ĐẠI HỌC QUỐC GIA HÀ NỘI TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
──────── * ───────
NGUYỄN THỊ QUYỀN
NGHIÊN CỨU DỰ ĐOÁN TÁC DỤNG PHỤ CỦA THUỐC TỪ Y VĂN SỬ DỤNG MẠNG NƠ-RON
DỰA TRÊN CƠ CHẾ TẬP TRUNG
LUẬN VĂN THẠC SĨ HỆ THỐNG THÔNG TIN
HÀ NỘI 06 – 2021
2
ĐẠI HỌC QUỐC GIA HÀ NỘI TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
──────── * ───────
NGUYỄN THỊ QUYỀN
NGHIÊN CỨU DỰ ĐOÁN TÁC DỤNG PHỤ CỦA THUỐC TỪ Y VĂN SỬ DỤNG MẠNG NƠ-RON
DỰA TRÊN CƠ CHẾ TẬP TRUNG
Ngành : Công nghệ thông tin Chuyên ngành : Hệ thống thông tin
Mã số : 8480104.01
LUẬN VĂN THẠC SĨ HỆ THỐNG THÔNG TIN
NGƯỜI HƯỚNG DẪN KHOA HỌC: TS. Đặng Thanh Hải
HÀ NỘI 06 – 2021
3 LỜI CAM ĐOAN
Tác giả xin cam đoan rằng luận văn thạc sĩ công nghệ thông tin “Dự đoán tác dụng phụ của thuốc từ y văn sử dụng mạng nơ ron dựa trên cơ chế tập trung”
là công trình nghiên cứu của riêng tác giả, không sao chép lại của người khác.
Trong toàn bộ nội dung của luận văn, những điều đã được trình bày hoặc là của chính cá nhân tác giả hoặc là được tổng hợp từ nhiều nguồn tài liệu. Tất cả các nguồn tài liệu tham khảo đều có xuất xứ rõ ràng và hợp pháp.
Tác giả xin hoàn toàn chịu trách nhiệm và chịu mọi hình thức kỷ luật theo quy định cho lời cam đoan này.
Hà Nội, ngày 30 tháng 06 năm 2021
Nguyễn Thị Quyền
4 LỜI CẢM ƠN
Trước tiên em xin dành lời cảm ơn chân thành và sâu sắc đến thầy giáo, TS.
Đặng Thanh Hải – người đã hướng dẫn, khuyến khích, chỉ bảo và tạo cho em những điều kiện tốt nhất từ khi bắt đầu cho tới khi hoàn thành công việc của mình.
Em xin dành lời cảm ơn chân thành tới các thầy cô giáo khoa Công nghệ thông tin, trường Đại học Công nghệ, ĐHQGHN đã tận tình đào tạo, cung cấp cho em những kiến thức vô cùng quý giá và đã tạo điều kiện tốt nhất cho em trong suốt quá trình học tập, nghiên cứu tại trường.
Đồng thời em xin cảm ơn tất cả những người thân yêu trong gia đình cùng toàn thể bạn bè những người đã luôn giúp đỡ, động viên những khi vấp phải những khó khăn, bế tắc và giúp đỡ em hoàn thành luận văn này.
Hà Nội, ngày 30 tháng 06 năm 2021
Nguyễn Thị Quyền
5
MỤC LỤC
LỜI CAM ĐOAN ... 3
LỜI CẢM ƠN... 4
MỤC LỤC ... 5
DANH MỤC CÁC KÝ HIỆU VÀ CHỮ VIẾT TẮT ... 7
DANH MỤC HÌNH VẼ ... 8
DANH MỤC BẢNG BIỂU ... 9
MỞ ĐẦU ... 10
CHƯƠNG 1: TỔNG QUAN VỀ TÁC DỤNG PHỤ CỦA THUỐC ... 12
1.1. Khái niệm ... 12
1.2. Hiện trạng ... 12
1.3. Hướng tiếp cận ... 13
CHƯƠNG 2: CƠ SỞ LÝ THUYẾT... 16
2.1. Mạng nơ-ron nhân tạo ... 16
2.1.1. Mạng nơ-ron tích chập (CNN) ... 17
2.1.2. Mạng nơ-ron hồi quy (RNN) ... 19
2.1.3. Mạng bộ nhớ dài – ngắn LSTM ... 21
2.1.4. Mạng GRU ... 22
2.2. Word Embedding ... 24
2.3. Position Embedding ... 25
2.4. Kỹ thuật attention ... 25
CHƯƠNG 3: THỰC NGHIỆM DỰ ĐOÁN TÁC DỤNG PHỤ CỦA THUỐC TỪ Y VĂN SỬ DỤNG MẠNG NƠ-RON DỰA TRÊN CƠ CHẾ TẬP TRUNG ... 27
3.1. Mô tả bài toán ... 27
3.2. Mô tả dữ liệu và các bước thực hiện ... 30
3.3. Cấu hình phần cứng ... 38
3.4. Tham số cài đặt mô hình ... 38
3.5. Phương pháp đánh giá ... 38
3.6. Kết quả thử nghiệm ... 39
6
KẾT LUẬN VÀ HƯỚNG PHÁT TRIỂN ... 42
Kết luận ... 42
Hướng phát triển tương lai ... 42
TÀI LIỆU THAM KHẢO ... 43
7
DANH MỤC CÁC KÝ HIỆU VÀ CHỮ VIẾT TẮT
Ký hiệu viết tắt Thuật ngữ đầy đủ Giải thích ADRs Drug side-effects/ adverse
drug reactions
Tác dụng phụ/ phản ứng có hại của thuốc
ATT Attention mechanism Cơ chế tập trung/ Cơ chế
chú ý
CDRs Chemical-Disease
Relations
Mối quan hệ giữa hóa chất và bệnh
CID Chemical-induced Disease Mối quan hệ của bệnh và hóa chất gây ra.
DNN Deep neural networks
(DNNs)
Mạng nơ-ron sâu
FFNN Feed forward neural
network
Mạng nơ ron truyền thẳng
GloVe Global vector Mô hình vector toàn cục
LSTM Long short term memory Mạng bộ nhớ dài ngắn NER Named entity recognition Nhận diện tên thực thể
NLP Natural language
processing
Xử lý ngôn ngữ tự nhiên
RNN Recurrent neural network Mạng nơ ron hồi quy
8
DANH MỤC HÌNH VẼ
Hình 2.1: Mô hình kiến trúc mạng nơ-ron [12] ... 16
Hình 2.2: Cấu trúc điển hình của CNN giữa các lớp đầu vào và đầu ra [6]. ... 18
Hình 2.3: Mô hình CNN cho trích xuất quan hệ [23] ... 19
Hình 2.4: Mô hình RNN tổng quát [2] ... 20
Hình 2.5: Minh họa khối bộ nhớ với một ô nhớ của LSTM [2]. ... 22
Hình 2.6: Minh họa GRU ... 23
Hình 2.7: Cơ chế tập trung dựa trên mạng RNN cho trích xuất quan hệ [16] ... 26
Hình 3.1: Minh họa bài toán trích xuất mối quan hệ giữa thuốc và bệnh ... 28
Hình 3.2: Tổng quan kiến trúc chương trình ... 29
Hình 3.3: Cách tạo các thể hiện quan hệ từ các câu ... 29
9
DANH MỤC BẢNG BIỂU
Bảng 3.1: Thống kê tập dữ liệu ... 31
Bảng 3.2: Bảng cấu hình phần cứng ... 38
Bảng 3.3: Các tham số được sử dụng ... 38
Bảng 3.4: Kết quả trung bình các thực nghiệm ... 40
Bảng 3.5: Thống kê kết quả thực hiện luận văn với một số thuật toán khác ... 40
10 MỞ ĐẦU
Trong y học, một tác dụng phụ là một tác dụng mà cho dù là hữu ích hay là bất lợi thì đều là thứ yếu so với dự định (ngoài ý muốn khi sử dụng thuốc). Phát triển thuốc là một quá trình phức tạp và khó để tạo ra một loại thuốc nhằm vào một bộ phận của cơ thể nhưng lại không ảnh hưởng đến các bộ phận khác. Tác dụng phụ bất lợi của thuốc là một vấn đề nghiêm trọng cấp bách về sức khỏe của con người cũng là trở ngại cho sự phát triển các loại thuốc có hiệu quả điều trị.
Mặc dù có nhiều nỗ lực liên tục để xác định tác dụng phụ của thuốc trước đó, nhưng đây vẫn là một nhiệm vụ đầy thách thức. Hầu hết các tác dụng của thuốc đều được phát hiện nhờ sử dụng nguồn dữ liệu từ các báo cáo tự phát trong giai đoạn trước và sau bán hàng. Đây là một hạn chế rất lớn. Các công ty dược phẩm mặc dù họ có khả năng xác định và giải quyết các tác dụng phổ biến nhưng nhìn chung không khả thi để xác định hoặc dự đoán các tác dụng phụ nghiêm trọng hiếm gặp. Sự bùng nổ của tài liệu y sinh đã tạo nên một nguồn tri thức phong phú giúp con người khai thác được nhiều thông tin hữu ích chẳng hạn như dự đoán mối quan hệ trong y sinh bao gồm việc dự đoán tác dụng phụ của thuốc từ y văn.
