Thank you to Dr.Wilkins and the Ole Miss Computer Science Department for keeping me on track and providing countless resources throughout this process. Seventy-eight open source novels were used in the analysis, with thirty-one books by female authors and forty-seven by male authors. Data from the novels was extracted using Python, natural language processing, and the Natural Language Toolkit (NLTK).
James wrote the first of the best-selling romance series Fifty Shades of Gray in 2011. All of the names previously mentioned are 'nom de plumes', or pen names, for some of the most popular female authors in history. Rowling, these are actually pen names of authors Erika Leonard and Joanne Rowling - two female authors who published their novels using gender-neutral names at the suggestion of their publishers.
In all of the previous cases, pen names were used as a means for these authors to 'separate' their genders from their novels.
Aims and Objectives
Description of Work
Text Corpus
Choosing Texts
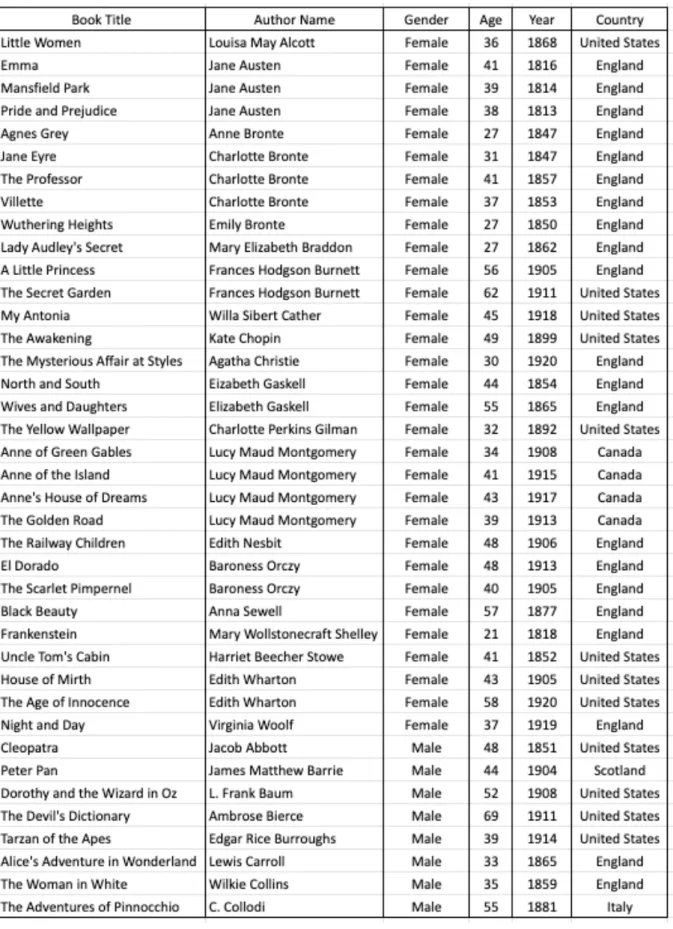
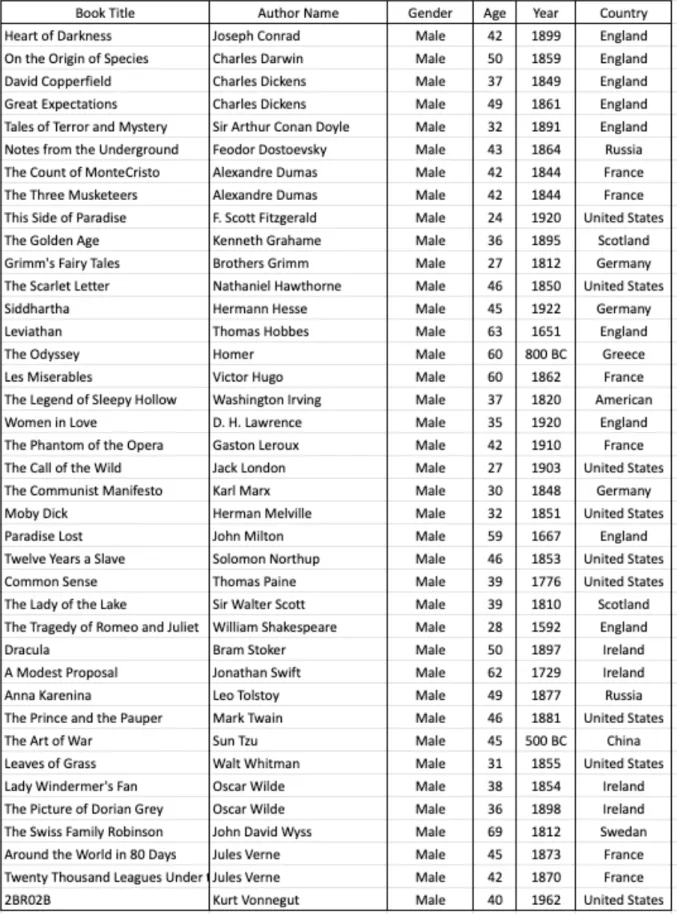
Book List & Data
Collection of Authors
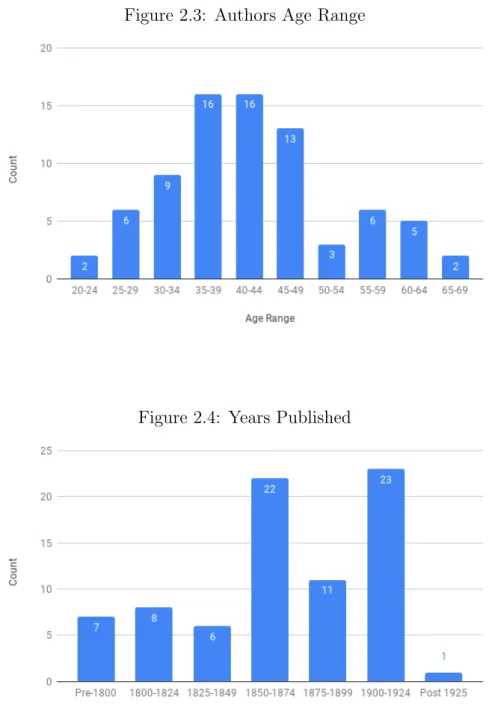
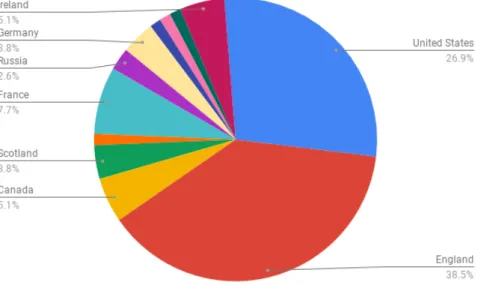
This average is due to the exclusion of two standout texts: Sun Tzu's The Art of War and Homer's Odyssey. As shown in Figure 2.5, most of the texts were originally written in English, with 70.5% of the texts coming from England, the United States, or Canada.
Conclusion
As indicated in Chapter 1, the first area that will be examined is the author's writing style, or the characteristics that contribute to it; for example structure and vocabulary. These ideas will be explored in answering the question posed in section 1.1: is it possible to predict the gender of the author of a novel by comparing features of the text with patterns found. To explore vocabulary, lexical diversity and dictionaries will be addressed to see if patterns exist in the words used by male versus female authors.
