However, most previous studies consider information networks with one type of nodes and relationships, i.e. most previous studies on HIN exploit different metapaths to solve different network mining problems.
Commonly Studied Problems over HIN
Some of the latest linkage prediction methods are Common Neighbor [8], Jaccard Coefficient [35], Adamic Adar Index [36]. Community structure is an inherent characteristic of real-world networks and helps in various applications such as rumor propagation [45, 46], epidemic propagation [47], etc.
Problem Statement
The input to the connectivity prediction model is a heterogeneous information network (at time T) with multiple types of nodes and edges (distinguished by different colors). Thus, this thesis formulates heterogeneous versions of state-of-the-art link prediction methods, capable of incorporating node importance by estimating the likelihood of link existence.
Contribution
- Link prediction in HIN
- Link Prediction Using Exogenous Factors as Node Importance 8
- HIN Embedding using k-hop Random Walks
- Effect of Class Imbalance in HIN Embedding
We see that our proposed network embedding model outperforms the baselines in most cases. We study the performance of state-of-the-art network embedding models subjected to HINs with different levels of class imbalance.
Outline of the Thesis
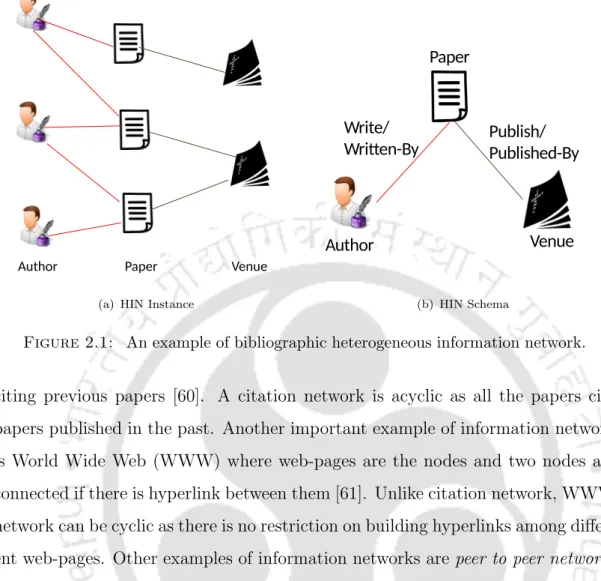
Another important example of an information network is the World Wide Web (WWW), where web pages are the nodes and two nodes are connected if there is a hyperlink between them [61]. Although the field of information networking is quite mature today, it is still an active area of research.
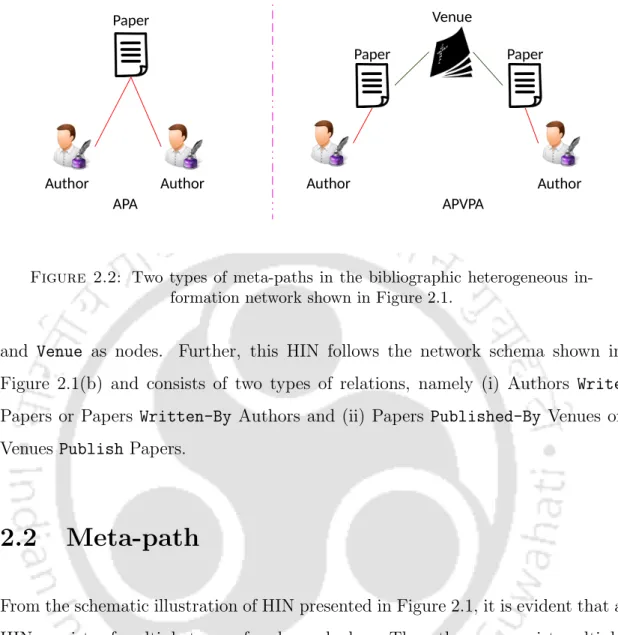
Meta-path
Furthermore, this HIN follows the network scheme shown in Figure 2.1(b) and consists of two types of relationships, namely (i) authors write articles or articles written by authors and (ii) articles published by venues or places publish articles. These two meta-paths capture proximity of different semantics between the given pair of nodes.
Local Similarity Measures
However, in social networks it is often visible that a common neighbor with high connections (degree) does not contribute much to the similarity between its neighbors. In particular, a common neighbor with higher connections contributes less, while a common neighbor with fewer connections contributes highly to the similarity score between Adam and Adar.