Nhờ đó khắc phục được rất nhiều hạn chế trong quá trình tìm ra tác dụng phụ của thuốc như trên.
Các nghiên cứu truyền thống sử dụng dữ liệu từ y văn chủ yếu sử dụng các phương pháp học máy như support vector machine (SVM) đã hoạt động tương đối tốt trong thập kỷ qua. Tuy nhiên không tránh khỏi một số lỗi không mong muốn đặc biệt khi phải xử lý các câu dài và khả năng khái quát hóa từ vựng hạn chế cho những từ chưa được nhìn thấy. Ngược lại, các phương pháp dựa trên mạng nơ-ron (NN) là các phương pháp học biểu diễn tự động với nhiều cấp độ biểu diễn, có được bằng cách kết hợp các mô-đun đơn giản nhưng phi tuyến tính. Gần đây, các phương pháp tiếp cận học sâu (Deep learning) đã được nghiên cứu rộng rãi và đạt được hiệu suất tiên tiến trong các nhiệm vụ NLP khác nhau như nhận diện thực thể (NER) và trích xuất quan hệ (Relation extraction). Trong các bài toán về trích xuất quan hệ y sinh, các từ “trigger word” là những từ xuất hiện trong ngữ cảnh trực tiếp chỉ ra sự tồn tại của các quan hệ ngữ nghĩa, được sử dụng rộng rãi như là các đặc điểm đầu vào của các phương pháp khai thác văn bản khác nhau. Cơ chế tập trung được đề xuất từ trực giác của sự chú ý trực quan của con người để nhấn mạnh phần tương đối quan trọng của dữ liệu đầu vào và đã được chứng minh là cải thiện hiệu suất mô hình và nâng cao khả năng diễn giải mô hình thông qua việc kết hợp thông tin chú ý vào học sâu.
11
Trong phạm vi khóa luận sẽ trình bày về mô hình mạng nơ-ron dựa trên cơ chế tập trung (attention-based neural networks) áp dụng vào việc dự đoán tác dụng phụ của thuốc sử dụng dữ liệu từ y văn. Kết quả thử nghiệm của khóa luận chỉ ra rằng mô hình ATT-RNN, ATT-GRU, ATT-LSTM hoạt động tốt hơn mô hình CNN khi không sử dụng các kỹ thuật attention và ATT-GRU đạt được điểm F1 trung bình tốt nhất là 0,6037 trên bộ thử nghiệm trong số các DNN được thử nghiệm. Quan sát kết quả cũng cho thấy cơ chế tập trung áp dụng hiệu quả hơn khi kết hợp với GRU và LSTM hơn so với khi áp dụng với RNN truyền thống.
Luận văn có bố cục gồm 3 chương chính:
Chương 1: Tổng quan về tác dụng phụ của thuốc
Chương này giới thiệu tổng quan về tác dụng phụ của thuốc và hướng tiếp cận sử dụng phương pháp học máy.
Chương 2: Cơ sở lý thuyết
Chương này đi sâu tìm hiểu về mô hình mạng nơ ron nhân tạo và mô hình mạng nơ-ron dựa trên cơ chế tập trung sẽ áp dụng trong khóa luận.
Chương 3: Thực nghiệm Dự đoán tác dụng phụ của thuốc từ y văn sử dụng mạng nơ ron dựa trên cơ chế tập trung.
Chương này sẽ trình bày việc áp dụng mô hình mạng nơ-ron dựa trên cơ chế tập trung áp dụng trong bài toán dự đoán tác dụng phụ của thuốc và các kết quả thực nghiệm.
Cuối cùng là một số kết luận và hướng phát triển trong tương lai
12
CHƯƠNG 1: TỔNG QUAN VỀ TÁC DỤNG PHỤ CỦA THUỐC 1.1. Khái niệm
Dưới đây là một số thuật ngữ thường được sử dụng để mô tả các tác dụng phụ của việc điều trị bằng thuốc theo Pharmacology Education Project (PEP) được phát triển bởi liên minh quốc tế về dược học cơ bản và lâm sàng (IUPHAR) [25]:
- Phản ứng có hại của thuốc (Adverse Drug Reaction - ADR) là phản ứng không mong muốn hoặc có hại xảy ra sau khi sử dụng thuốc hoặc kết hợp thuốc trong điều kiện sử dụng bình thường và được nghi ngờ có liên quan đến thuốc.
ADR thường sẽ yêu cầu ngừng thuốc hoặc giảm liều.
- Tác dụng phụ (side-effect) là bất kỳ tác dụng nào gây ra bởi một loại thuốc khác với tác dụng điều trị dự kiến, cho dù có lợi, trung tính hay có hại.
Kể từ năm 2012, định nghĩa về ADR đã bao gồm các phản ứng xảy ra do lỗi, sử dụng sai hoặc lạm dụng và các phản ứng nghi ngờ đối với các loại thuốc không có giấy phép hoặc được sử dụng ngoài nhãn ngoài việc sử dụng thuốc được phép với liều lượng bình thường [8].
Thông thường, ADR được phân thành hai loại [8]:
- Phản ứng loại A - đôi khi được gọi là phản ứng tăng cường - 'phụ thuộc vào liều lượng' và có thể dự đoán được dựa trên dược lý của thuốc.
- Phản ứng loại B - phản ứng kỳ lạ - mang tính đặc trưng và không thể dự đoán được trên cơ sở dược lý học.
1.2. Hiện trạng
Phản ứng có hại của thuốc là một vấn đề sức khỏe cấp bách và cũng là một trở ngại cho việc phát triển các loại thuốc có hiệu quả điều trị. Được biết, khoảng 7000 ca tử vong do ADRs gây ra mỗi năm trong một nghiên cứu được thực hiện trong năm 2000 [13]. Do đó, việc giám sát thuốc sau bán trên thị trường được yêu cầu để xác định các ADR tiềm ẩn như vậy sau khi sản xuất thuốc. Hiện tại, hầu hết các hoạt động giám sát thuốc sau bán trên thị trường đều dựa vào cơ sở dữ liệu hệ thống báo cáo tự phát thụ động, chẳng hạn như Hệ thống báo cáo sự kiện có hại của Cơ quan Quản lý Dược phẩm Liên bang (FAERS) của Mỹ [13], các hệ thống báo cáo tự phát như Chương trình Thẻ Vàng (Yellow Card Scheme) ở Anh được vận hành bởi Cơ quan Quản lý Thuốc và Sản phẩm Chăm sóc sức khỏe (MHRA) và Ủy ban Thuốc cho Người (CHM) [8]. Thông qua các báo cáo này, chương trình thu thập dữ liệu về các ADR nghi ngờ liên quan đến tất cả các loại
13
thuốc và vắc xin được cấp phép và không được cấp phép, bao gồm cả những loại thuốc được cấp theo đơn hoặc mua không cần kê đơn. Để một báo cáo có hiệu lực, chỉ cần có bốn mục thông tin: bệnh nhân, phản ứng, sản phẩm thuốc bị nghi ngờ và người báo cáo. Tuy nhiên, các báo cáo viên được khuyến khích cung cấp càng nhiều thông tin càng tốt, tức là cung cấp thêm dữ liệu và bối cảnh lâm sàng cho người đánh giá. Hệ thống như vậy có thể chậm và không hiệu quả. Nghiên cứu cho thấy 94% ADR được báo cáo thiếu ở các hệ thống chính thức [20]. Các loại thuốc đặc biệt liên quan đến ADR bao gồm thuốc chống kết tập tiểu cầu, thuốc chống đông máu, thuốc độc tế bào, thuốc ức chế miễn dịch, thuốc lợi tiểu, thuốc chống đái tháo đường và thuốc kháng sinh. ADRs gây tử vong thường là do xuất huyết, nguyên nhân phổ biến nhất được nghi ngờ là do thuốc chống đông máu được sử dụng đồng thời với thuốc chống viêm không steroid (NSAID) [8].
Dự đoán ADRs hiệu quả là điều cần thiết để cải thiện chăm sóc sức khỏe bệnh nhân và thúc đẩy quá trình phát triển thuốc. Các kỹ thuật tính toán khác nhau đã được sử dụng trong thời gian gần đây để tìm hiểu cơ chế phản ứng của thuốc.
Khi lĩnh vực tin sinh học đang phát triển nhanh chóng, người ta có thể thực hiện nhiều khám phá mới về thuốc mới. Dự đoán tác dụng phụ của thuốc là một bước tiến quan trọng, nhiều thú vị. Một số nghiên cứu gần đây [5], [21] tập trung vào ADR đề cập đến việc trích xuất trên văn bản y sinh. Nghiên cứu của tác giả được thực hiện trên kho ngữ liệu văn bản y sinh PubMed.
1.3. Hướng tiếp cận
Tóm lược tri thức (Abstract Knowledge) là một hình thức để hiểu thế giới, cung cấp nhận thức và trí thông minh ở cấp độ con người cho trí thông minh nhân tạo trong thế hệ tiếp theo. Một trong những thể hiện của tri thức là quan hệ ngữ nghĩa giữa các thực thể. Một cách hiệu quả để tự động thu nhận tri thức quan trọng này, được gọi là trích xuất quan hệ (Relation Extraction - RE), một nhiệm vụ của trích xuất thông tin, đóng một vai trò quan trọng trong Xử lý ngôn ngữ tự nhiên (NLP). Mục đích của nó là xác định các quan hệ ngữ nghĩa giữa các thực thể từ văn bản ngôn ngữ tự nhiên [7].
