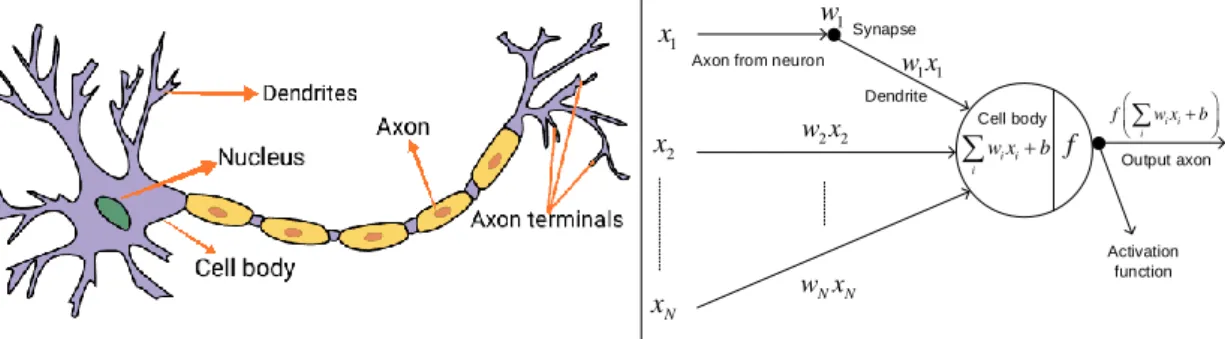
인공신경망은 다양한 분야에서 활용되며 중요한 역할을 한다. 특히, 인공 신경망 알고리즘의 수렴 속도를 가속화하기 위해 훈련 데이터 시퀀싱을 제안하는 이론적 접근 방식이 없습니다. 이 시퀀스는 단층 퍼셉트론 수렴 알고리즘을 위해 이론적으로 제시되었으며, 또한 구조가 다른 퍼셉트론을 위해 새로운 수렴 알고리즘을 생성하였다.
이러한 수렴 알고리즘의 증명을 바탕으로 수렴 속도를 높일 수 있는 훈련 데이터 시퀀스를 제시하고, 확장된 수렴 정리와 훈련 데이터 시퀀스의 효과를 수치 예를 통해 제시하였다. 퍼셉트론은 Rosenblatt[2]에 의해 처음 도입되었으며, 실수 값 벡터를 입력으로 받아 논리적 출력을 생성하는 매개변수화된 함수입니다. 그리고 기계 학습에서 퍼셉트론은 이진 분류기라고 하는 분류를 위해 단 두 개의 관련 범주로 분류되는 훈련 데이터의 감독 학습을 위한 알고리즘입니다.
Since the perceptron algorithm can converge slowly when Ω is a large dataset, we provide approaches to make the algorithm converge more quickly in Chapter 4. Neural networks are part of a broader family of machine learning, which is one of the most important topics in computer science and is a category of artificial intelligence (AI).
Brief history
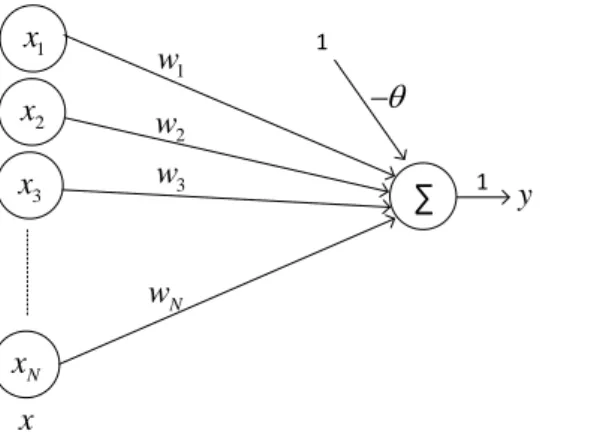
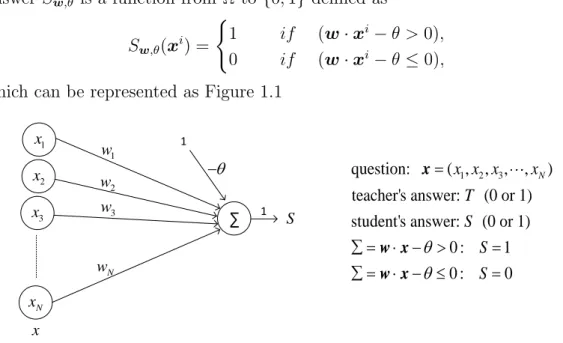
The model returns 1 if the dot product of the two vectors is greater than a threshold θ. Until 2006, researchers failed to train deep networks, so they were not sure if deep networks could be trained. Interest in deep feedforward networks was revived by two papers in 2006 [13] where they found that backpropagation can actually work well with deep networks as long as appropriate activation functions are used and the weights are initialized in a smart way.
