This paper proposes a deep learning-based mission planning algorithm for UAVs, which deals with heterogeneous types of missions. Then, we solve the problem using an attention-based reinforcement learning approach with its fast computation time and flexibility. We introduce the unified mission representation on heterogeneous missions and the action masking strategy to use an attention-based neural network for heterogeneous mission planning.
The proposed algorithm is compared with state-of-the-art heuristic algorithms on the performance and computation time in numerical simulation. Simulation results show that the proposed approach has significantly faster computation time than other baseline algorithms while maintaining good performance.
Introduction
Motivation
Research Objectives
The algorithm proposed in this paper deals with these challenges successfully by meeting quite good mission completion performance and computation time. This research presents unified mission representation for network inputs to provide sufficient information of heterogeneous missions for training. The REINFORCE algorithm [7], one of reinforcement learning, updates the neural network model to converge.
Then, the moving average of reward is used as a baseline for the stability of the training process by reducing the variance when updating the value of the gradient of the parameters. To this end, this research proposes an attention-based reinforcement learning algorithm for the heterogeneous mission planning of UAVs. First, this research formulates the heterogeneous mission planning problem as VRP with a graph form to use the solvers for VRP.
Finally, this study compares the proposed algorithm with state-of-the-art open-source heuristic algorithms. Numerical simulation is used to validate the feasibility and performance of the proposed approach.
Structure of Thesis
Although the existing neural network architectures from deep learning-based algorithms can handle different VRP, they only consider homogeneous mission input. The proposed algorithm uses the attention-based model architecture [6] for better computational efficiency than the simple RNN-based model architecture to prevent the vanishing gradient effect when dealing with long data sequences. Considering a realistic complex mission environment with the characteristics of UAVs, the reinforcement learning approach with an attention-based artificial neural network model is used to solve the problem with its fast computation time and flexibility.