Luận văn này tập trung vào bài toán trích xuất quan hệ trong lĩnh vực y sinh với đầu vào là dữ liệu từ các văn bản y sinh, đầu ra cần xác định được liệu một cặp thực thể ứng viên trong một văn bản hoặc trong một câu có mối quan hệ ngữ nghĩa hay không?
Một số mô hình trích xuất quan hệ truyền thống sử dụng các phương pháp thống kê như máy vectơ hỗ trợ (Support Vector Machine - SVM) [1] và trường
14
ngẫu nhiên có điều kiện (Conditional Random Field - CRF) [18]. Với sự phát triển mạnh mẽ của công nghệ học sâu, các mô hình mạng nơ-ron đã đạt được hiệu suất hiện đại trên nhiều tác vụ gắn nhãn theo trình tự như nhận dạng tên thực thể (NER) [17] và gắn thẻ từ loại (Part-Of-Speech - POS) [3] . Các mô hình học sâu hiện tại thường sử dụng word embeddings, cho phép chúng học các cách biểu diễn tương tự cho các từ tương tự về mặt ngữ nghĩa. Mặc dù đây là một cải tiến lớn so với các mô hình truyền thống, nhưng vẫn còn một số lỗi cần được giải quyết. Vấn đề khó khăn nhất là làm thế nào để đối phó với các từ “không nằm trong tập từ vựng có sẵn” (Out-Of-Vocabulary - OOV). Trong các văn bản y sinh như các tóm tắt Pubmeds, cách viết không chính thức hoặc mô tả kỹ thuật quá mức có thể khiến một số lượng lớn các từ OOV xuất hiện. Bởi vì những từ này không có từ tương ứng, chúng sẽ được khởi tạo ngẫu nhiên cho một số giá trị cụ thể. Điều này sẽ gây ra nhiều phân loại sai của các từ OOV đó trong tập dữ liệu.
Luận văn này đã tận dụng lợi thế của việc biểu diễn cấp độ từ và ký tự của một token, do đó các từ OOV đó có thể được gắn nhãn tốt hơn do bổ sung các biểu diễn ký tự chi tiết. Ngoài ra, luận văn cũng áp dụng cơ chế tập trung cho phép mô hình tự động và linh hoạt để học đặc trưng nào quan trọng hơn. Luận văn cũng sử dụng đầu ra trung gian của mô hình như một bộ phân loại phụ trợ để cải thiện hiệu suất dự đoán của mô hình. Để xác thực tính hiệu quả của mô hình, luận văn thực hiện thử nghiệm trên tập dữ liệu của PubMed. Cơ chế tập trung [28], được đề xuất từ trực giác về sự chú ý trực quan của con người để nhấn mạnh phần tương đối quan trọng của dữ liệu đầu vào, đã được chứng minh là cải thiện hiệu suất mô hình và tăng cường khả năng diễn giải mô hình thông qua việc kết hợp thông tin tâp trung vào việc học sâu [16]. Ở đây, luận văn trình bày cách tiếp cận bằng cách sử dụng các mạng nơ ron dựa trên cơ chế tập trung (ATT-) và chứng minh sức mạnh của các mô hình ATT về hiệu suất bằng cách so sánh với các phương pháp học sâu khác và khả năng hiểu của chúng bằng cách phân tích trọng số tập trung ở cấp độ từ.
Nhìn chung, mạng nơ ron sâu (DNN) đã được sử dụng rộng rãi trong các nhiệm vụ dự đoán, gán nhãn, trích xuất quan hệ với nhiều mô hình khác nhau. Ví dụ: Đề xuất mạng nơ-ron tích chập (CNN) sử dụng position embedding để trích xuất quan hệ [32], sử dụng mô hình bộ nhớ dài - ngắn (LSTM) cùng tính phụ thuộc và position embedding [29] đã cho thấy chiến lược học tập vượt trội hơn đáng kể so với các phương pháp mạng nơ-ron hồi quy (RNN) sử dụng các tính năng mở rộng bao gồm POS, NER và WordNet.
15
Trong lĩnh vực y sinh, các nhiệm vụ trích xuất quan hệ khác nhau như tương tác protein- protein, tương tác thuốc - thuốc và tương tác bệnh - hóa học đã được nghiên cứu. Các phương pháp dựa trên học máy khác nhau bao gồm các phương pháp học máy có giám sát, phân cụm mẫu và mô hình khai phá chủ đề đã được sử dụng trước khi các mô hình học sâu trở nên chiếm ưu thế trong những tiến bộ gần đây. Bên cạnh các mô hình DNN thông thường, sự phụ thuộc và thông tin cấp độ ký tự đã được sử dụng để cải thiện, nâng cao hiệu quả của các mô hình. Gần đây, cơ chế tập trung trên các mô hình DNN đã cho thấy sự hứa hẹn trong các nhiệm vụ NLP khác nhau, chẳng hạn như dịch máy [16], trả lời câu hỏi [26], phân loại tài liệu [30] cũng như trích xuất quan hệ.
Luận văn này trình bày nghiên cứu mạng nơ ron với cơ chế tập trung cho nhiệm vụ trích xuất tác dụng phụ của thuốc và chứng minh tính hiệu quả của cơ chế tập trung trong việc lựa chọn thông tin mức độ quan trọng.
16
CHƯƠNG 2: CƠ SỞ LÝ THUYẾT 2.1. Mạng nơ-ron nhân tạo
Mạng nơ-ron nhân tạo (Artificial Neural Network - ANN) là một tập con của học máy và là trung tâm của các thuật toán học sâu. Tên và cấu trúc của chúng được lấy cảm hứng từ não người, bắt chước cách các tế bào thần kinh sinh học truyền tín hiệu cho nhau.
Mạng nơ ron nhân tạo (ANN) bao gồm một lớp nút, chứa một lớp đầu vào (Input layer), một hoặc nhiều lớp ẩn (Hidden layer) và một lớp đầu ra (Output layer). Mỗi nút, hoặc mỗi nơron nhân tạo, kết nối với một nút khác và có trọng số và ngưỡng liên quan. Những trọng số này có được bằng cách học hỏi hoặc điều chỉnh từ một tập hợp các mẫu đào tạo [12]. Nếu đầu ra của bất kỳ nút riêng lẻ nào vượt quá giá trị ngưỡng được chỉ định, nút đó sẽ được kích hoạt, gửi dữ liệu đến lớp tiếp theo của mạng. Nếu không, không có dữ liệu nào được chuyển đến lớp tiếp theo của mạng. Từ “ẩn” có nghĩa là chúng ta có thể quan sát đầu vào và đầu ra trong khi cấu trúc kết nối chúng vẫn bị ẩn. Kiến trúc của mạng nơ ron nhân tạo được minh họa như Hình 2.1: Mô hình kiến trúc mạng nơ-ron [12]. Trong đó:
- x1…xn là các đầu vào của nơ-ron.
- W0…Wn là các trọng số.
Hình 2.1: Mô hình kiến trúc mạng nơ-ron [12]
Mạng nơ-ron dựa trên dữ liệu đào tạo để tìm hiểu và cải thiện độ chính xác của chúng theo thời gian.
Hầu hết các mạng nơ-ron sâu đều truyền thẳng, có nghĩa là chúng chỉ chạy theo một hướng, từ đầu vào đến đầu ra. Tuy nhiên, chúng ta cũng có thể đào tạo
17
mô hình của mình thông qua lan truyền ngược (backpropagation); nghĩa là di chuyển theo hướng ngược lại từ đầu ra đến đầu vào. Backpropagation cho phép chúng ta tính toán và quy lỗi liên quan đến mỗi nơ-ron, cho phép chúng ta điều chỉnh các tham số của các mô hình một cách thích hợp.
Mạng nơron có thể được phân thành nhiều loại khác nhau, được sử dụng cho các mục đích khác nhau. Mặc dù đây không phải là danh sách đầy đủ các loại, nhưng bên dưới sẽ đại diện cho các loại mạng nơ-ron phổ biến nhất mà chúng ta sẽ gặp trong các trường hợp sử dụng phổ biến:
Perceptron là mạng nơ-ron lâu đời nhất, được tạo ra bởi Frank Rosenblatt vào năm 1958 [14]. Nó là dạng đơn giản nhất của mạng nơ-ron, có thể có nhiều đầu vào và duy nhất một đầu ra.
Các mạng nơ-ron truyền thẳng hoặc các perceptron nhiều lớp (MLP): Bao gồm một lớp đầu vào, một hoặc nhiều lớp ẩn và một lớp đầu ra. Dữ liệu thường được đưa vào các mô hình này để đào tạo chúng và chúng là nền tảng cho thị giác máy tính, xử lý ngôn ngữ tự nhiên và các mạng nơ-ron khác.
