2008] proposed an interactive content presenter based on the perceived emotion of multimedia content and the user's physiological feedback. The major drawback of the categorical approach is that the number of primary emotion classes is too small compared to the richness of musical emotion perceived by humans. The major drawback of MER's categorical approach is that the small number of primary emotion classes is too small compared to the richness of music emotion perceived by humans.
This issue of ambiguity and granularity of emotion description gives rise to the proposal of the dimensional approach to MER, as described in Section 5.
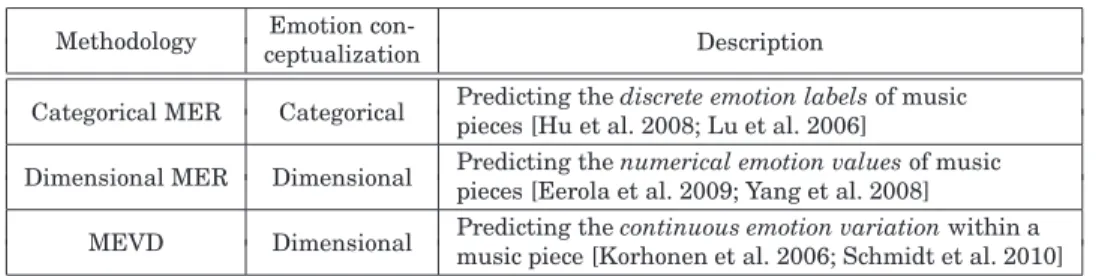
Data Preprocessing
Although the emotion annotations can be made publicly available, this is not the case for the audio files. The audio files are necessary if a researcher wants to extract new music features that may be relevant to emotion perception. In response to this need, the annual MIREX Audio Mood Classification (AMC) task has been held since 2007 with the aim of promoting MER research and providing benchmark comparisons [Hu et al.
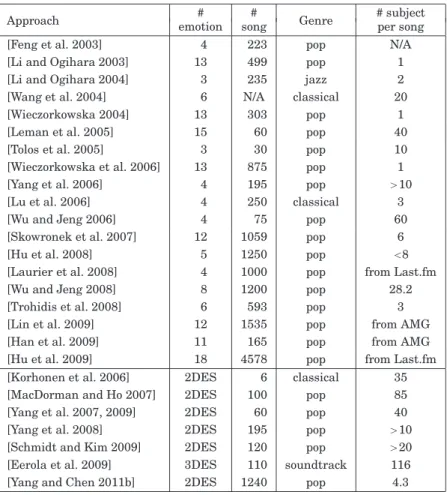
2008].5 The audio files are available to participants in the task who have agreed not to distribute the files for commercial purposes in order to get rid of the copyright issues. A more popular emotion taxonomy is to categorize emotions into four emotion classes, happy, angry, sad, and relaxed, partly because they are related to basic emotions studied in psychological theories and partly because they cover the four quadrants of the two-dimensional valence-arousal. aircraft [Laurier et al. Regarding the length of the music segment, a good note can be found in MacDorman and Ho [2007].
In principle, we like the segment to be as short as possible, so that our analysis of the song's dynamics can also be as fine-grained as possible. The expression of a shorter segment will also tend to be more homogeneous, resulting in higher consistency in an individual listener's ratings. Our literature review reveals that it appears to be common to use a 30-second segment, perhaps because it corresponds to the typical length of a choral section of popular music.
Subjective Annotation
Unfortunately, if the segment is too short, the listener cannot hear enough of it to make an accurate determination of its emotional content. Furthermore, estimates of very short segments lack ecological validity because the segment is stripped of its surrounding context. Because the perception of musical emotion is multidimensional, the following questions may also merit attention: Should we ask subjects to intentionally ignore the text.
Should we use foreign language songs to eliminate the topics influence of lyrics. To reduce the difficulty of subjective annotation, a recent trend is to get emotion tags directly from music websites such as AMG and Last.fm. The advantage of this approach is that it is easy to obtain the annotation of a large number of numbers (e.g. Bischoff et al.
However, the weakness is that the quality of such annotations is relatively lower than that collected by subjective annotations. The other trend is to harness so-called human computation to turn annotation into an entertaining task [Morton et al. More specifically, the idea is to let users contribute emotion annotations as a by-product of playing web-based games [Law et al.
