Alias Analysis is a static analysis which takes a program as input and calculates information points about the program. In this analysis of Andersen's nickname is based on the inclusion of points in the group, which is more accurate, but less efficient.
Clients of Alias Analysis
Issues with Scalable Alias Analysis
Our Contribution
Organization of this Thesis
In Section 2.4, we present alias analysis as a graph problem, which will give an idea of the information structure from point to. Additionally, in some cases, such as flow-sensitive analysis, a point-to-fact is defined at the program point. Here we calculated the alias by checking the common point in a set of two pointers.
Point-to Analysis: A mechanism for statically calculating a set of point-to pointers in a program. Analysis memory requirement is the total amount of memory in bytes used to store point-to constraints and point-to information. Clients: A client can be a program parser, a program transform, or an application that requests information about points to an alias analyzer.
However, all pointers accessed outside the function have the same point-to information, so such pointers can be merged to reduce the total number of variables tracked.
LLVM
Analysis Dimensions
Context-sensitivity
Flow-sensitivity
Field-sensitivity
Alias analysis as a graph problem
A bounded graph G is a directed graph where each node represents a pointer and each directed edge u → v represents a subset (or inclusion) relation. Each node also maintains its own set of points, which are updated as point information (flowing along its input edges and spreading along its output edges). The constraint graph is not static, and new edges are added to it when complex constraints are evaluated, when no more edges can be added and information from point to can no longer be propagated, a fixed point of information from point to graph is calculated at the node in the node.
The graph contains three nodes corresponding to each pointera, b, p, each node is associated with its points-to-information, as shown in the graph from example 2.6 by curly braces. A directed edge from a to binds the flow of points-to information from a to bedge is added due to the processing of the load constraint b=∗p. A points-to analysis using a constraint graph is shown in Algorithm 1 Algorithm 1Points-to analysis using a constraint graph.
This is done using two methods, first by dynamically collapsing cycles in a graph and second by propagating pointers to information in topological.
Chapter Summary
In this, we will try to cover the most interesting and important work in the analysis of nicknames. To understand the overview of alias parsing, we have tabulated all possible alias parsing algorithms by parsing and type, as shown in Table 3.1. In this, they have mentioned several dimensions which affect the trade-off between accuracy and scalability.
The survey discusses various dimensions such as flow sensitivity, context sensitivity, heap modeling (it tells how allocation sites are modelled). In this he discussed various types of flowcharts used in literature, namely context-sensitive call graph, inter-procedural control flow graph, procedure call graph. The analysis dimensions are field sensitivity, flow sensitivity, program representation, context sensitivity, and object representation.
Raman [15] presents three methods, Unification based analysis, Pointer analysis using BDD and application of pointer analysis in fault detection.
Two Key Points-to Analysis Methods
Andersen Alias Analysis
Steensgaard Alias Analysis
Algorithms which uses inclusion-based approach
The most important finding is that a flow-insensitive analysis with termination information does not improve accuracy compared to no-removal information. Cheng and Mei [19] propose a modular interprocedural pointer analysis based on pointer access paths. Pearce et al.[10] propose a field-sensitive point analysis for modeling aggregate and functional indicators.
They note that field-sensitive analysis is more expensive to calculate but more accurate than field-insensitive analysis. 8] Propose a heap cloning-based context-sensitive point-to-analysis to achieve scalable implementation. They use a unification-based analysis and flow-insensitive and left the context-sensitive analysis within a highly connected component. They show that stream information can be computed efficiently, considering only well-defined call-back sequences, even for higher-order programs.
Applications of Alias Analysis
Ghiya and Hendren provided the use of pointer information to develop shape analysis for C programs [28]. 29] use C++ stream-insensitive and context-insensitive point parsing for C++ to parse and slice definitions. Application of client-driven pointer analysis to C programs for multiple error detection problems Guyer and Lin [30].
More clients using pointer analysis are Mod/Ref analysis, live variable analysis, reach definitions analysis, conditional constant propagation and dead code elimination Hind and Pioli [4].
Alias Analysis for other languages
Chapter Summary
Section 4.1 presents the idea of Andersen analysis, such as what and why Andersen analysis is important.
What and Why of Andersen Alias Analysis
Alias Analysis in LLVM
Alias Analysis Class Overview in LLVM
Existing alias analysis implementations and clients in LLVM
The-globalsmodref-aapass: This pass performs simple context-sensitive parsing of mod/refs and aliases for global variables. -scev-aa transition: This transition executes AliasAnalysis queries by translating them into ScalarEvolution queries. pass-print-alias-sets: This pass is used to print alias sets.
The-count-aapass: This pass is useful for seeing how many queries a particular pass is making and what answers are returned from the alias analysis. -aa-eval pass: This pass simply iterates through all the pointer pairs in a function and asks for an alias analysis of whether or not it is the pointer's alias.
