A key feature of KDIPC is the use of a semaphore interface to support distributed synchronization. In the continuation of the diploma thesis, the specification of the system and a detailed discussion of the implementation of this library are presented.
Overview
Applications
Problem statement
Contributions
Preserving semantics
The decision to extend the System V IPC API was also motivated by the belief that programs designed for shared-memory parallel machines and those designed for distributed environments should have the same semantics regarding shared objects.
Organization of this thesis
Finally, the model, semantics of the distributed shared memory used in the KDIPC system, and the included application programming interface will be discussed. Shared memory systems cover a very wide range of systems, from multiprocessor machines to loosely coupled systems.
Related work
The lazy release consistency model used by TreadMarks significantly reduced communication bandwidth compared to Munin, but increased the complexity of the distributed shared memory system. The burden of monitoring each shared memory access and adapting the programs to the new semantics of the DSM system was placed entirely on the shoulders of the programmer.
Consistency models
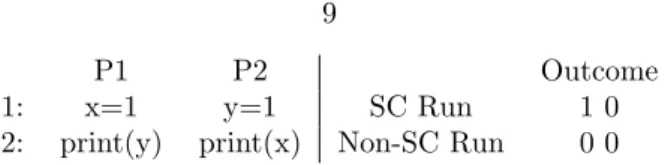
Sequential Consistency
TreadMarks is considered by many to be the state of the art DSM system despite its shortcomings. In the late 90s, there were new efforts to create a DSM system that would be included in Linux distributions.
Eager Release Consistency
Lazy Release Consistency
This requires less communication than in the eager release consistency model because accesses do not need to be committed globally on the next release, but rather are committed by other processes as release operations become visible to them.
The KDIPC approach
Maintaining Single Processor Semantics
System V / KDIPC API
The function shmat attaches the shared memory segment identified by shmid to the address space of the calling process” (shmat man page). The function smdt frees the shared memory segment at the address specified by shmaddr from the address space of the calling process” (smdt man page).
Related work
POSIX Semaphores
There can be multiple implementations, depending on the underlying mechanisms used in the POSIX IPC library deployment. As described in [24], the System V IPC API is a very powerful interface that can be natively used to implement the POSIX standard. A drawback of the POSIX standard is that the naming interface as well as the semaphore interface are not fully defined in the specification.
System V Semaphores
Richard Stevens [24] presents several possible implementations of the POSIX semaphore interface, one of which is of interest to us as it uses the System V IPC API (discussed in Section 3.4). Otherwise, the process calling the semop function is put to sleep until all the operations described by the function parameters are simultaneously successful. The type of control operations performed include getting the value of one or all semaphores in a semaphore set, initializing the value of one or all semaphores in a semaphore set to a specified value, and marking the semaphore set for deletion.
