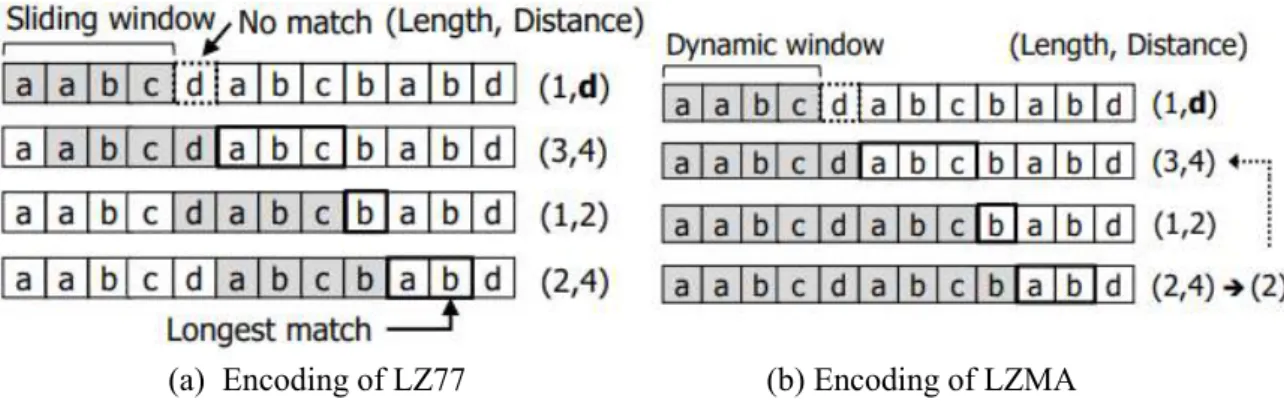
Note that as the encoding progresses, the length of a new phrase (that is, the number of symbols in the phrase) is determined by the longest matching subset of symbols that can be found in the sliding window. There is one exception when = 1 (i.e. the phrase consists of a single symbol), the symbol itself is encoded instead of the distance being encoded.
System Design
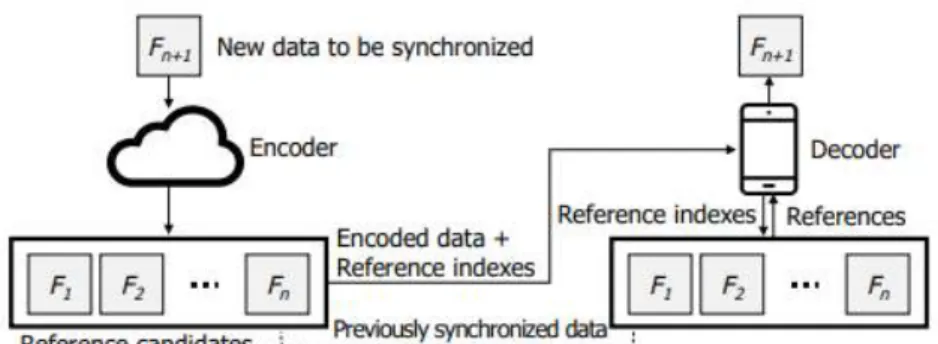
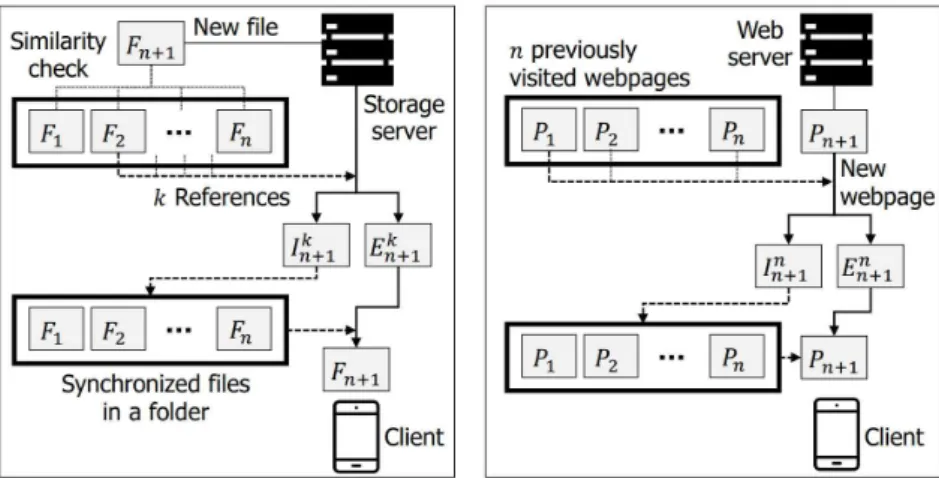
In this section, we formally identify the problem that SyncCoding addresses and propose the design of SyncCoding. We then provide a mathematical analysis of the design and explain how it compares with that of LZMA. To decode , let's SyncCoding first decode to call the references on the decoder side.
