MATERI PERKULIAHAN
MACHINE LEARNING
Kelompok Keilmuan Computer Science
3
Pemrosesan Data
Tujuan
Menentukan jenis data masukan yang dapat diproses dengan benar
Menentukan kebutuhan pemrosesan data masukan
Mengunakan teknik-teknik
pemrosesan data
Diskritisasi
Diskritisasi Data
• Mengkonversi data kontinu menjadi kategori
• Masalah utama:
Menentukan banyak kategori yang akan dipakai
Memutuskan berapa lebar interval yang akan
digunakan
Binning
• Menyederhankan data
• Memilih k sebagai pembagi data
• (Cara sederhana) dengan membagi range
kedalam k interval, masing-masing memuat
jumlah sampel yang hampir sama.
Contoh binning
• Misalkan diperoleh data sebagai berikut
(sudah diurutkan dari yang terkecil ke yang
terbesar) :45,49,50,61,68,69,75,75,81
Bin berdasarkan rata-rata
45,49,50,67,68,69,75,75,81
Jika diambil k = 3, maka data akan dibagi menjadi 3 kelompok, kemudian hitung rata-rata tiap kelompok, maka nilai anggota kelompok tersebut akan disamakan menjadi sebesar rata-rata
Kelompok Sebelum bin Rata-rata Setelah disederhanakan
45, 49, 50 48, 48, 48
61, 68, 69 66, 66, 66
75, 75, 81 77, 77, 77
Kelompok Sebelum bin Rata-rata Setelah disederhanakan
45, 49, 50 48, 48, 48
61, 68, 69 66, 66, 66
75, 75, 81 77, 77, 77
Bin berdasarkan median
45,49,50,67,68,69,75,80,85
Jika diambil k = 3, maka data akan dibagi menjadi 3 kelompok, kemudian pilih median (nilai tengah) dari tiap kelompok, ubah menjadi mediannya
Kelompok Sebelum bin Median Setelah disederhanakan
45, 49, 50 49 49, 49, 49
61, 68, 69 68 68, 68, 68
75, 75, 81 75 75, 75, 75
Bin berdasarkan batasan
45,49,50,67,68,69,75,80,85
Jika diambil k = 3, maka data akan dibagi menjadi 3 kelompok, kemudian pilih angka terbesar dan terkecil dari masing-masing kelompok kemudian bagi 2. Hanya tinggal dilihat lebih besar atau lebih kecil dari batasan
Kelompok Sebelum bin Batasan Setelah disederhanakan
45, 49, 50 45, 50, 50
61, 68, 69 61, 69, 69
75, 75, 81 75, 75, 81
Kelompok Sebelum bin Batasan Setelah disederhanakan
45, 49, 50 45, 50, 50
61, 68, 69 61, 69, 69
75, 75, 81 75, 75, 81
Daftar Distribusi Frekuensi (DDF)
• Mengelompokkan data dengan lebar interval yang sama
• Langkah-langkah:
1. Menentukan data terbesar dan data terkecil, kemudian dikurangi untuk mendapatkan range
2. Menentukan banyak kategori yang mau dipakai bisa pilih 5 sampai 10 atau menggunakan aturan sturges: 1+3,3 log N dimana N adalah banyak data (bulatkan ke bawah)
3. Menentukan lebar kategori dengan cara range dibagi banyak kategori (bulatkan ke atas)
4. Tentukan batas kategori pertama
79 48 81 87 80 90 91 82
70 92 56 74 68 85 65 83
90 83 74 86 92 76 90 67
80 61 97 88 70 99 80 71
63 83 60 89 76 88 66 79
49 74 98 80 84 70 93 89
71 38 81 73 72 51 93 86
35 73 43 68 93 71 72 75
91 72 91 81 74 95 58 77
60 82 67 63 63 70 88 75
Contoh
Misalkan nilai ujian statistika dari 80 orang mahasiswa adalah sebagai
berikut:
Jumlah data:
Nilai Terbesar:
Nilai Terkecil:
Rentang:
Banyak kelas:
Panjang kelas:
Ujung kelas:
Interval Kelas Batas Kelas Nilai Tengah Tabulasi F
80 99 35 64
7 10 32
32 42 52 62 72 82 92
- 41 - 51 - 61 - 71 - 81 - 91 - 101
31,5- 41,5 41,5- 51,5 51,5- 61,5 61,5- 71,5 71,5- 81,5 81,5- 91,5 91,5- 101,5
36,5 46,5 56,5 66,5 76,5 86,5 96,5
ll llll llll
llll llll llll l llll llll llll llll lll llll llll llll llll l llll llll
2
4
5
16
23
21
9
Data Terstruktur
• Data diagnose untuk prediksi penyakit, pergerakan nilai saham, data cuaca untuk menentukan pesawat dapat mendarat atau layak terbang
Data Tidak Terstruktur
• Pengenalan suara seseorang, menganalisis sentimen dari komentar teks pada twitter, mengukur kecepatan kendaraan
melalui video, mengetahui kematangan buah dari citra buah yang difoto.