Distributed Semaphores
Synchronization in TreadMarks
On the other hand, bottlenecks prevent one process from progressing until all other processes reach the barrier. The semaphore and barrier values are initialized during an initialization section required when the Tmk initialization function is called. Variation of the executed code is achieved by manually verifying the process ID and taking different actions depending on the value of theTmk.proc.id variable.
KDIPC approach
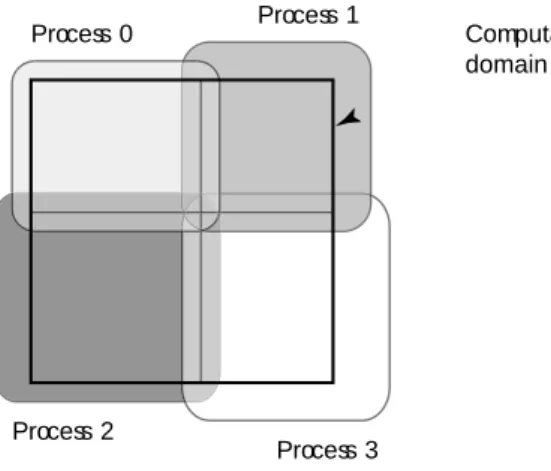
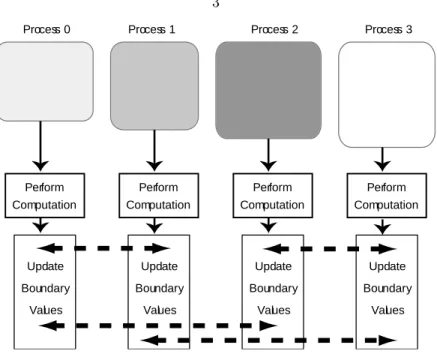
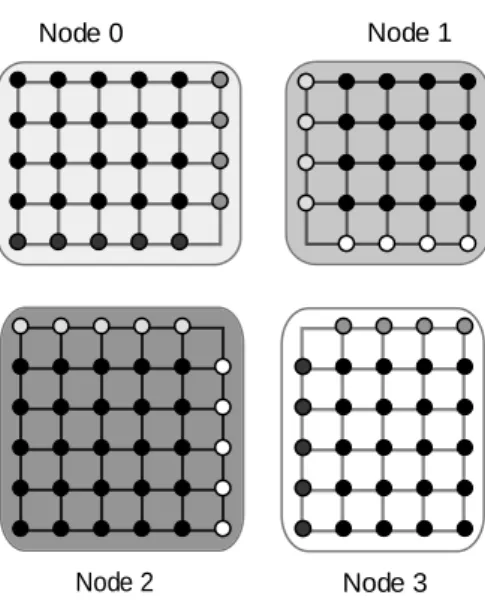
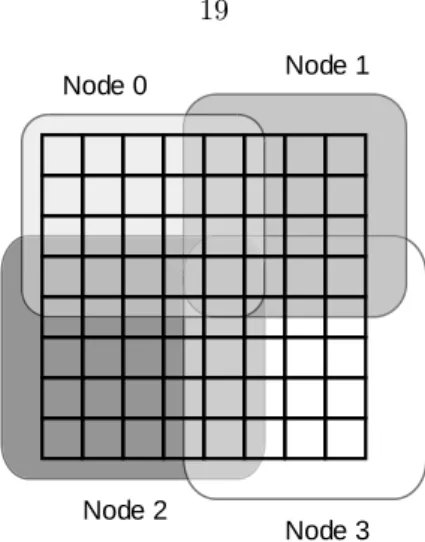
The breakdown of the computational grid and the distribution of work for a simple example are presented in Figures 4.1 and 4.2. This parallelization of computation allows nodes to compute local information and only need limited boundary information from their neighbors. An array is characterized by its size, the number of rows and columns of the grid, and a pointer to the actual data.
System V implementation
Each node information is associated with a given key, known by all nodes in the computation grid. Each node maps its local information into the self variable and maps its neighbors' information into the neighbor array. It is important to note that a node only needs to know the keys for its neighbors, and it does not need to have global knowledge of the keys related to the information of all the nodes in the system.

KDIPC implementation
TreadMarks implementation
As shown in Figure 4.8, some of the explicit locks have the sole purpose of ensuring memory consistency and cluttering the computation code. Furthermore, the bottleneck synchronization mechanism provided by Treadmarks cannot be applied to only a subset of the processes doing cooperative computation. This affects the overall performance of the calculation, slowing down all the nodes of the system to the speed of the slowest node.
Conclusion
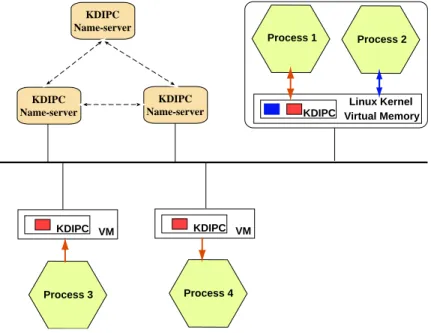
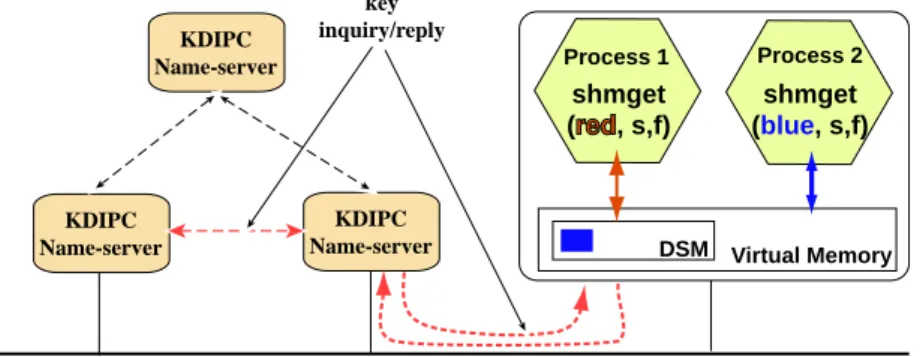
KDIPC name servers
KDIPC name servers have a functionality very similar to that of network name server: name resolution. When a distributed key is used on a node in the system, the node interacts with the name servers to find out if the key has been used before and which nodes have used it before.
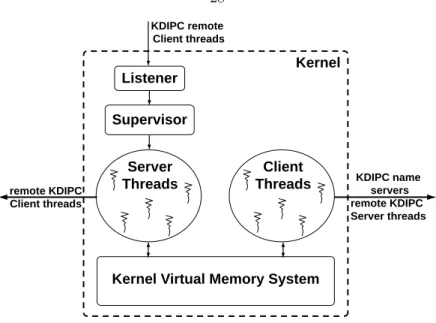
KDIPC kernel modules
- The Listener
- The Supervisor
- The Server
- The Client
Although not very intuitive, the separation between the functionality of the Listener thread and the Supervisor thread is very clear. The server threads, along with the client threads, are the core of the interface between the local KDIPC modules and remote KDIPC core modules. The kernel identifies the shared object and the key associated with it and wakes up one of the client threads.
