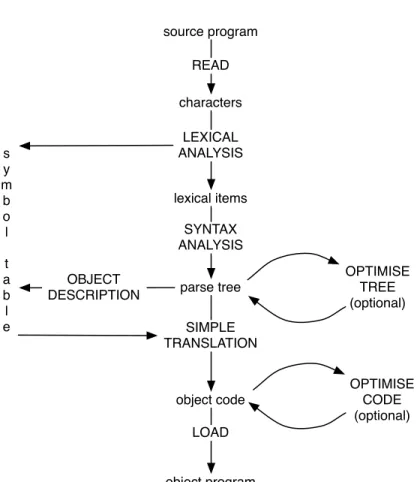
In the examples throughout the book, most algorithms are written in a version of the language BCPL, the details of which are briefly explained in appendix A. Once you understand the principles of compiler design, most of the details fall into place naturally. PHASES AND PASS one of the phases before any of them are presented to the next phase, we have a multipass compiler because each phase performs a separate run through the program.
However, in discussing compilation algorithms, it is usually simpler to imagine that each of the stages in a compiler always performs a separate pass over the program.
Tasks and Sub-tasks
Therefore, every compiler must be multi-pass, but it may or may not be multi-pass. Logically, the phases must be joined in the same order regardless of how many passes are employed, so it does not seem to matter whether this book concentrates on multi-pass or single-pass organization. For some languages – ALGOL 60 is a prominent example – it is actually difficult to construct an efficient single-pass compiler at all, and so the multi-pass organization is also more generally useful.
It is often assumed that multi-pass compilation is inherently less efficient than single-pass. This is simply untrue: since every fragment in any compiler must be processed by the same sequence of phases, a single-pass compiler must do the same amount of work as a multi-pass compiler. However, suppose that each pass of a multi-pass compiler had to write its output to a disk file (or any backup storage file) from which the next pass had to read it back in.
Such a multi-pass compiler would indeed be less efficient than a single-pass compiler that does not use a backing store, but the inefficiency would be caused by the overhead of input and output between passes. A multi-pass compiler that stores the output of each pass in main computer memory will certainly not be slower than a single-pass compiler. On a modern computer, the only drawback of multi-pass compilation is that it can take up quite a lot of space to store the output of the different passes.
TASKS AND SUB-TASKS 7
Translation and Optimisation
True optimizations, for the purposes of this book, are those translations that take advantage of idiosyncrasies of the control flow specified in the source program. There are essentially two ways in which a compiler can optimize a program, i.e. produce a more than simple translation. i). It may include a stage that changes the source program's algorithm in such a way that subsequent simple translation can produce the desired effect.
This is shown as OPTIMIZE TREE in figure 1.2: it essentially replaces the source program's algorithm with another that has the same effect but can be translated into more efficient code. ii). This may include a phase that modifies the code produced by simple translation to increase the efficiency of the object program. This is shown as OPTIMIZE CODE in figure 1.2: this phase mainly looks at the ways in which the code fragments link together.
These two approaches can be equivalent in their effect and sometimes compilers use both. The OPTIMIZE BOOM technique is the more machine independent of the two and is possibly the more powerful.
Object Descriptions in the Symbol Table
Run-time Support
In non-recursive languages such as FORTRAN, at most one activation can exist for each procedure, but in languages that allow recursion, there can exist multiple activations, each at a different stage of execution of a single procedure body and each with its private storage and private copy of the arguments with which it was called. Each of these activations can be described by a data structure – in a recursive programming language the data structure is an 'activation record', 'data frame' or 'stack frame' stored on a stack – and the links between these data structures define the Activation Record Structure . Maintaining the Activation Record structure in an implementation of a recursive programming language is an important 'overhead' cost in the execution of the object program.
By forbidding recursion, languages like FORTRAN reduce the overhead, but the discussion in Section III shows how careful design of code fragments can minimize or even eliminate the efficiency gap between recursive and nonrecursive languages. Even recursive languages must constrain the manipulation of some values in the object program to allow the activation record structure to be stored on a stack: Chapter 14 discusses the way in which the necessary constraints can be applied in an implementation of ALGOL 68 and touches on the implementation of SIMULA 67, which can avoid introducing such limitations because it does not use a data frame stack.