We then let SyncCoding create the associated file as if it were done in the encoder and compress it with LZMA. Once we get the output, we add it to the front of to create a compound and decode the compound with LZMA.
Comparative Analysis
Having a smaller number of phrases that will encode a smaller number of length-distance pairs is the main factor in reducing bits to encode for SyncCoding. Also, there is another side effect which is the increase in the distance of a length-distance pair. Thus, this larger bit increment is affected by the number of references and is limited by log2 k bits.
Under this setting, we derive an upper bound on the bit size of SyncCoding by assuming possible worst cases in combination as follows: 1) the distance to be coded in each length-distance pair is either not found based on one of the four last used distances or not with length one, 2) the phrases to be encoded whose length is one are completely removed using the references, for example = 0. These arguments with the Jensen inequality2 let us conclude that this at the top is bounded by the following lemma . This implies that selecting references that effectively reduce the number of sentences to be encoded is the key for SyncCoding to be superior to LZMA.
Questions on SyncCoding
It is complex to find the solution for γ that guarantees ℎ() > 0, but it is not difficult to show numerically that there exists γ < 1 that satisfies ℎ() > 0.
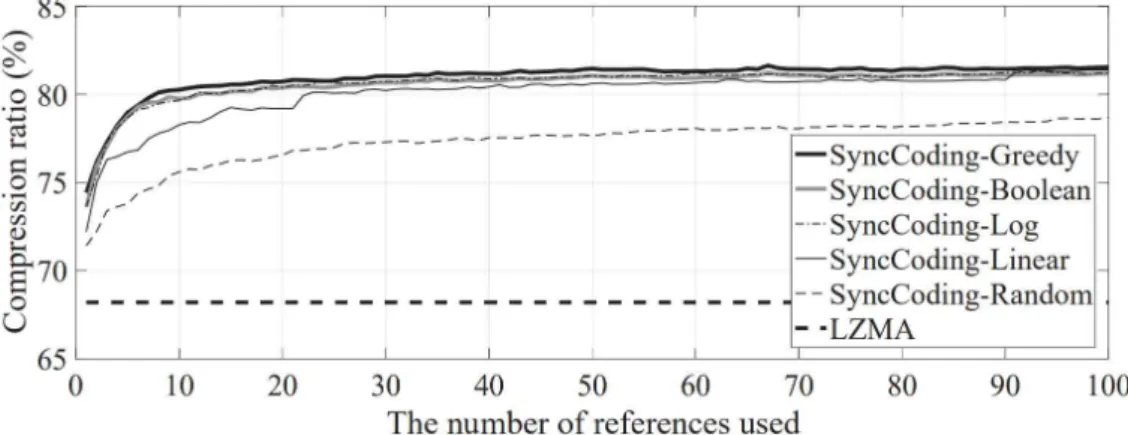
To validate the effectiveness of the proposed similarity measure, we randomly selected and downloaded a research paper from Google Scholar [27] with a keyword “wireless network”, which is arbitrarily chosen. Note that the compression ratio is the fraction of the compressed amount over the size of the original file, where the compressed amount is the difference between the size of the original file and the compressed file. In particular, with the reference candidate with the highest similarity rank, SyncCoding-Boolean achieves about 72.6% compression ratio, which means that the compressed size is only 27.4% of the original size.