In many fields they use collection of data that is large in volume and grows exponentially over time. This type of data is called big data with such large size and complexity that none of the traditional data management tools can store or process it efficiently. So AI comes here to solve the storage and management of such big data with the help of various methods like artificial neural networks.
AI and big data complement each other: a lot of data is needed for AI to be effective. Neural networks play a very important rule in technology such as in robotics, social media applications, online shopping, medical robots and biology, where Sang-Mok Choo [16] proposed a Boolean forward neural network modeling by neural network and Boolean combining network modeling identifies control targets that can induce desired cellular state switching.
Supervised machine learning algorithms
Linear classifier
Single and multi layer neural network
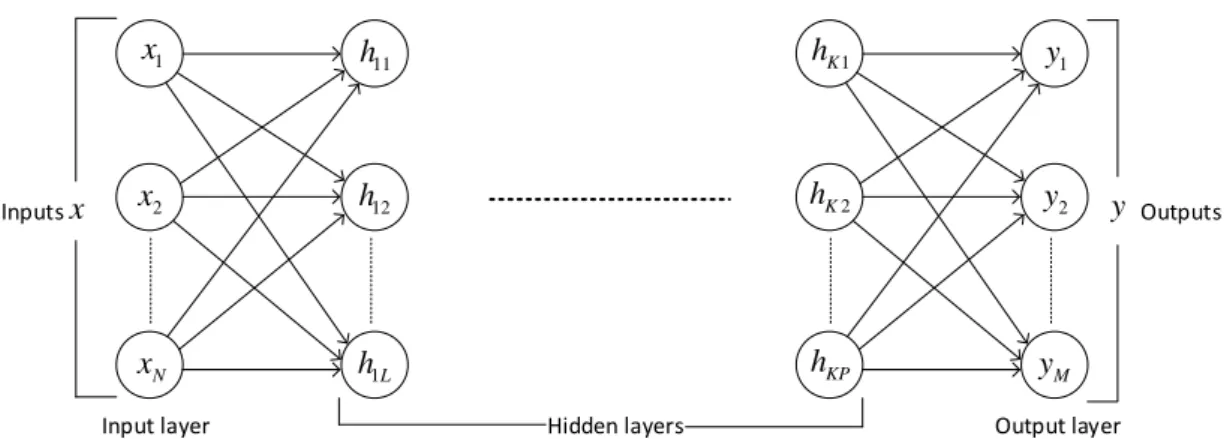
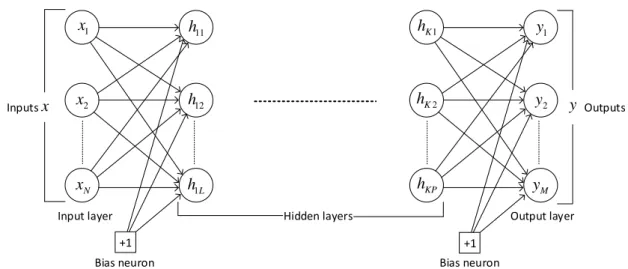
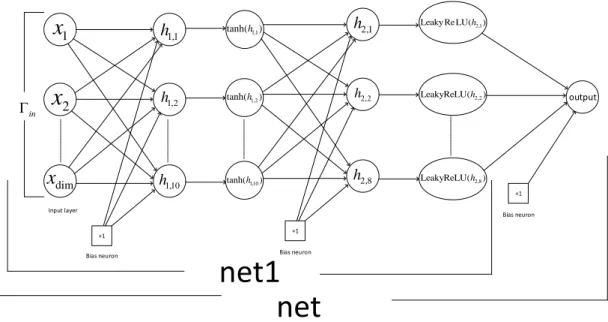
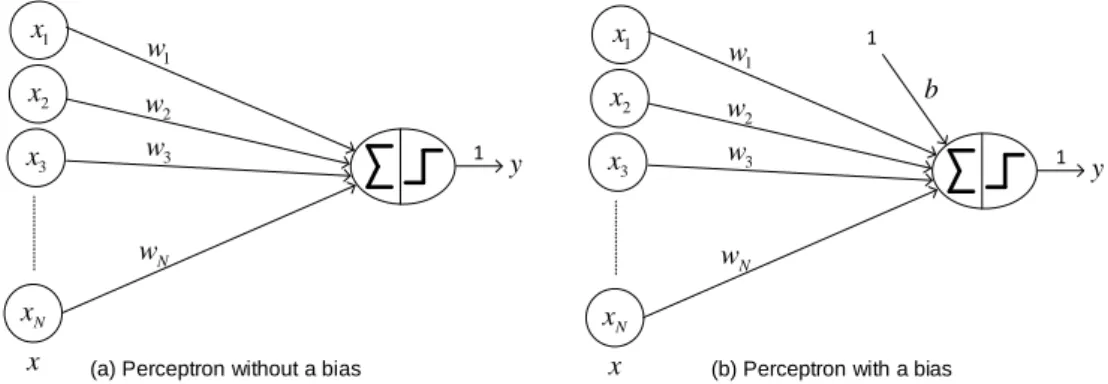
This simple neural network is also referred to as the perceptron, which is defined in subsection 2.2.1. a) Perceptron without bias (b) Perceptron with bias. Multilayer neural networks [5] contain several computational layers, and the additional intermediate layers (between input and output) are referred to as hidden layers. The basic multi-layer neural networks are called feed-forward networks because each neuron in one layer has directed connections only to the neurons in the subsequent layer, where the direction is from input to output.