Flow of Andersen Alias Analysis code base in LLVM
Object Identification: The object identification phase identifies all memory objects in the program, including globals, heap-mapped objects, and stack-mapped objects. Identification of Containment Constraints: The Identification of Containment Constraints phase finds all containment constraints in the program by scanning the program, looking for pointer assignments and other statements that affect the points-to-graph. For a statement like “A = B,” this statement is processed to indicate that A can refer to anything B can refer to.
Offline constraint graph optimization: The offline constraint graph optimization part includes an 'offine variable substitution algorithm' intended to calculate pointer and location equivalents. Pointer equivalences are those pointers that have the same point-to-sets, and location equivalences are those variables that always appear together in point-to-sets. Containment Constraint Solving: The containment constraint solving phase iteratively propagates the containment constraint until a fixed point is reached.
Chapter Summary
The basic idea is taken from the LLVM 2.6 code base and remains the same, but we need to make it suitable for the latest versions of LLVM. As mentioned in LLVM 2.6, the Andersen alias analysis [5] was available as a pass, but they mentioned that it was implemented for interprocedural alias analysis. In LLVM 3.4 we isolated key features and added them as separate files, making it easier to understand and improve.
We need to change some code of ConstraintOptimize.cpp because LLVM 3.6 changed the format of the error messages infileinclude/llvm-3.6/Support/ToolOutputFile.h. Another big change in AndersenTest.cpp at lines 134 to 145, which is due to a change in LLVM-3.6filellvm-3.6/unittests/Analysis/CFGTest.cpp. In LLVM 3.7, the most important changes are in DataLayout, as LLVM has made DataLayout a mandatory part of the LLVM framework in this version.
In LLVM 3.7 we also need to change the location of PassManger.h as it is moved to llvm-3.7/IR/PassManager.h.
Latest Included Modules in Andersen AA
To support exception handling, one needs to change the semantics of a function call and this call forks the execution flow. One branch is taken when everything is OK and second branch is taken in case of an exception. In LandingPad, all data such as personality routine, caught types, throw specifications and cleanup actions are already specified, so no additional data needs to be sent to the backend to generate exception related information in object file.
The LandingPad instruction uses the LLVM exception handling system to determine that the base block is the landing pad (the one where the exception lands) and corresponds to the code located in the catch portion of the try/catch sequence. The result is the value of the position in the aggregate determined by the index operands. Its value is the val value, except that the value at the position specified by the indices is the "elt" value.
Additional Test Cases are added to the Andersen implementation, which contains all test cases available from the LLVM unit test cases.
Experimental Result Analysis
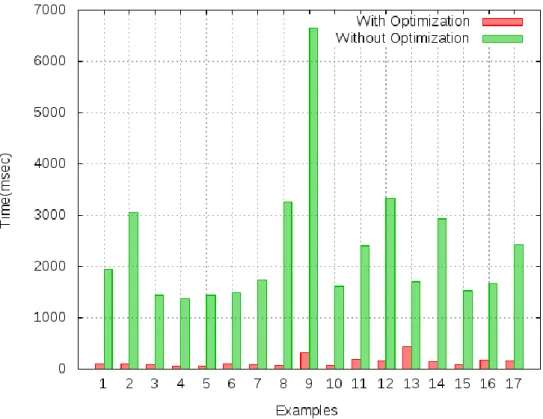
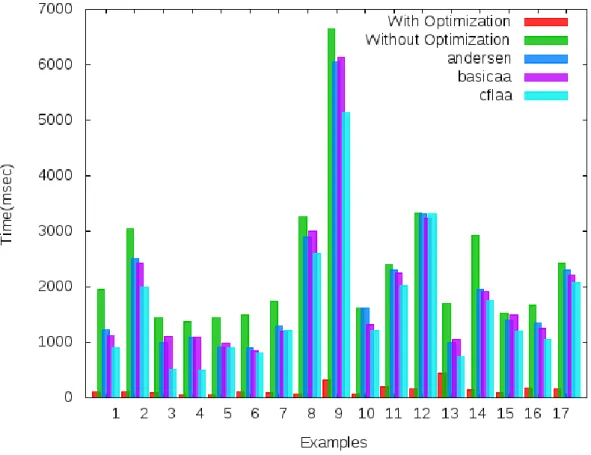
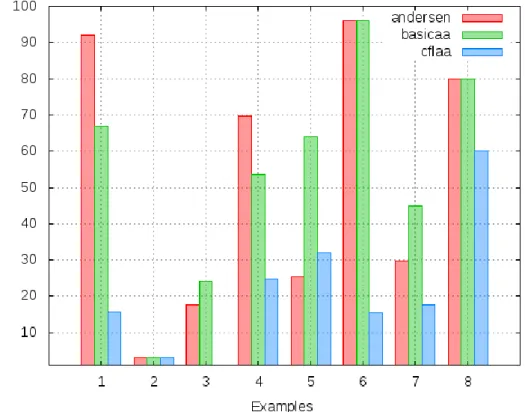
In Figure 5.5, we have produced the results for vectorization examples with and without enabling -O3 optimization. As mentioned in the Figure 5.5, the vectorization examples show the optimization after applying alias analysis. In Figure 5.6 we have shown results for vectorization examples after applying each algorithm such as Andersen, basicaa and cfl-aa.