Model Training
Tags in Last.fm can be irregular because they are usually assigned by online users for their own personal use. While playing the game, the player sees a list of semantically related words (eg musical instruments, emotions, uses, genres) and must choose the best and worst word to describe the song. Each player's score is determined by how closely the player's decisions match the decisions of all other players and is immediately displayed to each user.
DIMENSIONAL MUSIC EMOTION RECOGNITION
Model Training
Dimensional MER is usually formulated as a regression problem [Sen and Srivastava 1990] by considering the emotion values (i.e., VA values) as real values in [–1, 1]. More specifically, given N inputs (xi,yi),1 ≤ i ≤ N, where xi is a feature vector of the input sample and yi is the actual value to be predicted, a regression model (regressor) f(·) is created by minimizing the mismatch (i.e. mean squared difference) between the predicted and the ground truth values. Many good regression algorithms, such as support vector regression (SVR) [Sch¨olkopf et al.
It measures the proportion of the underlying data variation explained by the fitted regression model [Montgomery et al. R2 = 1 means that the model fits the data perfectly, while R2 = 0 indicates no linear relationship between the ground truth and the estimate. It is generally observed that valence recognition is much more challenging than arousal recognition [Fornari and Eerola 2008; Korhonen et al.
This is partly because valence perception is more subjective, and partly because it is computationally more difficult to extract features relevant to valence perception, such as musical mode and articulation [Lu et al. Next, we briefly describe SVR for its superior performance for dimensional MER [ Huq et al. For regression, we look for a function f(xs) = mφ(xs) +b that has at most ε deviation from the ground truth ys.
Subjective Annotation
A common kernel function is the radial basis function (RBF):K(xp,xq)≡φ(xp)φ(xq) = exp(−γ||xp−xq||2), where γ is a scale parameter.
Result Visualization
MUSIC EMOTION VARIATION DETECTION
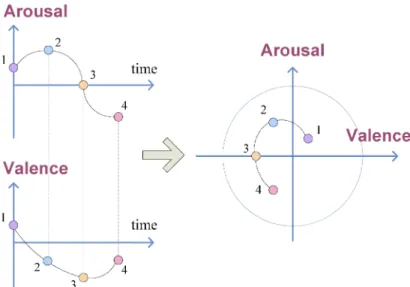
From an engineering perspective, the categorical approach and the dimensional approach offer different advantages that complement each other. With emotion variation detection, we can combine the valence and arousal curves (left) to form the affective curve (right), which represents the dynamic changes of the affective content of a video sequence or piece of music. For example, VA modeling is proposed in Hanjalic and Xu [2005] to detect the emotion variation in movie sequences.
VA values are calculated from the weighted sums of several component functions that are calculated along the timeline. The resulting valence and arousal curves are then combined to form an affective curve that makes it easy to track the emotion variation of the video sequence and identify segments with high affective content [Hanjalic and Xu 2005]. who modeled the emotions of music videos (MVs) and movies using 22 audio features (intensity, timbre, rhythm) and five visual features (motion intensity, frame rate, frame brightness, frame saturation, and color energy) ) and proposed an interface for affective visualization in the timeline.
They followed the approach described in the previous section and independently predicted the VA values for each short video clip. MEVD calculates the VA values of each ephemeral segment and represents a song as a series of VA values (points), while the dimensional MER calculates the VA values of a representative segment (often 30 seconds) of the song and represents it sends number as a single point. However, it should be noted that a dimensional MER system can also be applied to MEVD if we neglect the temporal information and calculate the VA values of each segment independently.
CHALLENGES
Difficulty of Emotion Annotation
Typically, to gather the ground truth necessary for training an automatic model, a subjective test is performed inviting human subjects to annotate the emotion of pieces of music. Since the MER system is expected to be used in the everyday context, the emotion annotation is better performed by ordinary people. However, the emotion annotation process of dimensional MER requires numerical emotion ratings which are not readily available in the online repository.
It is also difficult to ensure a consistent grading scale between different subjects and within the same subject [Ovadia 2004]. As a result, the quality of the ground truth varies, which in turn degrades the accuracy of MER. Since determining the straight sequence of musical pieces is a long process (requiring n(n−1)/2 comparisons), a music emotion tournament scheme is proposed to reduce the burden on subjects.
A subject compares the emotion values of two pieces of music in each match and decides whose emotion value is greater. Empirical evaluation shows that this scheme eases the burden of emotion annotation on the subjects and increases the quality of the ground truth. It is also possible to use an online game to utilize the so-called human computation and make the annotation process more engaging [Kim et al.