Spectral Graph Kernels
Graph Kernels and their spectral transformations
Path counting model can be transformed into a graph kernel by using only the topk positive eigenvalues of matrix A. Exponential kernel (EXP): Exponential kernel [87] estimates exponential for adjacency matrix A, which can be defined as follows.
Summary
Contribution
Proposed Heterogeneous Local Similarity Measures
Adamic Adar: Traditional AA index between two nodes x and y for homogeneous network is defined as SAA(x, y) = X. Resource allocation: RA index between two nodes x and y for homogeneous network is defined as SRA(x, y ) = X.
Proposed Heterogeneous Spectral Graph Kernels
Applications of the Proposed Methods
Car Tunnel CPI-Maoist Explosive Landmine 3 India South Asia Assam Kokrajhar Facility Transport Train/. Train Tracks NDFB Sabotage Equipment 4 India South Asia J&K Bijbehara Bombing Police Police Patrol Load Explosives Vehicle 5 Nigeria Sub-Saharan. To the best of our knowledge, the proposed methods are the first link prediction methods that can support the relationship between different node types within the counter-terrorism domain2.
Dataset
In this chapter, we have examined the effectiveness of predicting all four types of relationships mentioned above. Based on definition (2.1) and the data set described in Table 3.1, the experimental heterogeneous terrorist attack network is constructed as follows. For example, the GTD network constructed using Table 3.1 will have edges between India and the rest of the node class values available in the first four rows.

Experimental Setup
Link Prediction Using Heterogeneous Local Similarity Mea-
Link Prediction Using Heterogeneous Spectral Graph Kernels 32
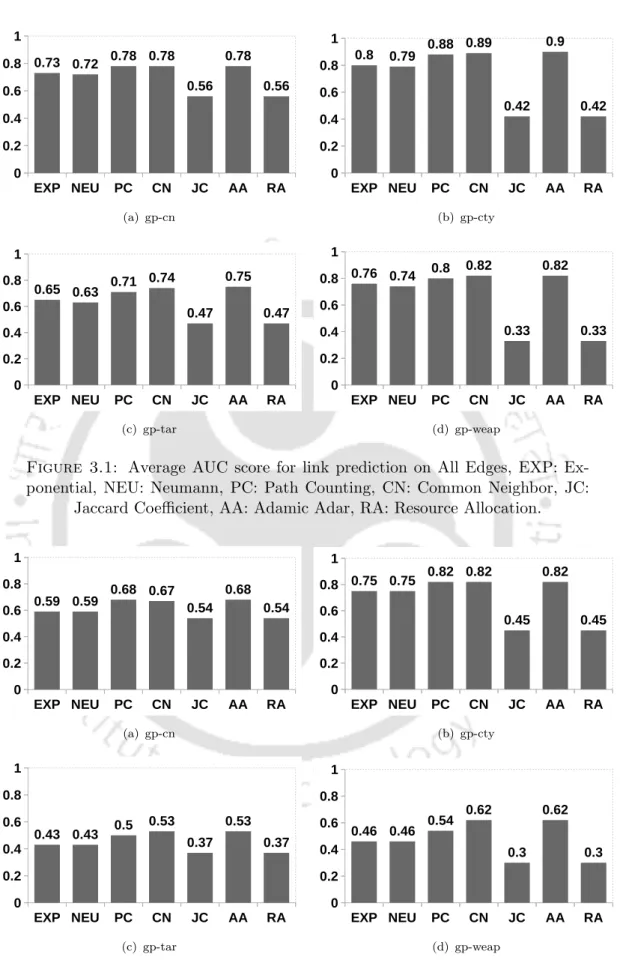
For the first type of test edges (i.e. All edges), we consider all the edges that appeared between years 2010 to 2014. For the second type of test edges (i.e. Missing edges), we only consider new edges that appeared between 2010 and 2014. all the above four types of existing test edges we generate more than five times of non-existent test edges and estimate the AUC.
