Tên chủ đề: Tìm hiểu về mô hình Word2Vec và các ứng dụng xử lý dữ liệu tiếng Việt. Hầu hết các mô hình deep learning hiện nay như: CNN, RNN, LSTM, v.v. sử dụng vectơ từ làm đầu vào và đã được chứng minh là mang lại kết quả tốt nhất trong nhiều vấn đề xử lý ngôn ngữ tự nhiên.
WORD2VEC
G IỚI THIỆU VỀ W ORD 2 VEC
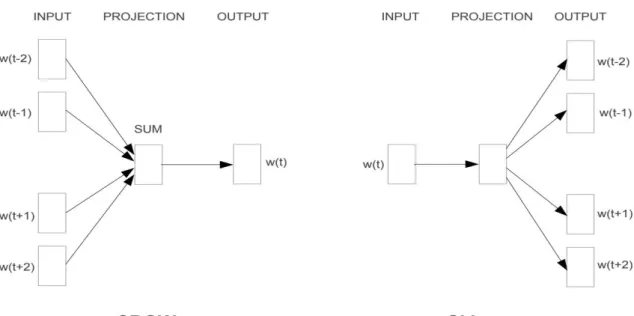
Mô hình Skip-Gram là mô hình dự đoán các từ xung quanh dựa trên một từ nhất định. Khi sử dụng mô hình Skip-Gram, đầu vào là một từ trong câu, thuật toán sẽ xem xét các từ xung quanh nó.
C HI TIẾT MÔ HÌNH
- Mô hình CBOW và Skip-Grams
- Lớp làm giả
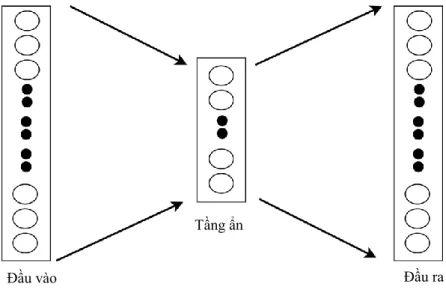
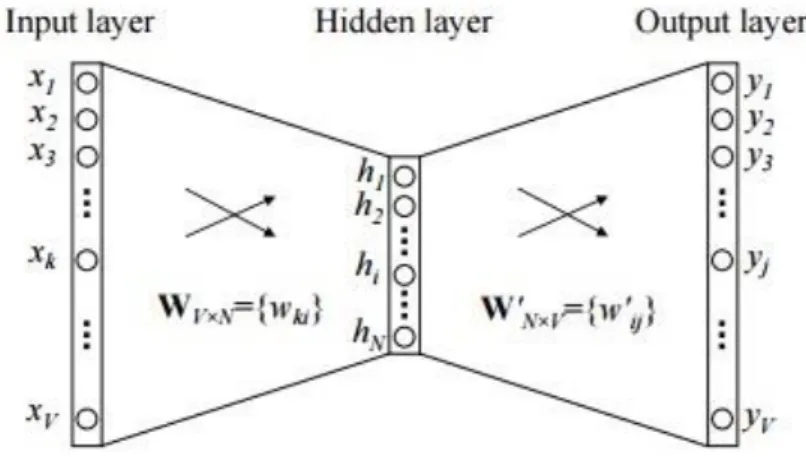
- Kiến trúc mạng nơ-ron
- Lớp ẩn
- Lớp đầu ra
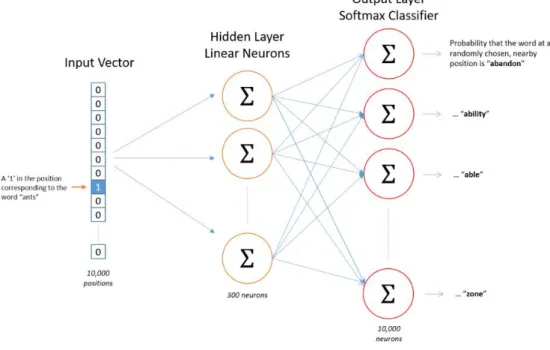
Đặt 'kiến' là một từ đầu vào được coi là một vectơ nóng. Giả sử chúng ta tính toán mối tương quan giữa từ “kiến” và từ “xe hơi”, thì hai từ này sẽ được vector hóa dựa trên ma trận trọng số của lớp ẩn đã được huấn luyện.
N HÚNG TỪ (W ORD E MBEDDING )
Nhân vectơ đầu vào một nóng với ma trận trọng số về cơ bản là tìm kiếm trong ma trận trọng số một vectơ đặc trưng có độ dài bằng số chiều của ma trận trọng số. Các từ có ý nghĩa ngữ nghĩa và ngữ cảnh tương tự cũng có cách biểu diễn vectơ tương tự, trong khi mỗi từ trong từ vựng sẽ đồng thời có một tập hợp biểu diễn vectơ duy nhất.