Source Program Errors
SOURCE PROGRAM ERRORS 13 be compiled and if possible make suggestions as to how the error might
ERRORS IN THE SOURCE PROGRAM 13translate and, if possible, give suggestions as to how the error could have occurred. Runtime error handling requirements can greatly affect the detailed design of object code fragments. In later chapters I will return again and again to the question of how the various phases can be designed to produce readable and understandable error reports.
Two-pass Compilation
TWO-PASS COMPILATION 15
AN EXAMPLE OF COMPILATION 17
An Example of Compilation
Optimizing the object code in this case could provide a huge improvement in execution efficiency. Simple translation is a mechanism that takes a representation of a fragment of the source program and produces an equivalent fragment in the object language - a fragment of code that, when executed by the object engine, will perform the operations specified by the original source fragment. Since the object program produced by a simple translator consists of a series of relatively independent object code fragments, it will be less efficient than a program produced by a mechanism that pays some attention to the context in which each fragment is to operate.
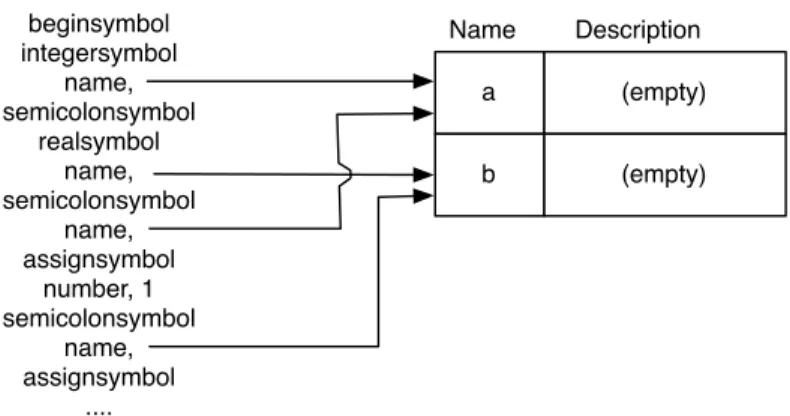
Optimization is a mechanism that exists to hide the errors of a simple compiler: it compiles larger parts of a program than a simple compiler to reduce object code inefficiencies caused by poorly linking code fragments. In order to generate object code phrases, the compiler must have access to a symbol table that provides a mapping of source program names to the runtime objects they denote. This table is constructed by the lexical analyzer (see Chapters 4 and 8), which correlates the different occurrences of each name throughout the program.
The mapping to runtime objects is provided by the object description phase (see Chapter 8), which processes declarative information from the source program to associate each identifier in the symbol table with a description of a runtime object. Such a translator consists of a number of mutually recursive procedures, each of which is capable of translating one kind of source program fragment, and each of which can generate a variety of different kinds of object code fragments depending on the detailed structure of the source fragment. presented to it. A simple translator will usually use less than 15% of the machine time used by all phases of the compiler combined, but will account for more than 50% of the compiler's own source code.
Phrases and Trees
PHRASES AND TREES 21
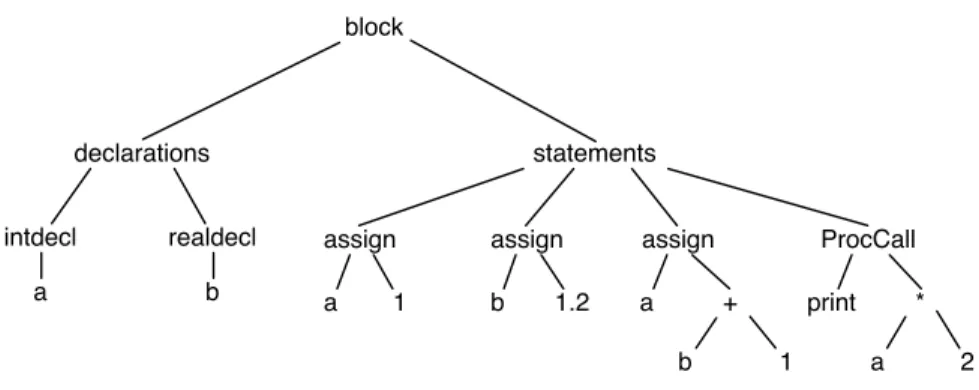
The state of the art in programming language translation is now, and will remain for some time to come, that a program can only be translated if it is first analyzed to find out how the phrases are related to each other: then the translator can translate each phrase considered in turn. The result of the analysis shows how the program (the phrase being translated) can be divided into sub-phrases and shows how these sub-phrases are interrelated to make up the whole phrase. For each sub-phrase, the description shows how it is divided into sub-sub-phrases and how they are interrelated.