Experimental Observation
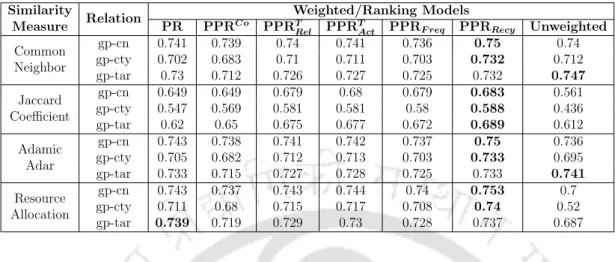
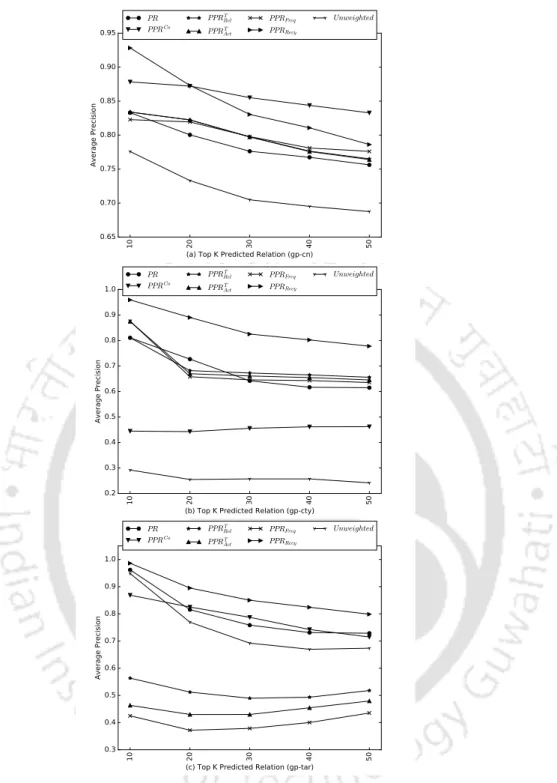
It is convincing to observe that among the good performance predictors, the least achieved performance in terms of AUC is 0.72 for gp-cn, 0.79 for gp-cty, 0.63 for gp-tar and 0.74 for gp -weap. On the other hand, for Missing Edges, all the link predictors except JC and RA achieve the accepted range of AUC scores for gp-cty relationship. One of the reasons for having a convincing link prediction performance for gp-cty relations (in both types of test edges, i.e. All Edges and Missing Edges) is that the terrorist attack network considered in this study has the highest number of entities from city type and second highest from group (see table 3.2).
Summary
Contribution
Proposed Framework
- Node Importance and Centrality Measures
- Random Walk-Based Method
- Personalised PageRank for heterogeneous network
- Incorporating Exogenous information
Considering all the nodes in the network, the above expression can be written as If the information is available in the form of a node vector r, we can expand equation (4.3) as . Similarly, if the information is available in the form of a matrix R, we can expand equation (4.3) as
Dataset and Experimental Setup
Parameters Used for Ranking Nodes Using PPR
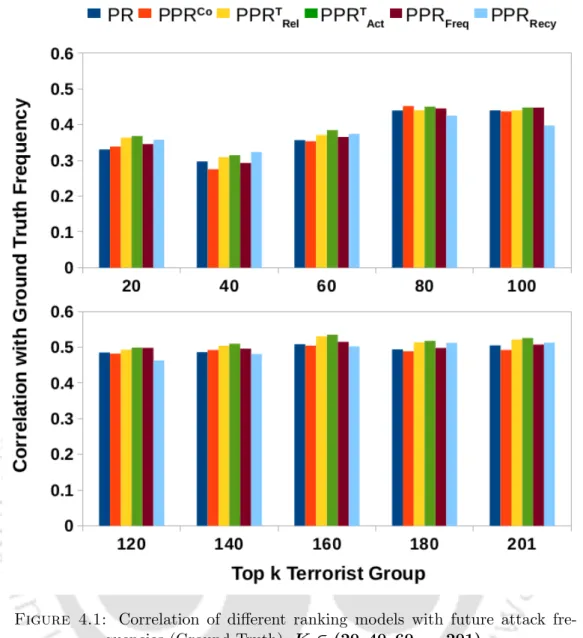
PPRF Requirement: PPR with node frequency during the training period, i.e., during the years 2000-2009 as the personalization vector. PPRRecy: PPR with the node frequency in the recent past is considered as the personalization vector. To estimate the last node frequency, we select the total node frequency in the last year from the training data, i.e.
