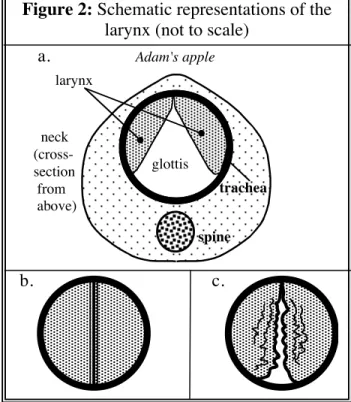
Similarly, a number of letters of the alphabet are not needed as IPA symbols for transcribing English consonant sounds. In an [l], the tip of the tongue often makes full contact with the alveolar ridge. We can also classify consonants according to the state of the larynx (phonation) during their pronunciation.
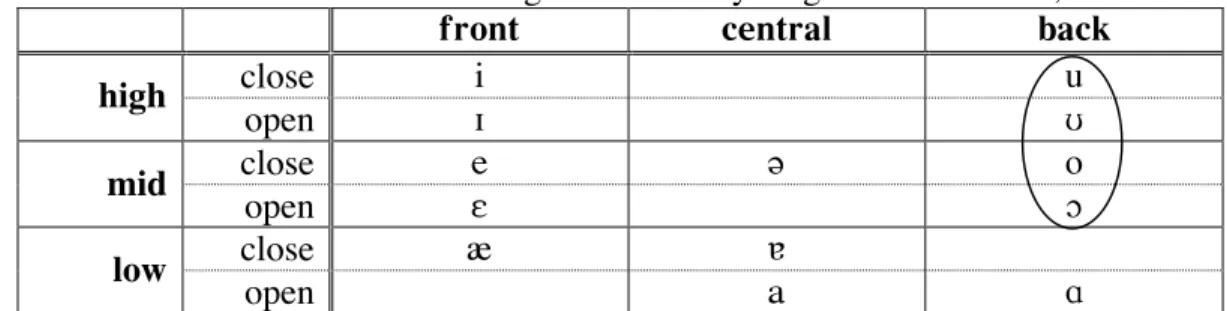
Post-alveolar (or palato-alveolar) ([S,Z]) involve constriction of the tip of the tongue and palate, immediately behind the alveolar ridge. 33 Our terminology here is an extension of IPA 'close' and 'open' for mid vowels.
Acoustic phonetics
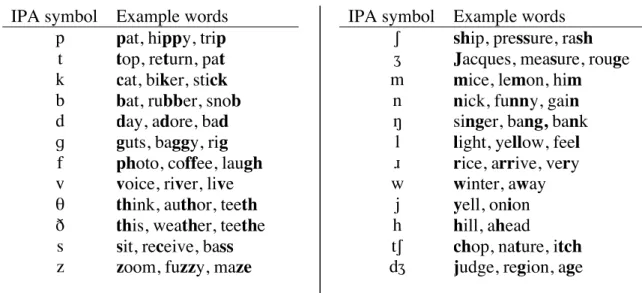
Give the IPA symbols for the sounds that correspond to the articulations shown in the following diagrams. Tuning is indicated by a zig-zag line at the larynx.). 300 Hz.4 Furthermore, the more extreme the pressure fluctuations, the greater the amplitude of the wave (measured in decibels) and the louder the sound. But just as we can sum simple sine waves to give the complex wave in Fig.
