When port-based mechanisms lost their effectiveness, the solution was to use deep packet inspection (DPI) techniques, often used by network intrusion detection systems (NIDS) for security purposes, to identify traffic by used signatures in the contents of packages. Most classification methods can be applied to classify traffic from different types of applications. They also described many research works in the field of traffic classification and provided a theoretical comparison of the results obtained from four different studies.
Passive measurements are therefore particularly useful for traffic management, as they obtain important knowledge about traffic behaviour. A special case of packet filtering is the use of packet sampling methods [Amer and Cassel 1989], the purpose of which is to randomly (or pseudorandomly) select a small set of the packets observed at the measurement point. The resulting set of packets is intended to be as representative as possible of the traffic one plans to measure.
DPI methods, usually the most accurate, are based on inspection of the packets' payload. Inspecting the contents of IP packets, as discussed in the previous section, is not always a valid option for identifying application-level protocols. Therefore, new methods have been developed that do not make use of the deep inspection of the packages.
2008], is to classify the traffic using behavioral or statistical patterns based on flow-level data or generic properties of the packets [Moore et al.

Traffic Classification Using Active Crawlers
Statistical mechanisms. Statistical methods usually rely on flow- and packet-level characteristics of the traffic, such as flow duration and size, inter-arrival times, IP addresses, TCP and UDP port numbers, TCP flags, packet size, etc. Heuristic-based methods. Many behavioral mechanisms for traffic classification are based on a predefined set of heuristics. Although a large part of them are common to the majority of research works, different combinations or sets are proposed in several studies.
Typical heuristics are the network diameter, the presence of nodes that act as both client and server, the number of hosts a user communicates with, the source-destination IP pairs using both TCP and UDP, the number of different addresses and ports a user has . connected to, etc. In general, the set of heuristics is checked sequentially, and depending on the result, the packet (or stream) is classified as belonging (or not) to a particular application-level protocol. Machine learning techniques. A large part of the studies propose classification mechanisms based on various supervised or unsupervised ML techniques, such as Bayesian estimators or networks [Moore and Zuev 2005; Auld et al.
They collect a set of traffic characteristics which they associate using probabilistic functions, associating each packet or flow into a particular class.
Ground Truth Verification
However, such an approach will depend on the accuracy of the classifiers used as a baseline. Alternatively, hand classification can be used to verify the ground truth information of the tracks [Moore and Zuev 2005]. It makes use of the packet payload inspection and several heuristic rules to derive the truth information, and it provides a graphical interface to facilitate manual verification of traffic traces.
Relying on an alternative classifier to work as a ground reference enables the identification of the ground truth in each trace, regardless of the size of the network. Of course, this also depends on how challenging the target application is to classify and the composition of the traces being analyzed. On the other hand, although manual traffic verification can enable better accuracy, it is only feasible for small data sets.
The method used to assess ground truth is of great importance for the quality of the evaluation results. Therefore, one should be aware of the capabilities and limitations of each method when evaluating a classification.
Performance Evaluation Metrics
Two of those measures, precision and recall, are used together to evaluate classification methods and are defined as follows [Nguyen and Armitage 2008b]. These metrics are used to evaluate the ability of the classifier to correctly identify the positive cases. Precision, also referred to as positive predictive value, evaluates how correctly the cases identified as positive by the classifier are, while recall, also referred to as hit rate or true positive rate, is the percentage of positive cases included in the dataset that are correct has been identified, expressed. by the classifier.
This means that if a C1 classifier returns, for example, ten false positives out of ten negatives and a C2 classifier returns an equal number of false negatives and true positives and ten false positives out of 1000 negatives, both classifiers will have the same accuracy and re- - call. However, C2 can be considered to have better performance, as it failed to correctly identify only 1% of negative cases, while C1 was unable to identify any negative cases. Furthermore, the accuracy obtained for a data set containing an extremely low percentage of positive cases may be affected by the high prevalence of negative cases.
In such contexts, even a very small percentage of negative cases falsely classified as positive cases may be enough to overcome the number of true positive cases identified by the classifier, due to the shortage of positive cases in the data set. In these situations, it may be beneficial to consider statistics that evaluate the classification of positive and negative cases separately. Therefore, recall can be used in conjunction with another measure, specificity, which is defined as follows [Wang 2008].
