Organizzazione del lavoro
Un vettore n-dimensionale può essere definito come una sequenza ordinata di n numeri; ad esempio rappresenta un vettore di dimensione 4 in cui il primo elemento è 2 ed il quarto Concludiamo questo paragrafo notando che i componenti di un vettore possono essere nominati, sia al momento della sua costruzione (inserendo i nomi quando si utilizza la funzione c()), sia tramite la funzionenames() per un vettore già esistente:.
Matrici
In una matrice è possibile sostituire completamente una riga (riga o colonna), purché le dimensioni corrispondano. Utilizzando un unico vettore x, è facile vedere che uno scalare e una matrice possono essere ottenuti attraverso x0x e xx0, cioè
Array
L'argomento può essere facilmente generalizzato per espandere il numero di variabili da selezionare e complicare la condizione di inclusione (o esclusione) mediante l'uso simultaneo di altri simboli come &e| considerare. Ad esempio, la funzione as.data.frame() può essere utilizzata per forzare un array di dati in un frame di dati, oppure i dati possono essere inseriti più facilmente tramite un foglio di calcolo: in questo caso, X<-data.frame() crea un frame di dati che puoi quindi aprire con confix(X) per inserire i dati direttamente nelle celle.
Valori mancanti
Il primo argomento specifica il numero massimo di righe da leggere e il secondo il numero di righe iniziali da saltare prima di importare il file. Ciò può essere facilmente ottenuto utilizzando l'argomento na.strings=999 nella funzione read.table() oppure la sostituzione può essere eseguita facilmente come segue. 1] FALSO FALSO FALSO FALSO VERO FALSO FALSO VERO FALSO FALSO Il rilevamento dei dati mancanti è fondamentale per R (così come per noi, ovviamente), poiché alcune funzioni non possono essere utilizzate con i dati mancanti o richiedono particolare attenzione durante l'utilizzo.
Per questo motivo è auspicabile avere il 'pieno controllo' sui dati mancanti: è possibile, ad esempio, selezionare a priori solo i dati non mancanti utilizzando la stessa funzione is.na(). La differenza tra X1 e X2 è che nella prima vengono eliminati solo i record con valori non mancanti per la variabile genere, mentre nella seconda quelli per cui mancano dati anche per la variabile età; in generale, quando mancano dati relativi a più variabili, il frame di sottodati contenente solo voci con valori completi può essere ottenuto tramite la funzione na.omit(), ovvero semplicemente na.omit(X).
Codifica di variabili
La funzione cut() crea una variabile categoriale dividendo la variabile numerica che appare come argomento in intervalli come ]xi, xi+1], dove gli estremi possono o meno essere inclusi a seconda di come vengono forniti gli argomenti include.lowest Giusto; l'inbreak può esprimere sia gli estremi degli intervalli (come nell'esempio sopra) sia il numero di intervalli desiderato, mentre i tag servono solo a nominare i tag della variabile categoriale appena creata; ponendalabels=FALSEinteri semplici '1','2',. Quando a R viene chiesto di valutare una riga di comando, durante l'interpretazione del codice, R cercherà i vari oggetti che appaiono nello script (comprese le funzioni) in un insieme di "luoghi" ordinati che definiscono un cosiddetto percorso di ricerca. Tuttavia, come si può vedere dalla 'risposta' della funzione search(), questa operazione porrà dataframeX alla posizione 2, poiché la prima è sempre riservata all'ambiente globale; di conseguenza, se c'è un oggetto con lo stesso nome della variabile (in questo caso y ), inserendo quel nome si invocherà l'oggetto nell'ambiente globale (nella posizione 1 ) invece di quello nel data frame (nella posizione 2 ) .
Un altro effetto indesiderato è che qualsiasi modifica alle variabili stesse del frame di dati creerà nuove variabili nell'ambiente globale piuttosto che nel frame di dati. In y NA sono state inserite le posizioni 2,56 e 90, mentre nell'altra variabile si è continuato con l'estrazione casuale degli indici. Nell'esempio sopra, la funzione dl() è stata utilizzata per generare una variabile categoriale di osservazioni di lunghezza con n livelli, ogni k volte;.
A questo proposito si noti come l'utilizzo di nomi ed etichette nella gestione delle variabili categoriali, pur non essendo strettamente necessario ai fini dei risultati, porti a risultati più leggibili e presentabili; infatti, incrociare più variabili magari con altrettante modalità senza nomi e/o etichette (come è stato volutamente fatto nell'esempio sopra con la terza variabile) porterebbe ad oggetti di difficile interpretazione e lettura. Normalmente, i nomi delle variabili in 'terms' saranno separati da un +, ma in generale sono ammessi altri simboli, ciascuno con il proprio significato.