And then the action masking strategy is designed to deal with the flight time constraint to complete each mission and use reinforcement learning to overcome the difficulty of generating sufficient optimal data.
Literature Review
Theoretical Background
- Artificial Neural Network
- Deep Learning-Based Approach
- Attention Mechanism
- Self-Attention
- Pointer Networks
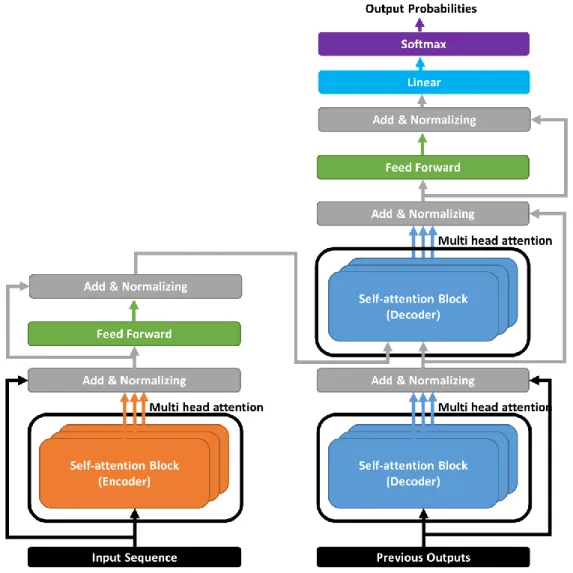
- Transformer
- Deep Reinforcement Learning
- REINFORCE Algorithm
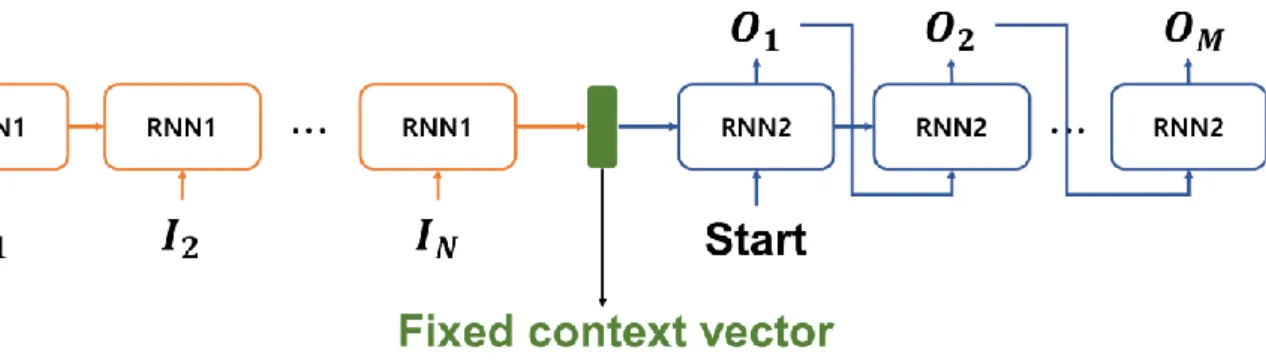
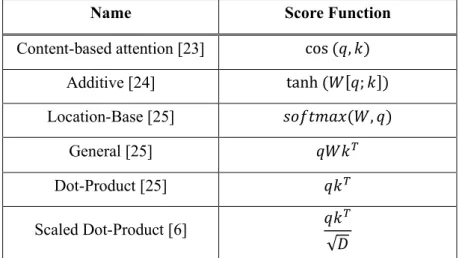
In addition, the computational process of the artificial neural network model is matrix multiplication, so that the computation can be parallelized and accelerated by a graphics processing unit (GPU). A fixed context vector must contain enough information about the input data into a fixed size vector. Therefore, if the length of the input sequence is too long or the relational information of the input sequence is too complex, the fixed context vector may not represent the corresponding information with its fixed size vector.
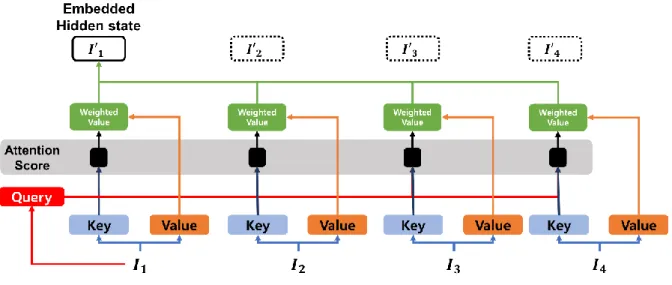
Then the query value value is obtained from the weighted sum of the value of each similarity. Motivated by the idea that the attention mechanism generates the attention result vector and embeds the context vector between the key and the query, the relational information between the elements of the input sequence can also be computed by the attention mechanism [6]. Exploiting the idea, the self-attention mechanism computes the output of attention and the inclusion of contextual information from the input sequence.
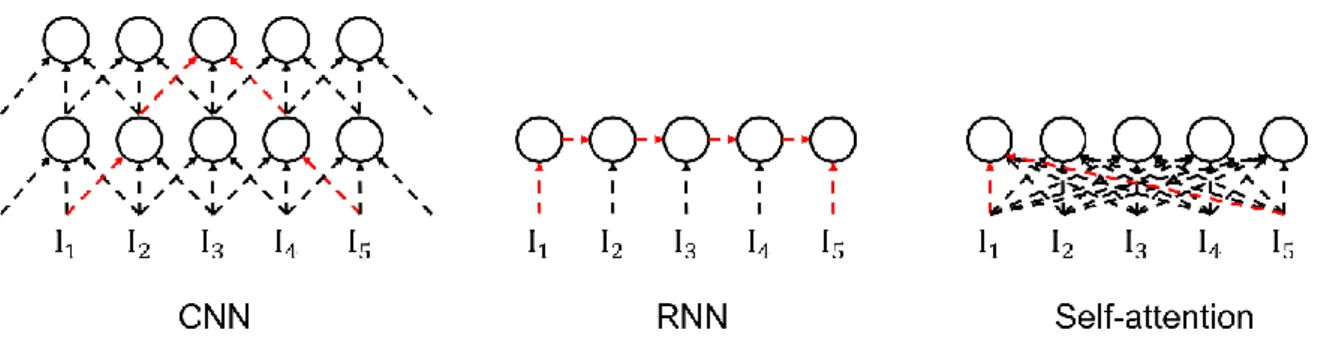
Each element of the input sequence is considered the key, the query, and the value by itself. Not only does it prevent the vanishing or exploding gradient update, but the self-attention mechanism also has efficiency in the computational aspect. The proposed pointer mechanism is proposed to select which element should be the next element in the solution set.