T ÍNH HIỆU QUẢ
Tính năng nhúng từ cố gắng nắm bắt ý nghĩa ngữ nghĩa, ngữ cảnh và cú pháp của từng từ vựng dựa trên cách những từ này được sử dụng trong câu.
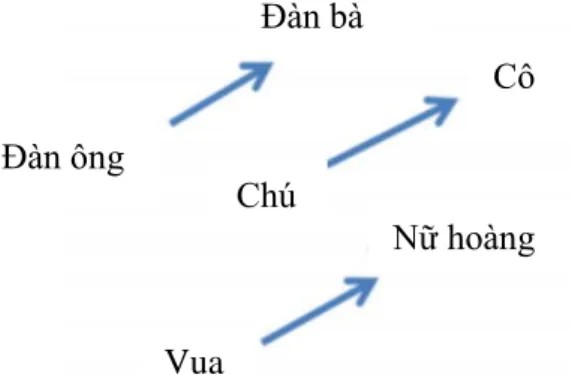
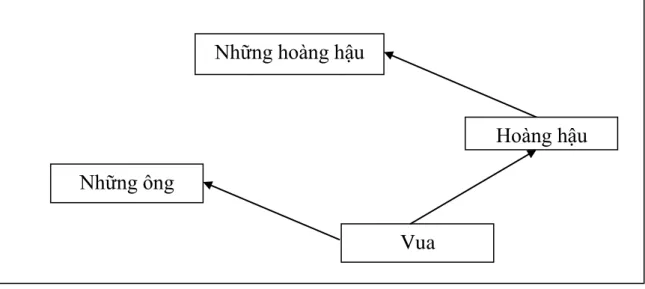
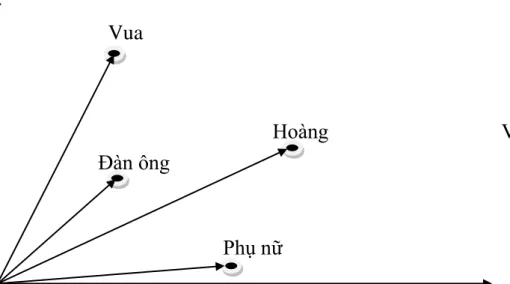
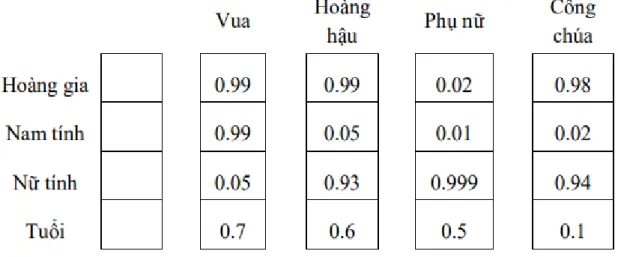
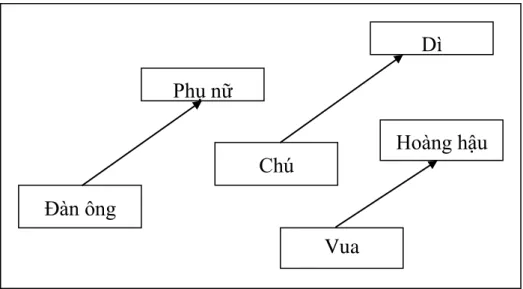
Dì sử dụng một phương pháp đơn giản là bù vectơ dựa trên khoảng cách anh em họ. Giá trị offset vector cho 3 cặp từ mô phỏng mối quan hệ giới tính. Tất cả những điều này thực sự đáng chú ý khi bạn cho rằng kiến thức này chỉ đơn giản đến từ việc xem xét nhiều từ trong ngữ cảnh (như chúng ta sẽ thấy ngay sau đây) mà không có bất kỳ thông tin nào khác về ngữ nghĩa.
Khá ngạc nhiên khi thấy rằng sự giống nhau trong cách biểu diễn từ vượt xa các quy tắc ngữ nghĩa đơn giản. Các vectơ từ có mối quan hệ ngữ nghĩa như vậy có thể được sử dụng để cải thiện nhiều ứng dụng NLP hiện có, chẳng hạn như dịch máy, hệ thống truy xuất thông tin và hệ thống câu hỏi/trả lời, đồng thời cũng có thể dẫn đến việc phát minh ra các ứng dụng khác trong tương lai. Kiểm tra các mối quan hệ từ ngữ nghĩa-cú pháp để hiểu một loạt các mối quan hệ như dưới đây.
