997). JST dapat digunakan untuk memodelkan hubungan kompleks antara input dan output untuk menemukan pola dalam data (Sarosa, M., Ahmad, A.S., dan Riyanto, B. Noer., 2007).
Tautan dari satu unit ke unit lainnya digunakan untuk menyebarkan aktivasi unit pertama ke unit lainnya. Proses ini digunakan untuk mengubah nilai masukan yang diteruskan (e dan de) menjadi derajat keanggotaan fuzzy.
Penerapan Quantum Perceptron Dalam Klasifikasi Data
Quantum Neural Network
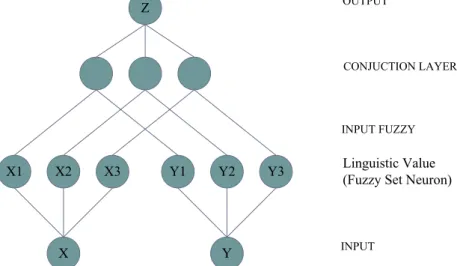
Pada metode ini arsitektur jaringan masih menggunakan jaringan syaraf tiruan klasik, namun penentuan input, bobot, algoritma pembelajaran dan tujuan sudah menggunakan pendekatan komputasi kuantum (Farhi dan Neven, 2018). Tujuan utama dari penggabungan kedua metode ini adalah untuk memberikan konsep yang lebih efisien dibandingkan jaringan saraf klasik. Dalam jaringan saraf klasik, kombinasi linier parameter masukan dengan bobot berbeda diumpankan ke beberapa neuron.
Ada juga pendapat bahwa fungsi aktivasi berkala dapat meningkatkan kinerja jaringan saraf secara keseluruhan dalam aplikasi tertentu (Daskin, 2019).
Quantum Perceptron
Pendekatan pertama berfokus pada aspek komputasi dari masalah, dan metode yang diusulkan menurunkan skala kompleksitas pelatihan secara kuadrat ke jumlah vektor pelatihan. Quantum Perceptron merupakan bagian dari metode jaringan saraf tiruan kuantum (Quantum Neural Network), yang menggabungkan komputasi kuantum dengan algoritma perceptron dalam jaringan saraf tiruan (Daskin, 2018). Konsep dasar metode Quantum Perceptron adalah menggunakan sifat-sifat atom dalam mekanika kuantum, yang disebut bit kuantum (qubit), untuk komputasi kuantum.
Qubit memiliki keadaan yang berbeda pada waktu tertentu dan memiliki nilai probabilitas (superposisi) yang berbeda.
Penerapan QuantumPerceptron Dalam Kalsifikasi Data
- Data Yang Digunakan
- Tahapan Analisis
- Preprocessing Data
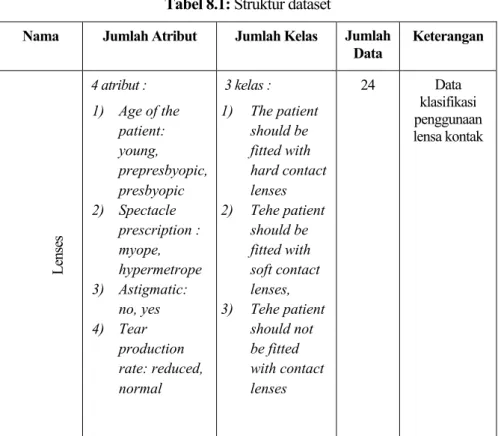
Nama Jumlah atribut Jumlah kelas Jumlah .. pasien: . muda, prepresbiopia, presbiopia 2) Kacamata..harus dilengkapi lensa kontak keras 2) Pasien..harus dilengkapi lensa kontak lunak, 3) Pasien. Dataset ini terdiri dari 24 sampel dengan sebaran kelas yaitu: 4 sampel kelas lensa kontak keras, 5 sampel kelas lensa kontak lunak, dan 15 sampel kelas tanpa lensa kontak. Misalnya sampel diambil dari kumpulan data nomor 1 yaitu kode biner 0101101 maka kode tersebut mempunyai arti yaitu: umur penderita = muda, resep kacamata = rabun, astigmatis, = ya, laju produksi air mata = ya dan kelas lensa kontak lunak.
Pada FNN, elemen-elemen yang berhubungan dengan neural network tidak lagi menggunakan bentuk klasik seperti pada neural network pada umumnya, melainkan sudah digantikan dengan pendekatan logika fuzzy. Pada FNN, elemen kunci jaringan syaraf tiruan tidak lagi menggunakan bentuk klasik seperti pada jaringan syaraf tiruan pada umumnya, namun digantikan dengan pendekatan logika fuzzy.
Fuzzy Neural Network, (Application System Control)
Fuzzy Neural Network
Jaringan saraf fuzzy (FNN) adalah jaringan saraf tiruan dengan basis aturan fuzzy. NN merupakan ilmu soft computing yang diambil dari kemampuan otak manusia dalam memberikan rangsangan, melakukan proses, dan memberikan hasil. (Jain, LC dan Martin, NM, 1998). Neuron yang umumnya terletak pada lapisan yang sama akan mempunyai kondisi yang sama. Jaringan saraf fuzzy (FNN) adalah model komputasi fuzzy yang dilatih menggunakan jaringan saraf, tetapi struktur jaringannya diinterpretasikan oleh seperangkat aturan fuzzy.
Proses fase-fase struktur neuron pada otak manusia yang telah dijelaskannya di atas merupakan konsep dasar membangun jaringan saraf tiruan (Artificial Neural Network). Dasar dari jaringan syaraf tiruan (JST) adalah model matematis berupa kumpulan unit-unit yang terhubung secara paralel yang bentuknya menyerupai jaringan syaraf pada otak manusia. Warren McCulloch dan Walter Pitts, 1943).
Pembuatan Model Sistem Kontrol
Simbol G(s) merupakan fungsi alih tumbuhan dan e –ts merupakan unsur waktu tunda yang terjadi pada tumbuhan.
Menentukan Fungsi Keanggotaan Fuzzy
Perancangan Struktur Jaringan FNN
Pelatiahan FNN
Pengujian Sistem
Hasil Pelatihan FNN
Algoritma Kohonen Self Organizing Map (SOM)
Contoh Soal dan Penyelesaiannya