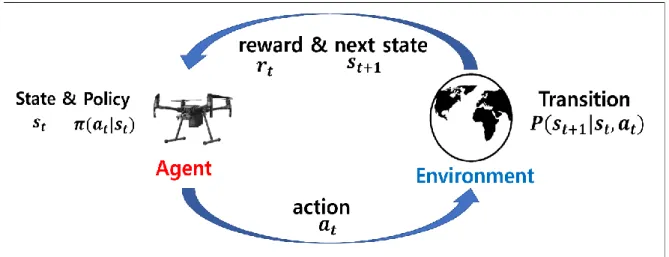
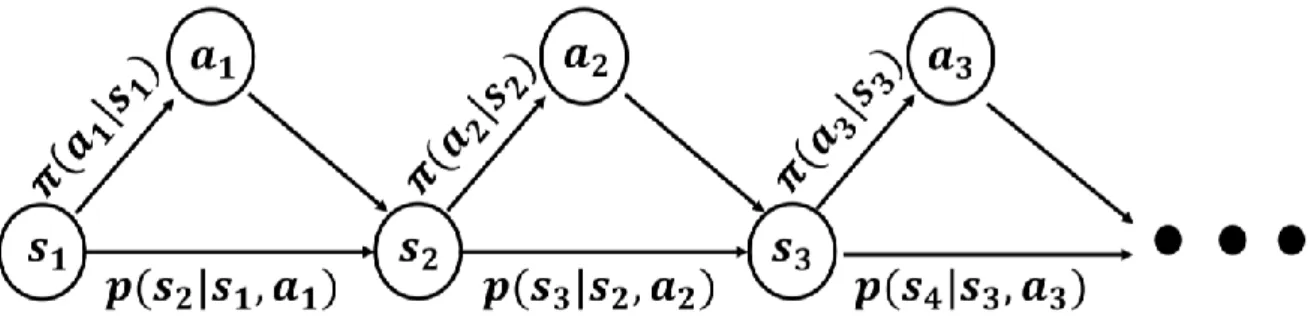
Since the NLP is also the sequence processing of the vectorized information, Transformer model has been used in various fields. Parallelization of the computation of multiple self-attention blocks which is a multi-head attention mechanism is proposed with Transformer. The goal of RL is to maximize the cumulative reward of the agent in the Markov decision process (MDP) [27].
The parameter of optimal policy 𝜃∗ is trained by interaction with environment of the problem and the agent. The policy is trained by updating the parameter of the model from experience of the agent. Equation (4) is the gradient ascending method for updating the parameters of the REINFORCE algorithm's model.
The REINFORCE algorithm has slow training convergence since the variance of the gradient is usually too high. Actor-critical algorithms are one of the policy gradient-based reinforcement algorithms that use value function as the baseline and the value function is modeled with neural network so that the value function and the policy are trained together.
Research Methods
Problem Definition
Our objective is to complete each given heterogeneous mission while minimizing the flight time of UAVs dispatched from the depot. If UAVs fly at a constant speed, the cost between missions is calculated by the total distance UAVs must fly. The cost to return to the depot 𝑐𝑥𝑣 with the depot visit mission point.
Deep Reinforcement Learning Framework for Heterogeneous Mission Planning
- Training Environment
- Unified Mission Representation
- Action Masking Strategy
- Neural Network Architecture
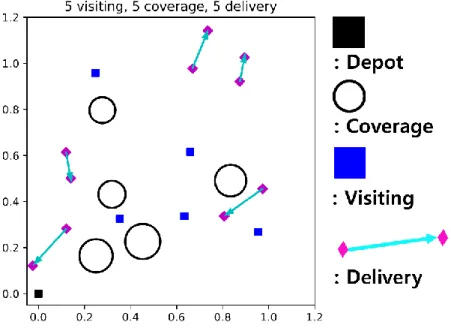
Our proposed algorithm optimizes an attention-based neural network to minimize 𝐿 through deep reinforcement learning. The following subsections describe the training environment, the neural architecture model, and ideas for using the model. The position of each mission is randomly generated on a (0,1) two-dimensional (2D) map with a uniform distribution.