N GỮ CẢNH
- Ngữ cảnh của một từ
- Ngữ cảnh của cụm từ
Mỗi hàng của W là một biểu diễn vectơ N chiều V của từ liên quan của lớp đầu vào. EH, vectơ N chiều, là tổng các vectơ đầu ra của tất cả các từ trong từ điển, được tính trọng số bởi lỗi dự đoán của chúng. Bằng trực giác, vì vectơ EH là tổng các vectơ đầu ra của tất cả các từ trong từ điển, có trọng số là sai số dự đoán của chúng ej = yj - tj, nên ta có thể hiểu rằng (CT 1.6 .1.13) cộng một phần của tất cả các vectơ đầu ra vào trong từ điển đến vectơ đầu vào của tập hợp các từ trong cùng một ngữ cảnh.
I được xác định bởi lỗi dự đoán của tất cả các vectơ trong từ vựng; Sai số dự đoán càng lớn thì ảnh hưởng của một từ đến vectơ đầu vào của một nhóm từ trong cùng một ngữ cảnh càng lớn. Tương tự, một vectơ đầu vào cũng có thể kéo theo nhiều vectơ đầu ra. Sau nhiều lần lặp, vị trí tương đối của vectơ đầu vào và đầu ra cuối cùng sẽ ổn định.
Khi tính toán đầu ra của lớp ẩn, thay vì sao chép trực tiếp các vectơ đầu vào của các nhóm từ cùng một bối cảnh đầu vào, mô hình CBOW tính toán các vectơ của các nhóm từ cùng một bối cảnh đầu vào và sử dụng kết quả của ma trận trọng số đầu vào, trọng số ẩn. ma trận và vectơ trung bình làm đầu ra: .
S OFT M AX PHÂN CẤP (H IERARCHICAL S OFT M AX )
- Lấy Mẫu phủ định (Negative Sampling)
- Lựa chọn mẫu phụ của các từ thường gặp (Subsampling of Frequent
Mnih và Hinton đã nghiên cứu các phương pháp khác nhau để xây dựng cấu trúc cây và những ảnh hưởng đến cả thời gian huấn luyện cũng như độ chính xác của mô hình kết quả. Trong công việc của họ, cây Huffman nhị phân được sử dụng vì nó gán mã ngắn cho các từ thường xuyên tạo ra kết quả nhanh. Việc nhóm các từ theo tần số của chúng trước đây đã được quan sát là hoạt động tốt như một kỹ thuật tăng tốc đơn giản cho mạng lưới thần kinh dựa trên các mô hình ngôn ngữ.
Điều này tương tự với điểm còn thiếu mà Collobert và Weston đã sử dụng để huấn luyện mô hình của họ bằng cách sắp xếp dữ liệu nhiễu. Mặc dù NCE có thể được hiển thị để tối đa hóa khả năng ghi nhật ký của SoftMax, nhưng mô hình Skip-Gram chỉ quan tâm đến việc nghiên cứu biểu diễn vectơ chất lượng cao, vì vậy chúng tôi có thể đơn giản hóa nó. Hóa học NCE miễn là các biểu diễn vectơ vẫn giữ được chất lượng của chúng. Ý tưởng này cũng có thể được áp dụng theo hướng ngược lại; Biểu diễn vectơ của các từ thông dụng không thay đổi đáng kể sau khi chạy trên vài triệu ví dụ.
Chúng tôi chọn công thức mẫu con này vì nó cho thấy rằng các từ trong mẫu con có tần số lớn hơn t trong khi vẫn giữ nguyên thứ tự tần số.
MỘT SỐ MÔ HÌNH HỌC SÂU
H ỌC SÂU - D EEP L EARNING
M ẠNG NƠ - RON HỒI QUY RNN (R ECURRENT N EURAL N ETWORK )
- Giới thiệu mạng nơ-ron hồi quy (RNN)
- Cấu trúc của RNN
- Các dạng của RNN
- Ví dụ ứng dụng
- Nhận xét
- Quá trình xử lý thông tin trong mạng RNN
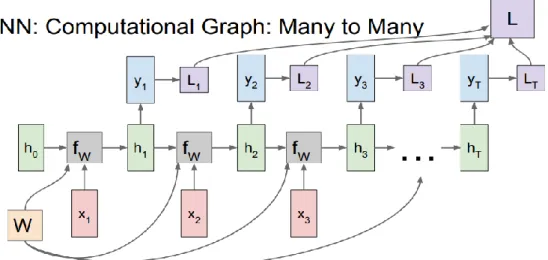
Mô hình bài toán cho Mạng thần kinh chuyển đổi (NN) và Mạng thần kinh chuyển đổi (CNN), 1 đầu vào và 1 đầu ra. Ví dụ: với CNN, đầu vào là một hình ảnh và đầu ra là một hình ảnh được phân đoạn. RNN One to One One to Many: vấn đề với 1 đầu vào nhưng nhiều đầu ra.