Text Length
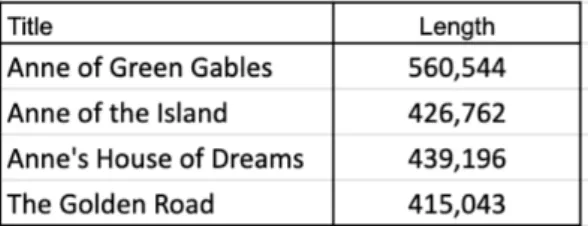
Since Victor Hugo's Les Mis`erables was the longest text in the corpus of men's texts, two additional texts by Hugo were obtained and analyzed from the Project Gutenberg website to investigate this hypothesis: Notre-Dame de Paris and Toilers of the Sea. Like Les Miserables, both Notre-Dame de Paris and Toilers of the Sea had high text lengths, placing them in the top 25% of male texts (849,904 words and 1,096,982 respectively). This pattern also applied to author Lucy Maud Montgomery and her works Anne of Green Gables, Anne's House of Dreams, Anne of the Island and The Golden Road.
As seen in Figure 3.2, Montgomery's works were all close in length, and had a standard deviation of 58,453.40 words compared to the text corpus standard deviation of. In addition, female authors had a more definite range for text length, while male authors had greater variance in text length. However, these observations, along with text length as an author characteristic, require further research with a larger text corpus to confirm these writing style tendencies.
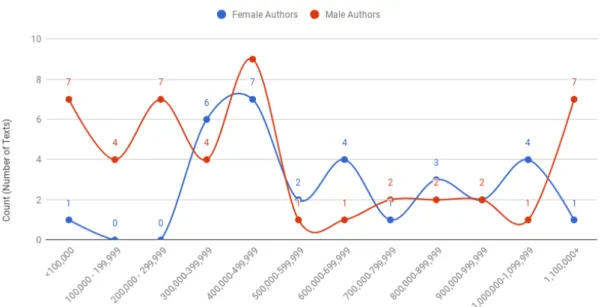
Sentence Length
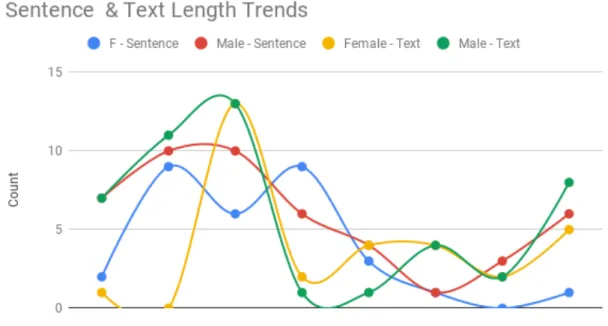
This means that women's novels are more similar in terms of sentence length and text, while men's novels and sentences are either much shorter or much longer in length. This is shown by the fact that the blue and yellow female lines in Figure 3.4 have a delayed initial peak and decrease faster than the red and green male lines.
Word Length
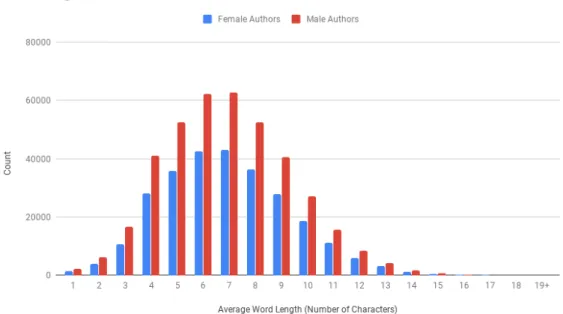
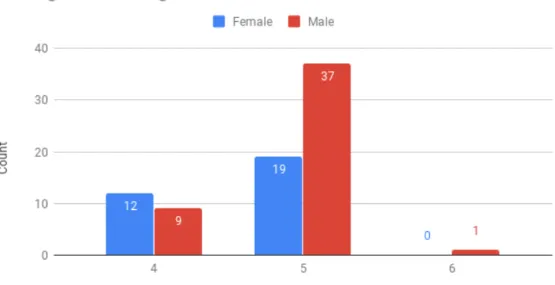
The higher word length among the male authors, shown in Figure 3.6, is due to the slightly larger number in the male collection texts than in the female texts. That is, it can be inferred that word length is an attribute of the English language rather than an author-specific characteristic. Further discussions on the English language and vocabulary will continue in the next section on vocabulary and lexical diversity.