Mạng nơ-ron tích chập (CNN) tương tự như mạng truyền thẳng, nhưng chúng thường được sử dụng để nhận dạng hình ảnh, nhận dạng mẫu và thị giác máy tính. Các mạng này khai thác các nguyên tắc từ đại số tuyến tính, đặc biệt là phép nhân ma trận, để xác định các mẫu trong một hình ảnh. Mạng nơ-ron hồi quy (RNN) được xác định bởi các vòng lặp phản hồi của chúng. Các thuật toán học tập này chủ yếu được tận dụng khi sử dụng dữ liệu chuỗi thời gian để đưa ra dự đoán về kết quả trong tương lai, chẳng hạn như dự đoán thị trường chứng khoán hoặc dự báo bán hàng.
2.1.1. Mạng nơ-ron tích chập (CNN)
Giống như các mạng nơ-ron khác, CNN bao gồm một lớp đầu vào, một lớp đầu ra và nhiều lớp ẩn ở giữa. Các lớp ẩn thực hiện các thao tác làm thay đổi dữ liệu với mục đích học các đặc trưng cụ thể của dữ liệu. Ba trong số các lớp phổ biến nhất là: lớp tích chập (convolution), lớp kích hoạt (activation) hoặc lớp kích hoạt phi tuyến ReLU (Rectified Linear Unit) và lớp tổng hợp (pooling) ngoài ra còn có lớp kết nối đầy đủ (fully-connected). Mô hình CNN bao gồm một tập hợp hữu hạn các lớp xử lý có thể học các dữ liệu đầu vào có các đặc trưng khác nhau (ví dụ: hình ảnh) với nhiều cấp độ trừu tượng. Các lớp bắt đầu học và phân tích các đặc trưng cấp cao (với độ trừu tượng thấp hơn), và các lớp sâu hơn học và cắt
18
bỏ các đặc trưng cấp thấp (với độ trừu tượng cao hơn). Cấu trúc điển hình của CNN được thể hiện trong hình 2.2 [6], trong đó có:
Lớp tích chập (convolution layer): Lớp tích chập là thành phần quan trọng nhất của bất kỳ kiến trúc CNN nào. Nó chứa một tập hợp các hạt nhân tích chập (Convolutional kernels) (còn được gọi là bộ lọc), được đối chiếu với hình ảnh đầu vào (số liệu N chiều) để tạo ra một bản đồ tính năng đầu ra. Một hạt nhân có thể được mô tả như một mạng lưới các giá trị hoặc số rời rạc, trong đó mỗi giá trị được gọi là trọng số của hạt nhân này. Trong khi bắt đầu quá trình huấn luyện của một mô hình CNN, tất cả các trọng số của nhân được gán với các số ngẫu nhiên (các phương pháp tiếp cận khác nhau cũng có sẵn ở đó để khởi tạo các trọng số).
Sau đó, với mỗi lượt đào tạo, các trọng số được điều chỉnh và hạt nhân được học để trích xuất các đặc điểm có ý nghĩa.
Lớp lấy mẫu (Pooling Layer): Các lớp lấy mẫu được sử dụng để lấy mẫu phụ bản đồ các đặc trưng (được tạo ra sau các hoạt động tích chập), tức là nó lấy bản đồ đặc trưng có kích thước lớn hơn và thu nhỏ chúng thành bản đồ đặc trưng có kích thước thấp hơn (hoặc thông tin) trong mỗi bước lấy mẫu. Hoạt động lấy mẫu được thực hiện bằng cách xác định kích thước vùng được lấy mẫu và bước của hoạt động, tương tự như hoạt động tích chập. Có nhiều loại kỹ thuật lấy mẫu khác nhau được sử dụng trong các lớp lấy mẫu khác nhau như lấy mẫu tối đa, lấy mẫu tối thiểu, lấy mẫu trung bình, v.v. Hạn chế chính của lớp lấy mẫu là nó đôi khi làm giảm hiệu suất tổng thể của CNN. Lý do đằng sau điều này là lớp lấy mấu giúp CNN tìm xem một đặc trưng cụ thể có xuất hiện trong hình ảnh đầu vào đã cho hay không mà không cần quan tâm đến vị trí chính xác của đặc trưng đó.
Lớp kết nối đầy đủ (Fully Connected (FC) Layer): Thông thường, lớp cuối cùng của mọi kiến trúc CNN (được sử dụng để phân lớp) bao gồm các lớp được kết nối chặt chẽ với nhau, trong đó mỗi nơ-ron bên trong một lớp được kết nối với mỗi nơ-ron từ lớp trước đó. Lớp cuối cùng của các lớp FC được sử dụng làm lớp đầu ra (bộ phân lớp) của kiến trúc CNN. Các lớp FC là loại mạng nơ-ron nhân tạo chuyển tiếp (feed-forward artificial neural network) và nó tuân theo nguyên tắc của mạng nơ-ron perceptron nhiều lớp truyền thống (MLP). Đầu vào lớp FC từ lớp lấy mẫu hoặc lớp tích chập cuối cùng, ở dạng một tập hợp các chỉ số (bản đồ
Hình 2.2: Cấu trúc điển hình của CNN giữa các lớp đầu vào và đầu ra [6].
19
đặc trưng) và các chỉ số đó được làm phẳng để tạo ra một véc tơ và véc tơ này sau đó được đưa vào lớp FC để tạo ra đầu ra cuối cùng của CNN.
Để chứng minh tính hiệu quả của mô hình ATT do luận văn đề xuất, trước tiên tác giả đã phát triển một mô hình trích xuất quan hệ sử dụng CNN làm đường cơ sở, đây là một trong những mô hình DNN được sử dụng rộng rãi nhất. Mô hình CNN để trích xuất quan hệ được xây dựng theo Zeng và các cộng sự [32]. Kiến trúc mô hình được thể hiện trong Hình 2.3: Mô hình CNN cho trích xuất quan hệ [23]. Lớp tích chập có thể nắm bắt thông tin ngữ cảnh của các bộ lọc có độ dài bộ lọc được xác định trước. Các bộ lọc tích chập được mong đợi sẽ tạo ra các đặc trưng cục bộ cấp cao từ các biểu diễn vectơ đầu vào. Đầu ra của lớp tích chập sau đó được chuyển tiếp đến lớp Global Max-pooling, nơi các giá trị lớn nhất của mỗi đầu ra bộ lọc được tổng hợp và nối để phân loại quan hệ.
Hình 2.3: Mô hình CNN cho trích xuất quan hệ [23]
2.1.2. Mạng nơ-ron hồi quy (RNN)
Mạng nơ-ron hồi quy (Recurrent Neural Network - RNN) là một loại mạng nơ-ron nhân tạo sử dụng dữ liệu tuần tự hoặc dữ liệu chuỗi thời gian (Time-series Data). Các thuật toán học sâu này thường được sử dụng cho các vấn đề thứ tự hoặc thời gian, chẳng hạn như dịch máy, xử lý ngôn ngữ tự nhiên (NLP), nhận dạng giọng nói và chú thích hình ảnh; chúng được tích hợp vào các ứng dụng phổ
20
biến như tìm kiếm bằng giọng nói và Google Dịch. Giống như mạng nơ-ron truyền thẳng và tích chập (CNN), mạng nơ-ron hồi quy sử dụng dữ liệu huấn luyện để học. Hình 2.4: Minh họa mô hình mạng nơ-ron hồi quy [2]. Chúng khác mạng nơ- ron khác bởi “bộ nhớ” khi chúng lấy thông tin từ các đầu vào trước đó để tác động đến đầu vào và đầu ra hiện tại. Trong khi các mạng nơron sâu truyền thống giả định rằng đầu vào và đầu ra là độc lập với nhau, đầu ra của mạng nơron hồi quy phụ thuộc vào các phần tử trước đó trong chuỗi. Một đặc điểm khác của mạng hồi quy là chúng chia sẻ các tham số trên mỗi lớp của mạng. Trong khi các mạng truyền thẳng có trọng số khác nhau trên mỗi nút, các mạng nơ-ron hồi quy chia sẻ cùng một trọng số trong mỗi lớp của mạng. Điều đó nói rằng, các trọng số này vẫn được điều chỉnh thông qua các quá trình nhân lan truyền ngược (backpropagation) và giảm độ dốc (gradient descent) để tạo điều kiện cho việc học củng cố. Mạng thần kinh hồi quy tận dụng thuật toán lan truyền ngược qua thời gian (Backpropagation through time - BPTT) để xác định độ dốc, hơi khác so với lan truyền ngược truyền thống vì nó dành riêng cho dữ liệu chuỗi. Các nguyên tắc của BPTT cũng giống như lan truyền ngược truyền thống, trong đó mô hình tự đào tạo bằng cách tính toán các lỗi từ lớp đầu ra đến lớp đầu vào của nó. Các tính toán này cho phép chúng ta điều chỉnh và lắp các thông số của mô hình một cách hợp lý. BPTT khác với cách tiếp cận truyền thống ở chỗ BPTT tính tổng các lỗi tại mỗi bước thời gian trong khi các mạng chuyển tiếp cấp dữ liệu không cần tính tổng các lỗi vì chúng không chia sẻ các tham số trên mỗi lớp.
