Shared virtual memory - so host code and devices can share complex pointer-based structures such as trees and linked lists, eliminating expensive data transfers between host and devices. Dynamic parallelism - so device cores can run on the same device without interacting with the host, eliminating significant bottlenecks.
CHAPTER
- INTRODUCTION TO HETEROGENEOUS COMPUTING
- THE GOALS OF THIS BOOK
- THINKING PARALLEL
- Thinking parallel 3
- Thinking parallel 5
- Concurrency and parallel programming models 7
- CONCURRENCY AND PARALLEL PROGRAMMING MODELS
- THREADS AND SHARED MEMORY
- Message-passing communication 9
- MESSAGE-PASSING COMMUNICATION
- DIFFERENT GRAINS OF PARALLELISM
- Different grains of parallelism 11
- DATA SHARING AND SYNCHRONIZATION
- SHARED VIRTUAL MEMORY
- HETEROGENEOUS COMPUTING WITH OPENCL
- Book structure 13
- BOOK STRUCTURE
Whether using threaded shared memory or explicit message passing, we can also vary the size (ie, granularity) of the parallel execution unit. The grain of parallelism is limited by the inherent characteristics of the algorithms that make up the application.
INTRODUCTION
To that end, OpenCL has a set of functions that attempt to detect unique hardware capabilities (for example, in this chapter we discuss some of these devices and the overall design space in which they reside.
HARDWARE TRADE-OFFS
In reality, we see combinations of these factors in different designs with different target markets, applications and price ranges. In this section, we examine some of these architectural features and discuss the extent to which various common architectures employ them.
Hardware trade-offs 17
- PERFORMANCE INCREASE WITH FREQUENCY, AND ITS LIMITATIONSAND ITS LIMITATIONS
- SUPERSCALAR EXECUTION
Superscalar and, by extension, out-of-order execution is a solution that has been included on CPUs for a long time; it has been included in x86 designs since the beginning of the Pentium era. In these designs, the CPU maintains dependency information between instructions in the instruction stream and schedules work on unused functional units where possible.
Hardware trade-offs 19
- VERY LONG INSTRUCTION WORD
In the example in Figure 2.2, we see that the instruction scheme has gaps: the first two VLIW packets are missing a third input, and the third VLIW packet is missing its first and second inputs. In the latter case, the situation will be no worse than for excluded execution, but will be more efficient since the scheduling hardware is reduced in complexity.
Hardware trade-offs 21
- SIMD AND VECTOR PROCESSING
- HARDWARE MULTITHREADING
A significant amount of code is not data parallel, and therefore it is not possible to find vector instructions to issue. As previously discussed, extracting independent instructions from an instruction stream is difficult, in terms of both hardware and compiler work, and is sometimes impossible.
Hardware trade-offs 23
When a thread reaches some kind of stall, it can be removed from the ready queue, so that only threads in the ready queue are scheduled for execution. Taken to an extreme, this kind of heavy multithreading can be seen as throughput computing: maximizing throughput at the expense of latency.
Hardware trade-offs 25
- MULTICORE ARCHITECTURES
- INTEGRATION: SYSTEMS-ON-CHIP AND THE APU
The AMD Puma (left) and Steamroller (right) high-level designs (not shown on a shared scale). For example, looking at the high-level AMD Radeon HD 6970 chart in Figure 2-8 shows a similar approach from Bulldozer taken to an extreme.
Hardware trade-offs 27
- CACHE HIERARCHIES AND MEMORY SYSTEMS
Spatial: Two or more memory accesses read or write addresses that are somewhat close to each other in memory. Temporal: Two or more memory accesses read or write the same address in a relatively small time window.
The architectural design space 29
THE ARCHITECTURAL DESIGN SPACE
- CPU DESIGNS
Most variants on the ARM ISA were in-order cores with three to seven pipeline stages. In general, low-power CPUs can be characterized by in-order or narrowly out-of-order execution with relatively narrow SIMD units.
The architectural design space 31
It is the compiler's job to package instructions into the VLIW/EPIC packets, and as a result, performance on the architecture is highly dependent on the compiler's capabilities. To help with this, numerous execution masks, dependency flags between bundles, prefetch instructions, speculative loads, and rotating register files are built into the architecture.
The architectural design space 33
- GPU ARCHITECTURES
The AMD Radeon R9 290X architecture seen in Figure 2.10 has 16 SIMD lanes in hardware and uses vector pipelines to execute a 64-element vector over four cycles. The AMD Radeon R9 290X design issues multiple instructions per cycle, each from a different active program counter, where a vector instruction will be issued each cycle to a different vector unit.