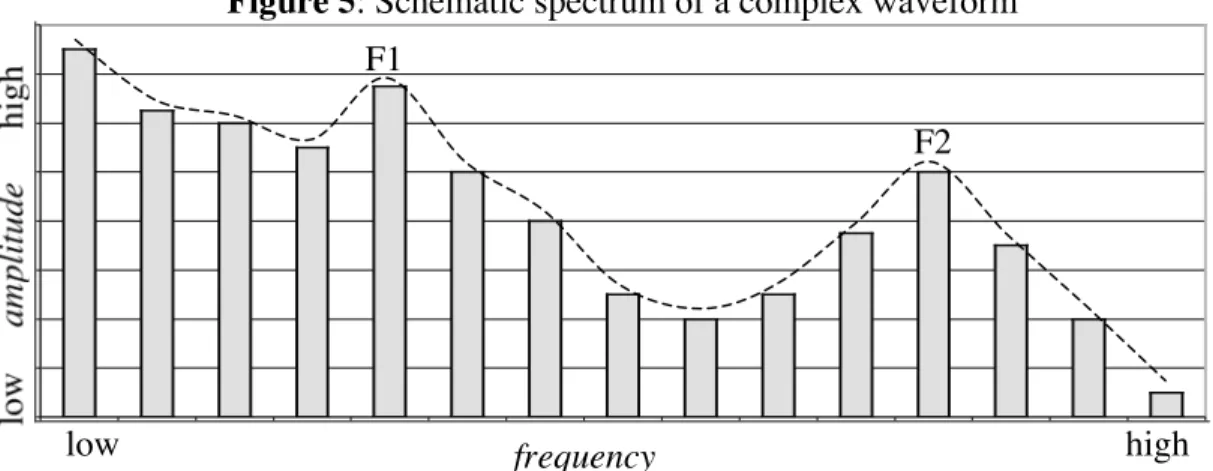
4c, we can also take a complex waveform and break it down into simple waves, each with its own frequency and amplitude (a mathematical technique called Fourier analysis). In speech, specific harmonics can be louder or quieter, depending on the position of the tongue and other organs of the vocal tract. The amplitude profile (the dashed line in Fig. 5) of these harmonics (the vertical bars of different heights) form a spectrum.
Peaks in the spectrum are called formants: the lowest-frequency peak above the fundamental is called the first formant or F1; the next is F2, and so on (only the first three formants are relevant for speech perception). However, it is more informative to show how the spectrum changes from moment to moment during speech. Such a display is called a spectrogram - with time on the x-axis, frequency on the y-axis, and the higher-amplitude frequency regions shown as darker areas (Fig. 6).
Vowel cues. Vowels are acoustically distinguished principally by the frequen- cies of the formants
Approximant cues. Approximants are similar in cues to vowels
The problem of variation in speech
But except in extreme cases, we are able to immediately recognize any utterance as merely a repetition of the same word, potato; indeed, we are generally not even aware of the variation. How is it that English speakers can – without any conscious thought – empathize with the properties of the sound signal that distinguish the intended word, in this case potato, from similar sounding words (e.g. tomato or petunia), without being distracted by the irrelevant differences. Speakers of other languages show the same ease in recognizing words from their language, despite similar variations in the signal.
Furthermore, the specific properties of the sound signal that distinguish one word from another vary from language to language. In English, for example, in the word boot ([but]) you can draw out the vowel for 400 msec (0.4 seconds) or shorten it to 150 msec (0.15 seconds): such a difference in vowel duration is merely insignificant. detail. But in the case of a first language, this knowledge appears to be acquired within a few years of birth, without any formal instruction—indeed, without much conscious thought.
In the remainder of this chapter, we focus on observing that languages obey phonological rules—rules about the sounds that can appear in the language and how these sounds can be put together to form the words of the language. Have you ever heard someone speak a language you didn't understand – yet you were able to recognize the language like French, Spanish, Chinese, etc. For example, you probably know how to pick up a carton of milk, a complex task that requires almost instantaneous estimation of the weight of the milk vs.
Psychologists call this 'implicit knowledge.' Speakers' knowledge of the phonological rules of their language is also implicit.
Phonemes and allophones
Indeed, it takes careful analysis and some understanding of phonetics to figure out what the rules are – even for one's own language.
Allophonic variation. Because the organs of the vocal tract generally move in smooth trajectories rather than abrupt jerks, sounds are inevitably influenced by the
This is not to say that anyone has ever sat down and consciously designed a phonological system. English speakers are generally unaware of this phonetic distinction in their speech, as there are no words distinguished solely by vowel nasalization. The closed vowels generally have a lower F1 than the open ones; but this is a minor difference and it is far from 100% reliable: some [E]s have a lower F1 than [e]s, even for the same speaker.
English has another trick up its sleeve: mid-mid vowels are heavily diphthongized in most dialects. Words such as day, fake, and so, boat are therefore narrowly transcribed [deI], [feIk] and [soU], [boUt] (the additional duration of mid-mid vowels is also reflected in this transcription, as there are two vowel symbols instead of one). These three cues working together make the close/open distinction in mid vowels more robust (ie, less likely to be misperceived).