Hình 2.4: Mô hình RNN tổng quát [2]
21
Các loại mạng nơ-ron hồi quy: Đối với RNN đầu vào và đầu ra của chúng có thể khác nhau về độ dài và các loại RNN khác nhau được sử dụng cho các trường hợp sử dụng khác nhau, chẳng hạn như tạo nhạc, phân loại ý kiến và dịch máy. Có các loại RNN như sau: One to one, One to many, Many to one, Many to many;
Các hàm kích hoạt được sử dụng phổ biến nhất gồm: Sigmoid, Tanh, Relu.
Một số kiến trúc biến thể của RNN như LSTM, GRU sẽ được trình bày cụ thể bên dưới.
2.1.3. Mạng bộ nhớ dài – ngắn LSTM
Đây là một kiến trúc RNN phổ biến, được giới thiệu bởi Sepp Hochreiter và Juergen Schmidhuber [22] như một giải pháp để làm biến mất vấn đề gradient, và sau đó đã được cải tiến và phổ biến bởi rất nhiều người trong ngành. Chúng hoạt động cực kì hiệu quả trên nhiều bài toán khác nhau nên dần đã trở nên phổ biến như hiện nay. Trong bài báo của họ, họ nghiên cứu để giải quyết vấn đề phụ thuộc xa (long-term dependency). Có nghĩa là, nếu trạng thái trước đó đang ảnh hưởng đến dự đoán hiện tại không phải là trong quá khứ gần đây, thì mô hình RNN có thể không thể dự đoán chính xác trạng thái hiện tại. Ví dụ: giả sử muốn dự đoán các từ in nghiêng sau đây, “Alice bị dị ứng với các loại hạt. Cô ấy không thể ăn bơ đậu phộng." Bối cảnh của dị ứng hạt có thể giúp chúng ta biết trước rằng thực phẩm không thể ăn được có chứa các loại hạt. Tuy nhiên, nếu bối cảnh đó là một vài câu trước đó, thì RNN sẽ khó hoặc thậm chí không thể kết nối thông tin. Để khắc phục điều này, các LSTM có "ô" trong các lớp ẩn của mạng nơ-ron, có ba cổng - một cổng đầu vào (Input gate), một cổng đầu ra (Output gate) và một cổng quên (Forget gate). Các cổng này kiểm soát luồng thông tin cần thiết để dự đoán đầu ra trong mạng. Ví dụ: nếu đại từ giới tính, chẳng hạn như “she”, được lặp lại nhiều lần trong các câu trước, chúng ta có thể loại trừ đại từ đó khỏi ô trạng thái. Kiến trúc LSTM [2] bao gồm một tập hợp các mạng con được kết nối lặp lại, được gọi là các khối bộ nhớ. Các khối này có thể được coi là một phiên bản có thể phân biệt được của các chip nhớ trong máy tính kỹ thuật số. Mỗi khối chứa một hoặc nhiều ô nhớ tự kết nối và ba cổng trên cung cấp các thao tác ghi, đọc và đặt lại tương tự liên tục cho các ô.
22
Hình 2.5: Minh họa khối bộ nhớ với một ô nhớ của LSTM [2]. Một mạng LSTM được hình thành giống hệt như một RNN đơn giản, ngoại trừ việc các đơn vị phi tuyến tính trong lớp ẩn được thay thế bằng các khối bộ nhớ. Ngoài ra, như với các RNN khác, lớp ẩn có thể được gắn vào bất kỳ loại lớp đầu ra có thể phân biệt nào, tùy thuộc vào nhiệm vụ được yêu cầu (hồi quy, phân loại, v.v.). Trạng thái bên trong của ô nhớ được duy trì với kết nối lặp lại có trọng số cố định 1.0.
Ba cổng thu thập các kích hoạt từ bên trong và bên ngoài khối để kiểm soát, điều khiển ô nhớ. Các chức năng kích hoạt đầu vào và đầu ra của ô (g và h) được áp dụng ở những vị trí được chỉ định.
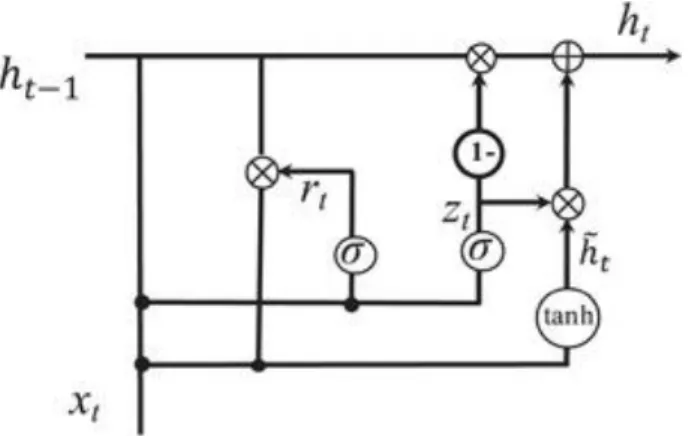
2.1.4. Mạng GRU
GRU (Gated recurrent units) là biến thể của RNN tương tự như LSTM vì nó cũng hoạt động để giải quyết vấn đề bộ nhớ ngắn hạn của các mô hình RNN.
Thay vì sử dụng "ô trạng thái" đề điều chỉnh thông tin, nó sử dụng các trạng thái ẩn và thay vì có ba cổng, nó có hai cổng: một cổng đặt lại (reset gate) và một cổng cập nhật (update gate). Tương tự như các cổng trong LSTM, các cổng đặt lại và cổng cập nhật kiểm soát số lượng và thông tin nào cần giữ lại. Trong khi CNN có thể chụp được các mẫu cục bộ trong không gian tích chập dưới dạng cấu trúc lớn
Hình 2.5: Minh họa khối bộ nhớ với một ô nhớ của LSTM [2].
23
hơn, các mô hình RNN được thiết kế để tìm hiểu các mẫu theo thời gian của các chuỗi đã cho. Tác giả nghiên cứu việc sử dụng RNN để trích xuất quan hệ. RNN mô hình câu thành một chuỗi các vectơ. Trong luận văn này đã thử nghiệm một đơn vị RNN khác, đó là Gated recurrent unit (GRU). GRU lần đầu tiên được đề xuất bởi Cho và các cộng sự [4]. Trực giác cho thấy GRU cũng tương tự như LSTM về cơ chế kiểm soát để kết hợp các bản cập nhật và đầu vào hiện tại vào mỗi đơn vị RNN. So sánh mô hình trước đây cho các nhiệm vụ học sâu khác cho thấy không có sự chiến thắng rõ ràng giữa LSTM và GRU [1].
Tác giả tuân theo công thức của GRU được sử dụng bởi Chung và các cộng sự [1]. Một GRU có thể được minh họa như Hình 2.6: Minh họa GRU [1]. Sử dụng xt để biểu thị vectơ đầu vào, W để biểu thị ma trận biến đổi của các đầu vào, U để biểu thị ma trận biến đổi của các trạng thái ẩn và b là độ lệch, đầu ra của GRU ht
có thể được tính như sau:
zt =𝛿(Wzxt +Uzht-1+bz), rt =𝛿(Wrxt +Urht-1+br),
ℎ̃𝑡=tanh(Whxt +Uh(rt*ht-1)+bh) , ht= rt*ht-1 + (1-zt)* ℎ̃𝑡,
trong đó 𝛿(. ) biểu thị hàm sigmoid và * biểu thị phép nhân ma trận. ‘Reset gate’
rt thể hiện mức độ ảnh hưởng của trạng thái hiện tại bởi lần kích hoạt trước đó.
ℎ̃𝑡 là "ứng cử viên trạng thái" ẩn của đầu ra. ‘Update gate’ zt nhằm mục đích quyết định quy mô của thiết bị dựa trên lần kích hoạt trước đó và nó kiểm soát mức độ ảnh hưởng của đầu ra ht bởi ℎ̃𝑡.
Hình 2.6: Minh họa GRU
24 2.2. Word Embedding
Word embedding là một kiểu biểu diễn từ cho phép các từ có nghĩa tương tự có thể biểu diễn tương tự. Đây là cách tiếp cận để biểu diễn các từ trong văn bản có thể được coi là một trong những bước đột phá quan trọng của học sâu trong các vấn đề xử lý ngôn ngữ tự nhiên đầy thách thức. Word embedding thực chất là một lớp kỹ thuật trong đó các từ riêng lẻ được biểu diễn dưới dạng vectơ có giá trị thực trong không gian vectơ được xác định trước. Mỗi từ được ánh xạ tới một vectơ và các giá trị vectơ được học theo cách tương tự như mạng nơ-ron, và do đó kỹ thuật này thường được gộp chung vào lĩnh vực học sâu.
Word embedding đã được sử dụng phổ biến trong các ứng dụng xử lý ngôn ngữ tự nhiên đặc biệt là trong văn bản y sinh học do khả năng biểu diễn vectơ có thể nắm bắt các thuộc tính ngữ nghĩa hữu ích và mối quan hệ ngôn ngữ giữa các từ. Word embedding thường được sử dụng làm các đặc trưng đầu vào cho các mô hình học máy, cho phép các kỹ thuật học máy ngữ cảnh hóa dữ liệu văn bản thô.
Word embedding đã trở thành nền tảng thiết yếu cho các phương pháp tiếp cận dựa trên mạng nơ-ron trong NLP và học từ kho ngữ liệu lớn không được gắn nhãn để nắm bắt ngữ nghĩa tiềm ẩn của từ [31].