The architectural design space 35
Each SMX has 12 SIMD units (with specialized double-precision units and special functions), a single L1 cache, and a read-only data cache.
The architectural design space 37
- APU AND APU-LIKE DESIGNS
The GPU is part of Intel's HD-series GPU design with full OpenCL and DirectX 11 capabilities. This advantage may be because the GPU's throughput-based design is not optimal for serial code, and the APU design may shorten the lead time of mixing CPU and GPU code, or because the algorithms are a communication bottleneck.
SUMMARY
4] Sandet Brobue; http://www.intel.com/content/dam/doc/manual/64-ia-32-architec tures-optimization-manual.pdf. 5] Haswell Arch;http://www.intel.com/content/dam/www/public/us/en/documents/manuals /64-ia-32-architectures-optimization-manual.pdf.
INTRODUCTION
- THE OpenCL STANDARD
- THE OpenCL SPECIFICATION
The code that runs on an OpenCL device, which is generally not the same device as the host central processing unit (CPU), is written in the OpenCL C language. Execution Model: Defines how the OpenCL environment is configured by the host, and how the host can direct the devices to perform work.
Kernel programming model: Defines how the concurrency model is mapped to physical hardware
While the OpenCL API itself is a C API, there are third-party bindings for many languages, including Java, C++, Python, and .NET. The concurrency model defines how an algorithm is decomposed into OpenCL work items and work groups.
Memory model: Defines memory object types, and the abstract memory hierarchy that kernels use regardless of the actual underlying memory
- The OpenCL platform model 43
- THE OpenCL PLATFORM MODEL
- PLATFORMS AND DEVICES
- The OpenCL execution model 45
- THE OpenCL EXECUTION MODEL
- CONTEXTS
- The OpenCL execution model 47
- COMMAND-QUEUES
- EVENTS
- The OpenCL execution model 49
- DEVICE-SIDE ENQUEUING
- KERNELS AND THE OpenCL PROGRAMMING MODEL
- Kernels and the OpenCL programming model 51
- Kernels and the OpenCL programming model 53
- COMPILATION AND ARGUMENT HANDLING
- Kernels and the OpenCL programming model 55
- STARTING KERNEL EXECUTION ON A DEVICE
- OpenCL MEMORY MODEL
- MEMORY OBJECTS
- OpenCL memory model 57
- OpenCL memory model 59
- DATA TRANSFER COMMANDS
- MEMORY REGIONS
- OpenCL memory model 61
- GENERIC ADDRESS SPACE
- THE OpenCL RUNTIME WITH AN EXAMPLE
- The OpenCL runtime with an example 63
The OpenCL memory model describes the structure of the memory system exposed by an OpenCL platform to an OpenCL program. Writing and reading from buffers is shown in the vector addition at the end of the chapter.
Discovering the platform and devices: Before a host can request that a kernel be executed on a device, a platform and a device or devices must be discovered
Discover the platform and devices: Before a host can request that a kernel run on a device, a platform and a device or devices must be discovered. In the full program listing that follows, we will assume that we are using the first platform and device found, which will allow us to reduce the number of function calls required.
Creating a context: Once the device or devices have been discovered, the context can be configured on the host
Creating a command-queue per device: Once the host has decided which devices to work with and a context has been created, one command-queue needs
Creating buffers to hold data: Creating a buffer requires supplying the size of the buffer and a context in which the buffer will be allocated; it is visible to all
- The OpenCL runtime with an example 65
The API call has a command-queue argument, so data is likely being copied directly to the device. Write data from the input arrays to buffer state = clEnqueueWriteBuffer(cmdQueue, bufA, CL_TRUE, 0, . datasize, A, 0, NULL, NULL);.
Creating and compiling a program from the OpenCL C source code: The vector addition kernel shown in Listing 3.3 is stored in a character array,
Copy the input data to the device: The next step is to copy data from a host pointer to a buffer. Creating and compiling a program from the OpenCL C source code: The vector addition kernel shown in Listing 3.3 is stored in a character array.
Extracting the kernel from the program: The kernel is created by selecting the desired function from within the program
Copy the output data back to the host: This step reads the data back into a pointer on the host.