Comparing this result with LZMA, which achieves the compression ratio of 68.2% and results in the compressed file whose size is 31.8% of the original, SyncCoding reduces the size of the compressed file by about 13.9% only with one well-chosen reference. 4 only considers the size of the compressed amount when evaluating the compression ratio and does not consider the cost of indexing the references, which will be discussed in the next subsection. Given that the computational complexities of the greedy search and SyncCoding-Boolean are () and (N)3, respectively, it is reasonable to conclude that SyncCoding-Boolean is a viable solution to the reference selection problem.
Maximum Compression Efficiency
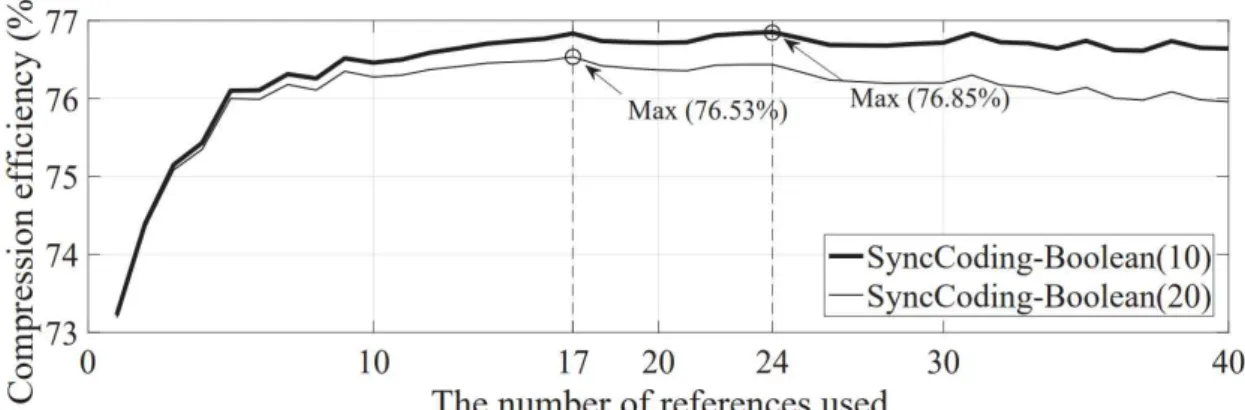
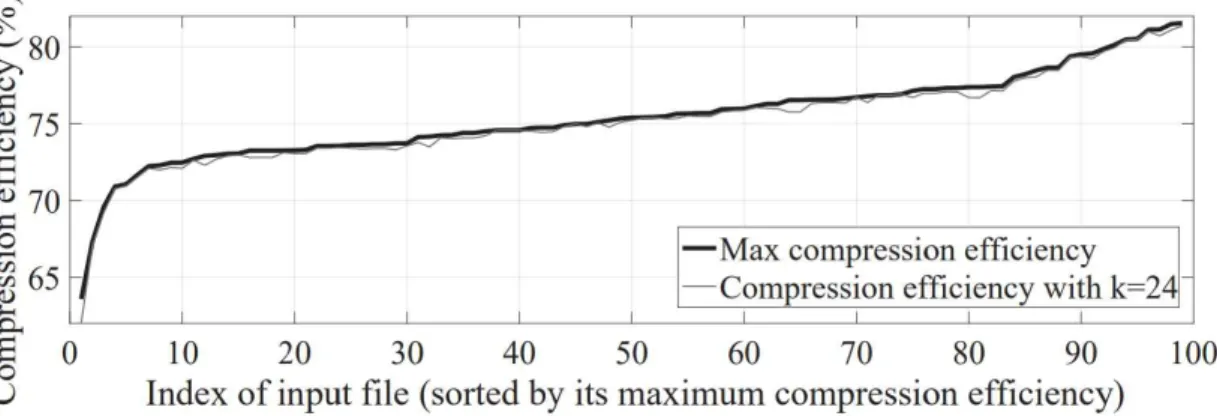
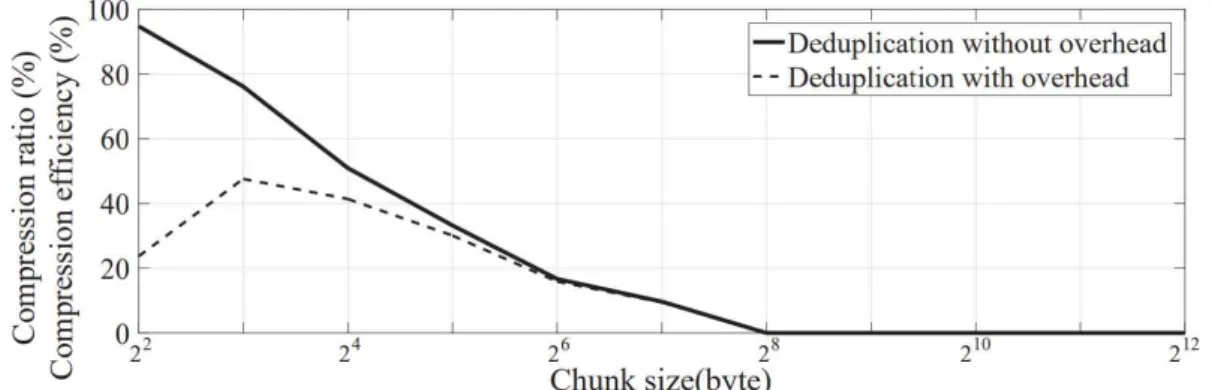
4, we also include for comparison the compression rates from a greedy search, where the reference that maximally improves the compression ratio out of all remaining references is added to the existing set of references and from a random addition. Maximum compression efficiency of SyncCoding obtained from 100 randomly selected documents is compared with the compression efficiency of SyncCoding using only 24 references. To avoid confusion, we define compression efficiency as the compression ratio evaluated with the compressed volume including overhead, i.e. the ratio of the compressed amount plus overhead to the original file size.