Apa perbedaan antara data terstruktur dan tidak terstruktur?
Data Tidak Terstruktur & Proses Ekstraksi Feature
• Ekstraksi feature adalah proses yang digunakan untuk mengubah data tidak terstruktur menjadi data terstruktur
Contoh proses ekstraksi feature yang biasa digunakan Data Masukan Contoh Metode Ekstaksi Ciri
Suara Mel Frequency Cepstral Coefficients (MFCC), Linear Prediction Coefficients (LPC), Linear Prediction Cepstral Coefficients (LPCC), Line Spectral Frequencies (LSF), Discrete Wavelet Transform (DWT) and Perceptual Linear Prediction (PLP)
Teks Term Frequent-Inverse Documen frequent (TF-IDF)
Video SURF (Speeded Up Robust Features), BRISK (Binary Robust Invariant Scalable Keypoints), BRISK (Binary Robust Invariant Scalable Keypoints), HOG (histogram of oriented gradients), Spatio- Temporal pyramid and motion features
Citra SURF (Speeded Up Robust Features), HOG (histogram of oriented gradients), Deteksi Tepi Sobel, Feature Geometri dan Topologi, Zoning, Proyeksi Histogram
S E L E K S I
F I T U R
Perbedaan Seleksi Feature dan Pengurangan Dimensi
• Seleksi feature bertujuan untuk memilih
feature yang relevan dalam membuat model.
• Pengurangan dimensi bertujuan untuk
mengubah matriks feature menjadi perkalian matriks feature yang berukuran lebih kecil
Metode Seleksi Feature yang dipelajari Korelasi Pearson, Chi Square, dan Information Gain
Metode Pengurangan Dimensi Principle Component Analysis
Korelasi Pearson
• Korelasi: istilah statistik untuk menyatakan derajat hubungan linear antara dua variabel atau lebih.
• Koefisien Korelasi (r) : Ukuran yang dipakai untuk mengukur derajat hubungan linear disebut
• Korelasi Pearson adalah metode yang digunakan untuk mengukur derajat hubungan linear antara dua variable.
• Jenis data yang diproses adalah data interval dan rasio
• Asumsi data linearitas dan normalitas
Nilai Koefisien Relasi
• -1 < r < 1
• r = -1 terdapat hubungan (sangat kuat) yang
negatif antara faktor X dan faktor Y (berlawanan)
• r = 0 tidak terdapat hubungan linear antara X dan Y tetapi bisa saja memiliki hubungan
misalnya nonlinear
• r = 1 terdapat hubungan (sangat kuat)yang
linear positif antara X & Y (searah)
Koefisien Korelasi
Y
X
r = 0 Y
X r = -1
Nilai Koefisien Relasi
Contoh Variabel Yang Diamati
• Adakah hubungan antara nilai kemampuan karyawan pada saat penerimaan pegawai dengan performanya
• Banyaknya pengujung dengan banyaknya pengunjung yang membeli barang
• Hubungan antara jumlah pelanggaran lalu lintas, jumlah kendaraan roda empat (mobil), kendaraan roda dua
(sepeda motor), jumlah polisi serta jumlah penduduk.