Copying output data back to the host: This step reads data back to a pointer on the host
Releasing resources: Once the kernel has completed execution and the resulting output has been retrieved from the device, the OpenCL resources that were
- COMPLETE VECTOR ADDITION LISTING
- The OpenCL runtime with an example 67
- Vector addition using an OpenCL c++ wrapper 69
- VECTOR ADDITION USING AN OpenCL C++ WRAPPER
- OpenCL for cuda programmers 71
- OpenCL FOR CUDA PROGRAMMERS
- SUMMARY
A comparison of OpenCL and CUDA versions of the vector addition example is shown in Listing 3.6. With OpenCL, platforms are discovered at runtime, and the program can also select a target device at runtime.
OpenCL EXAMPLES
This chapter discusses some basic OpenCL examples that allow us to summarize our understanding of the specifications discussed in Chapter 3. In addition, lists of utility functions used within the examples are provided at the end of the chapter.
HISTOGRAM
The examples discussed here serve as a starting point to compare more optimized code, which can be written after studying later chapters. The utility functions include code to check and report OpenCL errors, to read OpenCL programs from file to string (required for program creation), and to report program compilation errors.

Histogram 77
However, implementing a per-workgroup histogram comes with an extra wrinkle: we now have race ratios in local memory. Therefore, atomic operations on local memory are much cheaper than atomic access to global memory.
Histogram 79
Except for the initialization of the histogram buffer, the host-side program is very similar to the host program in the vector addition example in Chapter 3. Listing 4.2 provides the complete source code for the histogram host program. The kernel source in Listing 4.1 will need to be stored in a file named histogram.cl to be read by Listing 4.2.
Histogram 81
Image rotation 83
IMAGE ROTATION
In this kernel we use read_imagef(). line 38), since we are working with floating point data. Since we're working with a single-channel image (described next), we're only interested in the first component, which we access by appending .x to the end of the function call (line 38).
Image rotation 85
The pixel type and channel layout within the image are specified using an image format (typecl_image_format). Thus, an image that will hold a four-element vector type must use CL_RGBA for the channel order within the image format.
Image rotation 87
Image rotation 89
Image convolution 91
IMAGE CONVOLUTION
Image convolution 93
In this case, we create a sampler with the host API and pass it as a kernel argument. In this example, we will use the C++ API (the C++ sampler constructor has the same parameters).
Image convolution 95
Image convolution 97
Producer-consumer 99
PRODUCER-CONSUMER
The function returns 0 if a packet was read from the pipe, or a negative value if the pipe is empty. The function returns 0 if a value has been written to the pipe, or a negative value if the pipe is full.
Producer-consumer 101
Using multiple devices with this app requires a few extra host setup steps compared to the examples we've seen so far. When creating a context, two devices (one CPU device and one GPU device) must be supplied, and each device requires its own command queue.
Producer-consumer 103
Producer-consumer 105
Utility functions 107
UTILITY FUNCTIONS
- REPORTING COMPILATION ERRORS
- CREATING A PROGRAM STRING
Therefore, a more common use case is to create a separate file containing the OpenCL C source and read that file into a string within the host program.
Summary 109
SUMMARY
OpenCL supports a wide range of devices, ranging from discrete graphics processing unit (GPU) cards with thousands of "cores" to small embedded central processing units (CPUs). To achieve such broad support, it is essential that the memory and execution models for OpenCL are defined in such a way that we can achieve a high level of performance across a range of architectures without extraordinary programming effort.
COMMANDS AND THE QUEUING MODEL
- BLOCKING MEMORY OPERATIONS
- EVENTS
As the command moves in and out of the command queue and through its stages of execution, its status is constantly updated within its event. Sent: The command has been removed from the command queue and sent for execution on the device.
Commands and the queuing model 113
- COMMAND BARRIERS AND MARKERS
- EVENT CALLBACKS
- PROFILING USING EVENTS
The command_exec_callback_type parameter is the parameter used to specify when the callback should be invoked. For example, if different callbacks are registered for CL_SUBMITTED and CL_RUNNING, while state changes are guaranteed to occur in sequential order, the callback functions are not guaranteed to be processed in order.
Commands and the queuing model 115
- USER EVENTS
- OUT-OF-ORDER COMMAND-QUEUES
An out-of-order queue does not have a default order of operations defined on the queue. Setting this property will create an out-of-order queue on devices that support out-of-order execution.
Commands and the queuing model 117
MULTIPLE COMMAND-QUEUES
Multiple command-queues 119
The command queued on the CPU waits for both kernels on the GPU to finish executing. The enqueued kernel in the CPU command queue waits for the kernels in the GPU command queues to complete.