Figures 2.4 and 2.5 are general forms of unbiased and biased multilayer neural networks, each with K hidden layers. Starting from the input layer, the data is propagated forward to the output layer, which step is called forward propagation. The network parameters are then updated in the direction of reducing the error (the sum of the squares of the difference between the predicted and the known result) using a back-propagation algorithm.
In this chapter, we rewrite the convergence proof of the perceptron learning algorithm and make extension theorems of the perceptron learning algorithm. Note that the assumption of Theorem 3.4 is the existence of a hypersurface ψ(w∗·xi−θ∗) = 0(x∈R) separating the given set.
Extensions of the algorithm
In this chapter we present a generalized upper bound of the extended algorithm and construct the sequence of training data to accelerate the convergence speed. Then for any fixed m, {wm,n} and {θm,n} reach Case 1 (update stops) at iteration number n if the following inequality satisfies. Using the proof of Theorem 3.5 we have that when (wm,n, θm,n) is updated, n must satisfy the following inequality.
To find w, θ leading to Case 1 and the number of iterations defined in Theorem 3.5, let Ω. To find what leads to Case 1 and the number of iterations defined in Theorem 4.2, let Ω. In this example we show the application of our theorems to linear non-separable data.
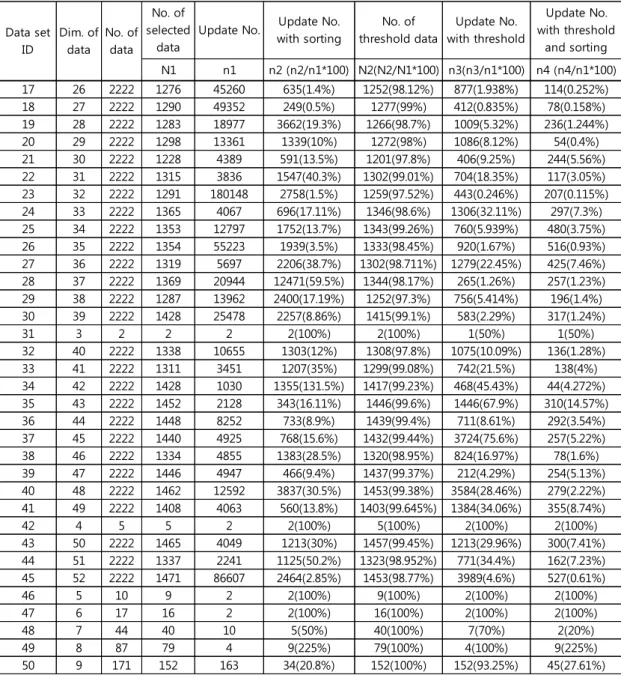
First we generate 50 input and objective data sets of Boolean states and then add 10% of the same input data with different objective data for each data set to make linearly separable data as Table 5.4, where the dimension and the number of input data are marked with 'Dim. To select the linearly separable data Ω from the non-separable data as well as T defined in Ω, we use a deep neural network, which is net=nn. Sequential(nn.Linear(dim,10), nn.Tanh(), nn.Linear(10,8), nn.LeakyReLU(), nn.Linear(8,1)). In the case of the first input and target data set (Γin,1,Γtar,1) in Table 5.4, we define the linearly separable data set Ω1 as net1(Γin,1).
The data number of Ω1 and the update number are 224 and 446 which are marked with 'No. Pitts, "A logical account of ideas immanent in neural activity," Bulletin of Mathematical Biophysics, vol. Miyake, “Neocognitron: A Self-Organizing Neural Network Model for a Visual Pattern Recognition Mechanism,” in Competition and Cooperation in Neural Networks, p.
Bengio, "Understanding the Difficulty of Training Deep-Feedback Neural Networks," in Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, pp.