GloVe (Global Vectors for Word Representation) là một phương pháp để tạo word embedding mà luận văn này sẽ sử dụng. Nó dựa trên kỹ thuật phân tích nhân ma trận trên ma trận ngữ cảnh từ [9]. Một ma trận lớn về thông tin đồng xuất hiện được xây dựng và đếm từng “từ” (các hàng) và tần suất chúng ta thấy từ này trong một số “ngữ cảnh” (các cột) trong một kho ngữ liệu lớn. Thông thường, chúng ta quét kho ngữ liệu của mình theo cách sau: đối với mỗi thuật ngữ, chúng ta tìm kiếm các thuật ngữ ngữ cảnh trong một số khu vực được xác định bởi window-size trước thuật ngữ và window-size sau thuật ngữ. Ngoài ra, chúng ta cho trọng số thấp hơn cho những từ xa nghĩa hơn. Tất nhiên, số lượng “ngữ cảnh”
là rất lớn, vì nó về cơ bản có kích thước tổ hợp. Vì vậy, sau đó cần phân tích nhân tử của ma trận này để tạo ra ma trận có chiều thấp hơn, trong đó mỗi hàng biểu diễn vectơ cho mỗi từ.
Trong luận văn sử dụng mô hình 300 chiều được đào tạo trước Glove-6B (https://nlp.stanford.edu/projects/glove/). Các thí nghiệm sơ bộ cho thấy rằng mô hình 300 chiều Glove-6B hoạt động tốt hơn các mô hình nhúng từ đã đào tạo bằng túi từ liên tục (CBOW) từ PubMed [23]. Nếu không tìm thấy từ nào từ mô hình nhúng từ, thì quá trình nhúng sẽ được tạo ngẫu nhiên và phần nhúng đã tạo sẽ được thêm vào mô hình
25 2.3. Position Embedding
Position embedding được tạo ra dựa trên khoảng cách tương đối của các từ với các thực thể. Các khoảng cách sau đó được dịch chuyển bằng một độ lệch tùy ý để ánh xạ khoảng cách thành số nguyên dương. Các position embedding sau đó được đào tạo chung trong giai đoạn đào tạo. Đối với mỗi thể hiện quan hệ, sẽ có hai vị trí nhúng cho mỗi từ từ hai thực thể cho các thực thể hóa học và bệnh tương ứng. Hai vị trí nhúng được nối với từ nhúng của từ làm đầu vào cho các mô hình mạng nơ-ron [23].
Luận văn làm theo phương pháp của Zeng và các cộng sự [32] để tạo ra vị trí nhúng của các thực thể trong mỗi câu tường thuật. Trong nghiên cứu này, tác giả sử dụng hai phương pháp: nhúng vị trí 50 chiều và nhúng từ 300 chiều, tạo ra vectơ đặc trưng 400 chiều cho mỗi từ.
2.4. Kỹ thuật attention
Sự ra đời của kỹ thuật attention trong học sâu đã cải thiện sự thành công của nhiều mô hình khác nhau trong những năm gần đây và tiếp tục là một thành phần có mặt khắp nơi trong các mô hình hiện đại. Do đó, điều quan trọng là chúng ta phải chú ý đến “attention” và làm thế nào để nó đạt được hiệu quả. Khi nghĩ về từ tiếng Anh “Attention”, chúng ta biết rằng nó có nghĩa là hướng sự tập trung của mình vào một điều gì đó và chú ý nhiều hơn. Cơ chế tập trung trong Học sâu dựa trên khái niệm hướng sự tập trung của mình và chú ý nhiều hơn đến các yếu tố nhất định khi xử lý dữ liệu. Nói một cách rộng rãi, “attention” là một thành phần của kiến trúc mạng và chịu trách nhiệm quản lý và định lượng sự phụ thuộc lẫn nhau.
Trong luận văn này tác giả sử dụng kỹ thuật attention được đề xuất bởi Thang Luong và các cộng sự [16] áp dụng cho mô hình RNN và các biến thể LSTM, GRU. Cơ chế tập trung được đề xuất để nhấn mạnh sự đóng góp của các đơn vị nơ-ron trong mô hình. Thay vì trực tiếp nhận các kích hoạt hoặc kết quả đầu ra từ các đơn vị RNN liên tiếp, lớp attention (lớp tập trung) bổ sung sẽ bỏ qua tất cả các đơn vị RNN của chuỗi đầu vào và gán các trọng số khác nhau cho mỗi đơn vị theo mức độ quan trọng của chúng. Trực giác để áp dụng mô hình ATT trong nhiệm vụ trích xuất quan hệ là cố gắng gán trọng số cao hơn cho các từ là chỉ số hoặc từ kích hoạt của các quan hệ ngữ nghĩa cụ thể. Tác giả sử dụng các phương trình lấy từ Luong và các cộng sự [16] để tính toán trọng số attention cho mỗi từ trong câu. ATT-RNN để trích xuất quan hệ được minh họa trong Hình 2.7:
Cơ chế tập trung dựa trên mạng RNN cho trích xuất quan hệ [16]. Kích hoạt của
26
các đơn vị RNN được ký hiệu là h=[h1, h2,…hT], trong đó T là độ dài câu. Với biểu diễn từ là w và các kích hoạt của đơn vị RNN trước đó ht, tác giả xác định ma trận trọng số ẩn của lớp attention là ut và vectơ quan trọng mức độ từ uw, là một biến có thể đào tạo. Vectơ biểu diễn quan hệ s là tổng trọng số của đầu ra RNN h và trọng số tập trung α:
ut=tanh(Wwht + bw), αt= exp (𝑢
𝑇 𝑡𝑢𝑤)
∑ exp (𝑢𝑇 𝑡𝑢𝑤) 𝑡
, s=∑ 𝛼𝑡 𝑡ℎ𝑡,
trong đó Ww và bw là ma trận trọng số và độ lệch của lớp attention, tương tự như ký hiệu của lớp GRU.
Hình 2.7: Cơ chế tập trung dựa trên mạng RNN cho trích xuất quan hệ [16]
27
CHƯƠNG 3: THỰC NGHIỆM DỰ ĐOÁN TÁC DỤNG PHỤ CỦA THUỐC TỪ Y VĂN SỬ DỤNG MẠNG NƠ-RON DỰA TRÊN CƠ CHẾ
TẬP TRUNG 3.1. Mô tả bài toán
Các khám phá khoa học trong lĩnh vực y sinh phụ thuộc rất nhiều vào nguồn tri thức ở định dạng có thể tính toán được để có thể phân tích, giải thích dữ liệu và áp dụng sự tiến bộ của các công nghệ phân tích dữ liệu lớn. Mục tiêu của việc trích xuất mối quan hệ y sinh là để tự động nắm bắt các mối quan hệ y sinh có giá trị, chẳng hạn như tương tác protein-protein (PPIs), tương tác thuốc thuốc (DDIs) và tương tác hóa học – protein (CPIs) từ văn bản y sinh không có cấu trúc với độ chính xác và hiệu quả cao thông qua các kỹ thuật xử lý ngôn ngữ tự nhiên (NPL) và các kỹ thuật học máy. Nói chung, trích xuất quan hệ y sinh bao gồm 2 bước chính [31]:
+ Nhận dạng tên thực thể y sinh (biomedical named entity recognition viết tắt NER)
+ Phân lớp quan hệ y sinh.
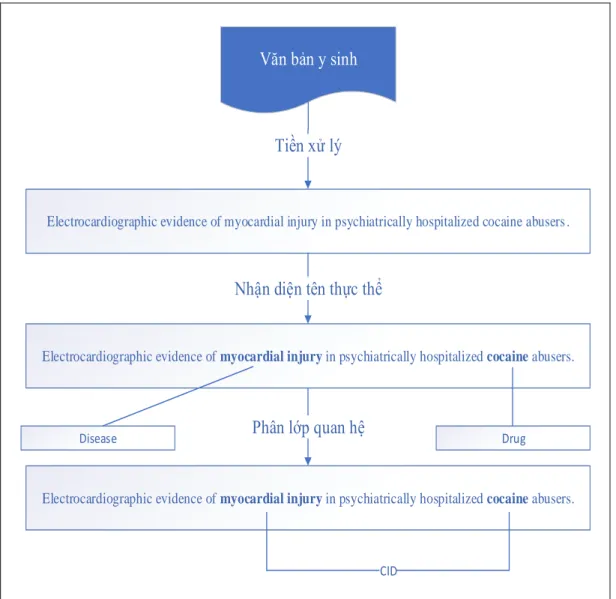
Một ví dụ cụ thể được minh họa trong Hình 3.1: Minh họa bài toán trích xuất mối quan hệ giữa thuốc và bệnh cho thấy chúng ta cần phải nhận dạng và chú thích được các tên thực thể “myocardial injury” và “cocaine” trong câu. Sau đó, phân lớp quan hệ để phát hiện mối quan hệ ngữ nghĩa giữa hai thực thể ứng viên trên.