The kernel execution domain 121
OpenCL's hierarchical execution mode takes it a step further, because the set of work items within a work set can be efficiently mapped to a smaller number of hardware thread contexts. Although work items are executed in steps, different work items can execute different instruction sequences of a kernel.
The kernel execution domain 123
- SYNCHRONIZATION
To resolve this issue, OpenCL 2.0 removed the requirement that NDRange dimensions must be a multiple of workgroup dimensions. Instead, OpenCL 2.0 defines residual workgroups as the boundaries of the NDRange, and the final workgroup need not be the same size as defined by the programmer.
The kernel execution domain 125
- WORK-GROUP BARRIERS
In Chapter 7, we'll go over the details regarding the scope parameter (and go deeper into the flags parameter). In the following example, we see work items caching data in local memory, where each work item reads a value from a buffer and requires it to be exposed.
The kernel execution domain 127
- BUILT-IN WORK-GROUP FUNCTIONS
- PREDICATE EVALUATION FUNCTIONS
The workgroup evaluation functions are defined for all OpenCL C built-in data types, such as half,int,uint,long,ulong,float anddouble. The predicate evaluation functions evaluate a predicate for all work items in the work group and return a non-zero value if the associated condition is satisfied.
The kernel execution domain 129
- BROADCAST FUNCTIONS
- PARALLEL PRIMITIVE FUNCTIONS
Most parallel programmers will be familiar with the prefix-sum operation, which can be implemented using work_group_scan_inclusive_add() or. Each work item provides and returns the value corresponding to its linear index within the work set.
NATIVE AND BUILT-IN KERNELS
- NATIVE KERNELS
The inclusive and exclusive versions of the scan operations specify whether or not the current element should be included in the calculation. The order of floating-point operations is not guaranteed for parallel primitive functions, which can be troublesome since floating-point operations are not associative.
Native and built-in kernels 131
- BUILT-IN KERNELS
The semantics of a built-in core can be defined outside of OpenCL, which is why implementation is defined. An example of built-in core infrastructure is the motion estimation extension for OpenCL released by Intel.
DEVICE-SIDE QUEUING
The common use of embedded kernels is to expose fixed-function hardware acceleration capabilities or embedded firmware associated with a specific OpenCL device or custom device. This extension depends on the OpenCL built-in core infrastructure to provide an abstraction for leveraging the domain-specific acceleration (for motion estimation in this case) in Intel devices that support OpenCL.
Device-side queuing 133
CLK_ENQUEUE_FLAGS_WAIT_KERNEL: The child kernel must wait for the parent kernel to reach the ENDED before executing. It is also important to note that the parent core cannot wait for the child core to complete execution.
Device-side queuing 135
- CREATING A DEVICE-SIDE QUEUE
- ENQUEUING DEVICE-SIDE KERNELS
Optionally, an additional argument, CL_QUEUE_ON_DEVICE_DEFAULT, can be provided to clCreateCommandQueueWithProperties(), making the command queue the "default" device-side command queue for the device. When we enqueue kernels for device-side commands with enqueue_kernel(), there is no equivalent mechanism to set arguments.
Device-side queuing 137
As a toy example to illustrate argument passing, we can modify vector addition so that the parent enqueues a child core to perform the work. Listing 5.11 shows the passing of argument when we create a block variable, and Listing 5.12 shows what argument passes when we use a block literal.
Device-side queuing 139
Device-side queuing 141
SUMMARY
The host-side memory model is important within the host program and involves allocating and moving memory objects. The device-side memory model discussed in the next chapter is important in kernels (written in OpenCL C) and involves performing calculations using memory objects and other data.
MEMORY OBJECTS
- BUFFERS
It is important to note that OpenCL's memory objects are defined in a context and not on a device. It is the job of the runtime to ensure that data is in the right place at the right time.
Memory objects 145
- IMAGES
Image objects mainly exist in OpenCL to provide access to special feature hardware on graphics processors designed to support highly efficient access to image data. The main difference between buffers and host images is in the formats that images can support.
Memory objects 147
- PIPES
Further, since a pipe cannot be accessed by the host, CL_MEM_HOST_NO_ACCESS will also be used implicitly, even if this is not specified by the programmer.
MEMORY MANAGEMENT
Memory management 149
- MANAGING DEFAULT MEMORY OBJECTS
An example showing a scenario where a buffer is created and initialized on the host, used for computation on the device, and transferred back to the host. Note that the runtime could also have created and initialized the buffer directly on the device. a) Creating and initializing a buffer in host memory.
