Corpus-based machine translation (MT) approaches dominate the MT research field today, with example-based MT (EBMT) and statistical MT (SMT) representing two distinct frameworks within the data-driven paradigm. We start with the introduction of the taxonomy of MT systems, followed by machine translation approaches.
Taxonomy of MT Systems
In this chapter, we conduct a literature review on machine translation with a focus on data-driven machine translation techniques. We then proceed to a brief description based on examples, statistical and hybrid machine translation techniques.
Difficulty in MT
Lexical/Phrasal Ambiguity
Each language also has its own idiomatic uses that are difficult to identify from a sentence.
Syntactic Ambiguity
Semantic Ambiguity
Ek bal en kolf met spel wees m{\ apn doen-tot\ к sAT хltA h hoofapne dosto ke saath khelta hoon.
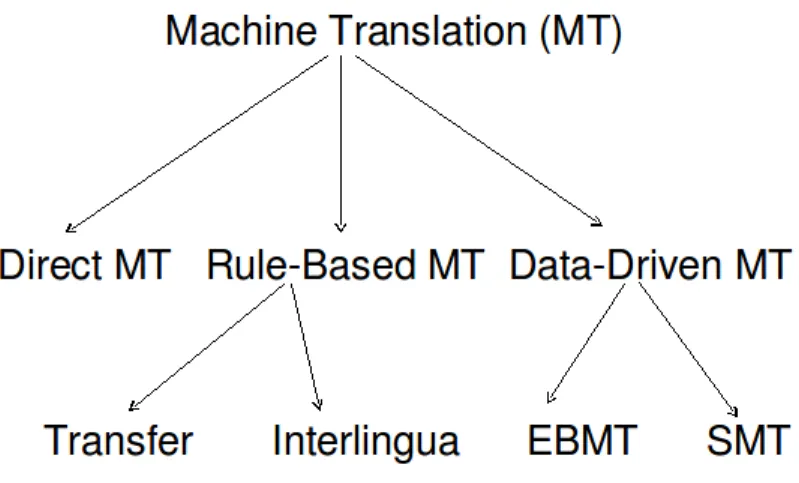
Approaches to MT
- Knowledge Driven Machine Translation
- Data Driven Machine Translation
- Hybrid Approaches
- Matching
- Alignment
- Recombination
Nagao (1984) also suggested how the modifiability of an example might be checked: "the replaceability of the corresponding words is tested by tracing the thesaurus relations". The corresponding translated segments of the target language are retrieved from the second part of the corpora.
Issues in EBMT
In this approach, sentences in the examples are replaced by these tokens, making the examples more general. In these systems, the examples are not stored at all, except to the extent that they occur in the corpus on which the system is based.
Translation Memory
Formalizing Translation Memories
Words: This is simply the order of the surface forms of the words of the sentence. Lemmas (Basic forms): The lemmas are part of the result of level analysis for a precise process of the sentences. XML empty tags: These tags handle objects that are inserted into the text flow of the XML segment.
The editing distance between layers sf1 and sf2 is the total cost of the sequence of elementary operations transforming sf1 into sf2 that minimizes this total cost. Let the above equation be the sequence of the number of these basic operations for editing S2 in S1.
Linking Translation Memory and EBMT
The way examples are found and stored, the matching techniques used, and the number of matches to be considered are common to both TM and EBMT. However, there are important differences, mainly stemming from the fact that a TMS is an aid to translators, where the user has the primary responsibility for making decisions, while EBMT is a way to do translation automatically. The main difference lies in the fact that a TMS basically only has the single step of matching examples, while the EBMT has to do something with the matches found.
Matching Techniques
- Introduction
- EBMT using DP-matching between word sequences
- A Matching Technique In Example-Based MT
- Two approaches to matching in EBMT
- Other Matching Techniques
The proposed approach extracts the most similar example by performing DP matching of the input sentence and example sentences while measuring the semantic distance of the words [Sum01]. In equation (1), dist is calculated as follows: The counts of the Insertion (I), Deletion (D), and Substitution (S) operations are summed and the total is normalized by the sum of the source and instance lengths. sequences. First, the step stores the hatched parts of the input sentence in memory for the following translation.