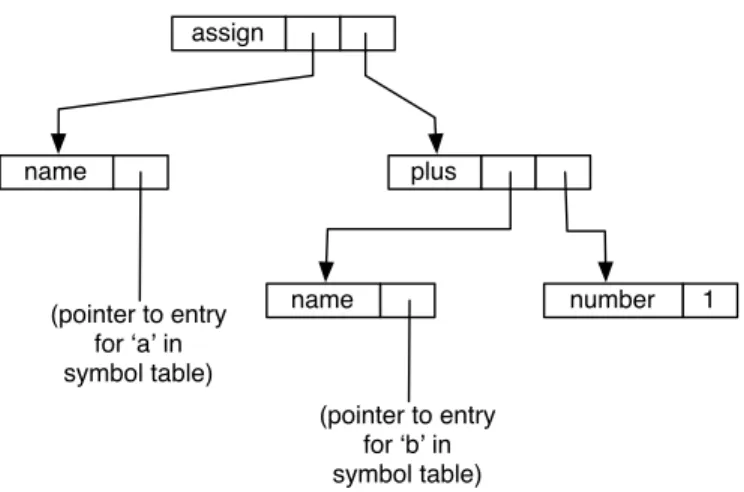
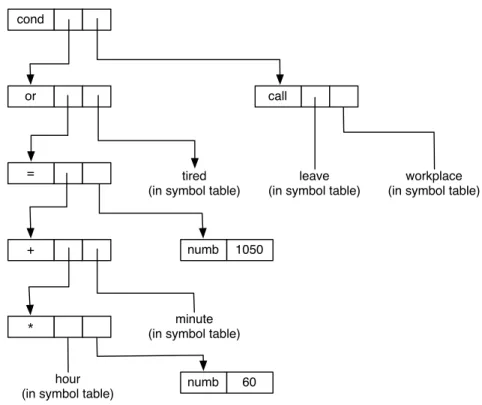
The most common representation of the results of such an analysis is a tree like that in figure 2.1. The top node of the tree is its root - the tree is conventionally drawn 'upside down'. Nodes that do not split into branches are leaves and represent the atomic items of the source program.
The tree structure, however presented, gives the translator the information he needs to translate the statement—it shows which sentences are related and how they are related. A look at the tree gives the answers - only the first one represents the node because the analysis has shown that it is a program phrase. There may be representations of the necessary information that are not tree-like, but the tree stores and displays the information in the most accessible and useful form.
Tree Walking
INTRODUCTION TO TRANSLATION at the top level - but a single page is not large enough to show the necessary trees. The description continues to show the subdivision of phrases in this way until the atomic phrases – items of the source text – are reached. To translate a phrase it is simply necessary to concentrate on one node and, if it has sub-nodes, translate its sub-nodes as well.
Many other representations are possible - e.g. one where each pointer is represented by a subscript of a large integer vector. In order to translate a sentence in a program, it is important to know what kind of sentence it is, what its sub-clauses are, and how they are interrelated.
TREE WALKING 23
Linear Tree Representations
Improving the Tree Walker
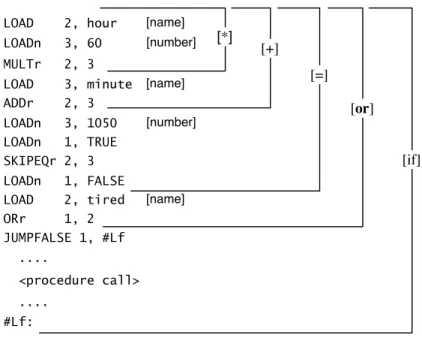
Modify the code that was generated after the tree walk is complete (optimize the code). generate code to calculate the value of the left operand in register k 2. if the right operand is a name then. generate ADD k,
. else if the correct operand is a number then generate ADDn k,IMPROVING THE TREE WALKER 29 LOAD 2, hour
Using the Symbol Table Descriptors
Translation Error Handling
TRANSLATION ERROR HANDLING 33
TRANSLATION ERROR HANDLING 35 the symbol table. They are all syntactic errors – semantic errors happen at