Le funzioni tapply(), apply(), lapply(), sapply()
Poiché qualsiasi funzione che accetta un argomento vettoriale è valida, è interessante vedere come è possibile ottenere tabelle di contingenza: utilizzando tapply(), . Atapply() è simile alla funzione by() tranne che il primo argomento non è un vettore, ma un data frame (o anche un array) e quindi la funzione da specificare deve essere relativa ad un data frame e non a di un vettore. Ad esempio, come abbiamo visto in precedenza, summary() applicato a un dataframe restituisce un vettore di misure sintetiche per ciascuna variabile nel dataframe; Per ottenere questo risultato per diversi livelli di una variabile di raggruppamento, puoi digitare .
Il secondo argomento MARGIN specifica se la funzione deve essere applicata alle colonne (MARGIN=2) o alle righe (MARGIN=1), nel qual caso il risultato con MARGIN=1 sarebbe un vettore di lunghezza pari a nrow(X). Nel primo esempio vengono restituite 150 medie perché ne viene calcolata una per ogni riga; nel secondo, perché il risultato di quantile() è un vettore. Quando si lavora con le stringhe, l'argomento MARGIN può anche essere un vettore; utilizzando l'array a precedentemente creato con table(), osservare i risultati ottenuti in questo esempio.
Come è possibile notare, il risultato restituito da lapply() è pur sempre una lista della stessa lunghezza della lista originale, mentre sapply() semplifica (se possibile) questa procedura restituendo un vettore o una matrice a seconda della funzione considerata . Si noti tuttavia che il risultato disapply() può comunque essere una lista se i risultati relativi ai diversi componenti non sono 'omogenei'.
Alcune rappresentazioni grafiche
Ogni figura salvata in questo modo può essere visualizzata nuovamente con replayPlot(o) o semplicemente digitando il nome dell'oggetto, o, sulla riga di comando. Quando viene specificato un solo argomento in plot() (cioè manca x), è possibile utilizzare quella funzione per tracciare un intervallo di valori. Aggiungere punti ad un grafico già esistente può essere molto utile per evidenziare diversi gruppi, vedi l'esempio sotto.
Tuttavia, se si devono sovrapporre linee anziché semplici punti, è possibile sostituire le linee (). Questo spazio è solitamente necessario in quanto riservato ai nomi degli assi, alle etichette, al titolo, ma spesso il nome può essere omesso o si può utilizzare un carattere più piccolo; in ogni caso e in alcuni casi questo spazio è eccessivo. Ai fini dell'esportazione e della visualizzazione dei risultati, questo può essere molto utile, vedere ?plotmath per i dettagli; tuttavia gli utenti LATEX potrebbero trovare il pacchetto psfrag molto più produttivo.
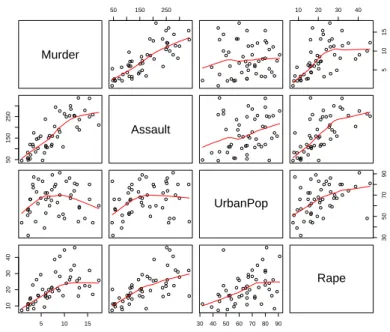
Tra i diversi modi in cui è possibile affrontare questo argomento, un approccio multivariato basato sulla modellizzazione è sicuramente il più difficile, ma anche il più completo, poiché consente una panoramica più ampia e quindi più completa. Il problema è chiaro: i In effetti, alcuni dei test 'bivariati' più familiari (come i test t per il confronto delle medie e i test X2 per le tabelle di contingenza) possono essere derivati da modelli appropriati. La matrice delle varianze e delle covarianzeV non è quindi altro che V = (D−M)n0(D−M) = Xn0X, infine la matrice di correlazione R può essere calcolata come matrice delle varianze dei dati standardizzatiZ. Nei risultati ottenuti con colMeans(), che calcola le medie delle colonne (come apply(U,2,mean), ma in modo più efficiente), si noti che i valori non sono esattamente zero, ma piuttosto 'machine-zero'; in queste e in circostanze simili, round() può essere utilizzato per arrotondare e visualizzare solo alcune cifre decimali.