Korelasi Pearson
r
r
Atau
Korelasi Pearson
Orang Usia (tahun) Tinggi Badan (cm) Berat badan (kg) Tekanan Darah Sistolik
A 34 160 45 108
B 43 150 44 129
C 49 155 56 126
D 58 165 60 149
E 64 170 70 168
F 73 168 66 161
G 78 160 55 174
H 60 150 45 108
I 45 175 60 120
J 50 162 55 118
Rata-rata
Hitunglah korelasi masing masing feature usia, tinggi badan, berat badan dengan tekanan darah Sistolik
r(umur, tekanan darah)
X y
34.00 -21.40 457.96 108.00 -28.10 789.61 601.34
43.00 -12.40 153.76 129.00 -7.10 50.41 88.04
49.00 -6.40 40.96 126.00 -10.10 102.01 64.64
58.00 2.60 6.76 149.00 12.90 166.41 33.54
64.00 8.60 73.96 168.00 31.90 1017.61 274.34
73.00 17.60 309.76 161.00 24.90 620.01 438.24
78.00 22.60 510.76 174.00 37.90 1436.41 856.54
60.00 4.60 21.16 108.00 -28.10 789.61 -129.26
45.00 -10.40 108.16 120.00 -16.10 259.21 167.44
50.00 -5.40 29.16 118.00 -18.10 327.61 97.74
Rata-rata 55.40 136.10
jumlah
1712.40 5558.90 2492.60
X y
34.00 -21.40 457.96 108.00 -28.10 789.61 601.34
43.00 -12.40 153.76 129.00 -7.10 50.41 88.04
49.00 -6.40 40.96 126.00 -10.10 102.01 64.64
58.00 2.60 6.76 149.00 12.90 166.41 33.54
64.00 8.60 73.96 168.00 31.90 1017.61 274.34
73.00 17.60 309.76 161.00 24.90 620.01 438.24
78.00 22.60 510.76 174.00 37.90 1436.41 856.54
60.00 4.60 21.16 108.00 -28.10 789.61 -129.26
45.00 -10.40 108.16 120.00 -16.10 259.21 167.44
50.00 -5.40 29.16 118.00 -18.10 327.61 97.74
Rata-rata
55.40 136.10
jumlah
1712.40 5558.90 2492.60
Korelasi Pearson
Misalkan diperoleh nilai korelasi
• Usia dengan tekanan darah sistolik 0.807896
• Tinggi badan dengan tekanan darah sistolik 0.380944
• Berat badan dengan tekanan darah sistolik 0.685666 Pemilihan feature didasarkan pada nilai threshold yang ditentukan.
Jika nilai threshold >=0.6 maka feature usia dan berat badan dapat digunakan sebagai feature untuk
menentukan tekanan darah sistolik
Chi Kuadrat Test
• Digunakan untuk mengukur kebergantungan antar variable
• Khusus data kategori contoh pada analisis sentiment
• Menggunakan table kontingensi
Kelas 1 Kelas 2 Jumlah Baris
Kategori 1 Kategori 2
… … …
Kategori m …
Jumlah Kolom
Kelas 1 Kelas 2 Jumlah Baris
Kategori 1 Kategori 2
… … …
Kategori m …
Jumlah Kolom
Nilai E dari tiap-tiap sel dihitung dengan cara
Contoh data kategori (sebagian dari 105 data)
Hobi Jenis Kelamin Hobi Jenis Kelamin
Musik Perempuan Musik Laki-laki
Baca Buku Laki-laki Musik Perempuan
Olah raga Laki-laki Baca Buku Perempuan
Olah raga Perempuan Musik Laki-laki
Musik Perempuan Olah raga Laki-laki
Musik Laki-laki Olah raga Laki-laki
Baca Buku Laki-laki Musik Perempuan
Musik Perempuan Baca Buku Perempuan
Baca Buku Laki-laki Baca Buku Laki-laki
Olahraga Perempuan …. ….
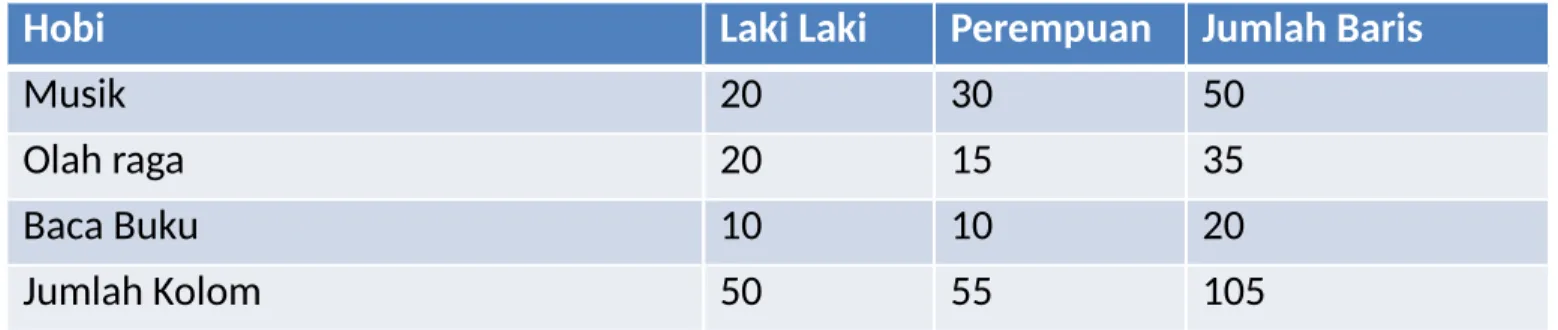
Tabel kontingensi musik dengan jenis kelamin
Hobi
Jenis kelamin
Jumlah Baris Laki Laki PerempuanMusik 20 30 50
Olah raga 20 15 35
Baca Buku 10 10 20
Jumlah Kolom 50 55 105
+ + + + =2,48
�
1=20, �
2=30, �
3=20, �
4= 15, �
5= 10, �
6=10
=23,81, =26,19, =16,67,
=18,33,
df=(3-1).(2-1)=2
Jika ada beberapa feature maka nilai akan dihitung untuk setiap feature dan dirangking serta dipilih dengan menggunakan nilai threshold yang ditentukan.