Subjectivity of Emotional Perception
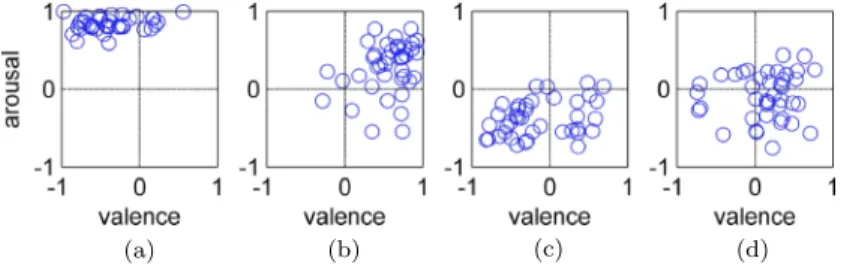
A subject is asked to compare the affective content of two songs and determine, for example, which song has a higher arousal value, rather than the exact emotional values. The musical emotion ranking is then converted to numerical values by a greedy algorithm [Cohen et al. Emotion notes in 2DES for four songs: (a) Smells Like Teen Spiritby Nirvana, (b) A New World by Peabo Bryson and Regina Belle, (c) The Roseby Janis Joplin, (d) Tell Laura I Love Herby Ritchie Valens.
For example, each circle in Figure 6 corresponds to a subject's annotation of the perceived emotion of a song [Yang et al. Most works either assume that a common consensus can be reached (especially for classical music) [Wang et al. This simple method is effective because the music content and the individuality of the user are treated separately.
Motivated by the observation that the perceived emotions of a song actually constitute an emotion distribution in the emotion level (cf. Figure 6), Yang and Chen [2011a]. An emotion distribution can be considered as a collection of users' perceived emotions of a song, and the perceived emotion of a specific user can be considered as an example of the distribution. Semantic gap between low-level music feature and high-level human perception The viability of an MER system lies largely in the accuracy of emotion recognition.
Semantic Gap Between Low-Level Music Feature and High-Level Human Perception The viability of an MER system largely lies in the accuracy of emotion recognition
CONCLUSION AND FUTURE RESEARCH DIRECTIONS
- Exploiting Vocal Timbre for MER
- Personalized Emotion-Based Music Retrieval
- Connections Between Dimensional and Categorical MER
- Considering the Situational Factors of Emotion Perception
We can also allow the users to decide the position of the affective terms and use such information to personalize the MER system. In Proceedings of the AAAI Workshop on Computational Aesthetics: Artificial Intelligence Approaches to Beauty and Happiness. In Proceedings of the International Conference on Music Information Retrieval.http://www.ofai.at/∼elias.pampalk/ma/.
![Fig. 1. Hevner’s eight clusters of affective terms [Hevner 1935].](https://thumb-ap.123doks.com/thumbv2/123dok/10239198.0/5.918.251.666.158.498/fig-hevner-s-clusters-affective-terms-hevner.webp)
![Fig. 2. The 2D valence-arousal emotion space [Russell 1980] (the position of the affective terms are only approximated, not exact).](https://thumb-ap.123doks.com/thumbv2/123dok/10239198.0/6.918.302.617.160.429/valence-arousal-emotion-space-russell-position-affective-approximated.webp)
![Table III. Emotion Taxonomy Adopted in MIREX [Hu and Downie 2007]](https://thumb-ap.123doks.com/thumbv2/123dok/10239198.0/11.918.258.659.177.290/table-iii-emotion-taxonomy-adopted-mirex-hu-downie.webp)
![Fig. 3. In Yang et al. [2008], each song is represented as a point in the 2DES. A user can retrieve music of a certain emotion by simply specifying a point or a path in the plane.](https://thumb-ap.123doks.com/thumbv2/123dok/10239198.0/14.918.248.674.161.478/yang-represented-point-retrieve-certain-emotion-simply-specifying.webp)
![Fig. 5. The ranking-based emotion annotation method proposed in Yang and Chen [2011b], which groups eight randomly chosen music pieces in a tournament of seven matches](https://thumb-ap.123doks.com/thumbv2/123dok/10239198.0/19.918.252.678.154.312/ranking-emotion-annotation-method-proposed-randomly-tournament-matches.webp)