The number of references that achieves the maximum compression efficiency is 24 and 17, which confirms the intuition that a higher overhead per reference makes the compression efficiency saturated earlier with respect to the number of references used. However, the maximum achieved compression efficiency does not change much, even with higher overhead per reference. 6, we show the maximum compression efficiency from 100 input documents in ascending order, and for the same input document, we also plot the compression efficiency achieved with 24 references, which is the optimal number of references in Figure 6.
Referencing Overhead Optimization
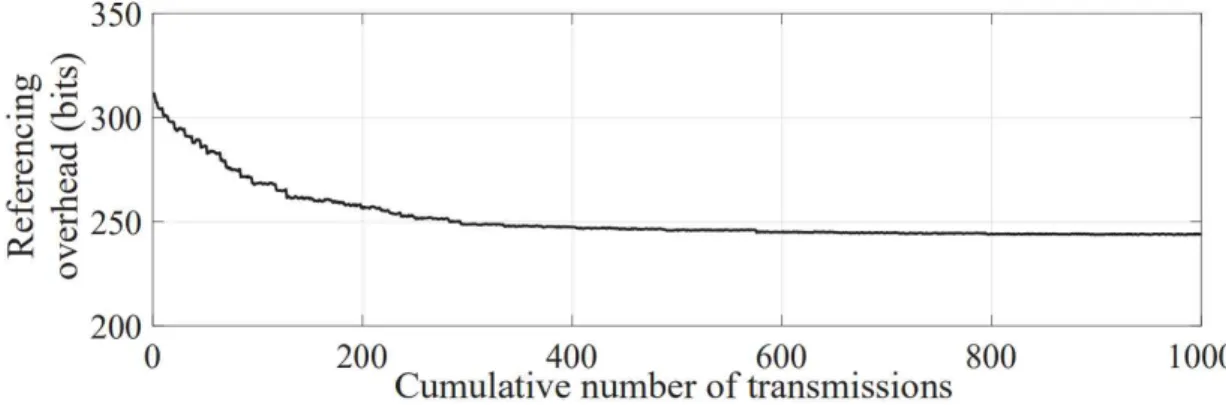
Therefore, unless otherwise specified, we choose to use k∗= 24 as our default reference number for all the following experiments. Reference overhead by indexing references with Huffman coding when reference candidate reference frequencies are updated during transmissions. Similarly, on each file transfer between end hosts, can be updated for all synchronized files and the reference indices can be reassigned accordingly.
We test the total referencing overhead for each file transfer where a thousand randomly selected files from the database are transferred sequentially, each with 24 references, and the indexes are updated as mentioned above. On a test, all other unchosen files are considered previously synced and used as reference candidates. Data centers with a large number of synchronized files in particular can benefit more from this.
