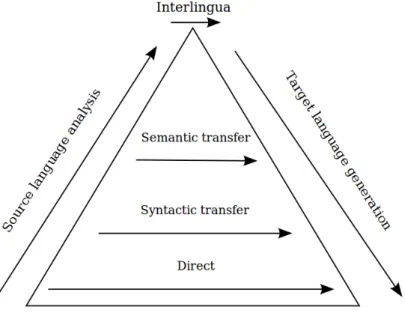
Interlingua Based: Translation is done using an intermediate representation of the text (interlingua) between source and target languages. In the transfer approach, a syntactic (or semantic) structure of the source sentence is built and this is transformed into a syntactic (or semantic) structure of the target sentence.
Statistical Machine Translation
Importance of large amounts parallel corpora for SMT
But one of the main challenges facing SMT is the scarce availability of parallel corpora. There are some language pairs, such as English-French or English-Spanish, for which a huge set of parallel corpora is available.
Comparable Corpora
Wikipedia
If the hyperlinks in a bilingual sentence pair match, then that sentence pair can be said to be parallel. There are thus many sources of useful information in Wikipedia that can be utilized for our purposes.
Quasi-Comparable Corpora
So, if the same image appears in an aligned pair of articles, its caption can be used in both of those articles as parallel sentences. First, they can be translations of each other, in which case they are almost parallel.
The Internet Archive
The archive is so large that all data processing must be done with algorithms of the least computational complexity.
Summary
Outline of the Report
The following chapters discuss various techniques for performing each of the steps mentioned in this chapter. In this method (Munteanu and Marcu, 2005), for each foreign language document, we try to select a list of English documents that are likely to contain sentences that are parallel to those in the given foreign document.
Cosine Similarity
Topic Alignment
Content Based Alignment
We use a generative, symmetric model based on a bilingual dictionary that gives a probability distribution 'p' over all possible link types in the corpus. So, finding the best set of links about X and Y is a Maximum Weighted Bipartite Matching (MWBM) problem. This similarity score should be high when many link tokens in the best link sequence do not have NULL on either side.
We can combine multiple sources of word-level translation information into the model such as dictionaries, the word-for-word translation model as described above, and attachments. Most of the techniques are applied to a set of bilingual document pairs that are topic-related, i.e., each pair of documents has content about roughly similar topics, so they tend to convey a lot of overlapping information. But when we do not have such a paired set of documents, the techniques discussed in the previous chapter can be used to align the documents.
The following are some techniques that can be used to classify parallel sentence pairs from all sentence pairs in the aligned set of documents.
Maximum Entropy Based Ranking Model
Formulation
For each source language sentence, we select a target language sentence that is most parallel to it. Thus, the sentence with the highest probability from the target is selected as parallel to the given source sentence. If no such target sentence is found, then the source sentence is NULL-aligned.
Sentence Similarity
Conditional Random Fields
Discriminative Word Alignment with Conditional Random Fields 24
Blunsom and Cohn (2006) describe a CRF sequence model evaluated on a small supervised learning set of word-aligned parallel sentences. It models many-to-one alignments, where each source word is aligned with zero or one target word, so that each target word can be aligned with multiple source words. Many-to-many alignments are obtained by overlapping the predicted alignments in both translation directions.
Each source word is marked with the index of the target word it is aligned with, or "null". The feature set includes two main types of feature functions: features defined on the candidate aligned word pair and Markov features defined on the alignment sequence predicted by the model. The parallel sentence extractor based on the CRF model described above uses a subset of the rich set of features described in the next section.
Features Functions
General Features
We consider the difference in the relative position of the sentences in their respective documents. So if a sentence is in the middle of the document in the source language, the translation can be found in the corresponding target language document in approximately the same region.
Word Alignment based Features
In the alignment calculated between a pair of sentences, if a single word in one sentence has an alignment of high fertility, it may indicate non-parallelism. This is because, in sentences that are translations of each other, words usually have low fertility and the number of words with high fertility is also less. So, we can find the top three greatest fertility in the alignment between the sentence pair to decide if they are parallel.
If the length of the longest unconnected span in a sentence is very large (more than say 1/3 of the sentence length), then it indicates non-parallelism.
Distortion Features
LEXACC (Lucene Based Parallel Sentence Extraction from Comparable
- Indexing, Searching and Filtering
- Translation Similarity Measure
- LLR to Estimate Word Translation Probabilities
- Detecting Parallel Fragments
Translation strength of content words: Find the best 1:1 alignment using a Giza++ lexicon, and find the ratio of summation of translation probabilities of the translated words and length of sentence. Strong Translation Sentinels: If sentences are parallel, there are content word translations near the beginning and end of the sentences. When the degree of parallelism of the comparable corpus is quite low, searching for absolutely parallel sentences may not yield good results.
This is because such parallel sentence pairs are not present in the corpus at all. The next step focuses on finding fragments of the source sentence that have a translation on the target page. So only the part that is positive is retained as the parallel fragment of the sentence.
For each linked target word, the value of the signal is the probability of its alignment link𝑃+(e|f).
Sentence Splitting for Phrase Alignment
Constrained IBM Model 1
Words within the source phrase are aligned with words within the target phrase, and words outside the source phrase are aligned with words outside the target phrase. The position alignment probability for a sentence is 1/𝐼, where 𝐼 = the length of the target sentence and 𝐽 the length of the source sentence. This is changed to 1/𝑘 inside the source phrase and 1/(𝐼−𝑘) outside the source phrase, where 𝑘 = the length of the target phrase.