Protocol description
Shared Object Creation/Mapping
If the key has not previously been seen by the KDIPC kernel module, the request is forwarded to the nearest KDIPC name server. Once the information is received by the requesting node, a local ID is generated and the system call returns control to the user. In the current implementation of the KDIPC system, the delay for retrieving the information associated with a given distributed IPC key occurs during the call to the shm/semget system call.
Shared Objects Accesses
- Shared Memory Accesses
- Shared Semaphore Set Access
The values of the semaphores in the semaphore set S are presented in the figure together with the operations that define the accesses. We assume that both operations will be applied to the initial value of the sema intent. This queue is used to wake sleeping processes when the values of the semaphores in the semaphore set allow a particular operation to be performed.
Challenges of the implementation
Analysis
For each version of the Matrix Multiplication Program, there is a main thread that creates the matrices to be multiplied and separate threads that make the actual calculation of the performance matrix. For the parallel version of the Matrix Multiplication Program, the results shown include the time to start the cloned thread from the main thread, but that does not include the actual time of the start of the whole process. The main point is that none of the two versions that provide better on a per thread basis can surpass the total driving time of the DSM Matrix multiplication program because they are bound to run on a single computer.
Future Work
As shown in Figure 6.1, the KDIPC version of the DSM implementation always outperforms the message passing version and is not much worse than the parallel or local shared memory version. To determine on which side of the kernel-user boundary the KDIPC implementation should reside, a series of benchmarks were used to measure the context switching time between two processes and the time required to move a large block of data across the network. a local area. Network (LAN). While this is not a complete coverage of the entire implementation, it does show the major steps taken to implement the KDIPC system at the kernel level.
KDIPC kernel changes
Each module that composes the KDIPC system will be described by its interaction with the kernel and the kernel data structures. Thekdipcmodule contains all the glue code that enables the interaction between the kernel and the KDIPC modules. The decision to enhance kernel data structures with KDIPC-specific fields was made to reuse the helper functions used by the kernel and to better integrate the KDIPC system with the Linux kernel.
The new field, called info, contains information that is specific for the KDIPC system and is required in the data structure that is linked to the System V IPC. Het mutex-veld wordt gebruikt om gelijktijdige toegang tot de velden van de datastructuur te voorkomen. Depppte-Envmap fields are used to keep track of the pageabel data that are linked to the shared memory segment and the allocation of these pages in the virtual memory of the process.
Most of the other data structures defined in this file are for administrative purposes only and are not relevant to the description of the KDIPC system. When a new key is declared with the IPC KDIPC flag, KDIPC functionality is required and the kdipc shm get function is called. When kdipc modules are inserted into the kernel, the pointer to the kdipc shm get mod function is updated with the value of the function inside the module.
KDIPC modules
KDIPC glue code - the kdipc module
If the key has not been seen locally before, one of the name servers is contacted, and the name solution is done. When the no page feature is called, it first checks the status of the page. If the page is not present and it has not yet been requested by another thread, one of the customer wires is given the task of removing the page from its remote location.
KDIPC daemon - kdipcd
- The client thread
- The server thread
- Parallel implementation of heat equation application using message passing
- Sequential Consistency. (Variables x and y both start with value 0)
- Work distribution per node
- Data structures and variables used in the example
- Mapping main matrix to local memory
- System V and KDIPC. Mapping the neighbors information to local memory
- System V and KDIPC. Performing computations
- TreadMarks: Mapping matrix and neighbors information
- TreadMarks: Performing computations
- Overview of the KDIPC system
- Architecture of KDIPC modules
- Create a new shared object. The shared memory segment identified by key red is seen
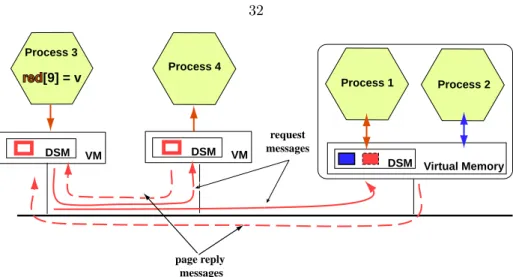
- Retrieve a page from a remote location
- Find a remote page. Node 0 tries to retrieve page associated with key k. Q(k) is a
- The notify mechanism for page location. Node 2 keeps track of Node 0’s request. After
- Accesses to a shared semaphore set
- Effective computation (in sec)
We missed the page so we are waiting for messages q->key=shm_data->perm->key;. If so, we need to contact them, // and see if they still need the page. If we have it, then we need to take it from memory and send it.
Benchmarks for Mojave Cluster
The kern ipc perm data structure in ipc.h
The kdipc info list t data structure defined in kdipc.h
Changes to the sys shmget function in shm.c
The kdipc shm get function defined in kdipc.c
Initialization and clean-up functions for the kdipc module
Pseudo-code for kdipc shm get module function
Pseudo-code for kdipc shmmem nopage module function
Pseudo-code for client thread (kdipcd shm perform task)
Pseudo-code for client thread (place page)
Pseudo-code for server thread (handle kdipc req shm)
Pseudo-code for server thread (send page reply)