Since there are no words in Spanish that separate from the closed/open distinction, Spanish speakers' mid vowels can vary between [e] and [E] without risk of confusion. The English vowel nasalization coarticulation described above, for example, can also be seen as a kind of perceptual enhancement: the nasalization of the vowel increases the perception of the following nasal consonant, thus preventing a word like bone from being confused with bowl or curved. By allowing the velum to descend sluggishly during the vowel + nasal sequence, rather than abruptly at the onset of the nasal, less articulatory precision and effort is required.
And by extending the space of the nasal sign to the preceding vowel, the perception of the nasal consonant is improved.
Phonemic analysis. To help us concisely describe the role of particular cues in particular languages' sound systems, linguists use the following terminology
The first step in solving the problem of phonemic analysis is to find a minimal pair in the data set, which means that here we do not have two words with different meanings, but two transcriptions of the same word with some variations in pronunciation. But the pattern can be explained more simply and insightfully by referring to the phonetic properties of the natural classes affected by the rule: a vowel is nasal before a nasal consonant and oral elsewhere.
Note that this rule statement claims that both diphthongs rise before a voiceless sound, even though we have no evidence in the data set that [aU] rises into [´U] before [k] or that [aI] does not rise before [k] . [D]. On the other hand, no data contradicts this rule; and the broader formulation of the rule conforms to our strategy of forming the most general hypothesis that the data permit (see sidebar). The best strategy is to formulate as general and far-reaching a hypothesis about the sound patterns of the language as the current data set allows.
For current purposes, you can assume that any dataset you get is fully representative of the sound patterns of the language. Scientific theories (including theories of language) allow us to make predictions about future data, by understanding the data we have and assuming that future data will behave in the same way. The sequences of vowel + [®] (which can be considered a kind of diphthong) are excluded from the rule, due to the reference to a high vowel as the second half of the diphthong.
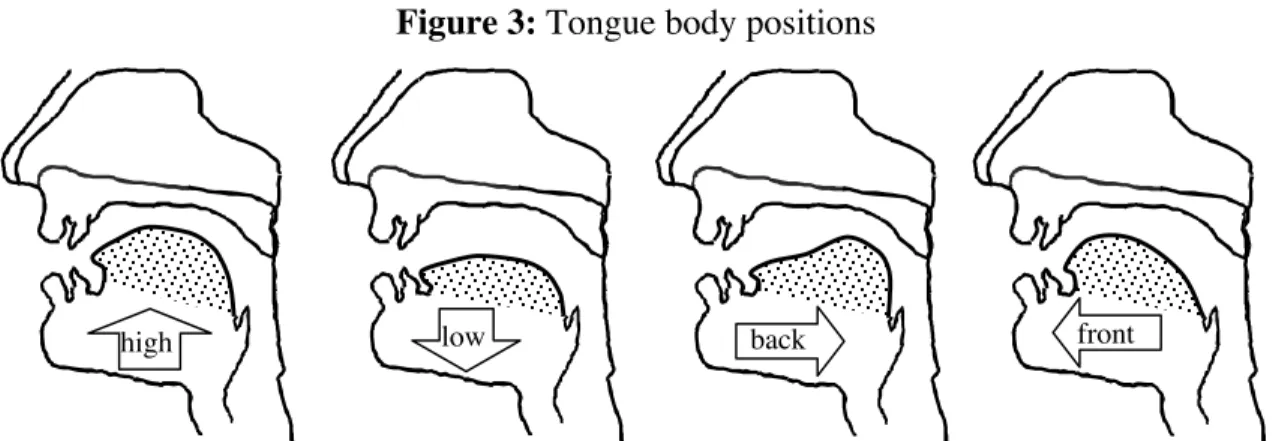
A diphthong beginning with a low vowel and ending with a high vowel involves considerable movement of the tongue body.