Encoding Time and Decoding Time of SyncCoding
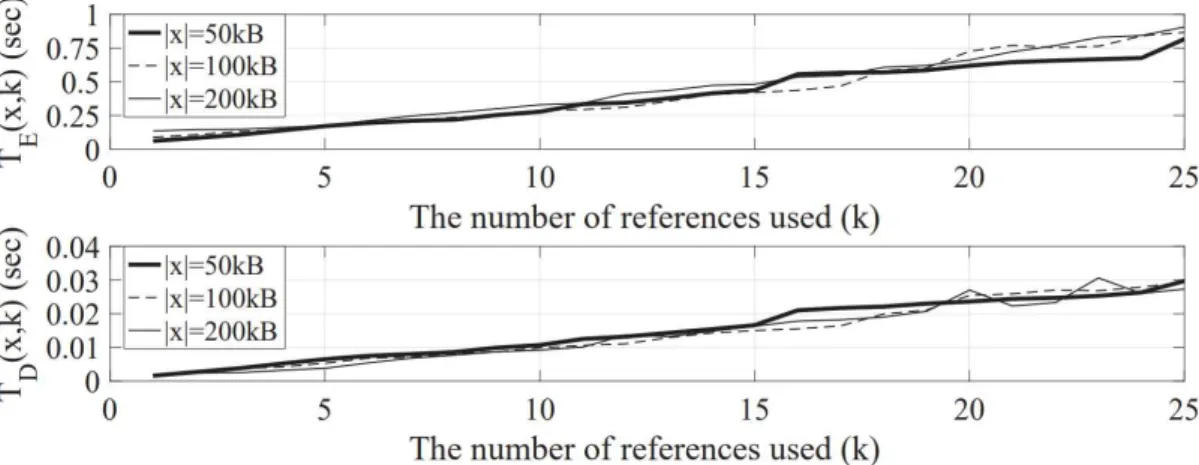
However, in the remaining sections, we use fixed-length indices to characterize the performance of SyncCoding more conservatively. Because the complexity of SyncCoding encoding and decoding with references is not much different from the complexity of LZMA repeated with times, it is expected that (, ) and (, ) grow linearly with increases for a given. 8, a measurement on Linux (Kernel el5) on an Intel i7-3770 CPU (3.40 GHz) for three types of research papers of about 50, 100, and 200 kB, randomly selected from the aforementioned dataset in Section 5.1, confirms that the average encoding time as well as the average decoding time from a hundred trials increases almost linearly in . Fig. 8 also confirms that the size of has little impact on time, because the size of the data to encode is relatively smaller than the total size of the references.
The decoding time is on the millisecond scale and is relatively negligible compared to the encoding time, which is on the second scale. One important thing to note is that the encoding time can often be hidden from users due to the following reasons: 1) the existence of a powerful encoding server, 2) parallelism between the encoding process and the network transfer process, and 3) SyncCoding preprocessing in the server. We will explain more about the usefulness of SyncCoding preprocessing for practical use cases in Section 6.
Mobile Energy Consumption of SyncCoding
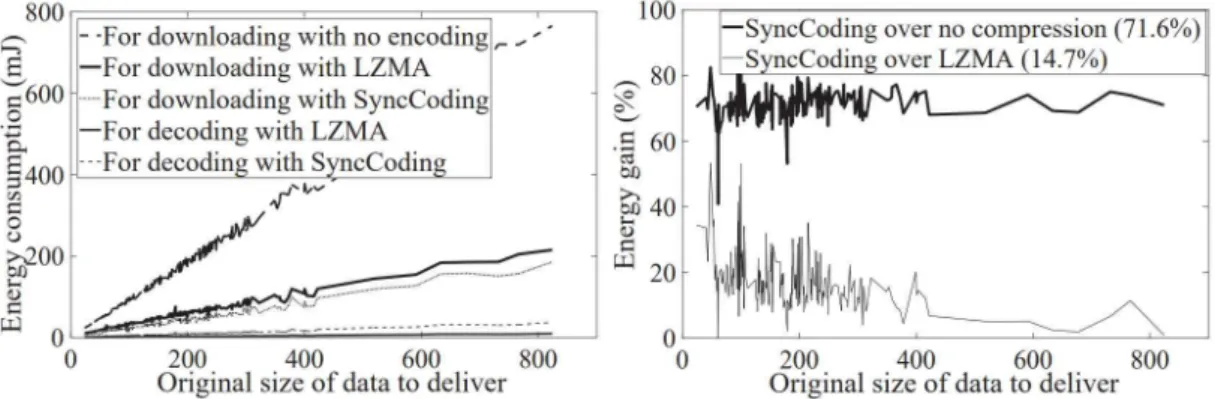
Energy consumption measurement results in the Galaxy Note 5 smartphone for downloading and decoding variable size data with SyncCoding and LZMA. We randomly select an input file (i.e., the target paper to be compressed) from this dataset and use 24 reference files (i.e., ∗= 24) selected from all other documents. The energy consumption for downloading, as well as decoding, increases almost linearly with the size of the input file.