Vocabulary & Lexical Diversity
- Lexical Diversity
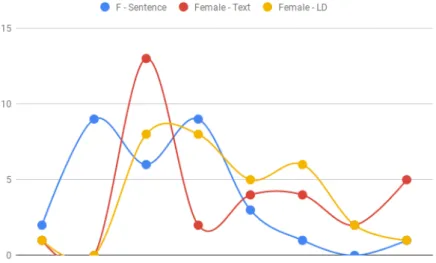
As shown in the figure and based on the calculated standard deviations, male authors tended to have either very low or very high lexical diversity ranges. Whereas female writers tended to have similar lexical diversity between the range of 11 and 22. These patterns are complementary to the patterns found with text and sentence length, suggesting that lexical diversity is not so much a factor of gender but rather an author-specific feature.
Dictionary Similarities Using TF-IDF
- The TF-IDF Method
- Calculating TF-IDF Similarity
- Creating the Dictionary Similarity Heat Maps
Before looking at dictionary similarities, the TF-IDF method will be explained in more detail. As explained by Bartosz Gralewicz, the TF-IDF method is defined as “an information retrieval technique that weights term frequency (TF) and its inverse document frequency (IDF). Each word or term has its own TF and IDF score.” The product of the two term scores is called the TF*IDF weight for that particular term.
Before calculating these vectors, the texts were preprocessed to remove stop words or frequently used words that could reduce the quality of the measurements; e.g. "the", "a" or "and". After the texts are scanned and preprocessed, each text is labeled as a vector. The TF-IDF method is used in two parts: the TF method or document-specific method and the IDF method or collection-specific method.
If a word appears frequently in a document, it is important, it gets a high score.” The IF method estimates how many times a term appears in the entire collection; moreover, if the term appears frequently in the documents, it gets a lower score. After calculating the TF and IDF scores for a word, the two scores are multiplied to get the TF-IDF score. Finally, the collection of TF-IDF scores for each text will be used to determine the similarity of the two documents by computing the dot product of the two vector lists.
Due to space limitations, the x-axis labels of the heatmaps have not been included, but they follow the same order as the y-axis. These will be evident from the yellow diagonal lines shown on the heatmaps showing how each text compares to itself. About fifteen texts are recognizably different from the rest of the corpus, shown in the blue colored lines in Figure 3.8.
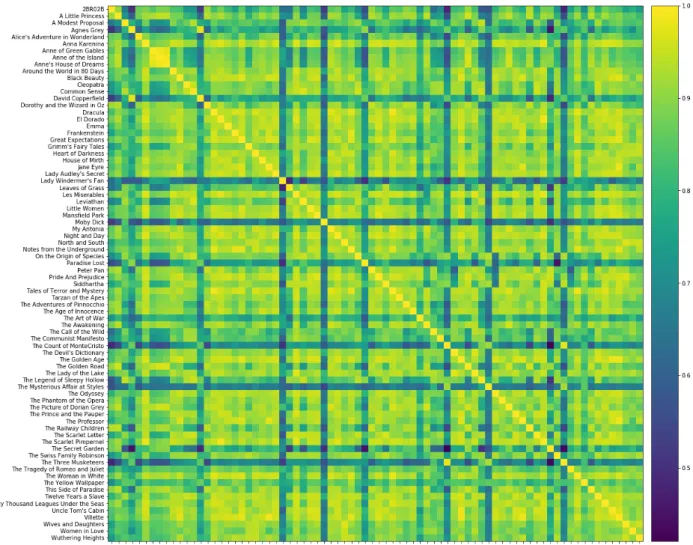
Conclusion
Figures 3.10 and 3.11 show that female authors had a higher average percentage of similarity between texts, while male text similarities changed more often. These findings confirm previous patterns found among authors' writing style, namely that female works maintain a more consistent style, while male authors' writing style fluctuated and had an inconsistent style. In this chapter, we will analyze the actual content of the novels, rather than looking at objective features such as structure, text length, and lexical variety.