If all else fails. What do you conclude if you can find neither a minimal pair nor evidence of allophonic variation (free variation or complementary distribution)? This
Phonotactics
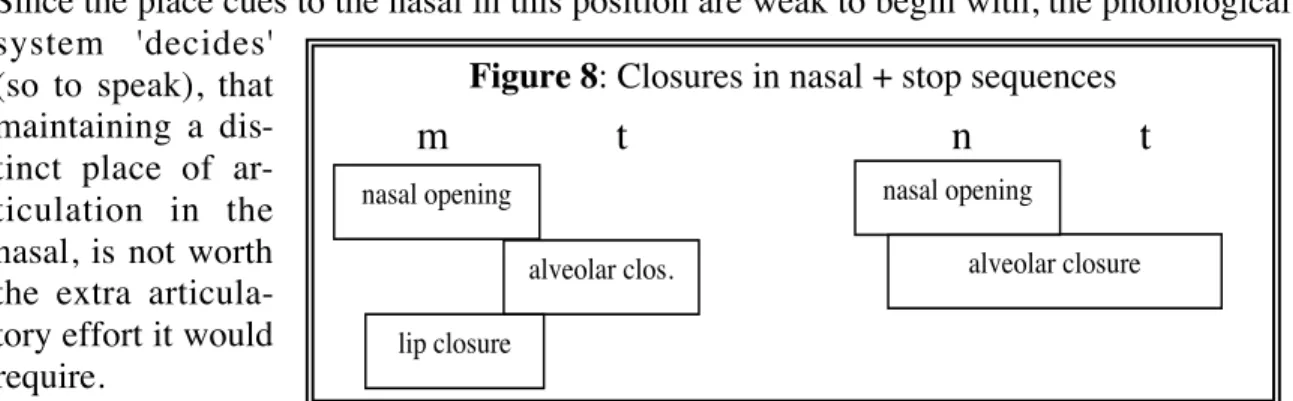
But there are also phonological ones. rules that limit how even the basic sounds of the language can be combined into words. The unacceptability of [tftkt] is also not due to any of the allophonic rules of English: [tÓftkt]. with allophonic aspiration of the initial /t/) is still unacceptable. The generalization here is that a nasal + stop sequence within words must have the same place of articulation: bilabial [mp], alveolar [nt], or velar [Nk].
The rule requiring the nose to be in the same place of articulation as the next stop can be expressed as follows:. The co-indexing of the position variable in the two parts of the line means that the position of the nose must match the position of the following consonant.). Vowels are typically the loudest part of the sound signal, and the perception of most consonants depends on, or is supported by, formant transitions in adjacent (or at least nearby) vowels.
Tashlhiyt Berber represents the extreme end of the spectrum, in terms of languages' tolerance for consonant sequences; but even in this language most of the words do have vowels between the consonants. Similarly, the requirement of shared place of articulation in nasal + stop sequences, seen in both English and Japanese, can be understood as a response to Ease of Articulation. The cues to place of articulation in a nasal are relatively weak before a stop, due to the absence of formant transitions to a following vowel.
Since nasal place cues in this position are initially weak, the phonological system 'decides'. so to speak), that maintaining a separate place of articulation in the nose is not worth the extra articular effort it would require.
Alternations
For present purposes, we can equate the base form of the stem with its pronoun. ciation in the absence of suffixes or prefixes. For example, the basic prefix form seen in {indiscreet, inherent, inactive, imprecise, unbalanced, improbable, ungrateful} is [I)n], which occurs in all contexts except before bilabial points [p,b]. The base of the noun stem in the diminutive can be equated with the bare noun (first column).
If we look down in the second column, however, we see two forms of the diminutive suffix: [c´] and [j´]. Since [j´] occurs in a wider range of contexts, it is the basic form of the suffix. Identify the basic forms of the stems and prefixes and state rules to account for any shifts.
Fundamental Frequency: The lowest frequency component of a complex waveform heard as the fundamental pitch of a speaker's voice, also called F0. Geminate: A consonant that lasts about twice as long as the normal duration of the corresponding single consonant. Nasalized: produced by lowering the velum, allowing air to flow through the nasal passages.
Pitch: The portion of a speech signal during which sound energy (and the configuration of the mouth to generate that sound energy) remains relatively stable.


![Figure 7: Spectrogram of [suSi]](https://thumb-ap.123doks.com/thumbv2/azpdfnet/10308368.0/16.918.407.779.677.966/figure-spectrogram-of-susi.webp)