Experimental Observations
- Centrality and its correlation with future activities
- Heterogeneous Relationship Prediction
- Predicting Top Alliance among various Terrorist Organizations 56
- Contribution
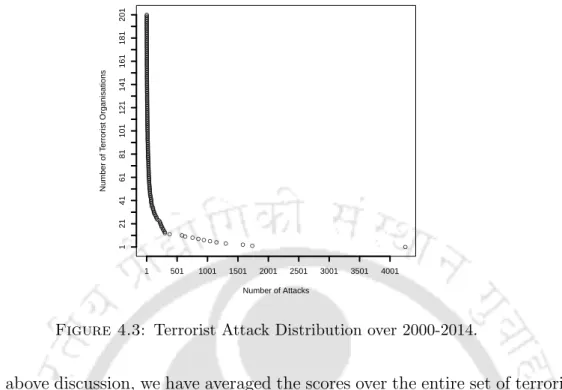
Moreover, it is noted that across all parts of the top organization, at least three parameterized models outperform non-parameterized models. This clearly shows that very few terrorist organizations carry out the majority of attacks worldwide. It is observed that almost 60% of the predicted alliances turn out to be true (highlighted in Table 4.4).
Literature Survey
It examines the effect of metapath-based HIN embedding frameworks in solving co-authorship prediction and author research field classification. It investigates the effectiveness of different types of metapath-based HIN embeddings on tasks of diverse nature viz. recently, Metapath2vec [1] is proposed for embedding heterogeneous networks, which samples the neighborhoods of nodes using a random walk guided through a metapath.
Network Embedding
Homogeneous Network Embedding
In a similar direction, study in [124] exploits the combined effect of different meta-paths of predefined length to generate node embeddings in heterogeneous networks.
Heterogeneous Network Embedding
Meta-path-based Heterogeneous Network Embedding
Experimental Setups and Analysis
Experimental Dataset
To investigate the performance of different meta-paths and their associated embedding, we evaluate the embedding quality using the following two applications. Classification AA APA AVA All AA APA AVA All AA APA AVA All AA APA AVA All. For each author in DBLP, we further identify (given the Field attribute in [125]) the area where the author has maximal publication and consider it the author's class label.
Result and Discussion
Tables 5.2 and 5.3 clearly show that APA is better than AVA for predicting co-authorship, while AVA is better than APA for classifying an author's research field. However, for the author's classification of research areas in Table 5.3, APA outperforms AA in almost all scenarios. Tables 5.2 and 5.3 show that combined embedding always outperforms single embedding for predicting co-authorship and author research field ranking in all four networks.
Summary
Contribution
Node Embedding
As discussed above, most previous studies exploit metapathway-based features to predict associations in HINs. Thus, this thesis incorporates exogenous information such as the media and temporal dynamics of the underlying network while predicting future connections. Thus, a latent network representation or network embedding can be useful for generating automatic node functions.
Furthermore, the performance of the proposed model is compared with recent state-of-the-art network embedding methodologies. Therefore, this chapter proposes heterogeneous transformations of various state-of-the-art similarity measures and spectral graph kernels for association prediction in HIN1. Table 5.2 shows that AA performs better than APA in predicting co-authorship in most cases.
The previous chapter exploits various meta-paths on the latest embedding models for embedding heterogeneous networks.

Network Sampling using k-hop Random Walk (RW-k)
Aggregate k-hop Embedding
The node embedding generated using different values ofkin RW-k does not capture the network characteristics described by intermediatek. Therefore, to capture the characteristics of each intermediate RW-k, we propose that the node embedding is obtained by different RW-k for each node.
Experimental Analysis
Dataset
Experimental Result and Discussion
Table 6.2 shows that network embedding exploiting RW-k outperforms state-of-the-art baselines 83% of the time. Therefore, it can be concluded that in heterogeneous information networks, capturing neighborhood features separated by some hops helps to create better network embedding. This indicates that capturing neighborhood features with small jumps can yield better network embedding, although increasing the jump size does not show significant improvement.
Summary
Contribution
We present a detailed study on the effect of class imbalance in mining heterogeneous bibliographic network for different network mining problems. We present a comparative study that analyzes the effect of class imbalance in heterogeneous information network embedding with varying amount of class imbalance on two applications, namely (i) Co-authorship prediction and (ii) Author's research area classification. Motivated by the applications of random walks in unsupervised network embedding, we further present a comparative study for the effect of class imbalance on inter-class and intra-class node ranking problems.
Literature Survey
Task-specific metapath-based network embedding models often combine a set of predefined metapaths (dedicated to the end task) to achieve better quality of embedding. However, selecting a set of task-specific metapaths may still not be solved trivially and may not be scalable for large graphs. Similarly, HINE [131] guides random walks exploiting several shorter length metapaths to learn to embed a node, while preserving metapath-based proximity.