Second, the step aligns the highlighted parts of the source sentence with the corresponding target sentence of the translation instance using lexical resources. If this cannot be determined, maximize the sum of word frequencies in the generated translation models.
![Figure 2.3: Resources used in EBMT DP Matching [Sum01]](https://thumb-ap.123doks.com/thumbv2/azpdfnet/10306019.0/24.892.292.618.360.577/figure-resources-used-ebmt-dp-matching-sum.webp)
Adaptation and Recombination
Whenever an I or G transition is probed, the system calls these second levels of the DP algorithm which produces an additional local score due to the possible similarity of lemmas and word labels located between the corresponding fws. the corresponding parts of the two vectors that contributed to the similarity score thus obtained. Divergence is removed from the obtained segments by matching the segments according to the features of the input sentence. In such cases, recombination cannot proceed to produce complete translations since multipart alignments on the target side of the template will remain uninstantiated.
A recursive algorithm is invoked which attempts to match successively shorter portions of the source side against the chunks in the translation templates. The target equivalents are naively concatenated, according to the order of the matches with the portions of the source pieces.
Approaches to EBMT
EBMT Using Proportional Analogies
In the recombination phase, a direct match is sought between source sentence pieces and pieces in translation templates. It is possible that there are no translation templates that directly match chunks of text on the source page bound with unmatched parts covered by multi-chunks. This method attempts to match a source text chunk composed of multiple chunks from the set of translation templates.
Once C is produced in the source page, the translation equivalents < A, B, C > are found in the target page of the source page. Furthermore, the three components of the target page are used in the same order to obtain a candidate translation D.
![Figure 2.4: Architecture EBMT using Analogies [DSMN10]](https://thumb-ap.123doks.com/thumbv2/azpdfnet/10306019.0/28.892.212.698.633.846/figure-architecture-ebmt-using-analogies-dsmn.webp)
Template Driven EBMT
In the translation process, a certain source language sentence in surface form is translated into the corresponding target language sentence in surface form. For each selected template, the variables are instantiated with corresponding values in the source sentence. This system maintains the indexing scheme and subphrase similarities found in Panlite and adds a "light" version of the structural similarities found in the Gaijin system.
This system does not require a template, it finds examples that correspond to each sub-section of the input sentence. The limitations of the system are with combining results from two different probability distributions, which is a difficult problem.
EBMT Using Chunk Alignments
Comparison to other MT Techniques
EBMT and SMT
EBMT and RBMT
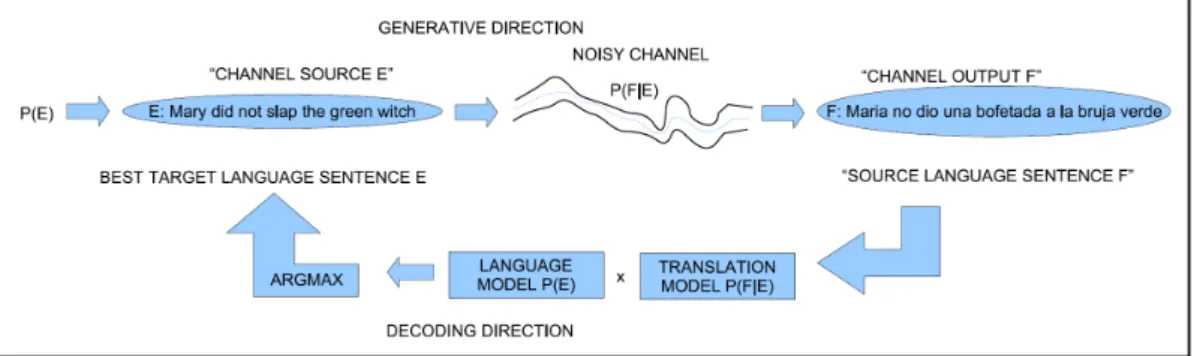
SMT models assume that every sentence in the target language is a translation of the sentence in the source language with a certain probability. Let's perfect the analogy and formalize the noisy channel model for statistical machine translation. We can ignore the denominator P(F) inside argmax since we are choosing the best Hindi sentence for a fixed foreign sentence F and therefore P(F) is a constant.
