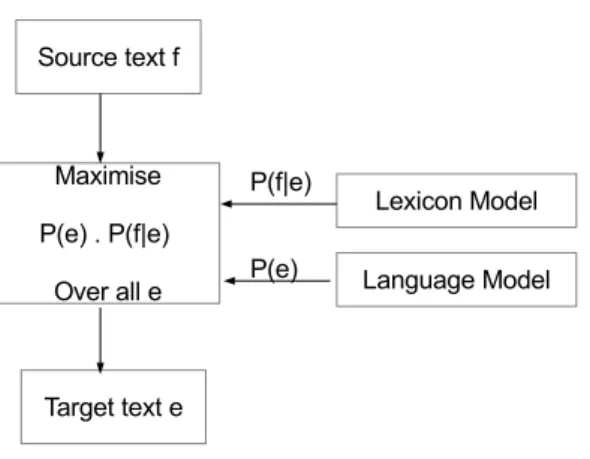
Machine translation (MT) is the task of automatically translating text from one language to another. When translating a text from one language to another, the quality of the translation can generally be measured based on two factors - relevance and fluency.
Approaches to machine translation
A transfer-based approach converts text from one language into an intermediate representation that captures the structure of the text and then uses this representation for translation into the target language. They use both rule and statistics when translating from one language to another.
Statistical MT
But in transfer-based MT, the intermediate representation is dependent on the two languages in question, while interlingua-based MT aims to convert to a representation that is independent of the two languages. It uses a parallel corpus, which contains a collection of sentences in one language and sentences in another language that are exact translations of the other.
Importance of large parallel corpora for SMT
So, we need methods by which we can automatically create parallel corpora with minimal effort. This will increase the size of available parallel corpora and therefore produce good quality translations.
Types of bilingual corpora
By exploiting comparable corpora, one can thus aim to extract some parallel sentences from them.
Common rules for parallel sentence extraction
This forms the basis for calculating similarity between different pairs of documents while extracting parallel sentences. This forms the basis for filtering non-comparable document pairs before extracting parallel sentences.
Outline
Out of the rules described above, only word overlap measure and sentence length can be applied across a wide range of corpora. The applicability of other principles such as context, position or word frequency depends on the degree of comparability of the corpus.
Summary
Greater the number of words that have translation on the other side, more likely the sentences are translations of each other. Parallel sentences usually tend to contain continuous words in one language that are translated into a continuous set of words in another language.
Iterative mining
The match score is calculated as the product of the translation probabilities of each aligned word in the sentence pair. For all documents in the collection, the target language is clarified with the help of a bilingual dictionary. For each document pair extracted, a word vector is constructed for each sentence in the document.
Then, for each sentence pair in the two documents, a similarity score is calculated and those above a threshold are output as parallel. For all sentence pairs extracted by the above step, lexicon conversion probabilities of all word pairs in the sentence pair are calculated.
Grammar based approach
Then both documents are represented as feature vectors and the similarity between the two documents is calculated. The alignment score measures, on average, how many known bilingual word pairs actually co-occur in the extracted parallel sentences. Then, once we have all the grammar rules needed to describe both languages, we assign a probability to each grammar rule and create a stochastic ITG.
Finally, to extract parallel sentences, the two sentences are parsed using the stochastic ITG grammar constructed earlier, and the best parse tree is constructed using the parsing algorithm described in (Wu, 1997). If the score of the obtained parse tree is above a threshold, the two sentences are considered parallel, otherwise they are discarded.
Extraction as information retrieval
Their premise is based on the fact that two sentences are likely to have similar syntactic structure on both sides and therefore, they try to exploit the sentence pair structure in the two languages. ITGs are synchronous grammars where we have grammar rules where each non-terminal produces two outputs one for each language. Moreover, ITGs also allow the inversion of production rules in two languages to be able to model well the phenomenon of word reordering in different languages.
For example, a grammar rule A → [BC] will produce B1C1 in one language and B2C2 in another language, while a rule A →< BC > will produce strings B1C1 in language 1 and C2B2 in another language.
Duplicate detection
Summary
In the context of identifying parallel sentences, LLR is used to estimate the independence of word pairs occurring in the corpus. A few words are said to be independent if they are not translations of each other. Each target word is linked to a word in the source that is most likely the translation.