Memory management 151
The write call specifies a copy from the host to the device (technically for global memory only), and the read call specifies a copy from the device to the host. That is, if we call clEnqueueReadBuffer(), we cannot expect to be able to read the data from the host array until we know that the read has finished - through the event mechanism, the aclFinish() call, or by passing.
Memory management 153
In addition to transferring data between the host and device, OpenCL provides a command, clEnqueueMigrateMemObjects(), to migrate data from its current location (wherever that may be) to a specified device. MEM_OBJECT_HOST that tells the runtime that the data should be migrated to the host.
Memory management 155
- MANAGING MEMORY OBJECTS WITH ALLOCATION OPTIONS
Since CL_MEM_USE_HOST_PTR and CL_MEM_ALLOC_HOST_PTR indicate that data must be created in host-accessible memory, the OpenCL specification provides a mechanism for the host to access the data without going through the explicit read and write API calls. In order for the host to access the data storage of a memory object, it must first map the memory object to its address space.
Memory management 157
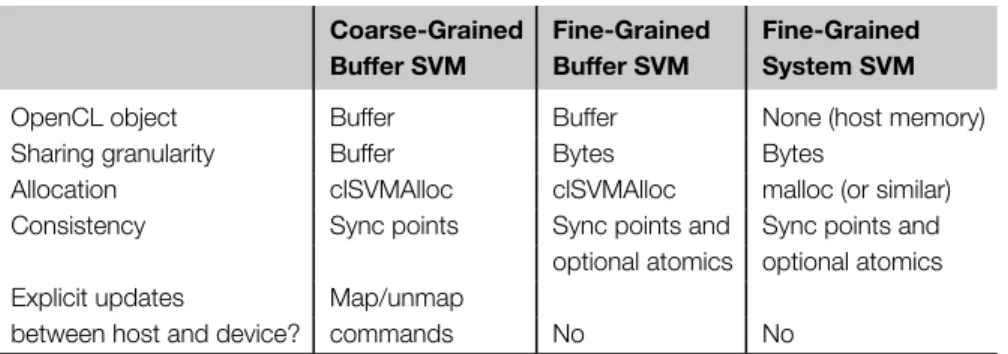
Shared virtual memory 159
SHARED VIRTUAL MEMORY
When clEnqueueMapBuffer() returns, all memory operations performed by the kernel in that buffer area will be visible to the host. If (optional) atomic SVM operations are supported, fine-grain buffer SVM can be used by the host and device to simultaneously read and update the same area of the buffer.
Summary 161
SUMMARY
The memory model also defines the memory consistency that work items can expect in each memory space. Before discussing memory spaces in detail, the following section outlines the capabilities of work items to synchronize and communicate.
SYNCHRONIZATION AND COMMUNICATION
Image arguments always live in the global address space, so we discuss images in those terms.
Synchronization and communication 165
- BARRIERS
- ATOMICS
When used for synchronization, atomics are used to access special variables (called synchronization variables) that enforce parts of the memory consistency model. As mentioned earlier, atomicity is used to ensure that threads do not see partial results in a series of events - this is a problem with shared memory concurrent programming.
Synchronization and communication 167
On some GPU architectures, for example, atomics are performed by hardware units in the memory system. Thus, certain types of atomic operations can be considered completed as soon as they are issued to the memory hierarchy.
GLOBAL MEMORY
- BUFFERS
However, using the returned value requires data to be returned to the compute unit, potentially adding tens to hundreds of latency cycles. The reason why atoms are discussed as part of the memory model chapter is that they now play a fundamental role in synchronization.
Global memory 169
- IMAGES
It is the sampler object that defines how the image is interpreted by the hardware or runtime system. The sampler object determines the addressing and filtering modes used when accessing an image, and whether the coordinates passed to the function are normalized or not.
Global memory 171
If we go further by setting up our computation in a two-dimensional layout (as we see in the graphics pipeline), we further improve this data locality. This kind of optimization is transparently possible (and so different optimizations can be done on different architectures) only if we don't give the kernel programmer any guarantees about the relative locations of memory elements.
Global memory 173
- PIPES
When reservation identifiers are used, OpenCL C provides blocking functions to ensure that the read or write has completed: commit_read_pipe() and. Once the function call has returned, it is safe to assume that all reads and writes have been completed. tube genotype p,. backup_id_t backup_id).
Local memory 175
CONSTANT MEMORY
LOCAL MEMORY
Local storage is most useful because it provides the most efficient method of communication between work items in a work group. Any allocated local storage buffer can be accessed by the entire workgroup at any location, so writes to the local array will be visible to other work items.
Local memory 177