One to many RNN Many to one: vấn đề với nhiều đầu vào nhưng chỉ có 1 đầu ra. RNN có thể truyền thông tin từ các lớp trước đến các lớp sau, nhưng trên thực tế, thông tin chỉ có thể được truyền qua một số trạng thái nhất định, mô hình chỉ học từ các trạng thái gần với Bộ nhớ ngắn hạn. Trong trường hợp này, khoảng cách đến thông tin liên quan được rút ngắn và mạng RNN có thể tìm hiểu và sử dụng thông tin trước đó.
Trường hợp có nhiều thông tin hơn trong một câu, ý nghĩa sẽ phụ thuộc vào ngữ cảnh.
M ẠNG B Ộ NHỚ DÀI NGẮN (L ONG - SHORT TERM MEMORY -LSTM)
- Giới thiệu
- Phân tích mô hình LSTM
- Một số biến thể của LSTM
- Kết luận
Bước đầu tiên của LSTM là quyết định loại bỏ thông tin nào khỏi trạng thái ô. Tiếp theo là lớp tanh tạo vectơ cho giá trị mới để thêm vào trạng thái. Sau đó kết hợp hai giá trị này để tạo ra một bản cập nhật trạng thái.
Nhân trạng thái cũ với ft để loại bỏ thông tin mà trước đây chúng ta đã quyết định quên. Giá trị đầu ra sẽ dựa trên trạng thái ô nhưng sẽ được tinh chỉnh liên tục. Đầu tiên, chúng tôi thực hiện một lớp sigmoid để quyết định phần nào của trạng thái ô mà chúng tôi muốn xuất ra.
Nó cũng hợp nhất trạng thái ô và trạng thái ẩn, tạo ra một thay đổi khác.

ỨNG DỤNG WORD2VEC CHO XỬ LÝ CHO DỮ LIỆU TIẾNG
B ÀI TOÁN PHÂN LOẠI QUAN ĐIỂM BÌNH LUẬN
Mình dùng 650, sáng nay ngủ dậy tự nhiên 3 phím bị liệt, backspace, space và phím đen dưới chữ A. Ngoài việc thiếu ROM cho máy này thì không có gì để chê A650 ở thời điểm này cả, vì nhìn vào giá của các sản phẩm xách tay Hàn Quốc thì thiết bị này có cấu hình cao, giá rất tốt nhưng ngược lại máy lại ổn định. quyết tâm cao". Dự án sử dụng bộ dữ liệu nhận xét về dịch vụ ăn uống được dán nhãn.
Rating: điểm đánh giá tính chủ quan của bình luận, Review: Nội dung bình luận, Label: lấy một trong 2 giá trị: 1: đánh giá tích cực, -1: đánh giá tiêu cực. Dự án sử dụng mô hình LSTM trong thư viện Keras của Python để phân loại các nhận xét là tích cực hoặc tiêu cực, nhúng vectơ từ bằng công cụ Nhúng trong Keras.
Ứ NG DỤNG THỰC NGHIỆM
- Thư viện sử dụng
- Python
- TensorFlow
- Import các thư viện cần thiết
- Lọc các cột cần thiết bằng cách sử dụng DataFrame của pandas
- Thiết lập tập dữ liệu cho việc huấn luyện và thử nghiệm
- Huấn luyện mô hình
- Đánh giá độ chính xác của mô hình
- Kết quả đánh giá dữ liệu test
Tensor là một cấu trúc dữ liệu trong tensorflow đại diện cho tất cả các loại dữ liệu. Việc xếp hạng này rất quan trọng vì nó còn giúp phân loại dữ liệu Tensor. Trong tập dữ liệu nhận xét cho vấn đề này, chỉ các nhận xét được đánh dấu là tích cực khớp với nhãn = '1' và phủ định khớp với nhãn.
Đánh giá tập dữ liệu thử nghiệm: Có nhiều nhận xét tích cực hơn tiêu cực trong dữ liệu này. Hầu hết các mô hình học sâu đều hoạt động tốt hơn khi có bộ dữ liệu lớn. Dự án đã xây dựng chương trình thử nghiệm phân loại dữ liệu bình luận tiếng Việt là tích cực hay tiêu cực.
Độ chính xác của mô hình chưa thực sự cao do dữ liệu vẫn còn một số hạn chế do xử lý trước văn bản do lỗi viết tắt trong nhận xét và dữ liệu huấn luyện nhỏ.