In this, to produce the results, we enabled optimization level three (-O3) for with optimization. While for results with Andersen, basicaa and cfl-aa we applied separate optimization option like, for Andersen algorithm we used -fresh-andersen-aa option with optimizer toolopt-3.7. Also, for cfl-aa we used cfl-aa option and for basicaa-basicaa option in LLVM.
The result shown for all three algorithms which cannot give good results compared to the optimization option, the reason behind this is that we used O3 optimization which also contains other optimizations.
Chapter Summary
Make Andersen alias analysis context sensitive: The Andersen alias analysis can be moved to context sensitivity, which will improve the scalability of the analysis and we can find out more precise point-to-pairs. In Proceedings of the 23rd ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL ’96. In Proceedings of the 5th ACM SIGPLAN-SIGSOFT Workshop on Program Analysis for Software Tools and Engineering, PASTE ’04.
In Proceedings of the 9th Annual IEEE/ACM International Symposium on Code Generation and Optimization, CGO ’11. In conjunction with the 9th European Software Engineering Conference jointly held with the 11th ACM SIGSOFT International Symposium on Foundations of Software Engineering, ESEC/FSE-11. In Proceedings of the 20th Annual ACM SIGPLAN Conference on Object-Oriented Programming, Systems, Languages, and Applications, OOPSLA ’05.
In Proceedings of the 20th International Conference on Building Compilers: Part of the Joint European Conferences on Software Theory and Practice, CC'11/ETAPS'11.
Constraint graph for example 2.6
Constraint graph for example 2.7
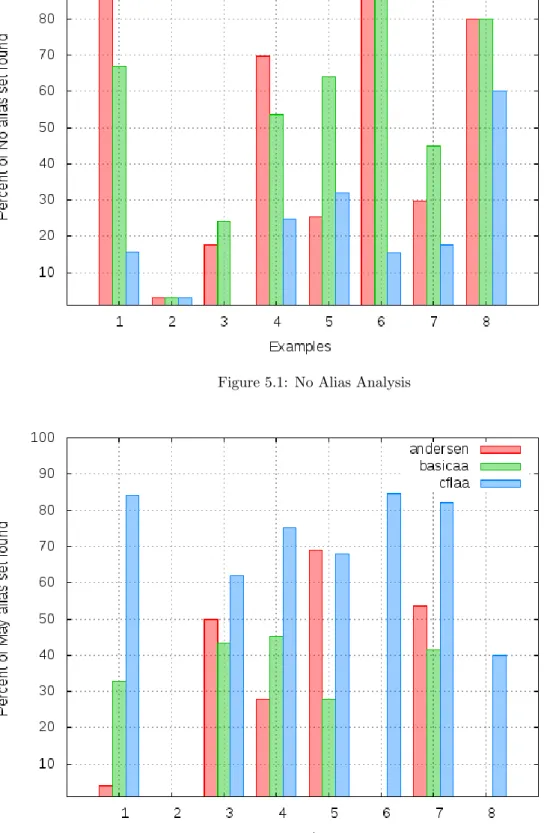
No Alias Analysis
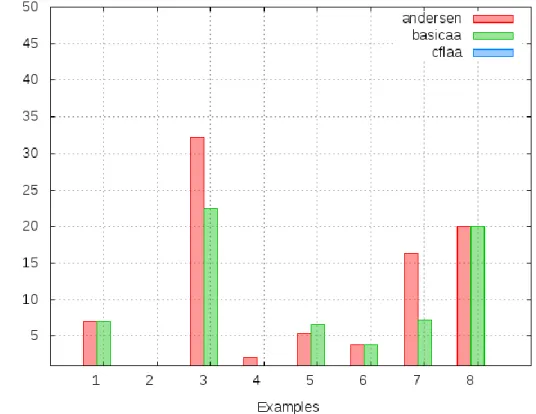
May Alias Analysis
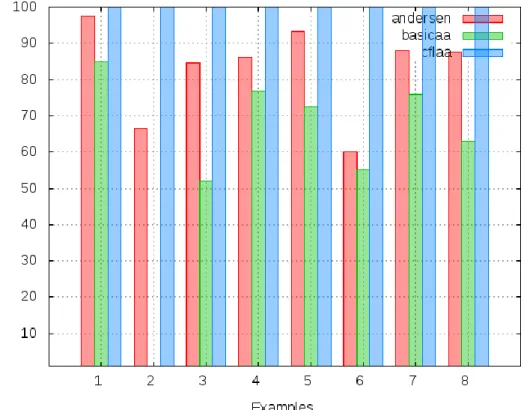
Must Alias Analysis
Mod/Ref Information
Improvement in vectorization due to Alias Analysis
Time required for vectorization after applying fresh-andersen alias analysis
![Table 3.2: Updating points-to sets (adapted from Rupesh Nasre [16])](https://thumb-ap.123doks.com/thumbv2/azpdfnet/10483112.0/24.892.132.794.635.722/table-updating-points-sets-adapted-rupesh-nasre-16.webp)