Tuy nhiên, trong thập kỷ qua với các tiến bộ khoa học đã tạo ra rất nhiều công cụ để xử lý bài toán nhận dạng tên thực thể y sinh với hiệu suất rất tốt [19][33]. Vì vậy, trong luận văn này, tác giả tập trung vào bài toán phân lớp quan hệ y sinh mà cụ thể là: Phân lớp các cặp quan hệ giữa thuốc và bệnh để kết luận xem chúng có quan hệ (thuốc – tác dụng phụ của thuốc) hay không (có/không)?
28
Electrocardiographic evidence of myocardial injury in psychiatrically hospitalized cocaine abusers .
Văn bản y sinh
Tiền xử lý
Electrocardiographic evidence of myocardial injury in psychiatrically hospitalized cocaine abusers.
Nhận diện tên thực thể
Disease Drug
Electrocardiographic evidence of myocardial injury in psychiatrically hospitalized cocaine abusers.
Phân lớp quan hệ
CID
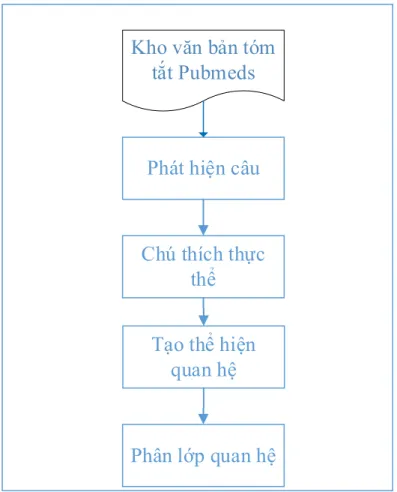
Hình 3.1: Minh họa bài toán trích xuất mối quan hệ giữa thuốc và bệnh Kiến trúc chương trình tác giả trình bày trong luận văn này được minh họa trong Hình 3.2: Tổng quan kiến trúc chương trình. Với dữ liệu thô là kho văn bản tóm tắt Pubmeds và cùng các thực thể thuốc và bệnh, tác giả mô hình hóa vấn đề khai thác mối quan hệ như một bài toán phân lớp quan hệ trong số tất cả quan hệ giữa các cặp thuốc và bệnh tiềm năng. Đầu tiên văn bản được phân tách thành các câu. Sau đó, các chú thích cho các đối tượng được gán và căn chỉnh theo từng câu.
Tiếp theo, câu và tập hợp các thực thể trong câu được sử dụng để tạo ra các thể hiện quan hệ. Cuối cùng, áp dụng các mô hình mạng nơ-ron được đề xuất trong luận văn để dự đoán nhãn của từng thể hiện quan hệ. YES với các cặp được xác định là giữa thuốc và bệnh có quan hệ tác dụng phụ (CID). NO với các cặp giữa thuốc và bệnh không có quan hệ với nhau.
29 Phát hiện câu
Tạo thể hiện quan hệ
Phân lớp quan hệ Chú thích thực
thể
Kho văn bản tóm tắt Pubmeds
Hình 3.2: Tổng quan kiến trúc chương trình
Trong nghiên cứu này, tác giả chỉ xem xét các quan hệ giữa các thực thể xuất hiện trong cùng một câu. Tác giả sử dụng trình dò câu Punkt trong Bộ công cụ ngôn ngữ tự nhiên [11], [15] để phát hiện và tách câu. Tiêu đề của mỗi bài báo được coi là câu đầu tiên của phần tóm tắt và nó không được xem xét riêng biệt.
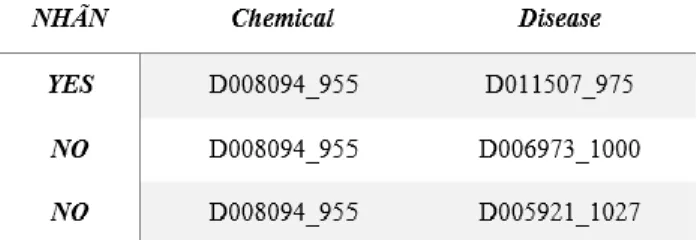
Ví dụ về cách các tạo các thể hiện quan hệ thuốc – bệnh từ các câu được thể hiện trong Hình 3.3: Cách tạo các thể hiện quan hệ từ các câu. Trong đó, có một đề cập hóa học: ‘Lithium’ và ba đề cập về bệnh ‘proteinuria’, ‘hypertension’ và
[Lithium] also caused [proteinuria] and systolic [hypertension] in absence of [glomerulosclerosis]
D008094_955: Chemical D011507_975: Disease D006973_1000: Disease D005921_1027: Disease
Hình 3.3: Cách tạo các thể hiện quan hệ từ các câu
30
‘glomerulosclerosis’. Từ câu đó ta có thể tạo ra 3 cặp quan hệ thuốc-bệnh trong đó có một cặp được gãn nhãn là YES với ý nghĩa là bệnh do thuốc gây ra.
3.2. Mô tả dữ liệu và các bước thực hiện
Hầu hết các phương pháp tiếp cận dựa trên mạng nơron là các phương pháp có giám sát và yêu cầu dữ liệu được gắn nhãn để đào tạo các mô hình học máy.
Do đó, kho ngữ liệu được gắn nhãn đóng một vai trò quan trọng trong phương pháp luận dựa trên mạng nơron trong phân lớp quan hệ y sinh. Kho tài liệu có sẵn công khai rất quan trọng để đánh giá và so sánh hiệu suất.
Dữ liệu được tác giả sử dụng trong luận văn này là kho ngữ liệu CDR chứa các quan hệ CID gồm 1500 bài báo PubMed, 4409 chú thích hóa chất, 5818 chú thích bệnh và 3116 quan hệ giữa thuốc và bệnh (CID). PubMed được biết đến là một cơ sở dữ liệu miễn phí về các tài liệu tham khảo và tóm tắt về các chủ đề khoa học đời sống và y sinh học. PubMed được NCBI (National Center for Biotechnology Information – Trung tâm Thông tin Công nghệ Sinh học Quốc gia (Hoa Kỳ)), thuộc NLM (National Library of Medicine – Thư viện Y khoa Quốc gia (Hoa Kỳ)), đặt tại NIH (National Institutes of Health – Viện Y học Quốc gia Hoa Kỳ) xây dựng và duy trì.
Trong BioCreative V, một thử thách mới đã được các nhà khoa học tổ chức với nhiệm vụ chính là nhận dạng thực thể bệnh (Disease named entity recognition- DNER) và trích xuất mối quan hệ bệnh do hóa chất gây ra (CID). Kết quả của thử thách này đã hình thành nên kho ngữ liệu có tên BC5CDR được sử dụng trong luận văn này.
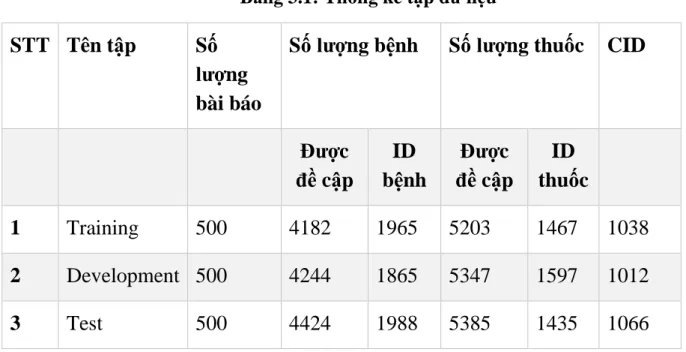
Kho ngữ liệu bao gồm ba nhóm bài báo riêng biệt với các bệnh, chất hóa học và mối quan hệ của chúng đã được chú thích trong đó tập huấn luyện (500 bài báo), tập phát triển (500 bài báo) và tập thử nghiệm (500 bài báo) được sử dụng để đánh giá hiệu suất chương trình. Chi tiết được thể hiện trong Bảng 3.1: Thống kê tập dữ liệu.
31
Bảng 3.1: Thống kê tập dữ liệu STT Tên tập Số
lượng bài báo
Số lượng bệnh Số lượng thuốc CID
Được đề cập
ID bệnh
Được đề cập
ID thuốc
1 Training 500 4182 1965 5203 1467 1038
2 Development 500 4244 1865 5347 1597 1012
3 Test 500 4424 1988 5385 1435 1066
Như thể hiện trong Bảng 3.2-1, ba tập dữ liệu có sự phân bổ tương tự về các đề cập thuốc, đề cập đến bệnh tật và quan hệ CID, điều này làm cho kho ngữ liệu hữu ích hơn cho các mô hình đào tạo. Bảng 3.2-1 cũng cho thấy rằng mặc dù có nhiều đề cập thuốc hơn đề cập đến bệnh trong kho ngữ liệu, nhưng có nhiều thực thể bệnh (ID bệnh) hơn thực thể thuốc (ID thuốc),
Thông tin chi tiết về tập dữ liệu lấy tại:
https://academic.oup.com/database/article/doi/10.1093/database/baw068/263041 4
Trong khuôn khổ của luận văn, tác giả sử dụng kho ngữ liệu chuẩn vàng BioCreative V – CDR chứa các bài báo khoa học mô tả có hay không quan hệ tác dụng phụ giữa thuốc và bệnh.