If there is no word that aligns with the target word, a negative of that value in the signal or a value of a negative association to a word in the source that is least likely not to be its translation , that is, one with a high value of negative association, assigned. -1 if there is no matching source word for that target word in the p−distribution. This is then also repeated in the other direction and the resulting fragments of words in the source and target side are considered parallel phrase pairs.
Chunking based approach
It is the difference in the number of characters in the source and target phrases. It is the difference in the number of words in the source and target phrases. It indicates whether the first word in the source phrase is a translation of the first word in the target phrase.
It indicates whether the last word in the source sentence is a translation of the last word in the target sentence. It is the ratio between the number of source sentence words with translations in the target sentence and the number of words in the source language. It is 1 if at least half of the words of the source sentence have translations in the target sentence, otherwise 0.
In the current scenario, the query Q is C(f) and the document is C(e), where we define C(word) as the context of the word in the corresponding language.
Classifier based approach
Using hierarchical alignment model
Jason and Daniel, 2012) use an existing alignment model, in this case a hierarchical model, to extract parallel phrases. It also monitors back pointers during bottom-up parsing so that we can get the best derived tree that maximizes the alignment result. This derived tree gives a hierarchical partitioning of the alignment and associated word spans.
To extract parallel phrases, the tree is now parsed in a top-down fashion, examining the fragments pointed to at each node along with their results. We further note that traversing the tree in a top-down fashion ensures that the larger fragment is detected first before its smaller version.
Generative model for sentence alignment
They then extract the maximum-length fragment with the alignment result above a threshold as a parallel fragment subject to the following constraints. There are no unequal target words within the passage that are also related to source words outside the passage. But the conditional model is asymmetric and has many free parameters to tune.
Since conditional models generally outperform joint models, p(e, f) decomposes as p(e, f) = p(e)p(f|e) = p(f)p(e|f) and the minimum of of the two generative models is used as an estimate for the joint probability. Then, for each fragment, predict the number of source and target words generated by the fragment, and then finally generate the source and target words in each fragment.
Text entailment
To extract the phrases from these pairs of sentences, a seed corpus of parallel fragments is used.
Summary
Standard approach
In this step, all words that occur in the same context as the candidate word are obtained. The context word can be within a word box, or words within the same sentence or paragraph. In a typical arrangement one usually obtains the co-occurrence counts of the context words and the candidate word and then normalizes this by a mutual information score or log probability.
The next question regarding the choice of context word is which word should be chosen as context word. Furthermore, one can choose to use such context words that occur very frequently in the corpus.
Analogy to Document retrieval
In Proceedings of the 36th Annual Meeting of the Association for Computational Linguistics and 17th International Conference on Computational Linguistics - Volume 1, ACL ’98, pages 414–420. In Conference Proceedings of the North American Section of the Association for Computational Linguistics (NAACL), NAACL ’13. Improving the ibm word alignment model 1. Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics, ACL ’04, Stroudsburg, PA, USA.
I Proceedings of the 21st International Conference on Computational Linguistics and the 44th Annual Meeting of Association for Computational Linguistics, ACL-44, side 81-88, Stroudsburg, PA, USA. In Human Language Technologies: Den årlige konference i 2010 for den nordamerikanske afdeling af Association for Computational Linguistics, HLT. I COLING ’96 Proceedings of the 16th conference on Computational linguistics - Volume 2, pages 836–841, Stroudsburg, PA, USA.
In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies: Short Papers - Volume 2, HLT.
Classifier based approach
Random forest classifier
Discriminative classifier
Combined string and context similarity
Georgios et al., 2014a) propose a method for extracting word translations by combining string-level similarity and context similarity. In addition, they also consider second-order features where each feature is a tuple of grams. Thus, each feature is 1 or 0 depending on whether the source and target terms contain all ngrams present in the tuple.
Thus, if there are p source ngrams and q target ngrams, there are in all p×q possible second-order functions. Finally, they combine the results obtained by combining the output of both string-based model and context-based model.
Topic models
Summary
In NAACL HLT ’12 Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, ACL, pages 538–542, Stroudsburg, PA, USA. 2014). Proceedings of the 3rd Workshop on Hybrid Approaches to Machine Translation (HyTra), chapter Automatic Building and Using Parallel Resources for SBS of Comparable Corpora, pages 48–57.