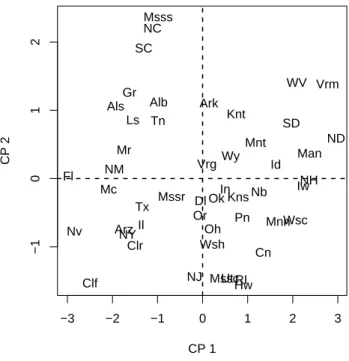
La rappresentazione grafica delle proiezioni delle osservazioni originali nel piano individuato dalle prime due componenti principali può essere considerata come una mappa a dimensione ridotta delle osservazioni multivariate; infatti ogni punto K dimensionale viene ridotto ed individuato da un vettore bidimensionale avente come coordinate i rispettivi valori delle due componenti.
I modelli di dipendenza
Cenni ai Modelli Lineari Generalizzati
- Cenni teorici
- Aspetti pratici
- Ancora sui GLM: il ciclo while
Sebbene la distribuzione di Y e il collegamento di funzione siano generalmente aspetti separati, a volte nelle applicazioni più comuni sono particolarmente legati in quanto a determinate distribuzioni corrispondono determinati collegamenti di funzione. Il primo argomento è la formula dell'equazione del modello, dove la variabile di risposta e le variabili esplicative sono separate dal simbolo ~ mentre le variabili esplicative sono tipicamente separate da un +, mentre familywithlink definisce la distribuzione ipotizzata della variabile di risposta e della funzione di collegamento. Il valore predefinito per family è gaussiano, mentre quello di link dipende dalla famiglia, poiché glm() seleziona il collegamento canonico per la distribuzione dell'insieme.
Ad esempio, in una formula, i segni “+” e “”- hanno un significato appropriato: aggiungi o rimuovi un termine dal predittore lineare; quindi se vogliamo inserire un termine ottenuto come somma algebrica reale tra due variabili, ad esempio x1ex2, dobbiamo 'proteggere' lo script x1+x2 semplicemente inserendo I(x1+x2) ed evitando che R sia interpretato come due -predittore lineare variabile. Di seguito utilizzeremo simulazioni per illustrare alcuni risultati teorici ben noti riguardanti la distribuzione campionaria della media aritmetica e dei coefficienti di regressione e alcune statistiche di test in un modello di dipendenza. A rigor di termini, la distribuzione della statistica di interesse dovrebbe essere valutata sulla base dell'intero universo campione di cui esiste l'enumerazione completa.
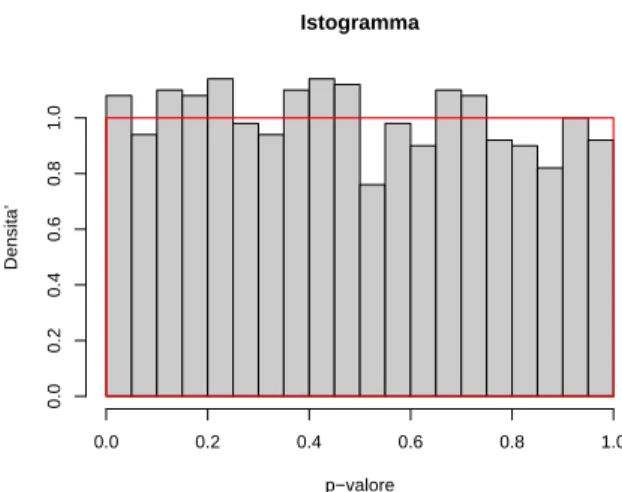
Yi è normale con un'adeguata media µ e una varianza σ2/n; questo risultato è esatto se la distribuzione della variabile originale è normale (cioè se Yi ∼ N(μ, σ)) e approssimato per le altre situazioni dal teorema del limite centrale. Consideriamo il caso molto semplice in cui vogliamo ottenere la distribuzione campionaria di ¯Y quando Yi∼ N(0,1) e Yi∼ U(0,1) per n= 50. Dal punto di vista del contenuto, gli istogrammi sovrapposti mostrano come la distribuzione campionaria per n = 80 sia meno dispersa e apparentemente più vicina alla "normalità" rispetto a quella ottenuta per n = 30.
Nei codici precedenti è stata inserita la funzione grey() come argomento di col per ottenere una gradazione di grigio (gray(1) è bianco) erect() per aggiungere (il dispositivo deve essere già aperto) la distribuzione teorica di riferimento, ovvero rettangolo con angoli specificati; l'argomento border determina i colori (sul bordo) di quel rettangolo.