Class Imbalance
Class Imbalance in Heterogeneous Information Network
As discussed in Section 7.1, we define the class imbalance in HIN by aggregating the ratio of the number of nodes in the majority class to the minority class, given that there is an edge between these two node classes.
Dataset and Experimental Analysis
Dataset
Constructing Heterogeneous Information Network
Experimental Setup
- Co-authorship Prediction
- Author’s Research Area Classification
Next, we evaluate the performance of inclusion in future Coauthor prediction and author search domain classification tasks. We perform five-fold cross-validation and report the prediction performance of Co-author using the Area under ROC score. We report the classification performance using the accuracy score. a) Prediction of co-authorship (b) Classification of the author's research area.
Experimental Observation
Network Embedding and Decreasing Class Imbalance
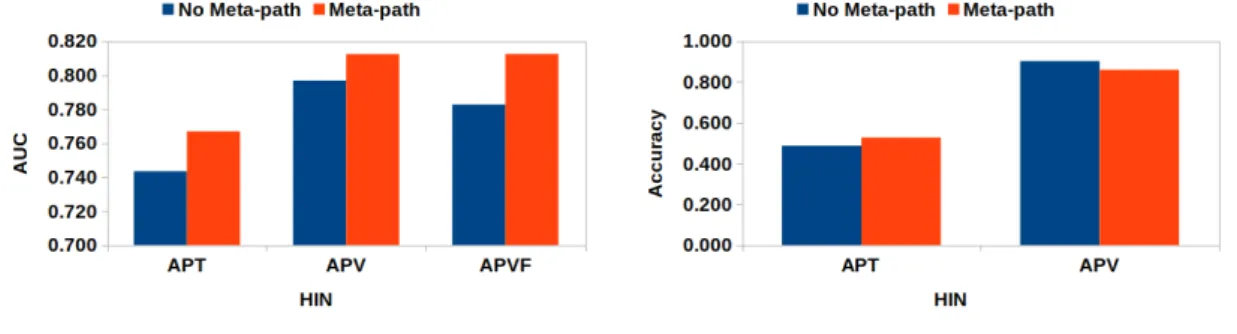
Out of all HIN variants considered for this task in DBLP-C, APV and AV rank lower than 71% and 57%, respectively, in terms of class imbalance, while AT has the highest amount of class imbalance. Further, it is clearly visible from Figure 7.2(a) that APVF and APV are ranked lower than 67% and 50% HINs, respectively, in terms of class imbalance, while APT has the maximum amount of class imbalance. Furthermore, in terms of class imbalance, APV ranks lower than 50% of the HINs, while AP has the lowest amount of class imbalance.
Network Schema, Class Imbalance, and Network Embedding 91
For example, any network embedding models are guided to follow APTPA metapath for APT, APVFVPA metapath for APVF, and APVPA metapath for APV-HINs. Since these meta-path-based HINs belong to DBLP-P, the experimental observation is consistent with the Section 7.5.2, i.e. Thus, it can be inferred that meta-path reduces the class imbalance but may perform differently in different scenarios.
Importance of Node Types
Effect of Class Imbalance on Centrality Estimation
Inter-class Centrality Distribution
Additionally, it should be noted that the closeness centrality measure is sensitive to the network scheme. It is obvious that in the case of DBLP-C, PPR assigns higher centrality to nodes belonging to lower cardinality classes regardless of the personalization parameter. Thus, it can be concluded that HINs under the click-based scheme are less sensitive to the personalization parameter and more biased by the degree distribution, while this may not be the case for the personalized HIN scheme.
Correlation Between Intra-class Ranking for APVTF and
Summary
This thesis proposes in Chapter 3 heterogeneous transformations for traditional common neighbor-based local similarity measures and spectral graph kernels for link prediction. Therefore, Chapter 6 proposes a new network embedding method for HINs that does not require explicit metapaths. Several experimental results show that the proposed network embedding method outperforms state-of-the-art link prediction baselines in most cases.
Limitation
Furthermore, selecting node types is as crucial as addressing class imbalance for efficient HIN embedding.
Future Works
A semantic-based recommendation system in heterogeneous networks,” in 18th Proceedings of the International Conference on Knowledge Discovery and Data Mining, 2012, pp. Zhu, “Structural deep network embedding,” in 22nd Proceedings of the International Conference on Knowledge Discovery and Data Mining, 2016, pp. Wang, “Coupledlp: Link prediction in coupled networks,” in 21st Proceedings of the International Conference on Knowledge Discovery and Data Mining, 2015, pp.