Note that applying the noisy channel model to machine translation requires looking at things backwards, as shown in Figure 3-1. We pretend that the Hindi input E is corrupted to a foreign sentence F while passing through a noisy channel.
Translation Models
The main intuition behind EM is this: If we know the number of times a word matches another in the corpus, we can easily calculate the word's translation probabilities. In other words, it adjusts the word translation probabilities so that the translation pairs in the training corpus get high probabilities. Now, given a parallel corpus of aligned sentences, we proceed in the following way to estimate translation probabilities.
Then, the probability expressing the word position in which English words end in the foreign sentence is the distortion probability, which depends on the length of the English and foreign sentence. The presence of house in the training data does not add anything to the knowledge about houses.
Decoding
Therefore, if there is no occurrence of house, it will be treated as an unknown word during translation despite the many occurrences of house. This approach to translation at the level of lemmas is highly desirable for morphologically rich languages. The compositional y-axis represents the degree to which rules are compositional as opposed to lexical.
The statistical z-axis represents the extent to which models make appropriate use of statistics as opposed to logic-based or set-theoretic methods.
Marker Based Hybrid MT
In the pre-processing stage, the source target-aligned sentences in the parallel corpus are segmented at each new occurrence of a marker word, subject to the constraint that each marker part contains at least one non-marker word (or content). The identification of relatives is implemented using the Levenshtein distance algorithm, with pairs of words < source, target > with a distance below an empirically set threshold considered as close. A word pair < source, target > with a high MI score indicates that they co-occur frequently within the corpus.
Hybrid Rule Based and Example Based MT
- CMU EBMT
- Marclator
- ALEPH - Proportional Analogies
- Gaijin Template Driven EBMT
One possible explanation is that evaluation based on WER metrics and individual translations may not fully reflect the actual contribution of TM, and better metrics are needed to evaluate MT systems. Construct all analog equations with the input sentence D and with all corresponding pairs of sentences (Ai , Bi ) from the source part of the bicorpus. For those sentences that are solutions of the previous analogical equations and do not belong to the bicorpus, translate them recursively using the present method.
For those sentences x = Ci,j, which are solutions of the previous analogous equations and belong to the bicorpus, do the following;. Construct all analogical equations with all possible target language sentences corresponding to source language sentences.
![Figure 5.1: The CMU EBMT System [Kim10]](https://thumb-ap.123doks.com/thumbv2/azpdfnet/10306019.0/50.892.174.745.102.487/figure-the-cmu-ebmt-system-kim.webp)
SMT Systems
GIZA++ - Aligner
Gaijin (Veale & Way 1997) is such a system, which uses statistical methods, string matching, case-based reasoning, and template matching to provide a linguistically lightweight solution to EBMT. The only linguistics Gaijin uses is the Psycholinguistic Constraints Hypothesis, which is minimal, easy to use, and arguably universal. Construction Generation Models: Used for a factored model where rules need to be defined to generate the final word from its components.
Create configuration file: All parameters learned during training are dumped into a configuration file called moses.ini.
Moses Decoder
Hybrid MT Systems
- Cunie System
- OpenMaTrEx System
- BLEU
- NIST
- Meteor
- Subjective Evaluation
Translation evaluation is nothing more than measuring the correctness of the translated text. If the length of the reference is equal to the length of the candidate sentence, then the penalty is 0. Hybrid techniques were briefly discussed followed by a description of existing MT systems and Machine Translation evaluation criteria.
Proceedings of the ACL 2005 Workshop on Building and Use Parallel Texts: Data-Driven Machine Translation and Beyond, 2005. In Proceedings of the Year Meeting of the Association for Computational Linguistics, demonstrasiesessie, 2007.