Average profits are presented in parentheses. a) The energy consumption for downloading and decoding data of variable sizes with SyncCoding and LZMA. We note that the energy gain of SyncCoding may be affected by network conditions or computational efficiency of mobile devices. We evaluate the effectiveness of SyncCoding in two real data synchronization services: 1) cloud data sharing and 2) web browsing.
Settings
The scenario we consider for cloud data sharing is to synchronize a new file of an existing folder from the storage server to the user's device, given that the folder already includes about a hundred files relevant to the new file. In the case of data sharing in the cloud, where users are less sensitive to synchronization delay, the processing time for SyncCoding can be successfully hidden from users. For parameters inherited from the LZMA implementation, we take the values from LZMA with the maximum compression option.
LZMA: For the evaluation of LZMA, we use its SDK (Software Development Kit) provided in [25]. Deflate: For the evaluation of Deflate, we use [32], a popular open source library that includes Deflate with all the parameters from the maximum compression option. Deduplication: For deduplication evaluation, we modify OpenDedup [21] to investigate its ideal deduplication performance for documents.
Use Case 1: Cloud Data Sharing
Compression efficiency of SyncCoding and other techniques (a) for different sizes of documents to be encoded, (b) for different numbers of references. c) A comparison of the compressed sizes of the 50 target documents when using ∗ references. For evaluating SyncCoding and other encoding techniques besides Deduplication, we consider a randomly selected file from the folder as the target file to encode for synchronization and assume that all other files in the folder are reference candidates. We perform the following three tests and evaluate the compression efficiency of SyncCoding and other techniques:.
12 (a) shows the average compression efficiency with 90% confidence intervals for different sizes of documents to encode and reveals that SyncCoding consistently outperforms others. We further test the compression efficiency of SyncCoding and other techniques on the outcomes of deduplication with a hundred reference files and its best part size in Fig. Compression efficiency of SyncCoding, SyncCoding-Cached and three other encoding techniques for the webpages visited consecutively by sample visit history obtained from (a) CNN (Politics section) and (b) Yahoo (Science section). c) A comparison of the average compressed sizes of web pages from three websites with no section restriction.
Use Case 2: Web Browsing
The compression gain of SyncCoding over LZMA with 90% confidence intervals for three encryption algorithms and for no data encryption. 18 shows the average compression gain of SyncCoding over LZMA with 90% confidence intervals for three encryption algorithms when the data is compressed after and before encryption. When the data is compressed before encryption, the gain of SyncCoding over LZMA is about 31.2%.
Lee, "Synccoding: A compression technique exploiting references to data synchronization services," in IEEE 25th International Conference on Network Protocols (ICNP), 2017. A lossless text transformation to improve compression," in IEEE International Conference on Information Technology:Coding and Computing , 2001. Miao, “Quicksync: Improving synchronization efficiency for mobile cloud storage services,” in ACM International Conference on Mobile Computing and Networking, 2015, p.
Kenny, "Cosine-ooreenkomstelling sonder telling normaliseringstegnieke," in Odyssey: The Speaker and Language Recognition Workshop, 2010. Chambliss, "Mixing deduplication and compression on active data sets," in Data Compression Conference (DCC pp.