Sensitivity measures the ratio of correctly classified positive cases to the total number of positive cases, while specificity estimates the correctly classified negative cases. In the context of traffic classification, sensitivity and specificity are particularly useful for evaluating classifiers that are focused on a specific class that constitutes a minority of the traffic in a data set, for example, a classifier designed to identify broadcast video or Voice over Internet Protocol (VoIP) traffic. 2005a] defined a different recall-like metric, which they called completeness, and used it together with precision, which they called precision.
To the best of our knowledge, the two measures were also used by Callado et al. Completeness measures the ratio of classified positive cases, correctly or incorrectly, to the total number of positive cases and is defined as follows. The criteria used to evaluate a classifier should be chosen depending on the context and purpose of each classifier.
DISCUSSION OF THE STATE OF THE ART ON TRAFFIC CLASSIFICATION
- Port-Based Classification
- Deep Packet Inspection Classification
- Classification Based on Active Mechanisms
- Classification through the Combination of Approaches
- Applications for Traffic Classification
- Summary and Challenges
They used the mechanism to classify traces collected on a university link, leaving only 2% of the traffic unclassified (98% recall). Besides these strategies, to verify the classification of the remaining streams, the authors identified the streams using defaultBitTorrentports and the default Gnutella port (6346). They evaluated the performance of the classifier using traffic from an academic network and compared the results with a signature-based method.
They analyzed the performance of the method using traffic traces collected on a university link and compared the results with a supervised ML technique, a Na¨ıve Bayes classifier. The authors used the size of the first packets of each flow as a feature for traffic classification and trained the mechanism using previously classified data through DPI. 2009] described a new approach to traffic classification that relies on identifying the service that generates the traffic.
Nevertheless, in the test conducted on the Internet connection of a university campus, the mechanism was able to classify 81% of the packets and 93%. Since the aim of the study was to characterize both systems, the presented results are not focused on the classification accuracy, but on the characteristics of the traffic. The authors also described a module for classifying the traffic using payload signatures, which was used in the training of the neural network.
They evaluated the mechanism using traces collected in various buildings on the university campus and verified by hand. The effectiveness of the solution was analyzed using the traffic covered by the network of five mobile operators in Europe and Asia. By manually creating traces, authors can be sure of the applications that generated the traffic.
The fifth data set was formed by the traffic in only one direction of the track from the academic backbone. Although mostly tested with ML algorithms, the method is independent of the classifiers. Nevertheless, the lower accuracy values were obtained for the datasets containing only one direction of the currents.
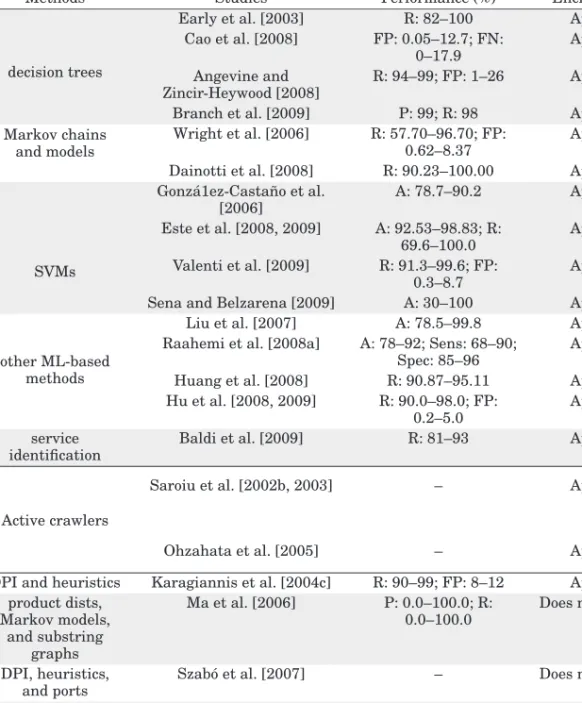
Its sole purpose is to provide an overview of the behavioral methods presented in the literature. The evaluation results were included to make it easier to see the effectiveness of each method.
CONCLUSIONS