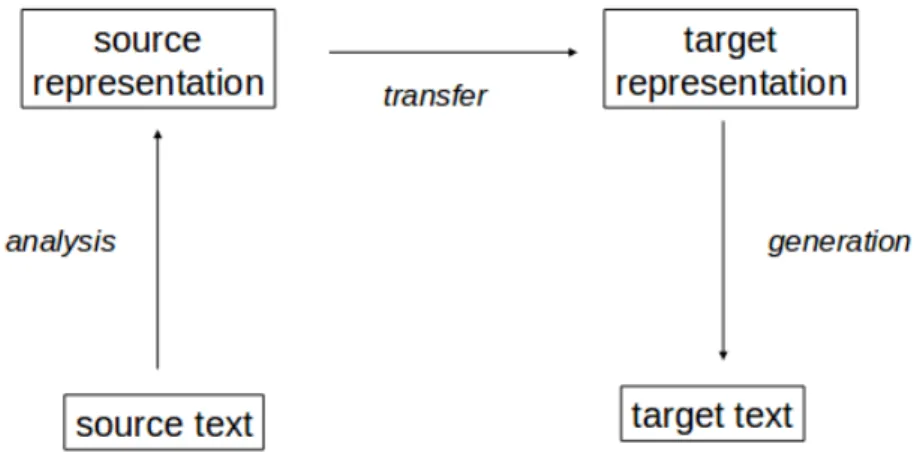
The Vauquois Triangle [Bha08]
MT Approaches
The Transfer Based Approach
The Vauquois Triangle Modified for EBMT [Som99]
The TELA Structure [PF99]
Resources used in EBMT DP Matching [Sum01]
Architecture EBMT using Analogies [DSMN10]
Chunk Translation Sequence pair extraction [KBC10]
Noisy channel model for translation
The MT Model Space
OpenMaTrEx is the FOS version of the core components of MaTrEx, a data-driven machine translation system designed by the Machine Translation Group at Dublin City University's School of Computing (Stroppa and Way 2006, Stroppa et al. 2006). In BLEU, each MT output line is ranked by the weighted average number of overlaps of N-grams with human translation [PRWZ02]. Combines the modified N-gram accuracies using a weighted average of the logarithm of the modified accuracies.
Sentence brevity penalty: BLEU considers the length of the proposed sentence and the reference sentence using a sigmoid filter. 4 Most of the meaning is conveyed 3 Much of the meaning is conveyed 2 Little meaning is conveyed. Linguistic knowledge of the system can be easily enriched in the case of EBMT by simply adding more examples, in contrast to knowledge-based approaches where the rules must be clearly stated.
In Proceedings of the Joint Conference on Human Language Technologies and the Annual Meeting of the North American Section of the Association of Computational Linguistics (HLT-NAACL), 2003.
The CMU EBMT System [Kim10]
Comparison between EBMT and SMT
Comparing EBMT and RBMT
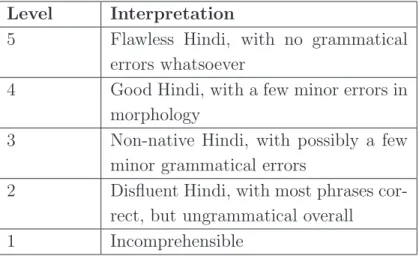
Subjective Evaluation - Fluency Scale
Subjective Evaluation - Adequacy Scale
![Figure 1.1: The Vauquois Triangle [Bha08]](https://thumb-ap.123doks.com/thumbv2/azpdfnet/10306019.0/10.892.185.728.101.501/figure-the-vauquois-triangle-bha.webp)
![Figure 2.1: The Vauquois Triangle Modified for EBMT [Som99]](https://thumb-ap.123doks.com/thumbv2/azpdfnet/10306019.0/17.892.203.712.97.379/figure-vauquois-triangle-modified-ebmt-som.webp)
![Figure 2.2: The TELA Structure [PF99]](https://thumb-ap.123doks.com/thumbv2/azpdfnet/10306019.0/23.892.124.779.97.398/figure-the-tela-structure-pf.webp)
![Figure 2.5: Chunk Translation Sequence pair extraction [KBC10]](https://thumb-ap.123doks.com/thumbv2/azpdfnet/10306019.0/31.892.239.682.587.1021/figure-chunk-translation-sequence-pair-extraction-kbc.webp)