The coverage mission's radius is randomly generated in the range of with the uniform distribution. The location position of the delivery mission is far from the selection position in the range of at the aspect of x, y axis respectively with the uniform distribution. We propose the unified mission representation 𝑣 = (𝑥1, 𝑦1)||(𝑥2, 𝑦2)||𝐴||𝐼𝑇𝑦𝑝𝑒 which combines the heterogeneous missions' spatial information, and where 1 is the indicator of each position, 1 is the mission, (𝑥2 , 𝑦2) is the end position, 𝐴 is the geometric information, and 𝐼𝑇𝑦𝑝𝑒 is the one-hot encoding indicator of each type.
The critical position represents the important position of each mission, such as the mission position of the visiting mission, the center position of the coverage mission area, and the selection position of the delivery mission. The end position represents the position when the UAVs complete the current mission that only the delivery mission has a different end position, but others have the same information as the critical position. The area information represents the radius of the coverage mission, the length of the delivery mission, and zero for the visiting mission.
We propose the action masking strategy by combining the termination mask 𝑀𝐶 = ( 𝑚𝑡𝑘). 𝑀𝑇 takes into account the cost of backtracking between the current mission and other missions so that the UAVs do not crash. The model takes the input sequence for the encoder and outputs the solution sequence with the decoder satisfying the constraints.
At each decoding step 𝑡 , the MHA decoder re-enters the outputs from the encoder into (ℎ𝑒1′ , ℎ𝑒2′ , ⋯ , ℎ𝑒𝑘′ ) then chooses the next node to be the solution sequence ℎ 1 part of the solution, ℡📝: obtained until now, and the remaining flight time budget 𝑇𝑅𝑒𝑚𝑎𝑖𝑛 for considering the flight time budget constraint. To use the model for heterogeneous mission planning, we propose the unified feature representation to represent 𝑣𝑖 ∈ 𝑚. And then, we propose the action masking strategy in the decoding step to meet the flight budget constraint.
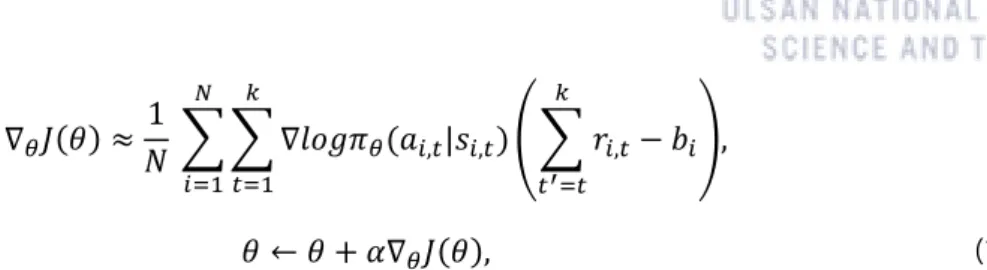
Numerical Simulations
- Baseline Algorithms
- Details of OR-Tools Algorithms
- Experiment Configuration
- Simulation Results
- Ablation Study
This section provides the comprehensive simulation result to show the performance of the proposed approach. The test environment is an untrained environment that has the same number of missions as the train environment. Each algorithm generates the feasible solutions and we analyze the performance and computation time of each algorithm.
In Figure 21, the proposed algorithm, PointerNet-RL, OR-Type1 and OR-Type2 have the least number of paths than the greedy algorithm which means the greedy algorithm has the worst performance among the algorithms. The total solution cost defined in Eq. 8) and the computation time is used to measure the performance of the algorithms. We use 10,000 mission instance samples to test the performance with different number of missions in the interval (3, 30).
The OR-Type2 shows the best performance, while the proposed algorithm has a similar performance with the OR-Type2. The computation time of the OR-Type2, which is the best algorithm for the cost, grows exponentially with the scale of the mission. The representation consists of the position of the mission, the geometric information of the mission and the type of mission.
The t-SNE is one of the dimension reduction methods to project the high dimensional data into low dimensional space, especially 2-dimensional space. The interesting point is that the NoType representation considers the cover missions and delivery missions as similar type of the mission.
Conclusion and Future Work
![Figure 6. Pointer Networks architecture. [13]](https://thumb-ap.123doks.com/thumbv2/123dokinfo/10494358.0/19.892.294.600.556.797/figure-6-pointer-networks-architecture-13.webp)