Chunking Based Approach
Chunking Source Sentences and Merging Chunks
Window Merge: In this type of merge, not only two but as many smaller chunks as possible are merged unless the number of tokens in the merged chunk does not exceed 'V'.
Finding Parallel Chunks
Refining the Extracted Parallel Chunks
The technique of extracting a bilingual lexicon from comparable to very non-parallel corpora is described by Fung and Cheung (2004a). Then the IBM Model 4 EM learning is applied to this extracted set of parallel sentences to find unknown word translations. Thus, the set of aligned sentence pairs may also contain many pairs that may not be truly parallel.
A solution to this problem is to initialize the EM estimation using a corpus of truly parallel data. Thus, this step is used to improve the existing lexicon, which in turn is used to extract more parallel sentences.
EM based Hybrid Model
The EM Algorithm
Similarity Features
Power spectrum is sensitive to relative spacing in time, but not to time shift. The EM algorithm, adapted to use all the above feature functions, converges to give an aligned set of terms from the comparable corpus. The performance of this technique is highly dependent on the degree of parallelism of the comparable corpus.
Pivot Language and Word Alignment
Approach
It appears to work well on similar corpora, but this framework works better on a parallel corpus. All words in Korean and Spanish now have a vector of corresponding English words with their corresponding matching scores. For each Korean word, the similarity of the English word vector to the English word vectors of each Spanish word is calculated by cosine similarity, dice coefficient, or Jacquard's similarity.
Canonical Correlation Analysis and EM
Generative model for Bilingual Lexicon Induction
𝑊𝑆is a 𝑑𝑆×𝑑matrix that transforms the language-independent concept 𝑍𝑖,𝑗 into a language-dependent vector 𝑓𝑆(𝑠𝑖) in the source space.
EM Framework of Inference
Feature Set
The number of parallel sentences that can be extracted from parallel or non-parallel corpora depends on the bilingual lexicon (dictionary) or phrase translation table created by training classifiers on the seed parallel corpus. If this seed corpus has poor dictionary coverage, it can negatively affect the parallel phrase extraction process. This is because many words from the possible sentence pairs will be out of the vocabulary for our translation table, so a sentence pair may be classified as non-parallel even if it is highly parallel.
In each iteration, we learn new word translations from the intermediate output of the previous parallel sentence extraction. Find all similar document pairs from the corpus using one of the previously discussed techniques. The extracted sentence pairs can be easily added to the training data and an updated bilingual lexicon can be obtained.
A bootstrapping system is able to learn new lexical items that occur only in the extracted parallel sentences.
Alternative Approach: Lexicon Induction
- Translation probability
- Orthographic Similarity
- Context Similarity
- Distributional Similarity
An HMM word alignment model can be trained on some seed-parallel data and translation probabilities can be taken as features. Orthographic similarity can be calculated using a function of the edit distance (Levenshtein distance) between source and target words. This distribution is based on the number of times a context word 𝑣𝑠 occurs in a position o in the context of 𝑤𝑠.
Bootstrapping can be used to increase the number of sentences that can be extracted. In Proceedings of the 21st International Conference on Computational Linguistics and the 44th Annual Meeting of the Society for Computational Linguistics, pages 65–72. In Proceedings of the 4th Workshop on Building and Using Comparable Corpora: Comparable Corpora and the Web, pages 61–68.
In the proceedings of the 21st International Conference on Computational Linguistics and the 44th annual meeting of the Association for Com-.
Vauquois’ Triangle
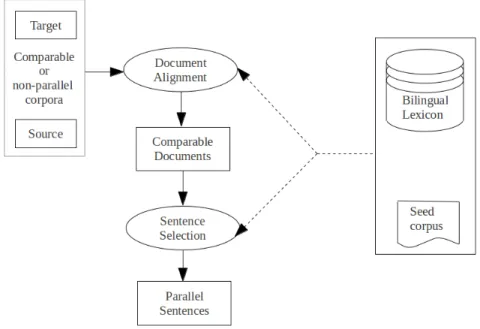
Example of Comparable Corpus
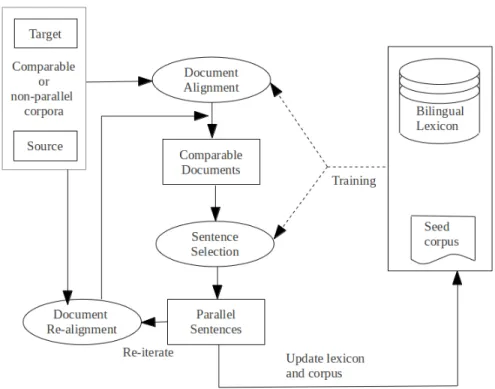
General Architecture of Parallel Sentence Extraction System
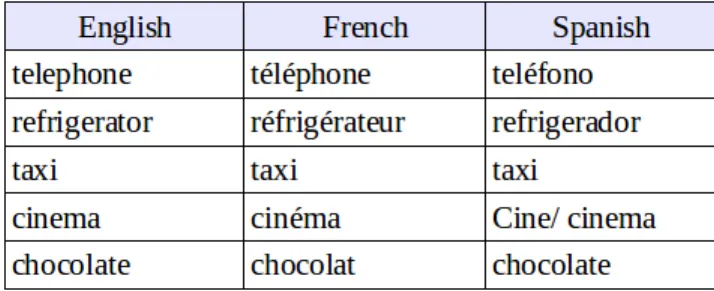
Parallel Sentence Extraction System with Bootstrapping
Levenshtein distance