Luận văn sử dụng các file sau trong kho ngữ liệu BC5CDR:
⚫ CDR_development.PubTator.txt == > Tạo thành data development
⚫ CDR_test.PubTator.txt ==> Tạo thành data test
⚫ CDR_training.PubTator.txt ==> Tạo thành data trainning Cấu trúc mỗi file dữ liệu bao gồm:
⚫ t: title của bài báo
⚫ a: Abstract của bài báo
32
⚫ Chemical: Danh sách các thuốc
⚫ Disease: Danh sách các bệnh
⚫ CID: Mối quan hệ giữa thuốc và bệnh Ví dụ:
6794356|t|Tricuspid valve regurgitation and lithium carbonate toxicity in a newborn infant.
6794356|a|A newborn with massive tricuspid regurgitation, atrial flutter, congestive heart failure, and a high serum lithium level is described. This is the first patient to initially manifest tricuspid regurgitation and atrial flutter, and the 11th described patient with cardiac disease among infants exposed to lithium compounds in the first trimester of pregnancy. Sixty-three percent of these infants had tricuspid valve involvement. Lithium carbonate may be a factor in the increasing incidence of congenital heart disease when taken during early pregnancy. It also causes neurologic depression, cyanosis, and cardiac arrhythmia when consumed prior to delivery.
6794356 0 29 Tricuspid valve regurgitation Disease D014262 6794356 34 51 lithium carbonate Chemical D016651
6794356 52 60 toxicity Disease D064420
6794356 105 128 tricuspid regurgitation Disease D014262 6794356 130 144 atrial flutter Disease D001282
6794356 146 170 congestive heart failure Disease D006333 6794356 189 196 lithium Chemical D008094
6794356 265 288 tricuspid regurgitation Disease D014262 6794356 293 307 atrial flutter Disease D001282
6794356 345 360 cardiac disease Disease D006331 6794356 386 393 lithium Chemical D008094
6794356 511 528 Lithium carbonate Chemical D016651
6794356 576 600 congenital heart disease Disease D006331 6794356 651 672 neurologic depression Disease D003866 6794356 674 682 cyanosis Disease D003490
33
6794356 688 706 cardiac arrhythmia Disease D001145 6794356 CID D016651 D003490
6794356 CID D016651 D001145 6794356 CID D016651 D003866 Các bước thực hiện:
- Từ dữ liệu BC5CDR thực hiện chuyển đổi mỗi tập data (development, test, training) thành 3 file cho mỗi tập như sau:
+ File *_abstract.tsv: Là dữ liệu text của bài báo gồm title và abstract
6794356 Tricuspid valve regurgitation and lithium carbonate toxicity in a newborn infant. A newborn with massive tricuspid regurgitation, atrial flutter, congestive heart failure, and a high serum lithium level is described. This is the first patient to initially manifest tricuspid regurgitation and atrial flutter, and the 11th described patient with cardiac disease among infants exposed to lithium compounds in the first trimester of pregnancy. Sixty-three percent of these infants had tricuspid valve involvement. Lithium carbonate may be a factor in the increasing incidence of congenital heart disease when taken during early pregnancy. It also causes neurologic depression, cyanosis, and cardiac arrhythmia when consumed prior to delivery.
+ File *_entities.tsv: Gồm tên các loại thuốc và các thuộc tính (tên đối tượng được cộng thêm start pos để tạo thành mã duy nhất):
6794356 D014262_0 Disease 0 29 Tricuspid valve regurgitation 6794356 D016651_34 Chemical 34 51 lithium carbonate 6794356 D064420_52 Disease 52 60 toxicity
6794356 D014262_105 Disease 105 128 tricuspid regurgitation 6794356 D001282_130 Disease 130 144 atrial flutter
6794356 D006333_146 Disease 146 170 congestive heart failure
6794356 D008094_189 Chemical 189 196 lithium
6794356 D014262_265 Disease 265 288 tricuspid regurgitation 6794356 D001282_293 Disease 293 307 atrial flutter
6794356 D006331_345 Disease 345 360 cardiac disease
34
6794356 D008094_386 Chemical 386 393 lithium
6794356 D016651_511 Chemical 511 528 Lithium carbonate 6794356 D006331_576 Disease 576 600 congenital heart disease
6794356 D003866_651 Disease 651 672 neurologic depression 6794356 D003490_674 Disease 674 682 cyanosis
6794356 D001145_688 Disease 688 706 cardiac arrhythmia + File *_gold_standard.tsv: Gồm các cặp thuốc và bệnh và mối quan hệ (YES/NO):
6794356 NO Arg1:D016651_34 Arg2:D014262_0 6794356 NO Arg1:D016651_34 Arg2:D064420_52 6794356 NO Arg1:D016651_34 Arg2:D014262_105 6794356 NO Arg1:D016651_34 Arg2:D001282_130 6794356 NO Arg1:D016651_34 Arg2:D006333_146 6794356 NO Arg1:D016651_34 Arg2:D014262_265 6794356 NO Arg1:D016651_34 Arg2:D001282_293 6794356 NO Arg1:D016651_34 Arg2:D006331_345 6794356 NO Arg1:D016651_34 Arg2:D006331_576 6794356 YES Arg1:D016651_34 Arg2:D003866_651 6794356 YES Arg1:D016651_34 Arg2:D003490_674 6794356 YES Arg1:D016651_34 Arg2:D001145_688 6794356 NO Arg1:D008094_189 Arg2:D014262_0 6794356 NO Arg1:D008094_189 Arg2:D064420_52 6794356 NO Arg1:D008094_189 Arg2:D014262_105 6794356 NO Arg1:D008094_189 Arg2:D001282_130 6794356 NO Arg1:D008094_189 Arg2:D006333_146 6794356 NO Arg1:D008094_189 Arg2:D014262_265 6794356 NO Arg1:D008094_189 Arg2:D001282_293
35
6794356 NO Arg1:D008094_189 Arg2:D006331_345 6794356 NO Arg1:D008094_189 Arg2:D006331_576 6794356 NO Arg1:D008094_189 Arg2:D003866_651 6794356 NO Arg1:D008094_189 Arg2:D003490_674 6794356 NO Arg1:D008094_189 Arg2:D001145_688 6794356 NO Arg1:D008094_386 Arg2:D014262_0 6794356 NO Arg1:D008094_386 Arg2:D064420_52 6794356 NO Arg1:D008094_386 Arg2:D014262_105 6794356 NO Arg1:D008094_386 Arg2:D001282_130 6794356 NO Arg1:D008094_386 Arg2:D006333_146 6794356 NO Arg1:D008094_386 Arg2:D014262_265 6794356 NO Arg1:D008094_386 Arg2:D001282_293 6794356 NO Arg1:D008094_386 Arg2:D006331_345 6794356 NO Arg1:D008094_386 Arg2:D006331_576 6794356 NO Arg1:D008094_386 Arg2:D003866_651 6794356 NO Arg1:D008094_386 Arg2:D003490_674 6794356 NO Arg1:D008094_386 Arg2:D001145_688 6794356 NO Arg1:D016651_511 Arg2:D014262_0 6794356 NO Arg1:D016651_511 Arg2:D064420_52 6794356 NO Arg1:D016651_511 Arg2:D014262_105 6794356 NO Arg1:D016651_511 Arg2:D001282_130 6794356 NO Arg1:D016651_511 Arg2:D006333_146 6794356 NO Arg1:D016651_511 Arg2:D014262_265 6794356 NO Arg1:D016651_511 Arg2:D001282_293 6794356 NO Arg1:D016651_511 Arg2:D006331_345 6794356 NO Arg1:D016651_511 Arg2:D006331_576 6794356 YES Arg1:D016651_511 Arg2:D003866_651 6794356 YES Arg1:D016651_511 Arg2:D003490_674
![Hình 2.1: Mô hình kiến trúc mạng nơ-ron [12]](https://thumb-ap.123doks.com/thumbv2/1libvncom/11360995.0/16.893.259.686.673.960/hình-mô-hình-kiến-trúc-mạng-nơ-ron.webp)
![Hình 2.3: Mô hình CNN cho trích xuất quan hệ [23]](https://thumb-ap.123doks.com/thumbv2/1libvncom/11360995.0/19.893.129.804.457.881/hình-mô-hình-cnn-trích-xuất-quan-hệ.webp)
![Hình 2.4: Mô hình RNN tổng quát [2]](https://thumb-ap.123doks.com/thumbv2/1libvncom/11360995.0/20.893.250.672.724.1023/hình-2-4-mô-hình-rnn-tổng-quát.webp)
![Hình 2.5: Minh họa khối bộ nhớ với một ô nhớ của LSTM [2]. Một mạng LSTM được hình thành giống hệt như một RNN đơn giản, ngoại trừ việc các đơn vị phi tuyến tính trong lớp ẩn được thay thế bằng các khối bộ nhớ](https://thumb-ap.123doks.com/thumbv2/1libvncom/11360995.0/22.893.249.649.104.548/hình-khối-mạng-thành-giống-giản-ngoại-tuyến.webp)
![Hình 2.7: Cơ chế tập trung dựa trên mạng RNN cho trích xuất quan hệ [16]](https://thumb-ap.123doks.com/thumbv2/1libvncom/11360995.0/26.893.220.697.444.836/hình-chế-tập-trung-dựa-mạng-trích-xuất.webp)