Semakin tinggi nilai maka dapat dikatakan semakin tinggi kebergantunga dari variable yang diamati (pada kasus ini adalah hobi dengan jenis kelamin)
Latihan chi-kuadrat
Tinggi badan Jenis Kelamin Jumlah
Laki-laki Perempuan
15 30 45
35 25 60
Jumlah 50 55
Tinggi badan Jenis Kelamin Jumlah
Laki-laki Perempuan
15 30 45
35 25 60
Jumlah 50 55
Menurut anda yang lebih baik digunakan dalam penentuan jenis kelamin sesorang
apakah hobi atau tinggi badan?
Information Gain (IG)
• Digunakan untuk mengukur efektivitas suatu atribut dalam mengklasifikasikan data.
���� ( � , � ) = ������� ( � ) − ∑
� ∈�����(�)
| �
�|
| � | ������� ( �
�)
• Dimana:
• A adalah fitur
• V adalah nilai yang mungkin untuk atribut A
• Value(A) adalah himpunan nilai-nilai yang mungkin untuk fitur A
• adalah jumlah sampel untuk nilai v
• adalah jumlah seluruh sampel data
• adalah entropy untuk sampel-sampel yang memiliki nilai v
Tabel kontingensi musik dengan jenis kelamin
Hobi Laki Laki Perempuan Jumlah Baris
Musik 20 30 50
Olah raga 20 15 35
Baca Buku 10 10 20
Jumlah Kolom 50 55 105
• Atribut jenis kelamin perempuan dimisalkan sebagai sampel positif (+) dan atribut jenis kelamin laki-laki dimisalkan sebagai sampel negative (-)
• Value (Hobi) = Musik, Olahraga, Baca Buku
• S = [ 55+,50-],
Entropy
Entropy adala suatu parameter untuk mengukur heterogenitas dalam suatu himpunan data.
•
Nilai IG
���� ( � , ���� ) = 0,9984 − ( 105 50 0,9710 + 35
105 0,9952+ 20
105 1 ) =0,0171
•
���� ( � , � ) = ������� ( � ) − ∑
� ∈�����(�)
| �
�|
| � | ������� ( �
�)
Jika ada yang lain fitur untuk menentukan seseorang berjenis kelamin
perempuan atau laki-laki, maka tinggal dihitung nilai gainnya, semakin
besar nilai gain, semakin besar nilai efektivitas fitur tersebut dalam
menentukan jenis kelamin seseorang.
Latihan IG
Tinggi badan Jenis Kelamin Jumlah
Laki-laki Perempuan
15 30 45
35 25 60
Jumlah 50 55
Tinggi badan Jenis Kelamin Jumlah
Laki-laki Perempuan
15 30 45
35 25 60
Jumlah 50 55
Menurut anda yang lebih baik digunakan dalam penentuan jenis kelamin sesorang
apakah hobi atau tinggi badan?
Principle Componen Analyzis (PCA)
• Salah satu teknik pengurangan dimensi
• Mengubah matrik menjadi perkalian matrik orthogonal
•
Mahasiswa Matematika B Inggris Seni Keputusan1 90 60 90 Lulus
2 90 90 30 Lulus
3 60 60 60 Tidak Lulus
4 60 60 90 Lulus
5 30 30 30 Tidak Lulus