That is, this chapter will focus on the connotations of gender and the overall impression of each novel in relation to gender. Furthermore, the main questions in this chapter are: How often is gender referenced in novels? To analyze gender sentiment in the text, the biggrams, or words immediately before and immediately after specific gender pronouns, are collected.
The most common couplets for each gender pronoun will then be displayed with word clouds.
Text Sentiment
If the word exists, the three scores for that word are added to their respective lists. After scanning the entire book, each dimension list is summed and divided by the number of terms within their lists. These final results represent the sentiment scores for a novel across the valence, arousal, and dominance scales.
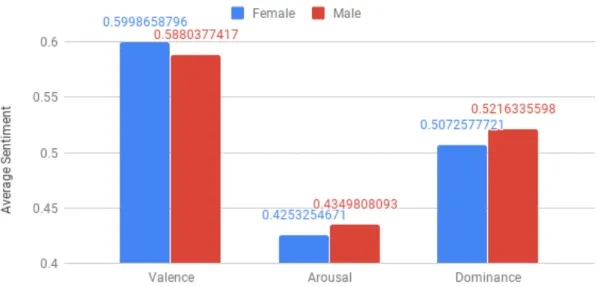
As shown in Figure 4.2, there is little difference in average sentiment across the three dimensions. The standard deviations for all six bars/columns were insignificant with all standard deviations being in a range of 0.011 and 0.028.
Gender Bi-gram Word Clouds
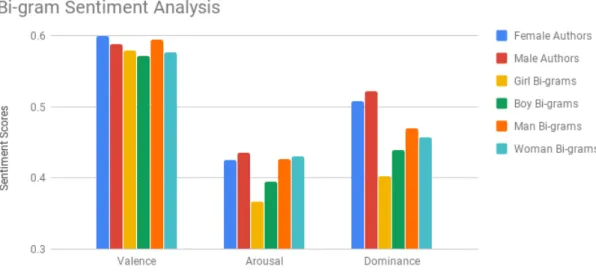
Similar to the Arousal scores, this meant that, on average, boys and girls were more likely to be described as weak and low in control. These ideas are supported by the lists of top occurrences of digrams and the word cloud results shown in Figure 4.3 and Figure 4.4. Now that we have reviewed the bigrams 'boy' and 'girl', 'woman' and 'man' will be analyzed.
The results presented above have a similar pattern to the BVAD and GVAD results, but to a lesser degree. The woman's VAD score (WVAD) is one standard deviation below the CVAD, meaning that women are described in an unpleasant or negative way compared to men. Arousal scores for both the WVAD and MVAD were also within one standard deviation of the CVAD arousal score, meaning they are referenced to the same activation/passivity scale.
WVAD for dominant deviation is 2.5 standard deviations below CVAD, while MVAD is 1.9 standard deviations below.

Conclusion
This is most prevalent in girls' bigrams, who are 4.6 standard deviations below the corpus mean. Because of this, it can be argued that young girls, more often than men or older women, will be described as more calm and passive. This is especially true for the girls' bigrams, who scored 4.7 standard deviations below the mean.
Conclusion
Results
Using the NRC VAD Lexicon, showed that while both genders had fairly equal valence, arousal, and dominance score averages, there was a drop in sentiment scores when looking at gender bigrams. Especially in the case of girl and boy bigrams, the lexicon scores were many standard deviations below the mean, meaning that they were more often described as calm, passive and weak. Similar results were found for male and female bigrams, but the scores were not as variable as the girl and boy scores.
Further Areas of Study
Conclusion
In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing, pages 579–586.